Exploration of Preterm Birth Rates Using the Public Health Exposome Database and Computational Analysis Methods


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Definitions
2.2. Data Sources
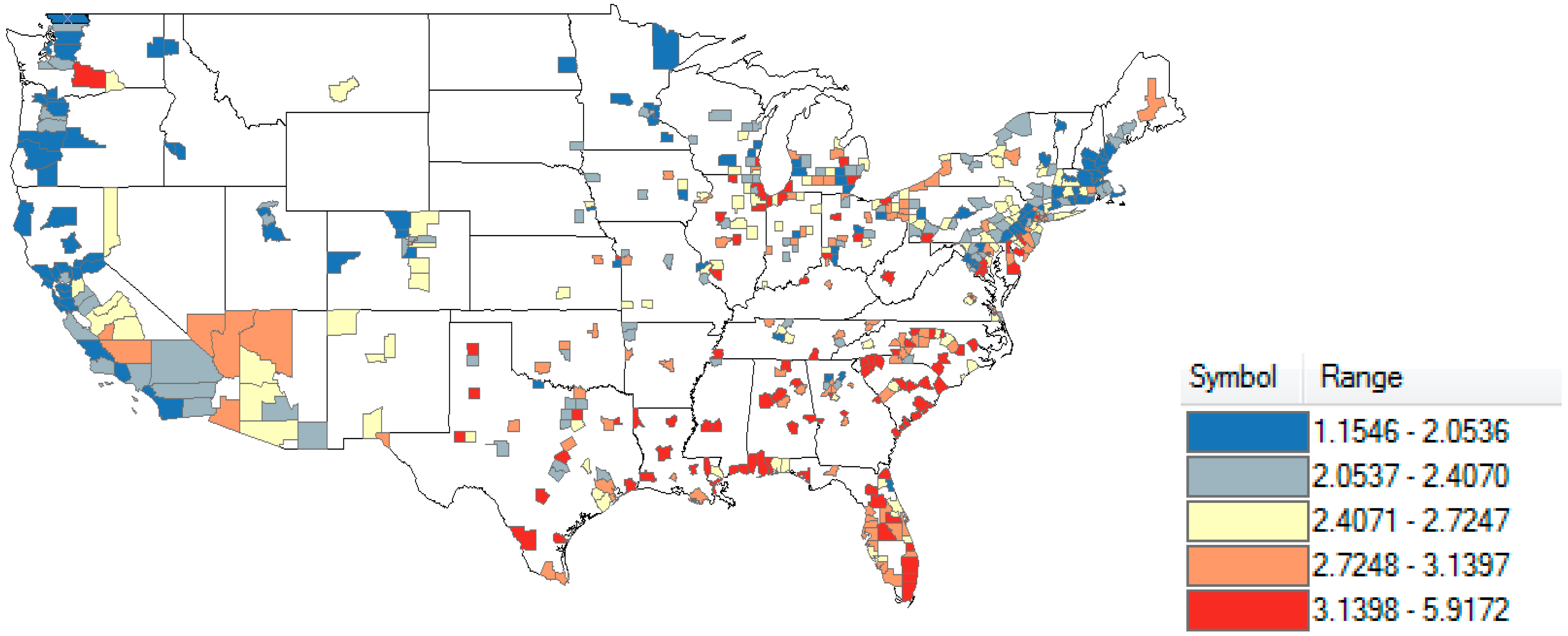
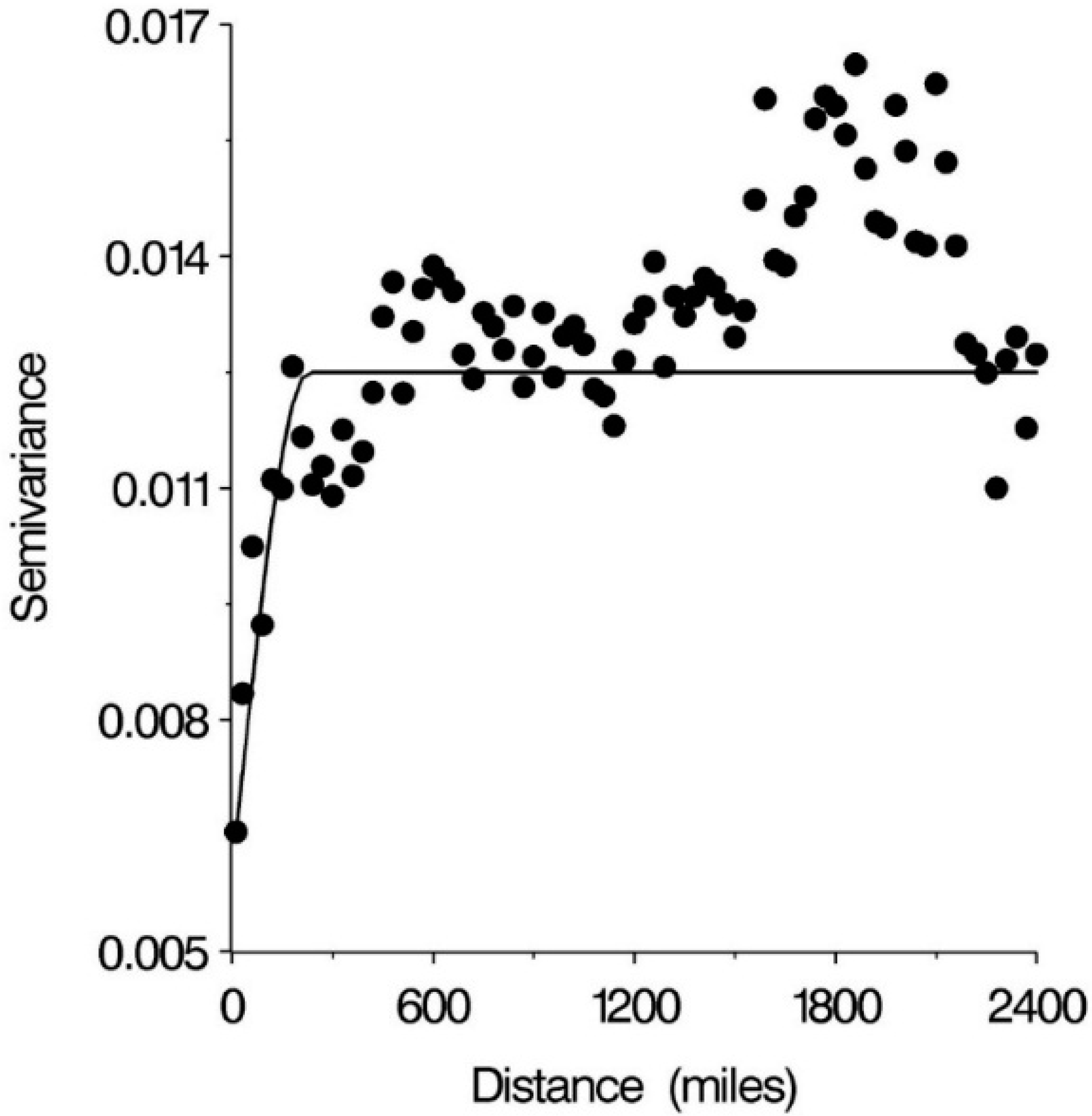
2.3. Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paraclique | Variables | Extracted Factors | Pearson Correlation of Factor to Logit Prematurity | N |
|---|---|---|---|---|
| 1. | Log (percent black/African Am pop, 2000) | Black population proportion | 0.686 | 520 |
| Black isolation index, 2000 | ||||
| Log (% Black, 2008) | ||||
| Rate gonorrhea, 2011 | STI | 0.710 | 520 | |
| Rate chlamydia, 2011 | ||||
| Black Protestant-rates of adherence per 1,000 population, (2010) | Excluded (missing values) | |||
| Low birth weight (<2500 gram) | Excluded (outcome variables) | |||
| Very low birth weight (<1500 gram) | ||||
| Premature birth; singleton births 24–33 weeks/singleton births ≥ 24 weeks | ||||
| 2. | Births to unmarried women | Married mother | −0.749 | 520 |
| % married mothers | ||||
| Percent Medicaid eligible female, 2004 | Medicaid | 0.428 | 520 | |
| Medicaid eligible total, 2004 | ||||
| Percent Medicaid eligible male, 2004 | Medicaid males | 0.465 | 520 | |
| Percent food stamp/SNAP * recipients, 2005 | Poverty and teen birth | 0.671 | 520 | |
| Poverty rate, 2008 | ||||
| Child poverty rate, 2008 | ||||
| Median household income | ||||
| Births to women under 18 | ||||
