Do Income, Race and Ethnicity, and Sprawl Influence the Greenspace-Human Health Link in City-Level Analyses? Findings from 496 Cities in the United States



Abstract
1. Introduction
1.1. Literature Review: Why Does the Greenspace—Health Relationship Vary?
1.1.1. Different Types of Indicators of Greenspace Exposure
1.1.2. Different Factors Moderating the Greenspace—Health Link
1.1.3. Different Health Outcomes
1.1.4. Different Units of Analysis
1.2. The Current Study: Examining the Greenspace—Health Link Across Cities
2. Materials and Methods
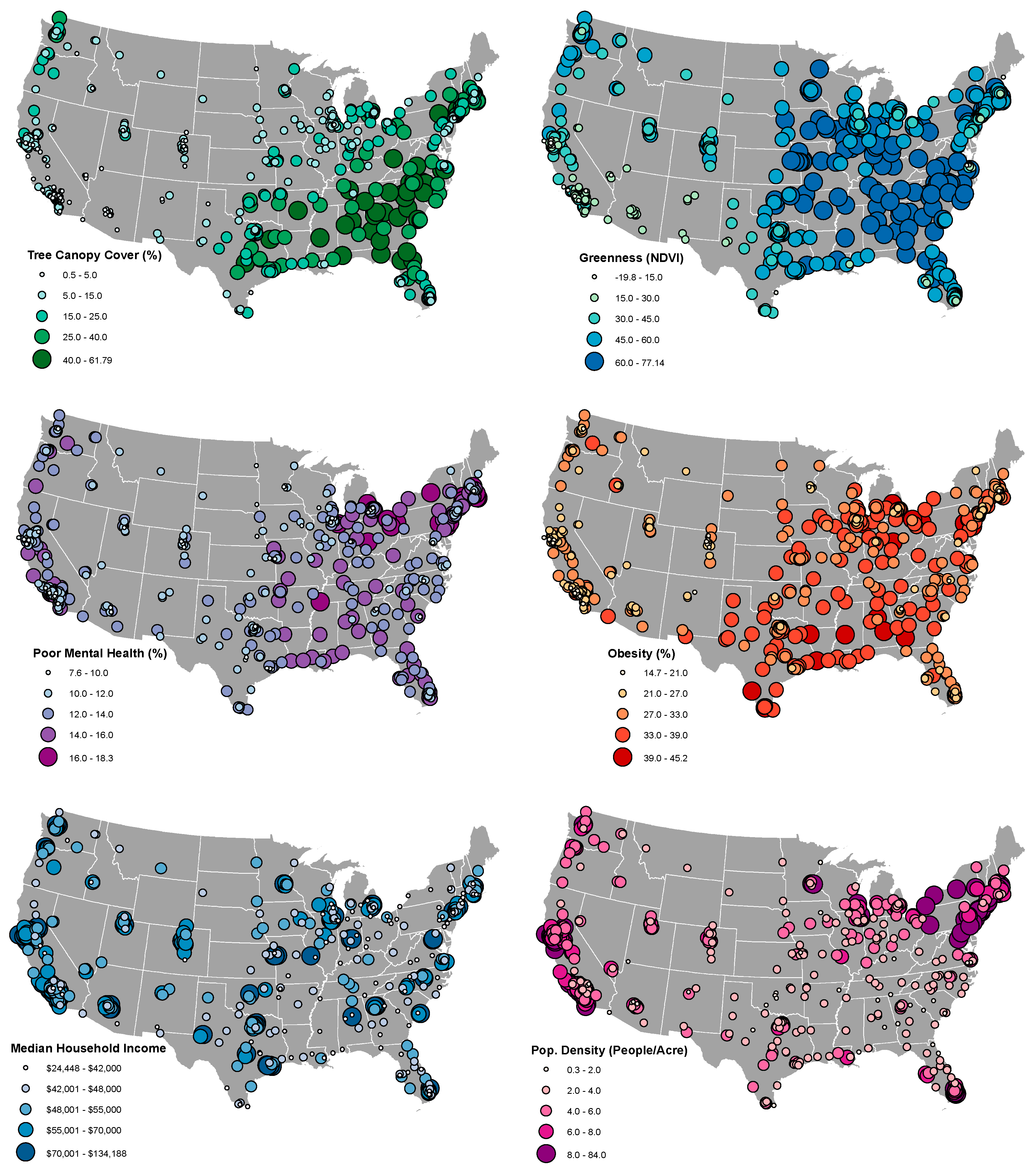
2.1. Sample
2.2. Sources of Data and Measures
2.3. Analyses
3. Results
3.1. Descriptive Statistics
3.2. Bivariate Correlations
3.3. Effects of Greenspace on Health in Multivariate Models
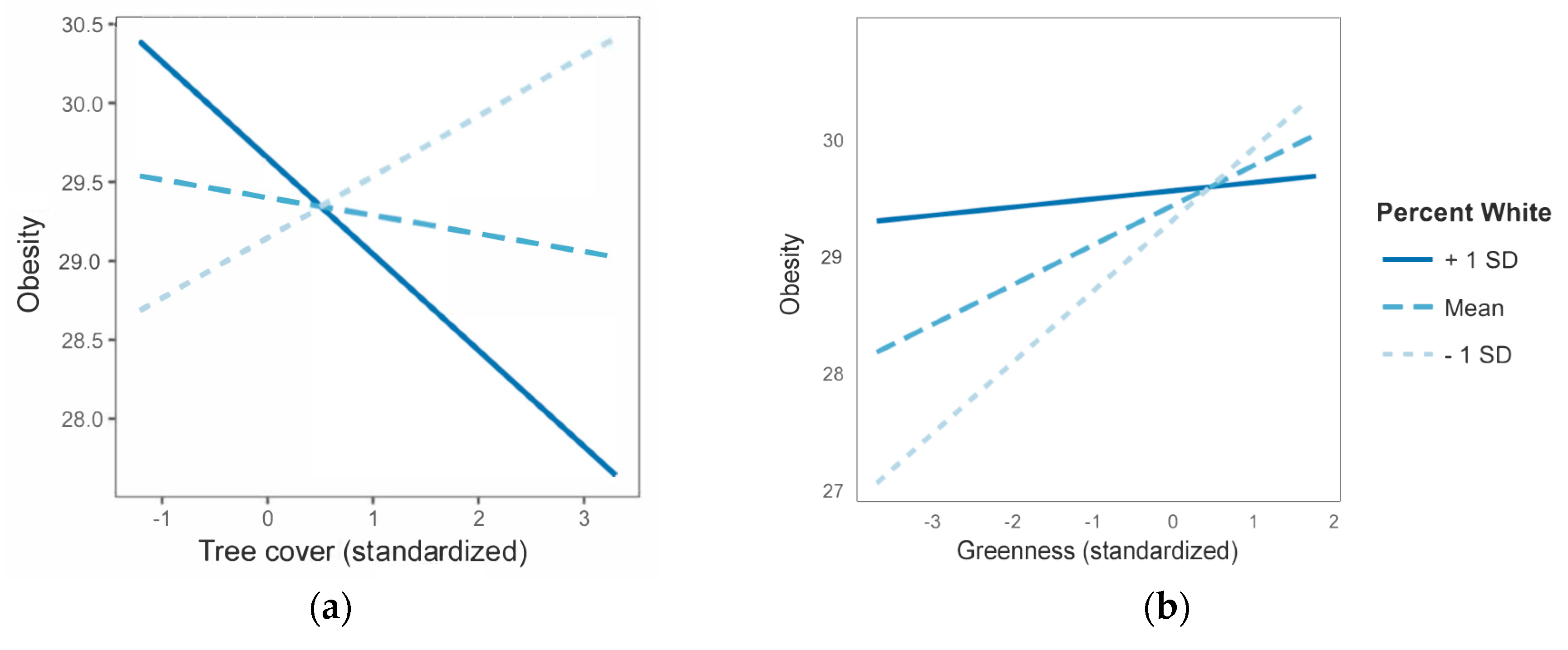
3.4. Moderation Effects in the Greenspace—Health Relationship
4. Discussion
4.1. Understanding the Impact of Different Types of Indicators of Greenspace Exposure
4.2. Understanding the Impact of Moderating Factors
4.3. Understanding the Impact of Health Outcomes
4.4. Understanding the Impact of Units of Analysis
4.5. Strengths and Limitations
4.6. Future Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Effects of Greenspaces on Obesity | |||
|---|---|---|---|
| Model | Predictor Coefficient | Model Fit 1 | |
| Greenness | AIC | Moran’s I | |
| Ordinary least squares (OLS) | 0.019 * | 2312 | 0.17 *** |
| Spatial lag (SpL) | 0.011 | 2240 | 0.12 *** |
| Spatial moving average (SMA) | 0.00037 | 2155 | −0.0045 |
