1. Introduction
Currently, the environmental problem may be the most severe problem which has a great influence on human health and ecosystems. The governments have put great efforts towards the control of pollution, and have obtained much success. Because of the use of gasoline and other petrochemicals and fossil fuels, air pollutants are emitted largely by industry and automobiles. The formation of air pollutants is a very complex and nonlinear phenomenon, due to photochemical processes.
Air pollution degrades air quality and leads to several diseases, such as asthma, wheezing, and bronchitis. Air Pollutant is formed in the atmosphere because other directly emitted pollutants react. While Air Quality System monitoring data are viewed as the gold standard for characterizing ambient air quality and determining compliance with the government Ambient Air Quality Standards, such data are limited in space and time. The prediction of the concentration of air pollutants can enhance the scientific understanding of air pollution and provide valuable information for the development of optimal emission control strategies [
1,
2,
3,
4,
5]. This predictive ability would also provide a better understanding of the nature and relative contributions of different emission sources that are responsible for the observed level of air pollutants. The system which is able to predict the concentration of air pollutants with sufficient anticipation can provide public authorities the time required to manage the emergency. Great progress has been made in the prediction of the concentration of air pollutants over the past decades. However, it is still challenging to accurately predict the concentration of air pollutants due to the complex influential factors. It is necessary to study more effective methods to accurately predict the concentration of air pollutants in the future.
The methods for the prediction of the concentration of air pollutants can be roughly divided into two types: deterministic and stochastic. The deterministic approaches model the physical and chemical transportation process of the air pollutants in terms of the influences of meteorological variables, such as wind speed, relative humidity, and temperatures with mathematical models to predict the level of air pollutants [
6]. These methods can generate either short-term or long-term pollutant concentration predictions. The performance of these models depends on a thorough understanding of the formation mechanism of pollutants. Some researchers try to develop and improve an integrated air quality modeling system that can simulate the sources, evolution, and environmental impacts of air pollutants at all scales. However, it is still challenging to precisely predict the concentration of air pollutants, due to the multiplicity of sources and the complexity of the physical and chemical processes which affect the formation and transportation of air pollutants. Firstly, the parameters in the equations have a vital influence on the prediction performance. Consequently, the complexity of the large partial differential equations is high—they are very difficult to solve exactly and will sacrifice great computation resources. Meanwhile, the density and quality of observations which are used as inputs to the model also affect the accuracy of numerical predictions.
A statistical approach learns from historical data and predicts the future behaviour of the air pollutants. Many statistical models are adopted to predict the concentration of air pollutants in space and time as related to the dependent variables [
7,
8,
9,
10,
11]. Some researchers proposed an exploitation of the statistical relationships between the concentration of air pollutants and the corresponding meteorological variables. It is not necessary to model a physical relationship between emissions and ambient concentrations, but to analyze the time series directly. The representative methods include time series analysis, Bayesian filter, artificial neural networks, etc. Although statistical models can present accurate prediction, they cannot provide a detailed explanation of the air pollution [
12,
13,
14,
15]. The spatial temporal interpolation is the most popular algorithm in the predictions, and is based on the assumption that the nearer two points are, the higher correlation they are [
16]. It firstly analyzes the correlation of the sampled data and then uses the correlation to predict the concentration in the future [
17]. However, these methods do not consider the transformation of the air pollutants in two adjacent times. Thus, the dynamical information are not considered. Some researchers proposed the combination of the observation and the output of the numerical weather system and obtain the fused estimation of the concentration of air pollutants in the Bayesian framework [
18]. However, the unanalytic formation of the posterior distribution is generally solved by Markov Chain Monte Carlo (MCMC) methods in which the parameters are generally difficult to determine.
Meteorological conditions significantly affect the levels of air pollution in the urban atmosphere, due to their important role in the transport and dilution of pollutants. It has also been concluded that there is a close relationship between the concentration of air pollutants and meteorological variables. Thus, multiple linear regression models (MLR) are trained based on existing measurements and are used to predict future concentrations of air pollutants in the future according to the corresponding meteorological variables. Well-specified regressions can provide reasonable results. However, the reactions between air pollutants and the influential factors are highly nonlinear, leading to a highly complex system of air pollutant formation mechanisms. Therefore, although multiple linear regressions are theoretically sophisticated for forecasting, they are not widely used in many applications. Moreover, the outliers and the noise in the data have a strongly negative influence on the performance of these regression-based algorithms. Statistical techniques do not consider individual physical and chemical processes, and use historical data to predict the concentration of air pollutants in the future. It is very challenging to predict air quality using a simple mathematical formula which is unable to capture the non-linear relationship among various variables.
Black box approaches have been recognized as perfect alternatives to traditional models for input–output mathematical models. It is shown that neural networks show better performances against MLR [
19,
20,
21,
22,
23,
24,
25]. Artificial neural networks (ANN) have the advantages of incorporating complex nonlinear relationships between the concentration of air pollutants and the corresponding meteorological variables, and are widely used for the prediction of air pollutants concentration. However, ANN-based approaches have the following main drawbacks: (1) ANN-based approaches very easily fall into the trap of local minimum and have poor generalization; (2) they lack an analytical model selection approach; (3) it is very time-consuming to find the best architecture and its weights by trial and error.
According to the above superiority, we proposed the use of an extreme learning machine (ELM) [
26,
27,
28] to efficiently predict the concentration of air pollutants. To the best of our knowledge, there are no declarations that use ELM to predict the concentration of air pollutants. Our paper has two main contributions: (1) the prediction of the concentration of air pollutants in the framework of ELM. It is concluded that ELM has stronger generalization than traditional statistical and ANN-based methods, with extreme learning speed. In the second part, a brief introduction of the ELM is given and we propose the prediction of the concentration of air pollutants based on ELM simultaneously [
29]; (2) ELM is evaluated on the Hong Kong data qualitatively and quantitatively in the third section comparing ELM with a feedforward neural network based on back propagation (FFANN-BP) and MLR. In the last section, we conclude our work and make some comments on future work.
2. Study Area
Hong Kong is located on China’s south coast, with around 7.2 million inhabitants of various nationalities, and is surrounded by the South China Sea on the east, south, and west, and borders the Guangdong city of Shenzhen to the north over the Shenzhen River. It has a land area of 1104 km2, is one of the world’s most densely populated metropolises, and consists of Hong Kong Island, the Kowloon Peninsula, the New Territories, and over 200 offshore islands, of which the largest is Lantau Island. In Hong Kong, millions of people live and work near heavily travelled roads. Summer is hot and humid with occasional showers and thunderstorms, and with warm air coming from the southwest, typhoons most often occur. The occasional cold front brings strong, cooling winds from the north. It is generally sunny and dry in Autumn. The most temperate seasons are spring, which can be changeable. The highest and lowest ever recorded temperatures across all of Hong Kong, on the other hand, are 37.9 °C at Happy Valley on 8 August 2015 and −6.0 °C at Tai Mo Shan on 24 January 2016, respectively. The primary pollutants are carbon monoxide and sulfur dioxide emissions from vehicles and power plants.
In a rapidly changing city like Hong Kong, traffic volume, regulations, and related policies have a great influence on the formation of air pollutants. Marine vessels and power plants are the influential factors of Hong Kong’s air pollution. The emissions of power stations, and domestic and commercial furnaces all contribute to the air pollution in Hong Kong. Smog is caused by a combination of pollutants—mainly from motor vehicles, industry, and power plants in Hong Kong and the Pearl River Delta. Approximately 80 % of the city’s smog originates from other parts of the Pearl River Delta. Air quality has deteriorated seriously in Hong Kong as a result of urbanization and modernization. Because of the reduction of air quality, cases of asthma and bronchial infections have recently increased. The mortality rate from vehicular pollution can be twice as high as near heavily travelled roads. Thus, city residents face a major health risk. Meanwhile, the pollution is costing Hong Kong financial resources. The Environment Bureau of Hong Kong has been implementing a wide range of measures locally to reduce the air pollution. The objective of overall policy for air quality management in Hong Kong is to achieve as soon as reasonably practicable and to maintain thereafter an acceptable level of air quality to safeguard the health and well being of the community, and to promote the conservation and best use of air in the public interest.
