1. Introduction
High physical activity (PA) and a low amount of sedentary behavior (SB) are often associated with several benefits for children and adolescents, including positive effects on cardiovascular, musculoskeletal and metabolic health [
1,
2], well-being [
3], and obesity [
4]. Movement/non-movement behavior patterns in youth may extend to adulthood [
5,
6] and, therefore, understanding the optimal structure of time spent in various activities in early life is desirable. Current PA guidelines for adolescents around the world focus mainly on time spent in moderate PA (MPA) and vigorous PA (VPA) and encourage children and adolescents to engage in at least 60 min of moderate-to-vigorous PA every day [
2]. However, being active for an hour a day does not mean that the rest of the day has no effect on overall health. Thus, some of the health benefits of meeting the PA recommendations might be lost if children are subject to extensive sitting. SB and light-intensity PA (LIPA) have not been a preferred subject of interest in public health research for decades. It was assumed that if MPA and VPA increase, SB inherently decrease. However, MPA and VPA usually account for less than 5% of the day, whilst the time spent in LIPA is approximately three times greater [
7]. LIPA may also be beneficial for children’s health [
8]. Additionally, excessive SB and inadequate sleep duration also represent critical health challenges to children and youth today [
9]. These behaviors account for a large proportion of the day (~80%) and are considered independent risk factors for obesity [
10].
The main issues in research on the relationship between movement behavior patterns and health outcomes are: (1) length of time needed for manifestation of diseases or disorders/health problems caused by an unhealthy lifestyle [
11] and (2) limited possibilities to distinguish between the effects of all components of PA and SB in the prevention of health problems (e.g., obesity) [
12]. It is widely thought that a greater understanding of the role of each PA and SB component with respect to other components in this age group is necessary and should be assessed in a more holistic way. Moreover, PA and SB data are compositional in nature and, hence, any proportional increase in one behavior necessarily causes a proportional decrease in one or more remaining behaviors; these behaviors are perfectly collinear if an exhaustive description of the movement behavior composition (including sleep) is provided. However, even if this is not the case, the information contained in the movement behavior composition is relative and thus scale invariant; i.e., it can be normalized to any sum (such as 1 in the case of proportions or 100 for percentages) without loss of information.
Standard statistical techniques such as multiple regression analysis are not well suited to describe the relationship between a response of interest and explanatory covariates of a compositional nature. They are not designed to accommodate and account for the relative contributions of the parts of a whole (herein “total wake time”), hereafter called compositional data [
13]. Although early studies point toward the use of compositional data analysis (CODA) in PA and SB research [
14,
15], it was not until the work by Chastin et al. [
12] that the CODA approach to PA research was introduced and discussed in a comprehensive and statistically-principled means using the latest methodological developments in the area to deal with behavioral data that represent parts of a whole (i.e., data carrying relative information), useful when either all parts or just some of them have been measured. Over the last few years, the CODA approach has notably increased its popularity in the physical activity community, and there has been a large number of studies examining the relationship between health and movement/non-movement behavior pattern among youth using CODA [
16,
17,
18,
19,
20,
21]. Finally, a theoretical framework, which describes the relationship between all movement/non-movement behaviors and health outcomes, has recently been updated to The Framework for Viable Integrative Research in Time-Use Epidemiology (VIRTUE framework) [
22]. Up to now, primarily classical statistical analysis methods were used in PA and SB research; therefore, the aims of this study are: (1) to present a concise regression framework within CODA in the presence of outlying observations, which often occur in most real-world data sets, encouraging the use of robust statistical methods instead of their classical counterparts in these situations; and (2) to investigate the combined effect of time spent in LIPA, MPA, VPA and SB on the risk of obesity within a robust CODA framework.
3. Results
In the following text, the above-introduced four distinct types of activities (SB, LIPA, MPA, and VPA) were analyzed. The average daily behavior of an individual was considered representative of their habitual PA. Additionally, adolescents’ sex, age, weight and height were recorded and the latter three variables were used in the following analysis.
For the sake of succinctness, the following notation will be used:
for the entire movement behavior (MB) composition and
for the PA subcomposition in particular.
3.1. Relationship between Various Movement Behaviour Intensities
At first, the authors analyzed the inter-relationships between the parts that form the MB composition. The proportional relationships were summarized in the so-called compositional variation matrix, formed by the variances of all possible pair-wise log-ratios [
28] (
Table 1). The lower the value of these variances, the more proportional the respective compositional parts are. Accordingly,
Table 1 shows that SB and LIPA were the most proportional parts, while the least proportional pair was LIPA and VPA.
Alternatively, a robust variation matrix [
38] as shown in
Table 2 can be obtained by robust estimation of the covariance matrix in any pivot coordinate system (MCD estimator was used here). By comparing it with the previous (classical) variation matrix, it can be observed that the proportionality between SB and LIPA was slightly weakened, therefore now LIPA and MPA become the most proportional components.
A limitation of the variation matrix is that it does not consider the effect of other parts on the relationship between the two components involved. Moreover, it does not provide information about positive or negative directions of the relationship. To circumvent this limitation, we investigated the relationship between SB, the “non-active” part in the MB composition, and the parts in the PA sub-composition via robust orthogonal regression. For this purpose, model (5) was specified as:
Thus, three models are obtained, where are pivot coordinates for the MB composition with SB in the first position and a particular part (either LIPA, MPA or VPA) in the second position. The estimate from each model is of interest.
The results (
Table 3) imply that the relative dominance of SB with respect to the average contribution of PA parts is positively associated with the relative dominance of LIPA with respect to the average contribution of the remaining PA parts, whereas it is negatively related to the relative dominance of MPA and VPA (with respect to the average contribution of the remaining PA parts). It can be concluded that those individuals who spend a relatively large amount of time in SB also tend to spend a relatively high amount of time in LIPA and a relatively small amount of time in MPA and VPA.
