Improved Estimates of Population Exposure in Low-Elevation Coastal Zones of China


Abstract
1. Introduction
2. Data and Methods
2.1. Population Census Data and Administrative Boundaries
2.2. Remote Sensing Data and Preprocessing
2.3. POIs and Processing
2.4. Cubist and Random Forest Regression
2.5. Model Fitting and Dasymetric Population Mapping
2.6. Extracting Extent of China’s LECZ
3. Results and Discussion
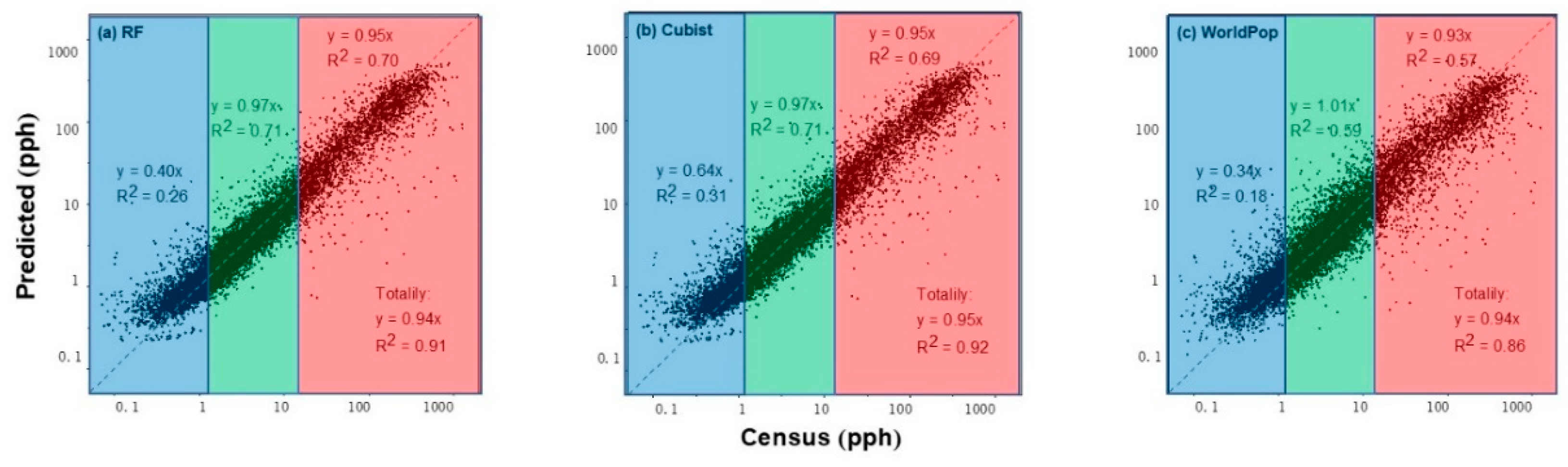
3.1. Accuracy Assessment of Population Mapping
3.2. Comparison between RF and Cubist Models
3.3. Variable Importance in Population Mapping
3.4. Contribution of POI Data
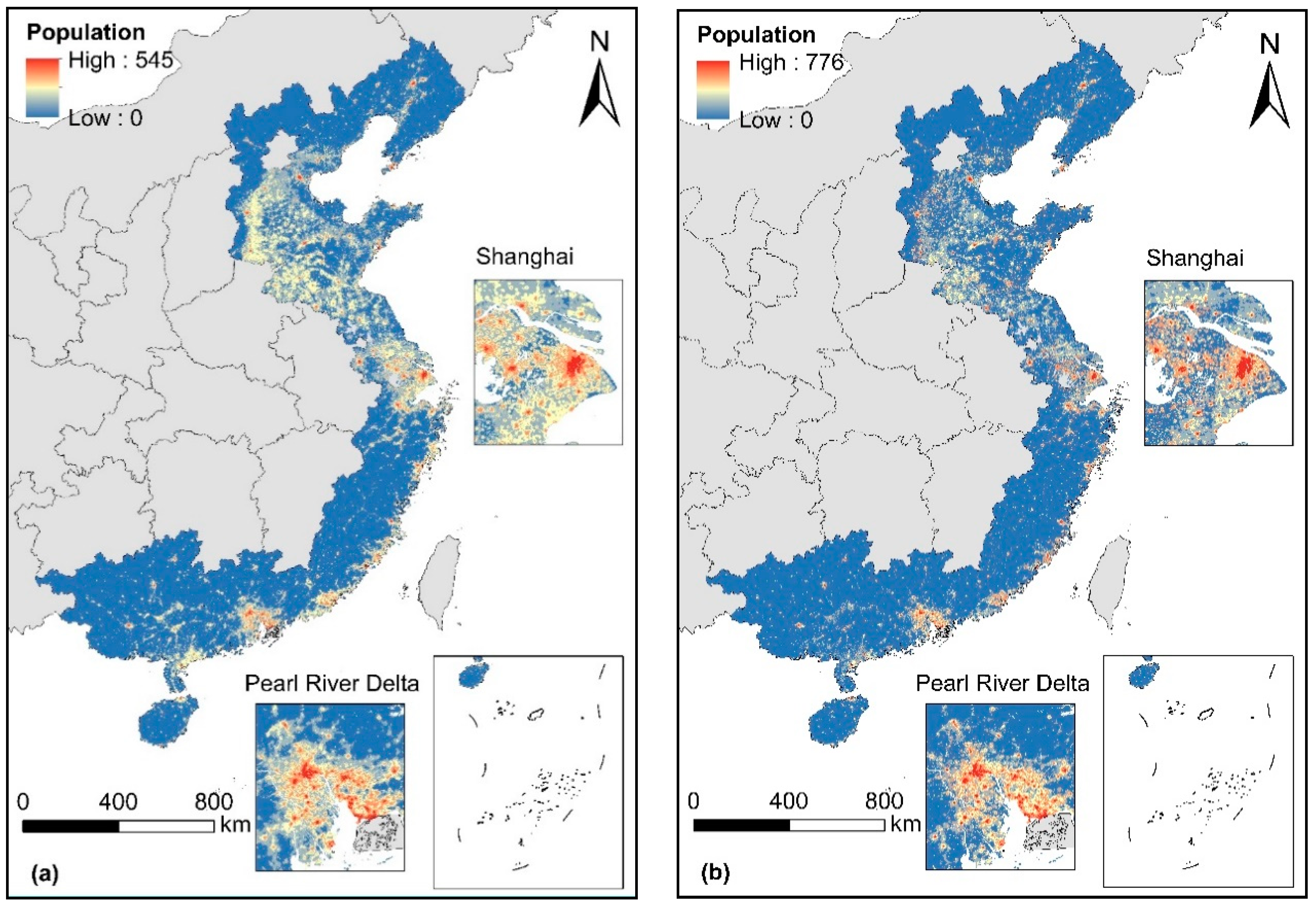
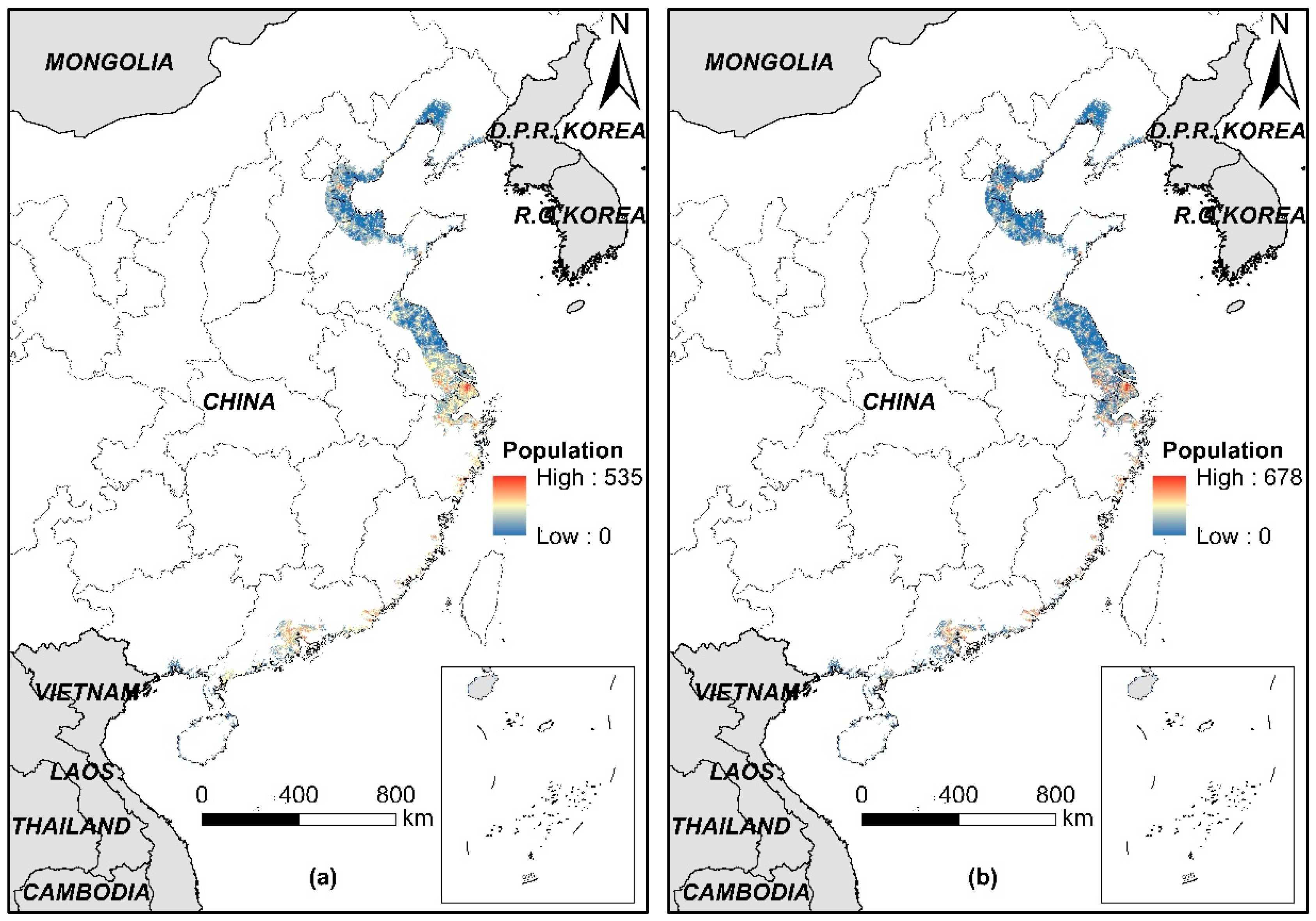
3.5. Population Distribution in LECZ
4. Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Small, C.; Nicholls, R.J. A Global Analysis of Human Settlement in Coastal Zones. J. Coast. Res. 2003, 19, 584–599. [Google Scholar]
- Small, C.; Gornitz, V.; Cohen, J.E. Coastal Hazards and the Global Distribution of Human Population. Environ. Geosci. 2000, 7, 3–12. [Google Scholar] [CrossRef]
- McGranahan, G.; Balk, D.; Anderson, B. The rising tide: Assessing the risks of climate change and human settlements in low elevation coastal zones. Environ. Urban. 2007, 19, 17–37. [Google Scholar] [CrossRef]
- Lichter, M.; Vafeidis, A.T.; Nicholls, R.J.; Kaiser, G. Exploring Data-Related Uncertainties in Analyses of Land Area and Population in the “Low-Elevation Coastal Zone” (LECZ). J. Coast. Res. 2011, 27, 757–768. [Google Scholar] [CrossRef]
- Mondal, P.; Tatem, A.J. Uncertainties in Measuring Populations Potentially Impacted by Sea Level Rise and Coastal Flooding. PLoS ONE 2012, 7, e48191. [Google Scholar] [CrossRef] [PubMed]
- Center for International Earth Science + Information Network—CIESIN—Columbia University. Low Elevation Coastal Zone (LECZ) Urban-Rural Population and Land Area Estimates, Version 2; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2013. [Google Scholar]
- Han, S.S.; Yan, Z. China’s Coastal Cities: Development, Planning and Challenges. Habitat Int. 1999, 23, 217–229. [Google Scholar] [CrossRef]
