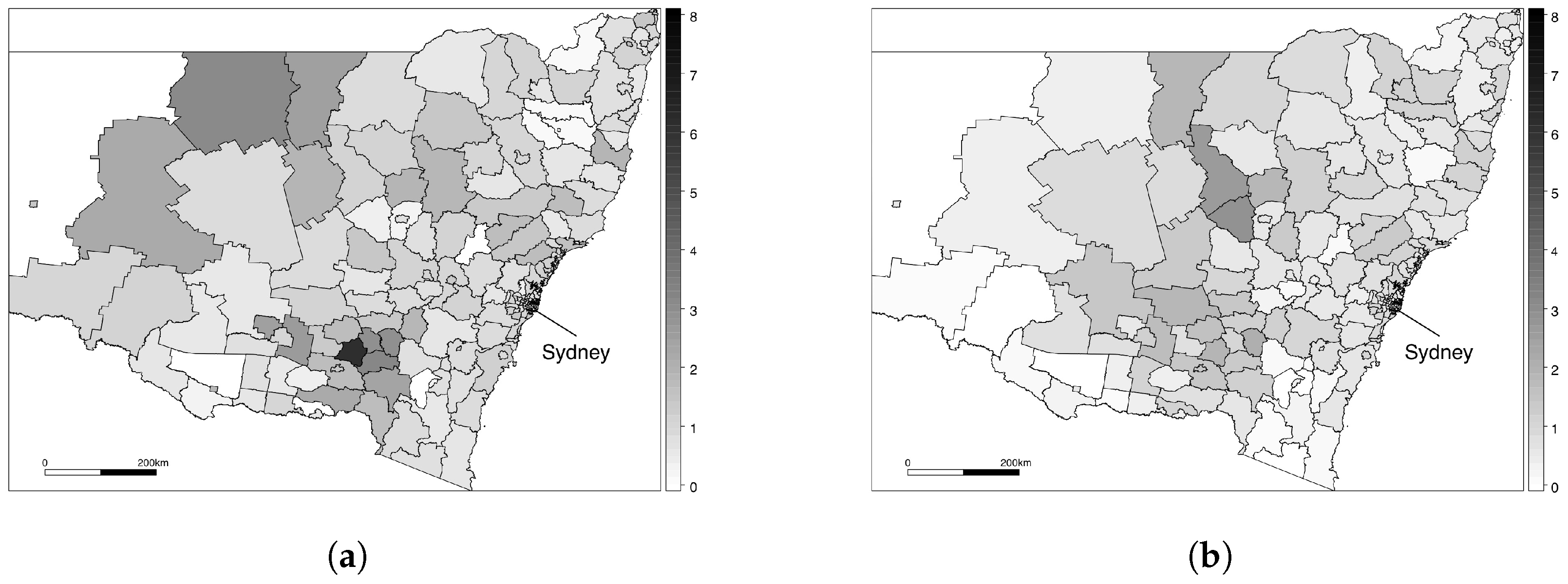
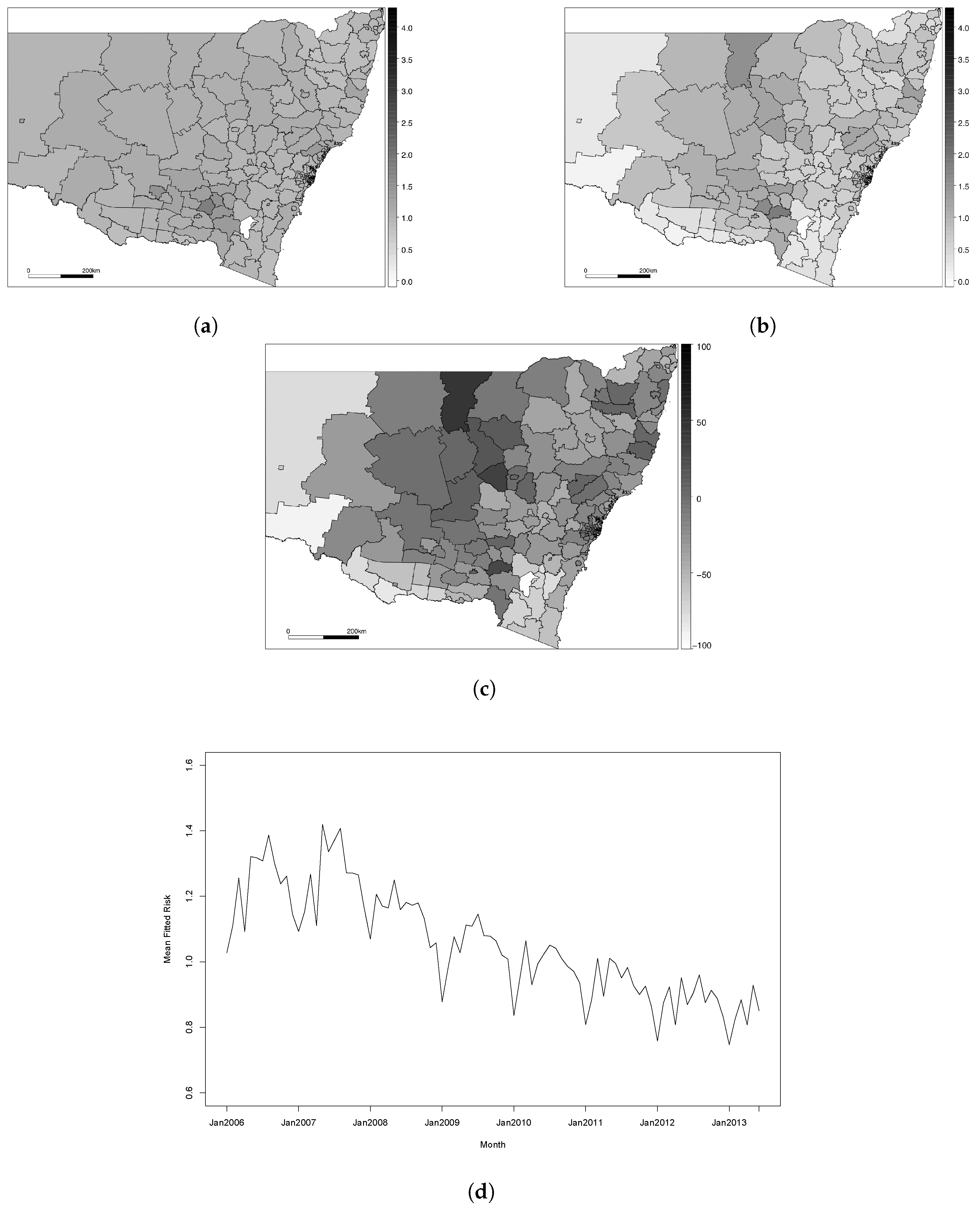
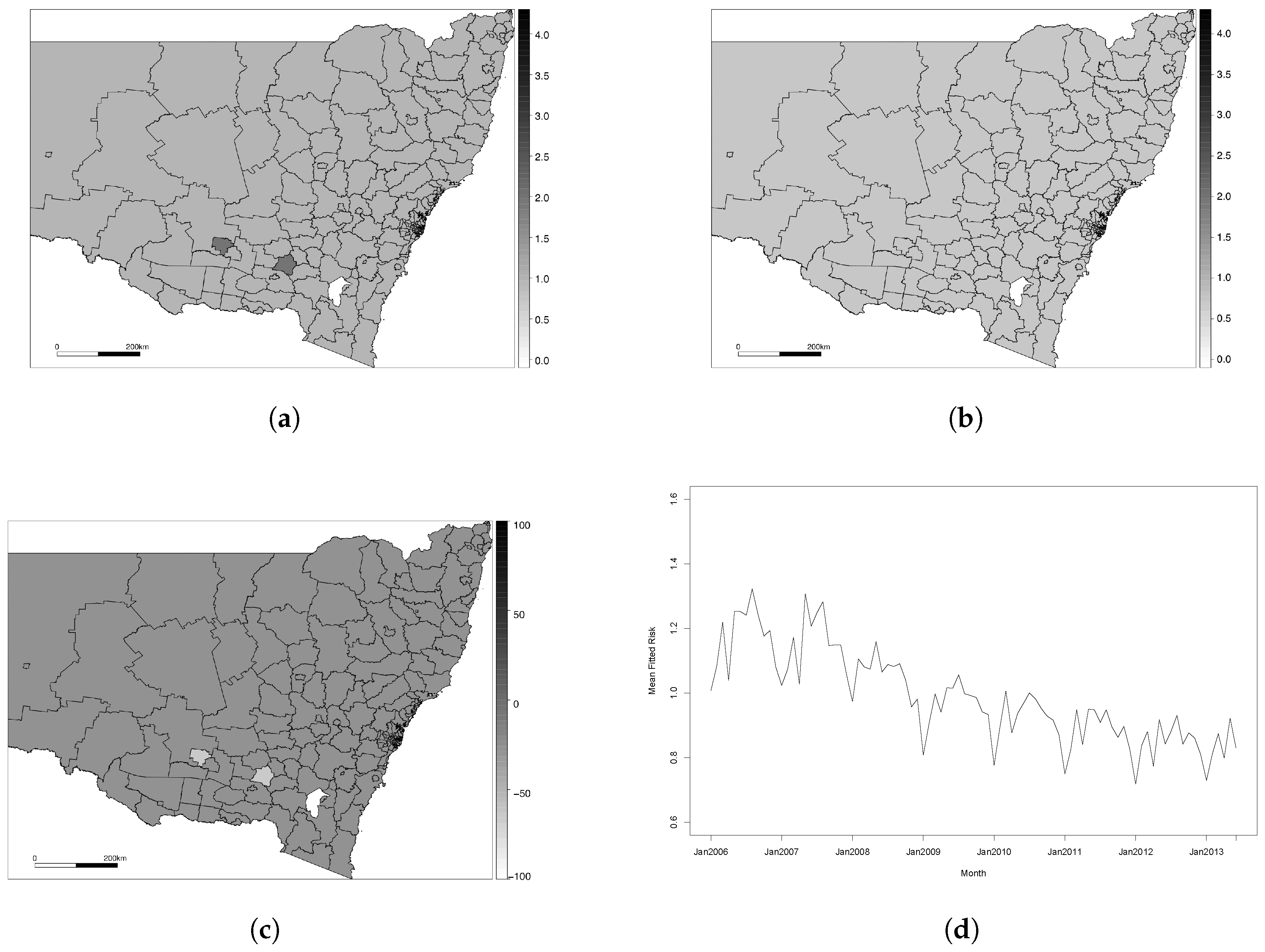
The spatial (and spatio-temporal) modelling literature centres around two main data types: areal (or lattice) and point-referenced (or geostatistical). Point-referenced data structures are based on the exact geographical location of an observation being recorded, generally in the form of latitude and longitude co-ordinates. This form of data is commonly used for monitoring environmental outcomes, where spatial modelling approaches can be used to characterise the nature of an environmental outcome across the entire study region based on a finite set of monitoring stations. Areal data structures are based on the study region being partitioned into a set of non-overlapping subregions known as areal units—for example, a county being divided into a set of postcode areas. Areal data are commonly used in health applications, where confidentiality issues prevent the exact geographical locations of disease cases being recorded. Instead, only the patient’s areal unit is recorded, and the data consists of an aggregated count for each individual areal unit. Thus, it is possible to conceptualise areal data as an aggregation of point-level data. Our ischaemic heart disease data is areal, and, therefore, this section will focus on discussing existing methodology for areal data. We will first outline the methodology used in a spatial context, and then show how this can be extended to account for spatio-temporal data.
2.1. Spatial Modelling
The aim of areal modelling is to estimate the occurence rate of an outcome (such as disease risk) in each areal unit, thus providing a set of risk estimates that cover the entire region. We may also be interested in identifying the spatial extent of covariate effects. Consider a study region , partitioned