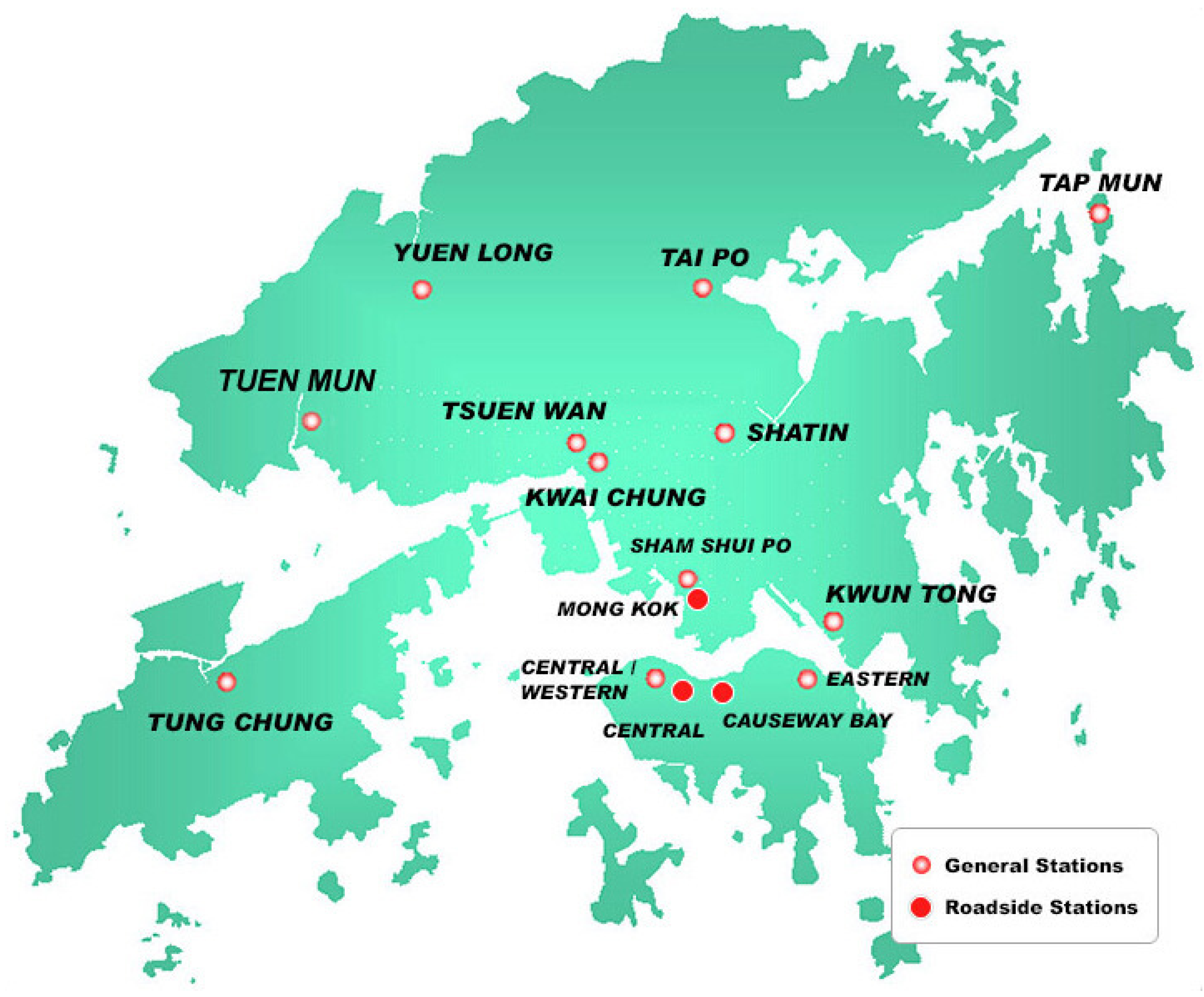
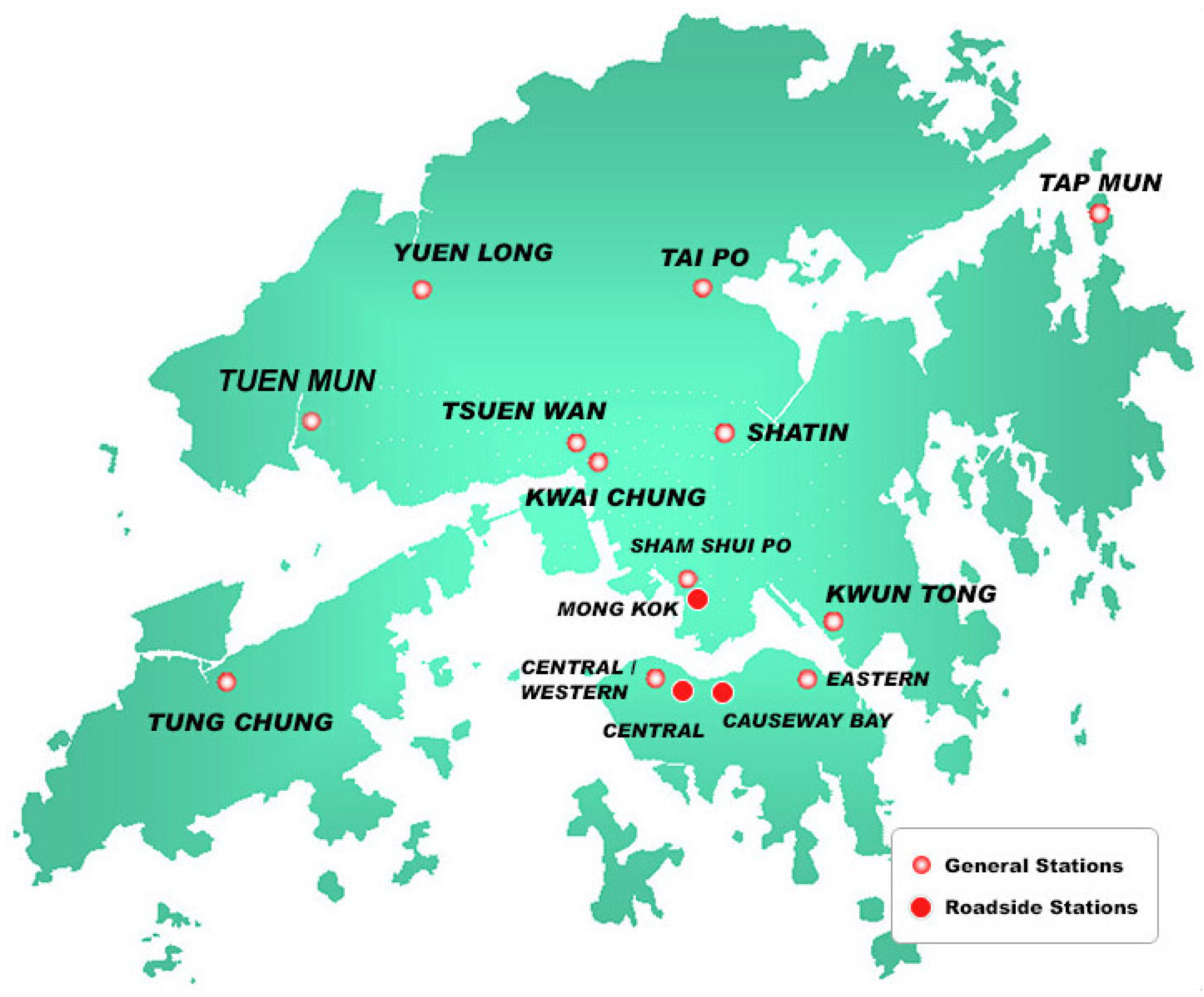
Air quality monitoring by the Environmental Protection Department is carried out by 12 general stations and three roadside stations, including Causeway Bay, Central, Central Western, Eastern, Mong Kok, Tung Chung, Shatin, Sham Shui Po, Kwai Chung, Kwun Tong, Tai Po, Tap Mun, Tsuen Wan, and Yuen Long air monitoring stations. The coordinates of monitoring stations are shown in
Figure 1. The department began reporting data on fine suspended particulate—which are a leading component of smog in the air—on an hourly basis. The seasons are defined as summer (March, April, and May), monsoon (June, July, August), post-monsoon (September, October, and November), and winter (December, January, and February). The descriptive statistics of air pollution in four season are shown in
Table 1, the winter and summer have the highest percentage.
3. Prediction of the Concentration of Air Pollutants Based on ELM
Meteorological conditions have a large and significant influence on the level of air pollutant concentrations in the urban atmosphere due to their important role in the transport and dilution of the pollutants. ELMs have become a hot area of research over the past years and have been proposed for both generalized single-hidden-layer feedforward and multi-hidden-layer feedforward networks. It has been becoming a significant research topic for artificial intelligence and machine learning because of fast training and good generalization. It seems that ELM performs better than other conventional learning algorithms in applications with higher noise.