3.2. Changes in Movement Behaviour with Increasing Age
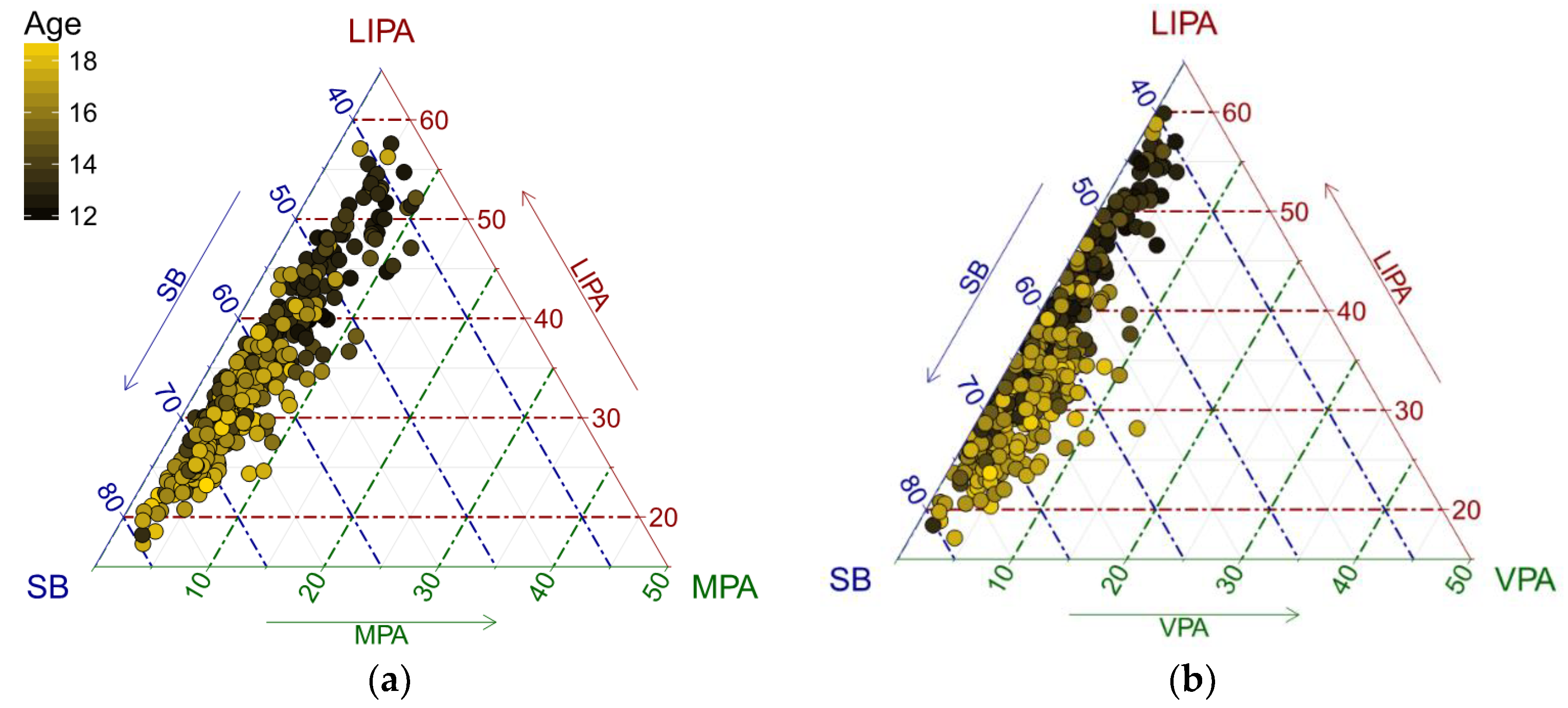
In the following part, we investigate how age is associated with the structure of adolescents’ PA. To get an initial insight into the problem, the data were displayed in a ternary diagram, which is a standard tool for visualization of the simplex sample space for a three-part (sub)composition [
28]. A color gradient was used to distinguish PA points by age (
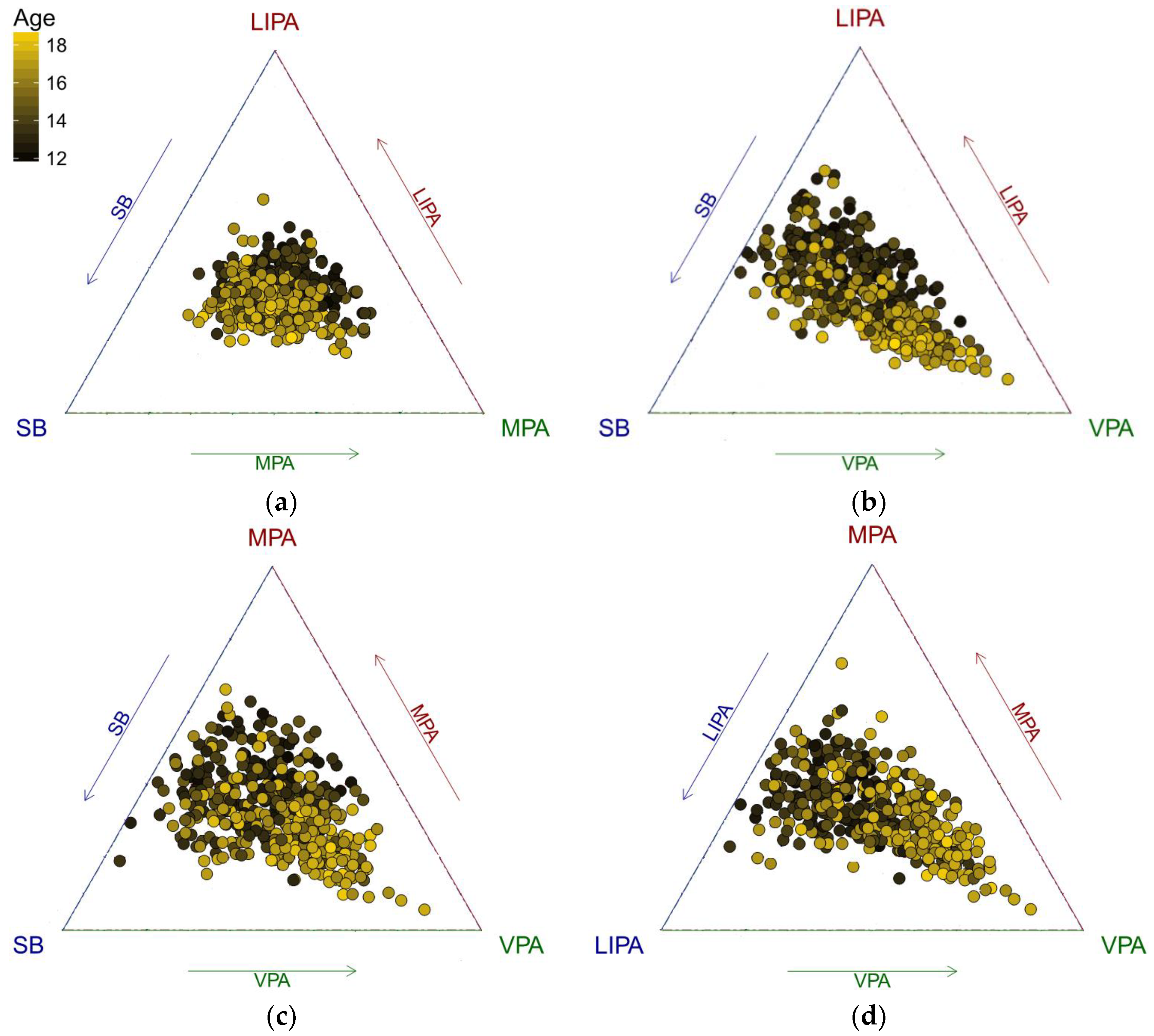
Figure 1). For a further insight, it is useful to plot centered data (
Figure 2), particularly when the data are concentrated near the borders of the ternary diagram. The reason for this is the relative scale of compositional data; near the borders, the ratios between the components change substantially more than near the barycenter and this is reflected by larger distances between points in terms of the Aitchison geometry [
39]. It means that near the borders, outlying observations might easily be overlooked due to the small relative values of compositional parts. Moreover, the centering operation can be robustified by computing a robust center measure, as it was the case of the present analysis, instead of the common compositional center in order to prevent possible masking of outliers. For the compositional center, using the geometric mean is a default choice in the compositional framework [
