
Automatic Target Detection from Satellite Imagery Using Machine Learning

 , ,
, ,  , and
, and 
Abstract
1. Introduction
1.1. Satellite Imagery
1.2. Satellite Imagery Acquisition for CV Applications
1.3. Object Detection in Satellite Images
1.4. Challenges in Satellite Images
1.5. Problem Statement
2. Contributions
- We created a dataset with object aircraft of satellite images and apply preprocessing techniques on the dataset for testing and training.
- We increased the number of objects in a dataset for achieving accuracy and also decreased the computational cost using low-resolution images.
- We carried out a survey of the existing approaches/algorithms used for detection of objects (aircraft) in satellite imagery.
- A comparison of performance of major algorithms (in terms of execution speed and accuracy) for detection and classification of aircraft in satellite imagery using custom dataset was performed. There are five sections to this study.
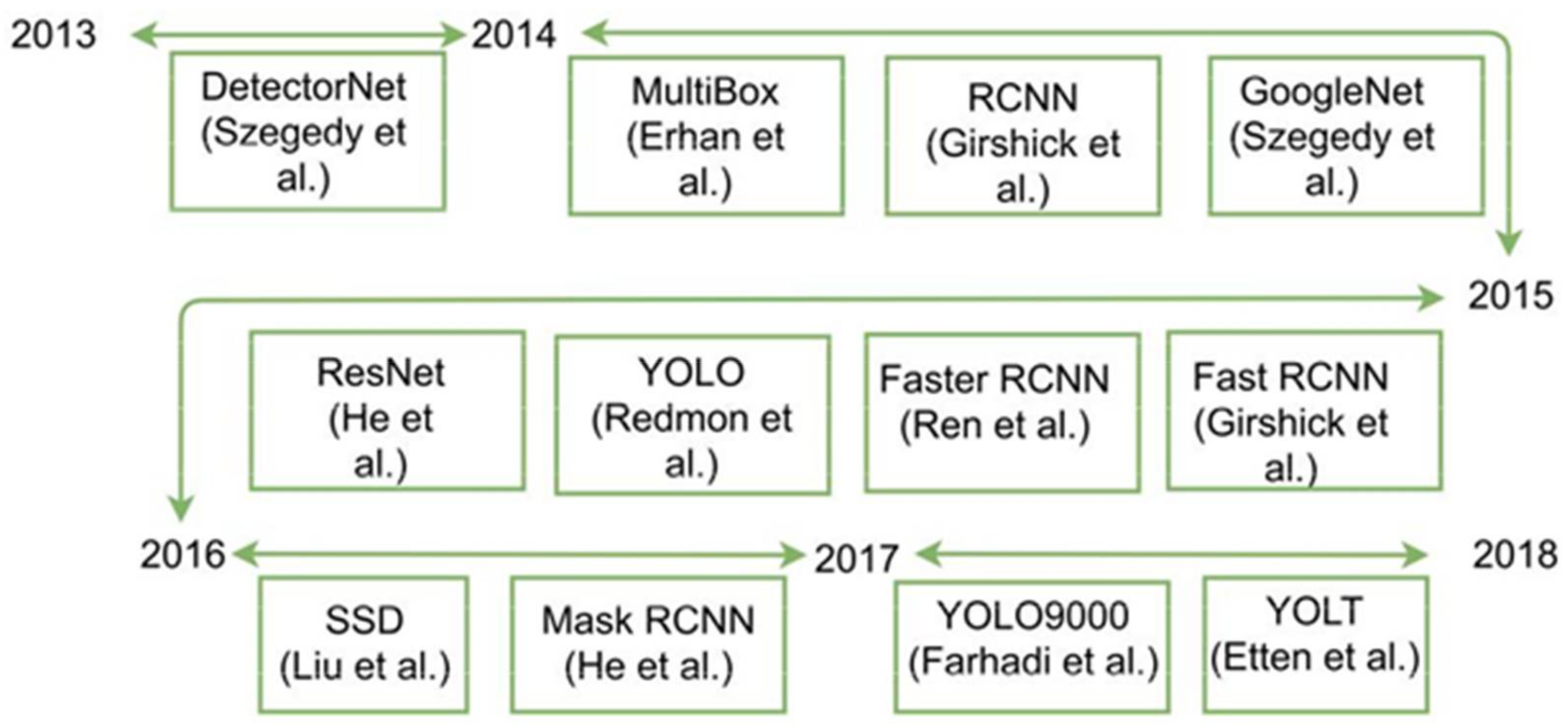
3. Related Work
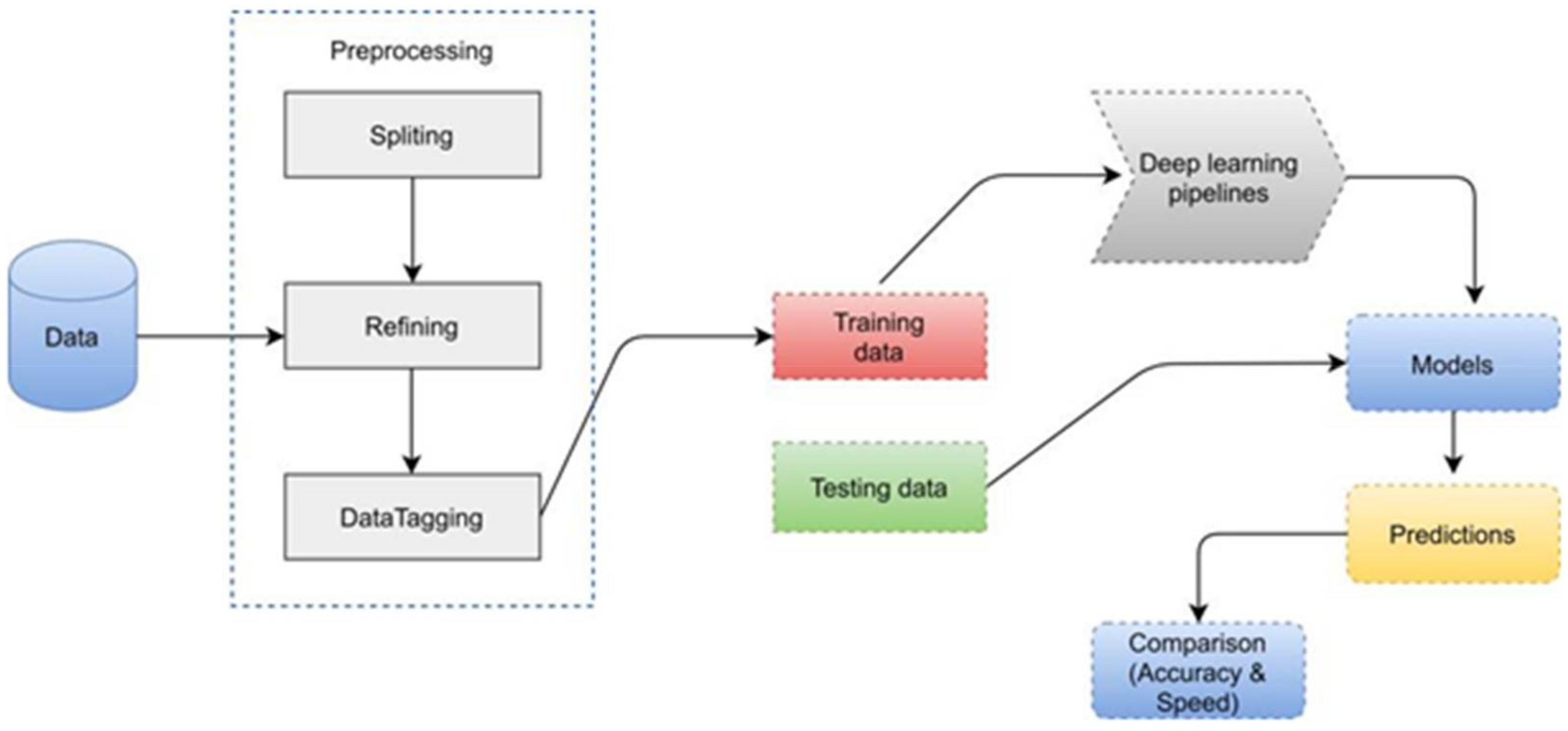
4. Methodology
4.1. Network Architectures
4.1.1. Faster RCNN
4.1.2. YOLO
4.1.3. SSD
4.1.4. SIMRDWN
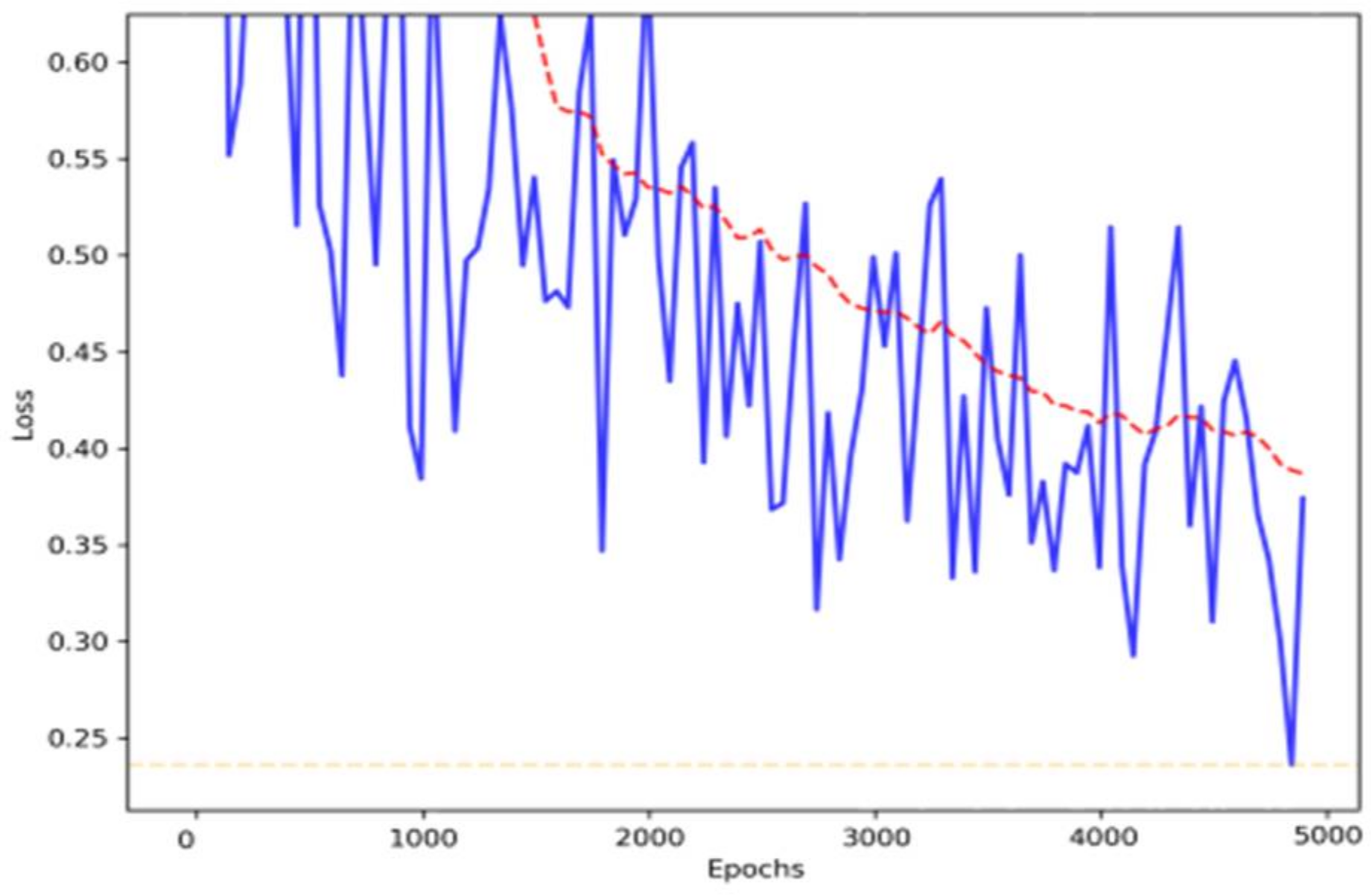
4.2. Network Training
4.2.1. Faster RCNN
4.2.2. YOLO
4.2.3. SSD
4.2.4. SIMRDWN
5. Results
5.1. Network Validation of Faster RCNN
5.2. Network Validation of YOLO
5.3. Network Validation of SSD
5.4. Network Validation of SIMRDWN
5.5. Interface Time
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
List of Abbreviations
| Faster RCNN | Faster region-based convolutional neural network |
| YOLO | You only look once |
| SSD | Single-shot detector |
| AI | Artificial intelligence |
| CV | Computer vision |
