1. Introduction
Air is a basic requirement for the survival and development of all lives on Earth. It affects health and influences the development of the economy. Today, due to the development of industrialization, the increase in the number of private cars, and the burning of fossil fuels, air quality is decreasing, with increasingly serious air pollution. There are many pollutants in the atmosphere, such as SO2, NO2, CO2, NO, CO, NOx, PM2.5, and PM10. Internationally, a large number of scholars have conducted research on air pollution and air quality forecasts, concentrating on the forecasting of contaminants.
Air pollution affects the life of a society, and even endangers the survival of mankind. During the Industrial Revolution, there was a dramatic increase in coal use by factories and households, and the smog caused significant morbidity and mortality, particularly when combined with stagnant atmospheric conditions. During the Great London Smog of 1952, heavy pollution for 5 days caused at least 4000 deaths [
1,
2]. This episode highlighted the relationship between air pollution and human health, yet air pollution continues to be a growing problem in cities and households around the world.
Air pollution is made up of a mixture of gases and particles in harmful amounts that are released into the atmosphere due to either natural or human activities [
3]. The sources of pollutants can be divided into two categories:
(1) Natural sources
Natural pollution sources are natural phenomena that discharge harmful substances or have harmful effects on the environment. Natural phenomena, such as volcanic eruptions and forest fires, will result in air pollutants, including SO2, CO2, NO2, CO, and sulfate.
(2) Anthropogenic (man-made) sources
Man-made sources such as the burning of fuels, discharges from industrial production processes, and transportation emissions are the main sources of air pollution. There are many kinds of pollutants emitted by man-made pollution sources, including hydrogen, oxygen, nitrogen, sulfur, metal compounds, and particulate matter.
With the increasing world population and the developing world economy, the demand for energy in the world has increased dramatically. The large-scale use of fossil energy globally has also led to a series of environmental problems that have received much attention due to their detrimental effects on human health and the environment [
3,
4,
5]. Air pollution is a fundamental problem in many parts of the world, with two important concerns: the impact on human health, such as cardiovascular diseases, and the impact on the environment, such as acid rain, climate change, and global warming [
6]. These environmental impacts are described below.
(1) Climate change
Some chemicals released into the atmosphere by human activities, such as CO
2, CH
4, N
2O, and chlorofluorocarbons (CFCs, exemplified byFreon-12), cause a greenhouse effect [
7,
8]. The burning of fossil fuels and other human activities increase the concentration of greenhouse gases, leading to global warming. This also leads to a rise in sea level, more extreme weather, and melting glaciers and ice caps. More alterations to the environment are inevitable as temperatures continue to climb [
7].
The studies have indicated that the rate of sea level increase was the fastest in the twentieth century, and data have proven this point of view. The sea level has risen 14 cm in the twentieth century. A study shows that the sea level will rise by 28 cm and is expected to reach a total of 131 cm in 2100 [
3,
7,
9], while average global temperature will increase by 3.6 °F to 8.1 °F (2 °C to 4.5 °C) [
7].
(2) Ozone Hole
The ozone layer is a relatively high level concentration of ozone in the stratosphere, and its main function is to absorb ultraviolet radiation. It has many useful functions for Earth, and the most important of those functions is to protect human beings, animals, and plants from short wave ultraviolet radiation [
10]. It also protects against the heating effect, as ozone absorbs the Sun’s ultraviolet rays and converts it to heat energy that heats the atmosphere [
11].
Freon, a halohydrocarbon, and N
2O can produce the greenhouse effect and can also react with stratospheric ozone, resulting in the depletion of the ozone layer and creation of holes in the ozone layer [
10,
12].
The decline of the stratospheric ozone level from anthropogenic source is internationally recognized as one of the Earth’s most important environmental issues [
13]. The ozone hole is affecting human health and the environment negatively and can cause severe diseases, such as skin cancer, eye damage, and genetic mutations [
10,
12]. Research results show that if stratospheric ozone concentrations decreased by 1%, the amount of ultraviolet radiation will be increased by 2%, and the cataract rate will increase 0.2–0.6%. Moreover, the depletion of the ozone layer seriously harms the human body, crops, and forests, even destroying natural biosphere generation and the marine ecological balance [
12].
In recent years, scientists discovered that the phenomenon of ozone reduction occurs in both the Antarctic and Arctic [
11]. In the spring of 2011, ozone column loss had reached 40%. According to the observations of Chinese atmospheric physics and meteorology over the Qinghai-Tibetan Plateau, the ozone layer is being reduced at a rate of 2.7% per 10 years.
(3) Particulate matter pollution
Atmospheric particulate matter consists of solid or liquid granular substances in the atmosphere. Thick smog along with particulate matter (PM) occurs and covers most cities of world frequently [
4]. According to medical research, PM causes different degrees of harm to human respiratory, cardiovascular, and central nervous, and immune systems and to genes [
14,
15].
China, as the largest developing country, has attracted great attention from all over the world for its rapid economic development and its air pollution. In 2015, China’s air pollution situation was very serious with most cities’ air quality exceeding the China National Standard. Moreover, some cities in China have been selected as the 10 most polluted cities in the world [
16]. In recent years in China, high concentrations of particulate matter have received increasing attention [
17].
Generally, air pollutants do not just harm the local or regional environment. They can also cause damage on a global scale. Certain man-made chemicals have damaged the planet’s protective ozone layer, allowing more harmful solar radiation to strike the Earth’s surface. Although the use of these chemicals is being phased out, their destructive effects will linger for many more decades.
Control of air pollution and improving air quality are presently concern of scientists globally [
18]. As one of the important results of urban air pollution control, urban air pollution forecasting has established an urban air pollution alarm system, effectively reducing the cost of air pollution control. The establishment of a reasonable and accurate forecasting model is the basis for forecasting urban air pollution. Forecasting is a requisite part of in the science of big data and can be used to infer the future development of an object relative to previous information. So “pollution forecasting” can be understood as estimation of pollutant concentration at specified future date.