into n non-overlapping areal units such that = {}. A response is observed in each areal unit, thus providing a set of response data . Area-level covariate information may also be available. In most cases, it is important to account for differences in population demographics across the study region, since some subregions are likely to contain a larger at-risk population. For example, areas which have a higher percentage of elderly people are likely to have higher rates of heart disease than those with a younger population, but this does not necessarily mean that there is any underlying in disease risk rate between the regions. We can account for these demographic differences by constructing a set of expected disease counts , where is the expected number of disease cases in area i. These expected counts can be constructed using either internal or external standardisation based on the age and sex demographics of the population within each areal unit.
Based on these expected counts, one simple measure of disease risk is the standardised incidence ratio (SIR), which is computed for area
i as
An SIR value larger than 1 indicates that a region has a higher than expected disease risk, while an SIR less than 1 implies a lower than expected risk. The SIR provides a useful exploratory tool but has the major disadvantage that it considers each areal unit independently and does not account for any form of spatial structure in the data. Additionally, in cases where a rare disease or a small population is being studied, some areal units may have a very low expected value , and the SIR would be susceptible to small random fluctuations in the response .
It is therefore more common to use a generalised linear model to estimate disease risk. Models for spatial data are based on an underlying belief that there is some form of correlation between areal units that are close to each other geographically. Given that the response is almost always based on count data, modelling is generally based on a Poisson log-linear model of the following form:
