A Cross-Reconstruction Method for Step-Changed Runoff Series to Implement Frequency Analysis under Changing Environment


 ,
, 
Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
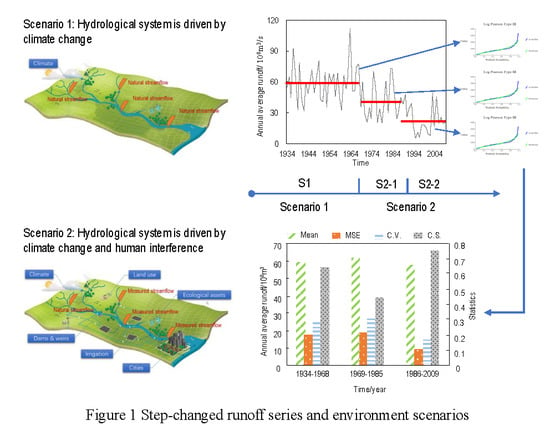
2.1. Step-Changed Runoff Series and Environment Scenarios
2.2. Pettitt Test and Iterative Cumulative Sum of Squares for Segmentation
2.2.1. Pettitt Test
2.2.2. Iterative Cumulative Sum of Squares
- (a)
- If Dk oscillates around zero, it represents that there is no change in the variance over the whole period;
- (b)
- If Dk departs from zero, it means that there are one or more shifts in variance;
- (c)
- If the maximum of exceeds the boundary values that are obtained from the asymptotic distribution of Dk, assuming constant variance, a significant shift in variance occurs at k. The 5% significant level is selected in the study, and ±1.358 is the asymptotic critical value.
2.3. Empirical Mode Decomposition
- (a)
- Identify all local extrema containing the maxima and minima of the original time series , and then fit all the local extrema with a cubic spline function to produce the lower and upper envelopes, and , respectively.
- (b)
- Compute the mean of the envelopes by .
- (c)
- Obtain the new series by .
- (d)
- Check whether is a nonstationary series; if yes, the above procedures must be repeated k times until . If not, is regarded as the first intrinsic mode function (IMF) as . The first IMF represents the highest frequency component of the original series.
- (e)
- Calculate the margin series , and the second IMF can be obtained from it. Such a procedure needs to be repeated until the last margin series is a monotone series and can’t be decomposed further. At this point, the decomposing is finished, and n-1 IMFs and a residual component are obtained where the residual represents the mean trend of the original series. If calculating the summation of all IMFs and the residual, the original series can be reconstructed as follows:
2.4. Kolmogorov–Smirnov (K-S) Test
2.5. Cross and Reconstruction
2.5.1. Cross Procedure
2.5.2. Runoff Reconstruction
- (a)
- The original runoff series are segmented based on change points in mean and variance.
- (b)
- Each segmented series should take the logarithm of an extended data series with the neural network for mitigating the boundary error [30], which is then decomposed by EMD. At this moment, multiple intrinsic mode functions (IMFs) and a residual trend term (Residual) of each segment can be obtained.
- (c)
- All the IMFs are done with the similarity detection by the K-S test. The similar IMFs are combined and superimposed. Figure 3 shows that each segment can be reconstructed by when the decomposed IMFs of each segment are similar, and the original series can eventually be expanded to a new sample with the size of .
