Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models


Abstract
1. Introduction
1.1. Overview
1.2. Literature Review
2. Methodology
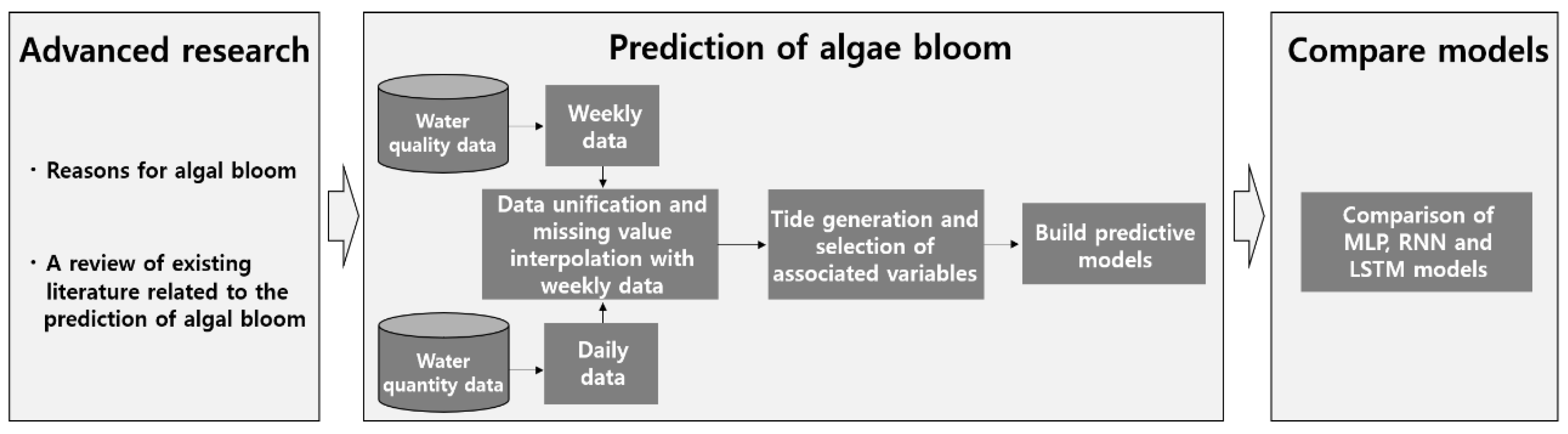
2.1. Scope and Composition of Research
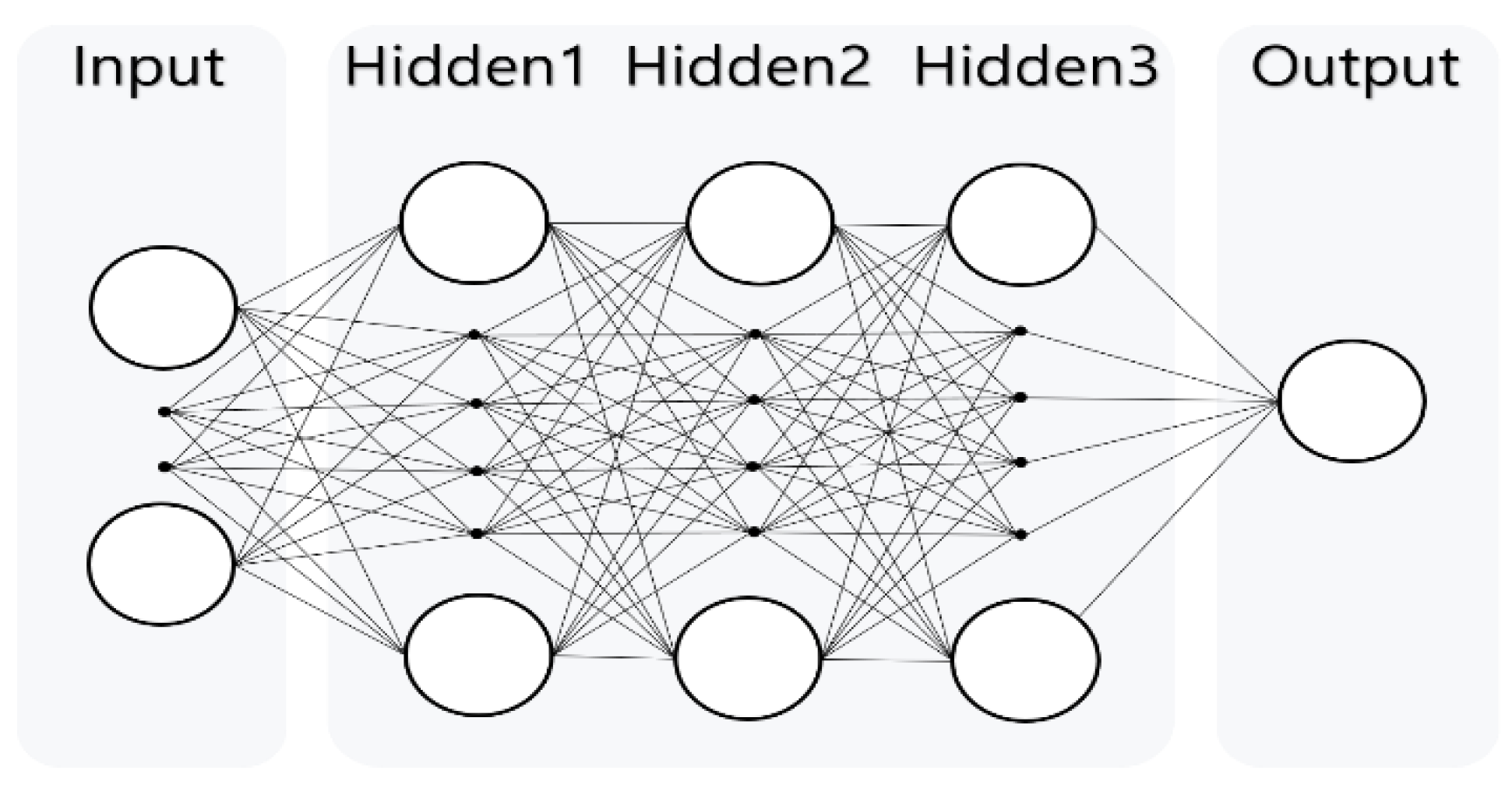
2.2. Analytical Model
2.3. Data
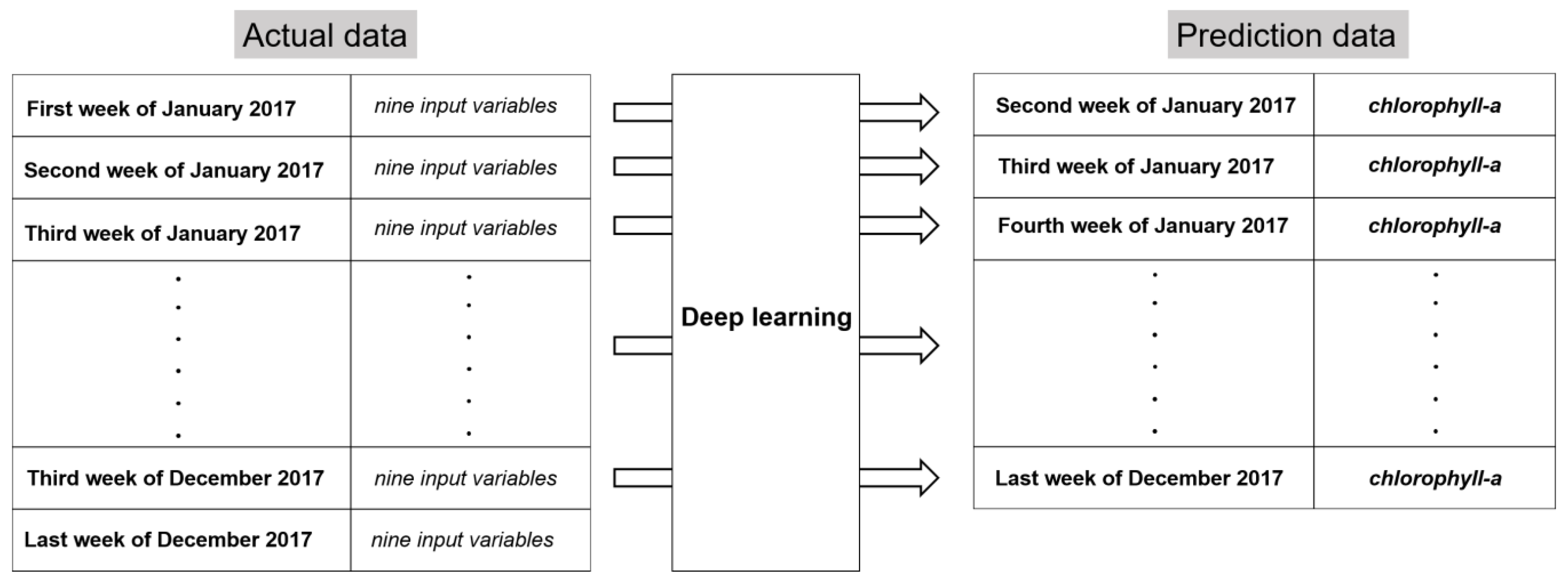
2.3.1. Data preprocessing
2.3.2. Dependent Variable
2.3.3. Control and Independent Variables
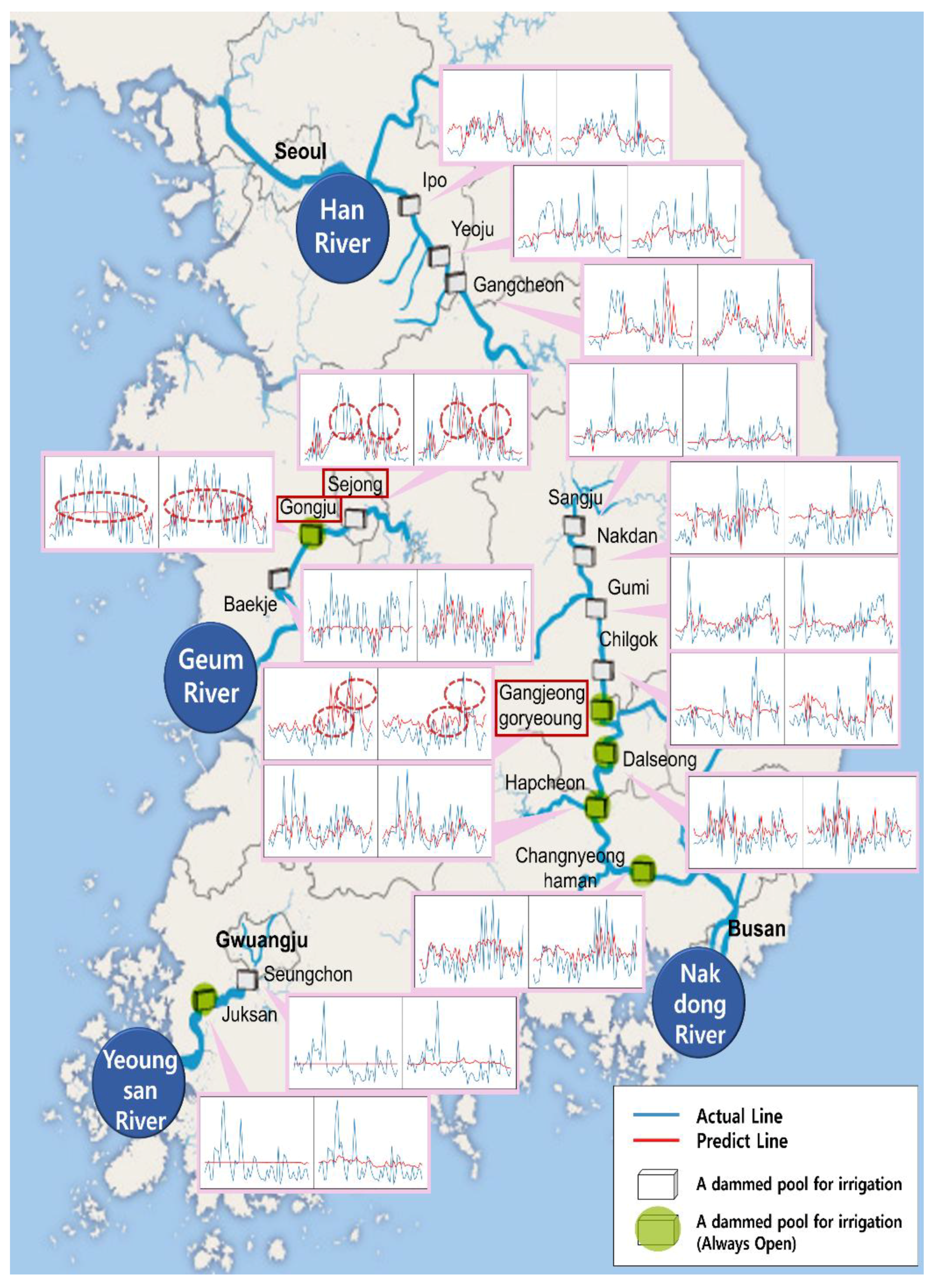
3. Results and Discussion
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Kahru, M.; Mitchell, B.G. Ocean Color Reveals Increased Blooms in Various Parts of the World. EOS 2008, 89, 170. [Google Scholar] [CrossRef]
