Integration of Remote Sensing and Social Sensing Data in a Deep Learning Framework for Hourly Urban PM2.5 Mapping


Abstract
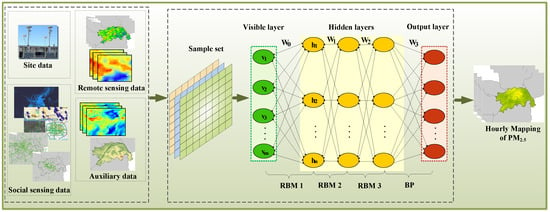
1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data Sets
2.2.1. Ground Station PM2.5
2.2.2. Social Sensing Data Remote Sensing Data
2.2.3. Remote Sensing Data
2.2.4. Meteorological Data
2.2.5. Terrain Data
3. Methods
3.1. Feature Extraction
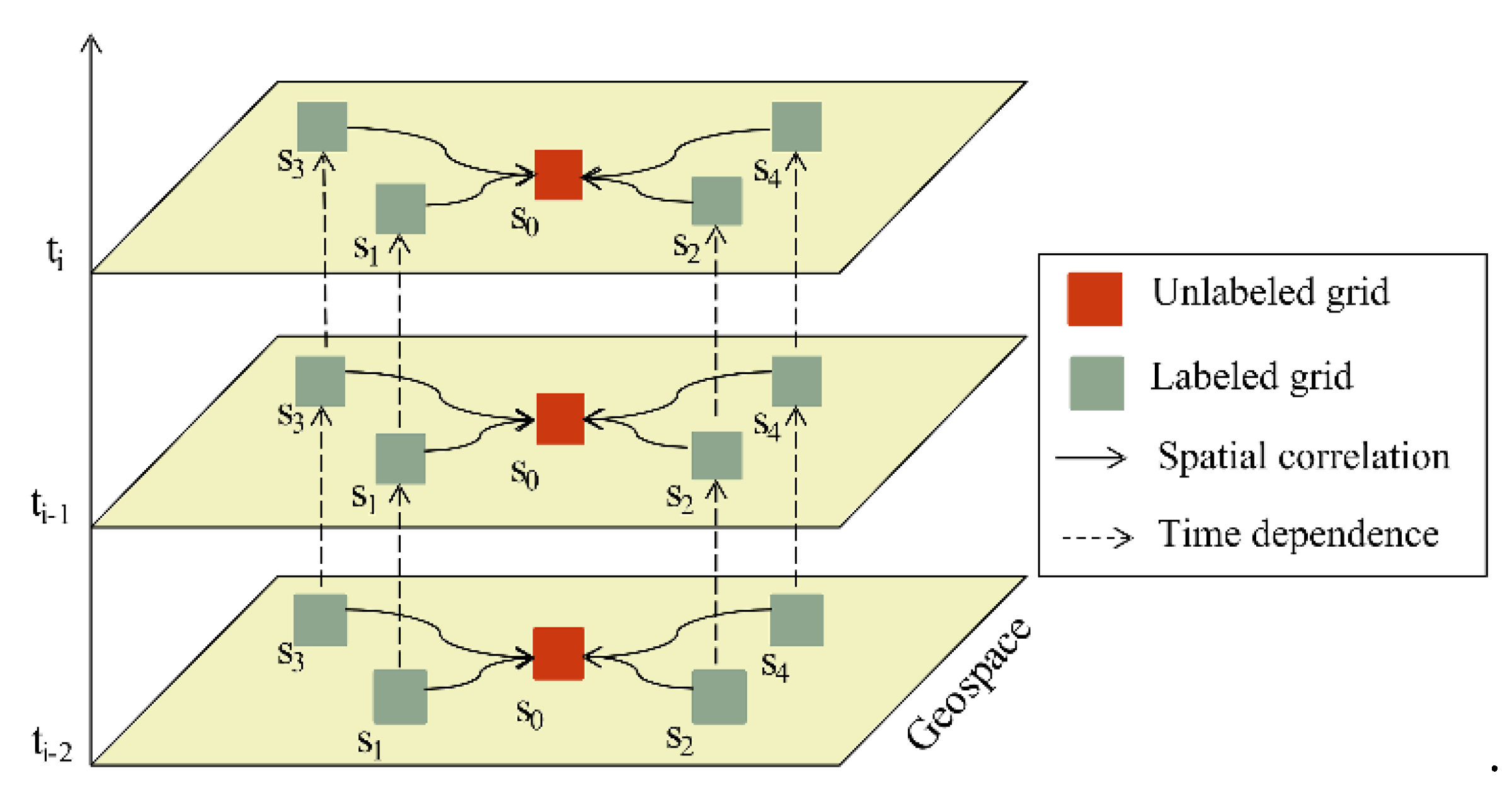
3.1.1. Spatiotemporal Features of PM2.5
3.1.2. Social Sensing Features
3.1.3. Other Raster Features
3.2. Deep Learning Model for PM2.5 Estimation
3.3. Validation
4. Results and Discussion
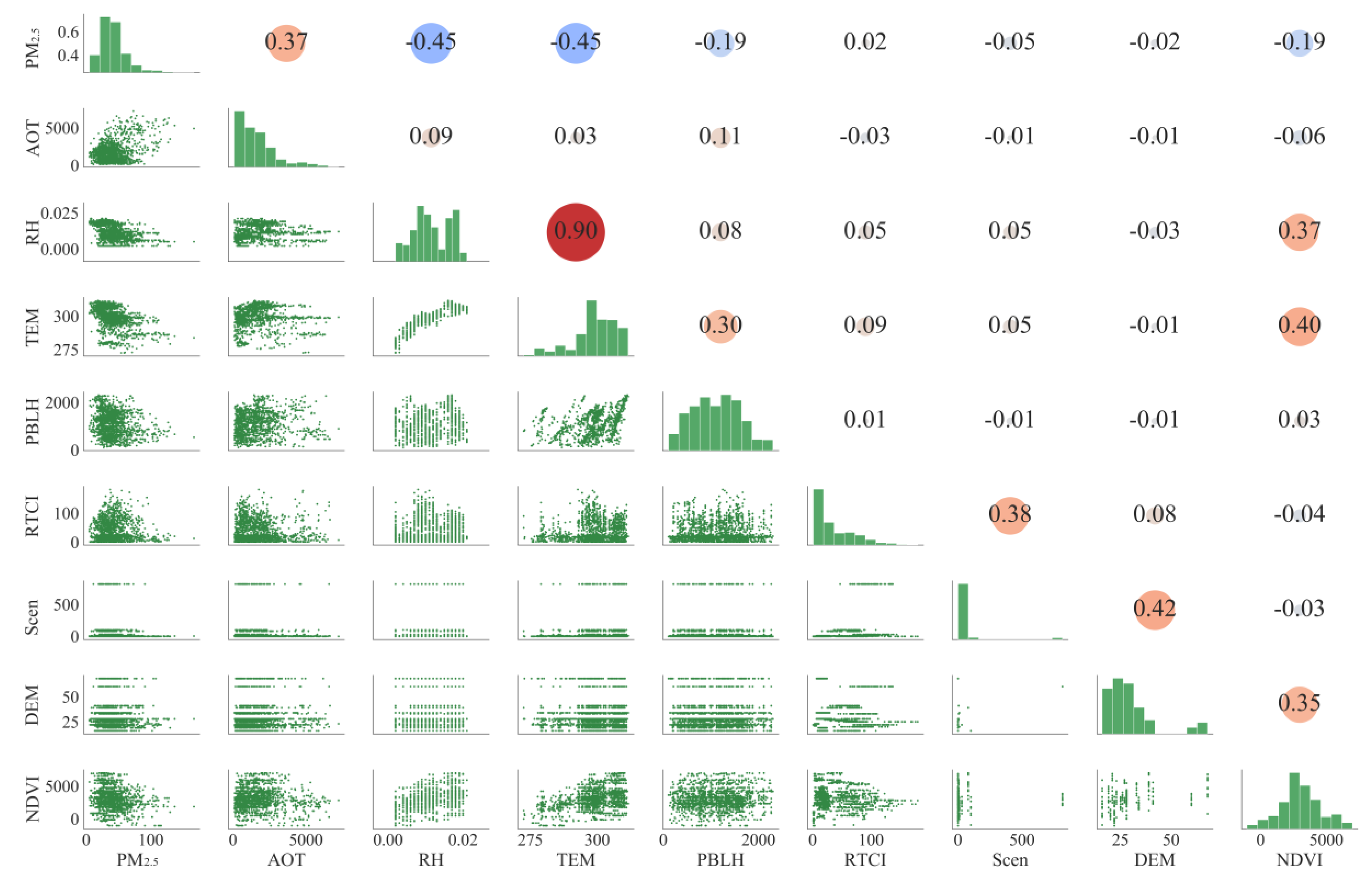
4.1. Descriptive Statistics
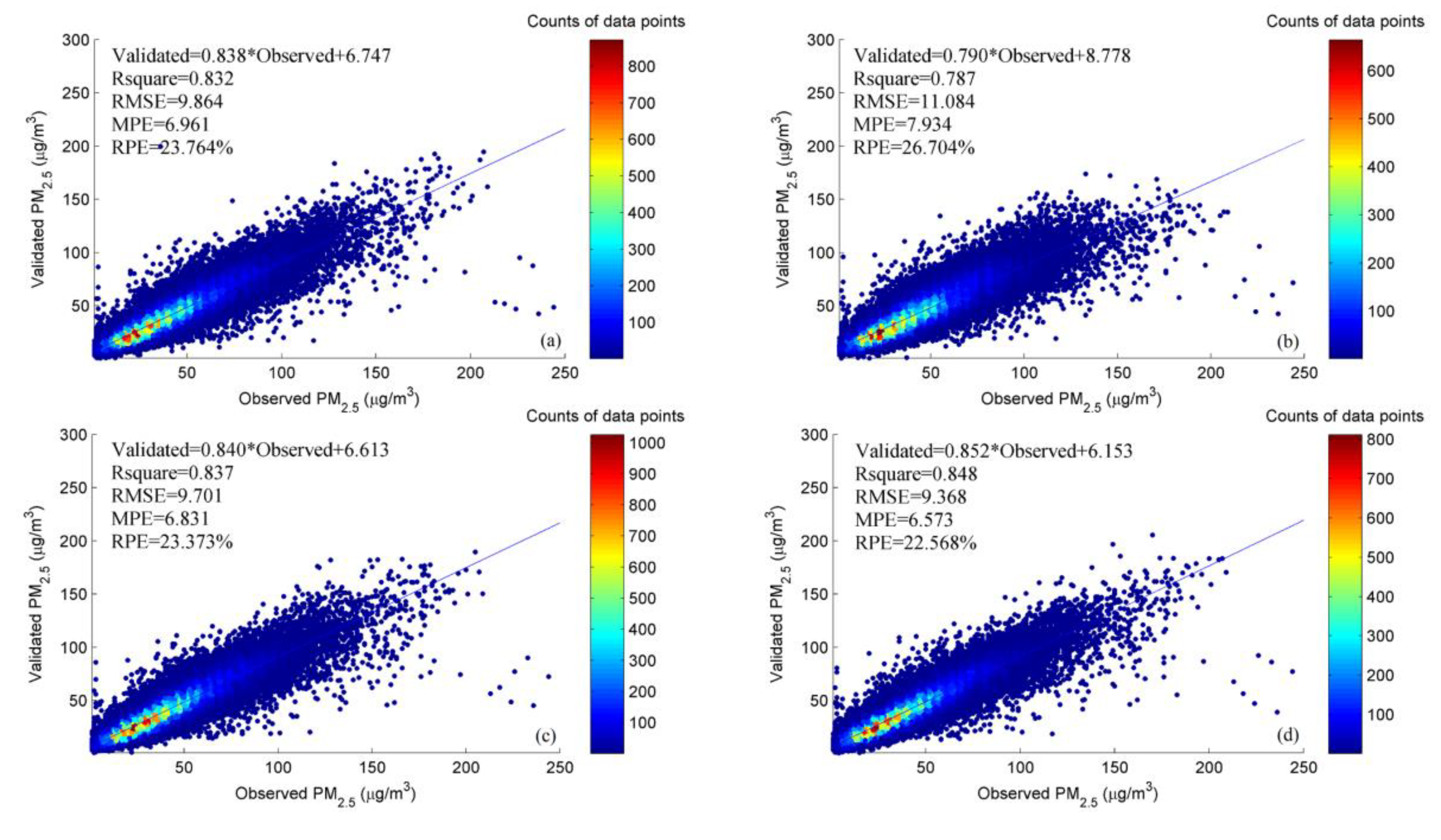
4.2. Model Accuracy Evaluation
4.2.1. Quantitative Evaluation Results
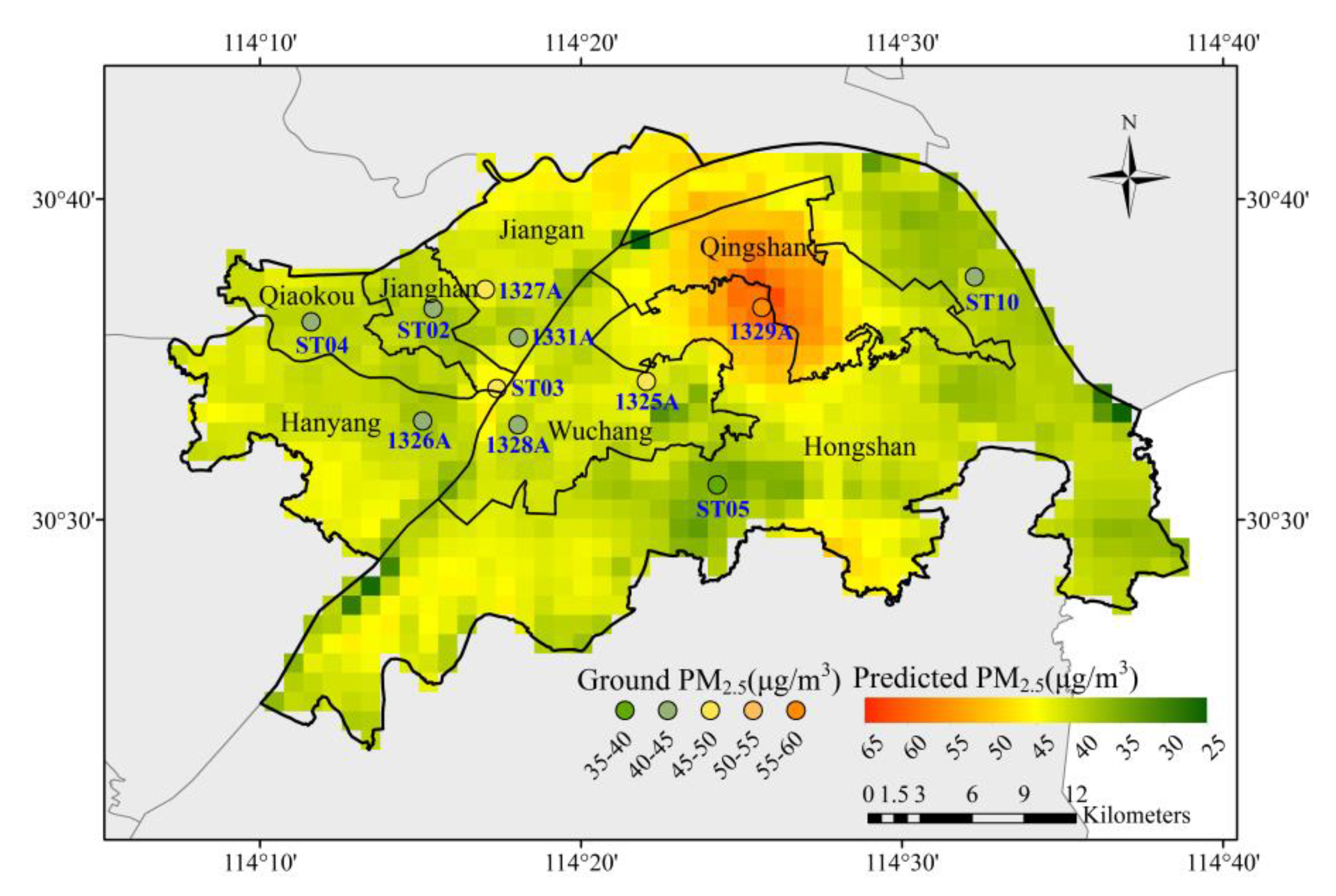
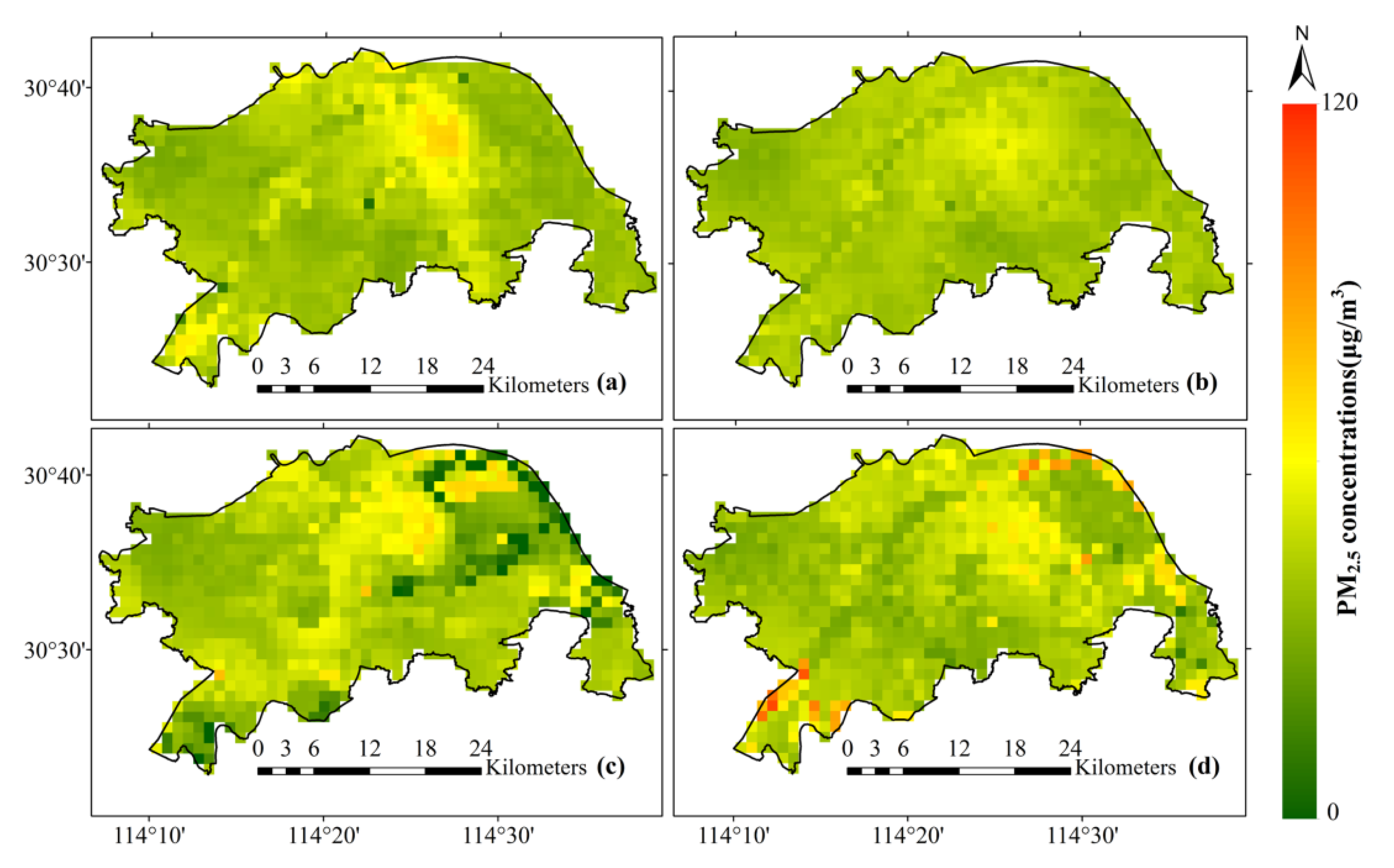
4.2.2. Mapping Results of PM2.5 Concentration
4.3. The Effects of the Social Sensing Variables
4.4. The Dialectical Selection of the AOT Variable
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- ISO. Air Quality-Particle Size Fraction Definitions for Health-Related Sampling; ISO: Geneva, Switzerland, 2006. [Google Scholar]
- Pope, C.A., III; Dockery, D.W. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Ambient Air Pollution: A Global Assessment of Exposure and Burden of Disease; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Cao, J. PM2.5 and the Environment; Science Press: Beijing, China, 2014. [Google Scholar]
