2.1. Grouped WQS Regression
We focus on the simultaneous exposure to many diverse environmental chemicals and use statistical methodology that extends weighted quantile sum regression to model disease risk for groups of exposures. Studies have shown that WQS regression is more sensitive and specific in identifying important chemicals risk factors than traditional regression and regularization methods such as lasso, adaptive lasso, and elastic net [
23]. Grouped WQS was first proposed to allow for multiple groups of chemicals to be considered in the model such that different magnitudes and direction of associations are possible for each group of chemicals [
25]. For example, some types of chemicals may have a positive association with disease while others may have a negative association.
Specifically, GWQS uses data with
components (e.g., chemical exposures) split between
groups with
components in the
group. Within each of these
groups, the components are scored into quantiles (e.g., quartiles 0,1,2,3) that can be plausibly combined into an index and are assigned a weight. The index weights in each group are empirically estimated and constrained to be between 0 and 1 and sum to 1, which helps reduce potential issues with collinearity and can reduce dimensionality through zero or near-zero weights. For a binary outcome
, the general GWQS regression model is
where
represents the weight for the
ith chemical component in the
jth group,
qji is the quantile of the
ith chemical in the
jth group, and the summation
represents a weighted index for the set of
chemicals of interest within group
. The vector
is a vector of covariates for which to adjust with regression coefficients in the vector
. While this is a model of the log-odds of disease, different link functions can be used depending on the type of outcome (e.g., continuous or count).
For estimation of the model parameters in Equation (1),
bootstrap samples of the training set are taken and nonlinear optimization is used to find the parameter values that maximize the log likelihood. In each bootstrap sample
, the estimated vector of weights is used to form the index and the significance of each group effect
is evaluated through a test statistic
. The final index weights are estimated from all the bootstrap samples using the test statistics as
, which is the weighted average of the component weights using the test statistics as weights over the bootstrap samples for component
in group
. The final estimated index for each of the
j chemical groups is then calculated as
. Final estimates of the group exposure effects and associated statistical significance are obtained in a validation data set by fitting the generalized linear model
In addition to estimating the chemical mixture exposure effects, the method allows one to identify the important chemicals in the mixture through the empirically estimated weights.
We have implemented the nonlinear optimization using the solnp function from the R package Rsolnp [
26,
27]. This function uses an augmented Lagrange multiplier method with a sequential quadratic programming interior algorithm. Our implementation is publicly available on The Comprehensive R Archive Network (CRAN) as an R package titled groupWQS to allow users to perform GWQS for their own research [
28].
2.2. Simulation Study Design
To evaluate the performance of GWQS, we generated chemical concentration data over several different exposure scenarios, where the scenarios varied in the number of chemical groups, the amount of correlation among the chemicals, and the strength of group associations with the outcome. There were three sets of scenarios (Scenarios A–C), where the scenarios differed according to the number of total chemicals and number of chemicals in each group. Each scenario had a range of true exposure effect strengths (Strengths 1–5), starting with a null effect and odds ratio (OR) = 1.00 and then increasing in strength (both positive and negative associations) for each group. For positive associations, strengths 2–5 represent odds ratios of 1.50, 2.00, 2.50, and 3.00 respectively. Negative associations were the reciprocals of the aforementioned odds ratios (0.67, 0.50, 0.40, 0.33, respectively). Within each scenario and exposure strength, three strengths of correlation amongst the chemical concentrations were considered: (1) weak correlation of 0.1 across group and 0.5 within group (W), (2) moderate correlation of 0.3 across group and 0.7 within group (M), and (3) strong correlation of 0.5 across group and 0.9 within group (S). The different correlation structures were specified through a matrix and then converted into a covariance matrix. A mean vector and standard deviation vector were selected to generate the covariance matrix and hence allow construction of the data that was distributed as multivariate normal. The sample size for each scenario was 1000 observations.