- Liu, J.; Wen, J.; Huang, Y.; Shi, M.; Meng, Q.; Ding, J.; Xu, H. Human settlement and regional development in the context of climate change: A spatial analysis of low elevation coastal zones in China. Mitig. Adapt. Strateg. Glob. Chang. 2015, 20, 527–546. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Yang, X.; Ye, T.; Zhao, N.; Chen, Q.; Yue, W.; Qi, J.; Zeng, B.; Jia, P. Population mapping with multisensor remote sensing images and point-of-interest data. Remote Sens. 2019, 11, 574. [Google Scholar] [CrossRef]
- Wang, L.; Fan, H.; Wang, Y. Fine-Resolution Population Mapping from International Space Station Nighttime Photography and Multisource Social Sensing Data Based on Similarity Matching. Remote Sens. 2019, 11, 1900. [Google Scholar] [CrossRef]
- Hsu, F.-C.; Baugh, K.; Ghosh, T.; Zhizhin, M.; Elvidge, C. DMSP-OLS Radiance Calibrated Nighttime Lights Time Series with Intercalibration. Remote Sens. 2015, 7, 1855. [Google Scholar] [CrossRef]
- Esch, T.; Heldens, W.; Hirner, A.; Keil, M.; Marconcini, M.; Roth, A.; Zeidler, J.; Dech, S.; Strano, E. Breaking new ground in mapping human settlements from space—The Global Urban Footprint. ISPRS J. Photogramm. Remote Sens. 2017, 134, 30–42. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2016, 31, 825–848. [Google Scholar] [CrossRef]
- Im, J.; Jensen, J.R.; Coleman, M.; Nelson, E. Hyperspectral remote sensing analysis of short rotation woody crops grown with controlled nutrient and irrigation treatments. Geocarto Int. 2009, 24, 293–312. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence; World Scientific: Singapore, 1992; Volume 92, pp. 343–348. [Google Scholar]
- Quinlan, J.R. Combining instance-based and model-based learning. In Proceedings of the Tenth International Conference on Machine Learning; Morgan Kaufmann Publishers, Inc.: San Mateo, CA, USA, 1993; pp. 236–343. [Google Scholar]
- Yoo, S.; Im, J.; Wagner, J.E. Variable selection for hedonic model using machine learning approaches: A case study in Onondaga County, NY. Landsc. Urban Plan. 2012, 107, 293–306. [Google Scholar] [CrossRef]