- Hart, J.E.; Liao, X.; Hong, B.; Puett, R.C.; Yanosky, J.D.; Suh, H.; Kioumourtzoglou, M.-A.; Spiegelman, D.; Laden, F. The association of long-term exposure to PM2.5 on all-cause mortality in the Nurses’ Health Study and the impact of measurement-error correction. Environ. Health 2015, 14, 38. [Google Scholar] [CrossRef] [PubMed]
- Seltenrich, N. A Satellite–Ground Hybrid Approach: Relative Risks for Exposures to PM2.5 Estimated from a Combination of Data Sources; National Institute of Environmental Health Sciences: Bethesda, ML, USA, 2017. [CrossRef]
- Badura, M.; Batog, P.; Drzeniecka-Osiadacz, A.; Modzel, P. Evaluation of low-cost sensors for ambient PM2.5 monitoring. J. Sens. 2018, 2018. [Google Scholar] [CrossRef]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled “online” chemistry within the WRF model. Atmos. Environ. 2005, 39, 6957–6975. [Google Scholar] [CrossRef]
- Van Donkelaar, A.; Martin, R.V.; Brauer, M.; Hsu, N.C.; Kahn, R.A.; Levy, R.C.; Lyapustin, A.; Sayer, A.M.; Winker, D.M. Global estimates of fine particulate matter using a combined geophysical-statistical method with information from satellites, models, and monitors. Environ. Sci. Technol. 2016, 50, 3762–3772. [Google Scholar] [CrossRef]