In the first set of scenarios (Scenario A), two chemical groups consisting of nine different chemicals (with five in the first group of chemicals and four in the second group of chemicals) were generated. After the null effects scenario, the first group of chemicals was set to have a negative association with the outcome, while the second group of chemicals had a positive association. In each of these groups, two of the chemicals were made to be important while the remaining were set to be unimportant through the true chemical weights. The chemicals labeled unimportant were assigned a true weight of 0 while the important chemicals in each group were given an equal weight such that the sum of the weights in each group would equal 1 (e.g., weight of 0.5 for each of two important chemicals in a group).
In the second set of scenarios (Scenario B), a total of 14 chemicals were divided into three groups with group 1 containing the first five, group 2 the next four, and group 3 the last five. After a null effects scenario, group 1 had a negative association with the outcome while groups 2 and 3 had a positive association. Only one chemical per group was important as specified through the weights. The third set of scenarios (Scenario C) was a slight modification of Scenario B where this time groups 1 and 3 had three important chemicals while group 2 had two. The different simulation scenario terms are listed in
Table 1 as a reference. These terms are used when presenting the results of the simulation study.
After defining the exposure scenarios, we created binary outcomes for case or control status to replicate a case-control study by having a relatively balanced number of cases and controls (50% ± 10% cases) in each iteration of data generation. Each data set generated was split in half to form a training dataset and a testing dataset (500 observations each). The binary outcome y was distributed as where and , where the star notation indicates true parameter values. As no covariates were used in generation of the data, the term . The number of quantiles used in all simulations was set at four when computing the weighted index for each group (i.e., ). Each scenario was simulated with 100 data sets.
For a comparison of GWQS with other methods, we also fitted WQS regression, lasso [
29], and group lasso [
30] to the simulated data using quantiles of exposures. Lasso imposes an L1 penalty (tuned by the parameter
) to a traditional regression model that can shrink some regression coefficients to zero while satisfying an objective function (i.e., minimizing AIC for model fit):
The group lasso applies a penalty to groups of the predictors as:
For both lasso and group lasso, we used 10-fold cross-validation for choosing the penalty term that minimized the Akaike Information Criterion (AIC). AIC is an estimator of out-of-sample prediction error, often used to compare the fit of different models to the same data (smaller AIC is better). We used a bi-level (group and component level) penalty known as group minimax concave penalty (MCP) for the group lasso to be more in spirit with the dimension reduction in the GWQS model [
31]. More specifically, the group MCP places an outer MCP penalty on a sum of inner MCP penalties for each group, resulting in differential shrinkage of regression coefficients for components inside a group (in contrast to uniform shrinkage of all components in a group).
To assess the performance of the models, we calculated the mean squared error (MSE), bias, and power on each of the group exposure effects and the sensitivity and specificity of identifying chemicals as important or not. Power is the probability of a hypothesis test detecting an effect if there is an effect to be found (i.e., chemical group associated with childhood leukemia). When calculating power, we used α = 0.05 to determine the significance of the association of each chemical group with the outcome. We measured sensitivity by determining the proportion of important chemicals that were identified by the models as being important. This was done by determining if the estimated weight of the important chemicals produced by the GWQS and WQS models was greater than or equal to the threshold . Likewise, we defined specificity as the proportion of the unimportant chemicals that were correctly deemed unimportant by the GWQS and WQS models. This was determined by checking if the estimated weights of the unimportant chemicals were less than the same threshold of .
For lasso and group lasso, the threshold on the estimated regression coefficients for calculating sensitivity and specificity was 0.0001. As p-values are typically not computed for these lasso methods, we calculated power in two different ways and presented them as a lower and upper bound. The lower bound was calculated by placing all the chemicals with non-zero weights into a generalized linear model and determining whether any chemicals in each group had a p-value less than 0.05. The proportion of datasets where this occurred was calculated as the lower bound of power. The upper bound was calculated by determining the proportion of datasets where at least one chemical in group had an estimated effect size greater than or equal to . Because the lasso models do not provide a group exposure effect coefficient like GWQS and WQS, we calculated MSE and bias using the differences of the true group effect multiplied by the true weight and the estimated chemical regression coefficients from the model. We summed the estimated regression coefficients overall for lasso and by group for the group lasso and exponentiated to get estimated health effects from the lasso and group lasso models.