| NLP | Natural language processing |
| ML | Machine learning |
| NN | Neural networks |
| CNN | Convolutional neural network |
| YOLT | You only look twice |
| CONV | Convolutional |
| VGG | Visual geometry group |
| ISPRS | International Society for Photogrammetry and Remote Sensing |
| SIMRDWN | Satellite imagery multiscale rapid detection with windowed networks |
References
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Munawar, H.S.; Mojtahedi, M.; Hammad, A.W.A.; Kouzani, A.; Mahmud, M.A.P. Disruptive technologies as a solution for disaster risk management: A review. Sci. Total Environ. 2021, 151351. [Google Scholar] [CrossRef] [PubMed]
- Sherrah, J. Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery. arXiv 2016, preprint. arXiv:1606.02585. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Akram, J.; Javed, A.; Khan, S.; Akram, A.; Munawar, H.S.; Ahmad, W. Swarm intelligence based localization in wireless sensor networks. In Proceedings of the ACM Symposium on Applied Computing, Gwangju, Korea, 22–26 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1906–1914. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khalid, U.; Maqsood, A. Fire detection through Image Processing; A brief overview. Int. Conf. Cult. Technol. 2017, 203–208. [Google Scholar]
- Khan, M.J.; Yousaf, A.; Javed, N.; Nadeem, S.; Khurshid, K. Automatic Target Detection in Satellite Images using Deep Learning. J. Space Technol. 2017, 7, 44–49. [Google Scholar]
- Lu, J.; Ma, C.; Li, L.; Xing, X.; Zhang, Y.; Wang, Z.; Xu, J. A Vehicle Detection Method for Aerial Image Based on YOLO. J. Comput. Commun. 2018, 6, 98–107. [Google Scholar] [CrossRef]