- Zhang, T.H.; Gong, W.; Wang, W.; Ji, Y.X.; Zhu, Z.M.; Huang, Y.S. Ground Level PM2.5 Estimates over China Using Satellite-Based Geographically Weighted Regression (GWR) Models Are Improved by Including NO2 and Enhanced Vegetation Index (EVI). Int. J. Environ. Res. Public Health 2016, 13, 12. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–13 August 2013; pp. 1436–1444. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Sun, C.; Li, V.O. An extended spatio-temporal granger causality model for air quality estimation with heterogeneous urban big data. IEEE Trans. Big Data 2017, 3, 307–319. [Google Scholar] [CrossRef]
- Lin, Y.; Chiang, Y.-Y.; Pan, F.; Stripelis, D.; Ambite, J.L.; Eckel, S.P.; Habre, R. Mining public datasets for modeling intra-city PM2.5 concentrations at a fine spatial resolution. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; p. 25. [Google Scholar]
- Qi, Z.G.; Wang, T.C.; Song, G.J.; Hu, W.S.; Li, X.; Zhang, Z.F. Deep air learning: Interpolation, prediction, and feature analysis of fine-grained air quality. IEEE Trans. Knowl. Data Eng. 2018, 30, 2285–2297. [Google Scholar] [CrossRef]
- He, J.; Christakos, G. Space-time PM2.5 mapping in the severe haze region of Jing-Jin-Ji (China) using a synthetic approach. Environ. Pollut. 2018, 240, 319–329. [Google Scholar] [CrossRef]
