Using Twitter to Better Understand the Spatiotemporal Patterns of Public Sentiment: A Case Study in Massachusetts, USA

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Twitter Data
2.2. Data Analysis
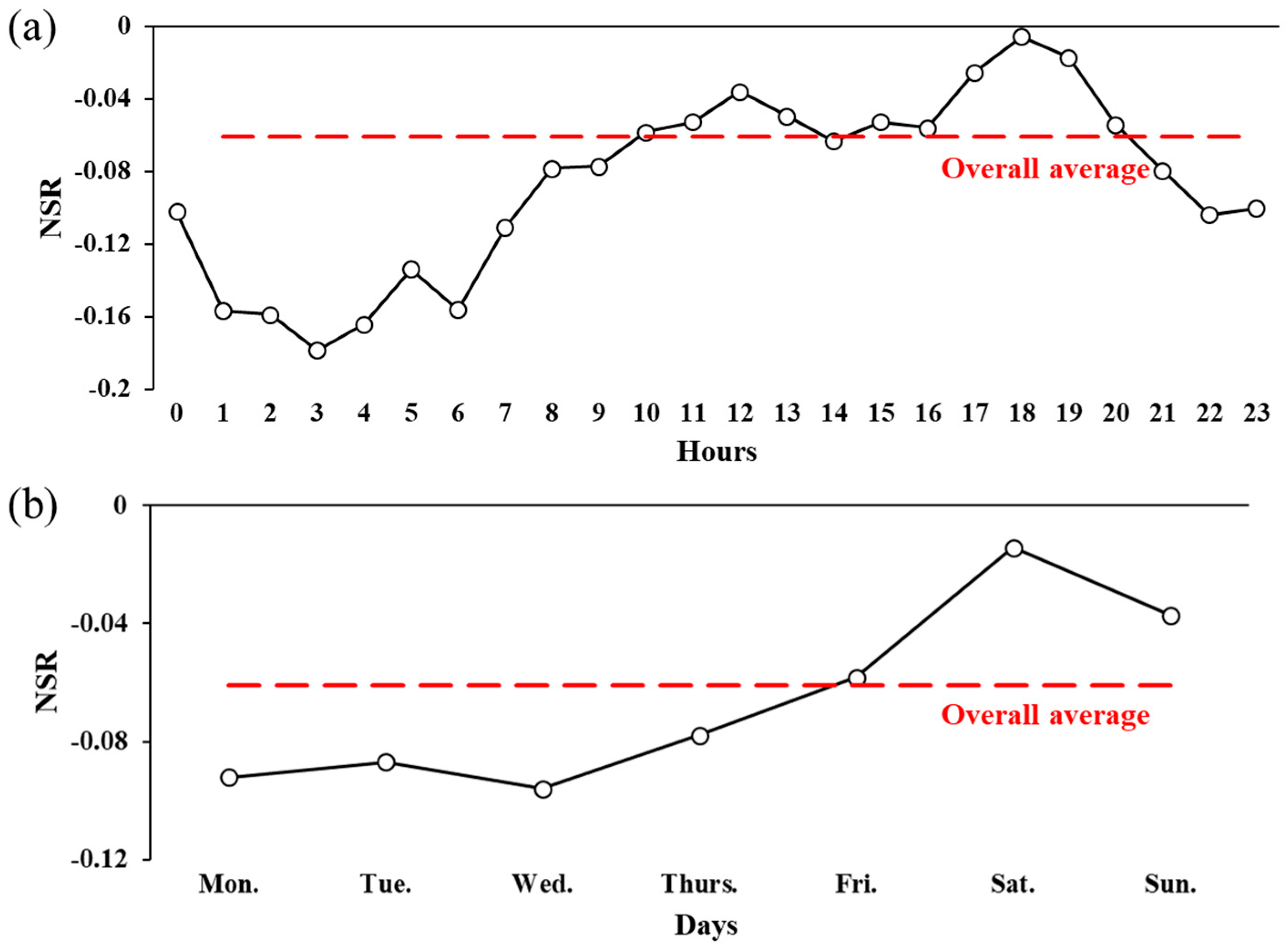
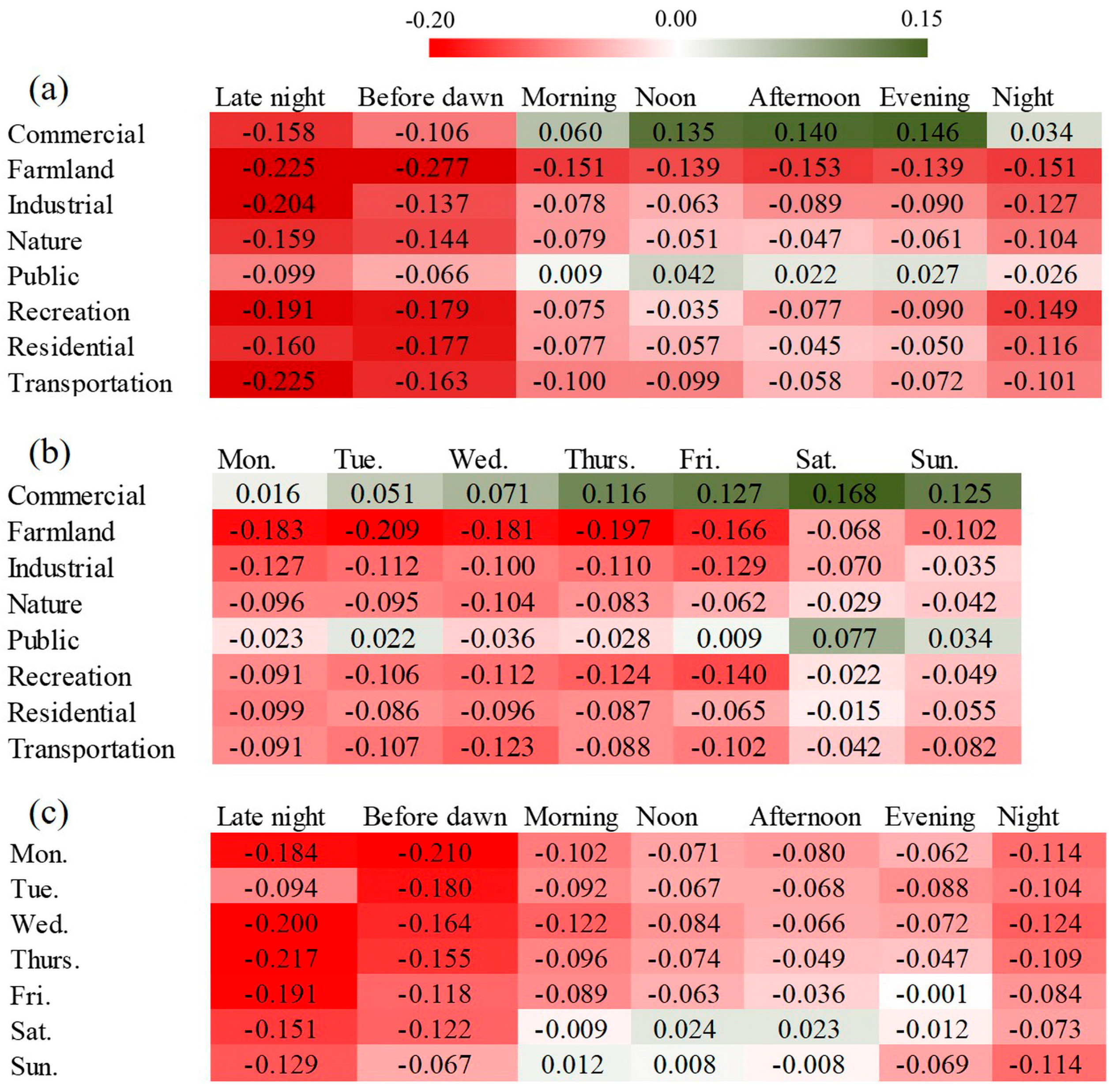
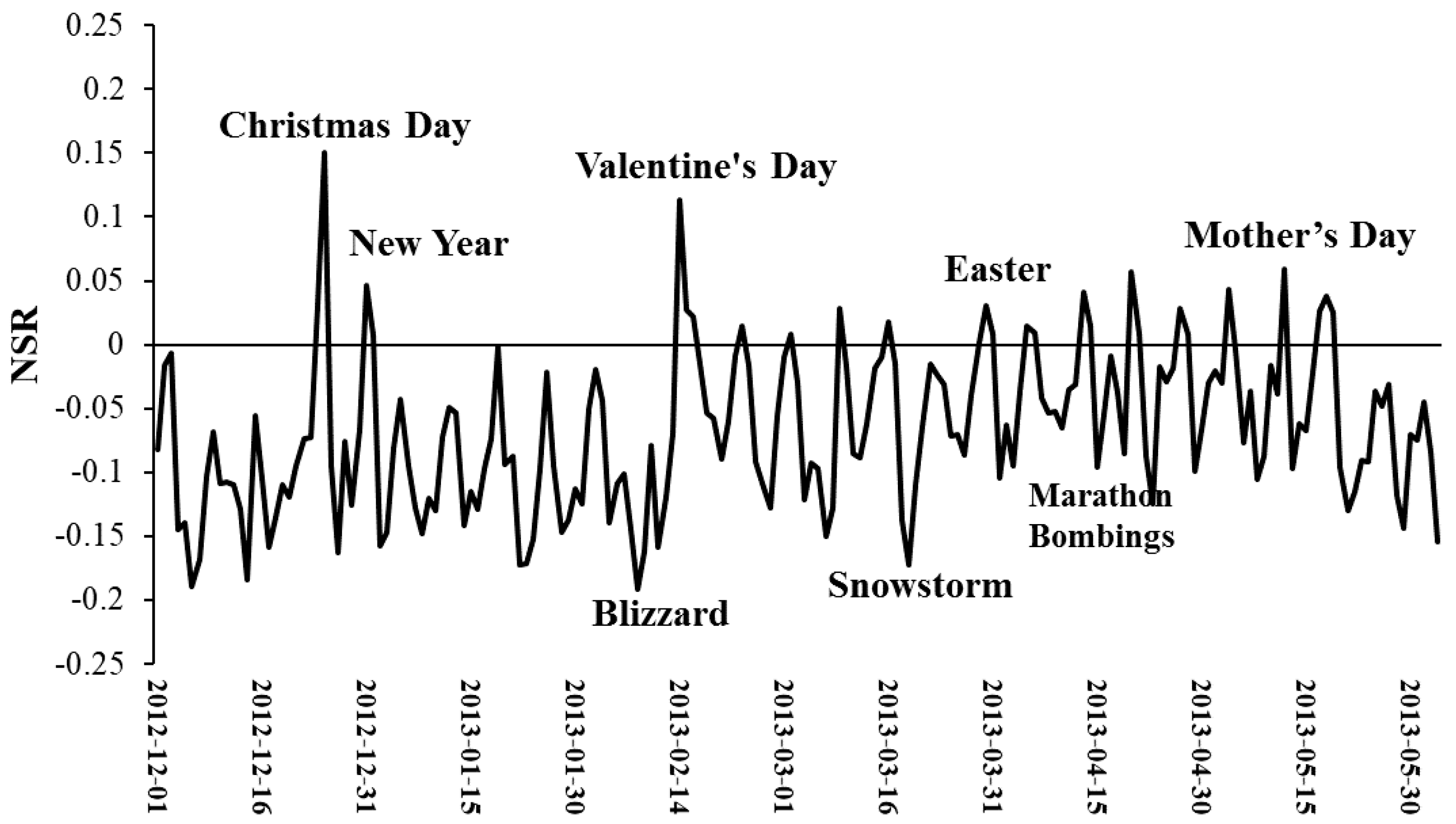
3. Results
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Twitter. Twitter Usage/Company Facts (Updated 30 June 2016). Available online: https://about.twitter.com/company (accessed on 5 January 2017).