- Turgeman, L.; May, J.H.; Sciulli, R. Insights from a machine learning model for predicting the hospital Length of Stay (LOS) at the time of admission. Expert Syst. Appl. 2017, 78, 376–385. [Google Scholar] [CrossRef]
- Walton, J.T. Subpixel Urban Land Cover Estimation: Comparing Cubist, Random Forests, and Support Vector Regression. Photogramm. Eng. Remote Sens. 2008, 74, 1213–1222. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Machine Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by RandomForest. R News 2002, 3, 18–22. [Google Scholar]
- Breiman, L. Out-of-Bag Estimation; Technical Report; Department of Statistics: University of California: Berkeley, CA, USA, 1996. [Google Scholar]
- Eicher, C.L.; Brewer, C.A. Dasymetric mapping and areal interpolation: Implementation and evaluation. Cartogr. Geogr. Inf. Sci. 2001, 28, 125–138. [Google Scholar] [CrossRef]
- Gaughan, A.E.; Stevens, F.R.; Huang, Z.; Nieves, J.J.; Sorichetta, A.; Lai, S.; Ye, X.; Linard, C.; Hornby, G.M.; Hay, S.I.; et al. Spatiotemporal patterns of population in mainland China, 1990 to 2010. Sci. Data 2016, 3, 160005. [Google Scholar] [CrossRef] [PubMed]
- Cockx, K.; Canters, F. Incorporating spatial non-stationarity to improve dasymetric mapping of population. Appl. Geogr. 2015, 63, 220–230. [Google Scholar] [CrossRef]
- Michie, D.; Spiegelhalter, D.J.; Taylor, C. Machine learning. Neural Stat. Classif. 1994, 1–298. [Google Scholar]
- Cai, J.; Huang, B.; Song, Y. Using multi-source geospatial big data to identify the structure of polycentric cities. Remote Sens. Environ. 2017, 202, 210–221. [Google Scholar] [CrossRef]
- Briggs, D.J.; Gulliver, J.; Fecht, D.; Vienneau, D.M. Dasymetric modelling of small-area population distribution using land cover and light emissions data. Remote Sens. Environ. 2007, 108, 451–466. [Google Scholar] [CrossRef]
- Wang, L.; Wang, S.; Zhou, Y.; Liu, W.; Hou, Y.; Zhu, J.; Wang, F. Mapping population density in China between 1990 and 2010 using remote sensing. Remote Sens. Environ. 2018, 210, 269–281. [Google Scholar] [CrossRef]