3. Method Validation
4. Application
4.1. Study Area and Data
4.1.1. Study Area
4.1.2. Data
4.2. Results
4.2.1. Segmentation
4.2.2. Decomposition
4.2.3. Kolmogorov–Smirnov (K-S) Test
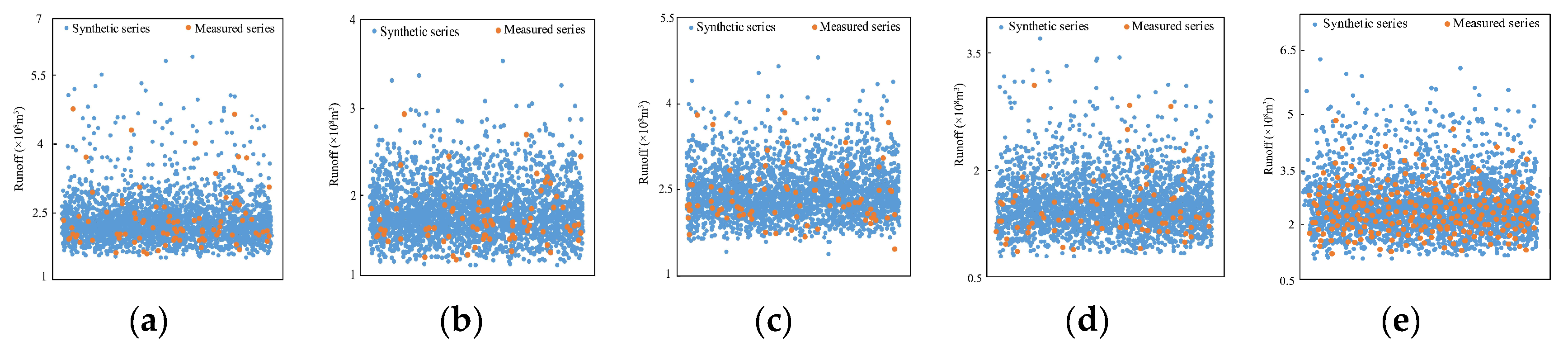
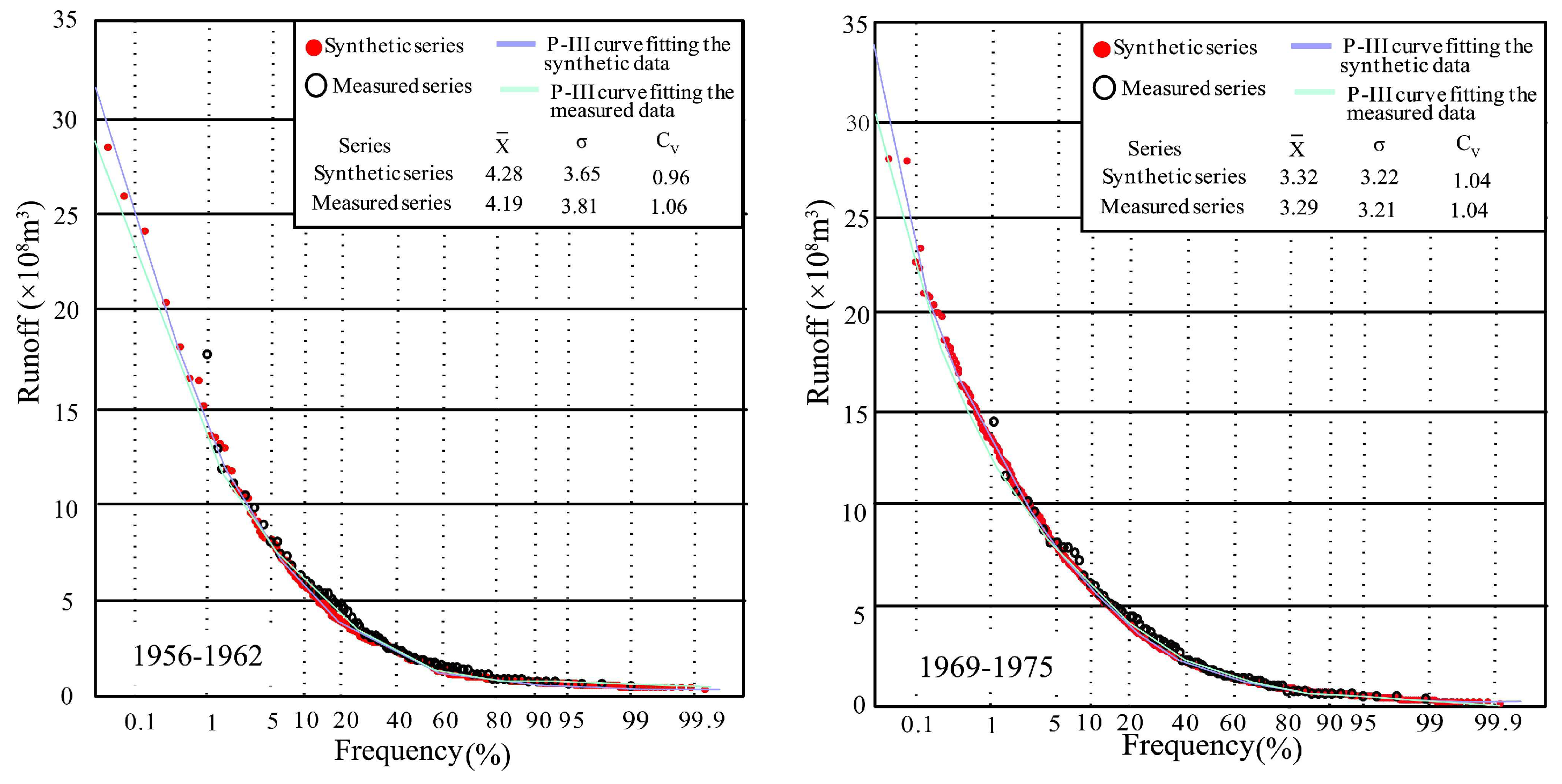
4.2.4. Cross and Reconstruction
4.3. Discussion
5. Conclusions
- (a)
- The cross-reconstruction method can effectively implement the data expansion and obtain the synthetic series meeting the requirement of data capacity for frequency analysis, which is closer to the population.