Since the 1960s, with the development of air pollution control and research, it has become urgent for people to understand the influence of air pollution and the trends of pollution. Therefore, forecasting air pollution began. Forecasting pollution using different patterns of performance can be divided into three types: potential forecasts, statistical models, and numerical models. For different elements, it is divided into pollution potential forecasting and concentration forecasting [
19]. Statistical methods and numerical modelling methods result in concentration forecasts. A potential forecast is mainly based on the meteorological conditions for atmospheric dilution and diffusion capacity. When the weather conditions are expected to be in line with the standards for possible serious pollution, a warning will be issued. A concentration forecast will forecast the concentration of pollutants in a certain area directly, and the forecast results are quantitative. These air pollutions forecasting models can be divided into parametric and nonparametric models, or deterministic and nondeterministic models. It is easy to distinguish the parametric models from nonparametric models, and deterministic models from nondeterministic models, but it is difficult to differentiate the parametric models from deterministic models. The most significant difference between parametric models and deterministic models is that for a deterministic model, the output can be determined, as long as inputs are fixed, regardless of the number of trials; while the parametric model is to determine the parameters of equations in the known model, and its output is uncertain. For example, the diffusion models in this paper belong to the deterministic model, and they are based on physical equations, driven by the chemistry and the transport of pollutants, requiring many accurate input data [
20]; models based on large amounts of historical data, such as regression, principal component analysis, etc., are usually parametric models.
The most popular statistical method uses artificial intelligence (AI) models. The accuracy of neural network (NN) forecasting models is higher than that of other statistical models [
21,
22,
23], but they should be improved. Therefore, some scholars have been improving the forecast accuracy by other methods. Grivas et al. developed an artificial neural network (ANN) that combined meteorological and time-scale input variables [
22]. Elangasinghe et al. built an ANN air pollution forecast tool based on meteorological parameters and the emission pattern of sources [
23]. The improved ANN models were found to be more effective based on the same input parameters [
24,
25,
26].
A commonly used numerical model is the Community Multi-scale Air Quality (CMAQ) modeling system. Since the 1970s, three generations of CMAQ models have been developed. Lou et al. used the CMAQ modeling system to analyze and evaluate air pollutant ozone concentrations in China and proposed that this method could be applied to other oxides of nitrogen [
27].
Up to now, a large number methodologies and approaches have been proposed for air pollution forecasting but no comparison of these methods in the accuracy of forecast have been made. In the present paper, we have discussed various approaches and given statistical analysis to find out an accurate method.
Figure 1 shows the plan of the study.
2. The Current Status of Pollution Research
Air pollution is regarded as an unavoidable reality. Over the past few years, much news about environmental pollution accidents have been reported, especially air pollution events. If the environmental problems are ignored in process of social progress, the ecological environment of the earth will gradually deteriorate, so the Earth is always in danger and every day will be “2012”. It is well-known that, compared with land pollution and water pollution, the consequences of air pollution are more serious. Scholars have conducted a series of studies on air pollution, from pollution sources to pollution management and pollution forecasts, including the problem of emissions inventories, pollution assessments, and pollution alarms. These topics lay the foundation for the research into air pollution covered in the following sections.
2.1. The Current Status of Pollution Emission Inventory Research
In the words of Seika, the emission inventory (EI) is a comprehensive list of various types of air pollutants emitted by various sources of pollution in a given area within a given time interval [
28]. EIs provide a description of the polluting activities that occur across a specific geographic domain and are widely used as input for air quality modeling for the assessment of compliance with environmental legislation [
29]. Air pollution control requires complex environmental management, in which clear EIs are the basis for other research.
United States Environmental Protection Agency (EPA) developed an emission inventory improvement program (EIIP) in 1993. This program promoted the development and usage of collection, storage, reporting, sharing and other standardization process of data. The EIIP documents were designed to provide standardized approaches for emission estimation, the emission estimates formula is as follows [
30]:
For point sources, activity levels represent the operating rate of the facility, estimated at the facility level. For area sources, replacing emissions with some other variable, such as population count in a region, is used as an activity level. The correlates between surrogate activity factor and the emission rate for the source determine the quality of the estimates. The emission factor is the value of the amount of pollutants released into the atmosphere per unit activity associated with the release of the contaminant. And the level of control is equal to the amount controlled, one minus the level of control is represents the amount emitted after control [
30].
2.2. The Health Effect of Pollution
Exposure to air pollution has been clearly associated with a range of adverse health effects. A report from the OECD indicated that outdoor air pollution could cost the world
$2.6 trillion a year, by 2060, which includes the cost of sick days, medical bills and reduced agricultural output. Moreover, welfare costs associated with premature death by 2060 will rise to as much as
$25 trillion [
31]. Lafuente et al. performed a systematic review to assess the effects of air pollutants on sperm quality [
32]. They set up four semen quality parameters, including DNA fragmentation, sperm count, sperm motility, and sperm morphology. Most studies concluded that air pollution impacted at least one of the four semen quality parameters included in the review.
Wei et al. studied the effects of ambient NO
2, SO
2, and PM
10 on childhood eczema in Shanghai, China. They selected 3358 preschool children for their 6-year research program. This study indicated that gestational and lifetime exposures to NO
2 were risk factors for atopic eczema in childhood; moreover, exposure to SO
2, and PM
10 may enhance the effect of NO
2 exposure on childhood eczema [
33].
Beelen et al. developed a multi-center cohort study for Europe. The results indicated that the risk of natural mortality was significantly increased when exposed to PM
2.5 for a long time [
34]. The study showed that there is a positive correlation between PM
2.5 and heart disease mortality. In addition, as the PM
2.5 concentration increased, the mortality rate of patients with heart disease increased.
Various studies have testified that air pollution is harmful to human and other kind of creatures, and lead to varies diseases and loss, such as respiratory disease, cardiovascular disease, Death of animals and plants and economic losses.