- Liu, Y.; Delahunty, T.; Zhao, N.; Cao, G. These lit areas are undeveloped: Delimiting China’s urban extents from thresholded nighttime light imagery. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 39–50. [Google Scholar] [CrossRef]
- Small, C.; Pozzi, F.; Elvidge, C. Spatial analysis of global urban extent from DMSP-OLS night lights. Remote Sens. Environ. 2005, 96, 277–291. [Google Scholar] [CrossRef]
- Imhoff, M.L.; Lawrence, W.T.; Stutzer, D.C.; Elvidge, C.D. A technique for using composite DMSP/OLS “City Lights” Satellite Data to Map Urban Area. Remote Sens. Environ. 1997, 61, 361–370. [Google Scholar] [CrossRef]
- Feng, Z.; Tang, Y.; Yang, Y.; Zhang, D. The relief degree of land surface in China and its correlation with population distribution. Acta Geogr. Sin. 2007, 62, 1073–1082. [Google Scholar]
- Yue, T.X.; Wang, Y.A.; Chen, S.P.; Liu, J.Y.; Qiu, D.S.; Deng, X.Z.; Liu, M.L.; Tian, Y.Z. Numerical simulation of population distribution in China. Popul. Environ. 2003, 25, 141–163. [Google Scholar] [CrossRef]
- Yue, T.X.; Wang, Y.A.; Liu, J.Y.; Chen, S.P.; Qiu, D.S.; Deng, X.Z.; Liu, M.L.; Tian, Y.Z.; Su, B.P. Surface modelling of human population distribution in China. Ecol. Model. 2005, 181, 461–478. [Google Scholar] [CrossRef]
- Weng, Q.; Lu, D.; Liang, B. Urban surface biophysical descriptors and land surface temperature variations. Photogramm. Eng. Remote Sens. 2006, 72, 1275–1286. [Google Scholar] [CrossRef]
- Yang, X.; Yue, W.; Gao, D. Spatial improvement of human population distribution based on multi-sensor remote-sensing data: An input for exposure assessment. Int. J. Remote Sens. 2013, 34, 5569–5583. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef]
- Harvey, J. Estimating census district populations from satellite imagery: Some approaches and limitations. Int. J. Remote Sens. 2002, 23, 2071–2095. [Google Scholar] [CrossRef]
- Langford, M. Obtaining population estimates in non-census reporting zones: An evaluation of the 3-class dasymetric method. Comput. Environ. Urban Syst. 2006, 30, 161–180. [Google Scholar] [CrossRef]