| Spatial autoregressive (SAC) | −0.0060 | 2140 | 0.044 *** |
| Spatial error (SpE) | −0.0060 | 2138 | 0.044 *** |
| Spatial durbin error (SDE) | −0.017 + | 2110 | 0.028 *** |
| Spatial durbin (SD) | −0.021 * | 2107 | 0.026 ** |
| Tree cover | AIC | Moran’s I | |
| OLS | −00.013 | 2315 | 0.18 *** |
| SpL | −0.020 * | 2237 | 0.12 *** |
| SMA | −0.026 * | 2149 | 0.50 |
| SAC | −0.032 ** | 2132 | 0.043 *** |
| SpE | −0.031 ** | 2131 | 0.043 *** |
| SD | −0.043 *** | 2013 | 0.028 *** |
| SDE | −0.039 *** | 2108 | 0.032 *** |
| Effects of Greenspaces on Poor Mental Health | |||
| Model | Predictor Coefficient | Model Fit 1 | |
| Greenness | AIC | Moran’s I | |
| OLS | −0.0097 ** | 1510 | 0.21 *** |
| SpL | −0.0085 * | 1455 | 0.16 *** |
| SMA | −0.0098 ** | 1242 | −0.020 *2 |
| SpE | −0.0022 | 1143 | 0.051 *** |
| SAC | −0.0018 | 1140 | 0.048 *** |
| SDE | −0.0010 | 1123 | 0.032 *** |
| SD | −0.00012 | 1116 | 0.021 ** |
| Tree cover | AIC | Moran’s I | |
| OLS | −00.00017 | 1517 | 0.22 *** |
| SpL | −0.0026 | 1460 | 0.17 *** |
| SMA | −0.0057 | 1247 | −0.019 |
| SpE | −0.0042 | 1142 | 0.050 *** |
| SAC | −0.0035 | 1132 | 0.043 *** |
| SDE | −0.00048 | 1120 | 0.031 *** |
| SD | −0.0026 | 1112 | 0.021 * |

References
- Taylor, L.; Hochuli, D. Defining greenspace: Multiple uses across multiple disciplines. Landsc. Urban Plan. 2017, 158, 25–28. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention Mental Health. Available online: https://www.cdc.gov/healthyplaces/healthtopics/mental.htm (accessed on 21 May 2018).