- Clark, J.M.; Schaeffer, B.A.; Darling, J.A.; Urquhart, E.A.; Johnston, J.M.; Ignatius, A.R.; Myer, M.H.; Loftin, K.A.; Werdell, P.J.; Stumpf, R.P. Satellite monitoring of cyanobacterial harmful algal bloom frequency in recreational waters and drinking water sources. Ecol. Indic. 2017, 80, 84–95. [Google Scholar] [CrossRef]
- Falconer, I.R.; Burch, M.D.; Steffensen, D.A.; Choice, M.; Coverdale, O.R. Toxicity of the blue-green alga (cyanobacterium) Microcystis aeruginosa in drinking water to growing pigs, as an animal model for human injury and risk assessment. Environ. Toxicol. Water Qual. 1994, 9, 131–139. [Google Scholar] [CrossRef]
- Heil, C.A.; Glibert, P.M.; Fan, C. Prorocentrum minimum (Pavillard) Schiller: A review of a harmful algal bloom species of growing worldwide importance. Harmful Algae 2005, 4, 449–470. [Google Scholar] [CrossRef]
- Svendsen, M.B.S.; Andersen, N.R.; Hansen, P.J.; Steffensen, J.F. Effects of Harmful Algal Blooms on Fish: Insights from Prymnesium parvum. Fishes 2018, 3, 11. [Google Scholar] [CrossRef]
- Backer, L.C.; Manassaram-Baptiste, D.; LePrell, R.; Bolton, B. Cyanobacteria and Algae Blooms: Review of Health and Environmental Data from the Harmful Algal Bloom-Related Illness Surveillance System (HABISS) 2007–2011. Toxins 2015, 7, 1048–1064. [Google Scholar] [CrossRef] [PubMed]
- Dodds, W.K.; Bouska, W.W.; Eitzmann, J.L.; Pilger, T.J.; Pitts, K.L.; Riley, A.J.; Schloesser, J.T.; Thornbrugh, D.J. Eutrophication of U.S. Freshwaters: Analysis of Potential Economic Damages. Environ. Sci. Techonol. 2009, 43, 12–19. [Google Scholar] [CrossRef]
- McPartlin, D.A.; Loftus, J.H.; Crawley, A.S.; Silke, J.; Murphy, C.S.; O’Kennedy, R.J. Biosensors for the monitoring of harmful algal blooms. Curr. Opin. Biotechnol. 2017, 43, 164–169. [Google Scholar] [CrossRef] [PubMed]
- Jeong, D.I.; Ryu, D.H.; Na, E.H.; Song, S.H.; Hwang, H.S.; Kim, E.K.; Kim, H.K.; Kim, S.Y. Hydraulic and Water Quality Modelling, 1st ed.; Publication No. 11-1480523-000052-01; Korean National Institute of Environmental Research: Incheon, Korea, 2006.