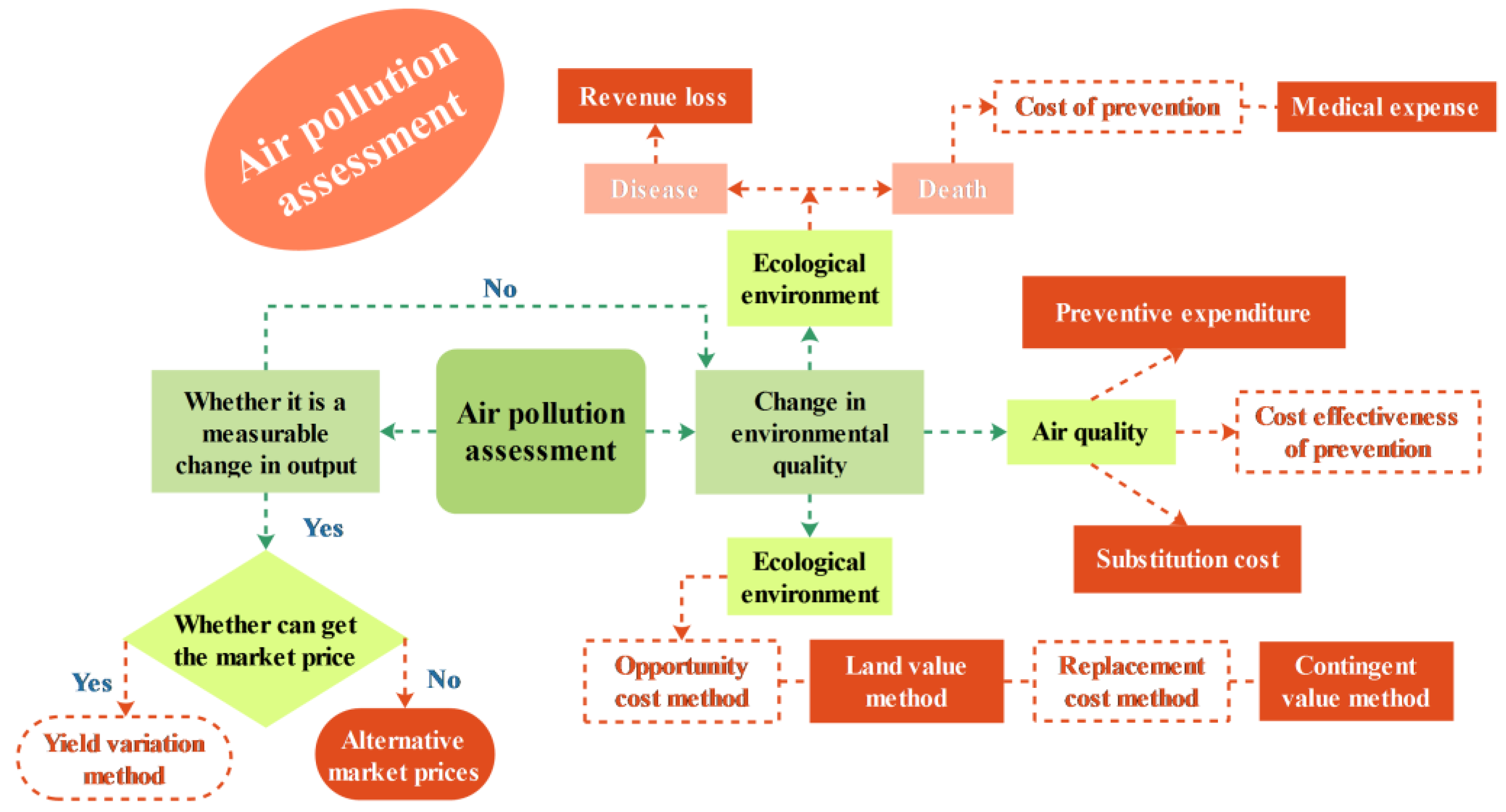
2.3. Air Pollution Assessment
In recent years, air pollution accidents have occurred frequently, which have damaged the economy and human life. To assess the extent of the damage, air pollution control must be evaluated in order to have a quantitative understanding of pollution.
The assessment of air pollution is identify and measure the degree and scope of damage caused by environmental pollution cover the economic, legal, technical and other means reasonably [
35,
36,
37].
Two of the more mature assessment methods will be described. The market value method is a type of cost benefit analysis method. It uses the change of product yield and profit caused by the environmental quality change to measure the economic loss related to the environmental quality change.
Environmental pollution and damage caused by air pollution can be prevented, restored, or replaced by the existing environmental functions. Therefore, the cost of preventing, restoring, or replacing the original functional protection facilities can be used to estimate the loss caused by pollution or damage to the environment. This method is called the engineering cost method.
The main equation and the meaning of the variables in those methods are given in
Table 1, and the flowchart of the assessment methods is given in
Figure 2.
2.4. Study of Air Pollution Control Efficienc
In order to solve increasingly serious environmental pollution problems, many countries have introduced policies to control pollution. In addition, the United Nations has organized international conferences, appealing to all countries to jointly manage global pollution. So, are these pollution control methods effective? The efficiency of environmental pollution control is the input and output efficiency in the process of environmental pollution control, reflecting the input of environmental pollution control and its pollution control effect.
Larsson et al. calculated air pollution control efficiency of the different enterprises in Norway [
38]. They examined the effect of both technical efficiency and environmental efficiency. The governance efficiency of SO
2 in each province of China was calculated by Shi et al. using the data envelopment analysis (DEA) method [
39]. Wang et al. used a super efficiency DEA model to analyze the atmospheric pollution governance efficiency in various provinces of China from 2004 to 2009 [
40]. Xie et al. studied Beijing and built an odd-and-even license plate model by a probabilistic modeling method and the analysis of means to quantify the pollution caused by vehicle exhaust emissions and the actual effect of the license plate limitation rule [
41]. Fan et al. indicated that the rate of industrial waste gas governance is low, and there are significant differences in the governance efficiency of different pollutants [
42]. Moreover, the Fan et al. research on China’s industrial air pollution control showed that, in different sectors, the air pollution treatment efficiency and its contributions from efficiency change and technology change differ significantly, and the contribution of technology advancement to the efficiency of industrial air pollution treatment are weak [
43].
Remark 1. There is much air pollution control efficiency research for different industries and different pollutants, and the main result of that research is to take pollution management related costs as input variables and pollutant emission reductions as output variables and use a DEA model to calculate pollution abatement efficiency.
2.5. Air Pollution Early Warning and Forecast
The most important function of air pollution early warning systems is to report the air quality to relevant departments when the air quality reaches the early warning standard. A complete pollution warning system includes the pollutant, resource, and scope of influence [
44].