28]. The robust compositional mean is then obtained by using the MCD estimator on pivot coordinates, and subsequently back-transforming, which results in a weighted geometric mean [
38].
An exchange between LIPA and SB time as adolescents get older is apparent (
Figure 1 and
Figure 2). It is interesting to see some outliers towards VPA that might indicate intensive sport activities of adolescents. Even in the PA sub-composition, a similar trend can be observed.
The relationship between age and MB composition was further examined via a regression analysis. The MB composition was set as the response and age as the explanatory variable. Thus, the following regression model (4) was considered:
Robust MM-estimation was conducted while focusing on the coefficient from each of the four models informing about increasing or decreasing dominance of the part isolated in the response pivot coordinate.
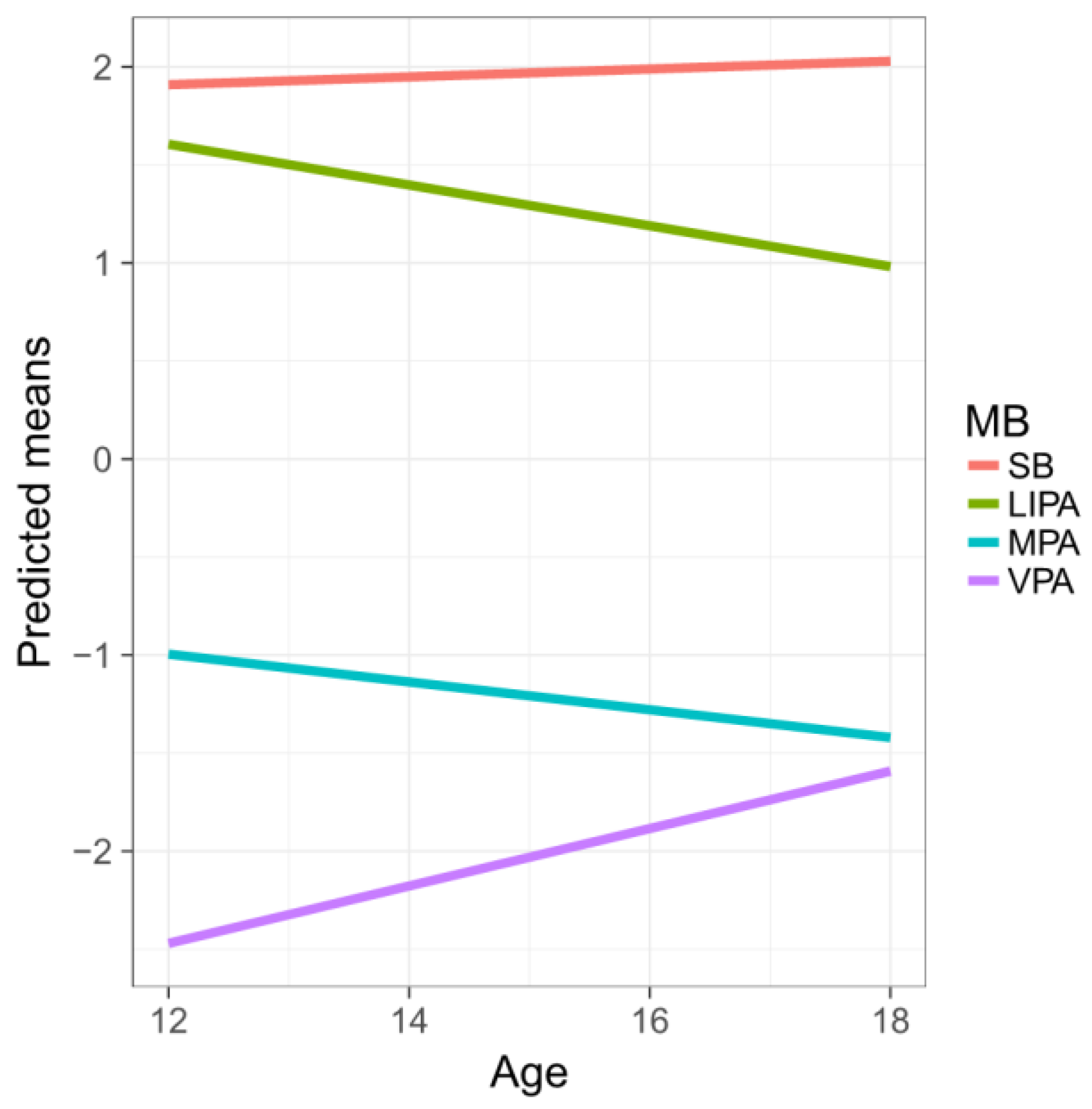
The results displayed in
Table 4 support the anticipated positive association between age and the relative dominances of SB and VPA (with respect to the average contribution of the other parts). Conversely, the relative dominances of LIPA and MPA were negatively associated with age. The older they get, Czech adolescents tend to spend more time in SB and VPA at the expense of LIPA and MPA.