3.1. Multiple Linear Regression
Multiple linear regression (MLR) tries to model the explanatory variables and response variables through fitting a linear relationship to observed data. That is to say,
represents the residual term, which is normally distributed with mean 0 and variance
σ. The coefficients
are calculated by minimizing the sum of the squares error from each data point to the optimal value.
3.2. Feedforward Neural Network Based on Back Propagation (FFANN-BP)
Inspired by biological neural networks, artificial neural networks are used to approximate functions that depend on a large number of inputs. The basic structure of artificial neural networks includes a system of layered, interconnected nodes. Feed forward artificial neural networks are a simplified mathematical model based on the knowledge of the human brain neural network from the perspective of information processing, and have been found to perform remarkably well in capturing complex interactions within the given input parameters with satisfactory performance.
FFANN-BP is the most popular and the widely-used supervised learning method, and requires a teacher who knows the desired output for any given input. FFANN-BPs are systems of interconnected neurons that exchange messages between each other, in which the connections have numeric weights that can be tuned based on experience. They consist of an input layer and a hidden layer, the output layer. Thus making FFANN-BPs adaptive to inputs and capable of learning. The learning process repeats until the error of neural network decreases to the desired minimum.
The factors that influence the pollution concentration are classified and detected cautiously and then used as the input data, and the concentrations are used as the output to train the neural networks. FFANN-BPs can accurately represent the relationships between the influential factors and the air pollution concentration which are not fully captured by the traditional approaches, and can be used to predict the air pollutant concentration with the known influential factors.
The training process of FFANN-BPs consists of two iterative steps, including the forward-propagating of the data stream and the back-propagating of the error signal. Firstly, original data are passed from the input layer to the output layer through the hidden processing layer. The input of the
j-th neuron in the
l-th layer
is
where
is the weight that connects the
i-th neuron in the
-th layer and the
j-th neuron in the
l layer,
is the response of the
j-th neuron in the
l-th layer, and
f is the activation function which is used to introduce the non-linearity into the network. Generally, any nonlinear function can be used as the activation function, such as the unit step function; the linear function and the sigmoid function,
, is the bias of the neuron. If the real output is not consistent with the desired output, then error is propagated backward through the network against the direction of forward computing. The learning process consists of forward and backward propagations. FFANN-BP dynamically searches the weight which minimizes the network error in the weight space, reaches the aim of the memory process and the information extraction, and makes the real output of the network closer to the desired output.
According to the convenience of the calculation, can be considered as the weight of the neuron whose response is constant with .
The total error of the network is
where
is the target output of the
j-th neuron in the output layer for the
q-th sample,
is the real output,
m is the number of training samples, and
L is the number of layers for neural network. The biases can be adjusted according to the adjusting rules of the neurons. The connected weights in the output layer can be updated online according to the following formula:
where
is defined as
The connected weights in the hidden layers are updated with the following formula,
where
is the number of the neurons in the
t-th hidden layer.
Three key drawbacks of FFANN-BP may be: (1) slow gradient-based learning algorithms are extensively used to train neural networks. It is clear that the learning speed of feedforward neural networks is in general far slower than required, and it has been a major bottleneck in their applications for past decades. The overtraining of the neural network results from FFANN-BP. Good performance is time-consuming in most applications due to the gradient-based optimization; (2) All the parameters of the networks are tuned iteratively by using such learning algorithms. When the learning rate η is too small, the convergence of FFANN-BP is too slow. When the learning rate η is too large, the performance of the algorithm is not stable, even divergence; (3) FFANN-BP is always prone to get caught up in a local minimum, not satisfying the performance requirements.
3.3. Prediction of the Concentration of Air Pollutants Based on ELM
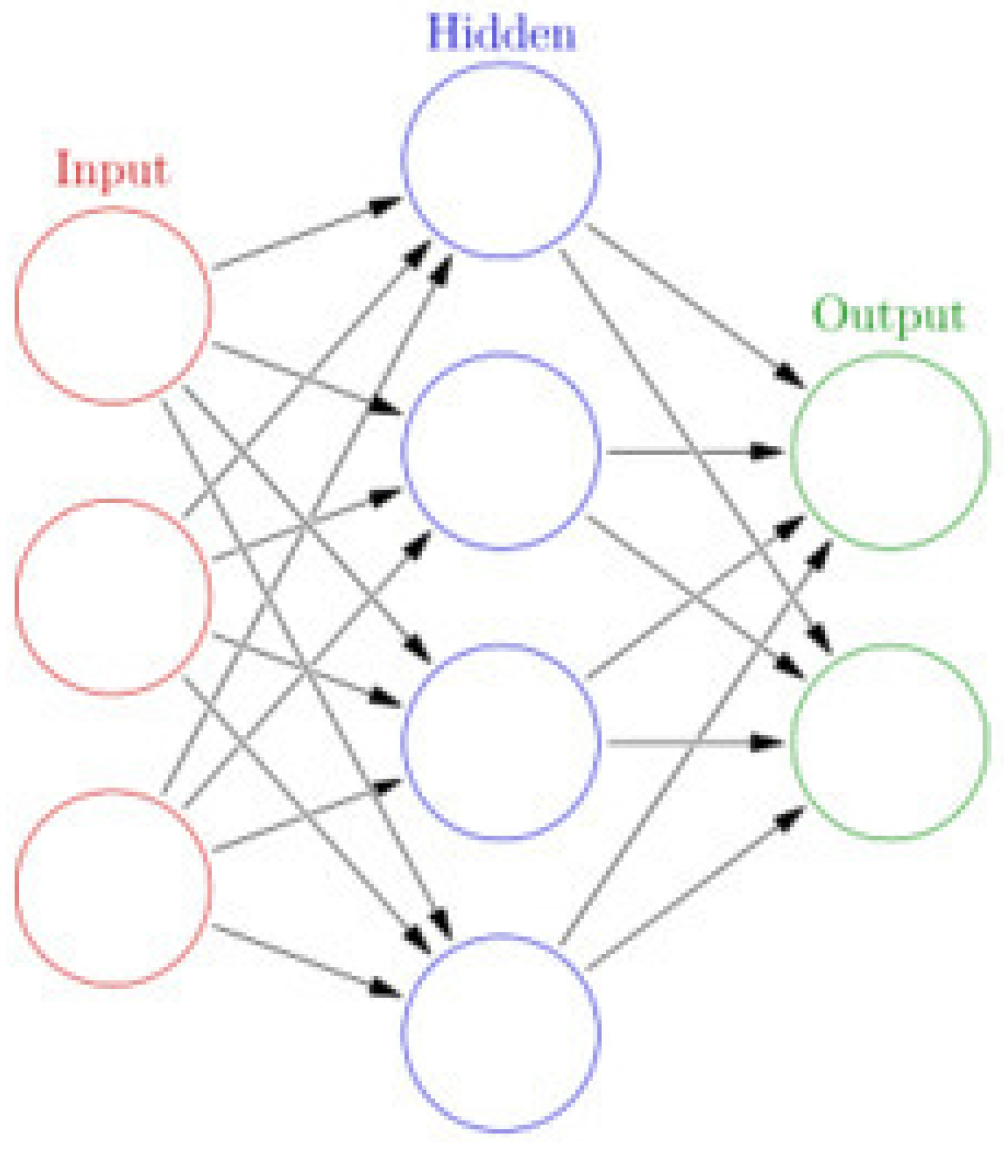
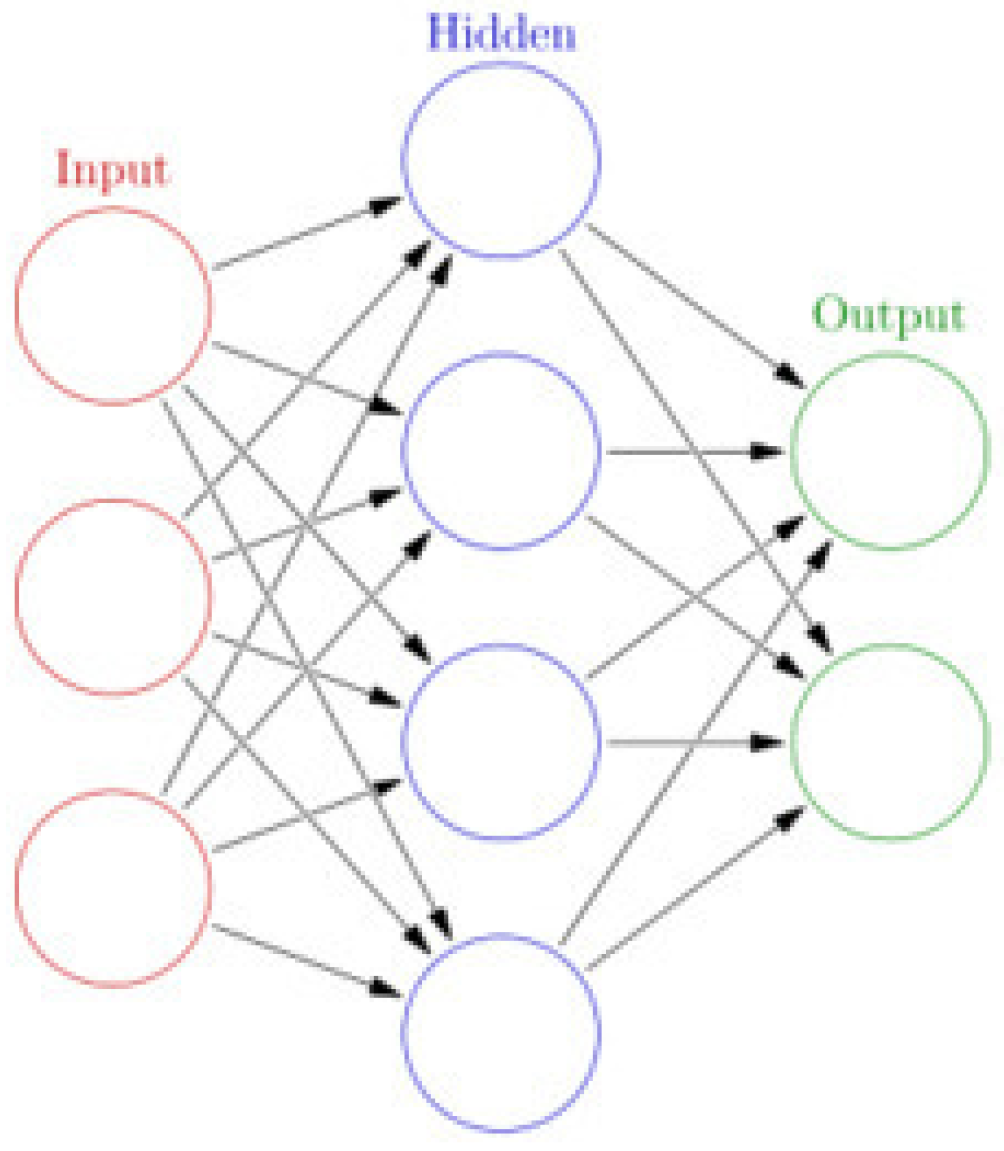
ELM is basically a two-layer neural network in which the first layer is fixed and random, and the second layer is trained. The basic structure of ELM is shown in
Figure 2. ELM has recently been used for classification and regression, clustering, feature selection, etc. Hardware implementation and parallel computation techniques guarantee the training of ELM. ELM has been widely used in a variety of areas, such as biomedical engineering and computer vision. Many researchers from every corner of the world pay great attention to finding an effective learning algorithm to train neural networks by adjusting hidden layers. ELM shows that hidden neurons are important but need not be tuned in many applications, which is proposed based on our intuitive belief in biological learning and neural networks’ generalization performance theories, in which the weights connecting inputs to hidden nodes are randomly assigned and never updated because of the randomly generated hidden nodes.
It is different with other machine learning algorithms, such as supported vector machine (SVM) [
30] and deep learning [