Air quality forecasting is an effective way of protecting public health by providing an early warning against harmful air pollutants [
9]. Urban air pollution events can be forecasted by meteorological elements to provide an early warning. Therefore, in the face of more and more urban air pollution incidents, in addition to risk prevention management and emergency measures, air pollution forecasts should also include the emergency warnings as an important part of the whole emergency system.
The early warning system for air pollution is triggered before the heavy pollution of urban air, according to the forecast of meteorological elements. Corresponding emergency measures are initiated as early as possible to reduce the discharge of pollutants and mitigate the consequences. Many countries have early warning systems for pollution. For example, the Air Quality Index (AQI) value is an index for the classification of the early warning level in China, and the early warning level is determined according to the upper limit of the pollution forecast. Therefore, the forecasting of air pollution as the basis for pollution warning systems and pollution control should be highly valued by all countries.
In China, Tang believed that air pollution is different from water pollution, because serious pollution incidents may occur in a short time, if the weather situation is not conducive to the spread of pollutants [
45]. However, Hong et al. showed that the potential forecast only forecasts the weather conditions of air pollution, and this method failed to give exact quantitative results for air pollution. Therefore, they developed a numerical forecasting method [
46].
Among these various methods, there is a classic forecasting method used to forecast air pollution quantitatively, namely the AI method. Grivas et al. developed an Artificial Neural Network (ANN) combined with meteorological and time-scale input variables [
22]. The input variables were selected by using a genetic algorithm optimization procedure.
In addition, the hybrid model also developed and performed well, and widely used in various fields [
47,
48,
49]. Güler Dincer et al. established a new Fuzzy Time Series model based on the Fuzzy K-Medoid clustering algorithm to forecast the concentration of SO
2 in Turkey [
50]. Wang et al. proposed a novel hybrid model, called Complementary Ensemble Empirical Mode Decomposition, Biogeography-Based Optimization based on Differential Evolution, and Linear Least Squares Support Vector Machine (CEEMD-BBODE-LSSVM), for air pollution point and interval forecasting [
51]. Xu et al. proposed a robust early warning system that includes an evaluation module, forecasting module, and characteristics estimation module. This system defines the air quality levels and is also used to determine the main pollutants [
52].
In the following sections, a thorough analysis and summary of the forecasting of air pollution will be provided. The structure of the second section is clearly summarized in
Figure 3.
5. Statistical Forecast Methods
Statistical forecast methods analyze the events without knowing the mechanism of the change; therefore, this method is not dependent on physical, chemical, or biological processes. Statistical forecasts include parametric and non-parametric statistical methods [
54]. Parametric models are traditional statistical models such as linear regression and principal component analysis; nonparametric models have no defined function form. Generally, nonparametric regression includes neural network models, Gaussian process regression etc., a detailed review of the application of statistical prediction models was published in [
55].
5.1. Regression Methods
Regression analysis is a statistical tool that investigates relationships between variables. Usually, the researchers seek to ascertain the causal effect of independent variables
Y upon dependent variables
xi [
56]. When we use the model to forecast y for a particular set of values of
xi, we want to measure how large the error of the forecast might be. All these elements, including dependent and independent variables and error, are part of a regression analysis, and the resulting forecast equation is often called a regression model [
57]. Regression analysis is a basic technique in air pollution forecasting.
Linear regression plays a strictly utilitarian role in the field of statistical methods. Its expression is as follows:
A multiple-linear regression (MLR) model is given as:
or:
where
Y is the dependent variable,
x and
xi are the independent variables,
b and
bi are the regression coefficients, and
e is the error. It has a normal distribution with a mean of 0.
For air pollution forecasting,
Y represents the pollutant concentration forecast at time
t + 1,
xi represents the pollutant concentrations and meteorological variables at time
t,
bi are the regression coefficients, and
e is an estimated error term obtained from independent random sampling. The values of
bi can be obtained by using a least squares error technique [
58].
Nonlinear regression analysis is an extension of the linear regression analysis, as well as the structural model of a traditional econometric analysis. In the social reality of economic life, many relationships between the analysis and forecast are generally used in nonlinear regression methods instead of a linear relationship.
In the classical regression analysis, solving the nonlinear regression problem requires the conversion of variables to a linear relationship and the use of linear regression theory to determine the regression coefficients [
59]. This method has been widely used for many years in practice.
General nonlinear regression models can be written in the following form [
59]:
For some special nonlinear relationships, variable transformations can be used to convert the nonlinear relationship into a linear one. The nonlinear equation can be transformed into a linear equation using the categories shown in
Table 4.
Cortina-Januchs et al. used the cluster algorithm to find relationships between PM
10 and meteorological variables and then used multilayer regression to forecast the concentration of PM
10. The results show that meteorological variables are important in air pollution forecasting [
60].
Remark 2. It should be noticed that there are many hypotheses for different regressions; and if any hypothesis is violated, the resulting estimate is biased. Therefore, the availability of regression methods should be taken into full consideration in solving exact problems. Moreover, in order to improve the prediction accuracy of regression equations, researchers often increase the variables in the regression equation. However, the increase of independent variables will increase the calculations. The regression process becomes longer, and the prediction problems and control problems become complicated. Therefore, the main problem of the regression model is to choose the variables for the regression equation. This requires significant experimental investigation.
5.2. ARIMA Methods
The autoregressive integrated moving average (ARIMA) model is a linear model that can show steady state in both stationary and non-stationary time series. When constructing the ARIMA model, there are three main steps (Rahman et al. [
21]):
Step 1. Tentative identification
Step 2. Parameter estimation
Step 3. Diagnostic checking
ARIMA with a seasonal difference is called SARIMA. SARIMA processes the data with a seasonal period length
S; and if
d and
D are non-negative integers, the difference series,
Wt = (1 −
B)d(1 −
B5)
Dxi, is a stationary autoregressive moving average process [
61]. The SARIMA model can be written as:
where
N is the number of observations up to time
t;
B is the backshift operator defined by
BαWt =
Wt−α;
ϕp(B) = 1 −
ϕ1B − … − ϕpBp is called a regular (non-seasonal) autoregressive operator of order
p;
ϕp(B
s) = 1 −
ϕ1Bs −
… −
ϕpBps is a seasonal autoregressive operator of order
p;
θq(B) = 1 −
θ1B −
… −
θqBq is a regular moving average operator of order
q; Θ
Q(B
S) = 1 − Θ
1BS −
… − Θ
QBQS is a seasonal moving average operator of order
Q;
εt is identically and independently distributed as normal random variables with mean zero, variance
α2 and cov(
εt,
εt−k) = 0, ∀k ≠ 0 [
61].