- (b)
- The synthetic series obtained can cover all the measured data and contain more information about the potential data population embedded in historical measured data, reflecting more possibilities in the future. The method has achieved satisfactory performance in a different watershed, implying that it has good applicability.
- (c)
- The synthetic series presented similarity with the measured data in distribution parameters and probability curves, and has an advantage in its extreme wet value, contributing to drawing reasonable probability density curves and obtaining an accurate design value. Thus, the CR method is suggested to offer a significant guide in practical work when the extreme runoff value is needed, but it can not be obtained from the limited measured data.
- (d)
- The synthetic series is generated at different steps, and its distribution characteristics can present the changes of runoff under different environment scenarios, including climate and social development situations. These advantages are significant for calculating the strategy of water resources management under a changing environment.
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.; Dehoff, A.D.; Pody, R.D. New Approach to Identify Trend Pattern of Streamflows. J. Hydrol. Eng. 2010, 15, 244–248. [Google Scholar] [CrossRef]
- Chung, F.I.; Kadir, T.N.; Galef, J.K. Water Resources Planning under Non-Stationary Hydroclimate in a Snow Dominant Watershed. In World Environmental and Water Resources Congress 2009: Great Rivers; ASCE Press: Kansas City, MO, USA, 2009; pp. 1–10. [Google Scholar]
- Murphy, K.W.; Ellis, A.W. An assessment of the stationarity of climate and stream flow in watersheds of the Colorado River Basin. J. Hydrol. 2014, 509, 454–473. [Google Scholar] [CrossRef]
- Milly, P.C.; Betancourt, J.; Falkenmark, M.; Hirsch, R.M. Climate change. Stationarity is dead: Whither water management? Science 2008, 319, 573–574. [Google Scholar] [CrossRef] [PubMed]
- Matalas, N.C. Comment on the Announced Death of Stationarity. J. Water Resour. Plann. Manag. 2012, 138, 311–312. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, X.; Xu, C.Y.; Yuan, L.; Yong, B.; Yan, S. Evaluating the non-stationary relationship between precipitation and streamflow in nine major basins of China during the past 50 years. J. Hydrol. 2011, 409, 81–93. [Google Scholar] [CrossRef]
- Milly, P.C.; Dunne, K.A.; Vecchia, A.V. Global pattern of trends in streamflow and water availability in a changing climate. Nature 2005, 438, 347–350. [Google Scholar] [CrossRef]
- Ren, C.; Li, Z.; Zhang, H. Integrated multi-objective stochastic fuzzy programming and AHP method for agricultural water and land optimization allocation under multiple uncertainties. J. Clean. Prod. 2018, 210, 12–24. [Google Scholar] [CrossRef]
- Nasri, B.; Bouezmarni, T.; Sthilaire, A.; Ouarda, T.B.M.J. Non-stationary hydrologic frequency analysis using B-spline quantile regression. J. Hydrol. 2017, 554, 532–544. [Google Scholar] [CrossRef]
- Vrac, M.; Naveau, P. Stochastic downscaling of precipitation: From dry events to heavy rainfalls. Water Resour. Res. 2007, 43, 256–260. [Google Scholar] [CrossRef]
- Adlouni, S.E.; Ouarda, T.B.M.J. Joint Bayesian model selection and parameter estimation of the generalized extreme value model with covariates using birth-death Markov chain Monte Carlo. Water Resour. Res. 2009, 45, 735–742. [Google Scholar] [CrossRef]