- American Association of Geographers Urban Parks & Green Spaces as a Panacea? Challenges and Opportunities for Urban Greening. Available online: https://aag.secure-abstracts.com/AAG%20Annual%20Meeting%202018/sessions-gallery/11412 (accessed on 21 May 2018).
- Markevych, I.; Schoierer, J.; Hartig, T.; Chudnovsky, A.; Hystad, P.; Dzhambov, A.M.; de Vries, S.; Triguero-Mas, M.; Brauer, M.; Nieuwenhuijsen, M.J.; et al. Exploring pathways linking greenspace to health: Theoretical and methodological guidance. Environ. Res. 2017, 158, 301–317. [Google Scholar] [CrossRef] [PubMed]
- Ruijsbroek, A.; Droomers, M.; Kruize, H.; van Kempen, E.; Gidlow, C.J.; Hurst, G.; Andrusaityte, S.; Nieuwenhuijsen, M.J.; Maas, J.; Hardyns, W.; et al. Does the Health Impact of Exposure to Neighbourhood Green Space Differ between Population Groups? An Explorative Study in Four European Cities. Int. J. Environ. Res. Public Health 2017, 14, 618. [Google Scholar] [CrossRef] [PubMed]
- Richardson, E.A.; Mitchell, R.J.; Hartig, T.; de Vries, S.; Astell-Burt, T.; Frumkin, H. Green cities and health: A question of scale? J. Epidemiol. Community Health 2011, 66, 160–165. [Google Scholar] [CrossRef] [PubMed]
- Joassart-Marcelli, P.; Wolch, J.R.; Salim, Z. Building the healthy city: The role of nonprofits in creating active urban parks. Urban Geogr. 2013, 32, 682–711. [Google Scholar] [CrossRef]
- Rigolon, A.; Browning, M.; Jennings, V. 2018 Inequities in the quality of urban park systems: An environmental justice investigation of cities in the United States. Landsc. Urban Plan. 2018, 178, 156–169. [Google Scholar] [CrossRef]
- Pincetl, S. Nonprofits and park provision in Los Angeles: An exploration of the rise of governance approaches to the provision of local services. Soc. Sci. Q. 2003, 84, 979–1001. [Google Scholar] [CrossRef]
- Robert Wood Johnson Foundation County and City Health Departments: The Need for Sustainable Funding through Health Reform. Available online: http://healthyamericans.org/assets/files/Sustainable.pdf (accessed on 21 May 2018).
- Ogden, C.L.; Carroll, M.D.; Kit, B.K.; Flegal, K.M. Prevalence of childhood and adult obesity in the United States, 2011–2012. JAMA 2014, 311, 806–814. [Google Scholar] [CrossRef] [PubMed]
- Hodson, C.B.; Sander, H.A. Green urban landscapes and school-level academic performance. Landsc. Urban Plan. 2017, 160, 16–27. [Google Scholar] [CrossRef]
- Kweon, B.-S.; Ellis, C.D.; Lee, J.; Jacobs, K. The link between school environments and student academic performance. Urban For. Urban Green. 2017, 23, 35–43. [Google Scholar] [CrossRef]
- Reid, C.; Clougherty, J.; Shmool, J.; Kubzansky, L. Is all urban green space the same? A comparison of the health benefits of trees and grass in New York City. Int. J. Environ. Res. Public Health 2017, 14, 1411. [Google Scholar] [CrossRef] [PubMed]
- Fong, K.C.; Hart, J.E.; James, P. A review of epidemiologic studies on greenness and health: Updated literature through 2017. Curr. Environ. Health Rep. 2018, 2, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Browning, M.; Lee, K. Within what distance does “greenness” best predict physical health? A systematic review of articles with GIS buffer analyses across the lifespan. Int. J. Environ. Res. Public Health 2017, 14, 675. [Google Scholar] [CrossRef] [PubMed]
- Grove, J.M.; Locke, D.H.; O’Neil-Dunne, J.P.M. An ecology of prestige in New York City: Examining the relationships among population density, socio-economic status, group identity, and residential canopy cover. Environ. Manag. 2014, 54, 402–419. [Google Scholar] [CrossRef] [PubMed]
- Lachowycz, K.; Jones, A.P. Towards a better understanding of the relationship between greenspace and health: Development of a theoretical framework. Landsc. Urban Plan. 2013, 118, 62–69. [Google Scholar] [CrossRef]
- Browning, M.; Kuo, F.; Sachdeva, S.; Lee, K.; Westphal, L. Greenness and school-wide test scores are not always positively associated—A replication of “linking student performance in Massachusetts elementary schools with the ‘greenness’ of school surroundings using remote sensing.”. Landsc. Urban Plan. 2018, 178, 69–72. [Google Scholar] [CrossRef]