| SNAP *authorized stores/ 1000 pop, 2008 | Not included (below threshold for factors) | |||
| Free lunch %, 2008 | ||||
| 3. | Percent white population, 2000 | Race/STI | 0.468 | 439 |
| Rate HIV mortality | ||||
| Rate HIV prevalence | ||||
| Rate syphilis | ||||
| 4. | Number of days with maximum temperatures ≥ 90 degrees Farenheit | Temperature/Divorce | 0.433 | 512 |
| Daily maximum temperature 1999–2009 | ||||
| Divorced rate | ||||
| Average minimum daily temperature | Temperature/Land | 0.441 | 520 | |
| Average nightly land surface temperature | ||||
| Average daily land surface temperature | Sunlight | 0.219 | 520 | |
| Average direct solar radiation in kilojoules per square meter | ||||
| Percent less than 65 no health insurance | No Health Insurance | 0.203 | 520 | |
| Percent females less than 65 no health insurance | ||||
| 5. | Adult diabetes rate | Diabetes/Obesity | 0.603 | 520 |
| Age-adjusted rates of leisure-time physical inactivity, 2009 | ||||
| Adult obesity rate | ||||
| Age adjusted obesity rates, 2009 | ||||
| Average life expectancy | Excluded (outcome) | |||
| 6. | Rate of hospital admissions, 2005 | Hospital Admissions | 0.465 | 520 |
| Rate of short term general hospital admissions, 2005 | ||||
| Rate of short term community hospital admissions, 2005 | ||||
| Rate of medical/surgical intensive care beds, 2006 | Hospital Beds1 | 0.427 | 520 | |
| Rate of operating rooms, 2005 | ||||
| Rate of licensed beds short term hospital, 2005 | ||||