- Xu, Y.; Ho, H.C.; Wong, M.S.; Deng, C.; Shi, Y.; Chan, T.-C.; Knudby, A. Evaluation of machine learning techniques with multiple remote sensing datasets in estimating monthly concentrations of ground-level PM2.5. Environ. Pollut. 2018, 242, 1417–1426. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, Y. When remote sensing data meet ubiquitous urban data: Fine-grained air quality inference. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1252–1261. [Google Scholar] [CrossRef]
- Brokamp, C.; Jandarov, R.; Hossain, M.; Ryan, P. Predicting daily urban fine particulate matter concentrations using a random forest model. Environ. Sci. Technol. 2018, 52, 4173–4179. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Lang, Y.; Christakos, G. High-resolution spatiotemporal mapping of PM2.5 concentrations at Mainland China using a combined BME-GWR technique. Atmos. Environ. 2018, 173, 295–305. [Google Scholar] [CrossRef]
- Zhang, T.; Zang, L.; Wan, Y.; Wang, W.; Zhang, Y. Ground-level PM2.5 estimation over urban agglomerations in China with high spatiotemporal resolution based on Himawari-8. Sci. Total Environ. 2019, 676, 535–544. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Mao, F.; Zou, B.; Guo, J.; Wu, L.; Pan, Z.; Zang, L. Two-stage model for estimating the spatiotemporal distribution of hourly PM1.0 concentrations over central and east China. Sci. Total Environ. 2019, 675, 658–666. [Google Scholar] [CrossRef] [PubMed]