- Suliman Munawar, H. An Overview of Reconfigurable Antennas for Wireless Body Area Networks and Possible Future Prospects. Int. J. Wirel. Microw. Technol. 2020, 10, 1–8. [Google Scholar] [CrossRef]
- Marcum, R.A.; Davis, C.H.; Scott, G.J.; Nivin, T.W. Rapid broad area search and detection of Chinese surface-to-air missile sites using deep convolutional neural networks. J. Appl. Remote Sens. 2017, 11, 1. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Suliman Munawar, H. Reconfigurable Origami Antennas: A Review of the Existing Technology and its Future Prospects. Int. J. Wirel. Microw. Technol. 2020, 10, 34–38. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The Isprs Benchmark On Urban Object Classification And 3d Building Reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1–3, 293–298. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, Z.; Wu, J. A Hierarchical Oil Tank Detector With Deep Surrounding Features for High-Resolution Optical Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4895–4909. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khan, S.I.; Ullah, F.; Kouzani, A.Z.; Parvez Mahmud, M.A. Effects of COVID-19 on the Australian economy: Insights into the mobility and unemployment rates in education and tourism sectors. Sustainability 2021, 13, 11300. [Google Scholar] [CrossRef]
- Radovic, M.; Adarkwa, O.; Wang, Q. Object recognition in aerial images using convolutional neural networks. J. Imaging 2017, 3, 21. [Google Scholar] [CrossRef]
- Munawar, H.S. Applications of leaky-wave antennas: A review. Int. J. Wirel. Microw. Technol. (IJWMT) 2020, 10, 56–62. [Google Scholar]
- Rachwan, J. 3D Labeling Tool. 2019. Available online: https://digitalgate.usek.edu.lb/xmlui/handle/1050/4471. (accessed on 13 October 2021).
