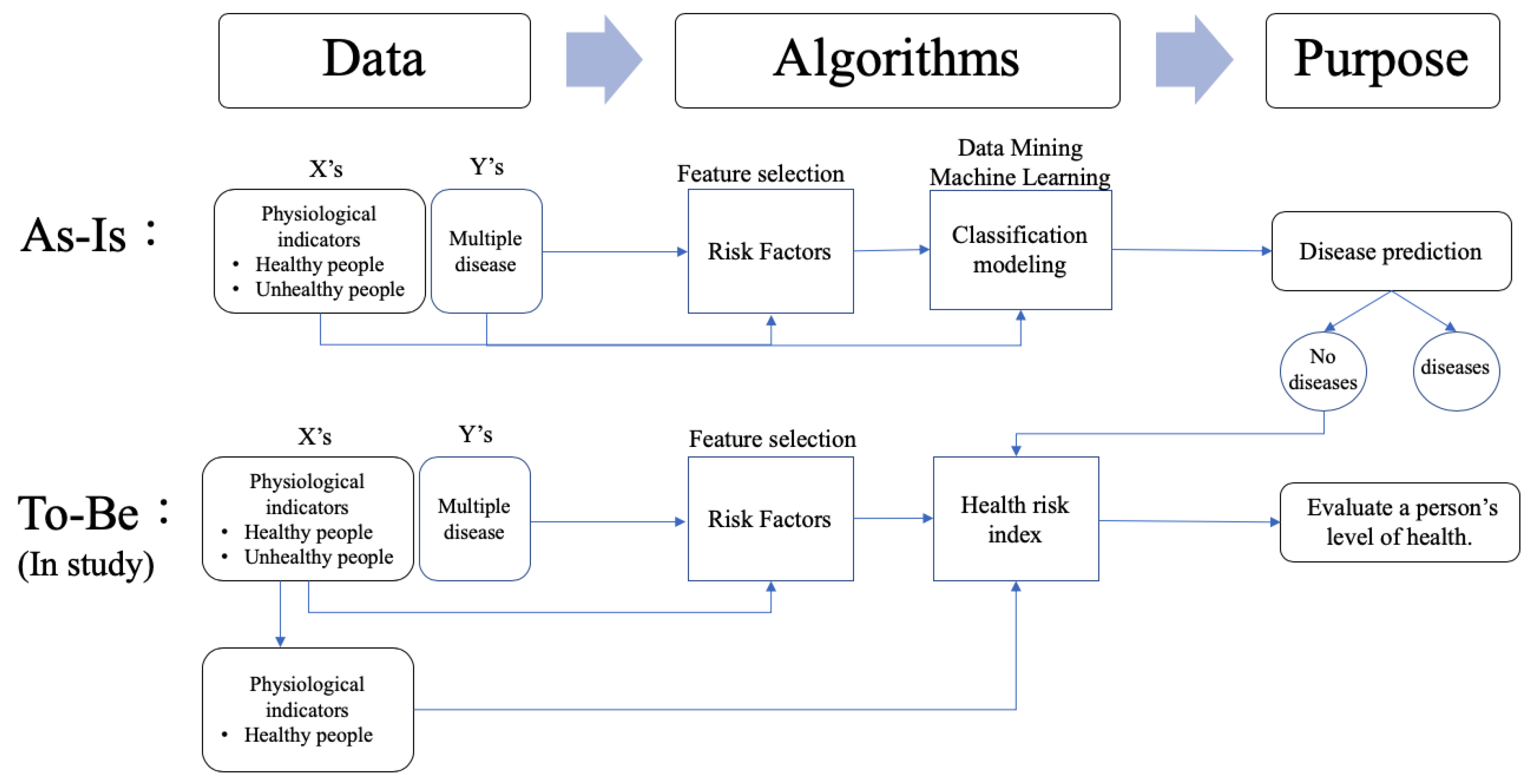
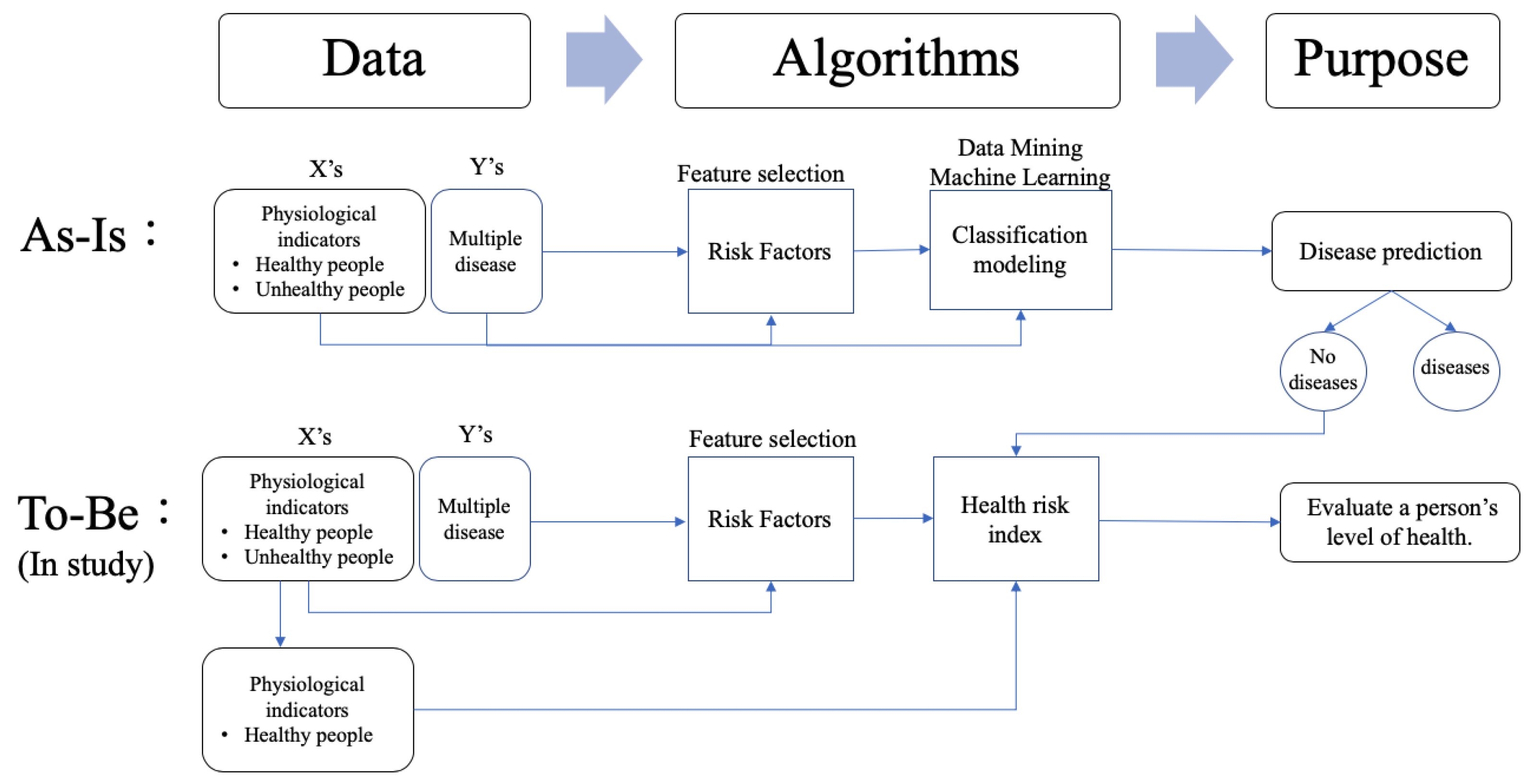
This study proposed a novel three-stage analysis procedure involving the feature selection method, the kernel density estimation method, and mathematical approaches to calculate the health risk index of healthy people. Stage 1 adopted the findings from our previous study [
8]. The procedure used six classification techniques to individually screen for the key risk factors for multiple diseases. Based on the results of previous research [
8], we used five common risk factors: fasting plasma glucose (FPG), total cholesterol (T-CHO), TGs, SBP, and DBP, to determine the risks for hypertension, hyperlipidemia, and hyperglycemia. After identifying these risk factors, we compared the risk factors for each disease to determine the common risk factors for multiple diseases. Stage 2 used the kernel density estimation method to fit density curves for the common risk factors individually. Finally, stage 3 calculated the health risk index based on the kernel density function of the common risk factors. The two primary methods of kernel density estimation and the calculation of the health risk index are described below. The proposed methodology is explained below using data on 6496 subjects (3104 males and 3392 females) with Triple H disease from the National Health Insurance Research Database in Taiwan and the research results of Stewart et al. [
11], who conducted a six-week exercise intervention. The reason for applying Stewart et al. [
11] research data is that the five risk factors proposed are the same as the five common risk factors in this study. Also, the effectiveness of preventive maintenance was evaluated using a health risk curve.
2.1. Kernel Density Estimation Method
The kernel density estimation approach was first described by Rosenblatt [