- Dadvand, P.; Wright, J.; Martínez, D.; Basagaña, X.; McEachan, R.R.C.; Cirach, M.; Gidlow, C.J.; de Hoogh, K.; Grazuleviciene, R.; Nieuwenhuijsen, M.J. Inequality, green spaces, and pregnant women: Roles of ethnicity and individual and neighbourhood socioeconomic status. Environ. Int. 2014, 71, 101–108. [Google Scholar] [CrossRef] [PubMed]
- McEachan, R.R.C.; Prady, S.L.; Smith, G.; Fairley, L.; Cabieses, B.; Gidlow, C.J.; Wright, J.; Dadvand, P.; van Gent, D.; Nieuwenhuijsen, M.J. The association between green space and depressive symptoms in pregnant women: Moderating roles of socioeconomic status and physical activity. J. Epidemiol. Community Health 2015, 70, 253–259. [Google Scholar] [CrossRef] [PubMed]
- Ewing, R.; Pendall, R.; Chen, D. Measuring sprawl and its transportation impacts. Trans. Res. Rec. J. Trans. Res. Board 2007, 1831, 175–183. [Google Scholar] [CrossRef]
- Sultana, S.; Weber, J. Journey-to-work patterns in the age of sprawl: Evidence from two midsize southern metropolitan areas. Prof. Geogr. 2007, 59, 193–208. [Google Scholar] [CrossRef]
- De Nazelle, A.; Nieuwenhuijsen, M.J.; Antó, J.M.; Brauer, M.; Briggs, D.; Braun-Fahrlander, C.; Cavill, N.; Cooper, A.R.; Desqueyroux, H.; Fruin, S.; et al. Improving health through policies that promote active travel: A review of evidence to support integrated health impact assessment. Environ. Int. 2011, 37, 766–777. [Google Scholar] [CrossRef] [PubMed]
- Frumkin, H.; Frank, L.; Jackson, R.J. Urban Sprawl and Public Health: Designing, Planning, and Building for Healthy Communities; Island Press: Washington, DC, USA, 2004. [Google Scholar]
- Frumkin, H. Urban sprawl and public health. Public Health Rep. 2002, 117, 201–217. [Google Scholar] [CrossRef]
- Gascon, M.; Triguero-Mas, M.; Martínez, D.; Dadvand, P.; Rojas-Rueda, D.; Plasència, A.; Nieuwenhuijsen, M.J. Residential green spaces and mortality: A systematic review. Environ. Int. 2016, 86, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Ruokolainen, L. Green living environment protects against allergy, or does it? Eur. Respir J. 2017, 49, 1–4. [Google Scholar] [CrossRef] [PubMed]
- James, P.; Banay, R.F.; Hart, J.E.; Laden, F. A review of the health benefits of greenness. Curr. Epidemol. Rep. 2015, 2, 131–142. [Google Scholar] [CrossRef] [PubMed]
- Van den Berg, M.; Wendel-Vos, W.; van Poppel, M.; Kemper, H.; van Mechelen, W.; Maas, J. Health benefits of green spaces in the living environment: A systematic review of epidemiological studies. Urban For. Urban Green. 2015, 14, 806–816. [Google Scholar] [CrossRef]
- Gascon, M.; Triguero-Mas, M.; Martínez, D.; Dadvand, P.; Forns, J.; Plasència, A.; Nieuwenhuijsen, M.J. Mental health benefits of long-term exposure to residential green and blue spaces: A systematic review. Int. J. Environ. Res. Public Health 2015, 12, 4354–4379. [Google Scholar] [CrossRef] [PubMed]
- Kondo, M.C.; Fluehr, J.; McKeon, T.; Branas, C. Urban green space and its impact on human health. Int. J. Environ. Res. Public Health 2018, 15, 445. [Google Scholar] [CrossRef] [PubMed]
- Kuo, F. How might contact with nature promote human health? Promising mechanisms and a possible central pathway. Front. Psychol. 2015, 6, 1–8. [Google Scholar] [CrossRef] [PubMed]
- West, S.T.; Shores, K.A.; Mudd, L.M. Association of Available Parkland, Physical Activity, and Overweight in America?s Largest Cities. J. Public Health Manag. Pract. 2012, 18, 423–430. [Google Scholar] [CrossRef] [PubMed]
- Larson, L.R.; Jennings, V.L.; Cloutier, S.A. Public Parks and Wellbeing in Urban Areas of the United States. PLoS ONE 2016, 11, e0153211. [Google Scholar] [CrossRef] [PubMed]
- Rigolon, A. A complex landscape of inequity in access to urban parks: A literature review. Landsc. Urban Plan. 2016, 153, 160–169. [Google Scholar] [CrossRef]
- Gerrish, E.; Watkins, S.L. The relationship between urban forests and income: A meta-analysis. Landsc. Urban Plan. 2018, 170, 293–308. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, W.C.; Frumkin, H.; Jackson, R.J.; Chang, C.-Y. Gaia meets Asclepius: Creating healthy places. Landsc. Urban Plan. 2014, 127, 182–184. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention 500 Cities: Local Data for Better Health. Available online: https://www.cdc.gov/500cities (accessed on 21 May 2018).