| Rate of licensed beds total hospital, 2005 | ||||
| Rate medical/surgical adult beds | ||||
| Rate of hospital beds, 2005 | Hospital Beds2 | 0.467 | 520 | |
| Rate of short term general hospital beds, 2005 | ||||
| Rate of total inpatient beds | ||||
| Rate surgical operations inpatient | Surgical Operations | 0.357 | 520 | |
| Rate surgical operations total | ||||
| Rate hospital beds | Hospital Beds3 | 0.416 | 520 | |
| Rate of short term community hospital. beds, 2005 | Not included (below threshold for factors) | |||
| 7. | Average daily maximum heat index | Heat Index | 0.492 | 511 |
| Daily maximum heat index 1999–2009 | ||||
| Log (number of days with maximum temperatures ≥ 100 degrees Farenheit) | ||||
| Index combining average fine particulate matter with average daily maximum temperature. | Pollution | 0.528 | 512 | |
| Normalized average fine particulate matter (2003–2008) plus average daily maximum heat index 1999–2009 | ||||
| 8. | Per capita income, 2005 | Income/Private Practice | −0.360 | 520 |
| Rate dentists private practice, 2007 | ||||
| Births to women over 40 | Mother’s Age | −0.563 | 520 | |
| Mean mother age | ||||
| Percent mother’s education > 15 years | Mother’s Education | −0.529 | 453 | |
| 9. | Median household income, white | Medicare Disabled/Income | 0.411 | 520 |
| Percent Medicare enrollment disabled hospital insurance, 2005 | ||||
| Percent Medicare enrollment disabled, 2005 | ||||