In the definition above,
p represents the autoregressive term;
q is moving average order;
P represents the seasonal period length of the model,
S, of the autoregressive term;
Q represents the seasonal period length of the model,
S, of moving average order;
D represents the order of seasonal differencing; and
d represents the order of ordinary differencing [
61].
When fitting a SARIMA model to data, the estimation of the values of
d and
D is primary, with the orders of differencing needed to make the series stationary and to remove most of the seasonality. The values of
p,
q and
Q need to be estimated by the autocorrelation function (ACF) and partial autocorrelation function (PACF) of the differenced series and other parameters can be estimated by suitable iterative procedures [
61].
Rahman et al. (2015) forecasted the API from three different stations [
21]. The forecasting accuracy of the possible SARIMA model is shown in
Table 5.
In this study, the authors contrasted the result of SARIMA and a fuzzy time series (FTS) model. According to the result, the conventional ARIMA model outperformed the FTS model in two urban areas and the FTS only perform better in a sub-urban area.
Remark 3. The ARIMA model requires time series data to be stable or stable after differentiation. Moreover, the ARIMA model can only describe the linear relationship between variables to model and predict and cannot describe the nonlinear relationship between variables. However, pollution data are complex and combine geography, weather, and other factors to make data unstable and nonlinear, so the data should be processed into a stable and linear format before forecasting by ARIMA. If the data cannot be processed into stable and linear, other forecasting models should be chosen.
5.3. Projection Pursuit Model (PP)
This method was developed in the 1970s. The main idea of air pollution forecasting statistical methods is to be a “supposition-simulation-forecast”, so those methods are not suitable for analyzing the data of nonlinear relationships or non-normal distributions. In contrast, the projection pursuit (PP) technique presents a new method of exploratory data analysis of “review of data-simulation-forecast”, which can be used to a certain extent in some nonlinear problems [
62]. The main idea of projection pursuit is to machine-pick low dimensional projections of high dimensional point cloud by numerically maximizing a certain objective function or projection index [
63].
The general form of an order
K PP autoregression model is as follows:
where Z
m is the estimated value of time series {
x} at
t time;
xi represents
K time series forecast factors, its selection is ultimately determined by the data structure;
am represents the projection direction for the
mth content, it satisfies
;
Gm is the optimal piecewise linear function of Z
m, called ridge function. It is a numerical function;
βm is the weight coefficients of the contribution of the
mth ridge function to
Xt.
The optimization process of the final model can be divided into two steps [
6]:
Step 1. Local optimization process
The highest linear combination of M and the optimal parameters αm and βm, and the ridge functions Gm are determined by the stepwise alternating optimization method.
Step 2. Global optimization process
In order to find a better model, the linear combination of M and the number of parameters were optimized further, eliminating the unimportant items in the model one by one. The model number decreased to Mu,Mu−1,L,1, determined the number for M, and found the best solution of the minimum M.
Deng et al. (1997) used PP regression to forecast SO
2 concentration based on historic data [
62].
At first, standardizing SO
2 concentration data according to Equation (9):
The range of
values is listed in
Table 6:
Sample test results are shown in
Table 7.
The authors defined that when the absolute relative errors were less than 20%, the result was qualified; therefore, in their study, the forecast accuracy of the sample was 75%.
Remark 4. The PP method overcomes the difficulties of the “dimensionless curse” caused by high dimensional distribution and has the advantages of assumption, objective, robustness, anti-interference, accuracy, wide applicability, and rapid modeling. It can adapt to the form of flexible development requirements. For different research objects, it can use various forms of the model based on this method. Therefore, a series of methods, such as the PP regression and PP clustering methods, have been derived. However, this method also has many disadvantages, including complex computation, difficulties in finding the optimal projection direction, falling into local optima easily, and difficulties in solving highly nonlinear problems.
5.4. Principal Component Analysis Model
A principal component analysis (PCA) is a multivariate statistical analysis technique based on data compression and feature extraction. PCA is able to extract the dominant patterns in the matrix in terms of a complementary set of score and loading plots. And those extracted patterns contain majority information of the original data [
64].
A PCA reduces the number of predictor variables by transforming them into new variables; those new variables are called principal components (PCs). These PCs retain the maximum possible variance of the same data. The correlation matrix of the normalized input data can provide the PCs, and the eigenvalues of the correlation matrix “
C” are obtained from its characteristic equation as given in Equation (10) [
25]:
where
λ is the eigenvalue, and
I is the identity matrix. For every eigenvalue, there is a non-zero eigenvector, which can be defined as:
The
ith variance of the
ith PC is given as:
After obtaining all of the PCs, the initial data set is transformed into the orthogonal set by multiplying the eigenvectors [
58,
65].
Kumar et al. (2011) proposed a PCR model to forecast AQI in Delhi. The so-called PCR model transformed the data set into a multiple linear regression equation [
58].
Remark 5. The PCA algorithm reduces the dimensions of a series. It converts a number of related variables into a small number of unrelated variables that contain large amounts of original information. In the application of PCA, we choose the index to be representative, objective, independent, and comprehensive. At the same time, if the data set contains extreme values and nonlinear variables, the analysis effect will be greatly discounted. Therefore, the nonlinear PCA and independent component analysis methods are proposed, and these two methods are widely used in the forecasting field, but they are rarely used in pollution forecasting and need to be further explored.
5.5. Support Vector Regression
Support vector regression (SVR) is the application of support vectors in a regression function. There are two main types used for the regression analysis in SVR:
ε-
SVR and
ν-
SVR. SVR have advantages in high dimensionality space because SVR optimization does not depend on the dimensionality of the input space [
66].
In the highly dimensional feature space, there is a linear function, which maps the input data into higher dimensional space through nonlinear mapping. Such a linear function is known as the SVR equation [
24]:
where
f(
x) indicates forecast value;
w is N-dimensional weight vector; the dimension of
w is the dimension of feature space;
b is the threshold. The specific calculation method of (
w,
b) is given in [
26].