- Nieves, J.J.; Stevens, F.R.; Gaughan, A.E.; Linard, C.; Sorichetta, A.; Hornby, G.; Patel, N.N.; Tatem, A.J. Examining the correlates and drivers of human population distributions across low- and middle-income countries. J. R. Soc. Interface 2017, 14, 20170401. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Pei, T.; Sobolevsky, S.; Ratti, C.; Shaw, S.-L.; Li, T.; Zhou, C. A new insight into land use classification based on aggregated mobile phone data. Int. J. Geogr. Inf. Sci. 2014, 28, 1988–2007. [Google Scholar] [CrossRef]
- Bakillah, M.; Liang, S.; Mobasheri, A.; Jokar Arsanjani, J.; Zipf, A. Fine-resolution population mapping using OpenStreetMap points-of-interest. Int. J. Geogr. Inf. Sci. 2014, 28, 1940–1963. [Google Scholar] [CrossRef]
- McKenzie, G.; Janowicz, K.; Gao, S.; Yang, J.-A.; Hu, Y. POI pulse: A multi-granular, semantic signature–based information observatory for the interactive visualization of big geosocial data. Cartogr. Int. J. Geogr. Inf. Geovis. 2015, 50, 71–85. [Google Scholar] [CrossRef]
- Qiu, F.; Sridharan, H.; Chun, Y. Spatial autoregressive model for population estimation at the census block level using LIDAR-derived building volume information. Cartogr. Geogr. Inf. Sci. 2010, 37, 239–257. [Google Scholar] [CrossRef]
- Zandbergen, P.A. Dasymetric mapping using high resolution address point datasets. Trans. GIS 2011, 15 (Suppl. 1), 5–27. [Google Scholar] [CrossRef]
- Tapp, A.F. Areal Interpolation and Dasymetric Mapping Methods Using Local Ancillary Data Sources. Cartogr. Geogr. Inf. Sci. 2010, 37, 215–228. [Google Scholar] [CrossRef]
- Coveney, S.; Fotheringham, A.S. The impact of DEM data source on prediction of flooding and erosion risk due to sea-level rise. Int. J. Geogr. Inf. Sci. 2011, 25, 1191–1211. [Google Scholar] [CrossRef]
- West, H.; Horswell, M.; Quinn, N. Exploring the sensitivity of coastal inundation modelling to DEM vertical error. Int. J. Geogr. Inf. Sci. 2018, 32, 1172–1193. [Google Scholar] [CrossRef]