- Famoso, F.; Wilson, J.; Monforte, P.; Lanzafame, R.; Brusca, S.; Lulla, V. Measurement and modeling of ground-level ozone concentration in Catania, Italy using biophysical remote sensing and GIS. Int. J. Appl. Eng. Res. 2017, 12, 10551–10562. [Google Scholar]
- Ma, X.; Longley, I.; Gao, J.; Kachhara, A.; Salmond, J. A site-optimised multi-scale GIS based land use regression model for simulating local scale patterns in air pollution. Sci. Total Environ. 2019, 685, 134–149. [Google Scholar] [CrossRef]
- Vert, C.; Sánchez-Benavides, G.; Martínez, D.; Gotsens, X.; Gramunt, N.; Cirach, M.; Molinuevo, J.L.; Sunyer, J.; Nieuwenhuijsen, M.J.; Crous-Bou, M. Effect of long-term exposure to air pollution on anxiety and depression in adults: A cross-sectional study. Int. J. Hyg. Environ. Health 2017, 220, 1074–1080. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Zeng, C.; Yuan, Q.; Zhang, L. Point-surface fusion of station measurements and satellite observations for mapping PM2.5 distribution in China: Methods and assessment. Atmos. Environ. 2017, 152, 477–489. [Google Scholar] [CrossRef]
- Shen, H.; Li, T.; Yuan, Q.; Zhang, L. Estimating regional ground-level PM2.5 directly from satellite top-of-atmosphere reflectance using deep belief networks. J. Geophys. Res. Atmos. 2018, 123, 13875–13886. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, X.; Zhang, L. Estimating ground-level PM2.5 by fusing satellite and station observations: A geo-intelligent deep learning approach. Geophys. Res. Lett. 2017, 44, 11985–11993. [Google Scholar] [CrossRef]