31]. SVM uses a kernel function to implement the feature mapping. In deep learning, one uses Restricted Boltzmann machines or Auto-Encoders/Auto-Decoders for feature mapping. It is different with traditional learning algorithms such as FFANN-BP, in which the parameters of hidden layers and the output layer all need to be adjusted. In ELM, the weights of hidden layers need not to be adjusted.
The training of ELM generally consists of two main stages, including random feature mapping and linear parameters solving. In the second stage, the output weight fi is calculated.
Given
N different samples
, where
and
. In our study,
is the
i-th air pollutants concentration, and
is the corresponding meteorological variables. The neural network has
hidden nodes,
. One first randomly assigns input weight
and bias
, and hidden node number
, maps the input data nonlinearly into a feature space by the specified transform activation function
, and obtains the hidden layer output matrix
. The weight vector
connects the
i-th hidden neuron and the input neurons, and the weight vector
connects the
i-th hidden neuron and the output neurons;
is the threshold of the
ith hidden neurons. Compared with FFANN-BP, the input weights and the biases of the hidden layer are first randomly generated, and then the output weights are analytically adjusted through simple generalized inverse operation of the hidden layer output matrices in ELM. This is equivalent to minimizing the cost function
It is undesirable that the learning algorithm stops at a local minima if it is located far above a global minima. Thus, the weights between the hidden layer and the output layer are the only parameters needing to be tuned. It has been proven that the standard single layer forward networks with
hidden nodes and activation function
can approximate these
N samples with error and give sufficient training error for any given training set with probability one. That is to say, there theoretically exist the weight vector
and threshold
such that
We write the above
N equations compactly as follows:
where
Theoretically, any output functions may be used in different hidden neurons. However, it is necessary to satisfy the universal approximation capability theorem.
In the second stage of ELM training, we found the weights connecting the hidden layer and the output layer
where
represents the Moore–Penrose generalized inverse of matrix
,
is the hidden layer output randomized matrix, and
is the training data target matrix,
The learning stability is also considered in ELM. ELMs have more generalization ability, and aim to reach the global maximum solution. ELMs not only achieve state-of-the-art performances, but also speed up the training of the network. It is difficult to achieve such performance by conventional learning techniques.
It is noted that there are no biases in the output nodes which will result in suboptimal solutions. Moreover, the number of the hidden neurons is smaller than the number of distinct training samples. The activation function of the hidden neurons is generally continuous and differentiable in the traditional feed forward neural network. FFANN-BP is quite essentially different from MLR. However, each of them can be adjusted to suit the specific applications.
4. Experiments
The performance of MLR, FFANN-BP, and ELM are evaluated on Hong Kong data sets which are observed from Hong Kong Observatory (HKO) and Environmental Protection Department (EPD). Because of the performance of the instruments, the data sets are not noise -free. The effectiveness of the data are poor, and the incompleteness of data has a limitation on our study. In this study, six year daily data (2010–2015) of five air pollutants at Sham Shui Po and Tap Mun air quality monitoring stations in Hong Kong was used to evaluate the accuracy of the above-mentioned statistical techniques. The air quality variables used in this study are nitrogen dioxide (NO2), nitrogen oxide (NOx), ozone (O3), particulate matter under 2.5 m (PM2.5), and sulfur dioxide (SO2). We took the average of 24 h concentration as the daily mean concentration. All the values are in g/m3. We deleted all NAs (missing values) in the data set. Eleven predictor variables and one response variable were used, which is the next day’s air pollutant concentration. For each pollutant, NAs and outliers are about 3%.
Similarly, meteorological parameters were recorded on a daily basis. Hence, the 24 hourly averaged surface meteorological variables such as daily maximum temperature, minimum temperature, difference between daily maximum and minimum temperature, average temperature (T in °C), wind speed (WS in
), wind direction (WD in rad), relative humidity, and three time variables such as day of the week and month of the year as inputs for three machine learning models, observed in Sham Shui Po and Tap Mun and acquired from Hong Kong observatory for the period from 2010 to 2015. The influential factors are selected by the a priori knowledge of the characteristics of potential input variables, such as the close relationship between each pollutant and the meteorological variables. Furthermore, the different combinations of the meteorological variables were tested, and we selected the combination with the best performance to predict the air pollutant concentrations based on the trained neural network and the corresponded predictors. Lagged air pollutant concentrations were included as a predictor variable. It is noted that the wind direction is replaced by the following, which has been calculated through:
where
φ is the wind direction in radians.
The experiments are carried out in MATLAB 2014 environment running in a Pentium 4, 1.9 GHZ CPU. We adopted 10-fold cross-validation to assess whether ELM can be generalized to an independent data set. Using the 10-fold cross validation (CV) scheme, the dataset was randomly divided into ten equal subsets. At each run, nine subsets were used to construct the model, while the remaining subset was used for prediction. The average results and the correlation coefficients are shown in
Table 2. The average accuracy for 10 iterations was recorded as the final prediction. We use the training subset to learn and adjust the weights and biases of the predefined ELMs, and the testing subset is used to evaluate the generalization ability of the trained network. Generally, the larger the training set, more accurate models will be obtained.