17] and Parzen [
18]. It is a nonparametric statistical method used to estimate an unknown probability distribution. The method does not require a priori knowledge or make any additional assumptions regarding data distribution. In practice, it is often assumed that the values of the risk factor follow a normal distribution; however, this assumption lacks strong supporting evidence. Therefore, in this study, we adopted the kernel density method to estimate the risk factor distribution.
If
are independent and identically distributed unknown observations, the probability density function
can be estimated by the kernel density function as follows:
where
is a kernel function that was symmetric and integrated into one. The
variable is the bandwidth to determine the degree of smoothness of the kernel function. This study evaluated six types of common kernel functions, including Gaussian, Epanechnikov, Triangular, Uniform, Bright, and Cosine, to estimate the kernel density values for all the common risk factors.
Table 1 shows the six common types of kernel functions.
When using the kernel density estimation method, we must choose the kernel function and set the bandwidth. The choice of kernel function was adopted through the six common types in
Table 1. To select the kernel function, all values of the risk factors were initially used to calculate the probability density value as the real density value. Then, the six common types of kernel functions in
Table 1 were used to estimate the kernel density function for the risk factor as the estimated density value. Finally, a suitable kernel function was chosen using the minimum difference between the sum of the real density value and the estimated density value. Therefore, each density function of the risk factors might be fitted with different kernel functions.