Figure 3 shows the predicted means for the first pivot coordinates with increasing age. Indeed, the most dramatic difference is observed for VPA, reflecting on previous observations. Note that R
2 values differ due to the different response coordinates.
3.3. The Association between Movement Behaviour and Obesity
Finally, we examined the differences in PA between adolescents from different weight groups.
Table 5 shows the compositional center of MB computed for all adolescents, compared with that in the underweight/normal and overweight/obese groups.
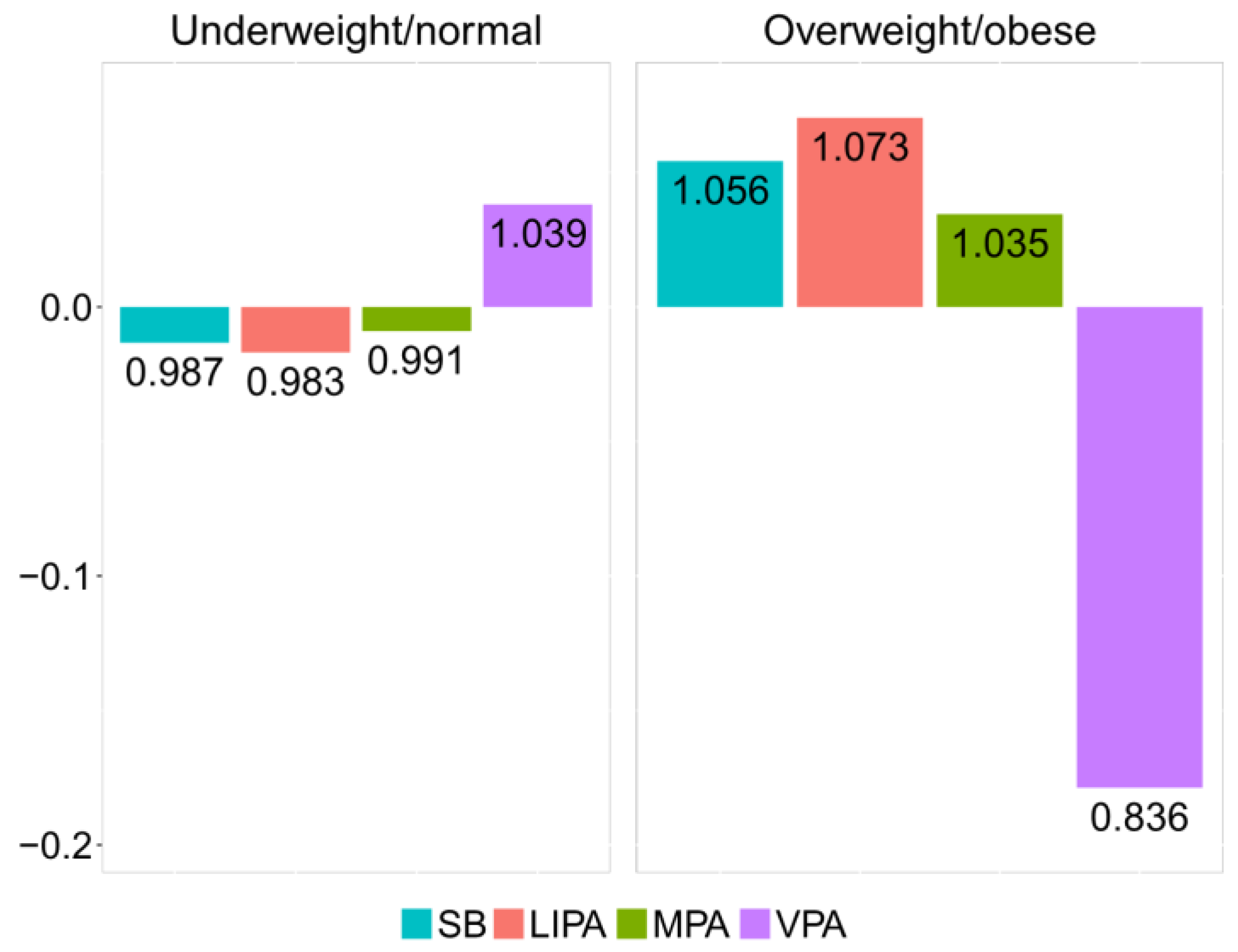
The relative difference between underweight/normal and overweight/obese groups can be visualized by the compositional mean barplot [
12] (
Figure 4). The vertical axis values correspond to the log-ratios between the respective group centers and the overall center after data centering. The numeric labels of the bars inform about the relative differences with respect to the overall center. Thus, in the overweight/obese group, the proportion of time spent in VPA is reduced by 16.4% relatively to the overall center. Accordingly, VPA stands out as a key driver of the difference between the underweight/normal and overweight/obese groups, stressing on the lack of VPA time in overweight/obese adolescents.