2.3. Data Analysis
As an application of the grouped index method to actual data, we used GWQS regression to analyze childhood leukemia in the CCLS. The CCLS is a population-based case-control study conducted in northern and central California (17 counties in the San Francisco Bay area and 18 counties in the Central Valley) designed to examine the relationships between various environmental exposures, genetic factors, and childhood leukemia [
17]. Cases ≤ 14 years of age were identified within 72 h after diagnosis from the nine major pediatric clinical centers in the study area from 1995 to 2012. Eligible criteria include (1) age under 15 years, (2) without prior cancer diagnosis, (3) residence in California at the time of diagnosis, and (4) having an English or Spanish-speaking biological parent. Controls were selected from California birth certificate files and matched to cases on date of birth, sex, Hispanic ethnicity, and maternal race.
As part of a second interview (first interviews were conducted from December 1999 to November 2007) dust samples were collected from homes of cases and controls younger than 8 years at diagnosis (similar reference date for controls) who were still living at the diagnosis home. Eligibility was limited to younger cases and controls so that the carpet dust sample would reflect exposures over a substantial portion of the child’s early life. A total of 277 eligible cases and 308 eligible controls participated in the second interview (n = 583).
Dust samples were collected by high-volume small surface sampler (HVS3) from a carpet or rug in the room where the child spent the most time while awake (commonly the family room). Vacuum dust samples were collected by removing the used bag or by emptying the loose dust from the household vacuum cleaner into a sealable polyethylene bag. The household vacuum was found to be a reasonable alternative to the HVS3 for detecting, ranking, and quantifying the concentrations of pesticides and other compounds [
32]. As previously described, concentrations of 64 organic chemicals were measured using gas chromatography/mass spectrometry (GC/MS) in multiple ion monitoring mode after extraction with three different extraction methods [
32]. Nine metals were measured using microwave-assisted acid digestion combined with inductively coupled plasma/mass spectrometry (ICP/MS). Due to missing covariate information for some participants, 268 cases and 296 controls were included in this analysis (
n = 564). We considered exposure to 49 chemicals (
Supplementary Table S1) for which at least 20% of the measurements were above the limit of detection. Chemicals concentrations below the limit of detection were imputed to be between 0 and the detection limit using univariate imputation assuming a lognormal distribution.
The concentrations of some of the chemicals measured in the house dust samples were strongly correlated for some chemical pairs. Chemicals with the strongest correlation were in the same chemical class. For example, several PAHs were highly correlated (r > 0.6) with each other (e.g., r = 0.90 for benzo[a]anthracene, chrysene). Some chemicals or congeners within the following chemical classes were also highly correlated: organochlorine insecticides, pyrethroid insecticides, and PCBs. The strong correlations between chemicals in these chemical classes prohibits using traditional regression methods to model cumulative chemical exposure effects and requires mixture analysis methods.
