Sensitivity of Nutrition Indicators to Measure the Impact of a Multi-Sectoral Intervention: Cross-Sectional, Household, and Individual Level Analysis


Abstract
1. Introduction
2. Materials and Methods
- Child had to be in the same household over time.
- Child had to be of the same gender over time.
- Child had to be within 12 or 24 months (depending on the difference in time between data collection) with a margin of error of plus or minus six months over time. Capturing the true age of a child is notoriously difficult in settings like eastern Chad, due to lack of birth certificates and other documentation. Hence, enumerators use seasons and holidays to place the age of the child and there is likely a wide margin of error.
- is the outcome variable for i-child from j-household at t-time (t = 0, 2, 3 for 2012, 2014, and 2015). In Equation (2), j equals i because we only have one observation per household (nutritionally worst-off or best-off child in the household);
- represents intervention (treatment vs. control) for i-child from j-household;
- represents time for i-child from j-household;
- represents the interaction term between the intervention and time for i-child from j-household;
- represents the vector of k-control child-level variables for i-child from j-household at t-time;
- represents the vector of k-control household-level variables for j-household at t-time;
- is the intercept;
- is the impact of the intervention in 2012;
- is the impact of time in the control group;
- is the impact of the intervention over time;
- is a vector of household-specific intercepts;
- is the error term for i-child;
- is the error term for i-child from j-household at t-time.
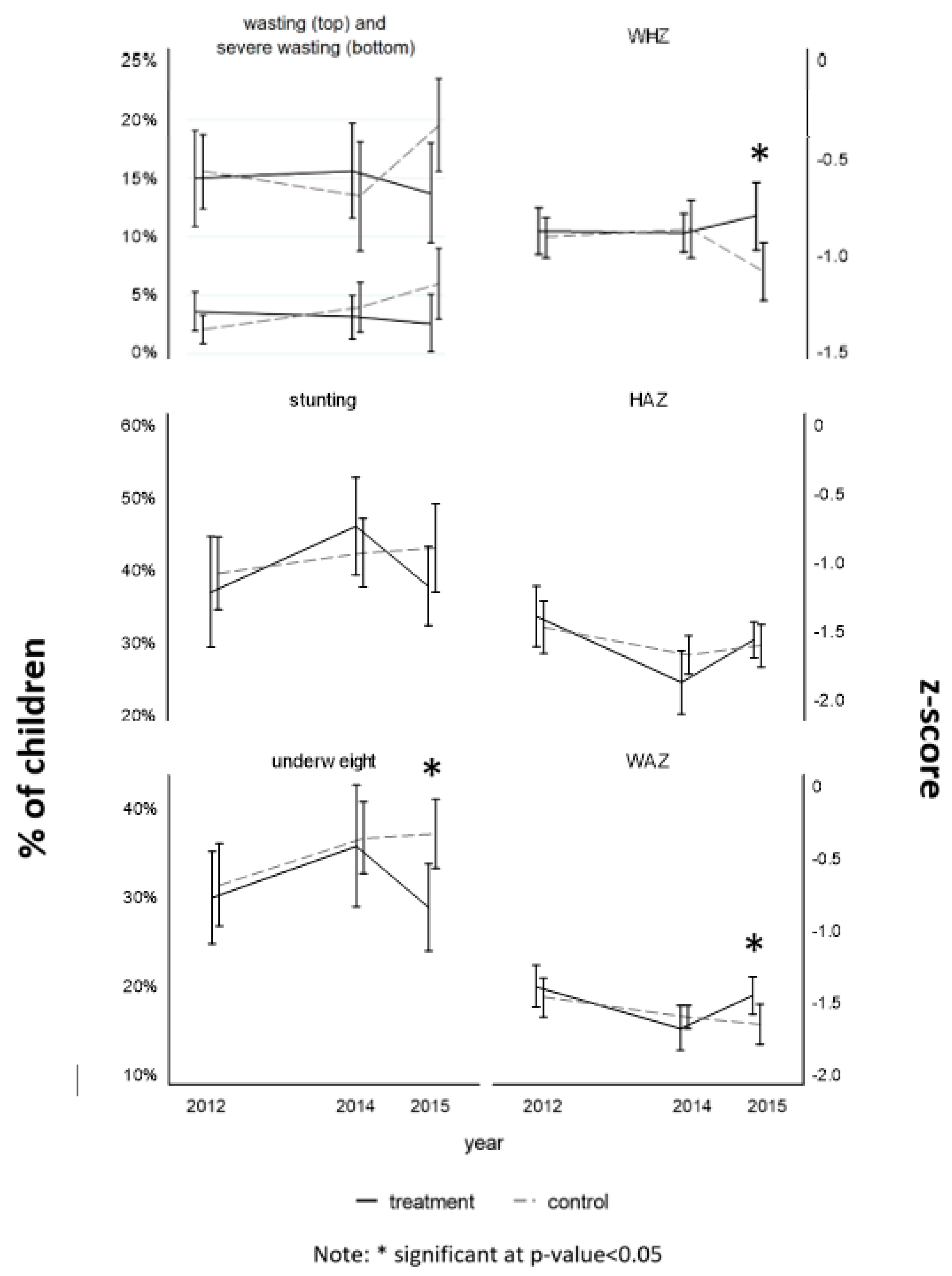
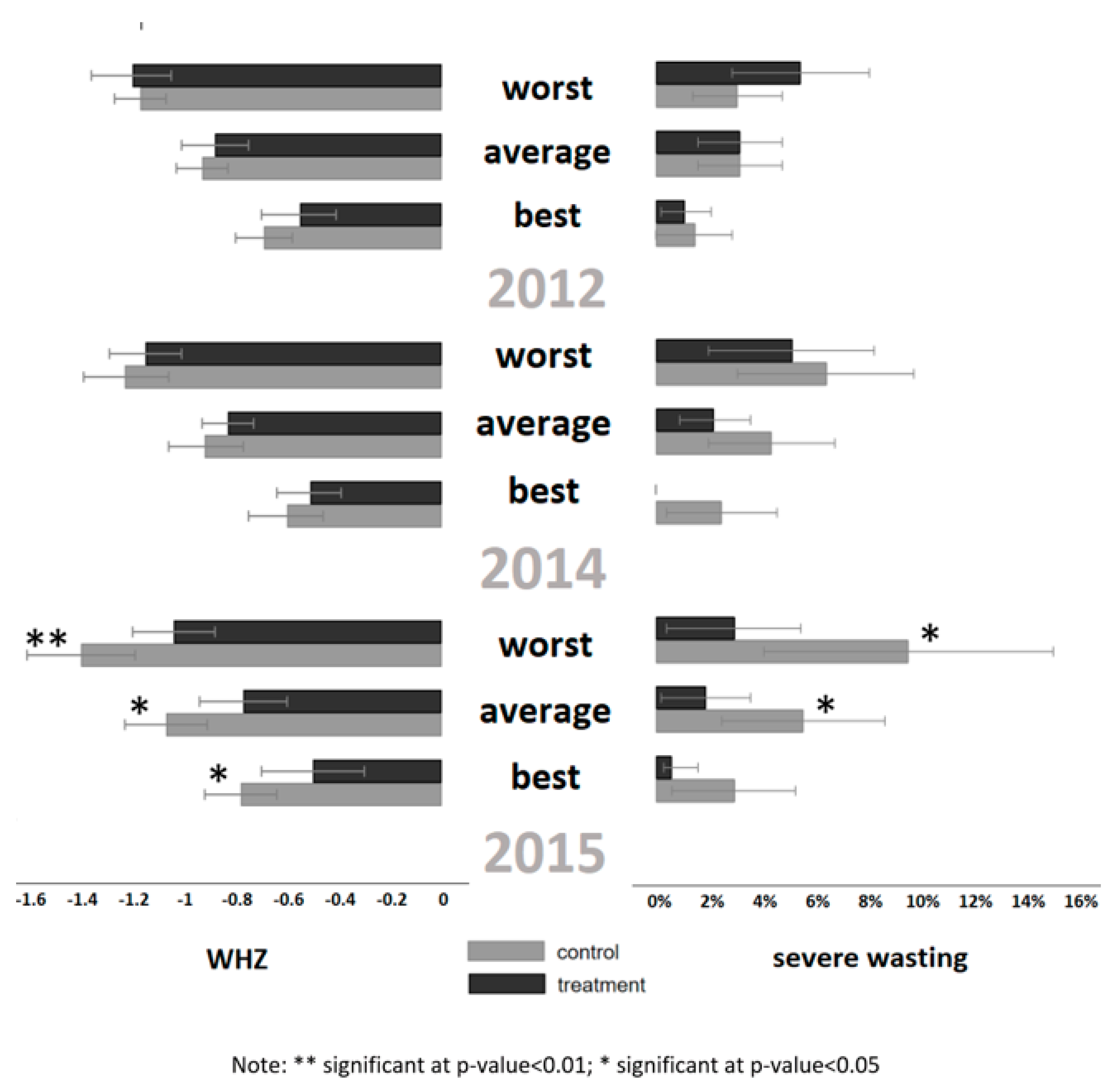
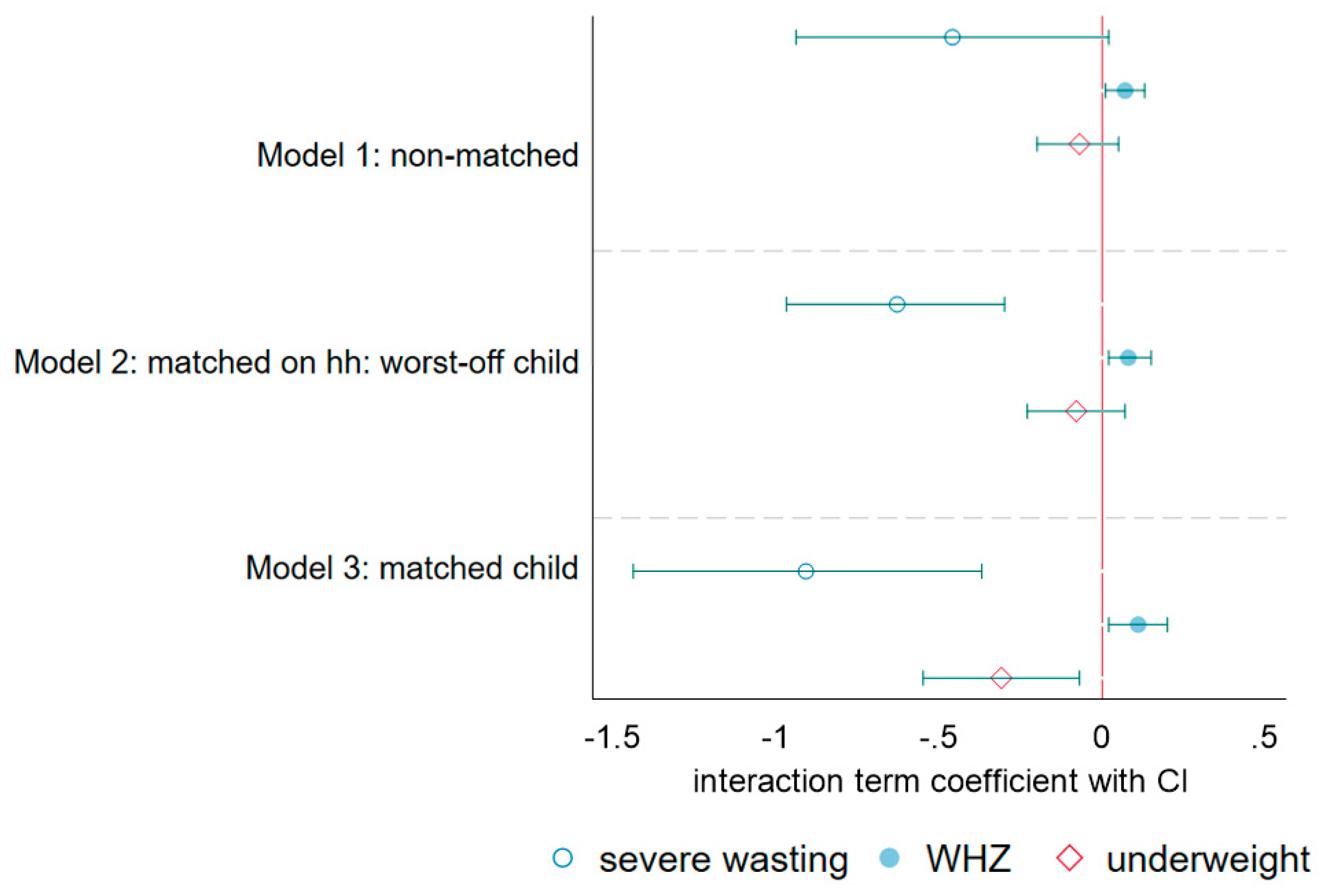
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- UN (United Nations). The 2030 Agenda for the Sustainable Development Goals; UN: New York, NY, USA, 2015. [Google Scholar]
- UNICEF; WHO; The World Bank. Joint Child Malnutrition Estimates-Levels and Trends (2016 edition); The World Bank: Washington, DC, USA, 2016. [Google Scholar]
- Grebmer, K.V.; Patterson, J.B.F.; Andrea Sonntag, L.M.K.; Fahlbusch, J.; Towey, O.; Foley, C.; Gitter, S.; Ekstrom, K.; Fritschel, H. Global Hunger Index: Forced Migration and Hunger; Concern Worldwide: Dublin, Germany; Bonn, Irland, 2018. [Google Scholar]
- DFATD; USAID. REACH (Renewed Efforts Against Hunger and Undernutrition) Annual Report 2013; USAID: Arlington, VA, USA, 2013. [Google Scholar]
- Wuehler, S.E.; Nadjilem, D. Situational analysis of infant and young child nutrition policies and programmatic activities in Chad. Matern. Child Nutr. 2011, 7 (Suppl. 1), 63–82. [Google Scholar] [CrossRef] [PubMed]
- Scaling Up Nutrition (SUN) Movement. SUN Compendium: Chad. The SUN, 2014. Scaling Up Nutrition. Available online: http://scalingupnutrition.org/wp-content/uploads/2014/11/SUN_Compendium_ENG_20141026_37Chad.pdf (accessed on 28 April 2020).