| Percent Medicare enrollment disabled supplementary medical insurance, 2005 | ||||
| Less than high school white female %, 2010 | Low Education White | 0.451 | 520 | |
| White low education %, 2000 | ||||
| 10. | College black female %, 2010 | Education Black | −0.491 | 387 |
| College black male %, 2010h | ||||
| Black high education %, 2000 | ||||
| Percent mothers education > 15 years, black | ||||
| Mean mother age, black | Income, Married, Age Black | −0.563 | 443 | |
| Median household income, 2000, black | ||||
| Per capita income 2010, black | ||||
| Married mothers, black | ||||
| 11. | GINI inequality index, 2000 | Income Inequality | 0.431 | 520 |
| Theil inequality index, 1990 | ||||
| Gini index, 2010 | ||||
| 12. | Black low education %, 2000 | Low Education, Black1 | 0.410 | 520 |
| Black male low education %, 2000 | ||||
| Black female low education %, 2000 | Low Education, Female Black2 | 0.471 | 520 | |
| Less than high school black male %, 2010 | Not included (below threshold for factors) | |||
| 13. | Median age black/African American female, 2000 | Aged Black | 0.443 | 520 |
| Percent African American females 65+, 2000 | ||||
| Percent African American males 65+, 2000 | ||||
| 14. | Separated/widow/divorced white %, 2010 | Separated White1 | 0.404 | 520 |
| Separated/widow/divorced white female %, 2010 | ||||
| Separated/widow/divorced white male%, 2010 | Separated White2 | 0.312 | 520 | |
| Percent divorced females | ||||
| 15. | Teen birth rate | Religion/Teenbirth/Stores | 0.510 | 520 |