- Adlouni, S.E.; Ouarda, T.B.M.J.; Zhang, X.; Roy, R.; Bobee, B. Generalized maximum likelihood estimators for the nonstationary generalized extreme value model. Water Resour. Res. 2007, 43, 455–456. [Google Scholar] [CrossRef]
- Pujol, N.; Neppel, L.; Sabatier, R. Regional tests for trend detection in maximum precipitation series in the French Mediterranean region. Hydrol. Sci. J. 2007, 52, 956–973. [Google Scholar] [CrossRef]
- Renard, B.; Lang, M.; Bois, P. Statistical analysis of extreme events in a non-stationary context via a Bayesian framework: Case study with peak-over-threshold data. Stoch. Environ. Res. Risk. Assess. 2006, 21, 97–112. [Google Scholar] [CrossRef]
- Sugahara, S.; Rocha, R.P.D.; Silveira, R. Non-stationary frequency analysis of extreme daily rainfall in Sao Paulo, Brazil. Int. J. Climatol. 2010, 29, 1339–1349. [Google Scholar] [CrossRef]
- Cannon, A.J. Quantile regression neural networks: Implementation in and application to precipitation downscaling. Comput. Geosci. 2011, 37, 1277–1284. [Google Scholar] [CrossRef]
- Sarhadi, A.; Soltani, S.; Modarres, R. Probabilistic flood inundation mapping of ungauged rivers: Linking GIS techniques and frequency analysis. J. Hydrol. 2012, 5, 68–86. [Google Scholar] [CrossRef]
- Brodie, I.M. Rational Monte Carlo method for flood frequency analysis in urban catchments. J. Hydrol. 2013, 486, 306–314. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de Répartition À N Dimensions Et Leurs Marges. Publ. Inst. Stat. Univ. Paris. 1959, 8, 229–231. [Google Scholar]
- Kao, S.C.; Rao, S.G. A copula-based joint deficit index for droughts. J. Hydrol. 2010, 380, 121–134. [Google Scholar] [CrossRef]
- Song, S.; Singh, V.P. Meta-elliptical copulas for drought frequency analysis of periodic hydrologic data. Stoch. Environ. Res. Risk Assess. 2010, 24, 425–444. [Google Scholar] [CrossRef]
- Pettitt, A.N. A non-parametric approach to the change-point problem. Appl. Stat. 1979, 28, 126–135. [Google Scholar] [CrossRef]
- Gao, P.; Mu, X.M.; Wang, F. Changes in streamflow and sediment discharge and the response to human activities in the middle reaches of the Yellow River. Hydrol. Earth Syst. Sci. 2011, 15, 1–10. [Google Scholar] [CrossRef]
- Inclan, C.; Tiao, G.C. Use of cumulative sums of squares for retrospective detection of changes of variance. J. Am. Stat. Assoc. 1994, 89, 913–923. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.L.C.; Shih, H.H.; Zheng, Q.N.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition method and the Hilbert spectrum for non-stationary time series analysis. Proc. R. Soc. Lond. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, H.; Singh, V.P. Forward Prediction of Runoff Data in Data-Scarce Basins with an Improved Ensemble Empirical Mode Decomposition (EEMD) Model. Water 2018, 10, 4. [Google Scholar] [CrossRef]
- Zhang, H.; Singh, V.P.; Wang, B.; Yu, Y. CEREF: A hybrid data-driven model for forecasting annual streamflow from a socio-hydrological system. J. Hydrol. 2016, 540, 246–256. [Google Scholar] [CrossRef]
- Filippatos, A.; Langkamp, A.; Kostka, P.; Gude, M. A Sequence-Based Damage Identification Method for Composite Rotors by Applying the Kullback–Leibler Divergence, a Two-Sample Kolmogorov–Smirnov Test and a Statistical Hidden Markov Model. Entropy 2019, 21, 7. [Google Scholar] [CrossRef]
- Miller, L.H. Table of Percentage Points of Kolmogorov Statistics. Am. Stat. Assoc. 1956, 51, 111–121. [Google Scholar] [CrossRef]