- Garrett, J.; Natalicchio, M. Workin Multisectorally in Nutrition: Principles Practices, and Case Studies; International Food Policy Research Institute: Washington, DC, USA, 2011. [Google Scholar]
- Buchsbaum, A.; Shoham, J.; Harris, J.; McGrath, M. Introduction to teh special issue. Field Exch. 2016, 51. [Google Scholar] [CrossRef]
- Langendorf, C.; Roederer, T.; de Pee, S.; Brown, D.; Doyon, S.; Mamaty, A.A.; Toure, L.W.; Manzo, M.L.; Grais, R.F. Preventing acute malnutrition among young children in crises: A prospective intervention study in Niger. PLoS Med. 2014, 11, e1001714. [Google Scholar] [CrossRef] [PubMed]
- Remans, R.; Pronyk, P.M.; Fanzo, J.C.; Chen, J.; Palm, C.A.; Nemser, B.; Muniz, M.; Radunsky, A.; Abay, A.H.; Coulibaly, M.; et al. Multisector intervention to accelerate reductions in child stunting: An observational study from 9 sub-Saharan African countries. Am. J. Clin. Nutr. 2011, 94, 1632–1642. [Google Scholar] [CrossRef] [PubMed]
- Arifeen, S.; Hoque, E.; Akter, T.; Rahman, M.; Hoque, M.E.; Begum, K.; Chowdhury, E.K.; Khan, R.; Blum, L.S.; Ahmed, S.; et al. Effect of the Integrated Management of Childhood Illness strategy on childhood mortality and nutrition in a rural area in Bangladesh: A cluster randomized trial. Lancet 2009, 374, 393–403. [Google Scholar] [CrossRef]
- Grellety, E.; Luquero, F.J.; Mambula, C.; Adamu, H.H.; Elder, G.; Porten, K. Observational bias during nutrition surveillance: Results of a mixed longitudinal and cross-sectional data collection system in Northern Nigeria. PLoS ONE 2013, 8, e62767. [Google Scholar] [CrossRef]
- Marshak, A.; Young, H.; Bontrager, E.N.; Boyd, E.M. The Relationship Between Acute Malnutrition, Hygiene Practices, Water and Livestock, and Their Program Implications in Eastern Chad. Food Nutr. Bull. 2017, 38, 115–127. [Google Scholar] [CrossRef] [PubMed]
- Marshak, A.; Young, H.; Radday, A. Water, Livestock, and Malnutrition. Findings from an Impact Assessment of “Community Resilience to Acute Malnutrition” Programming in the Dar Sila Region of Eastern Chad, 2012–2015.; Feinstein International Center, Tufts University: Somerville, MA, USA, 2016. [Google Scholar]
- Concern Worldwide. Building Community Resilience to Acute Malnutrition Research Description 2012; Concern Worldwide: Dublin, Ireland, 2015; Available online: http://alliance2015.de-web.ws/fileadmin/Texte__Pdfs/Text_Documents/Round_Table_Dublin_Docs_and_Photos/Alliance2015_Roundtable_Chad_paper_on_CRAM.pdf (accessed on 28 April 2020).
- Ruel, M.T.; Menon, P.; Hobicht, J.-P.; Loechl, C.; Bergeron, G.; Pelto, G.; Arimond, M.; Maluccio, J.; Michaud, L.; Hankebo, B. Age-based preventive targetting of food assistance and behaviour change and communication for reduction of childhood undernutrition in Haiti: A cluster randomized trial. Lancet 2008, 371, 588–595. [Google Scholar] [CrossRef]