Chen et al. used SVR to forecast the concentration of SO
2. First, they analyzed and forecasted the influencing factors. Next, as a key step, they preprocessed the daily average concentration of SO
2, covering the period during 2001–2002 in Xi’an by using PCA to reduce the dimensionality of the input factors. Finally, the support vector regression model based on the radial basis function (RBF) kernel was established [
67].
Remark 6. Statistics are widely used in the forecasting field, and many existing models are based on it, such as the support vector machine (SVM). However, there are some problems in the application of classical statistical forecasting. For example, forecasting results from a single model are worse and have a low degree of integration with other methods. Therefore, researchers improve the statistical forecasting methods through various channels, such as proposing new hybrid models, changing the form of input variables, and studying new criteria for error evaluation. These measures have improved the prediction accuracy to varying degrees.
5.6. Artificial Neural Network
An ANN is a NN that mimics animal behavior characteristics. It is a mathematical model of distributed parallel information processing. ANN relies on the complexity of the system, through adjustment of the internal connection between a large numbers of nodes, to achieve the purpose of processing information. The NN has the capabilities of self-learning and self-adaptation.
A common feed forward Network Multilayer consists of three parts: the input layer, hidden layer, and output layer, and each of the layers contains several processing units connected by acyclic links. Those link points are named neurons.
From the viewpoint of mathematics, the hidden neuron
hj can be described by the Equation (14) [
68]:
where
ϕ(
zj) is an activation function, usually expressed as
;
;
wij is the weight of input
xi at neuron
j;
bj represent bias of neuron
j.
The relationship between the output
f(
x) and the inputs has the following representation:
where
wj is a model parameter, often called connection weights;
q is the number of hidden nodes.
An ANN is representative of AI methods for forecasting air pollution. Wang et al. (2015) used an ANN model to forecast the concentrations of SO
2 and PM
10 in four stations in Taiyuan to compare with a hybrid model. The ANN forecast accuracy is shown in
Table 8 [
68].
In Rahman’s study, they contrasted the results of SARIMA, ANN, and a fuzzy time series (FTS), and the results are shown in
Table 9. The study results indicated that the ANN model was capable of modeling and forecasting index values of API [
21].
Elangasinghe et al. built an ANN air pollution forecast model based on meteorological parameters and the emission patterns of the sources. First, they identified the various data sets, and after cleaning, normalizing, and randomizing the data, they built an ANN model. Then, they applied forward selection, backward elimination, and genetic algorithms with sensitivity analysis techniques as the selection tool to eliminate the irrelevant inputs from the network [
23].
Remark 7. The ANN, as the simplest NN, has been applied to predict air pollution. It has good nonlinear fitting ability and improves the prediction accuracy. However, there are many factors affecting pollution and the relationship is complicated for clarifying the relationship between these factors and improving the prediction accuracy of the ANN.
5.7. Back Propagation Neural Network
Back propagation (BP), meaning “error backward propagation”, is one of the most widely used NN models, which is trained by the error back propagation algorithm. It consists of two processes: the forward propagation of information and the back propagation of error. When the actual output is not in conformity with the expected output, the reverse propagation phase of the error is entered. The error is corrected by the output layer, and the weight of each layer is updated by the error gradient descent method. The cycle of information forward propagation and error back propagation processes and the constant adjustment of the weights of each layer are the learning and training processes of the NN, and those two processes are executed until the network output error is reduced to an acceptable level or pre-set learning times are reached.
When modeling a BPNN, the number of hidden nodes is the primary variable to be determined. Recently, the trial and error method and an empirical formula (Equation (16)) have been applied to solve this issue [
24]:
Bai et al. improved the BPNN model based on wavelet decomposition to improve the feature representations in multi-scales and weaken the randomness. The operations of the model are as follow [
24]:
Step 1: Collect the modeling data that contain historical air pollutants concentrations C and meteorological data M.
Step 2: Perform the stationary wavelet transform (SWT) to decompose the time series of C.
Step 3: Normalize the meteorological parameters and one level of wavelet coefficients into [0, 1] according to Equation (17):
Step 4: Calculate the
tth wavelet coefficients of the
zth scale using
BPNNz,
z = 1, 2, …,
l,
l + 1 with the
tth meteorological data and (
t − 1)th wavelet coefficients:
Step 5: Perform the inverse SWT to generate the estimated daily pollutants concentrations.
Step 6: Output the forecasting result.
The comparison between the results of W-BPNN and BPNN are shown in
Table 10. From the table, we find that the values of the mean absolute percent error (MAPE) and root mean square error (RMSE) for W-BPNN are lower than the values for BPNN, which indicates that W-BPNN has the best forecasting performance.
Wang et al. improved the BPNN from other side. They added SSA algorithm to reduce the effect of chaotic nature on pollution sequences and improve BPNN forecasting performance [
69].
Remark 8. The convergence speed of the BPNN is slow, and it cannot guarantee the convergence to the global optimum. At the same time, the selection of the operational parameters of the BPNN is generally based on experience and lacks theoretical guidance. Therefore, when using BP, it should be combined with other optimization algorithms to improve its prediction accuracy.
5.8. Wavelet Neural Network
Another commonly used NN is the wavelet NN. As the name suggests, the term wavelet means a small waveform, and “small” means that it has decay, and ”wave” refers to its volatility. Wavelet analysis is used to gradually refine the signal (function) through expansion and translation operations. Finally, the high frequency is subdivided by time, and the low frequency is subdivided by frequency. A wavelet analysis can automatically adapt to the requirements of a time-frequency signal analysis, so it can focus on any details of the signal.
The wavelet function
ψ(
t) refers to a shock characteristic that can quickly decay to zero for a class of functions, defined in Chen [
70] as:
If
ψ(
t) satisfies the following admissibility condition (Equation (21)), we term
ψ(
t) as a basic wavelet or wavelet:
After dilation and translation of function
ψ(
t), we obtain Equation (22):
This is called a wavelet sequence, where a is the expansion factor, and b is the translation factor.