| Convenience stores with gas/ 1000 pop, 2008 | ||||
| Evangelical Protestant rates of adherence per 1,000 population, (2010) |
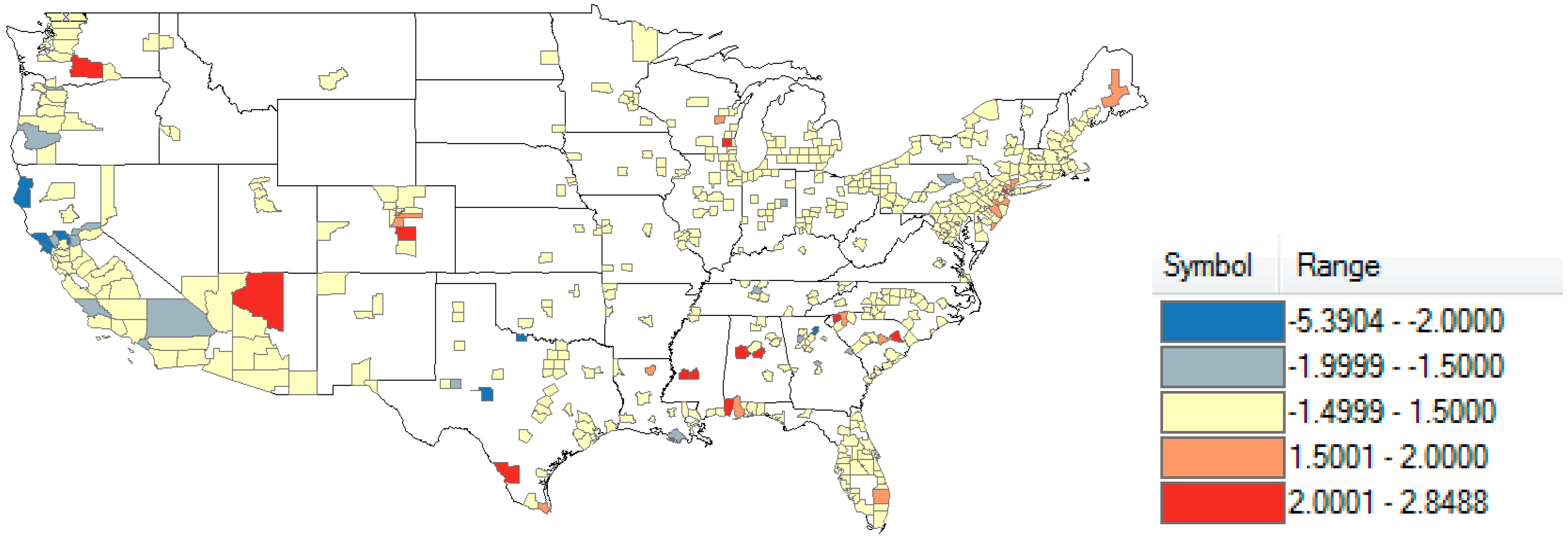
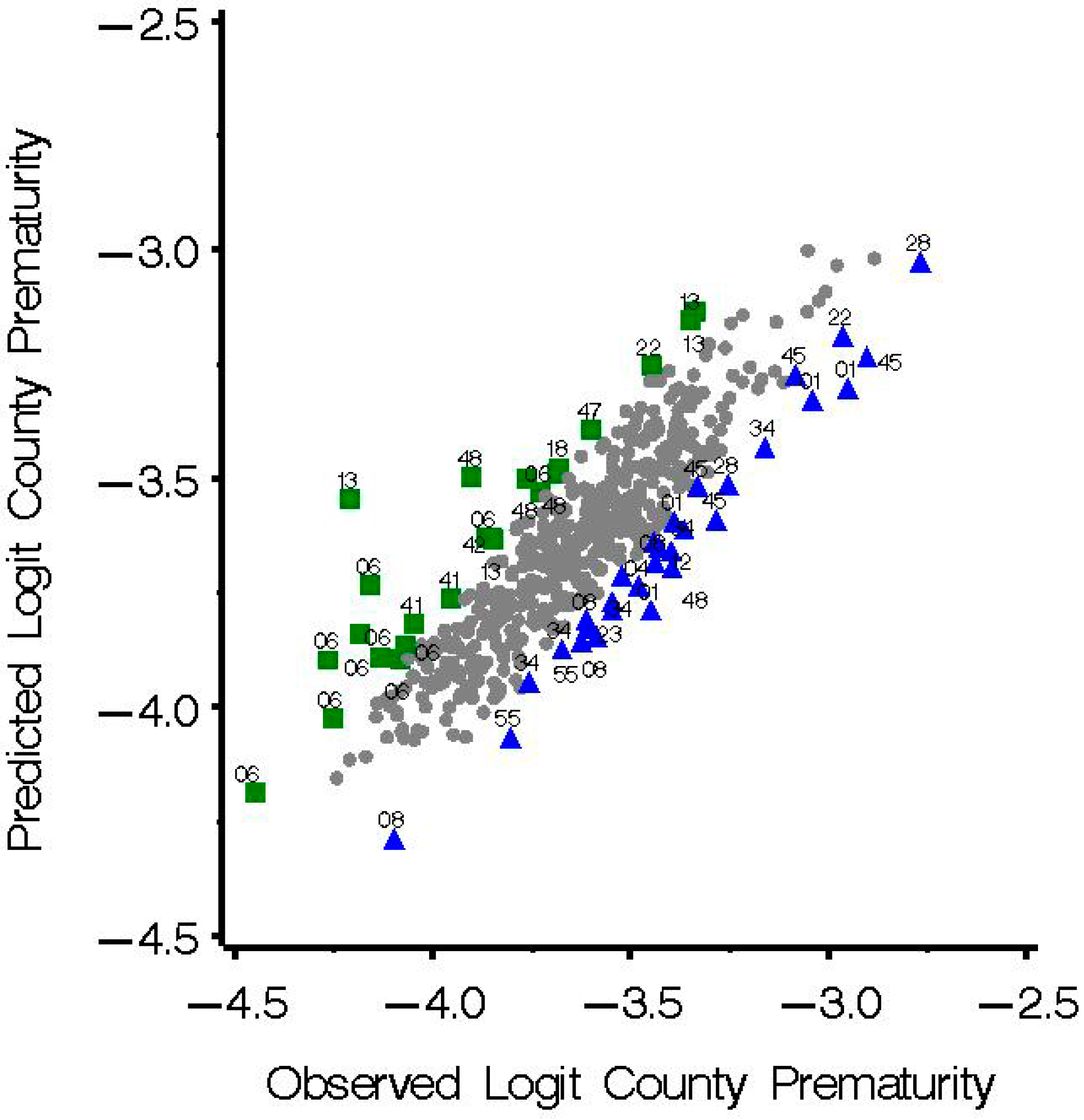
3. Results
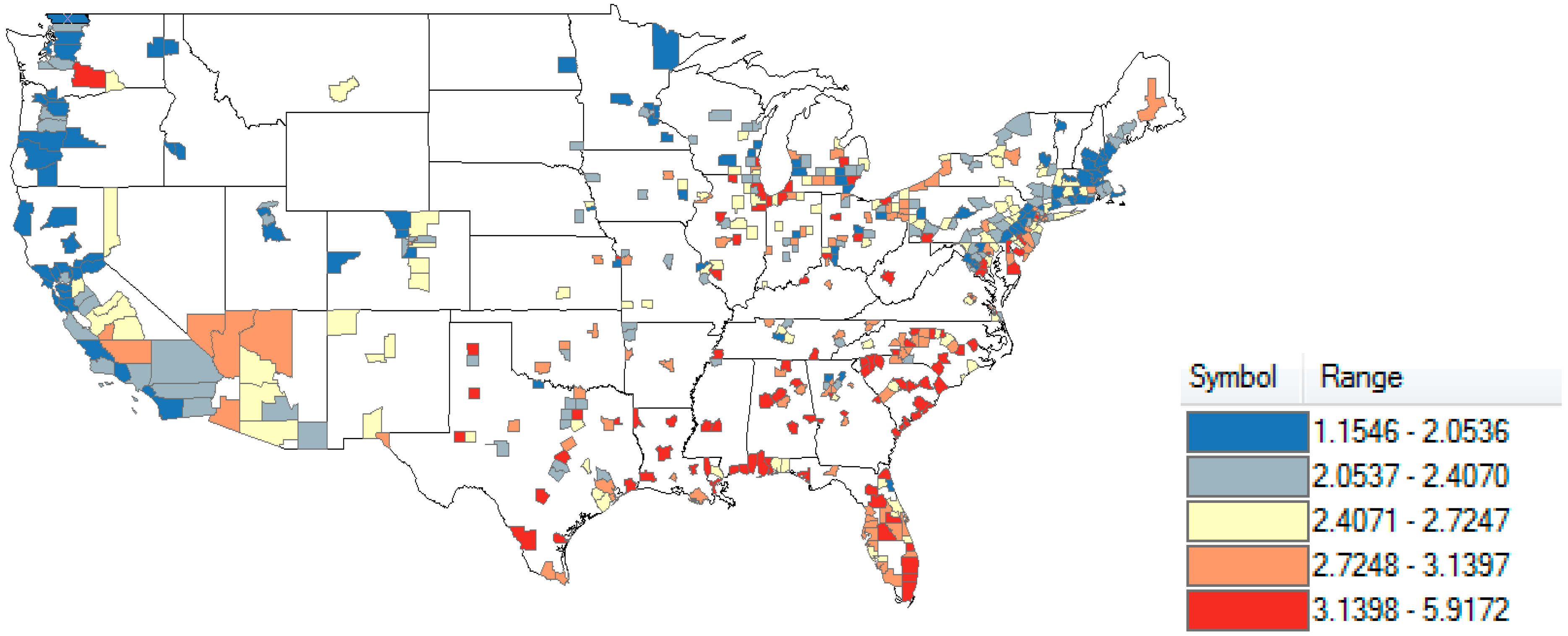
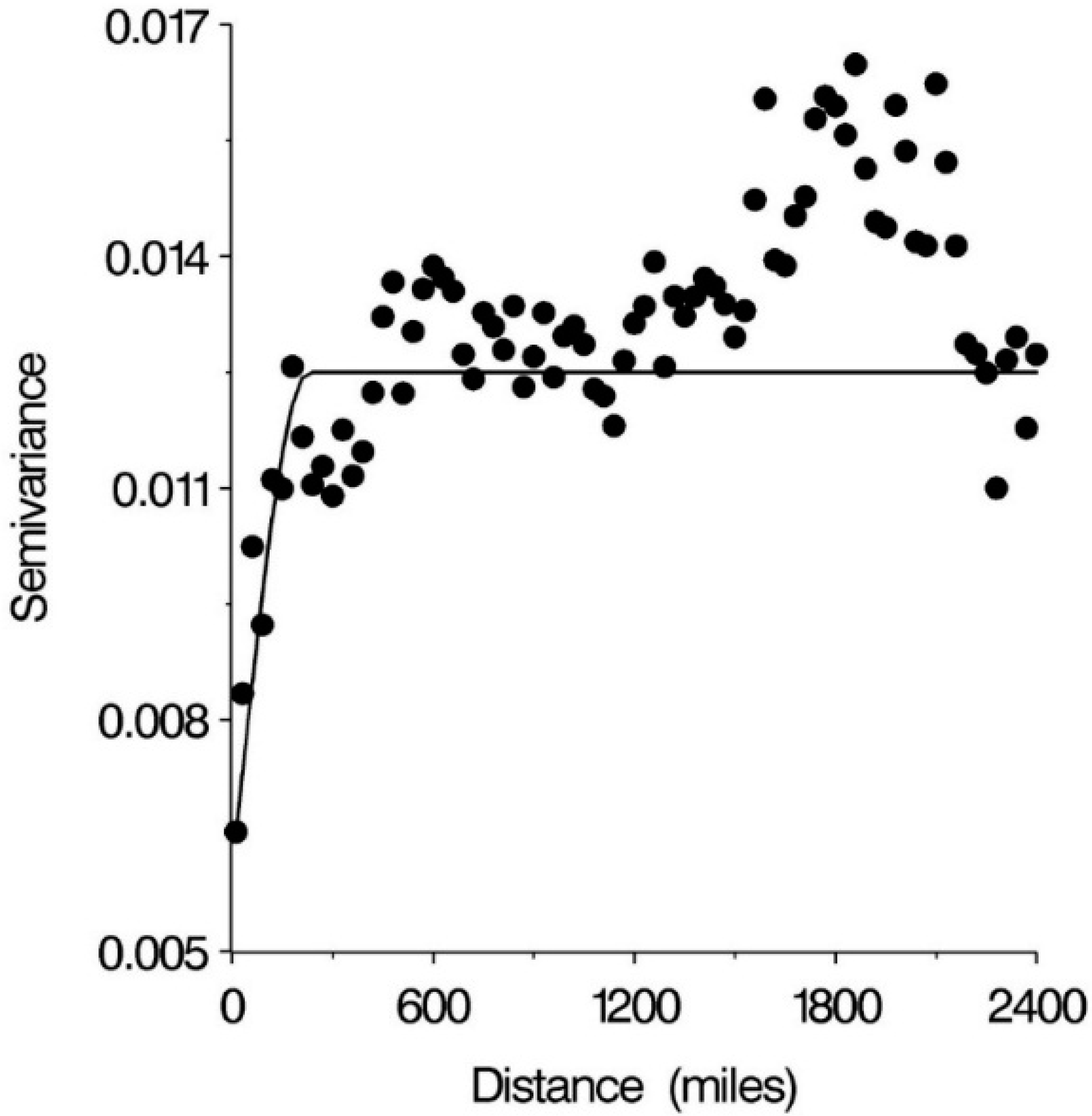
| Factor | Parameter Estimate | Standard Error | p | AIC |
|---|---|---|---|---|
| STI | 0.04431 | 0.00921 | <0.0001 | −837.6 |
| Black proportion | 0.05950 | 0.01000 | <0.0001 | |
| Married Mother | −0.07493 | 0.01001 | <0.0001 | |
| Diabetes/Obesity | 0.02879 | 0.01098 | 0.0090 | |
| Medicare Disabled/Income | 0.02275 | 0.00820 | 0.0058 | |
| Pollution | 0.03426 | 0.01095 | 0.0020 | |
| Income/Private Practice | 0.02481 | 0.00951 | 0.0094 | |
| Mother’s Age | −0.04749 | 0.01324 | 0.0004 | |
| No Health Insurance | 0.03449 | 0.00799 | <0.0001 |
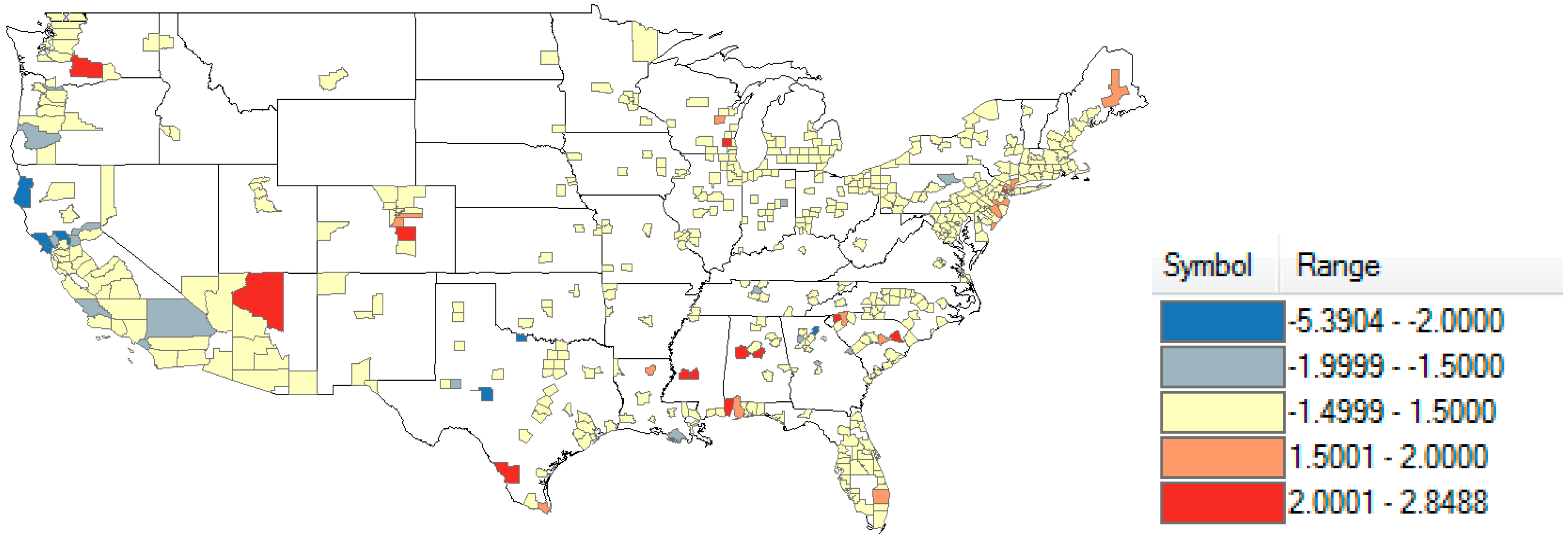
| Humboldt County, California | Shelby County, Alabama |
| Wichita County, Texas | Florence County, South Carolina |
| Sonoma County, California | Webb County, Texas |
| Yolo County, California | Pickens County, South Carolina |
| Marin County, California | Tuscaloosa County, Alabama |
| Tom Green County, Texas | Essex County, New Jersey |
| El Paso County, Colorado | |
| Yakima County, Washington | |
| Rankin County, Mississippi | |
| Waukesha County, Wisconsin | |
| Hinds County, Mississippi |
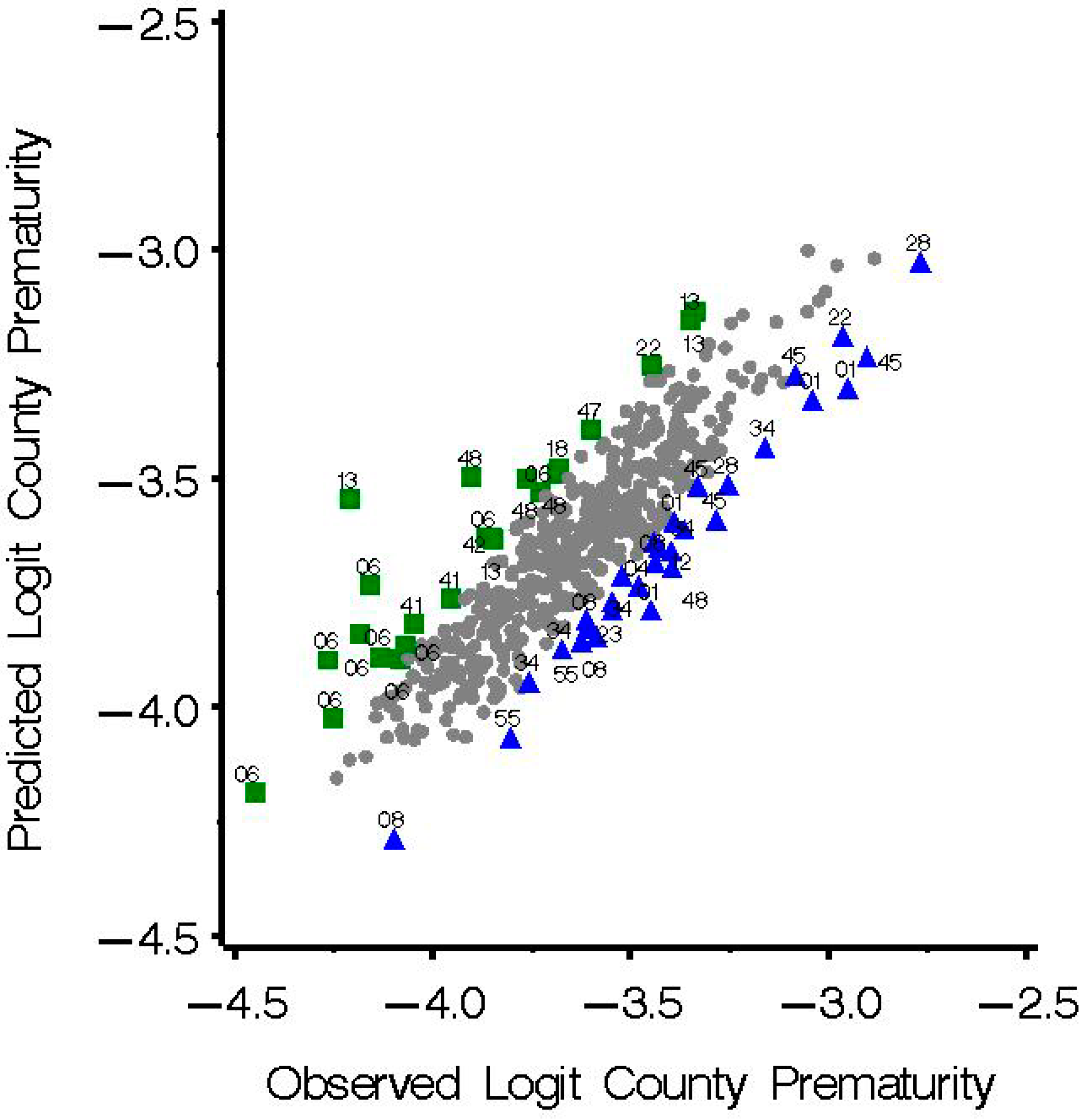