- Wamani, H.; Astrom, A.N.; Peterson, S.; Tumwine, J.K.; Tylleskar, T. Boys are more stunted than girls in sub-Saharan Africa: A meta-analysis of 16 demographic and health surveys. BMC Pediatr. 2007, 7, 17. [Google Scholar] [CrossRef] [PubMed]
- Svedberg, P. Undernutrition in Sub-Saharan Africa: Is there a gender bias? J. Dev. Stud. 1990, 26, 469–486. [Google Scholar] [CrossRef]
- Harding, K.L.; Aguayo, V.M.; Webb, P. Factors associated with wasting among children under five years old in South Asia: Implications for action. PLoS ONE 2018, 13, e0198749. [Google Scholar] [CrossRef] [PubMed]
- Baker, P.; Dworkin, S.L.; Tong, S.; Banks, I.; Shand, T.; Yamey, G. The men’s health gap: Men must be included in the global health equity agenda. Bull. World Health Organ. 2014, 92, 618–620. [Google Scholar] [CrossRef] [PubMed]
- Cronk, L. Low Socioeconmic Status and Female-biased Parental Investment: The Mukogodo Example. Am. Anthropol. 1989, 91, 414–429. [Google Scholar] [CrossRef]
- Elsmen, E.I.; Hansen Pupp, H.-W.L. Preterm male infants need more initial respiratory and circulatory support than female infants. Acta Paediatr. 2004, 93, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Larsen, A.F.; Headey, D.; Masters, W.A. Misreporting Month of Birth: Diagnosis and Implications for Research on Nutrition and Early Childhood in Developing Countries. Demography 2019, 56, 707–728. [Google Scholar] [CrossRef] [PubMed]
- Hampshire, K.R.; Panter-Brick, C.; Kilpatrick, K.; Casiday, R.E. Saving lives, preserving livelihoods: Understanding risk, decision-making and child health in a food crisis. Soc. Sci. Med. 2009, 68, 758–765. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Variable | Definition | Options | |
|---|---|---|---|
| Outcome | WHZ | weight-for-height z-score | −5 to 5 z-score |
| Wasting | weight-for-height z-score <−2 | 1 = wasted 0 = non-wasted | |
| Severe wasting | weight-for-height z-score <−3 | 1 = severely wasted 0 = not severely wasted | |
| HAZ | height-for-age z-score | −6 to 6 z-score | |
| Stunting | height-for-age z-score <−2 | 1 = stunted 0 = non-stunted | |
| WAZ | weight-for-age z-score | −6 to 6 z-score | |
| Underweight | weight-for-age z-score <−2 | 1 = underweight 0 = non-underweight | |
| Input | Treatment | whether the hh was in a village randomized to receive CRAM | 1 = treatment |
| 0 = control | |||
| Time | what year the survey was conducted (month = November/December) | 0 = 2012 | |
| 2 = 2014 | |||
| 3 = 2015 | |||
| Time × treatment | interaction term between time and treatment | 0 = control or 2012 2 = treatment in 2014 3 = treatment in 2015 | |
| Control | number of children in hh | number of children (in the roster) under the age of 5 in the hh | 1 to 5 children |
| Female | if the child is female | 0 = boy | |
| 1 = girl | |||
| age | age of the child in months | 6 to 59 months | |
| child died in the household | whether the household reported a child 5 years or younger having died in the past year | 0 = no | |