- Zhang, G.; Rui, X.; Fan, Y. Critical review of methods to estimate PM2.5 concentrations within specified research region. ISPRS Int. Geo-Inf. 2018, 7, 368. [Google Scholar] [CrossRef]
- Li, J.; He, Z.; Plaza, J.; Li, S.; Chen, J.; Wu, H.; Wang, Y.; Liu, Y. Social media: New perspectives to improve remote sensing for emergency response. Proc. IEEE 2017, 105, 1900–1912. [Google Scholar] [CrossRef]
- Kang, G.K.; Gao, J.Z.; Chiao, S.; Lu, S.; Xie, G. Air quality prediction: Big data and machine learning approaches. Int. J. Environ. Sci. Dev. 2018, 9, 8–16. [Google Scholar] [CrossRef]
- Engel-Cox, J.A.; Hoff, R.M.; Haymet, A. Recommendations on the use of satellite remote-sensing data for urban air quality. J. Air Waste Manag. Assoc. 2004, 54, 1360–1371. [Google Scholar] [CrossRef] [PubMed]
- Zou, B.; Pu, Q.; Bilal, M.; Weng, Q.; Zhai, L.; Nichol, J.E. High-resolution satellite mapping of fine particulates based on geographically weighted regression. IEEE Geosci. Remote Sens. Lett. 2016, 13, 495–499. [Google Scholar] [CrossRef]
- Picornell, M.; Ruiz, T.; Borge, R.; Garcia-Albertos, P.; de la Paz, D.; Lumbreras, J. Population dynamics based on mobile phone data to improve air pollution exposure assessments. J. Expo. Sci. Environ. Epidemiol. 2019, 29, 278–291. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Yuan, Q.; Li, T.; Shen, H.; Zhang, L. The relationships between PM2.5 and meteorological factors in China: Seasonal and regional variations. Int. J. Environ. Res. Public Health 2017, 14, 1510. [Google Scholar] [CrossRef]