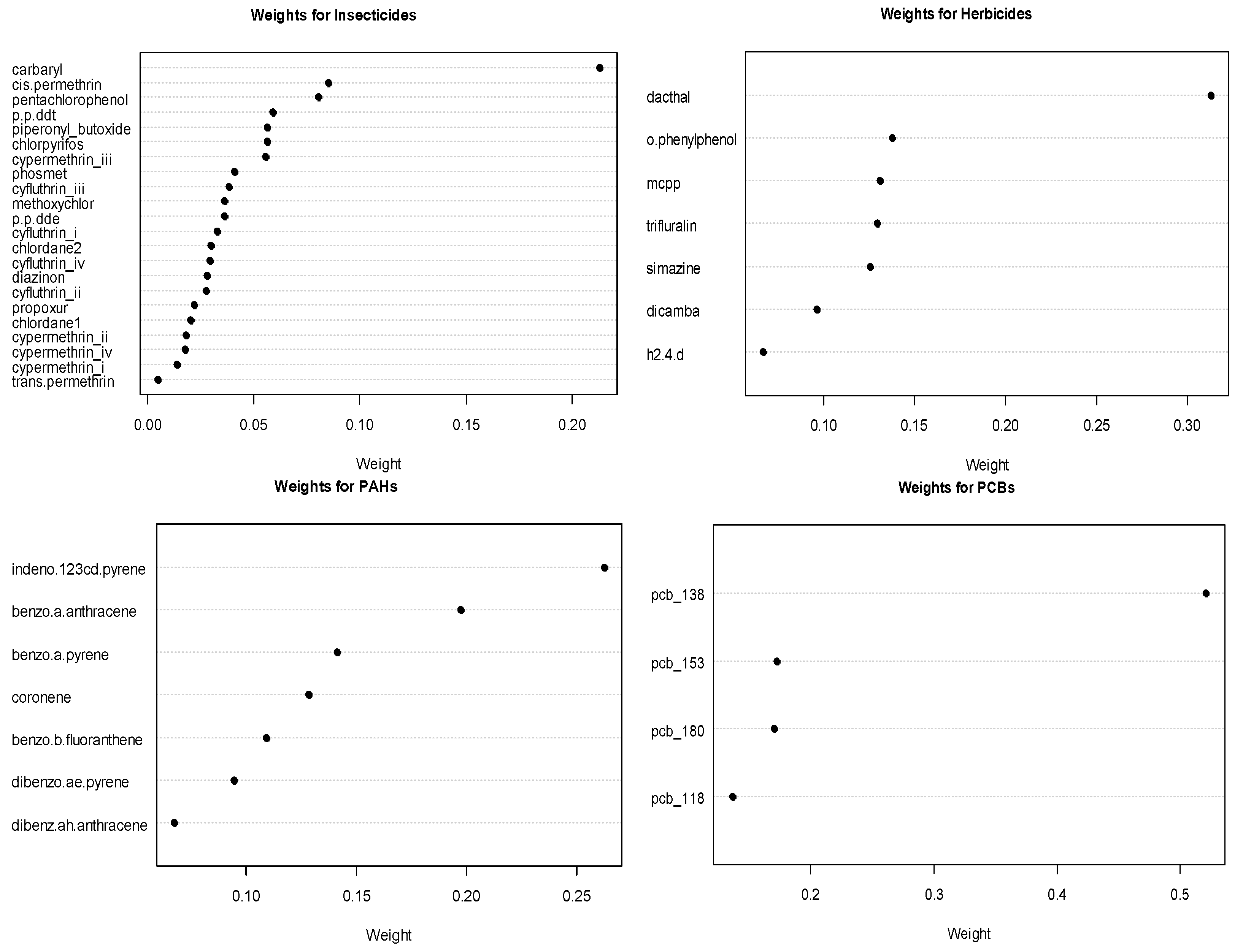
To analyze the association of exposure to the 49 chemicals and childhood leukemia, we placed the chemicals into the following six chemical groups: PCBs, PAHs, insecticides, herbicides, metals, and the tobacco exposure markers of nicotine and cotinine. These groupings were based on structural similarity (e.g., PCBs, PAH) or their use (herbicides, insecticides). We placed the fungicide ortho-phenylphenol in the herbicide group. For the analysis, we estimated the exposure effect for each of the six groups simultaneously for childhood leukemia using GWQS regression. In addition to modeling groups of environmental chemical exposures, we adjusted for the following covariates: child’s age, sex, ethnicity, annual household income, mother’s education level, mother’s age at birth of child, at whether the child lived at the sampling residence since birth. In fitting the GWQS model, we used four quantiles with 100 bootstraps and a 50–50 split of training and validation datasets We summarized the results using ORs for each group along with 95% confidence intervals and forest plots. We also assessed the important chemical exposures in the group using the estimated weights.


 ,
, 


{kind=link}
{kind=link}