- Wang, Y.; Holt, J.B.; Zhang, X.; Lu, H.; Shah, S.N.; Dooley, D.P.; Matthews, K.A.; Croft, J.B. Comparison of Methods for Estimating Prevalence of Chronic Diseases and Health Behaviors for Small Geographic Areas: Boston Validation Study, 2013. Prev. Chronic Dis. 2017, 14, 170281. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Holt, J.B.; Yun, S.; Lu, H.; Greenlund, K.J.; Croft, J.B. Validation of multilevel regression and poststratification methodology for small area estimation of health indicators from the behavioral risk factor surveillance system. Am. J. Epidemiol. 2015, 182, 127–137. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention About the Behavioral Risk Factor Surveillance System (BRFSS). Available online: https://www.cdc.gov/brfss/about/about_brfss.htm (accessed on 19 June 2018).
- Centers for Disease Control and Prevention Behavioral Risk Factor Surveillance System 2016 Summary Data Quality Report. Available online: https://www.cdc.gov/brfss/annual_data/2016/pdf/2016-sdqr.pdf (accessed on 19 June 2018).
- Pierannunzi, C.; Hu, S.S.; Balluz, L. A systematic review of publications assessing reliability and validity of the Behavioral Risk Factor Surveillance System (BRFSS), 2004–2011. BMC Med. Res. Methodol. 2013, 13, 49. [Google Scholar] [CrossRef] [PubMed]
- Fitzpatrick, K.M.; Shi, X.; Willis, D.; Niemeier, J. Obesity and place: Chronic disease in the 500 largest U.S. cities. Obes. Res. Clin. Pract. 2018. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.H.; Li, Y.; Liu, B. Exploratory Cluster Analysis to Identify Patterns of Chronic Kidney Disease in the 500 Cities Project. Prev. Chronic Dis. 2018, 15, 170372. [Google Scholar] [CrossRef] [PubMed]
- Birkhead, G.S. Successes and Continued Challenges of Electronic Health Records for Chronic Disease Surveillance. Am. J. Public Health 2017, 107, 1365–1367. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.H.; Liu, B.; Li, Y. Risk factors associated with multiple correlated health outcomes in the 500 Cities Project. Prev. Med. 2018, 112, 126–129. [Google Scholar] [CrossRef] [PubMed]
- Wickham, J.; Homer, C.; Vogelmann, J.; McKerrow, A.; Mueller, R.; Herold, N.; Coulston, J. The Multi-Resolution Land Characteristics (MRLC) Consortium—20 Years of Development and Integration of USA National Land Cover Data. Remote Sens. 2014, 6, 7424–7441. [Google Scholar] [CrossRef]
- Wickham, J.; Stehman, S.V.; Fry, J.A.; Smith, J.H.; Homer, C. Thematic accuracy of the NLCD 2001 land cover for the conterminous United States. Remote Sens. Environ. 2010, 114, 1286–1296. [Google Scholar] [CrossRef]
- Greenfield, E.J.; Nowak, D.J.; Walton, J.T. Assessment of 2001 NLCD percent tree and impervious cover estimates. Photogr. Eng. Remote Sens. 2009, 75, 1279–1286. [Google Scholar] [CrossRef]
- United State Census Bureau TIGER Products. Available online: https://www.census.gov/geo/maps-data/data/tiger.html (accessed on 21 May 2018).
- United State Census Bureau American FactFinder. Available online: https://factfinder.census.gov/faces/nav/jsf/pages/guided_search.xhtml (accessed on 21 May 2018).