Here,
represents the mean risk for area
i,
is the set of coefficients relating to the covariates
X and
is a random effect specific to area
i, used to account for unexplained spatial autocorrelation. The set of random effects
are commonly represented by a conditional autoregressive (CAR) prior distribution. CAR priors can typically be specified via a multivariate normal distribution
with a covariance function Σ that reflects the spatial correlation between the random effects. Besag et al. [
11] proposed the intrinsic CAR prior with covariance matrix
, where
is a conditional variance parameter and
D and
W are matrices determined by the neighbourhood structure of the data. D is a diagonal matrix where the
ith entry on the diagonal is equal to the number of neighbours for areal unit
i.
W is a neighbourhood matrix which is defined as follows:
Here,
means that areas
i and
are neighbours. Typically, areas are defined as neighbours if they are adjacent and thus share a common border, though other specifications are also possible [
12].
This specification does not have a parameter that controls the strength of the spatial correlation, and is thus inappropriate in cases with weak spatial correlation. The work of Cressie [
13] and Leroux et al. [
14] led to a more generalised version of the original that accounted for different strengths of spatial correlation using an additional smoothing parameter
ρ. The covariance matrix is redefined as
, where
ρ controls the level of spatial correlation present, with
corresponding exactly to the intrinsic CAR model outlined above, and
corresponding to complete spatial independence. It is generally straightforward to estimate
ρ from the data.