- Qassim, H.; Verma, A.; Feinzimer, D. Compressed residual-VGG16 CNN model for big data places image recognition. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 169–175. [Google Scholar] [CrossRef]
- Suliman Munawar, H.; Khalid, U.; Jilani, R.; Maqsood, A. Version Management by Time Based Approach in Modern Era. Int. J. Educ. Manag. Eng. 2017, 7, 13–20. [Google Scholar] [CrossRef]
- Abbas, Q.; Ibrahim, M.E.A.; Jaffar, M.A. A comprehensive review of recent advances on deep vision systems. Artif. Intell. Rev. 2019, 52, 39–76. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Suliman Munawar, H.; Ali Awan, A.; Khalid, U.; Munawar, S.; Maqsood, A. Revolutionizing Telemedicine by Instilling H.265. Int. J. Image Graph. Signal Processing 2017, 9, 20–27. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, preprint. arXiv:1804.02767. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, preprint. arXiv:1803.08375. [Google Scholar]
- Munawar, H.S. Image and Video Processing for Defect Detection in Key Infrastructure. Mach. Vis. Insp. Syst. 2020, 1, 159–177. [Google Scholar] [CrossRef]
- Kabani, A.; El-Sakka, M.R. Object Detection and Localization Using Deep Convolutional Networks with Softmax Activation and Multi-class Log Loss. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016; pp. 358–366. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R.C. Empirical study of particle swarm optimization. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; pp. 1945–1950. [Google Scholar] [CrossRef]
- Munawar, H.S.; Inam, H.; Ullah, F.; Qayyum, S.; Kouzani, A.Z.; Mahmud, M.A.P. Towards smart healthcare: Uav-based optimized path planning for delivering COVID-19 self-testing kits using cutting edge technologies. Sustainability 2021, 13, 10426. [Google Scholar] [CrossRef]
- Ullah, F.; Khan, S.I.; Munawar, H.S.; Qadir, Z.; Qayyum, S. Uav based spatiotemporal analysis of the 2019–2020 new south wales bushfires. Sustainability 2021, 13, 10207. [Google Scholar] [CrossRef]
- Gu, C.; Fan, L.; Wu, W.; Huang, H.; Jia, X. Greening cloud data centers in an economical way by energy trading with power grid. Future Gener. Comput. Syst. 2018, 78, 89–101. [Google Scholar] [CrossRef]
- Munawar, H.S. Flood Disaster Management: Risks, Technologies, and Future Directions. Mach. Vis. Insp. Syst. Image Processing Concepts Methodol. Appl. 2020, 1, 115–146. [Google Scholar]
- Hameed, A.; Khoshkbarforoushha, A.; Ranjan, R.; Jayaraman, P.P.; Kolodziej, J.; Balaji, P.; Zeadally, S.; Malluhi, Q.M.; Tziritas, N.; Vishnu, A.; et al. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems. Computing 2016, 98, 751–774. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Heravi, A. Application of Deep Learning on UAV-Based Aerial Images for Flood Detection. Smart Cities 2021, 4, 1220–1243. [Google Scholar] [CrossRef]
- Abido, M.A. A niched Pareto genetic algorithm for multiobjective environmental/economic dispatch. Int. J. Electr. Power Energy Syst. 2003, 25, 97–105. [Google Scholar] [CrossRef]
- Hussain, B.; Hasan, Q.U.; Javaid, N.; Guizani, M.; Almogren, A.; Alamri, A. An Innovative Heuristic Algorithm for IoT-Enabled Smart Homes for Developing Countries. IEEE Access 2018, 6, 15550–15575. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T. A review on flood management technologies related to image processing and machine learning. Autom. Constr. 2021, 132, 103916. [Google Scholar] [CrossRef]
- Hussain, M.M.; Alam, M.S.; Beg, M.M.S. Fog Computing in IoT Aided Smart Grid Transition- Requirements, Prospects, Status Quos and Challenges. arXiv 2018, preprint. arXiv:1802.01818. [Google Scholar]
- Ibrahim, A.S.; Hamlyn-Harris, J.; Grundy, J. Emerging Security Challenges of Cloud Virtual Infrastructure. arXiv 2016, preprint. arXiv:1612.09059. [Google Scholar]
- Liaquat, M.U.; Munawar, H.S.; Rahman, A.; Qadir, Z.; Kouzani, A.Z.; Mahmud, M.A.P. Localization of sound sources: A systematic review. Energies 2021, 14, 3910. [Google Scholar] [CrossRef]
- Akram, J.; Najam, Z.; Rafi, A. Efficient resource utilization in cloud-fog environment integrated with smart grids. In Proceedings of the 2018 International Conference on Frontiers of Information Technology, FIT 2018, Islamabad, Pakistan, 17–19 December 2019; pp. 188–193. [Google Scholar] [CrossRef]