- Spielman, S.E.; Folch, D.; Nagle, N. Patterns and causes of uncertainty in the American Community Survey. Landsc. Urban Plan. 2014, 46, 147–157. [Google Scholar] [CrossRef] [PubMed]
- Williamson, T. Sprawl, Spatial Location, and Politics: How Ideological Identification Tracks the Built Environment. Am. Politics Res. 2008, 36, 903–933. [Google Scholar] [CrossRef]
- Bailey, Z.D.; Krieger, N.; Agénor, M.; Graves, J. Structural racism and health inequities in the USA: Evidence and interventions. Landsc. Urban Plan. 2017, 389, 1453–1463. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Y.-C. Spatial-temporal dynamics of urban green space in response to rapid urbanization and greening policies. Landsc. Urban Plan. 2011, 100, 268–277. [Google Scholar] [CrossRef]
- Anselin, L. Exploring Spatial Data with GeoDa; University of Illinois at Urbana-Champaign: Urbana, IL, USA, 2005; pp. 1–244. [Google Scholar]
- Best, N.; Richardson, S.; Thomson, A. A comparison of Bayesian spatial models for disease mapping. Environ. Behav. 2005, 14, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Baron, R.M.; Kenny, D.A. The moderator-mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. J. Pers. Soc. Psychol. 1986, 51, 1173–1182. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, C. Residential greenness and adiposity: Findings from the UK Biobank. Environ. Int. 2017, 106, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Crouse, D.L.; Pinault, L.; Balram, A.; Hystad, P.; Peters, P.A.; Chen, H.; van Dnokelaar, A.; Martin, R.V.; Menard, R.; Robichaud, A.; Villeneuve, P.J. Urban greenness and mortality in Canada’s largest cities: A national cohort study. Landsc. Urban Plan. 2017, 1, e289–e297. [Google Scholar] [CrossRef]
- Lachowycz, K.; Jones, A.P. Does walking explain associations between access to greenspace and lower mortality? Soc. Sci. Med. 2014, 107, 9–17. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, R.J.; Popham, F. Effect of exposure to natural environment on health inequalities: An observational population study. Lancet 2008, 372, 1655–1660. [Google Scholar] [CrossRef]
- Cusack, L.; Larkin, A.; Carozza, S.; Hystad, P. Associations between residential greenness and birth outcomes across Texas. Environ. Res. 2017, 152, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Agay-Shay, K.; Peled, A.; Crespo, A.V.; Peretz, C.; Amitai, Y.; Linn, S.; Friger, M.; Nieuwenhuijsen, M.J. Green spaces and adverse pregnancy outcomes. Occup. Environ. Med. 2014, 71, 562–569. [Google Scholar] [CrossRef] [PubMed]
- Thiering, E.; Markevych, I.; Brüske, I.; Fuertes, E.; Kratzsch, J.; Sugiri, D.; Hoffmann, B.; von Berg, A.; Bauer, C.-P.; Koletzko, S.; et al. Associations of residential long-term air pollution exposures and satellite-derived greenness with insulin resistance in German adolescents. Environ. Health Perspect. 2016, 124, 1291–1298. [Google Scholar] [CrossRef] [PubMed]
- Maas, J.; Verheij, R.A.; Spreeuwenberg, P.; Groenewegen, P.P. Physical activity as a possible mechanism behind the relationship between green space and health: A multilevel analysis. BMC Public Health 2008, 8, 206. [Google Scholar] [CrossRef] [PubMed]
- Schwanen, T.; Dijst, M.; Dieleman, F.M. A Microlevel Analysis of Residential Context and Travel Time. Environ. Plan. A 2016, 34, 1487–1507. [Google Scholar] [CrossRef]
- Cohen, D.A.; Marsh, T.; Williamson, S.; Derose, K.P.; Martinez, H.; Setodji, C.; MacKenzie, T.L. Parks and physical activity: Why are some parks used more than others? Landsc. Urban Plan. 2010, 50, S9–S12. [Google Scholar] [CrossRef] [PubMed]
- Bell, J.F.; Wilson, J.S.; Liu, G.C. Neighborhood greenness and 2-year changes in body mass index of children and youth. Amepre 2008, 35, 547–553. [Google Scholar] [CrossRef] [PubMed]
- Pereira, G.; Christian, H.; Foster, S.; Boruff, B.J.; Bull, F.; Knuiman, M.; Giles-Corti, B. The association between neighborhood greenness and weight status: An observational study in Perth Western Australia. Environ. Health 2013, 12, 49. [Google Scholar] [CrossRef] [PubMed]
- Dadvand, P.; Villanueva, C.M.; Font-Ribera, L.; Martínez, D.; Basagaña, X.; Belmonte, J.; Vrijheid, M.; Grazuleviciene, R.; Kogevinas, M.; Nieuwenhuijsen, M.J. Risks and benefits of green spaces for children: A cross-sectional study of associations with sedentary behavior, obesity, asthma, and allergy. Environ. Health Perspect. 2014, 122, 1329–1335. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.C.; Wilson, J.S.; Qi, R.; Ying, J. Green neighborhoods, food retail and childhood overweight: Differences by population density. Am. J. Health Promot. 2007, 21, 317–325. [Google Scholar] [CrossRef] [PubMed]
- Peen, J.; Schoevers, R.A.; Beekman, A.T.; Dekker, J. The current status of urban-rural differences in psychiatric disorders. Acta Psychiatr. Scand. 2010, 121, 84–93. [Google Scholar] [CrossRef] [PubMed]
- Tsai, W.-L.; McHale, M.; Jennings, V.L.; Marquet, O.; Hipp, J.; Leung, Y.-F.; Floyd, M. Relationships between Characteristics of Urban Green Land Cover and Mental Health in U.S. Metropolitan Areas. Int. J. Environ. Res. Public Health 2018, 15, 340. [Google Scholar] [CrossRef] [PubMed]
- Fewell, Z.; Davey Smith, G.; Sterne, J.A.C. The Impact of Residual and Unmeasured Confounding in Epidemiologic Studies: A Simulation Study. Am. J. Epidemiol. 2007, 166, 646–655. [Google Scholar] [CrossRef] [PubMed]
- Brown, B.B.; Yamada, I.; Smith, K.R.; Zick, C.D.; Kowaleski-Jones, L.; Fan, J.X. Mixed land use and walkability Variations in land use measures and relationships with BMI, overweight, and obesity. Health Place 2009, 15, 1130–1141. [Google Scholar] [CrossRef] [PubMed]
- O’Neil-Dunne, J. Available online: http://gis.w3.uvm.edu/utc (accessed on 19 July 2018).