| Overpredicted Group, Studentized Residuals <−1.5 | Studentized Residuals −1.5–+1.5 | Underpredicted Group, Studentized Residuals > +1.5 | p | |
|---|---|---|---|---|
| Prenatal care not received in first 3 months of pregnancy | 16.3%, N = 19 | 14.8%, N = 405 | 18.5%, N = 23 | 0.0197 |
| Poverty rate | 14.1%, N = 23 | 12.2%, N = 459 | 12.8%, N = 30 | 0.2901 |
| Non-Hispanic Black Proportion | 5.5%, N = 23 | 7.6%, N = 459 | 9.6%, N = 30 | 0.3929 |
| Non-Hispanic White Proportion | 64.4%, N = 23 | 77.4%, N = 459 | 64.7%, N = 30 | 0.0079 |
| Age Adjusted Obesity 2009 | 27.8%, N = 23 | 28.4%, N = 459 | 27.2%, N = 30 | 0.2802 |
| Rate Gonorrhea | 116.4/100,000, N = 23 | 67.8/100,000, N = 459 | 62.3/100,000, N = 30 | 0.9458 |
| Mean Mother Age | 27.0, N = 23 | 27.2, N = 459 | 27.1, N = 30 | 0.6735 |
| Mother smoker | 10.7%, N = 9 | 12.9%, N = 383 | 8.6%, N = 23 | 0.0065 |
| Married mothers | 61.2%, N = 23 | 64.2%, N = 459 | 65.8%, N = 30 | 0.6742 |
| Mothers education >15 years | 26.3%, N = 19 | 25.6%, N = 405 | 27.1%, N = 23 | 0.7891 |
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Callaghan, W.M.; MacDorman, M.F.; Rasmussen, S.A.; Qin, C.; Lackritz, E.M. The contribution of preterm birth to infant mortality rates in the United States. Pediatrics 2006, 118, 1566–1573. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, B.E.; Martin, J.A.; Ventura, S.J. Births: Preliminary Data for 2011. Available online: http://www.cdc.gov/nchs/products/nvsr.htm (accessed on 8 October 2014).