- Akram, J.; Najam, Z.; Rizwi, H. Energy Efficient Localization in Wireless Sensor Networks Using Computational Intelligence. In Proceedings of the 2018 15th International Conference on Smart Cities: Improving Quality of Life Using ICT and IoT, HONET-ICT 2018, Islamabad, Pakistan, 8–10 October 2018; pp. 78–82. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T.; Thaheem, M.J.; Shrestha, A. An integrated approach for post-disaster flood management via the use of cutting-edge technologies and UAVs: A review. Sustainability 2021, 13, 7925. [Google Scholar] [CrossRef]
- Wang, J.; Ju, C.; Gao, Y.; Sangaiah, A.K.; Kim, G.J. A PSO based energy efficient coverage control algorithm for wireless sensor networks. Comput. Mater. Contin. 2018, 56, 433–446. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Khan, S.I.; Mojtahedi, M. Uavs in disaster management: Application of integrated aerial imagery and convolutional neural network for flood detection. Sustainability 2021, 13, 7547. [Google Scholar] [CrossRef]
- Pananjady, A.; Bagaria, V.K.; Vaze, R. Optimally Approximating the Coverage Lifetime of Wireless Sensor Networks. IEEE ACM Trans. Netw. 2017, 25, 98–111. [Google Scholar] [CrossRef]
- Ullah, F.; Al-Turjman, F. A conceptual framework for blockchain smart contract adoption to manage real estate deals in smart cities. Neural Comput. Appl. 2021, 1–22. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khan, S.I.; Qadir, Z.; Kouzani, A.Z.; Mahmud, M.A.P. Insight into the impact of COVID-19 on Australian transportation sector: An economic and community-based perspective. Sustainability 2021, 13, 1276. [Google Scholar] [CrossRef]
- Manju Chand, S.; Kumar, B. Target coverage heuristic based on learning automata in wireless sensor networks. IET Wirel. Sens. Syst. 2018, 8, 109–115. [Google Scholar] [CrossRef]
- Qadir, Z.; Munir, A.; Ashfaq, T.; Munawar, H.S.; Khan, M.A.; Le, K. A prototype of an energy-efficient MAGLEV train: A step towards cleaner train transport. Clean. Eng. Technol. 2021, 4, 100217. [Google Scholar] [CrossRef]
- Liaquat, M.U.; Munawar, H.S.; Rahman, A.; Qadir, Z.; Kouzani, A.Z.; Mahmud, M.A.P. Sound localization for ad-hoc microphone arrays. Energies 2021, 14, 3446. [Google Scholar] [CrossRef]
- Maqsoom, A.; Aslam, B.; Gul, M.E.; Ullah, F.; Kouzani, A.Z.; Mahmud, M.A.P.; Nawaz, A. Using Multivariate Regression and ANN Models to Predict Properties of Concrete Cured under Hot Weather. Sustainability 2021, 13, 10164. [Google Scholar] [CrossRef]
- Khan, S.I.; Qadir, Z.; Munawar, H.S.; Nayak, S.R.; Budati, A.K.; Verma, K.D.; Prakash, D. UAVs path planning architecture for effective medical emergency response in future networks. Phys. Commun. 2021, 47, 101337. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.E.; Jamaluddin Thaheem, M.; Cynthia Wang, C.; Imran, M. It’s all about perceptions: A DEMATEL approach to exploring user perceptions of real estate online platforms. Ain Shams Eng. J. 2021. [CrossRef]
- Thathachar, M.A.L.; Sastry, P.S. Varieties of learning automata: An overview. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2002, 32, 711–722. [Google Scholar] [CrossRef] [PubMed]
- Shaukat, M.A.; Shaukat, H.R.; Qadir, Z.; Munawar, H.S.; Kouzani, A.Z.; Mahmud, M.A.P. Cluster analysis and model comparison using smart meter data. Sensors 2021, 21, 3157. [Google Scholar] [CrossRef] [PubMed]
- Mostafaei, H.; Montieri, A.; Persico, V.; Pescapé, A. A sleep scheduling approach based on learning automata for WSN partialcoverage. J. Netw. Comput. Appl. 2017, 80, 67–78. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-based crack detection methods: A review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Mehmood, M.; Javaid, N.; Akram, J.; Abbasi, S.H.; Rahman, A.; Saeed, F. Efficient Resource Distribution in Cloud and Fog Computing. In Lecture Notes on Data Engineering and Communications Technologies; Springer: Berlin/Heidelberg, Germany, 2019; pp. 209–221. [Google Scholar] [CrossRef]
- Ullah, F.; Qayyum, S.; Thaheem, M.J.; Al-Turjman, F.; Sepasgozar, S.M.E. Risk management in sustainable smart cities governance: A TOE framework. Technol. Forecast. Soc. Change 2021, 167, 120743. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Khan, S.I.; Qadir, Z.; Qayyum, S. Uav assisted spatiotemporal analysis and management of bushfires: A case study of the 2020 victorian bushfires. Fire 2021, 4, 40. [Google Scholar] [CrossRef]