- Trust for Public Land ParkServe. Available online: https://parkserve.tpl.org/ (accessed on 21 May 2018).
- Spielman, S.E.; Folch, D.C. Reducing Uncertainty in the American Community Survey through Data-Driven Regionalization. PLoS ONE 2015, 10, e0115626. [Google Scholar] [CrossRef] [PubMed]
- Rigolon, A. Parks and young people: An environmental justice study of park proximity, acreage, and quality in Denver, Colorado. Landsc. Urban Plan. 2017, 165, 73–83. [Google Scholar] [CrossRef]
- Rigolon, A.; Németh, J. “We’re not in the business of housing” Environmental gentrification and the nonprofitization of green infrastructure projects. Cities 2018. [Google Scholar] [CrossRef]
- Wolch, J.R.; Byrne, J.; Newell, J.P. Urban green space, public health, and environmental justice: The challenge of making cities “just green enough.”. Landsc. Urban Plan. 2014, 125, 234–244. [Google Scholar] [CrossRef]


| Variable | Description | Source 1 |
|---|---|---|
| Percent poor mental health (“poor mental health”) | Percentage of residents who reported poor mental health 14 or more out of the last 30 days | CDC |
| Percent obese (“obesity”) | Percentage of residents with Body Mass Index (BMI) ≥30.0 kg/m2 | CDC |
| NDVI (“greenness”) | Mean of 250 m NDVI pixel values within city limit | MODIS |
| Percent tree cover (“tree cover”) | Mean of 30 m percent tree canopy cover pixel values within city limit | MLRC |
| Median income | Median household income in dollars | ACS |
| Percent degree | Percentage of residents aged 25 and older with bachelor, associates, professional, or doctoral degree | ACS |
| Percent White | Percentage of non-Hispanic White residents | ACS |
| Percent drivers | Percentage of people aged 16 or above commuting to work via automobile (alone) and a measure for urban sprawl | ACS |
| Population density | Number of residents per acre and a measure for urban sprawl | ACS |
| Median age | Median age of residents | ACS |
| Percent female | Percentage of female residents | ACS |
| Physically inactive | Percentage of people who did not participate in physical activities or exercise in the past month | CDC |
| Median age of housing | Median age of housing structure in years (2018 minus the median year when housing buildings were built) | ACS |
| Population | Total population of city | ACS |
| Variable | Mean | Sd | Median | Min | Max |
|---|---|---|---|---|---|
| Poor mental health | 12.4 | 2.1 | 12.4 | 7.6 | 18.3 |
| Obesity | 29.3 | 5.9 | 29.5 | 14.7 | 45.2 |
| Greenness | 45.5 | 17.7 | 47.9 | −19.8 | 77.1 |
| Tree cover | 17.0 | 13.5 | 13.6 | 0.5 | 61.8 |
| Median income | $56,515 | $19,115 | $50,956 | $24,448 | $134,188 |
| Percent degree | 31.9 | 13.9 | 29.3 | 6.0 | 76.7 |
| Percent White | 50.0 | 21.6 | 51.1 | 1.1 | 89.2 |
| Percent drivers | 76.1 | 9.1 | 78.5 | 28.2 | 89.9 |
| Population density | 6.4 | 4.9 | 4.9 | 0.3 | 34.0 |
| Median age | 35.0 | 4.1 | 34.8 | 22.6 | 47.6 |
| Percent female | 51.0 | 1.3 | 51.0 | 41.7 | 55.0 |
| Physically inactive | 25.8 | 6.2 | 26.0 | 13.0 | 44.8 |
| Median age of housing | 42.5 | 15.5 | 40.0 | 12.0 | 77.0 |
| Population | 197,340 | 297,127 | 110,983 | 42,556 | 3,918,872 |
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | (11) | (12) | (13) | (14) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Poor mental health (1) | ||||||||||||||
| Obesity (2) | 0.70 *** | |||||||||||||
| Greenness (3) | 0.13 ** | 0.40 *** | ||||||||||||
| Tree cover (4) | 0.18 *** | 0.30 *** | 0.72 *** | |||||||||||
| Median income (5) | −0.80 *** | −0.76 *** | −0.24 *** | −0.20 *** | ||||||||||
| Percent degree (6) | −0.76 *** | −0.60 *** | 0.11 * | 0.15 ** | 0.65 *** | |||||||||
| Percent White (7) | −0.30 *** | −0.19 *** | 0.39 *** | 0.16 *** | 0.15 *** | 0.43 *** | ||||||||
| Percent drivers (8) | −0.023 | 0.140 ** | 0.19 *** | 0.07 | 0.023 | −0.24 *** | 0.17 *** | |||||||
| Population density (9) | 0.054 | −0.21 *** | −0.37 *** | −0.31 *** | 0.07 | −0.019 | −0.43 *** | −0.63 *** | ||||||