- Lam, N.S.N.; Arenas, H.; Li, Z.; Liu, K.B. An Estimate of Population Impacted by Climate Change Along the U.S. Coast. J. Coast. Res. 2009, II, 1522–1526. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Format | Source |
|---|---|---|
| POIs (2010) | Point features | Baidu Map Services (http://map.baidu.com) |
| Nighttime light (2010) | Grid | The National Oceanic and Atmospheric Administration’s National Geophysical Data Center (NGDC), USA (https://ngdc.noaa.gov/eog/dmsp/download_radcal.html) |
| NDVI (2010) | Grid | Vlaamse Instelling Voor Technologish Onderzoek, Belgium (http://www.vgt.vito.be/) |
| GDEM | Grid | The Earth Remote Sensing Data Analysis Center (ERSDAC), Japan (http://www.gdem.aster.ersdac.or.jp/search.jsp) |
| Census population data (2010) | Table | National Bureau of Statistics of China |
| Global Urban Footprint (GUF) (2011–2012) | Grid | German Aerospace Center (DLR), (https://www.dlr.de/eoc/en/desktopdefault.aspx/tabid-9628/16557_read-40454/) |
| Boundary maps | Polygon features | Administration of Surveying Mapping and Geoinformation, China |
| WorldPop Mainland China dataset (2010) | Grid | WorldPop China Mainland dataset: people per pixel (‘ppp’) (http://esa.un.org/wpp/) |
| Category | Counts | Category | Counts |
|---|---|---|---|
| Governmental agency | 192,196 | Commercial Building | 20,465 |
| Airport | 311 | Retail | 591,372 |
| Railway station | 666 | Hotel | 71,622 |
| Motorcycle station | 3729 | Restaurant and entertainment | 380,637 |
| Bus station | 145,049 | Hospital and clinic | 78,867 |
| Gas station | 39,583 | Educational facility | 134,506 |
| Factory | 81,018 | Company | 492,264 |
| Service zone of highway | 10,873 | Parking lot | 75,415 |
| Toll station | 6461 | Residential community | 91,065 |
| Bank | 154,266 | Park and square | 7159 |
| RF | Cubist | WorldPop | |
|---|---|---|---|
| Mean | 42833.51 | 42830.36 | 44363.85 |
| MRE (%) | 41.73 | 39.87 | 56.01 |
| MAE | 11809.11 | 11898.52 | 15996.73 |
| RMSE | 19999.14 | 20270.09 | 28190.86 |
| %RMSE | 46.54 | 47.16 | 65.60 |
| Administrative Region | RF | Cubist | WorldPop | |||