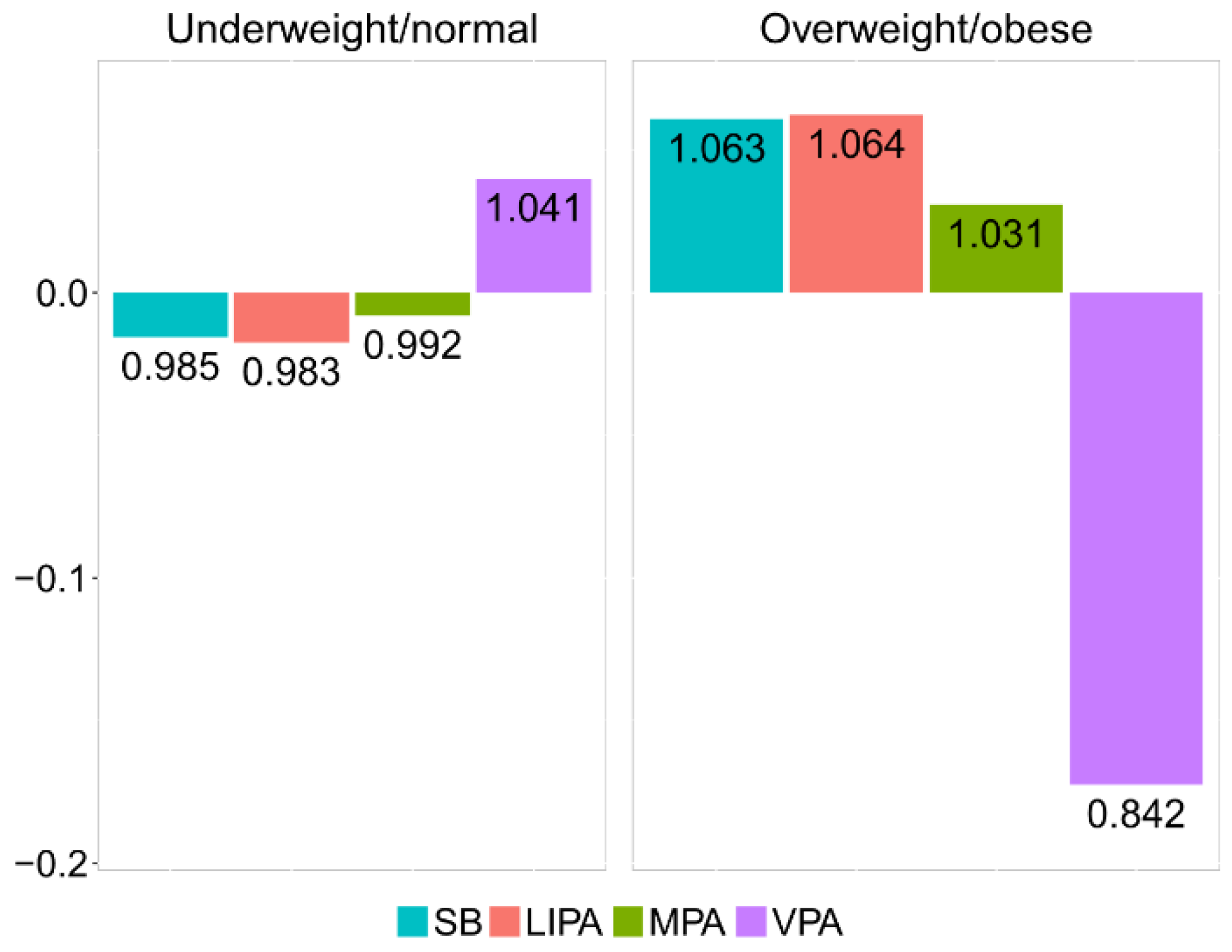
In order to investigate the effect of outlying observations in the whole data set, as well as in both weight groups, robust counterparts of the compositional centers and barplots were considered (
Table 6 and
Figure 5). Although no dramatic changes can be observed in this case, some patterns are evident. Specifically, it can be observed that the robust center for VPA was slightly higher in all groups (compared to the classical one shown in
Table 5) and that the relative difference in VPA was smaller in both groups (
Figure 5). This suggests the presence of some outliers (those with very low relative contribution of VPA to PA) in both groups of observations. Downplaying them thus provides a more reliable result that better summarizes adolescents’ behavior. Particularly, the robust compositional mean barplot (
Figure 5) shows that the proportion of time spent in VPA in the overweight/obese group was reduced by 15.8%, relative to the overall mean composition.