- McAvoy, D.C.; Masscheleyn, P.; Peng, C.; Morrall, S.W.; Casilla, A.B.; Lim, J.M.U.; Gregorio, E.G. Risk assessment approach for untreated wastewater using the QUAL2E water quality model. Chemosphere 2003, 52, 55–56. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, B.; Johnson, B.E. Integration of a benthic sediment diagenesis module into the two dimensional hydrodynamic and water quality model—CE-QUAL-W2. Ecol. Model. 2015, 297, 213–231. [Google Scholar] [CrossRef]
- Chae, B.; Koo, J.; Lee, S.; Kwon, J.; Kong, S.; Song, G. Development of Prediction Model for Machine Learning Based Algal Bloom; NEAR & Future INSIGHT; National Information Society Agency (NIA): Seoul, Korea, 2017; Volume 4.
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Zhao, M.-R.; Zhou, X.-H.; Xue, Y.; Zheng, Y.-J. Predicting gastrointestinal infection morbidity based on environmental pollutants: Deep learning versus traditional models. Ecol. Indic. 2017, 82, 76–81. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Wua, C.L.; Chau, K.W. Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 399, 394–409. [Google Scholar] [CrossRef]
- Felder, M.; Kaifel, A.; Graves, A. Wind power prediction using mixture density recurrent neural networks. In Proceedings of the European Wind Energy Conference and Exhibition, Warsaw, Poland; 2010; pp. 20–23. [Google Scholar]
- Kim, B.; Choi, K.; Kim, C.; Lee, U.-H.; Kim, Y.-H. Effects of the summer monsoon on the distribution and loading of organic carbon in a deep reservoir, Lake Soyang, Korea. Water Res. 2000, 34, 3495–3504. [Google Scholar] [CrossRef]
- Ha, K.; Cho, E.-A.; Kim, H.-W.; Joo, G.-J. Microcystis bloom formation in the lower Nakdong River, South Korea: Importance of hydrodynamics and nutrient loading. Mar. Freshw. Res. 1999, 50, 89–94. [Google Scholar] [CrossRef]
- Kim, S.-G.; Rhee, S.-K.; Ahn, C.-Y.; Ko, S.-R.; Choi, G.-G.; Bae, J.-W.; Park, Y.-H.; Oh, H.-M. Determination of Cyanobacterial Diversity during Algal Blooms in Daechung Reservoir, Korea, on the Basis of cpcBA Intergenic Spacer Region Analysis. Appl. Environ. Microbiol. 2006, 72, 3252–3258. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. ICANN 1999, 850–855. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Danihelka, I.; Graves, A. Grid Long Short-Term Memory. arXiv, 2016; arXiv:1507.01526. [Google Scholar]
- Anderson, D.M.; Glibert, P.M.; Burkholder, J.M. Harmful algal blooms and eutrophication: Nutrient sources, composition, and consequences. Estuaries 2002, 25, 704–726. [Google Scholar] [CrossRef]
- Paerl, H.W.; Paul, V.J. Climate change: Links to global expansion of harmful cyanobacteria. Water Res. 2012, 46, 1349–1363. [Google Scholar] [CrossRef] [PubMed]
- Paerl, H.W.; Fulton, R.S.; Moisander, P.H.; Dyble, J. Harmful Freshwater Algal Blooms, with an Emphasis on Cyanobacteria. Sci. World J. 2001, 1, 76–113. [Google Scholar] [CrossRef] [PubMed]