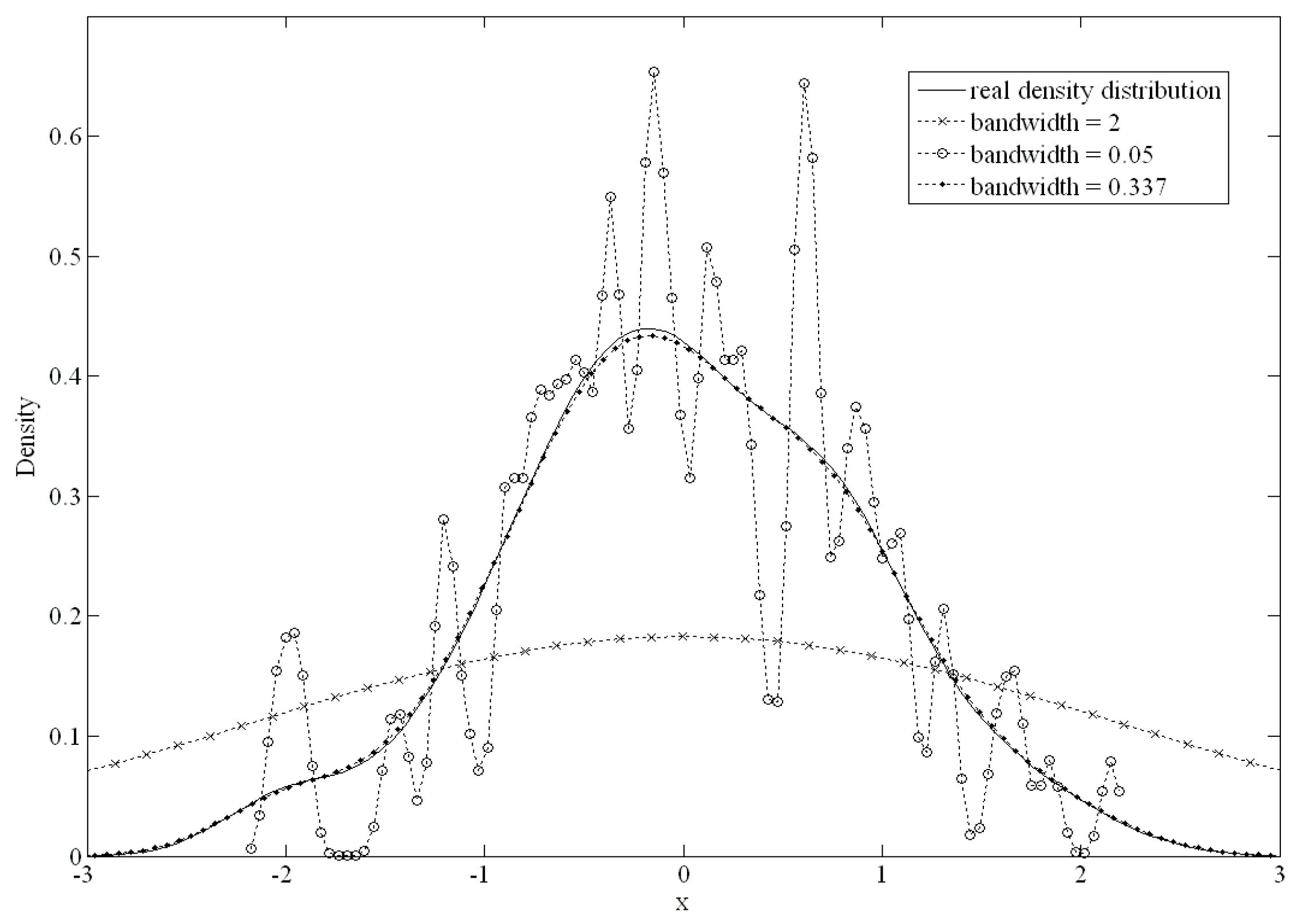
The bandwidth of the kernel function is an important parameter that has a strong influence on the resulting estimate. A narrow bandwidth would allow more over-fitting of the data. Conversely, an overly wide bandwidth would not have an appropriate data fit.