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of Twitter and flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Xu, C.; Wong, D.W.; Yang, C. Evaluating the “geographical awareness” of individuals: An exploratory analysis of Twitter data. Cartogr. Geogr. Inf. Sci. 2013, 40, 103–115. [Google Scholar] [CrossRef]
- Zhao, D.; Rosson, M.B. How and why people Twitter: The role that micro-blogging plays in informal communication at work. In Proceedings of the ACM 2009 International Conference on Supporting Group Work, Sanibel Island, FL, USA, 10–13 May 2009; pp. 243–252. [Google Scholar]
- Singleton, A.D.; Longley, P. The internal structure of greater london: A comparison of national and regional geodemographic models. Geo: Geogr. Environ. 2015, 2, 69–87. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Longley, P.A.; Adnan, M.; Lansley, G. The geotemporal demographics of Twitter usage. Environ. Plan. A 2015, 47, 465–484. [Google Scholar] [CrossRef]
- Lansley, G.; Longley, P.A. The geography of Twitter topics in london. Comput. Environ. Urban Syst. 2016, 58, 85–96. [Google Scholar] [CrossRef]
- Soliman, A.; Soltani, K.; Yin, J.; Padmanabhan, A.; Wang, S. Social sensing of urban land use based on analysis of Twitter users’ mobility patterns. PLoS ONE 2017, 12, e0181657. [Google Scholar] [CrossRef] [PubMed]
- Balahur, A.; Mihalcea, R.; Montoyo, A. Computational approaches to subjectivity and sentiment analysis: Present and envisaged methods and applications. Comput. Speech Lang. 2014, 28, 1–6. [Google Scholar] [CrossRef]
- Abbasi, A.; Hassan, A.; Dhar, M. Benchmarking Twitter Sentiment Analysis Tools. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 823–829. [Google Scholar]
- Neppalli, V.K.; Caragea, C.; Squicciarini, A.; Tapia, A.; Stehle, S. Sentiment analysis during hurricane sandy in emergency response. Int. J. Disaster Risk Reduct. 2017, 21, 213–222. [Google Scholar] [CrossRef]
- Jiang, H.; Qiang, M.; Lin, P. Assessment of online public opinions on large infrastructure projects: A case study of the three gorges project in China. Environ. Impact Assess. Rev. 2016, 61, 38–51. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, X. World cup 2014 in the Twitter world: A big data analysis of sentiments in US sports fans’ tweets. Comput. Hum. Behav. 2015, 48, 392–400. [Google Scholar] [CrossRef]
- Palomino, M.; Taylor, T.; Göker, A.; Isaacs, J.; Warber, S. The online dissemination of nature–health concepts: Lessons from sentiment analysis of social media relating to “nature-deficit disorder”. Int. J. Environ. Res. Public Health 2016, 13, 142. [Google Scholar] [CrossRef] [PubMed]
- Widener, M.J.; Li, W. Using geolocated Twitter data to monitor the prevalence of healthy and unhealthy food references across the US. Appl. Geogr. 2014, 54, 189–197. [Google Scholar] [CrossRef]
- Naaman, M.; Becker, H.; Gravano, L. Hip and trendy: Characterizing emerging trends on Twitter. J. Assoc. Inf. Sci. Technol. 2011, 62, 902–918. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Y.; Tsou, M.-H.; Fu, X. Using social media to detect outdoor air pollution and monitor air quality index (AQI): A geo-targeted spatiotemporal analysis framework with Sina Weibo (Chinese Twitter). PLoS ONE 2015, 10, e0141185. [Google Scholar] [CrossRef] [PubMed]
- Woo, H.; Cho, Y.; Shim, E.; Lee, K.; Song, G. Public trauma after the sewol ferry disaster: The role of social media in understanding the public mood. Int. J. Environ. Res. Public Health 2015, 12, 10974–10983. [Google Scholar] [CrossRef] [PubMed]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Tumasjan, A.; Sprenger, T.O.; Sandner, P.G.; Welpe, I.M. Election forecasts with Twitter: How 140 characters reflect the political landscape. Soc. Sci. Comput. Rev. 2011, 29, 402–418. [Google Scholar] [CrossRef]
- Finfgeld-Connett, D. Twitter and health science research. West. J. Nurs. Res. 2015, 37, 1269–1283. [Google Scholar] [CrossRef] [PubMed]
- Broniatowski, D.A.; Paul, M.J.; Dredze, M. National and local influenza surveillance through Twitter: An analysis of the 2012–2013 influenza epidemic. PLoS ONE 2013, 8, e83672. [Google Scholar] [CrossRef] [PubMed]