- Davis, T.W.; Berry, D.L.; Boyer, G.L.; Gobler, C.J. The effects of temperature and nutrients on the growth and dynamics of toxic and non-toxic strains of Microcystis during cyanobacteria blooms. Harmful Algae 2009, 8, 715–725. [Google Scholar] [CrossRef]
- Ji, D.; Wells, S.A.; Yang, Z.; Liu, D.; Huang, Y.; Ma, J.; Berger, C.J. Impacts of water level rise on algal bloom prevention in the tributary of Three Gorges Reservoir, China. Ecol. Eng. 2017, 98, 70–81. [Google Scholar] [CrossRef]
- AMichalak, M.; Anderson, E.J.; Beletsky, D.; Boland, S.; Bosch, N.S.; Bridgeman, T.B.; Chaffin, J.D.; Cho, K.; Confesor, R.; Daloğlu, I.; et al. Record-setting algal bloom in Lake Erie caused by agricultural and meteorological trends consistent with expected future conditions. PNAS 2013, 110, 6448–6452. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Zhang, H.; Zhu, Y.; Xiao, Y.; Chen, L. Effect of flow velocity on phytoplankton biomass and composition in a freshwater lake. Sci. Total Environ. 2013, 447, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Boyer, J.N.; Kelble, C.R.; Ortner, P.B.; Rudnick, D.T. Phytoplankton bloom status: Chlorophyll a biomass as an indicator of water quality condition in the southern estuaries of Florida, USA. Ecol. Indic. 2009, 9, 56–67. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.; Liu, L.; Fan, Y.; Li, L.; Yang, Y.; Lu, Z.; Zhang, X. Annual periodicity in planktonic bacterial and archaeal community composition of eutrophic Lake Taihu. Sci. Rep. 2015, 5, 15488. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Gao, Y.; Xu, Z.; Xu, W. Elman’s Recurrent Neural Network Applied to Forecasting the Quality of Water Diversion in the Water Source of Lake Taihu. Energy Procedia 2011, 11, 2139–2147. [Google Scholar] [CrossRef]
- Meloun, M.; Militký, J. Detection of single influential points in OLS regression model building. Anal. Chim. Acta 2001, 439, 169–191. [Google Scholar] [CrossRef]
- Paerl, H.W.; Xu, H.; McCarthy, M.J.; Zhu, G.; Qin, B.; Li, Y.; Gardner, W.S. Controlling harmful cyanobacterial blooms in a hyper-eutrophic lake (Lake Taihu, China): The need for a dual nutrient (N & P) management strategy. Water Res. 2011, 45, 1973–1983. [Google Scholar] [CrossRef] [PubMed]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Olyaie, E.; Banejad, H.; Chau, K.-W.; Melesse, A.M. A comparison of various artificial intelligence approaches performance for estimating suspended sediment load of river systems: A case study in United States. Environ. Monit. Assess. 2015, 187, 189. [Google Scholar] [CrossRef] [PubMed]
- Taormina, R.; Chau, K.-W.; Sivakumar, B. Neural network river forecasting through baseflow separation and binary-coded swarm optimization. J. Hydrol. 2015, 529, 1788–1797. [Google Scholar] [CrossRef]