- Hoyert, D.L.; Xu, J. Deaths: Preliminary Data for 2011. Available online: http://www.cdc.gov/nchs/products/nvsr.htm (accessed on 8 October 2014).
- MacDorman, M.F.; Hoyert, D.L.; Mathews, T.J. Recent declines in infant mortality in the United States, 2005–2011. NCHS Data Brief 2013, 120, 1–8. [Google Scholar] [PubMed]
- Centers for Disease Control and Prevention. Reproductive Health: Preterm Birth. Available online: http://www.cdc.gov/reproductivehealth/maternalinfanthealth/pretermbirth.htm (accessed on 8 October 2014).
- O’Campo, P.; Burke, J.G.; Culhane, J.; Elo, I.T.; Eyster, J.; Holzman, C.; Messer, L.C.; Kaufman, J.S.; Laraia, B.A. Neighborhood deprivation and preterm birth among non-hispanic black and white women in eight geographic areas in the United States. Am. J. Epidemiol. 2008, 167, 155–163. [Google Scholar] [CrossRef] [PubMed]
- Schoendorf, K.C.; Hogue, C.J.; Kleinman, J.C.; Rowley, D. Mortality among infants of black as compared with white college-educated parents. N. Engl. J. Med. 1992, 326, 1522–1526. [Google Scholar] [CrossRef] [PubMed]
- Foster, H.W.; Wu, L.; Bracken, M.B.; Semenya, K.; Thomas, J.; Thomas, J. Intergenerational effects of high socioeconomic status on low birthweight and preterm birth in African Americans. J. Natl. Med. Assoc. 2000, 92. [Google Scholar] [CrossRef]
- Rappazzo, K.M.; Daniels, J.L.; Messer, L.C.; Poole, C.; Lobdell, D.T. Exposure to fine particulate matter during pregnancy and risk of preterm birth among women in New Jersey, Ohio, and Pennsylvania, 2000–2005. Environ. Health Perspect. 2014, 122, 992–997. [Google Scholar] [PubMed]
- Goldenberg, R.L.; Cliver, S.P.; Mulvihill, F.X.; Hickey, C.A.; Hoffman, H.J.; Klerman, L.V.; Johnson, M.J. Medical, psychosocial, and behavioral risk factors do not explain the increased risk for low birth weight among black women. Am. J. Obstet. Gynecol. 1996, 175, 1317–1324. [Google Scholar] [CrossRef] [PubMed]
- Wild, C.P. The exposome: From concept to utility. Int. J. Epidemiol. 2012, 41, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Juarez, P. Sequencing the public health genome. J. Health Care Poor Underserved 2013, 24, 114–120. [Google Scholar] [CrossRef] [PubMed]
- Juarez, P.D.; Matthews-Juarez, P.; Hood, D.B.; Im, W.; Levine, R.S.; Kilbourne, B.J.; Langston, M.A.; Alhamdan, M.Z.; Crosson, W.L.; Estes, M.G.; et al. A population-based, exposure science approach to health disparities research. Int. J. Environ. Res. Public Health. (accepted for publication).
- Jay, J.J.; Eblen, J.D.; Zhang, Y.; Benson, M.; Perkins, A.D.; Saxton, A.M.; Voy, B.H.; Chesler, E.J.; Langston, M.A. A systematic comparison of genome-scale clustering algorithms. BMC Bioinform. 2012, 13. [Google Scholar] [CrossRef]
- Chesler, E.J.; Langston, M.A. Combinatorial genetic regulatory network analysis tools for high throughput transcriptomic data. In Systems Biology and Regulatory Genomics; Eskin, E., Ed.; Springer: Berlin/Heidelberg, Germany; Volume 4023, pp. 150–165.
- United States Department of Health and Human Services Centers for Disease Control and Prevention. National center for health statistics, Division of Vital Statistics, Natality Public-Use Data CDC Wonder Online Database. Available online: http://wonder.cdc.gov/natality/.html (accessed on 8 October 2014).
- National Center for Health Statistics. Hyattsville, Maryland. Datafile 2004. Available online: http://www.nber.org/data/vital-statistics-natality-data.html (accessed on 8 February 2014).
- National Center for Health Statistics. Hyattsville, Maryland. Datafile 2002. Available online: http://www.nber.org/data/vital-statistics-natality-data.html (accessed on 8 February 2014).
- CDC WONDER Online Database. Daily Fine Particulate Matter (PM2.5) (µg/m³) for years 2003–2008. Available online: http://wonder.cdc.gov/NASA-PM.html (accessed on 8 October 2014).
- National Center for Chronic Disease Prevention and Health Promotion Division of Diabetes Translation. Diabetes Interactive Atlases. Maps and Data Tables. County Data. Available online: http://www.cdc.gov/diabetes/atlas/interactive_atlas.htm (accessed on 8 October 2014).
- US Department of Health and Human Services Health Resources and Services Administration Bureau of Health Professions Rockville MD. Area Resource File, 2011–2012. Available online: http://ahrf.hrsa.gov/ (accessed on 8 October 2014).
- GeoDa Center for Geospatial Analysis and Computation. Diversity and Social Segregation. Available online: http://geodacenter.asu.edu/%5Btermalias-raw%5D/diversity-and-s-0 (accessed on 8 October 2014).
- US Department of Health and Human Services Centers for Disease Control and Prevention National Center for HIV STD and TB Prevention (NCHSTP). Sexually Transmitted diseasE Morbidity 1996–2011, by Gender, Age Group and Race/Ethnicity. C.D.C. Wonder Online Database. Available online: http://wonder.cdc.gov/wonder/help/std-std-race-age.html (accessed on 8 December 2013).