- Stoové, M.A.; Pedrana, A.E. Making the most of a brave new world: Opportunities and considerations for using Twitter as a public health monitoring tool. Prev. Med. 2014, 63, 109–111. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Cámara, E.; Martín-Valdivia, M.T.; Urena-López, L.A.; Montejo-Ráez, A.R. Sentiment analysis in Twitter. Nat. Lang. Eng. 2014, 20, 1–28. [Google Scholar] [CrossRef]
- Ballas, D. What makes a ‘happy city’? Cities 2013, 32, S39–S50. [Google Scholar] [CrossRef]
- Mulligan, G.F.; Carruthers, J.I. Amenities, quality of life, and regional development. In Investigating Quality of Urban Life; Springer: Berlin, Germany, 2011; pp. 107–133. [Google Scholar]
- Morais, P.; Camanho, A.S. Evaluation of performance of European cities with the aim to promote quality of life improvements. Omega 2011, 39, 398–409. [Google Scholar] [CrossRef]
- Dolan, P.; Peasgood, T.; White, M. Do we really know what makes us happy? A review of the economic literature on the factors associated with subjective well-being. J. Econ. Psychol. 2008, 29, 94–122. [Google Scholar] [CrossRef]
- Layard, R. Measuring subjective well-being. Science 2010, 327, 534–535. [Google Scholar] [CrossRef] [PubMed]
- Oswald, A.J.; Wu, S. Objective confirmation of subjective measures of human well-being: Evidence from the USA. Science 2010, 327, 576–579. [Google Scholar] [CrossRef] [PubMed]
- Ballas, D.; Tranmer, M. Happy people or happy places? A multilevel modeling approach to the analysis of happiness and well-being. Int. Reg. Sci. Rev. 2012, 35, 70–102. [Google Scholar] [CrossRef]
- Aslam, A.; Corrado, L. The geography of well-being. J. Econ. Geogr. 2011, 12, 627–649. [Google Scholar] [CrossRef]
- Bhatti, S.S.; Tripathi, N.K.; Nagai, M.; Nitivattananon, V. Spatial interrelationships of quality of life with land use/land cover, demography and urbanization. Soc. Indic. Res. 2017, 132, 1193–1216. [Google Scholar] [CrossRef]
- Higgins, P.; Campanera, J.; Nobajas, A. Quality of life and spatial inequality in London. Eur. Urban Reg. Stud. 2014, 21, 42–59. [Google Scholar] [CrossRef]
- Ballas, D. Geographical modelling of happiness and well-being. In Spatial and Social Disparities; Springer: Berlin, Germany, 2010; pp. 53–66. [Google Scholar]
- Berry, B.J.; Okulicz-Kozaryn, A. An urban-rural happiness gradient. Urban Geogr. 2011, 32, 871–883. [Google Scholar] [CrossRef]
- Yang, W.; Mu, L. Gis analysis of depression among Twitter users. Appl. Geogr. 2015, 60, 217–223. [Google Scholar] [CrossRef]
- Nguyen, Q.C.; Li, D.; Meng, H.-W.; Kath, S.; Nsoesie, E.; Li, F.; Wen, M. Building a national neighborhood dataset from geotagged Twitter data for indicators of happiness, diet, and physical activity. JMIR Public Health Surveill. 2016, 2, e158. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, L.; Frank, M.R.; Harris, K.D.; Dodds, P.S.; Danforth, C.M. The geography of happiness: Connecting Twitter sentiment and expression, demographics, and objective characteristics of place. PLoS ONE 2013, 8, e64417. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Hernandez, I.; Newman, D.A.; He, J.; Bian, J. Twitter analysis: Studying US weekly trends in work stress and emotion. Appl. Psychol. 2016, 65, 355–378. [Google Scholar] [CrossRef]
- MacNaughton, P.; Eitland, E.; Kloog, I.; Schwartz, J.; Allen, J. Impact of particular matter exposure and surrounding “greenness” on chronic absenteeism in Massachusetts public schools. Int. J. Environ. Res. Public Health 2017, 14, 207. [Google Scholar] [CrossRef] [PubMed]
- Zandbergen, P.A. Accuracy of iphone locations: A comparison of assisted GPS, WiFi and cellular positioning. Trans. GIS 2009, 13, 5–25. [Google Scholar] [CrossRef]
- Massgov. Massgis Data—Land Use (2005). Available online: http://www.mass.gov/anf/research-and-tech/it-serv-and-support/application-serv/office-of-geographic-information-massgis/datalayers/lus2005.html (accessed on 11 January 2016).
- Waston, I. Alchemy-Language—API Reference. Available online: https://www.ibm.com/watson/developercloud/alchemy-language/api/v1/ (accessed on 11 January 2016).