In order to avoid the performance being dominated by any variables, we scaled the data set to commensurate data ranges, data including the inputs and the targets have been normalized into . The results of the models were reverse-scaled to compare the performance of MLR, FFANN-BP, and ELM. For FFANN-BP, we adopted the Levenberg–Marquardt algorithm, which is generally the fastest method for training moderate-sized FFANN. For ELM, the sigmoid function for the hidden layer and linear function for the output layer are used in our paper.
The number and selection of input variables are very important in the performance of the prediction of air pollutant concentration algorithms. For FFANN-BP and ELM, the number of hidden nodes are gradually increased. We selected the optimal number of nodes for FFANN-BP and ELM by cross-validation. The number of the hidden nodes for ELM and FFANN-BP was set as 20.
In order to evaluate the performance of the three methods, four statistical parameters were calculated, including mean absolute error (MAE), root mean square error (RMSE), the index of agreement (IA), and the coefficient of determination (
). RMSE, MAE, IA, and
of the three models are shown in
Table 2. The results with the highest
value and the lower value of RMSE is the best method. RMSE is calculated as follows :
where
is the
i-th corresponding observed concentration,
is the
i-th predicted concentration,
is the average of observation, and
n is the number of data.
Table 3 summarizes the performance of the derived models in the four sites in terms of the squared correlation coefficient (
) among the observed the observed and predicted values, the mean average error (MAE), the root mean square error (RMSE), and the index of agreement (IA).
4.1. Results
Firstly, the architectures for the four seasons of summer, monsoon, post-monsoon, and winter have been trained through MLR, FFANN-BP, and ELM based on daily data of 2010–2015. Hence, the forecasted values of daily air pollutant concentrations for the validated data have been compared with the observed values of the same time, as shown in
Table 2. The
, RMSE, IA, and MAE were found to be better in summer than in all three seasons. The coefficients of determination (
) have almost significant values (0.70) in all seasons. The statistical analysis of the three models’ validation in the validated data have been shown in the same table, which reveals that ELM is performing satisfactorily with respect to RMSE and
in summer, winter, post-monsoon, and monsoon, in decreasing order. However, we found that the ELM model obtained the best performance in terms of four statistical parameters. We found that root mean square error (RMSE) and mean absolute error (MAE) were better in summer than in all three seasons, the
and IA were observed to be almost the same in all seasons.
4.1.1. Coefficient of Determination
Based on the performance measures, ranking of the statistical models used in the present study have been done in
Table 2. We selected the Sham Shui Po monitoring station to demonstrate the performance of the three methods. The coefficient of determination for
varied from 0.52 to 0.61 for MLR, 0.57 to 0.67 for FFANN-BP, and 0.65 to 0.71 for ELM for four seasons. The coefficient of determination for