The continuous character of zBMI was used to obtain more precise information about the association between PA and obesity using an appropriate regression model. zBMI was set as the response in the regression model (3) and the parts of the MB composition as covariates. Using the notation (6), the corresponding four models are as follows:
where
are pivot coordinates for the MB composition resulting from sequential placement of each part originally in position
at the first position (i.e.,
= 1,2,3,4 for SB, LIPA, MPA and VPA, respectively). We focused on the estimate
from each of the four models, which refers to the dominance of the corresponding part within the given composition. These models were applied in the PA context in [
12,
40] using standard LS estimation. Here, robust MM-estimation was used instead to lessen the influence of outlying observations.
The results of MM-regression are displayed in
Table 7. Accordingly, when considering just statistically significant coefficients (
p-value < 0.05) the relative dominance of SB (with respect to the average contribution of the other parts) was in positive relationship with zBMI, while the relative dominance of VPA was in inverse relationship with zBMI. Those who spend too much time in SB and not enough time in VPA tend to have higher BMI.
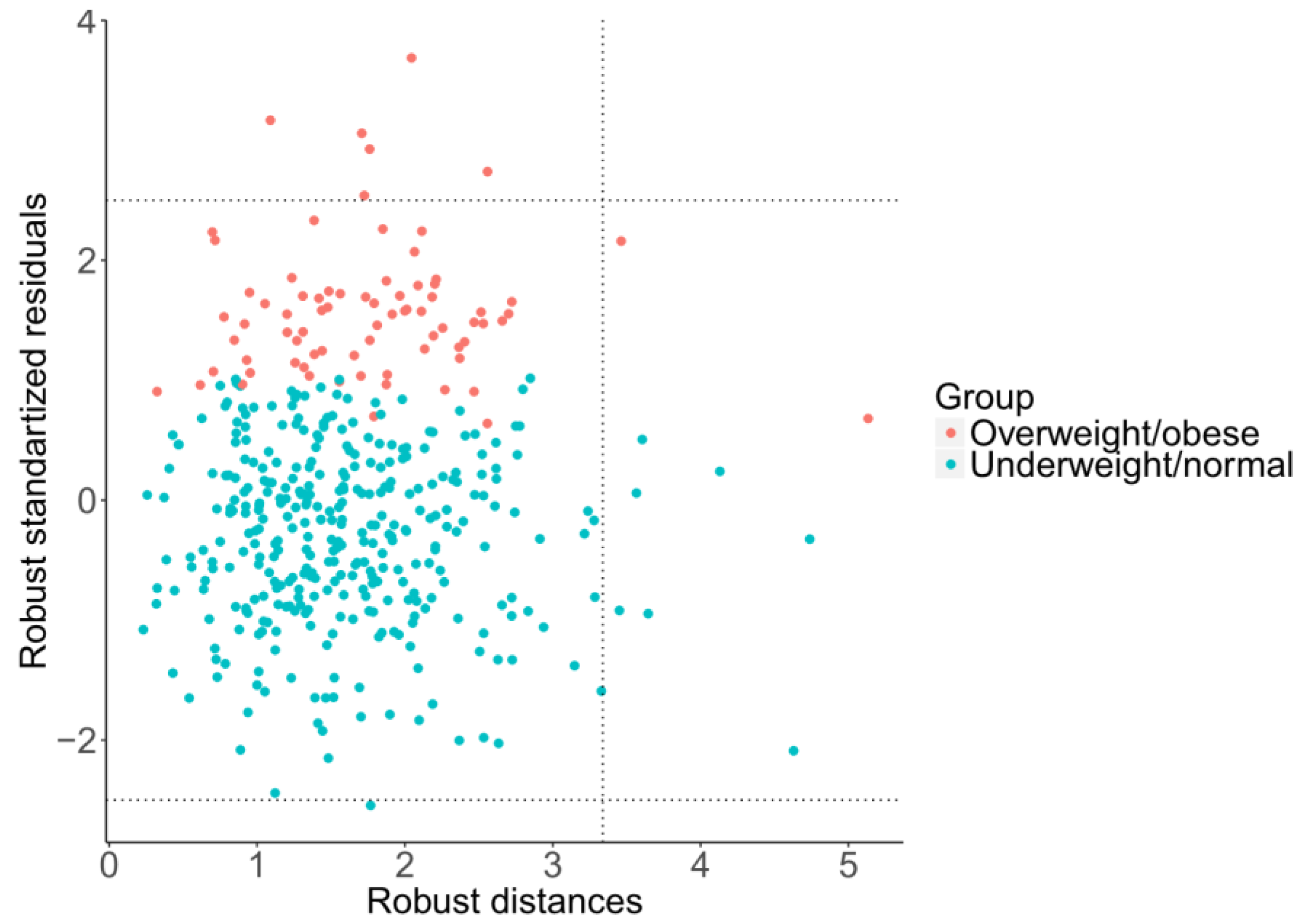
Moreover, using robust regression, it is possible to investigate the effects of outlying observations using a diagnostic plot of standardized residuals versus robust distances of the predictor variables [
26], as shown in
Figure 6. Following Rousseeuw [
31], this enables us to distinguish three basic types of outliers: good leverage points, bad leverage points, and vertical outliers. Good leverage points are points (formed by response values and predictors) that are close to the regression plane; that is, good leverage points improve the precision of the regression coefficients. Bad leverage points are points that are far from the regression plane; that is, bad leverage points reduce the precision of the regression coefficients. Vertical outliers are outlying observations caused by the response, again negatively affecting the regression outputs. In this case, just one diagnostic plot (
Figure 6) covers all four regression models due to mutual relationships between pivot coordinates. It can be observed that, although there are some good leverage points (middle right rectangular), bad leverage points (upper or bottom right rectangular) do not occur here. The vertical outliers (upper or bottom left rectangular) appear mostly in the overweight/obese group of adolescents, which indicates that this group has more outliers than the underweight/normal one, including some extremely obese adolescents. Despite the absence of bad leverage points, the presence of vertical outliers indicates possible differences between classical (LS) and robust regression models.