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inf. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Gao, S.; Hao, J.; Fu, Y. The application and comparison of web services for sentiment analysis in tourism. In Proceedings of the 2015 12th International Conference on Service Systems and Service Management (ICSSSM), Guangzhou, China, 22–24 June 2015; pp. 1–6. [Google Scholar]
- Meehan, K.; Lunney, T.; Curran, K.; McCaughey, A. Context-aware intelligent recommendation system for tourism. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), St. Louis, MO, USA, 23–27 March 2013; pp. 328–331. [Google Scholar]
- Luo, F.; Cao, G.; Mulligan, K.; Li, X. Explore spatiotemporal and demographic characteristics of human mobility via Twitter: A case study of Chicago. Appl. Geogr. 2016, 70, 11–25. [Google Scholar] [CrossRef]
- Lansley, G.; Longley, P. Deriving age and gender from forenames for consumer analytics. J. Retail. Consum. Serv. 2016, 30, 271–278. [Google Scholar] [CrossRef]
- Smith, A.; Brenner, J. Twitter use 2012. Pew Internet Am. Life Proj. 2012, 4, 1–12. [Google Scholar]
- Plutchik, R. Emotion: A Psychoevolutionary Synthesis; Harpercollins College Division: New York, NY, USA, 1980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Land Use Type | Number of Tweets |
|---|---|---|
| Commercial | Commercial | 35,610 |
| Farmland | Cranberry Bog, Cropland, Orchard, Pasture | 14,951 |
| Industrial | Industrial, Junkyard, Mining, Powerline/Utility, Waste Disposal | 14,292 |
| Nature | Brushland, Forest, Forested Wetland, Non-Forested Wetland, Open Land, Saltwater, Sandy Beach, Saltwater Wetland, Water | 567,086 |
| Public | Urban Public/Institutional | 27,786 |
| Recreation | Golf Course, Marina, Participation Recreation, Spectator Recreation, Water-based Recreation | 21,365 |
| Residential | High Density Residential, Low Density Residential, Medium Density Residential, Multi-Family Residential, Very Low Density Residential | 181,577 |
| Transportation | Transportation | 17,981 |
| Excluded | Cemetery, Nursery, Transitional | 289 |
| Variables | Coefficients of Fixed Effects | Standard Error | p-Value | |
|---|---|---|---|---|
| Intercept | −0.111 | 0.007 | <0.0001 | |
| Land use | Commercial | 0.064 | 0.006 | <0.0001 |
| Farmland | 0.000 (referent) | - | - | |
| Industrial | 0.021 | 0.008 | 0.0082 | |
| Nature | 0.026 | 0.006 | <0.0001 | |
| Public | 0.037 | 0.007 | <0.0001 | |
| Recreation | 0.022 | 0.007 | 0.0022 | |
| Residential | 0.026 | 0.006 | <0.0001 | |
| Transportation | 0.016 | 0.007 | 0.0302 | |
| Days of the week | Mon. | 0.004 | 0.002 | 0.0345 |
| Tue. | 0.007 | 0.002 | 0.0004 | |
| Wed. | 0.000 (referent) | - | - | |
| Thurs. | 0.006 | 0.002 | 0.0042 | |
| Fri. | 0.014 | 0.002 | <0.0001 | |
| Sat. | 0.030 | 0.002 | <0.0001 | |
| Sun. | 0.030 | 0.002 | <0.0001 | |
| Times of the day | Late night | 0.012 | 0.004 | 0.0044 |
| Before dawn | 0.000 (referent) | - | - | |
| Morning | 0.034 | 0.003 | <0.0001 | |
| Noon | 0.044 | 0.003 | <0.0001 | |
| Afternoon | 0.046 | 0.003 | <0.0001 | |
| Evening | 0.054 | 0.003 | <0.0001 | |
| Night | 0.040 | 0.003 | <0.0001 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, X.; MacNaughton, P.; Deng, Z.; Yin, J.; Zhang, X.; Allen, J.G. Using Twitter to Better Understand the Spatiotemporal Patterns of Public Sentiment: A Case Study in Massachusetts, USA. Int. J. Environ. Res. Public Health 2018, 15, 250. https://doi.org/10.3390/ijerph15020250
Cao X, MacNaughton P, Deng Z, Yin J, Zhang X, Allen JG. Using Twitter to Better Understand the Spatiotemporal Patterns of Public Sentiment: A Case Study in Massachusetts, USA. International Journal of Environmental Research and Public Health. 2018; 15(2):250. https://doi.org/10.3390/ijerph15020250
Chicago/Turabian StyleCao, Xiaodong, Piers MacNaughton, Zhengyi Deng, Jie Yin, Xi Zhang, and Joseph G. Allen. 2018. "Using Twitter to Better Understand the Spatiotemporal Patterns of Public Sentiment: A Case Study in Massachusetts, USA" International Journal of Environmental Research and Public Health 15, no. 2: 250. https://doi.org/10.3390/ijerph15020250
APA StyleCao, X., MacNaughton, P., Deng, Z., Yin, J., Zhang, X., & Allen, J. G. (2018). Using Twitter to Better Understand the Spatiotemporal Patterns of Public Sentiment: A Case Study in Massachusetts, USA. International Journal of Environmental Research and Public Health, 15(2), 250. https://doi.org/10.3390/ijerph15020250