- Koskela, T.; Lehtokangas, M.; Saarinen, J.; Kaski, K. Time Series Prediction with Multilayer Perceptron, FIR and Elman Neural Networks. In Proceedings of the World Congress on Neural Networks, San Diego, CA, USA, 15–16 September 1996. [Google Scholar]
- Goh, A.T.C. Back-propagation neural networks for modeling complex systems. Artif. Intell. Eng. 1995, 9, 143–151. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J.L. ADAM: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Phu, S.T.P. Research on the Correlation between Chlorophyll-a and Organic Matter BOD, COD, Phosphorus, and Total Nitrogen in Stagnant Lake Basins. Sustain. Living Environ. Risks 2014, 177–191. [Google Scholar] [CrossRef]
- Kumar, A.; Dhall, P.; Kumar, R. Redefining BOD: COD ratio of pulp mill industrial wastewaters in BOD analysis by formulating a specific microbial seed. Int. Biodeterior. Biodegrad. 2010, 64, 197–202. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Variable Description | Source | Number of Data | Average | Standard Deviation | Minimum Value | Maximum Value |
|---|---|---|---|---|---|---|---|
| temperature | water temperature (°C) | Ministry of Environment | 4464 | 17.40 | 8.16 | 0.30 | 34.30 |
| pH | potential of hydrogen | 4464 | 8.00 | 0.54 | 5.70 | 9.70 | |
| DO | dissolved oxygen (mg/L) | 4464 | 10.70 | 2.66 | 2.20 | 19.20 | |
| BOD | biochemical oxygen demand (mg/L) | 4464 | 2.00 | 1.26 | 0.30 | 9.60 | |
| COD | chemical oxygen demand (mg/L) | 4464 | 5.80 | 1.82 | 1.80 | 19.50 | |
| cyanobacteria | cyanobacteria cell number | 4464 | 4041 | 20,695 | 0 | 556,740 | |
| chlorophyll | chlorophyll-a | 4464 | 23.76 | 23.15 | 0.10 | 177.90 | |
| water level | water level (el.m) | Ministry of Land, Infrastructure and Transport | 4464 | 19.49 | 13.78 | 1.50 | 47.52 |
| pondage | pondage (million m3) | 4464 | 43.67 | 30.64 | 4.829 | 205.58 |
| Variable Name | Coefficient | Standard Error | p > t |
|---|---|---|---|
| temperature | 3.262 × 10−1 | 5.918 × 10−2 | 3.74 × 10−8 *** |
| pH | 3.218 × 10−1 | 6.706 × 10−1 | 6.31 × 10−1 |
| DO | 1.466 | 1.912 × 10−1 | 2.13 × 10−14 *** |
| BOD | 2.222 | 3.455 × 10−1 | 1.39 × 10−10 *** |
| COD | 2.580 | 2.635 × 10−1 | 2 × 10−16 *** |
| cyanobacteria | −6.105 × 10−5 | 1.46 × 10−5 | 2.93 × 10−5 *** |
| water level | −4.891 × 10−1 | 2.85 × 10−2 | 2 × 10−16 *** |
| pondage | −1.260 × 10−1 | 1.076 × 10−2 | 2 × 10−6 *** |
| _cons | −4.18 | 4.692 | 3.73 × 10−1 |
| p > F | 2.2 × 10−16 | ||
| R2 | 0.3032 | ||
| adjusted R2 | 0.302 | ||
| number of observations | 4464 |
| Measuring Point | MLP | LSTM | ||||||
|---|---|---|---|---|---|---|---|---|
| Epoch | 100 | 300 | 500 | 700 | 100 | 300 | 500 | 700 |
| Ipo | 7.84871 | 8.42762 | 9.2777 | 10.7004 | 7.67382 | 8.31658 | 8.73067 | 9.06951 |
| Yeoju | 5.49547 | 5.6166 | 6.07492 | 4.49033 | 5.61138 | 5.73774 | 5.81824 | 6.13268 |
| Gangcheon | 3.64954 | 3.99566 | 4.431429 | 35.5032 | 3.60946 | 3.83244 | 3.86594 | 3.86588 |
| Sejong | 39.6119 | 35.9101 | 33.4814 | 10.3041 | 30.8273 | 31.0018 | 30.9622 | 31.7447 |