An alternative method for handling different strengths of spatial correlation is the Besag–York–Mollie (BYM) model, proposed by Besag et al. [
11]. The BYM model extends the intrinsic CAR model by including a set of spatially independent random effects,
θ such that:
where
. Different strengths of spatial correlation can be accounted for by varying the relative sizes of the random effects
φ and
θ. The main drawback of this approach is that only the sum
is identifiable for each region, but, nonetheless, the BYM approach remains popular within the spatial and spatio-temporal literature.
2.2. Spatio-Temporal Modelling
The spatial models outlined in
Section 2.1 apply to data observed at a single time point, but there are many cases where data from multiple time points are available. In addition to the spatial correlations described in the previous section, these data will also have temporal correlations, with observations at consecutive time points having more in common than those further apart. There is also the possibility of a space–time interaction, given that different areas may have different temporal trends, and these trends may be more similar in areas which are closer together geographically. Consider the case where data are collected across
J discrete time points at each of the
n areal units. We have response data
where
is the set of
J observations for area
i. We consider the case where the timepoints are the same at each location, though this is not necessary for all models.
The majority of spatio-temporal models for areal data have been developed by extending the spatial model (
2) as follows:
where
is a function that captures spatial correlation,
is a function for temporal correlation and
is a function capturing space–time interaction. However, while this formulation is conceptually straightforward, implementation can be difficult, especially with larger datasets. The biggest challenge in such approaches is making a choice for the spatio-temporal term
that accurately reflects the underlying spatio-temporal risk structure, and, in particular, the possibility of different trends occurring in different regions. The remainder of this section provides an overview of the existing literature for spatio-temporal modelling.
Table 1 provides a brief summary of the literature covered in this section, and, in particular, the types of spatial, temporal and spatio-temporal effects used in each method.
One of the earliest spatio-temporal models for areal data was proposed by Bernardinelli et al. [
6], who suggested a model where each areal unit has a separate linear trend. Here,
, a spatial random effect,
, a linear trend over time and
, the area-specific deviation from the trend. Both
φ and
η are modelled by a CAR prior, as outlined in
Section 2.1. This approach therefore allows each areal unit to have its own intercept modelled by
and its own slope modelled by
. Although this approach is flexible in allowing each areal unit to have its own trend, it is restrictive in requiring these trends to be linear, which may not be appropriate in many applications.
An alternative approach was outlined by Waller et al. [
15], who proposed a spatio-temporal extension of the BYM model (
4). The authors propose fitting a separate BYM model at each time point, which is
and
, where
is a set of random effects at time
j modelled by a CAR prior, and
is a set of independent random effects. This formulation allows a different spatial pattern to be estimated at each time point, with the patterns being uncorrelated from one time point to the next. A similar approach is outlined by Xia and Carlin [
16], who also include an age-group specific term to allow different trends for different age groups. However, these approaches make no attempt at smoothing over time, which may not be realistic in practice. One would expect some sort of temporal correlation to exist in most spatio-temporal datasets, and models should ideally account for this.
An alternative temporal extension of the BYM model is proposed by Knorr-Held and Besag [
18]. They propose a model consisting of a pair of spatial random effects and a pair of temporal effects, with each pair consisting of one structured term and one unstructured term. This model has
,
and
, where
φ is modelled by a CAR prior,
α follows a first order random walk in time and (
) represent independent random effects with mean 0 and variance
ϵ. The authors acknowledge that their model combines space and time additively and does not make provisions for cases where there is an interaction between time and space.
Knorr-Held [
20] addresses this problem by extending [
18] to include an additive space–time interaction term
. This interaction term has a covariance structure specified by the Kronecker product of the structures of the random effects which are interacting. Of particular interest is the case where the spatially correlated random effect
φ and the temporally correlated random effect
α interact. In this case, the spatio-temporal random effect
δ has a specification that combines a spatial CAR model and a random walk in time. These approaches are thus able to account for spatial and temporal trends as well as potential area-specific differences in trends, but, over longer time periods, the random walk may not capture the complexity of the temporal trends.
Non-parametric smoothing approaches provide an alternative way to capture temporal trends in spatio-temporal models. One of the first such approaches was proposed by MacNab and Dean [
7], who outlined a generalised additive mixed model for estimating disease risk, combining a CAR model for the spatial pattern (
) and a set of smooth functions known as B-splines [
31] for the temporal trends. The authors discuss two possible formulations for the space–time interaction term: one parametric and one non-parametric. The parametric approach follows [
6] by allowing spatially correlated area-specific linear deviations from the global trend by setting
, where
η follows a CAR prior. The non-parametric approach models the spatio-temporal term
using area-specific B-splines for each region, thus allowing nonlinear area-specific deviations. The interaction term is spatially correlated in the parametric approach, but not in the non-parametric approach, where the area-specific deviations are assumed to be independent. However, the non-parametric approach allows a great deal more flexibility and may therefore provide a more realistic estimation of temporal trends, particularly in applications covering longer time periods.