The wavelet transform of the function
f(
t) is as follows:
where
wf(
a,b) are the wavelet coefficients, which can reflect the characteristics of the frequency domain parameter a and the time domain parameter
b. When parameter
a is smaller, the resolution of the frequency domain is lower, but the resolution is higher in the time domain. In contrast, when
a is larger, the resolution of the frequency domain is higher, and the resolution is lower in the time domain. Therefore, the wavelet transform can realize the time frequency localization of the fixed size and variable shape of the window.
Chen applied the method of wavelet analysis and neural networks to forecast the concentration of atmospheric pollutants. The steps in the study were [
70]:
Step 1: The low frequency coefficients of the highest layer are reconstructed after wavelet decomposition, clearly determining the annual change of atmospheric pollutant concentration. By using wavelet decomposition, the lowest two layers with high frequency signals are reconstructed, so abrupt change points of the time series of atmospheric pollutant concentration can be clearly judged.
Step 2: The time series of atmospheric pollutant concentration are decomposed into different frequency channels by wavelet decomposition, and then the corresponding time series model is considered. Finally, the predicted values of different frequency channels are combined to obtain the predictive value of the original time series.
Step 3: The input samples of the NN prediction model are studied, and the input variables of the NN prediction model are analyzed by using the principle of atmospheric pollution meteorology. Then, the PCA is used to reduce the dimension of the input variables.
Step 4: The annual variation trend of atmospheric pollutant concentration time series are segmented by wavelet decomposition and reconstruction. On this basis, the NN prediction model is designed for each segment.
Step 5: The decomposed wavelet coefficients are reconstructed to the original scale, and the NN that contains the meteorological elements is applied to analyze the wavelet coefficients of low and medium frequency. For the high frequency wavelet coefficients, the wavelet coefficients of the first few days are used as the input values of the NN model. Finally, the forecast of each wavelet coefficient sequence value is synthetized, and the forecasted value of the original sequence is obtained.
A summary of commonly used wavelet is shown in
Table 11.
Remark 9. Wavelet analysis is proposed to overcome the shortcomings of the Fourier transform in analyzing non-stationary signals, and it can effectively extract the local information of signals and has good analysis ability for the localization time-frequency. However, the selection of the wavelet basis is difficult.
ANNs have the advantages of self-organized learning and adaptive and good fault tolerance; however, the traditional NNs also have some shortcomings, such as slow convergence, and they easily fall into local minima. Therefore, Zhang et al. proposed the concept and algorithm for a wavelet NN in 1992. Wavelet NNs inherit the merits of a wavelet analysis and NN and function well for of approximations and for their pattern classification ability; therefore, they are widely used in prediction [
71].
5.9. Support Vector Machine (SVM)
Support vector machine (SVM) is a new generation of machine learning technology based on statistical learning theory developed by Vapnik, and practical problems, such as small samples, nonlinearity, high dimensions, and local minimum points, can be solved effectively. SVM is successfully used in classification, regression and time series forecasts, and other fields. Originally, SVMs were used for classification purposes, but their principles can be extended easily to the task of regression and time series forecasting [
61].
Forecast models of atmospheric pollutant concentration change based on SVM. The key issues are the determination of the input mode, the selection of training samples, and the selection of model structure parameters [
72]. The steps to build an atmospheric pollutant concentration forecast model are as follows:
Build an effective forecast factor.
Select kernel function and parameter values.
Train the sample to provide the SVM forecast model with optimized parameters, get the support vector, and then determine the structure of the SVM.
Train the support vector predictor to forecast the test samples.
Chen used SO
2 as an example and established a forecast model for atmospheric pollutant concentration. The author chose different kernel functions to analyze and compare each function’s mean relative error (MRE) and RMSE. Ultimately, studies showed that different kernel functions have different prediction results. They established the model that combined wavelet decomposition with SVM to forecast urban atmospheric pollutant concentration [
67]. Wang et al. improved the forecast accuracy of SVM by using the Taylor expansion forecasting model to revise the residual series [
68]. The forecast accuracies are shown in
Table 12.
Remark 10. SVMs were initially used as a pattern recognition method based on statistical learning theory and has better predictive processing ability for small samples and nonlinear data. However, the SVM algorithm is difficult to be implemented in large-scale training samples. When the number of training samples is large, the storage and computation of the data matrix will consume a great deal of machine memory and computation time. At the same time, SVMs are sensitive to missing data. If there are more missing values in the data sequence, the accuracy of the forecasting results will be affected. SVMs have no general solutions to nonlinear problems. Since the choice of kernel function is the key to solving problems, the kernel function should be carefully chosen. In addition, the SVM algorithm only gives a two-class algorithm; there are limitations on the solution of multi-classification problems.
5.10. Fuzzy Time Series (FTS) Analysis
In 1993, Chissom and Song proposed the definition of fuzzy time series (FTS) based on fuzzy set [
73]. At present, FTS has been used in the field of air pollution forecasting. The method for forecasting the API using the FTS simply can be presented as follows [
21,
74]:
Step 1: Define and partition the universe of discourse U = (Dmin − D1, Dmax + D2) into several equal intervals denoted as u1,u2,L,um.
Step 2: Based on the SARIMA model, determine the FLRs.
Step 3: In order to select the best input for FLR, different combination inputs are attempted from single input to two inputs, three inputs and four inputs.
Step 4: The optimum length of intervals was calculated by following the average-based length.
Step 5: The forecasted outputs are calculated.
Rahman et al. forecasted the API for three different stations in Malaysia [
21]. The forecasting accuracy in the testing period of the FTS model is shown in
Table 13.