| 1 = yes | |||
| Design effect | Households | Controlling for household level characteristics | |
| Village | Controlling for village level characteristics | ||
| Sample | Outcome Indicator | Time | Treatment | Time * Treatment | # of Children <5 | Female Child | Age (in Months) | Child <5 Died in hh | Constant | n |
|---|---|---|---|---|---|---|---|---|---|---|
| Non-matched | Wasting | 0.07 (−0.03; 0.19) | 0.05 (−0.31; 0.42) | −0.09 (−0.27; 0.08) | −0.34 ** (−0.55; −0.12) | −0.00 (−0.01; 0.00)) | −0.14 (−0.62; 0.33) | −1.37 *** (−1.75; −0.99) | 3462 | |
| Severe wasting | 0.36 * (0.03; 0.69) | 0.58 (−0.19; 1.37) | −0.45 (−0.93; 0.02) | −0.36 (−0.82; 0.08) | −0.01 (−0.02; 0.00) | −0.26 (−1.26; 0.74) | −3.28 *** (−3.97; −2.58) | 3462 | ||
| WHZ | −0.04 * (−0.08; −0.00) | −0.01 (−0.16; 0.14) | 0.06 * (0.00; 0.12) | 0.09 * (0.01; 0.17) | 0.00 (−0.00; 0.00) | −0.06 (−0.28; 0.15) | −0.96 *** (−1.11; −0.80) | 3462 | ||
| Stunting | 0.04 (−0.01; 0.10) | −0.03 (−0.39; 0.31) | 0.00 (−0.15; 0.13) | −0.24 *** (−0.37; −0.12) | −0.00 (−0.00; 0.00) | 0.02 (−0.34; 0.39) | −0.44 * (−0.45; −0.03) | 3459 | ||
| HAZ | −0.04 (−0.10; 0.00) | −0.02 (−0.24; 0.30) | 0.03 (−0.15; 0.07) | 0.18 ** (0.07; 0.29) | −0.00 (−0.00; 0.00) | −0.01 (−0.31; 0.28) | −1.57 *** (−1.72; −1.41) | 3459 | ||
| Under-weight | 0.09 ** (0.02; 0.015) | −0.02 (−0.34; 0.28) | −0.07 (−0.20; 0.05) | −0.21 ** (−0.35; −0.07) | −0.00 * (−0.01; −0.00) | 0.11 (−0.29; 0.52) | −0.50 *** (−0.78; −0.22) | 3522 | ||
| WAZ | −0.05 *** (−0.09; −0.02) | 0.03 (−0.16; 0.22) | 0.01 (−0.05; 0.09) | 0.12 *** (0.04; 0.19) | −0.00 (−0.00; 0.00) | −0.03 (−0.26; 0.19) | −1.50 *** (−1.67; −0.13) | 3522 | ||
| Matched on the household (worst-off child) | Wasting | 0.03 (−0.09; 0.15) | 0.17 (−0.25; 0.61) | −0.13 (−0.31; 0.04) | 0.47 *** (0.30; 0.63) | −0.39 ** (−0.63; −0.15) | −0.00 (−0.01; 0.00) | −0.29 (−0.85; 0.25) | −2.13 *** (−2.65; −1.60) | 2254 |
| Severe wasting | 0.29 * (0.06; 0.53) | 0.86 * (0.19; 1.54) | −0.63 *** (−0.97; −0.29) | 0.54 *** (0.27; 0.81) | −0.46 * (−0.88; −0.04) | −0.00 (−0.02; 0.00) | −0.17 (−1.14; 0.80) | −4.36 *** (−5.35; −3.37) | 2254 | |
| WHZ | −0.02 (−0.06; 0.02) | −0.06 (−0.25; 0.11) | 0.08 ** (0.01; 0.14) | −0.24 *** (−0.30; −0.18) | 0.13 ** (0.04; 0.22) | 0.00 (−0.00; 0.00) | −0.03 (−0.21; 0.15) | −0.83 *** (−1.02; −0.64) | 2254 | |
| Stunting | 0.02 (−0.06; 0.12) | −0.23 (−0.56; 0.08) | 0.06 (−0.07; 0.21) | 0.34 *** (0.20; 0.47) | −0.33 *** (−0.52; −0.14) | −0.00 (−0.00; 0.01) | 0.09 (−0.31; 0.49) | −0.67 ** (−1.07; −0.27) | 2261 | |
| HAZ | −0.02 (−0.09; 0.04) | 0.07 (−0.15; 0.30) | −0.04 (−0.14; 0.05) | −0.25 *** (−0.34; −0.16) | 0.23 *** (0.10; 0.36) | −0.00 (−0.01; 0.00) | 0.01 (−0.26; 0.28) | −1.41 *** (−1.69; −1.14) | 2261 | |
| Under-weight | 0.09 (−0.00; 0.20) | 0.00 (−0.33; 0.35) | −0.07 (−0.22; 0.06) | 0.35 *** (0.21; 0.49) | −0.37 *** (−0.57; −0.16) | −0.00 (−0.00; 0.00) | 0.12 (−0.30; 0.54) | −0.87 *** (−1.30; −0.44) | 2277 | |