MacNab and Gustafson [
32] proposed a method that combined both of these appealing properties by including spatially-varying B-splines that allow the interaction term to be nonlinear but still spatially correlated. This is achieved by allowing the set of coefficients of the area-specific B-splines to follow a CAR prior, thus inducing correlation in the spline coefficients between areas which are close together. An alternative approach to modelling the space–time interaction in this model form was proposed by Torabi and Rosychuk [
27], who proposed a covariance structure similar to that used in the fully-parametric form in [
20]. Here,
is modelled with a covariance matrix given by the Kronecker product of the spatial random effects and the B-splines. These approaches are all based on using B-splines for smoothing, but more flexible smoothing approaches are available, and these could be more appropriate in certain applications.
MacNab [
23] compared the B-spline smoothing approach to a number of specifications which used either smoothing splines [
33] or P-splines [
34]. For the B-spline model, the author had to run multiple models, each with a different number of knots, in order to select the optimal choice, while the smoothing spline and P-spline approaches allow the suitable number of knots to be selected automatically, which has obvious computational advantages. However, the author concluded that these more flexible smoothing approaches were more sensitive to the choice of hyperprior in cases where the amount of data was limited. Nonetheless, it was noted that their performance would be likely to improve for datasets with larger amounts of temporal data.
Ugarte et al. [
26] use the latitudes and longitudes of the centroid of the areal units in order to apply a spatial spline smoothing approach that was originally proposed for point-referenced data [
35]. This approach uses separate P-splines for the spatial and temporal terms
and
, and then develops a spatio-temporal effect
by combining these P-splines via tensor products. The authors compare this approach to the CAR approach outlined in [
20] using an application of brain cancer in Spain, and identify a more gradual pattern of spatial smoothing for the P-splines approach, with this approach also exhibiting narrower confidence bands than the CAR approach. However, the authors did not carry out a simulation study to compare the performances of these methods in a case where the true spatial and temporal structure is known, and it is thus unclear whether these advantages persist across a variety of applications.
An alternative non-parametric approach to areal disease mapping is proposed by Kottas et al. [
24], who contend that the risk within an areal unit can be considered as the aggregation of a continuous spatial risk surface across the area. This approach cannot easily be represented in terms of the general formulation outlined above, but instead relies on modelling continuous spatial surfaces via spatial Dirichlet processes at each time point. The risk for each areal unit at each time point is modelled as the block average of this process over the required area, and temporal correlation can be induced in these spatial risk surfaces by introducing dependence on the risk surface at the previous time point. This approach provides a potential solution to some of the modelling issues inherent in the standard adjacency-based approach to areal disease mapping, such as non-standard areal unit sizes and non-constant spatial correlation, though the complexity of the design may not be suitable for data with a large temporal scale.
Bohning et al. [
19] proposed modelling the disease risk via a mixture model, with the space–time interaction terms being drawn from a mixture of Poisson distributions such that
, where
are a set of mixture weights and
is the
kth Poisson mixture component. Bohning [
21] extended this approach to outline two possible approaches for constructing spatio-temporal mixtures. The first approach identifies a separate mixture model at each time period, thus meaning that at each time point there may be a different set of Poisson distributions from which the mixture is drawn. The second approach fits a single mixture model such that the same set of Poisson distributions exists across all time points, though areas can move between these mixture components at different time points. The latter method is preferred because the mixture components remain the same at all time points and thus different time points are directly comparable. This approach has benefits in terms of identifying possible clusters in the disease risk pattern, but has been designed for applications with a small number of time points, and may become computationally complex for data with a larger temporal scale.
Both [
19,
21] discuss methods for introducing a random temporal effect into the mixture, but there is no attempt to account for spatial or temporal correlation. This approach is therefore unlikely to successfully estimate risk in cases where underlying spatial or temporal trends exist. However, Lawson et al. [
28] extended the mixture model idea from [
19] by introducing a spatial term
modelled via a CAR model and a temporal term
modelled via an autoregressive model. The mixture components are a set of temporal profiles that specify a time-dependent risk structure, and these are allocated to areal units based on a set of spatially-dependent weights that are modelled via a CAR model. The authors note that care must be taken to avoid identifiability issues within the model, and also point out a potential issue with label switching.
Another alternative specification was proposed by Congdon and Southall [
22], who suggest a combination of a CAR model and a set of area-specific autoregressive time series models [
17] such that
. Here,
, where
λ controls the amount of temporal correlation, and
ϵ is random noise. This means that each value depends on the value in that areal unit at the previous time point. This structure allows each areal unit to have a different temporal trend, but there is no structured space–time interaction, and thus no inherent spatial correlation in these area-specific trends. An alternative autoregressive approach which does account for structured space–time interaction was proposed by Martinez-Beneito et al. [
25]. The spatio-temporal interaction term
can be considered as a random effect with an extended CAR prior, which is based not only on the values of its neighbours at the current time point, but also the values of those neighbours at the previous time point. The term
can thus be considered to be a combination of a spatial CAR model and an autoregressive time series.