- Deng, Y.; Wang, W.; Qian, C.; Wang, Z.; Dai, D. Boundary-processing-technique in EMD method and Hilbert transform. Chin. Sci. Bull. 2001, 46, 954. [Google Scholar] [CrossRef]
- Yang, J.; Chang, J.; Wang, Y.; Li, Y.; Hu, H.; Chen, Y.; Huang, Q.; Yao, J. Comprehensive drought characteristics analysis based on a nonlinear multivariate drought index. J. Hydrol. 2017, 557, 651–667. [Google Scholar] [CrossRef]
- Zhao, J.; Huang, Q.; Chang, J.; Liu, D.; Huang, S.; Shi, X. Analysis of temporal and spatial trends of hydro-climatic variables in the Wei River Basin. Environ. Res. 2015, 139, 55–64. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Huang, S.; Huang, Q.; Xie, Y.; Leng, G.; Luan, J.; Song, X.; Wei, X.; Li, X. Identification of the non-stationarity of extreme precipitation events and correlations with large-scale ocean-atmospheric circulation patterns: A case study in the Wei River Basin, China. J. Hydrol. 2017, 548, 184–195. [Google Scholar] [CrossRef]
- Huang, S.; Chang, J.; Huang, Q.; Chen, Y. Spatio-temporal Changes and Frequency Analysis of Drought in the Wei River Basin, China. Water Resour. Manag. 2014, 28, 3095–3110. [Google Scholar] [CrossRef]
- Huang, S.; Huang, Q.; Leng, G.; Zhao, M.; Meng, E. Variations in annual water-energy balance and their correlations with vegetation and soil moisture dynamics: A case study in the Wei River Basin, China. J. Hydrol. 2017, 546, 515–525. [Google Scholar] [CrossRef]
- Fan, L.; Liu, G.; Wang, F.; Geissen, V.; Ritsema, C.J.; Tong, Y. Water use patterns and conservation in households of Wei River Basin, China. Resour. Conserv. Recycl. 2013, 74, 45–53. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Wang, J.; He, R.; Amgad, E.M.; Liu, J.; Wang, X.; David, K.; Shamsuddin, S. Climate change and water resources management in Tuwei river basin of Northwest China. Mitig. Adapt. Strateg. Glob. Chang. 2014, 19, 07–120. [Google Scholar]
- Yang, Z.; Wang, W.; Wang, Z.; Jiang, G.; Li, W. Ecology-oriented groundwater resource assessment in the Tuwei River watershed, Shaanxi Province, China. Hydrogeol. J. 2016, 24, 1–14. [Google Scholar] [CrossRef]





















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Zhang, H.; Ren, C.; Nan, Z.; Wei, X.; Li, C. A Cross-Reconstruction Method for Step-Changed Runoff Series to Implement Frequency Analysis under Changing Environment. Int. J. Environ. Res. Public Health 2019, 16, 4345. https://doi.org/10.3390/ijerph16224345
Yang J, Zhang H, Ren C, Nan Z, Wei X, Li C. A Cross-Reconstruction Method for Step-Changed Runoff Series to Implement Frequency Analysis under Changing Environment. International Journal of Environmental Research and Public Health. 2019; 16(22):4345. https://doi.org/10.3390/ijerph16224345
Chicago/Turabian StyleYang, Jiantao, Hongbo Zhang, Chongfeng Ren, Zhengnian Nan, Xiaowei Wei, and Ci Li. 2019. "A Cross-Reconstruction Method for Step-Changed Runoff Series to Implement Frequency Analysis under Changing Environment" International Journal of Environmental Research and Public Health 16, no. 22: 4345. https://doi.org/10.3390/ijerph16224345
APA StyleYang, J., Zhang, H., Ren, C., Nan, Z., Wei, X., & Li, C. (2019). A Cross-Reconstruction Method for Step-Changed Runoff Series to Implement Frequency Analysis under Changing Environment. International Journal of Environmental Research and Public Health, 16(22), 4345. https://doi.org/10.3390/ijerph16224345