- Centers for Disease Control and Prevention National Center for Health Statistics. Underlying Cause of Death 1999–2010 on CDC Wonder Online Database. Available online: http://wonder.cdc.gov/ucd-icd10.html (accessed on 8 November 2013).
- Langston, M.A.; Levine, R.S.; Kilbourne, B.J.; Rogers, G.L.; Kershenbaum, A.D.; Baktash, S.H.; Coughlin, S.S.; Saxton, A.M.; Agboto, V.K.; Hood, D.B.; et al. Scalable combinatorial tools for health disparities research. Int. J. Environ. Res. Public Health 2014, 11, 10419–10443. [Google Scholar] [CrossRef] [PubMed]
- Perkins, A.D.; Langston, M.A. Threshold selection in gene co-expression networks using spectral graph theory techniques. BMC Bioinform. 2009, 10. [Google Scholar] [CrossRef]
- Consulting group of the Division of Statistics and Scientific Computing at the University of Texas at Austin. Institute for Digital Research and Education. U.C.L.A. Factor Analysis Using SAS Proc Factor. Available online: http://www.ats.ucla.edu/stat/sas/library/factor_ut.htm (accessed on 8 October 2014).
- SAS/STAT(R) 9.22 User’s Guide. Available online: http://support.sas.com/documentation/cdl/en/statug/63347/HTML/default/viewer.htm#statug_factor_sect006.htm (accessed on 8 October 2014).
- Nagelkerke, N.J.D. A note on a general definition of the coefficient of determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Fry-Johnson, Y.W.; Levine, R.; Rowley, D.; Agboto, V.; Rust, G. United States black: White infant mortality disparities are not inevitable: Identification of community resilience independent of socioeconomic status. Ethn. Dis. 2010, 20, S131–S135. [Google Scholar]
- Levine, R.S.; Briggs, N.C.; Kilbourne, B.S.; King, W.D.; Fry-Johnson, Y.; Baltrus, P.T.; Husaini, B.A.; Rust, G.S. Black–white mortality from HIV in the united states before and after introduction of highly active antiretroviral therapy in 1996. Am. J. Public Health 2007, 97, 1884. [Google Scholar] [CrossRef] [PubMed]
- Suhr, D.D. Sugi 31. Statistics and Data Analysis. Paper 200–31. Exploratory or Confirmatory Factor Analysis. Available online: http://www2.sas.com/proceedings/sugi31/200–C31.pdf (accessed on 8 October 2014).
- Cnattingius, S.; Villamor, E.; Johansson, S.; Edstedt Bonamy, A.K.; Persson, M.; Wikström, A.K.; Granath, F. Maternal obesity and risk of preterm delivery. JAMA 2013, 309, 2362–2370. [Google Scholar] [CrossRef] [PubMed]
- Berkowitz, G.S.; Blackmore-Prince, C.; Lapinski, R.H.; Savitz, D.A. Risk factors for preterm birth subtypes. Epidemiology 1998, 9, 279–285. [Google Scholar] [CrossRef] [PubMed]
- Hedderson, M.M.; Ferrara, A.; Sacks, D.A. Gestational diabetes mellitus and lesser degrees of pregnancy hyperglycemia: Association with increased risk of spontaneous preterm birth. Obstet. Gynecol. 2003, 102, 850–856. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention. 2011 Sexually Transmitted Disease Surveillance. S.T.Ds in Racial and Ethnic Minorities. Available online: http://www.cdc.gov/std/stats11/minorities.htm (accessed on 8 October 2014).
- Donders, G.; Desmyter, J.; de Wet, D.; van Assche, F.A. The association of gonorrhoea and syphilis with premature birth and low birthweight. Genitourin. Med. 1993, 69, 98–101. [Google Scholar] [PubMed]
- Mann, J.R.; McDermott, S.; Gill, T. Sexually transmitted infection is associated with increased risk of preterm birth in South Carolina women insured by Medicaid. J. Maternal-Fetal Neonatal Med. 2010, 23, 563–568. [Google Scholar] [CrossRef]
- Fiscella, K. Racial disparities in preterm births. The role of urogenital infections. Public Health Rep. 1996, 111, 104–113. [Google Scholar] [PubMed]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kershenbaum, A.D.; Langston, M.A.; Levine, R.S.; Saxton, A.M.; Oyana, T.J.; Kilbourne, B.J.; Rogers, G.L.; Gittner, L.S.; Baktash, S.H.; Matthews-Juarez, P.; et al. Exploration of Preterm Birth Rates Using the Public Health Exposome Database and Computational Analysis Methods. Int. J. Environ. Res. Public Health 2014, 11, 12346-12366. https://doi.org/10.3390/ijerph111212346
Kershenbaum AD, Langston MA, Levine RS, Saxton AM, Oyana TJ, Kilbourne BJ, Rogers GL, Gittner LS, Baktash SH, Matthews-Juarez P, et al. Exploration of Preterm Birth Rates Using the Public Health Exposome Database and Computational Analysis Methods. International Journal of Environmental Research and Public Health. 2014; 11(12):12346-12366. https://doi.org/10.3390/ijerph111212346
Chicago/Turabian StyleKershenbaum, Anne D., Michael A. Langston, Robert S. Levine, Arnold M. Saxton, Tonny J. Oyana, Barbara J. Kilbourne, Gary L. Rogers, Lisaann S. Gittner, Suzanne H. Baktash, Patricia Matthews-Juarez, and et al. 2014. "Exploration of Preterm Birth Rates Using the Public Health Exposome Database and Computational Analysis Methods" International Journal of Environmental Research and Public Health 11, no. 12: 12346-12366. https://doi.org/10.3390/ijerph111212346
APA StyleKershenbaum, A. D., Langston, M. A., Levine, R. S., Saxton, A. M., Oyana, T. J., Kilbourne, B. J., Rogers, G. L., Gittner, L. S., Baktash, S. H., Matthews-Juarez, P., & Juarez, P. D. (2014). Exploration of Preterm Birth Rates Using the Public Health Exposome Database and Computational Analysis Methods. International Journal of Environmental Research and Public Health, 11(12), 12346-12366. https://doi.org/10.3390/ijerph111212346