Another fully-parametric approach is outlined by Rushworth et al. [
30], who proposed a single set of random effects
to account for both spatial and temporal correlation. Here, the random effects at time point 1,
are modelled via a CAR prior with mean 0 as in (
3), and then random effects at subsequent time points are modelled via a CAR prior with mean
such that the random effects at one time point are dependent on the value of the random effect at the previous time point. Lee and Lawson [
29] propose a similar model that can simultaneously estimate disease risk and identify spatio-temporal disease clusters. This approach includes an additional piecewise constant clustering component
such that
. This component allows areal units in different clusters to have different baseline levels of disease risk. A maximum number of clusters is defined in advance, and an indicator function is used to allocate areal units to clusters. The clustering component can vary in size from one time point to the next, and an areal unit can be in different clusters at different time points. The authors outline a number of possible specifications of
, and simulation results show that simply setting
performs best in terms of accurately identifying clusters, while a specification based on that of [
30] provides the most accurate risk estimation. The former approach forces risk to be constant within clusters, which is unlikely to be realistic. Therefore, it seems more likely that the latter approach will have more applications in practice.




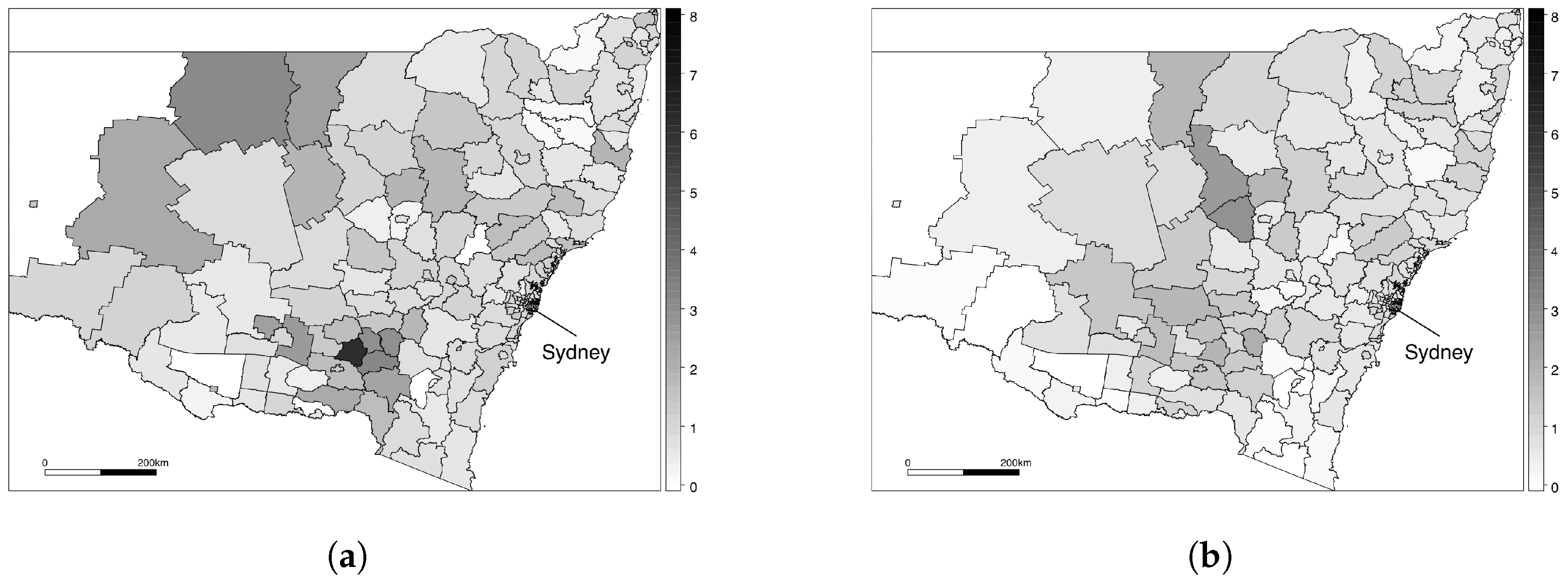
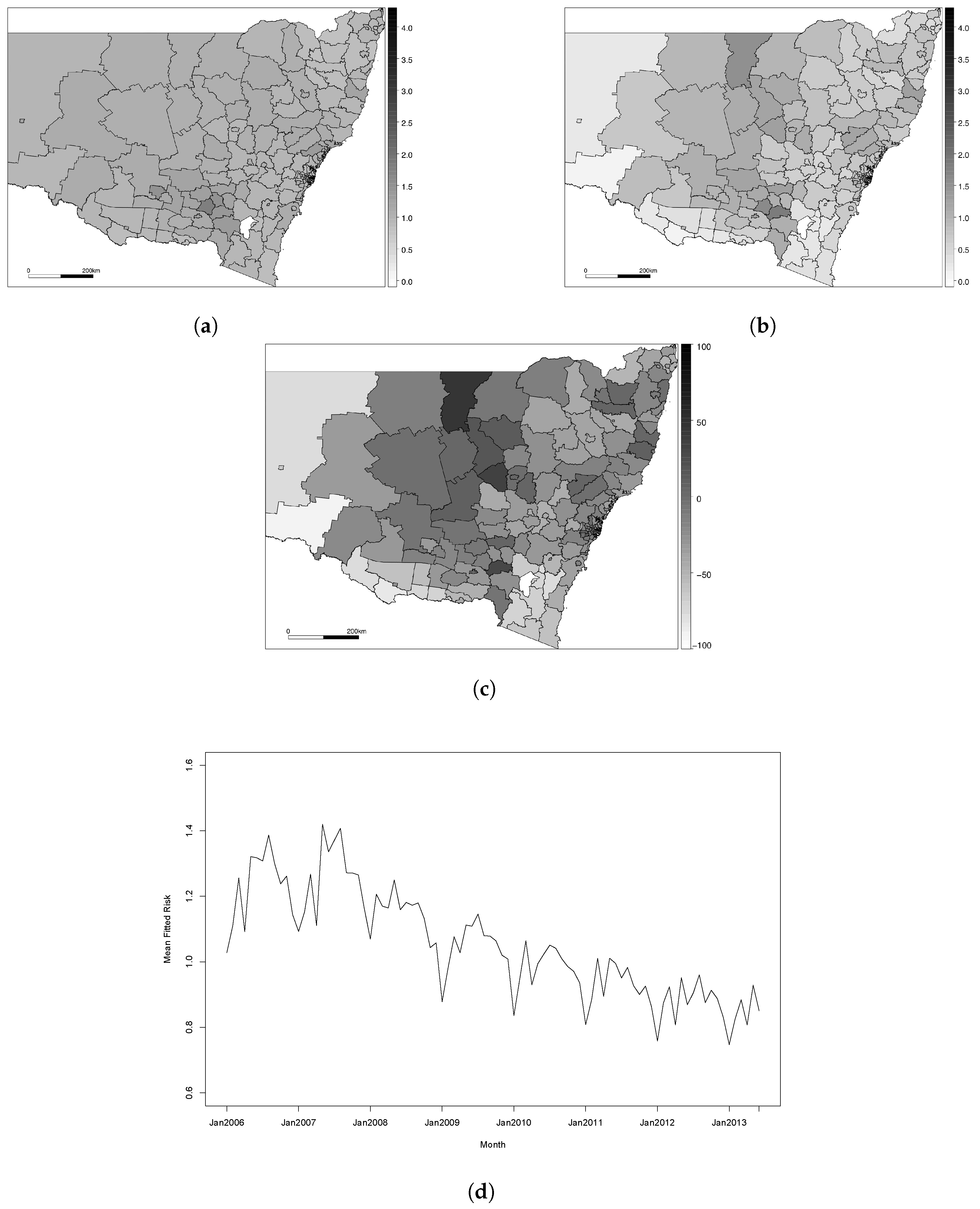
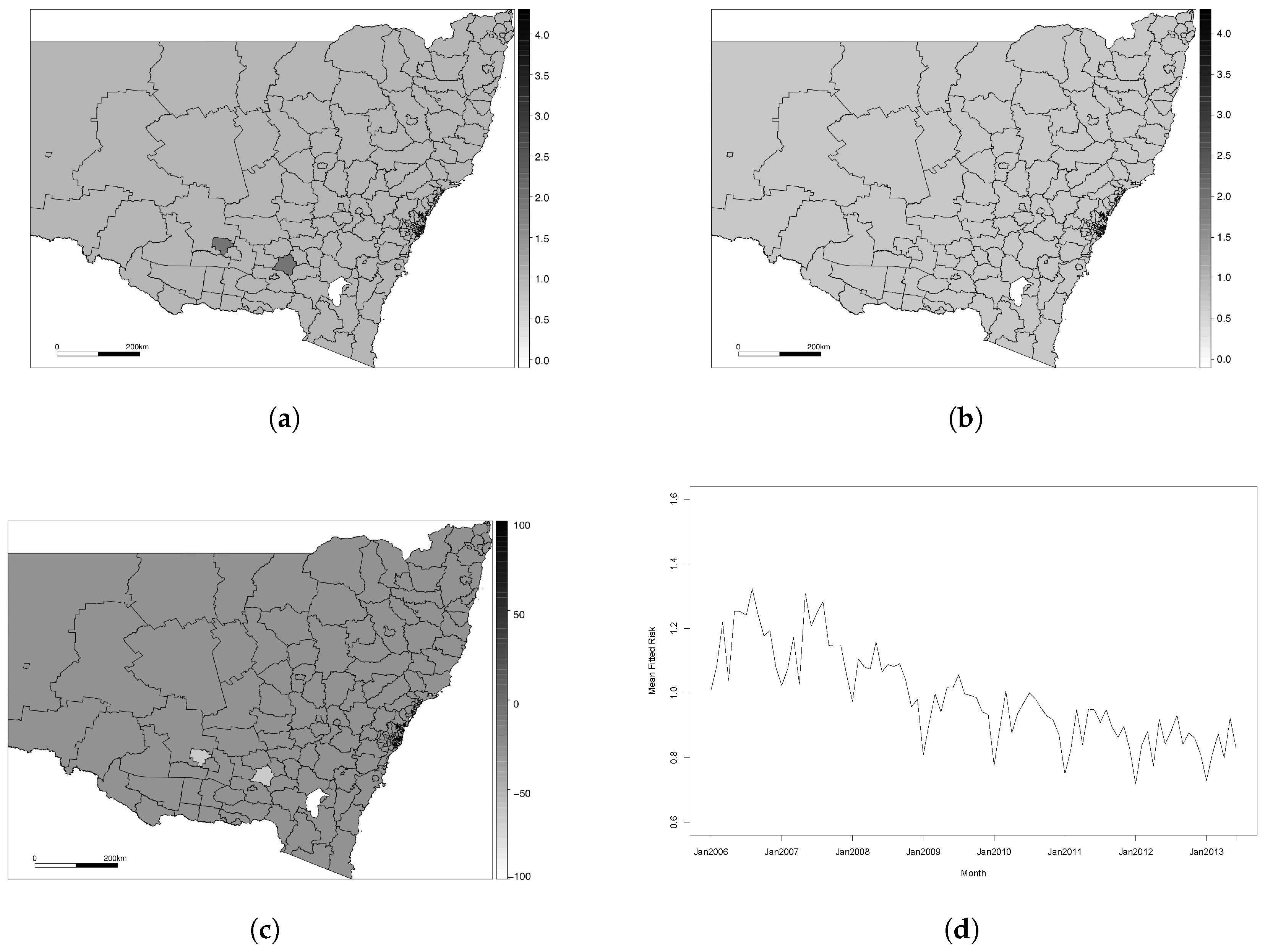
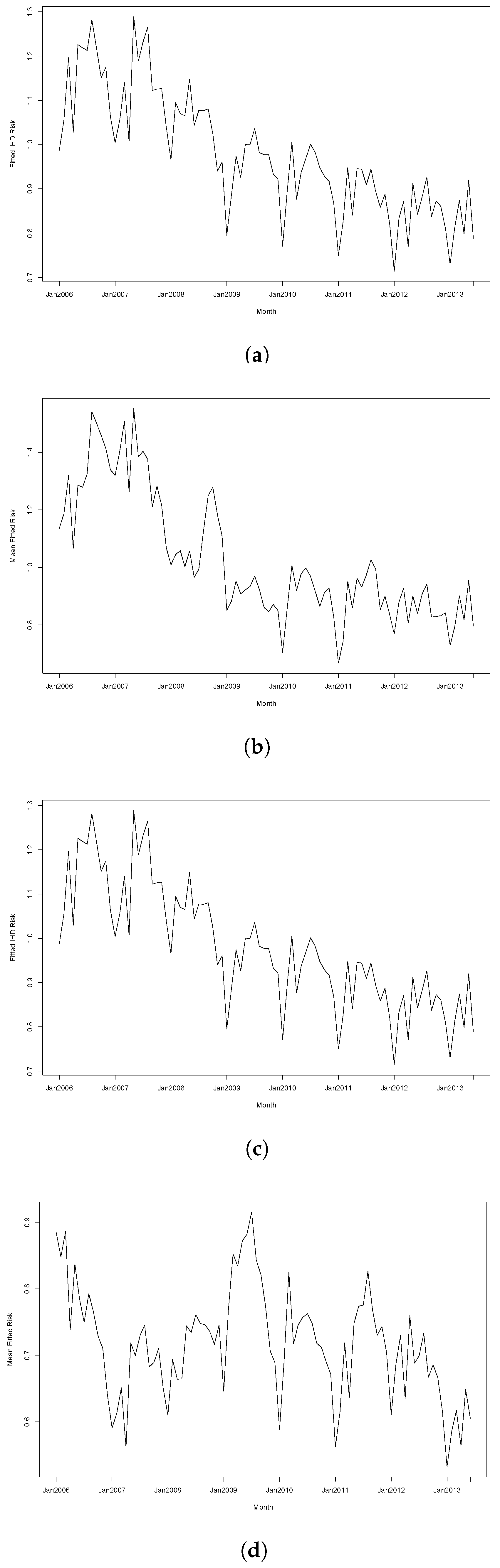

{kind=link}
{kind=link}
{kind=link}
{kind=link}