- Callebaut, G.; Leenders, G.; Van Mulders, J.; Ottoy, G.; De Strycker, L.; Van der Perre, L. The Art of Designing Remote IoT Devices—Technologies and Strategies for a Long Battery Life. Sensors 2021, 21, 913. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozer, S.; Tahmasebinia, F.; Mohammad Ebrahimzadeh Sepasgozar, S.; Davis, S. Examining the impact of students’ attendance, sketching, visualization, and tutors experience on students’ performance: A case of building structures course in construction management. Constr. Econ. Build. 2020, 20, 78–102. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khalid, U.; Maqsood, A. Modern Day Detection of Mines; Using the Vehicle Based Detection Robot; Iacst: Singapore, 2017. [Google Scholar]
- Ullah, F.; Sepasgozar, S.M.E.; Thaheem, M.J.; Al-Turjman, F. Barriers to the digitalisation and innovation of Australian Smart Real Estate: A managerial perspective on the technology non-adoption. Environ. Technol. Innov. 2021, 22, 101527. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khan, S.I.; Qadir, Z.; Kiani, Y.S.; Kouzani, A.Z.; Parvez Mahmud, M.A. Insights into the mobility pattern of australians during COVID-19. Sustainability 2021, 13, 9611. [Google Scholar] [CrossRef]
- Han, G.; Liu, L.; Jiang, J.; Shu, L.; Hancke, G. Analysis of Energy-Efficient Connected Target Coverage Algorithms for Industrial Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2017, 13, 135–143. [Google Scholar] [CrossRef]
- Agiwal, M.; Roy, A.; Saxena, N. Next Generation 5G Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- Qadir, Z.; Khan, S.I.; Khalaji, E.; Munawar, H.S.; Al-Turjman, F.; Mahmud, M.A.P.; Kouzani, A.Z.; Le, K. Predicting the energy output of hybrid PV—Wind renewable energy system using feature selection technique for smart grids. Energy Rep. 2021. [CrossRef]
- Low, S.; Ullah, F.; Shirowzhan, S.; Sepasgozar, S.M.E.; Lin Lee, C. Smart Digital Marketing Capabilities for Sustainable Property Development: A Case of Malaysia. Sustainability 2020, 12, 5402. [Google Scholar] [CrossRef]
- Mostafaei, H.; Meybodi, M.R. Maximizing Lifetime of Target Coverage in Wireless Sensor Networks Using Learning Automata, Wireless Personal Communications. 2013; 71, 1461–1477. [Google Scholar] [CrossRef]
- Munawar, H.S.; Aggarwal, R.; Qadir, Z.; Khan, S.I.; Kouzani, A.Z.; Mahmud, M.A.P. A gabor filter-based protocol for automated image-based building detection. Buildings 2021, 11, 302. [Google Scholar] [CrossRef]
- Rostami, A.S.; Mohanna, F.; Keshavarz, H.; Badkoobe, M. Target coverage in wireless sensor networks. Recent Adv. Ad Hoc Netw. Res. IEEE 2014, 52, 113–151. [Google Scholar]
- Akram, J.; Malik, S.; Ansari, S.; Rizvi, H.; Kim, D.; Hasnain, R. Intelligent Target Coverage in Wireless Sensor Networks with Adaptive Sensors. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Munawar, H.S.; Awan, A.A.; Maqsood, A.; Khalid, U. Reinventing Radiology in Modern Era. IJ Wirel. Microw. Technol. 2020, 4, 34–38. [Google Scholar]
- Ullah, F.; Al-Turjman, F.; Qayyum, S.; Inam, H.; Imran, M. Advertising through UAVs: Optimized path system for delivering smart real-estate advertisement materials. Int. J. Intell. Syst. 2021, 36, 3429–3463. [Google Scholar] [CrossRef]
- Aslam, B.; Maqsoom, A.; Khalid, N.; Ullah, F.; Sepasgozar, S. Urban Overheating Assessment through Prediction of Surface Temperatures: A Case Study of Karachi, Pakistan. ISPRS Int. J. Geo-Inf. 2021, 10, 539. [Google Scholar] [CrossRef]
- Rashid, B.; Rehmani, M.H. Applications of wireless sensor networks for urban areas: A survey. J. Netw. Comput. Appl. 2016, 60, 192–219. [Google Scholar] [CrossRef]
- Ullah, F.; Thaheem, M.J.; Sepasgozar, S.M.E.; Forcada, N. System Dynamics Model to Determine Concession Period of PPP Infrastructure Projects: Overarching Effects of Critical Success Factors. J. Leg. Aff. Disput. Resolut. Eng. Constr. 2018, 10, 04518022. [Google Scholar] [CrossRef]
- Munawar, H.S.; Maqsood, A. Isotropic surround suppression based linear target detection using hough transform. Int. Adv. Appl. Sci. 2017.