- Mbululo, Y.; Qin, J.; Yuan, Z.X. Evolution of atmospheric boundary layer structure and its relationship with air quality in Wuhan, China. Arab. J. Geosci. 2017, 10, 477. [Google Scholar] [CrossRef]
- Tian, L.; Hou, W.; Chen, J.Q.; Chen, C.N.; Pan, X.J. Spatiotemporal changes in PM2.5 and their relationships with land-use and people in Hangzhou. Int. J. Environ. Res. Public Health 2018, 15, 2192. [Google Scholar] [CrossRef]
- Yuan, M.; Huang, Y.; Shen, H.; Li, T. Effects of urban form on haze pollution in China: Spatial regression analysis based on PM2.5 remote sensing data. Appl. Geogr. 2018, 98, 215–223. [Google Scholar] [CrossRef]
- Forehead, H.; Huynh, N. Review of modelling air pollution from traffic at street-level—The state of the science. Environ. Pollut. 2018, 241, 775–786. [Google Scholar] [CrossRef]
- Yun, G.; Zuo, S.; Dai, S.; Song, X.; Xu, C.; Liao, Y.; Zhao, P.; Chang, W.; Chen, Q.; Li, Y.; et al. Individual and interactive influences of anthropogenic and ecological factors on forest PM2.5 concentrations at an urban scale. Remote Sens. 2018, 10, 521. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2019. [Google Scholar] [CrossRef]
- Wuhan Statistical Yearbooks; Wuhan Yearbook Club: Wuhan, China, 2016; p. 605.