varied from 0.54 to 0.66 for MLR, 0.56 to 0.76 for FFANN-BP, and 0.62 to 0.83 for ELM for four seasons. The coefficient of determination for
varied from 0.54 to 0.59 for MLR, 0.59 to 0.60 for FFANN-BP, and 0.55 to 0.72 for ELM. The coefficient of determination for
varied from 0.50 to 0.64 for MLR, 0.52 to 0.67 for FFANN-BP, and 0.70 to 0.82 for ELM. The coefficient of determination for
varied from 0.55 to 0.74 for MLR, 0.54 to 0.71 for FFANN-BP, and 0.61 to 0.78 for ELM. The observations made in the study reveal that the ELM-based technique scored well over MLR and FFANN-BP. ELM is the most suitable statistical technique for the prediction of air pollutant concentrations. The results reveal that the performance of the statistical models is often superior to MLR and FFANN-BP for four seasons.
4.1.2. RMSE
There appears to be very good agreement between the predicted and observed concentrations for three models. However, the ELM model yielded the lowest RMSE compared to the slightly higher values obtained by FFANN-BP and MLR. The ELM model performed best in terms of RMSE, which is in agreement with the coefficient of determination results. It is shown in
Table 2 that the RMSE between the predicted and the observed concentrations for each air pollutant has the lowest values for ELM. However, for MLR and FFANN-BP, the RMSE is higher. A similar conclusion is drawn for mean absolute error. Clearly, ELM outperforms the other two counterparts in the testing phase. This indicates that the ELM model had a slightly better skill in the generalization. The same advantages of the three techniques is that they use a single type of data concentration and effort in training the data with meteorological, emission, and other such data—in comparison to other methods such as the numerical models. However, MLR can not capture the complex relationship of the data. This results in the poor performance of MLR. The high values of the index of agreement indicate a satisfying forecast of the daily average values of air pollutant concentration by the three models for four seasons.
4.1.3. Speed
Moreover, it is shown in
Table 3 that ELM performs better in terms of the learning speed against MLR and FFANN-BP. The greatest proportion of learning time of ELM is spent on calculating the Moore–Penrose generalized inverse of the hidden layer output matrix
H. We run the efficient optimal FFANN-BP package provided by MATLAB2014 (MathWorks, Natick, MA, USA) for this application. The learning speed of ELM is faster than classic learning algorithms, which generally take a long time to train FFANN-BP. It is noted that ELM is the fastest compared to MLR and FFANN-BP. The experimental results show that ELM spent 0.183 s obtaining the testing RMSE 10.1; however, for FFANN-BP, it took 5 s to reach a much higher testing error of 15.8 for the
concentration at Sham Shui Po. It can also be seen that ELM runs around 25 times faster than FFANN-BP, and eight times faster than MLR for the prediction of Hong Kong air pollutants. However, ELM only spent 0.05 s on learning, while FFANN-BP spent nearly 3 s on training. The underlying reason is that it is not necessary for ELM to iteratively search for the optimal solution. On the contrary, FFANN-BP obtains the optimal solution by gradient-based optimization.