- Qayyum, S.; Ullah, F.; Al-Turjman, F.; Mojtahedi, M. Managing smart cities through six sigma DMADICV method: A review-based conceptual framework. Sustain. Cities Soc. 2021, 72, 103022. [Google Scholar] [CrossRef]
- Lu, Z.; Li, W.W.; Pan, M. Maximum Lifetime Scheduling for Target Coverage and Data Collection in Wireless Sensor Networks. IEEE Trans. Veh. Technol. 2015, 64, 714–727. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.; Hussain Ali, T. Real Estate Stakeholders Technology Acceptance Model (RESTAM): User-focused Big9 Disruptive Technologies for Smart Real Estate Management Smart City Management: Applications of Disruptive Technologies View project Six Sigma implementation in construction. In Proceedings of the 2nd International Conference on Sustainable Development in Civil Engineering (ICSDC 2019), Jamshoro, Pakistan, 5–7 December 2019; pp. 5–7. [Google Scholar]
- Munawar, H.S.; Khan, S.I.; Anum, N.; Qadir, Z.; Kouzani, A.Z.; Parvez Mahmud, M.A. Post-flood risk management and resilience building practices: A case study. Appl. Sci. 2021, 11, 4823. [Google Scholar] [CrossRef]
- Manju, C.S.; Kumar, B. Maximising network lifetime for target coverage problem in wireless sensor networks. IET Wirel. Sens. Syst. 2016, 6, 192–197. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.E.; Shirowzhan, S.; Davis, S. Modelling users’ perception of the online real estate platforms in a digitally disruptive environment: An integrated KANO-SISQual approach. Telemat. Inform. 2021, 63, 101660. [Google Scholar] [CrossRef]
- Qadir, Z.; Ullah, F.; Munawar, H.S.; Al-Turjman, F. Addressing disasters in smart cities through UAVs path planning and 5G communications: A systematic review. Comput. Commun. 2021, 168, 114–135. [Google Scholar] [CrossRef]
- Munawar, H.S.; Zhang, J.; Li, H.; Mo, D.; Chang, L. Mining Multispectral Aerial Images for Automatic Detection of Strategic Bridge Locations for Disaster Relief Missions. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; pp. 189–200. [Google Scholar] [CrossRef]
- Ayub, B.; Ullah, F.; Rasheed, F.; Sepasgozar, S.M. Risks In EPC Hydropower Projects: A Case Of Pakistan. In Proceedings of the 8th International Civil Engineering Congress (ICEC-2016) “Ensuring Technological Advancement through Innovation Based Knowledge Corridor”, Karachi, Pakistan, 23–24 December 2016; pp. 23–24. [Google Scholar]
- Munawar, H.S.; Hammad, A.; Ullah, F.; Ali, T.H. After the flood: A novel application of image processing and machine learning for post-flood disaster management. In Proceedings of the 2nd International Conference on Sustainable Development in Civil Engineering (ICSDC 2019), Jamshoro, Pakistan, 5–7 December 2019; pp. 5–7. [Google Scholar]
- Atif, S.; Umar, M.; Ullah, F. Investigating the flood damages in Lower Indus Basin since 2000: Spatiotemporal analyses of the major flood events. Nat. Hazards 2021, 108, 2357–2383. [Google Scholar] [CrossRef]
- Munawar, H.S. Isotropic surround suppression and Hough transform based target recognition from aerial images. Int. J. Adv. Appl. Sci. 2017, 4, 37–42. [Google Scholar] [CrossRef]
- Van Etten, A. Satellite Imagery Multiscale Rapid Detection with Windowed Networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 735–743. [Google Scholar] [CrossRef]
- Ullah, F.; Thaheem, M.J. Concession period of public private partnership projects: Industry-academia gap analysis. Int. J. Constr. Manag. 2018, 18, 418–429. [Google Scholar] [CrossRef]
- Munawar, H.S.; Qayyum, S.; Ullah, F.; Sepasgozar, S. Big data and its applications in smart real estate and the disaster management life cycle: A systematic analysis. Big Data Cogn. Comput. 2020, 4, 1–53. [Google Scholar] [CrossRef]
- Manju, B.P.; Kumar, S. Target K-coverage problem in wireless sensor networks. J. Discret. Math. Sci. Cryptogr. 2020, 23, 651–659. [Google Scholar] [CrossRef]
- Munawar, H.S.; Mojtahedi, M.; Hammad, A.W.; Ostwald, M.J.; Waller, S.T. An ai/ml-based strategy for disaster response and evacuation of victims in aged care facilities in the Hawkesbury-Nepean Valley: A perspective. Buildings 2022, 12, 80. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Rafi, A.; Adeel-ur-Rehman, A.G.; Akram, J. Efficient Energy Utilization in Fog Computing based Wireless Sensor Networks. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (ICoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.E. Key Factors Influencing Purchase or Rent Decisions in Smart Real Estate Investments: A System Dynamics Approach Using Online Forum Thread Data. Sustainability 2020, 12, 4382. [Google Scholar] [CrossRef]