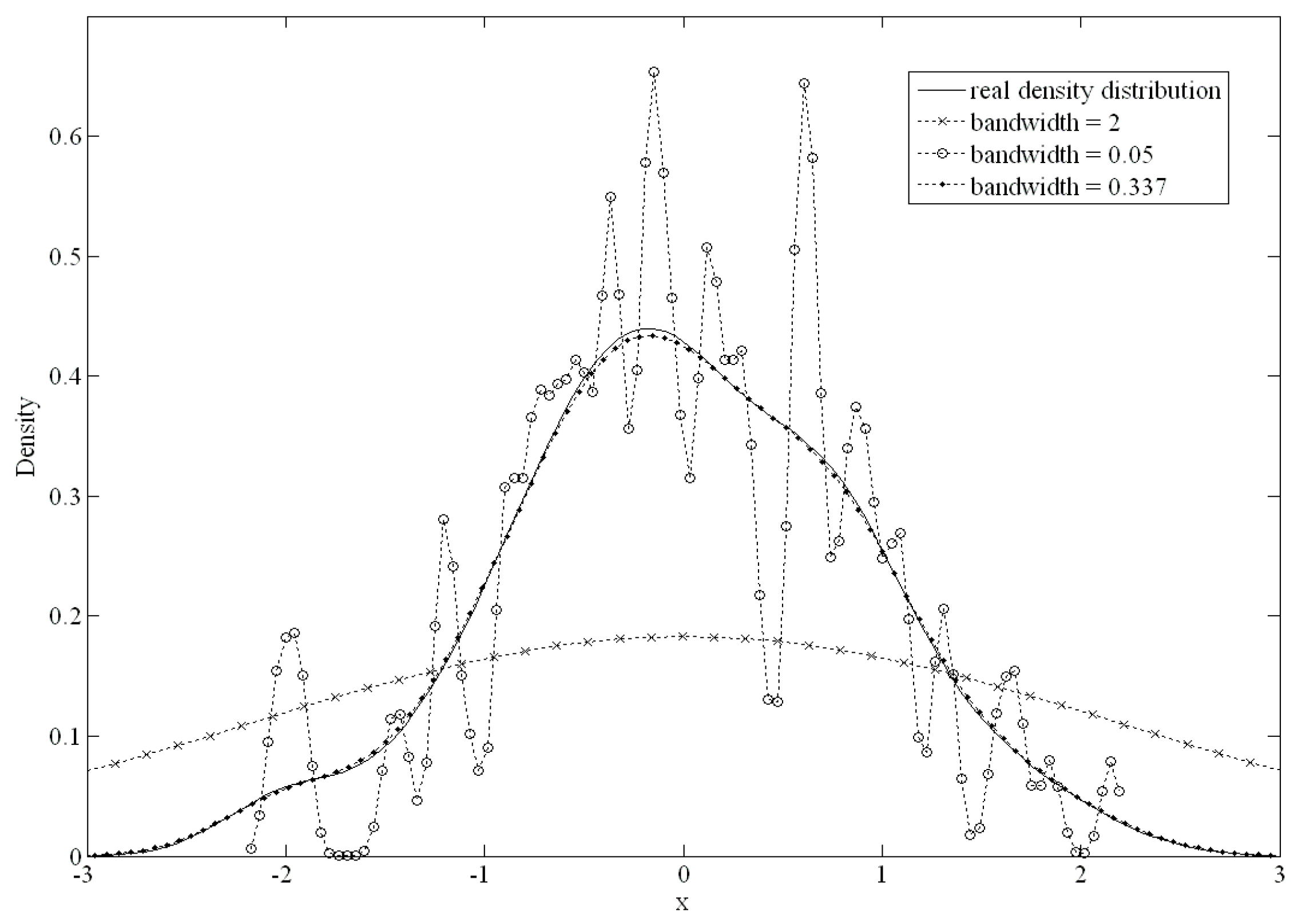
Figure 2 shows the differences from 100 standard normally distributed datapoints. When the bandwidth was set to 0.05 or 2, there was a large difference from the original density distribution; conversely, if the bandwidth was set to 0.337, there was an excellent fit.
The mean integrated squared error (
MISE) was used to choose the best bandwidth. The
MISE can be calculated as follows:
The
MISE was separated into two parts including
and
.
was the estimated density value using the kernel function, and
was the unknown true density value.
using the Taylor expansion method was derived as
,
and
.
n and
h were the sizes of the data and bandwidth, respectively. If
n was large and
h was small, the variance of
can be derived as
. Therefore, an approximate mean integrated squared error (
AMISE) was calculated as follows:
We estimated the optimal bandwidth by minimizing
AMISE regarding
h by the first derivative. The optimal bandwidth
h was:
In practice, the above formula has an infinite loop problem when calculating both
and an unknown function
. Liu et al. compared the accuracies of nine types of bandwidth selection methods and found that no particular method performed better for all problems [
19]. Therefore, in this study, we used the NDR0 method, which was suggested by Liu et al. [
19]. The NDR0 method has the advantage of being easily calculated using the standard deviation (
) and inter-quartile range of the dataset. The bandwidth can be calculated using the NDR0 as follows:
From the above procedure, we can determine the probability density function of the risk factors using the kernel density estimation approach. Next, the health risk index was proposed to estimate the health status of healthy people.
2.2. Health Risk Index Calculation
The
was defined as a function of human health evaluation; it describes the
t value of the risk factor once it has reached a certain value for a physiological state that was still healthy. In other words,
is the health risk at value
t for a particular risk factor. With an increase in the risk factor value, the disease or health risk will also increase. We assumed that
n of multiple diseases were studied, and there was one normal state (healthy people) and (
) combinations of people who suffered from different diseases. The
variable is representative of healthy individuals with the
ith risk factor in the probability density function. The
variables represent the probability density function of the different combinations of diseases with the
ith risk factor. The probability density function used the kernel density estimation approach. In this study, the health risk index
was defined for healthy people with the
ith risk factor and was calculated as follows:
where
t represents the value of the
ith risk factor, and the interval
represents the range of values in the
ith risk factors for healthy people.