For this reason, it was sensible to perform a comparison with classical LS estimates (
Table 8). MM-regression outputs (
Table 7) show a stronger relationship between zBMI and relative dominance of
SB, while the association between zBMI and relative dominance of VPA is slightly weaker (which is in line with the barplots in
Figure 4 and
Figure 5).
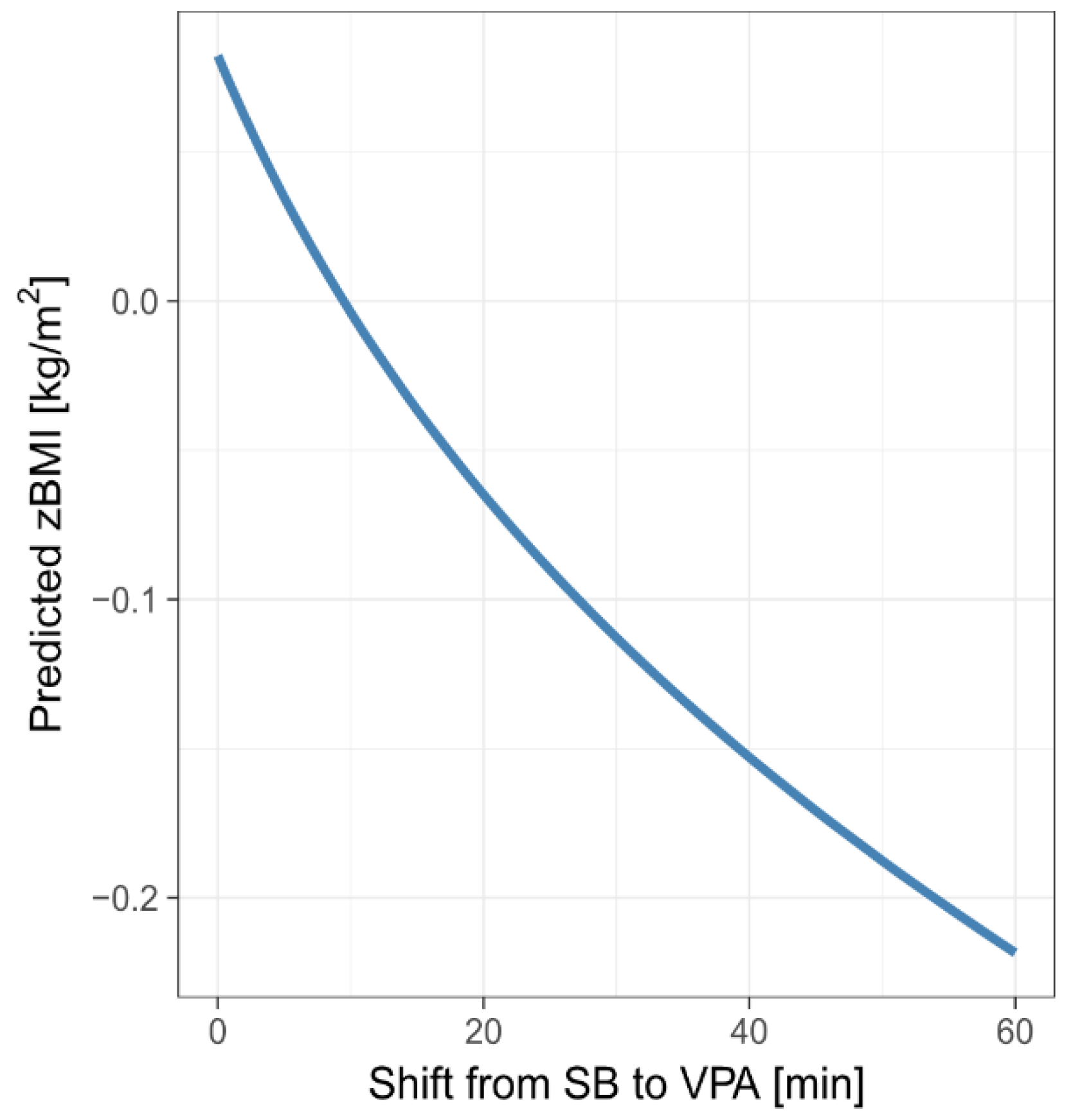
The graph in
Figure 7 shows predicted zBMI for the mean MB composition (MM-estimates are considered) when re-allocating between 0 and 60 min from SB to VPA. We considered the total MB composition to stand for 16 h, assuming 8 h of sleep a day. The predicted zBMI associated with a 60-min SB-to-VPA re-allocation was reduced by 0.30. However, due to the small value of R
2, the predictive power of these graph is rather limited.
For example, the difference in predicted zBMI is 0.30 kg/m
2 after re-allocating 60 min. For an average girl resp. boy from our sample (15.1 years old with a height of 1.64 m resp. 1.71 m), this would mean a 2.05 kg resp. 1.91 kg reduction in weight. For more details, see
Table 9.