- Ali, Q.; Thaheem, M.J.; Ullah, F.; Sepasgozar, S.M.E. The Performance Gap in Energy-Efficient Office Buildings: How the Occupants Can Help? Energies 2020, 13, 1480. [Google Scholar] [CrossRef]
- Ullah, F. A Beginner’s Guide to Developing Review-Based Conceptual Frameworks in the Built Environment. Architecture 2021, 1, 5–24. [Google Scholar] [CrossRef]
- Njoya, A.N.; Thron, C.; Barry, J.; Abdou, W.; Tonye, E.; Siri Lawrencia Konje, N.; Dipanda, A. Efficient scalable sensor node placement algorithm for fixed target coverage applications of wireless sensor networks. IET Wirel. Sens. Syst. 2017, 7, 44–54. [Google Scholar] [CrossRef]
- Azeem, M.; Ullah, F.; Thaheem, M.J.; Qayyum, S. Competitiveness in the construction industry: A contractor’s perspective on barriers to improving the construction industry performance. J. Constr. Eng. Manag. Innov. 2020, 3, 193–219. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Filters | Stride | Output |
|---|---|---|---|
| Conv | 32 | 3 × 3 | 416 × 416 × 32 |
| Maxpooling | 2 × 2 | 208 × 208 × 32 | |
| Conv | 64 | 3 × 3 | 208 × 208 ×64 |
| Maxpooling | 2 × 2 | 104 × 104 × 64 | |
| Conv | 128 | 3 × 3 | 104 × 104 × 128 |
| Conv | 64 | 1 × 1 | 104 × 104 × 64 |
| Conv | 128 | 3 × 3 | 104 × 104 × 128 |
| Maxpooling | 2 × 2 | 52 × 52 × 64 | |
| Conv | 256 | 3 × 3 | 52 × 52 × 256 |
| Conv | 128 | 1 × 1 | 52× 52 × 128 |
| Conv | 256 | 3 × 3 | 52 × 52 ×256 |
| Maxpooling | 2 × 2 | 26 × 26 × 256 | |
| Conv | 512 | 3 × 3 | 26 × 26 × 512 |
| Conv | 256 | 1 × 1 | 26 × 26 × 256 |
| Conv | 512 | 3 × 3 | 26 × 26 × 512 |
| Conv | 1024 | 3 × 3 | 26 × 26 × 512 |
| Conv | 1024 | 3 × 3 | 26 × 26 × 1024 |
| Passthrough | 10 → 20 | 26 × 26 × 1024 | |
| Conv | 1024 | 3 × 3 | 26 × 26 × 1024 |
| Conv | Nf | 1 × 1 | 26 × 26 |
| Classification | Category | Detection | |
|---|---|---|---|
| Aircraft | Not Aircraft | ||
| Actual | Aircraft Not Aircraft | 561 0 | 24 N/A |
| Classification | Category | Detection | |
|---|---|---|---|
| Aircraft | Not Aircraft | ||
| Actual | Aircraft Not Aircraft | 555 0 | 30 N/A |
| Classification | Category | Detection | |
|---|---|---|---|
| Aircraft | Not Aircraft | ||
| Actual | Aircraft Not Aircraft | 500 0 | 85 N/A |
| Classification | Category | Detection | |
|---|---|---|---|
| Aircraft | Not Aircraft | ||
| Actual | Aircraft Not Aircraft | 1054 96 | 32 N/A |
| Sr. | Name | Accuracy | F1-Score |
|---|---|---|---|
| 1 | Faster RCNN | 95.8% | 97% |
| 2 | YOLO | 94.87% | 96% |
| 3 | SSD | 85.4% | 91% |
| 4 | SIMRDWN | 97% | 93% |
| Faster RCNN | YOLO | SSD | SIMRDWN | ||||
|---|---|---|---|---|---|---|---|
| Resolution | Time | Resolution | Time | Resolution | Time | Resolution | Time |
| 523 × 315 | 3.12 s | 523 × 315 | 179.28 ms | 523 × 315 | 3.12 s | 4800 × 2718 | 25.61 s |
| 416 × 416 | 2.97 s | 416 × 416 | 177.77 ms | 416 × 416 | 2.13 s | 1920 × 1080 | 5.17 s |
| 416 × 416 | 2.95 s | 416 × 416 | 178.36 ms | 416 × 416 | 2.90 s | 8316 × 6088 | 103.43 s |
| 519 × 323 | 3.12 s | 519 × 323 | 180.87 ms | 519 × 323 | 2.97 s | 4800 × 2718 | 25.64 s |
| 640 × 360 | 4.95 s | 640 × 360 | 191 ms | 640 × 360 | 2.96 s | 1920 × 1080 | 5.12 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tahir, A.; Munawar, H.S.; Akram, J.; Adil, M.; Ali, S.; Kouzani, A.Z.; Mahmud, M.A.P. Automatic Target Detection from Satellite Imagery Using Machine Learning. Sensors 2022, 22, 1147. https://doi.org/10.3390/s22031147
Tahir A, Munawar HS, Akram J, Adil M, Ali S, Kouzani AZ, Mahmud MAP. Automatic Target Detection from Satellite Imagery Using Machine Learning. Sensors. 2022; 22(3):1147. https://doi.org/10.3390/s22031147
Chicago/Turabian StyleTahir, Arsalan, Hafiz Suliman Munawar, Junaid Akram, Muhammad Adil, Shehryar Ali, Abbas Z. Kouzani, and M. A. Parvez Mahmud. 2022. "Automatic Target Detection from Satellite Imagery Using Machine Learning" Sensors 22, no. 3: 1147. https://doi.org/10.3390/s22031147
APA StyleTahir, A., Munawar, H. S., Akram, J., Adil, M., Ali, S., Kouzani, A. Z., & Mahmud, M. A. P. (2022). Automatic Target Detection from Satellite Imagery Using Machine Learning. Sensors, 22(3), 1147. https://doi.org/10.3390/s22031147