| WAZ | −0.03 (−0.08; 0.01) | 0.01 (−0.16; 0.18) | 0.02 (−0.04; 0.08) | −0.19 *** (−0.26; −0.13) | 0.17 *** (0.08; 0.27) | −0.00 (−0.00; 0.00) | −0.01 (−0.18; 0.20) | −1.42 *** (−1.62; −1.23) | 2277 | |
| Matched on the child | Wasting | 0.06 (−0.13; 0.27) | 0.38 (−0.28; 1.06) | −0.24 (−0.52; 0.03) | −0.35 * (−0.69; −0.01) | −0.00 (−0.01; 0.00) | −0.62 (−1.48; 0.24) | −1.87 *** (−2.46; −1.28) | 1487 | |
| Severe wasting | 0.30 (−0.09; 0.71) | 1.28 ** (0.12; 2.44) | −0.90 *** (−1.44; −0.37) | 0.20 (−0.36; 0.77) | 0.01 (−0.00; 0.03) | −0.39 (−1.84; 1.06) | −4.42 *** (−5.77; −3.08) | 1487 | ||
| WHZ | -0.04 (−0.10; 0.02) | −0.13 (−0.39; 0.12) | 0.10 * (0.01; 0.20) | 0.03 (−0.08; 0.15) | 0.00 (−0.00; 0.00) | −0.01 (−0.27; 0.25) | −0.92 *** (−1.1-2; 0.71) | 1487 | ||
| Stunting | 0.04 (−0.11; 0.20) | −0.08 (−0.62; 0.45) | −0.06 (−0.15; 0.28) | −0.43 ** (−0.71; −0.15) | −00 (−0.00; 0.01) | −0.09 (−0.72; 0.52) | −0.41 (−0.86; 0.03) | 1487 | ||
| HAZ | −0.06 (−0.15; 0.03) | −0.11 (−0.43; 0.21) | 0.01 (−0.10; 0.14) | 0.34 *** (0.18; 0.51) | −0.00 (−0.00; 0.00) | 0.26 (−0.08; 0.62) | −1.60 *** (−1.87; −1.34) | 1487 | ||
| Under-weight | 0.20 * (0.02; 0.37) | 0.52 (−0.07; 1.12) | −0.30 * (−0.54; −0.06) | −0.48 ** (−0.79; −0.16) | 0.00 (−0.00; 0.01) | −0.52 (−1.24; 0.18) | −1.00 *** (−1.51; −0.49) | 1505 | ||
| WAZ | −0.05 (−0.12; 0.00) | −0.13 (−0.36; 0.09) | 0.06 (−0.02; 0.15) | 0.19 *** (0.07; 0.31) | −0.00 (−0.00; 0.00) | 0.15 (−0.10; 0.40) | −1.47 *** (−1.66; −1.28) | 1505 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marshak, A.; Young, H.; Radday, A.; Naumova, E.N. Sensitivity of Nutrition Indicators to Measure the Impact of a Multi-Sectoral Intervention: Cross-Sectional, Household, and Individual Level Analysis. Int. J. Environ. Res. Public Health 2020, 17, 3121. https://doi.org/10.3390/ijerph17093121
Marshak A, Young H, Radday A, Naumova EN. Sensitivity of Nutrition Indicators to Measure the Impact of a Multi-Sectoral Intervention: Cross-Sectional, Household, and Individual Level Analysis. International Journal of Environmental Research and Public Health. 2020; 17(9):3121. https://doi.org/10.3390/ijerph17093121
Chicago/Turabian StyleMarshak, Anastasia, Helen Young, Anne Radday, and Elena N. Naumova. 2020. "Sensitivity of Nutrition Indicators to Measure the Impact of a Multi-Sectoral Intervention: Cross-Sectional, Household, and Individual Level Analysis" International Journal of Environmental Research and Public Health 17, no. 9: 3121. https://doi.org/10.3390/ijerph17093121
APA StyleMarshak, A., Young, H., Radday, A., & Naumova, E. N. (2020). Sensitivity of Nutrition Indicators to Measure the Impact of a Multi-Sectoral Intervention: Cross-Sectional, Household, and Individual Level Analysis. International Journal of Environmental Research and Public Health, 17(9), 3121. https://doi.org/10.3390/ijerph17093121