4. Discussion
This study presented a concise framework for robust CODA, mainly focusing on regression problems, in the presence of outlying observations, which often occur in real-world data sets. Although there is an increasing application of CODA methods in diverse fields of the natural [
32,
39,
41,
42,
43] and social sciences [
17,
44,
45,
46,
47], classical statistical inference methods have been primarily used so far. Robust CODA methods have been used almost exclusively in geochemical applications [
48,
49,
50]. This paper demonstrates the potential of robust CODA using movement behavior data of Czech adolescents. Robust counterparts have been also introduced for common compositional descriptive statistics, including a novel way to conduct robust data centering. The key point of robust statistical methods in a compositional context is that observations with large absolute values are not necessarily those to be downplayed, but rather the focus is on aberrant log-ratios between the parts of the composition. By comparing the classical and robust variation matrices (
Table 1 and
Table 2), this seems to be particularly the case of pairwise log-ratios involving VPA in the present case study, which was already hinted by the ternary diagram visualization. Outliers affect classical tools such as the compositional mean barplot and ordinary LS regression; as well as the compositional centre and variation matrix used as basic descriptive statistics in CODA. The robust counterparts introduced in this work just focus on the majority of the data avoiding the extremes, hence providing more stable tools in the presence of outlying observations. They also help to reveal potential outliers, to be further analyzed and potentially suppressed. Moreover, robust centering highlights possible aberrant observations that would be masked in a classical case, where the center itself is affected by aberrant observations, particularly those close to the boundaries of the simplex. Robust regression also enabled to create a diagnostic plot to reveal vertical outliers and leverage points and enhance interpretation of the modelling; of course, similar diagnostics would also be possible for other robust regression models discussed in the manuscript. The present study demonstrated the role of orthonormal coordinates in the representation of compositional covariates, leading to the same goodness-of-fit measures and diagnostic plots for all possible choices of pivot coordinates.
The present study includes three main findings. Firstly, by using the classical compositional variation matrix, SB and LIPA showed the highest proportionality. These two parts also showed the highest proportionality (except for combination with sleep) in the study conducted by Carson et al. [
16], where the same approach was applied. Using a robust compositional variation matrix, LIPA and MPA showed the highest proportionality, although SB and LIPA still retained a strong relative relationship. Moreover, both approaches have shown the highest log-ratio variances in cases where VPA was involved (reduced by using the robust approach though), indicating a possible presence of aberrant log-ratios. Although there were mostly small differences between the classical and robust variation matrices in this illustrative application (up to those variances where VPA was involved), it is well-established that the use of robust statistical methods in general tends to improve estimates in cases where an increasing presence of outliers distorts the information in the data set [
36]. Secondly, an interesting feature was revealed when age was considered as an explanatory variable. Namely, with higher age the relative contributions of SB was expected to increase and VPA was expected to decrease. There is consistent evidence that SB increases with age in school-aged children and adolescents [
51], but an increase in VPA with age is a rather unexpected finding. Given the higher number of outliers towards VPA (
Figure 1 and
Figure 2), this might be explained by intense sport activities of some adolescents pulling up the trend, even when using robust regression to quantify the relationships. The effect of VPA can be better seen in
Figure 2 using centered compositions, which helps to avoid the artifacts of the relative scale of the data near the borders of the ternary diagram and facilitates the interpretation of distances between points in an (almost) usual, Euclidean, sense. Regarding the fact that in the relative scale the ratios are responsible for dissimilarities between compositions, low proportions of some components (here MPA and VPA in particular with respect to SB and LIPA, respectively; see
Figure 1) might also be a source of outliers, whose impact is reduced automatically by using robust centering, instead of the classical one in
Figure 2. Finally, a significant relationship between VPA and adolescents’ obesity was demonstrated. In the overweight/obese group, the relative time spent in VPA was reduced by 15.8% to the overall mean movement behavior composition, the highest reduction (using moderate-to-vigorous PA though) to overall mean composition in obese group was also found in [
16].
In summary, this study has systematically considered and presented CODA regression methods which are, by construction, robust to the presence of outlying observations. They were discussed in relation to standard ‘non-robust’ regression models, as those applied in previous studies using movement behavior data [
12,
30,
40]. Robust MM regression, which aims to retain robustness and resistance against outliers whilst gaining in statistical efficiency, is a proper tool for dealing with real-world data with natural presence of extreme observations; similar goals are also achieved by robust orthogonal regression. Accordingly, robust regression enables to extract the main trends in the data although we should be aware that from the methodological perspective, robust estimators are less efficient (precise) than the classical ones. At the same time, the associated diagnostics tools help to reveal deviating data points, which contributes to enhanced interpretation of the results. Although it is formally well-established that robust methods are generally less sensible to the presence of outlying observations, a simulation study would be necessary to determine and test for the significance of the differences in estimates between classical and robust models in an application. In our case study, we relied just on the general fact that robust estimators take into account majority of data and thus downgrade the influence of aberrant observations.
There are several strengths and limitations to this study that should be discussed. The availability of data of a relatively large number of individuals supported the statistical power of the regression significance tests and facilitated the application of robust statistical methods. Accordingly, trustworthy trends in movement behavior composition of adolescents were revealed, including those with respect to variables such as zBMI and age. The estimate of SB and PA used in this study was measured by the hip-worn ActiGraph accelerometer, the most commonly used validated accelerometer in PA research. However, due to the design of the study, the participants did not wear the accelerometer overnight, so we were not able to conduct an analysis on 24-h time budget data.
The accelerometers were set-up to record data at 60-s epochs, which can result in lower estimates of accelerometer-determined MPA and VPA [
52]. The SB and PA intensities were only analyzed using Evenson cut-points. It is assumed that the decision of selecting among various cut-points significantly influences the levels of MPA and VPA [
4]. Finally, BMI was calculated from self-reported height and weight. All this may introduce bias in relationship between SB, PA and obesity. Moreover, it was not possible to infer causality relationships from this observational cross-sectional study or totally discard the potential influence of unmeasured confounding variables.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}