4.1.4. Generalization
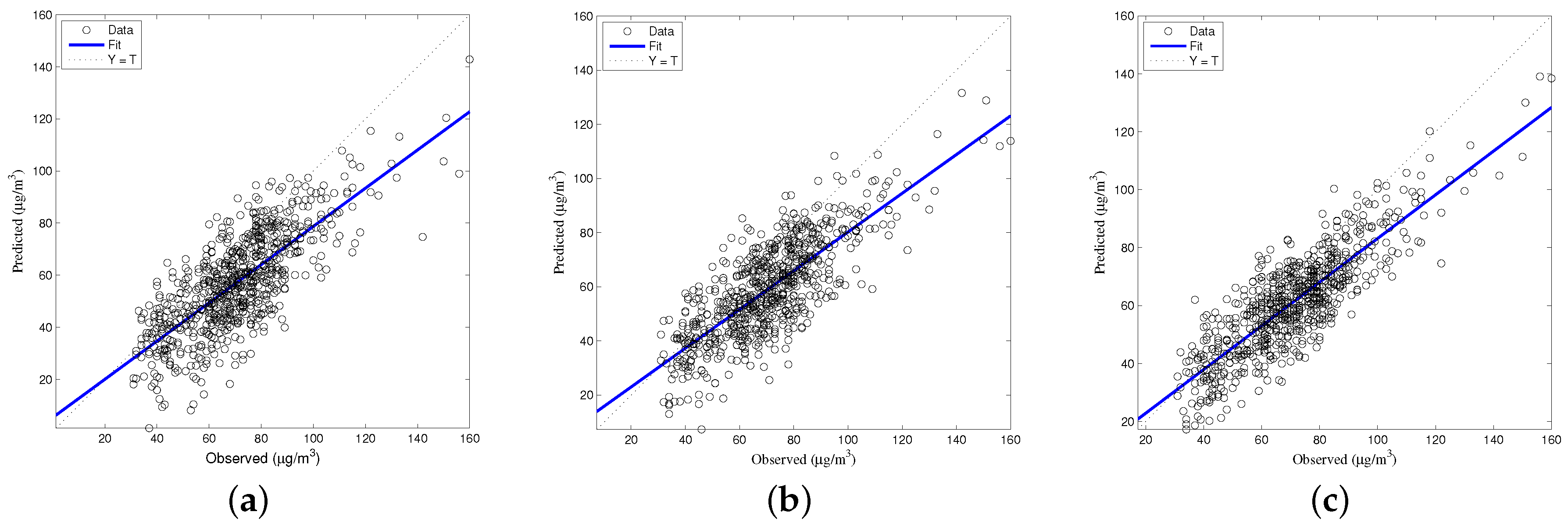
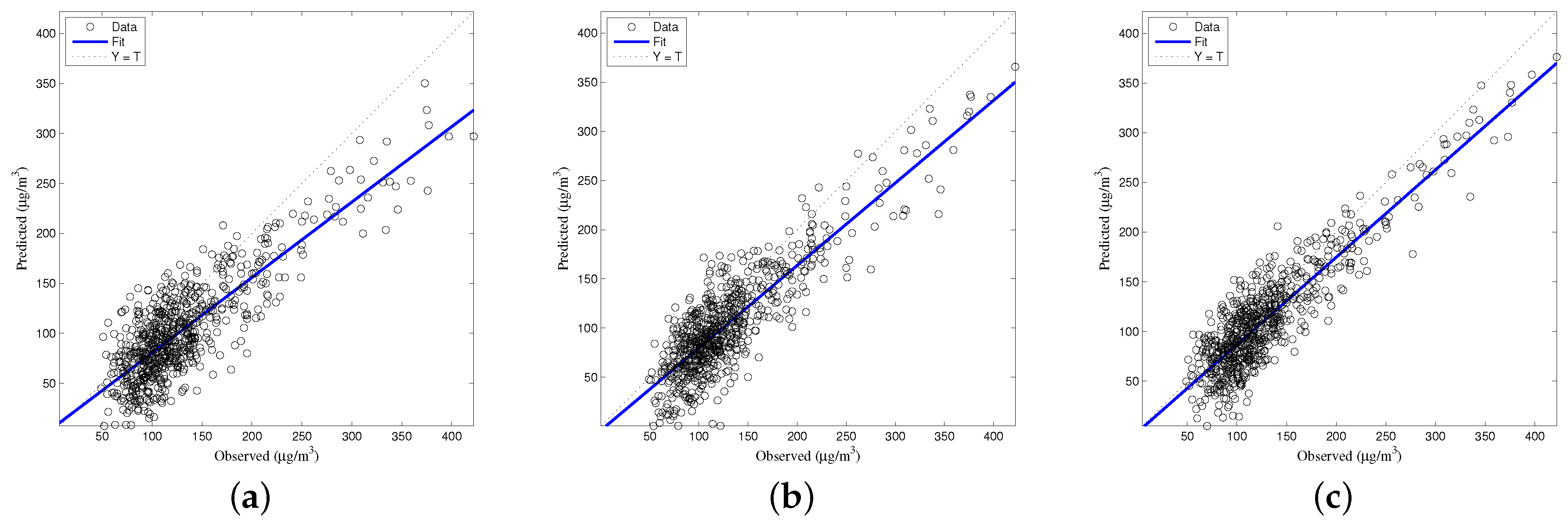
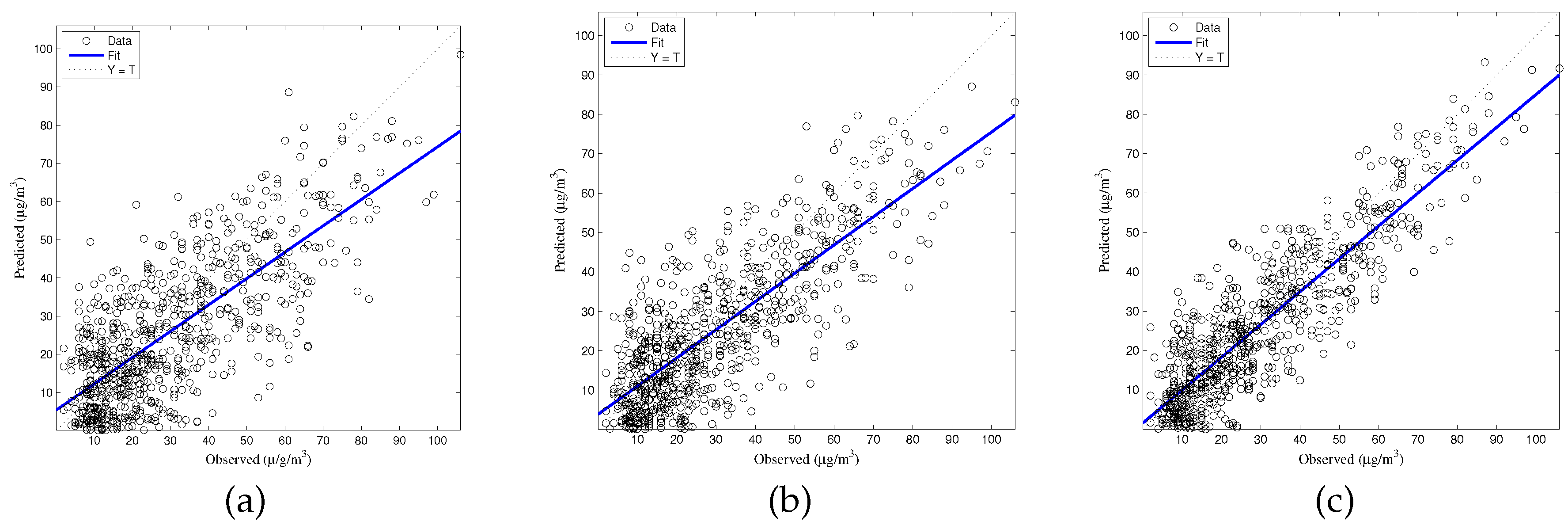
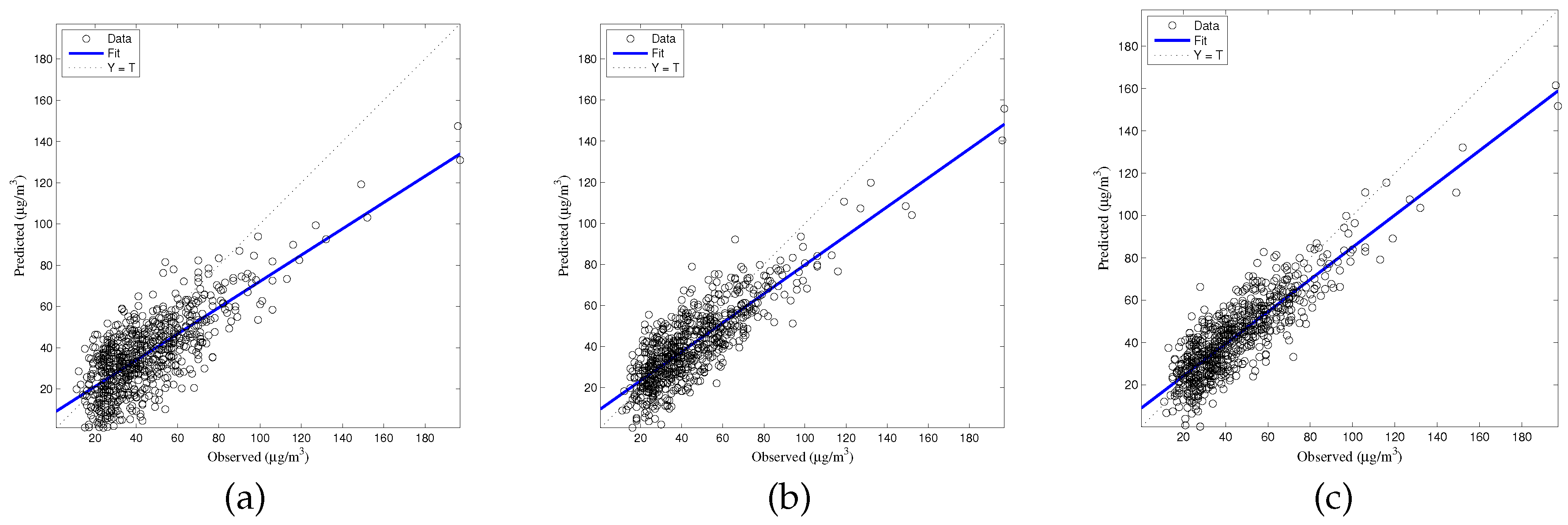
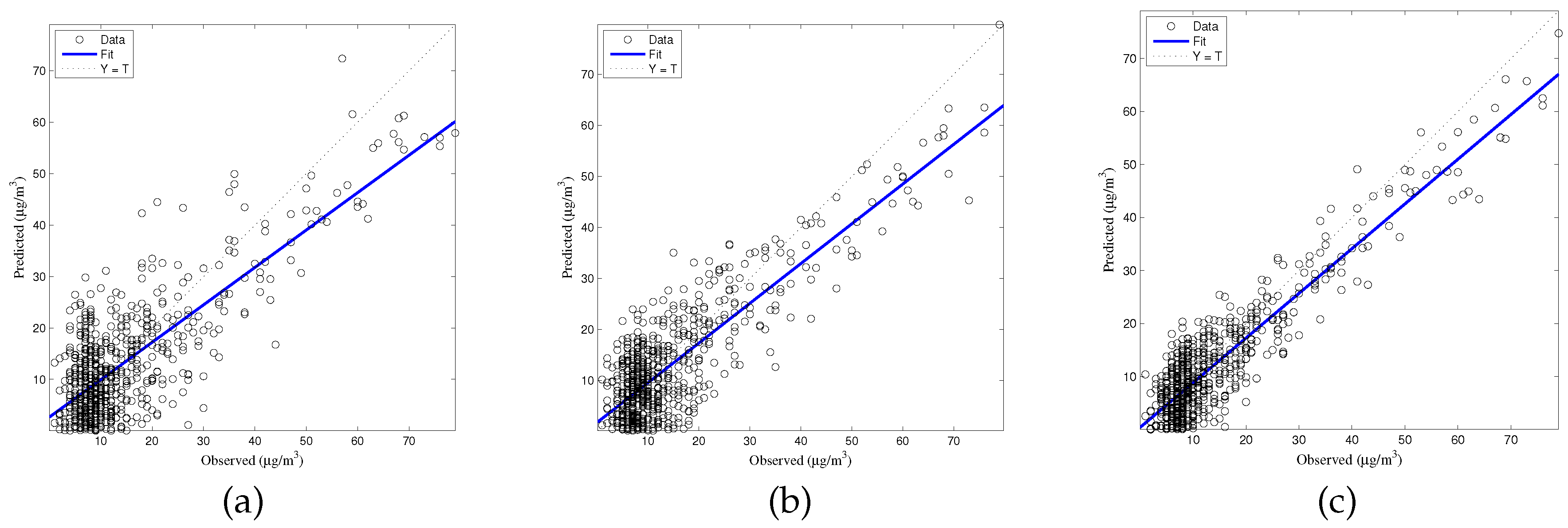
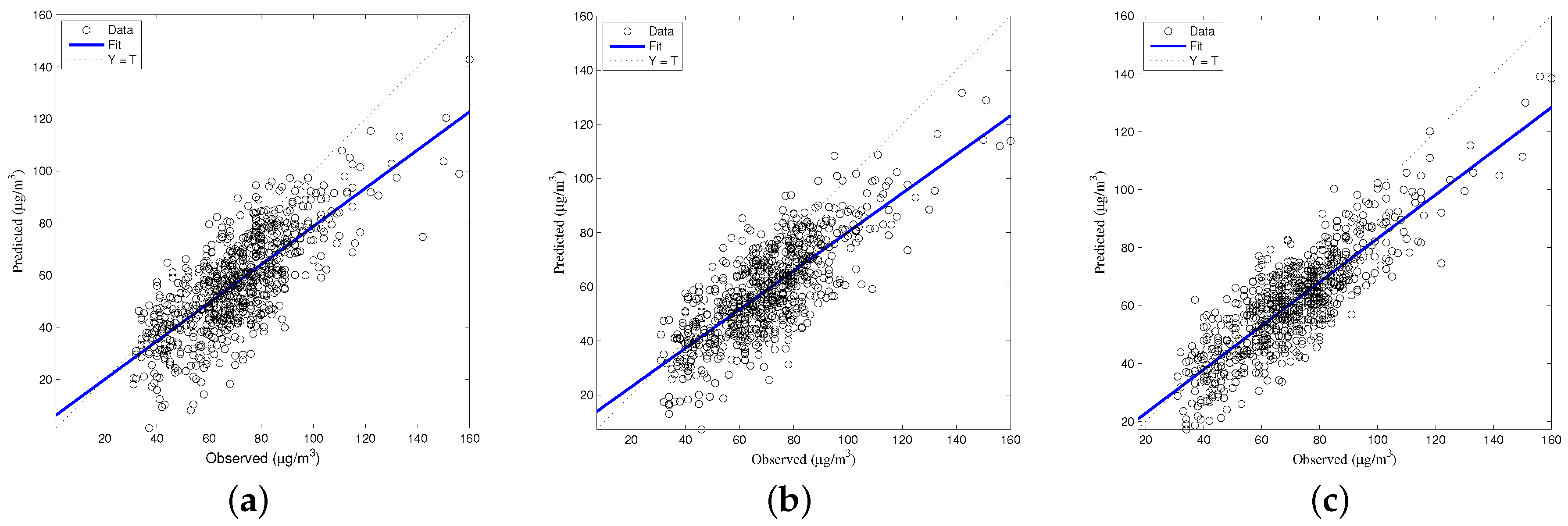
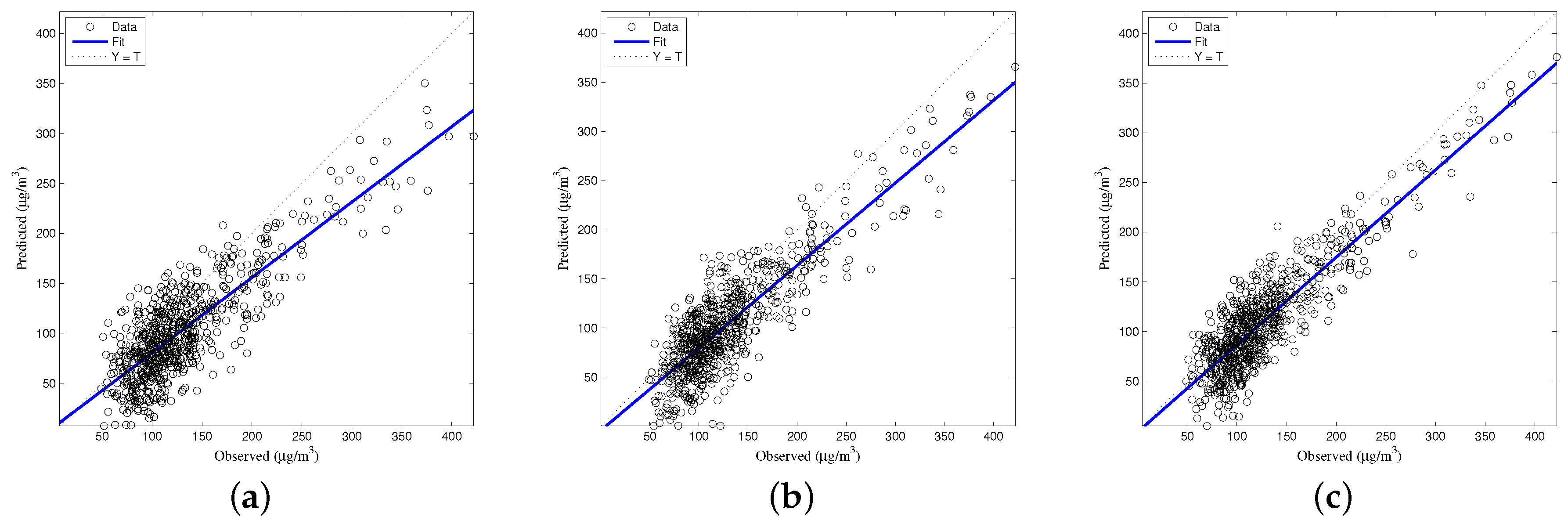
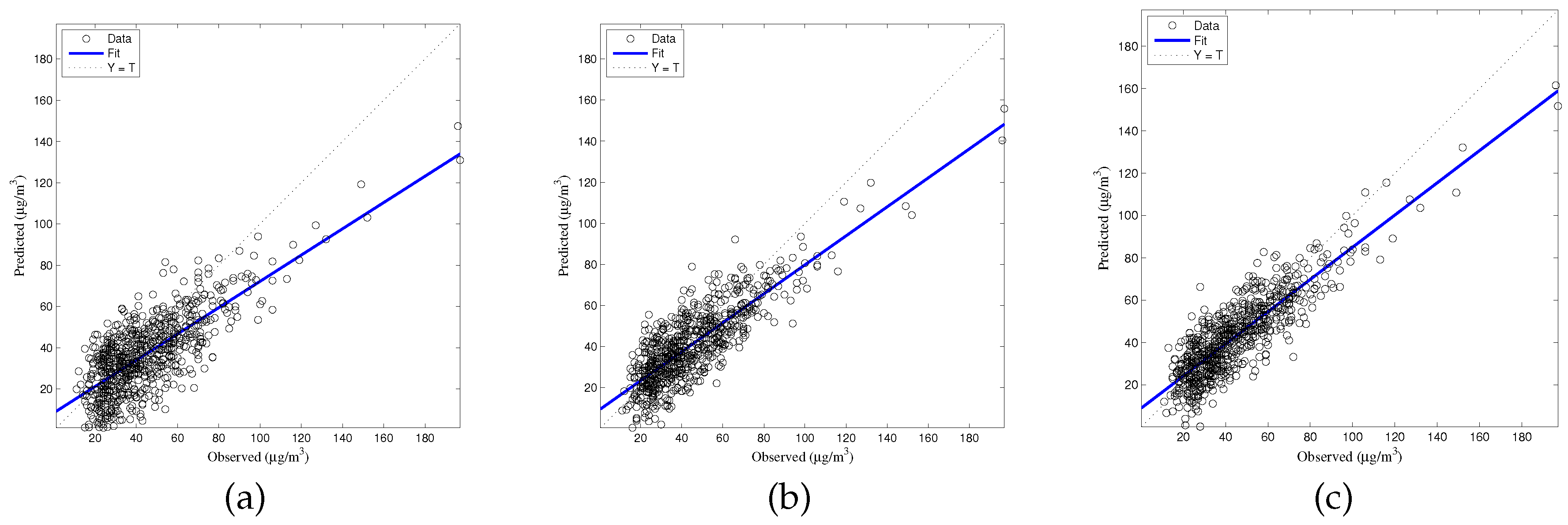
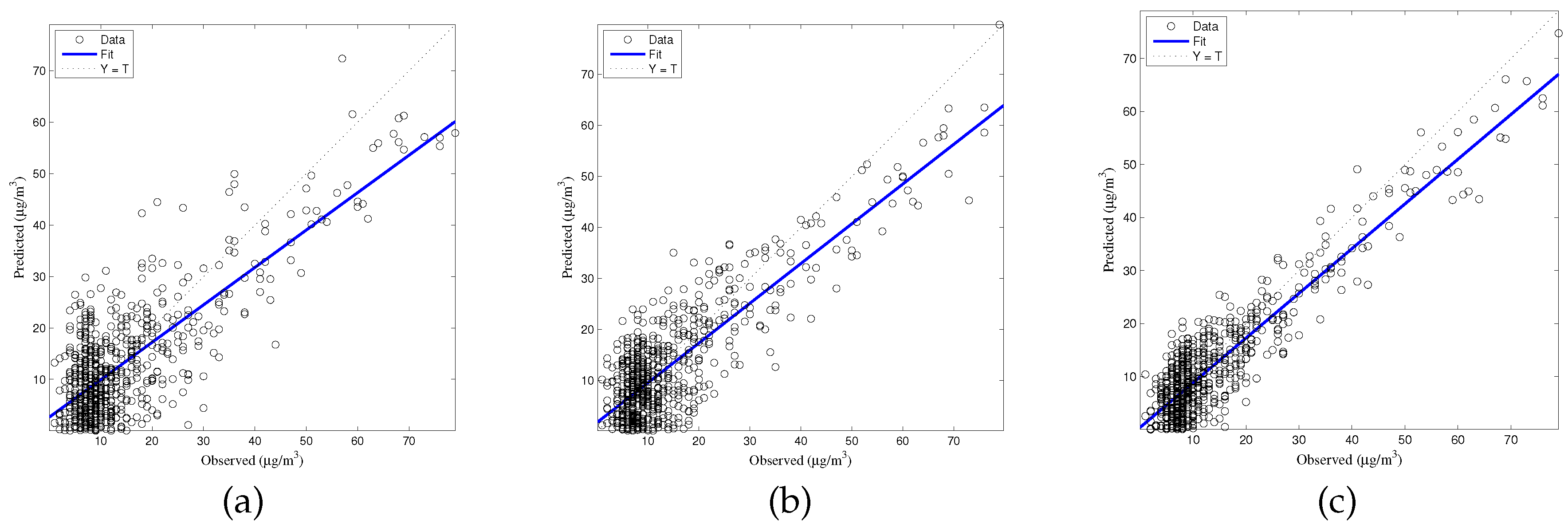
The generalized accuracy is estimated in our study. It is shown in
Table 2 and
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 that the generalization of ELM is often better than gradient-based learning, as in FFANN-BP. FFANN-BP has some drawbacks, such as local minima and low convergence rate. It is shown that FFANN-BP falls into the trap of local minima. Some measures, such as weight decay and early stopping strategies are adopted to avoid these issues. In a reverse manner, ELM, reaching the solutions directly, is simpler than FFANN-BP. It is shown that the generalization ability of ELM is very stable with the number of the hidden nodes.
4.2. Episode
Different breakpoint concentrations and different air quality standards have been reported in the literature. In Hong Kong, to reflect the status of air quality and its effects on human health breakpoints have been considered for individual air pollutants; for example, for PM2.5 (0–50 g/m3) “Low”, “High” (≥50 g/m3). In summary, the “High” level is around 33.5%, and the percentage of “Low” level is around 66.5% in Hong Kong, respectively (about 3% of the data are NAs). The daily average values of days and the annual average value was persistently higher than the limit value of 50 g/m3. Thus, the limit value of 50 g/m3 was selected in order to verify the forecast quality of the developed models.
As was mentioned in the introduction, the concentration levels in Hong Kong center are considerable when compared to the standards imposed by the World Health Organization (WHO). The daily average values exceeded the limit value of 50
g/m
3 in 38% of days. Thus, the limit value of 50
g/m
3 was selected in order to verify the predicted quality of the ELM model. We selected the probability of detection (POD) and false alarm rate (FAR) indices in order to evaluate the prediction accuracy for the exceedances of the imposed limit. The POD and FAR should be reasonably high and low, respectively. It is shown in
Table 4 that the three models fulfill these conditions to a large extent. Particularly, the ELM model can predict the exceedance and the non-exceedances accurately.
In order to show that the models can accurately predict the exceedances of the imposed limit, the values of POD and FAR should be reasonably high and low, respectively. The definitions of b, POD, PC and FAR are shown in the Formulas (20)–(23). As is exhibited in
Table 4, these conditions are fulfilled by both models to a large extent. Moreover, the developed models can predict the exceedances and the non-exceedance to a satisfactory level.