|---|---|---|---|---|---|---|
| Population in LECZ | Percentage of Population (%) | Population in LECZ | Percentage of Population (%) | Population in LECZ | Percentage of Population (%) | |
| Liaoning | 5,744,143 | 13.52 | 5,865,836 | 13.80 | 4,348,797 | 10.23 |
| Hebei | 7,544,156 | 10.77 | 7,532,371 | 10.75 | 5,959,338 | 8.51 |
| Tianjin | 8,626,425 | 78.62 | 8,676,403 | 79.07 | 8,050,853 | 73.37 |
| Shandong | 10,543,409 | 11.34 | 10,473,863 | 11.27 | 8,301,668 | 8.93 |
| Jiangsu | 34,691,242 | 47.11 | 34,544,677 | 46.91 | 29,578,425 | 40.17 |
| Zhejiang | 26,552,658 | 49.25 | 27,594,627 | 51.18 | 19,506,037 | 36.18 |
| Shanghai | 19,383,507 | 85.11 | 19,586,423 | 85.99 | 15,432,892 | 67.76 |
| Fujian | 7,794,071 | 21.57 | 8,404,211 | 23.26 | 5,624,798 | 15.57 |
| Guangdong | 34,549,207 | 33.51 | 34,973,304 | 33.92 | 26,907,720 | 26.10 |
| Guangxi | 1,190,414 | 2.62 | 1,262,995 | 2.78 | 1,070,519 | 2.36 |
| Hainan | 1,589,500 | 20.42 | 1,724,000 | 22.14 | 1,428,907 | 18.35 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yao, C.; Chen, Q.; Ye, T.; Jin, C. Improved Estimates of Population Exposure in Low-Elevation Coastal Zones of China. Int. J. Environ. Res. Public Health 2019, 16, 4012. https://doi.org/10.3390/ijerph16204012
Yang X, Yao C, Chen Q, Ye T, Jin C. Improved Estimates of Population Exposure in Low-Elevation Coastal Zones of China. International Journal of Environmental Research and Public Health. 2019; 16(20):4012. https://doi.org/10.3390/ijerph16204012
Chicago/Turabian StyleYang, Xuchao, Chenming Yao, Qian Chen, Tingting Ye, and Cheng Jin. 2019. "Improved Estimates of Population Exposure in Low-Elevation Coastal Zones of China" International Journal of Environmental Research and Public Health 16, no. 20: 4012. https://doi.org/10.3390/ijerph16204012
APA StyleYang, X., Yao, C., Chen, Q., Ye, T., & Jin, C. (2019). Improved Estimates of Population Exposure in Low-Elevation Coastal Zones of China. International Journal of Environmental Research and Public Health, 16(20), 4012. https://doi.org/10.3390/ijerph16204012