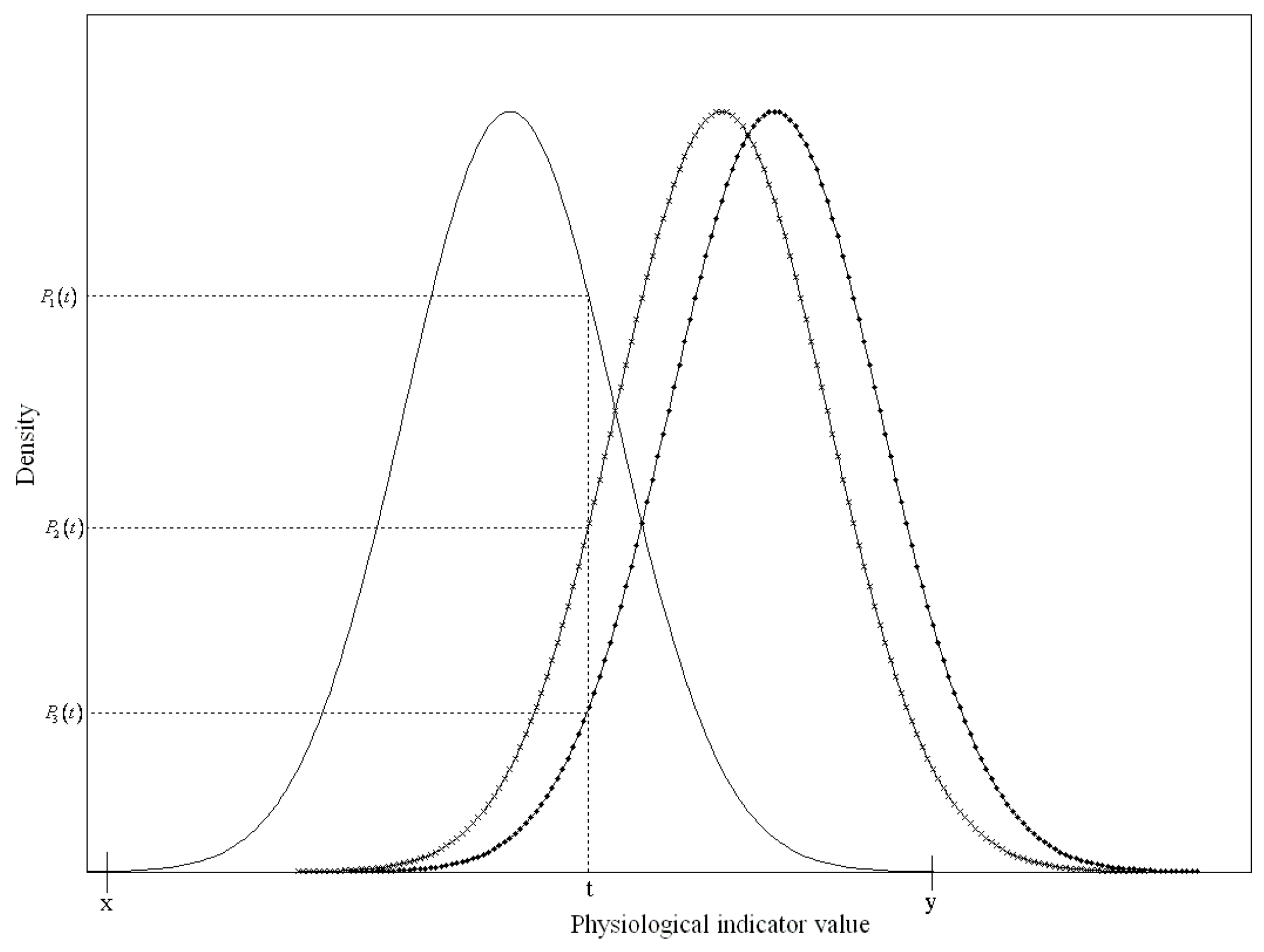
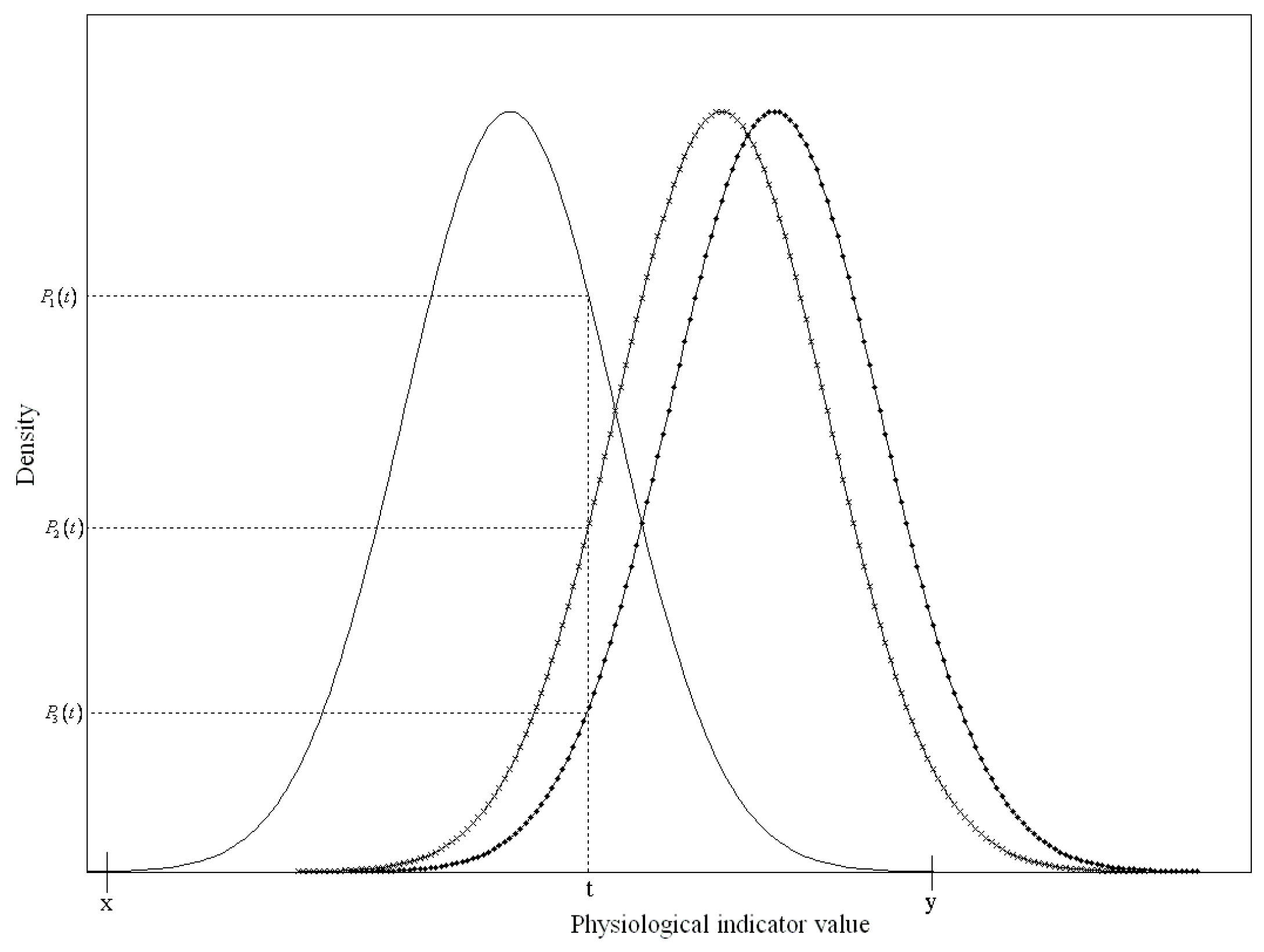
Figure 3 presents an example of three different status functions of a risk factor to describe the health risk index. The solid line represents the function of the risk factor values of healthy subjects, and the other two lines with signs represent groups that suffered from different diseases.
Since the
t value of the risk factor only fell onto the
x and
y-axes for healthy subjects when it was between
x and
y,
was the ratio of the probability density of the normal group