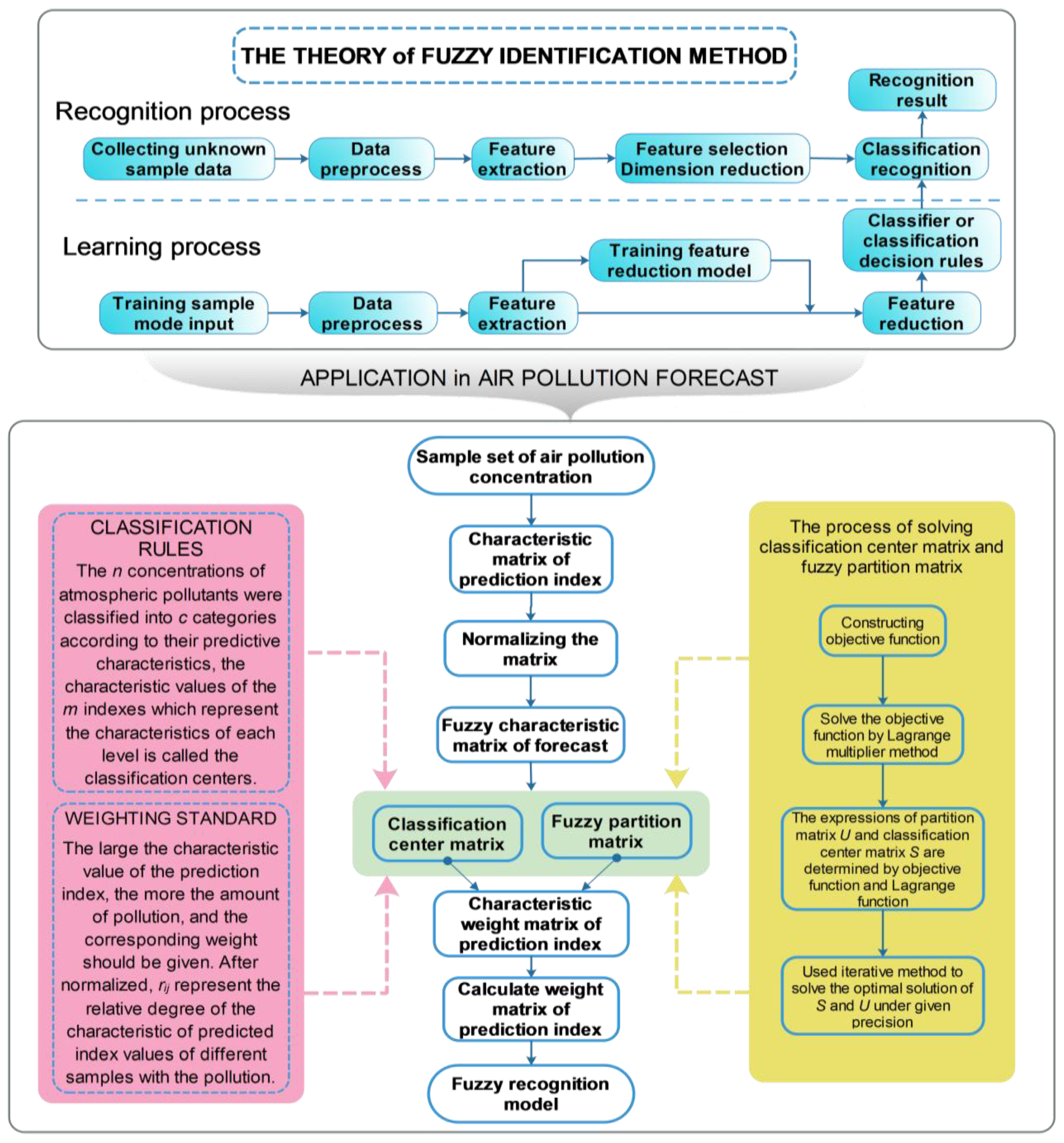
5.11. Fuzzy Recognition
Fuzzy pattern recognition recognizes a given object, and there are usually two processes in fuzzy identification: the recognition process and the learning process.
Figure 4 shows the steps for the two processes.
Xiong et al. proposed the fuzzy recognition theory and model for air pollution concentration forecasting and made an empirical study based on the measured concentration data of SO
2. Fuzzy recognition can be used to forecast the information [
75]. The forecast model contains the index weight matrix, which provides a new way of improving the forecast accuracy.
Remark 11. Theoretically, fuzzy methods have a high fault tolerance and do not require accurate mathematical models with each man-machine interaction; however, those methods have a relatively low accuracy and lack systematization. The computation of fuzzy identification is complex, and the performance of the fuzzy time series forecasting method is affected when outliers exist. The fuzzy method should be further optimized during its application, for example, combining subtractive clustering, optimizing the parameters of membership functions, and combining a BPNN to optimize fuzzy rules. The quantization factor and proportionality factor are optimized based on genetic algorithms.
5.12. Adaptive Neural Network Fuzzy Inference System
ANFIS is a fuzzy inference system based on adaptive networks structure, it uses neural network algorithms to obtain fuzzy rules and membership functions from data, and uses neural networks to implement fuzzy inference processes. The general principles and methods of ANFIS have been systematically studied and summarized in the Ref [
76]. ANFIS is composed of two parts: primary and inference. These two parts are connected by a network with fuzzy rules [
77].
The most commonly used ANFIS structure is the Sugeno fuzzy model. The basic structure can be expressed as a feedforward NN with five layers [
78]:
Layer 1: In this layer, every node
i is an adaptive node and the node function is the membership function to determine the degree of satisfaction. All the parameters in this layer are called antecedent parameters.
where
x is the input to node
i,
Ai is a linguistic label to node
i, and
is the membership grade of
Ai.
Layer 2: Every node in this layer is a circle node labeled
and the output is the multiplies of all incoming signals [
79]:
Layer 3: The output of every node
i is called normalized firing strength. Each node calculates the rate of the
ith rule’s firing strength to the sum of all the rules’ firing strengths and normalization [
78]:
Layer 4: This layer is the conclusion layer, every node
i is a square node or adaptive node with a node function. And parameters in this layer will be referred to as consequent parameters [
79].
where
is the output of Layer 3 and (
pi,qi,ri) is the parameter set of this node.
Layer 5: In this layer, the single node is a fixed node that computes the summation of all incoming signals [
77].
Remark 12. It is being proven that the accuracy of AI forecasts is higher than traditional statistical forecasts. More recently, researchers select meteorological or geographic factors as input variables, and those adjusted models are shown to improve the accuracy of forecasting. From the results of a comparison by Rahman (2015), ANN can be used to predict the fluctuation series, which contain certain trends and seasonality, such as those in air quality data. However, ANN and SVM have limitations inherent to their input variables; their main defect is a failure to obtain complete information about research questions related to learning goals. Therefore, the shortcomings of ANNs facilitate the development of hybrid models.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}