- Wang, X.; Wang, W.; Jiao, S.; Yuan, J.; Hu, C.; Wang, L. The effects of air pollution on daily cardiovascular diseases hospital admissions in Wuhan from 2013 to 2015. Atmos. Environ. 2018, 182, 307–312. [Google Scholar] [CrossRef]
- Yoshida, M.; Kikuchi, M.; Nagao, T.M.; Murakami, H.; Nomaki, T.; Higurashi, A. Common retrieval of aerosol properties for imaging satellite sensors. J. Meteorol. Soc. Jpn. Ser. II 2018. [Google Scholar] [CrossRef]
- Kikuchi, M.; Murakami, H.; Suzuki, K.; Nagao, T.M.; Higurashi, A. Improved hourly estimates of aerosol optical thickness using spatiotemporal variability derived from Himawari-8 geostationary satellite. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3442–3455. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Tobler, W. On the first law of geography: A reply. Ann. Assoc. Am Geogr 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Cai, J.; Huang, B.; Song, Y. Using multi-source geospatial big data to identify the structure of polycentric cities. Remote Sens. Environ. 2017, 202, 210–221. [Google Scholar] [CrossRef]
- Dunkel, A. Visualizing the perceived environment using crowdsourced photo geodata. Landsc. Urban Plan. 2015, 142, 173–186. [Google Scholar] [CrossRef]
- Song, Y.; Huang, B.; Cai, J.; Chen, B. Dynamic assessments of population exposure to urban greenspace using multi-source big data. Sci. Total Environ. 2018, 634, 1315–1325. [Google Scholar] [CrossRef] [PubMed]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar] [CrossRef]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Moré, J.J. The Levenberg-Marquardt algorithm: Implementation and theory. In Numerical Analysis; Springer: Berlin/Heidelberg, Germany, 1978; pp. 105–116. [Google Scholar] [CrossRef]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Liu, C.; Zeng, K.; Ding, L.; Cheng, S. Spatio-temporal distribution of PM2.5 in Wuhan and its relationship with meteorological conditions in 2013–2014. Ecol. Environ. Sci. 2015, 24, 1330–1335. [Google Scholar] [CrossRef]
- China, M. Ambient Air Quality Standards; GB 3095-2012; China Environmental Science Press: Beijing, China, 2012. [Google Scholar]
- Xu, S.; Zou, B.; Lin, Y.; Zhao, X.; Li, S.; Hu, C. Strategies of method selection for fine-scale PM2.5 mapping in an intra-urban area using crowdsourced monitoring. Atmos. Meas. Tech. 2019, 12, 2933–2948. [Google Scholar] [CrossRef]
- Morawska, L.; Thai, P.K.; Liu, X.; Asumadu-Sakyi, A.; Ayoko, G.; Bartonova, A.; Bedini, A.; Chai, F.; Christensen, B.; Dunbabin, M. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone? Environ. Int. 2018, 116, 286–299. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Model Fitting | 10 Fold Cross-Validation | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE 1 | MPE 2 | RPE 3 (%) | R2 | RMSE | MPE | RPE (%) | |
| optimal variables A 4 | 0.850 | 9.303 | 6.683 | 22.412 | 0.832 | 9.864 | 6.961 | 23.764 |
| without RTCI 5, TID 6 | 0.792 | 10.966 | 7.889 | 26.418 | 0.787 | 11.084 | 7.934 | 26.704 |
| without PMs 7, PMt 8 | 0.830 | 9.916 | 7.180 | 23.890 | 0.810 | 10.478 | 7.573 | 25.244 |
| without Wea 9 | 0.831 | 9.888 | 7.021 | 23.822 | 0.824 | 10.092 | 7.099 | 24.313 |
| without NDVI | 0.833 | 9.813 | 7.057 | 23.643 | 0.810 | 10.467 | 7.414 | 25.216 |
| without Time | 0.825 | 10.065 | 7.158 | 24.250 | 0.821 | 10.168 | 7.198 | 24.496 |
| Model | Model Fitting | 10 Fold Cross-Validation | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MPE | RPE (%) | R2 | RMSE | MPE | RPE (%) | |
| optimal variables B 1 | 0.834 | 8.136 | 6.152 | 19.647 | 0.742 | 10.161 | 7.478 | 24.537 |
| without AOT | 0.798 | 9.001 | 6.836 | 21.737 | 0.709 | 10.821 | 7.965 | 26.131 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, H.; Zhou, M.; Li, T.; Zeng, C. Integration of Remote Sensing and Social Sensing Data in a Deep Learning Framework for Hourly Urban PM2.5 Mapping. Int. J. Environ. Res. Public Health 2019, 16, 4102. https://doi.org/10.3390/ijerph16214102
Shen H, Zhou M, Li T, Zeng C. Integration of Remote Sensing and Social Sensing Data in a Deep Learning Framework for Hourly Urban PM2.5 Mapping. International Journal of Environmental Research and Public Health. 2019; 16(21):4102. https://doi.org/10.3390/ijerph16214102
Chicago/Turabian StyleShen, Huanfeng, Man Zhou, Tongwen Li, and Chao Zeng. 2019. "Integration of Remote Sensing and Social Sensing Data in a Deep Learning Framework for Hourly Urban PM2.5 Mapping" International Journal of Environmental Research and Public Health 16, no. 21: 4102. https://doi.org/10.3390/ijerph16214102
APA StyleShen, H., Zhou, M., Li, T., & Zeng, C. (2019). Integration of Remote Sensing and Social Sensing Data in a Deep Learning Framework for Hourly Urban PM2.5 Mapping. International Journal of Environmental Research and Public Health, 16(21), 4102. https://doi.org/10.3390/ijerph16214102