where A, B, C, D represent the number of exceedances that were observed and forecasted, the number of exceedances that were observed but not forecasted, the number of exceedances that were not observed but forecasted and non-exceedances, respectively. Generally, the high levels of POD values show that the perfect performance of ELM in predicting the exceedances of PM
2.5. Moreover, the FAR are found to be around 30%, the success rate of detection reach up to 91%. The lower performance of the RBF-NN shows that it is not appropriate for the prediction of the concentration of exceedances. Multilayer perceptron (MLP-NN) maps sets of input data onto a set of appropriate output. It provides powerful models which can distinguish data that are either nonlinearly. Radial basis function (RBF-NN) which is a neural network has radially symmetric functions in the hidden layer nodes. For RBF, the distance between the input vector and a prototype vector play an important role on the activation of the hidden neurons.
4.3. Comparison with Previous Studies
As stated above, during the last decade, many researchers used ANNs to forecast the particulate matter concentration levels in the ambient air pollution for Hong Kong, and numerous papers have been published. Some of them have focused on the prediction of hourly PM
2.5 concentrations in Central and Mong Kong, Hong Kong [
32,
33], and proved the effectiveness of the proposed model. Specifically, Fei et al. [
34] used to forecast hourly air pollutant NO
2 concentrations in Hong Kong, and reported a correlation coefficient between modeled and measured concentrations around 0.70; there was a reasonably good agreement between the predicted and observed NO
x and O
3 values. Zhao et al. (2003) [
35] proposed the use of quantile and multiple line regression models for the forecasting of O
3 concentrations in Hong Kong, and reported better performance, depending on the site, the training algorithm, the input configuration, etc. The results proved that the MLR worked better at suburban and rural sites compared to urban sites, and worked better in winter than in summer. Gong [
36] proposed the combination of preprocessing methods and ensemble algorithms to effectively forecast ozone threshold exceedances, aiming to determine the relative importance of the different variables for the prediction of O
3 concentration.
We also compare the performance of ELM with other similar methods in
Table 5 [
37,
38,
39,
40,
41].
5. Conclusions
In this paper, we proposed the prediction of the concentration of air pollutants based on ELM, due to the drawbacks of FFANN-BP, such as low convergence and their tendency to get caught in the local minimum. Compared with FFANN-BP, ELM overcomes the above drawbacks. ELM has several interesting and significant advantages compared with FFANN-BP which are based on a gradient learning algorithm.
It was shown that ELM performs well in terms of precision, robustness, and generalization. There are no significant differences between the prediction accuracies of each model. ELM provided the best performance on indicators related to goodness of the prediction, such as and RMSE, etc. The present study revealed that ELM perform slightly better than those of the simple statistical techniques.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}