| Median age (10) | −0.25 *** | −0.40 *** | −0.084 | −0.013 | 0.41 *** | 0.19 *** | 0.24 *** | 0.22 *** | −0.011 | |||||
| Percent female (11) | 0.26 *** | 0.25 *** | 0.25 *** | 0.32 *** | −0.22 *** | −0.058 | −0.045 | 0.12 * | −0.069 | 0.19 *** | ||||
| Physically inactive (12) | 0.75 *** | 0.86 *** | 0.29 *** | 0.28 *** | −0.72 *** | −0.64 *** | −0.39 *** | 0.015 | 0.015 | −0.33 *** | 0.24 *** | |||
| Median age of housing (13) | 0.38 *** | 0.23 *** | 0.031 | 0.035 | −0.32 *** | −0.16 *** | −0.15 *** | −0.51 *** | 0.51 *** | −0.016 | 0.11 * | 0.34 *** | ||
| Population (14) | 0.017 | 0.046 | −0.085 | −0.018 | −0.077 | 0.026 | −0.15 *** | −0.17 *** | 0.12 ** | −0.072 | −0.018 | 0.056 | 0.083 |
| Model Variables and Fit Statistics | Model 1 | Model 2 | Model 3 | Model 4 |
|---|---|---|---|---|
| Obesity 1 | Poor Mental Health | |||
| Greenness | Tree Cover | Greenness | Tree Cover | |
| Greenspace variable | 0.00037 (0.0090) | −0.026 (0.11) * | −0.0099 (0.0037) ** | −0.0057 (0.0044) |
| Intercept | 7.3 (3.8) + | 6.6 (3.7) + | 3.6 (1.4) * | 3.6 (1.4) * |
| Median income 2 | −0.98 (0.18) *** | −0.95 (0.18) *** | −0.85 (0.071) *** | −0.86 (0.072) *** |
| Percent White | 0.0082 (0.0075) | 0.011 (0.0071) | 0.0014 (0.0030) | −0.00083 (0.0028) |
| Percent drivers | 0.033 (0.018) + | 0.027 (0.018) | 0.013 (0.0068) + | 0.012 (0.0069) + |
| Population density | −0.15 (0.033) *** | −0.17 (0.034) *** | 0.0085 (0.013) | 0.010 (0.013) |
| Median age | −0.11 (0.033) ** | −0.11 (0.032) *** | 0.0025 (0.013) | 0.0064 (0.013) |
| Percent female | 0.12 (0.072) + | 0.15 (0.071) * | 0.060 (0.027) + | 0.043 (0.027) |
| Physically inactive | 0.65 (0.035) *** | 0.67 (0.034) *** | 0.21 (0.014) *** | 0.20 (0.014) *** |
| Median age of housing | 0.020 (0.011) + | 0.021 (0.011) + | 0.0025 (0.0043) | 0.0064 (0.013) * |
| Population 2 | −0.0042 (0.082) | 0.00089 (0.081) | 0.0022 (0.030) | 0.0067 (0.031) |
| AIC | 2155 | 2149 | 1242 | 1247 |
| Lambda | 0.77 | 0.78 | 0.96 | 0.95 |
| Likelihood ratio test value | 159 *** | 168 *** | 270 *** | 271 *** |
| −2 log likelihood | 2028 | 2124 | 1216 | 1212 |
| Maximum likelihood residual variance | 4.8 | 4.8 | 0.82 | 0.83 |
| Moran’s I (observed) | −0.0045 | −0.0081 | −0.020 | −0.019 |
| Moran’s I (expected) | −0.0020 | −0.0020 | −0.0020 | −0.0020 |
| Subsample Characteristics | Green Space-Health Relationships Tested | ||||
|---|---|---|---|---|---|
| Majority Group | Number of Cities | Obesity-Greenness | Obesity-Tree Cover | Mental Health-Greenness | Mental Health-Tree Cover |
| Non-Hispanic Black majority | 44 | −0.054 * | −0.10 *** | n.s. | n.s. |
| Hispanic or Latino majority | 103 | n.s. | n.s. | n.s. | n.s. |
| Non-Hispanic White majority | 349 | n.s. | n.s. | n.s. | n.s. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Browning, M.H.E.M.; Rigolon, A. Do Income, Race and Ethnicity, and Sprawl Influence the Greenspace-Human Health Link in City-Level Analyses? Findings from 496 Cities in the United States. Int. J. Environ. Res. Public Health 2018, 15, 1541. https://doi.org/10.3390/ijerph15071541
Browning MHEM, Rigolon A. Do Income, Race and Ethnicity, and Sprawl Influence the Greenspace-Human Health Link in City-Level Analyses? Findings from 496 Cities in the United States. International Journal of Environmental Research and Public Health. 2018; 15(7):1541. https://doi.org/10.3390/ijerph15071541
Chicago/Turabian StyleBrowning, Matthew H. E. M., and Alessandro Rigolon. 2018. "Do Income, Race and Ethnicity, and Sprawl Influence the Greenspace-Human Health Link in City-Level Analyses? Findings from 496 Cities in the United States" International Journal of Environmental Research and Public Health 15, no. 7: 1541. https://doi.org/10.3390/ijerph15071541
APA StyleBrowning, M. H. E. M., & Rigolon, A. (2018). Do Income, Race and Ethnicity, and Sprawl Influence the Greenspace-Human Health Link in City-Level Analyses? Findings from 496 Cities in the United States. International Journal of Environmental Research and Public Health, 15(7), 1541. https://doi.org/10.3390/ijerph15071541