| Gongju | 42.7369 | 35.3198 | 33.7732 | 12.2273 | 31.9164 | 31.9498 | 32.1146 | 33.1228 |
| Baekje | 36.477 | 27.7607 | 26.5994 | 12.7383 | 27.3673 | 27.1477 | 27.1138 | 27.0187 |
| Sangju | 14.7071 | 14.0804 | 14.0761 | 26.0294 | 14.4853 | 14.4771 | 14.2902 | 14.1571 |
| Nakdan | 9.96028 | 10.4088 | 10.5436 | 14.0869 | 9.84722 | 9.50639 | 10.137 | 10.0699 |
| Gumi | 11.0802 | 10.2963 | 10.1364 | 32.6677 | 10.5159 | 10.2251 | 10.0779 | 10.2275 |
| Chilgok | 10.3898 | 10.2936 | 9.80221 | 29.1884 | 11.0027 | 10.5753 | 10.2638 | 10.204 |
| Gangjeong goryeoung | 9.2862 | 8.20598 | 9.2837 | 5.8793 | 7.85588 | 8.00324 | 8.78411 | 8.99846 |
| Dalseong | 10.2755 | 11.3021 | 11.7977 | 9.91085 | 12.6251 | 12.7122 | 13.1197 | 13.4175 |
| Hapcheon | 15.0435 | 13.9717 | 13.9468 | 27.4545 | 14.1113 | 13.9893 | 14.1398 | 13.9613 |
| Changnyeong haman | 12.1064 | 12.2411 | 12.0053 | 12.288 | 13.2302 | 12.6724 | 12.501 | 12.416 |
| Seungchon | 36.0572 | 29.4183 | 29.0971 | 9.44017 | 30.4663 | 36.1613 | 37.7719 | 40.2004 |
| Juksan | 29.7646 | 28.017 | 28.4197 | 14.114 | 26.3498 | 26.865 | 26.9653 | 26.7871 |
| Sum of RMSE | 294.4903 | 265.2658 | 262.7467 | 267.0229 | 257.4954 | 263.1734 | 266.6562 | 271.3935 |
| Measuring Point | OLS | MLP | RNN | LSTM |
|---|---|---|---|---|
| Ipo | 13.21 | 9.28 | 7.93 | 7.67 |
| Yeoju | 9.13 | 6.07 | 5.60 | 5.61 |
| Gangcheon | 6.50 | 4.43 | 3.58 | 3.61 |
| Sejong | 29.78 | 33.48 | 30.42 | 30.83 |
| Gongju | 32.30 | 33.77 | 32.08 | 31.92 |
| Baekje | 25.30 | 26.60 | 25.95 | 27.37 |
| Sangju | 10.18 | 14.08 | 14.37 | 14.49 |
| Nakdan | 11.88 | 10.54 | 9.34 | 9.85 |
| Gumi | 13.32 | 10.14 | 10.26 | 10.52 |
| Chilgok | 11.82 | 9.80 | 10.55 | 11.00 |
| Gangjeong goryeoung | 10.02 | 9.28 | 8.11 | 7.86 |
| Dalseong | 19.63 | 11.80 | 13.24 | 12.63 |
| Hapcheon | 14.87 | 13.95 | 14.35 | 14.11 |
| Changnyeong haman | 19.40 | 12.01 | 12.83 | 13.23 |
| Seungchon | 34.24 | 29.10 | 33.25 | 30.47 |
| Juksan | 22.44 | 28.42 | 26.22 | 26.35 |
| RMSE average | 17.75 | 16.42 | 16.13 | 16.09 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Lee, D. Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. Int. J. Environ. Res. Public Health 2018, 15, 1322. https://doi.org/10.3390/ijerph15071322
Lee S, Lee D. Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. International Journal of Environmental Research and Public Health. 2018; 15(7):1322. https://doi.org/10.3390/ijerph15071322
Chicago/Turabian StyleLee, Sangmok, and Donghyun Lee. 2018. "Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models" International Journal of Environmental Research and Public Health 15, no. 7: 1322. https://doi.org/10.3390/ijerph15071322
APA StyleLee, S., & Lee, D. (2018). Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. International Journal of Environmental Research and Public Health, 15(7), 1322. https://doi.org/10.3390/ijerph15071322