to all of the probability densities of the three status functions. Therefore,
can be simplified as:
Each probability density value was a positive number less than 1. Therefore, was between 0 and 1.
If any of the risk factors were over the threshold values, we determined that the person had the disease(s). Therefore, the health risk index
for a healthy person can be presented as follows:
We can plot the curve of the health risk index from
for all
t values of the risk factors. According to the health risk index curve, we can then evaluate the effect on health risks when risk factors change after a period of maintenance activities (such as exercise or diet control).
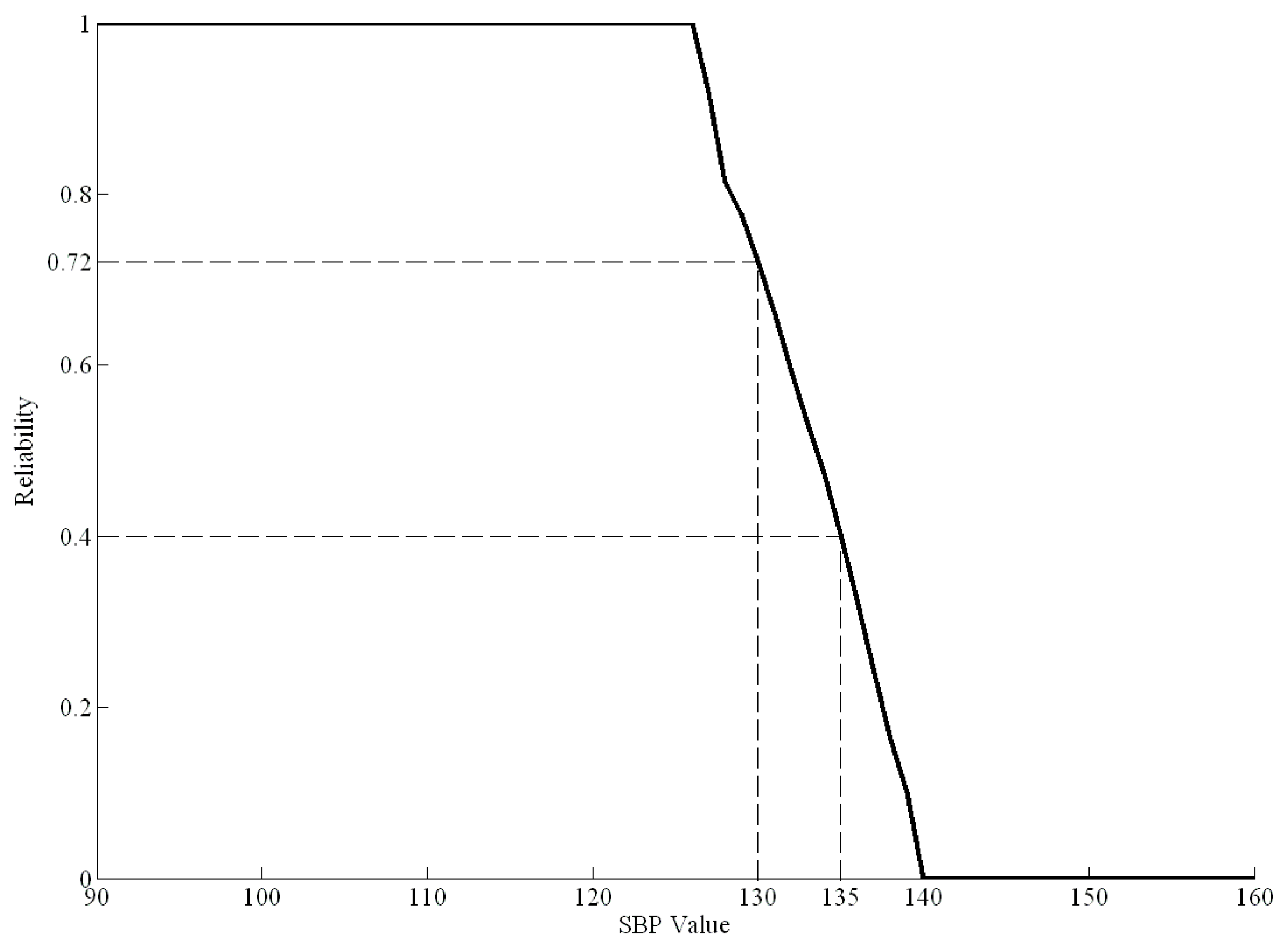
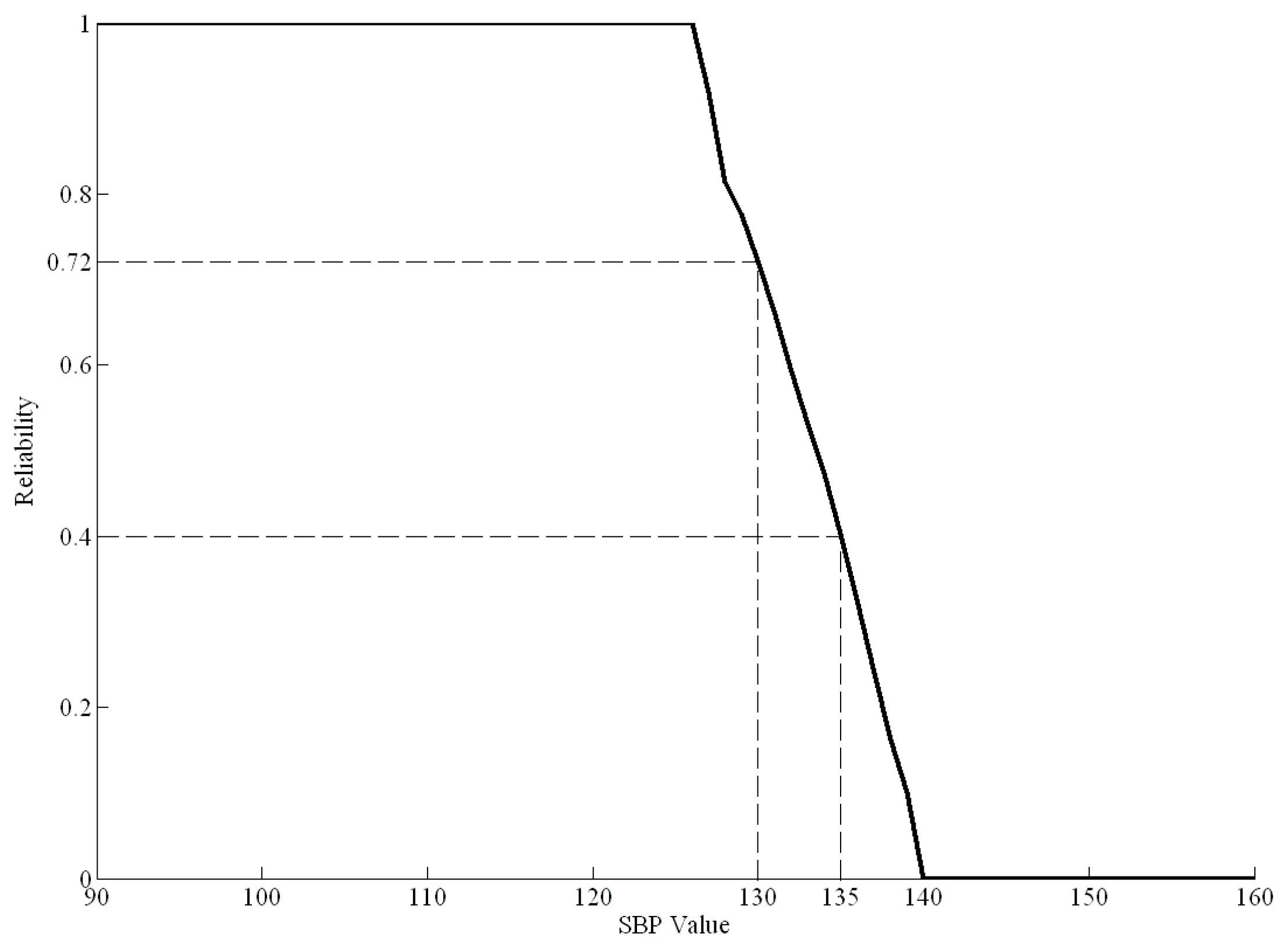
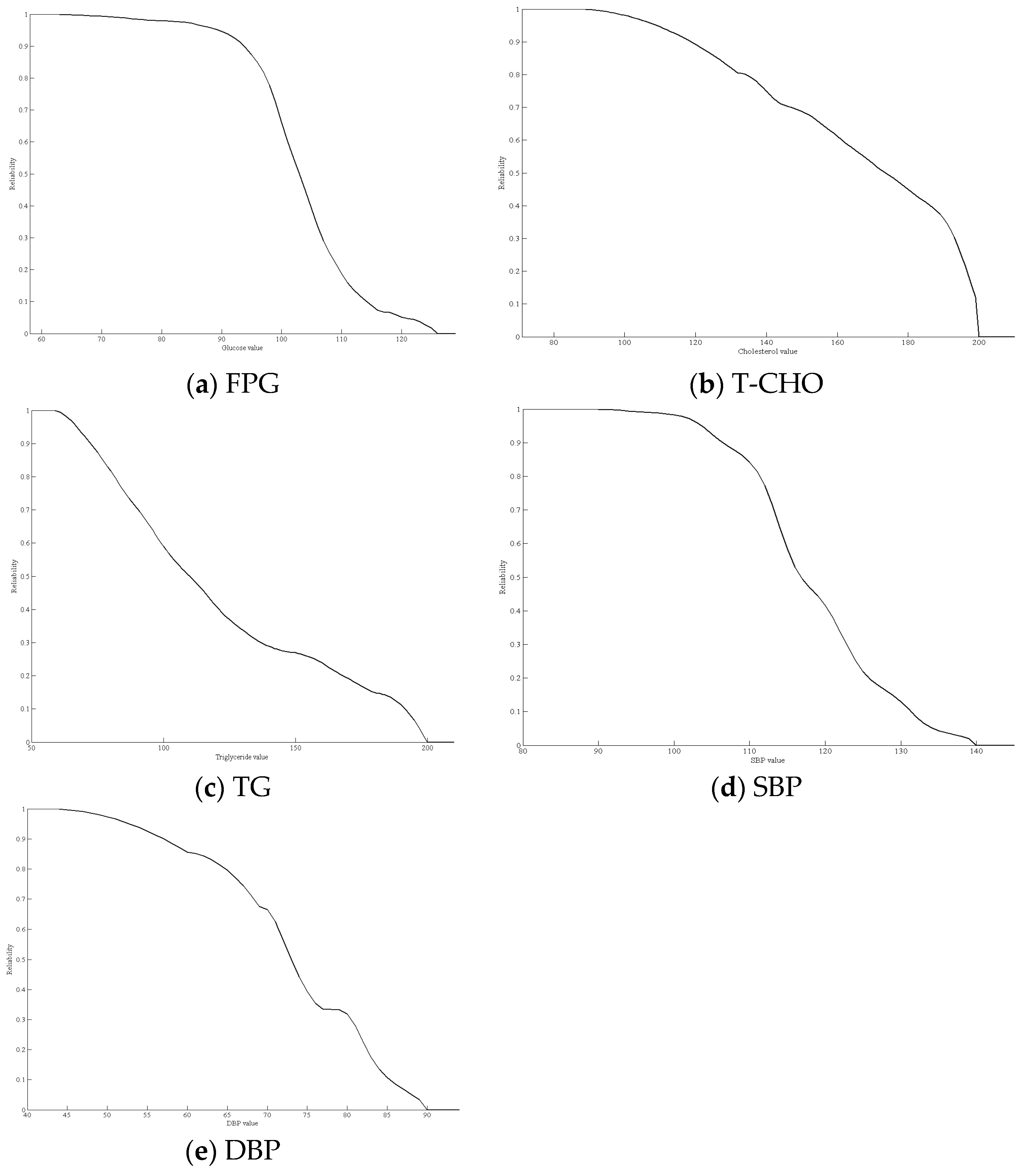
Figure 4 shows an example of the health risk curve for SBP from 90 to 160 mmHg based on real data.
In
Figure 4, when the SBP is greater than 127 mmHg, the health risk curve begins to decline, indicating a gradual decline in health. When the SBP is greater than 140 mmHg, the health risk index is zero, indicating that the individual has the disease. For example, if a healthy person had an SBP of 135 mmHg before dietary control, the health risk index
of SBP would be 0.4. Moreover, if their SBP decreased to 130 mmHg after a period of dietary control, the new health risk index
of SBP would be 0.72. Therefore, the difference value between 0.4 and 0.72 (0.32) is the effect of the dietary control.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}