
Predictive Maintenance in the Automotive Sector: A Literature Review





Abstract
:1. Introduction
- •
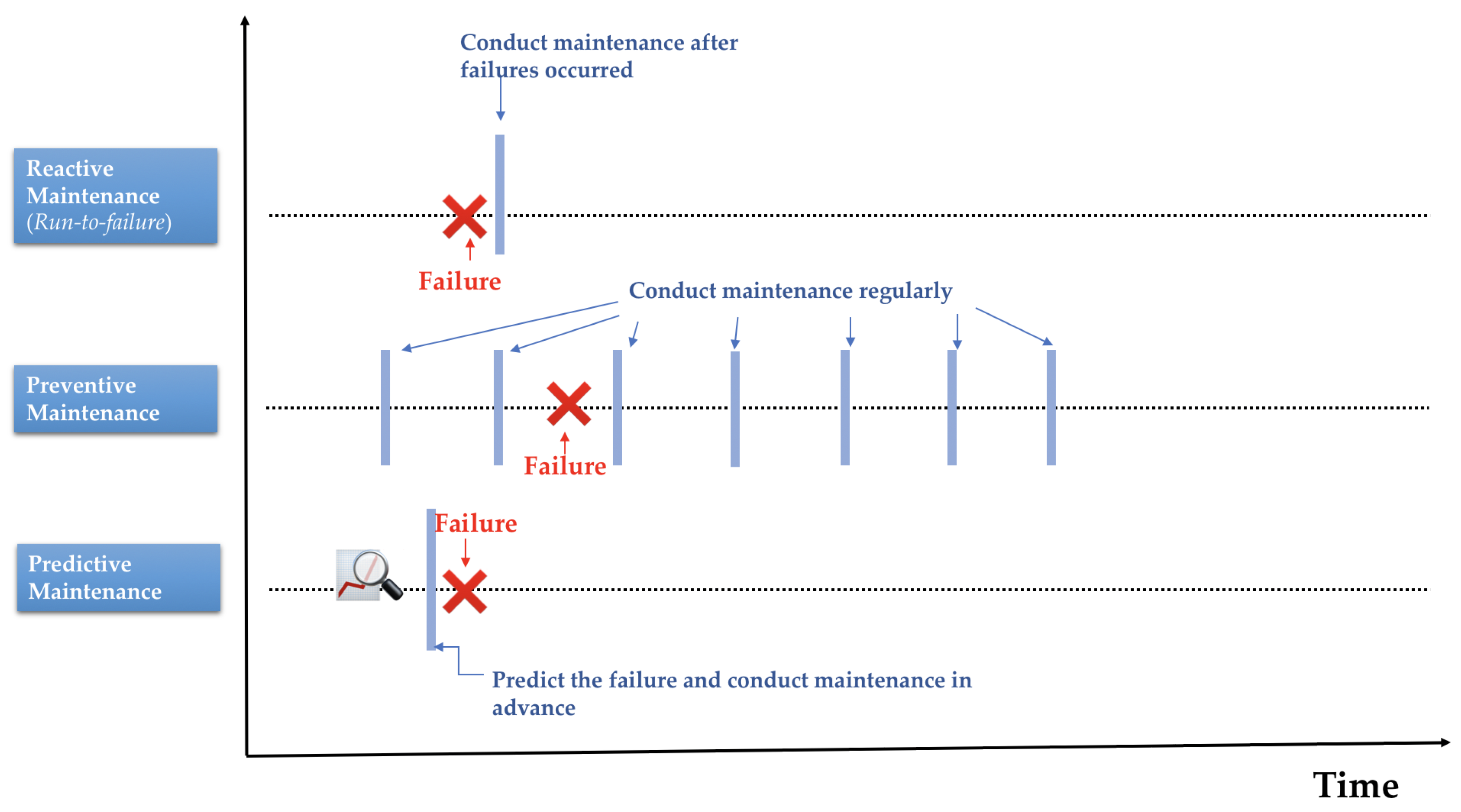
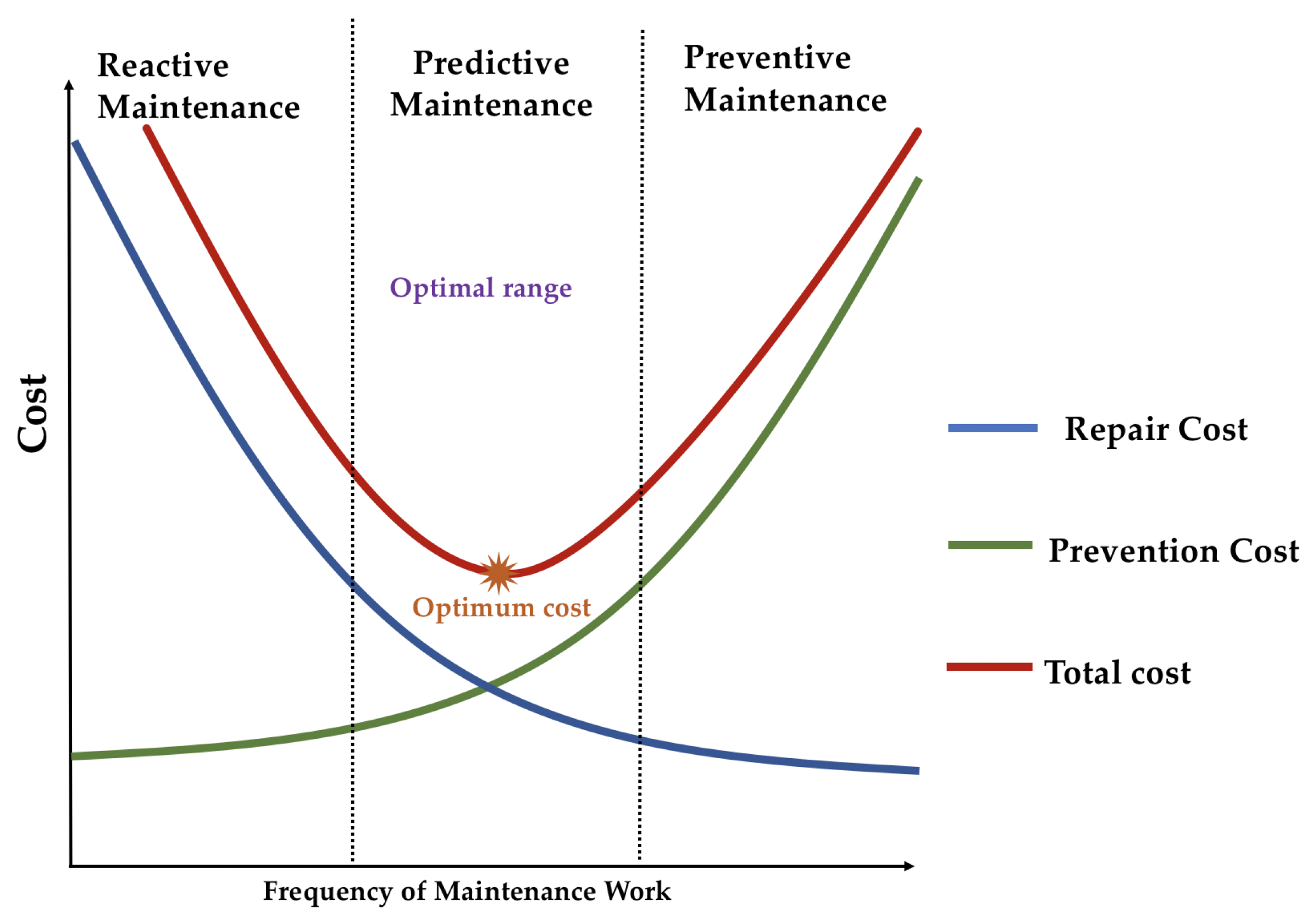
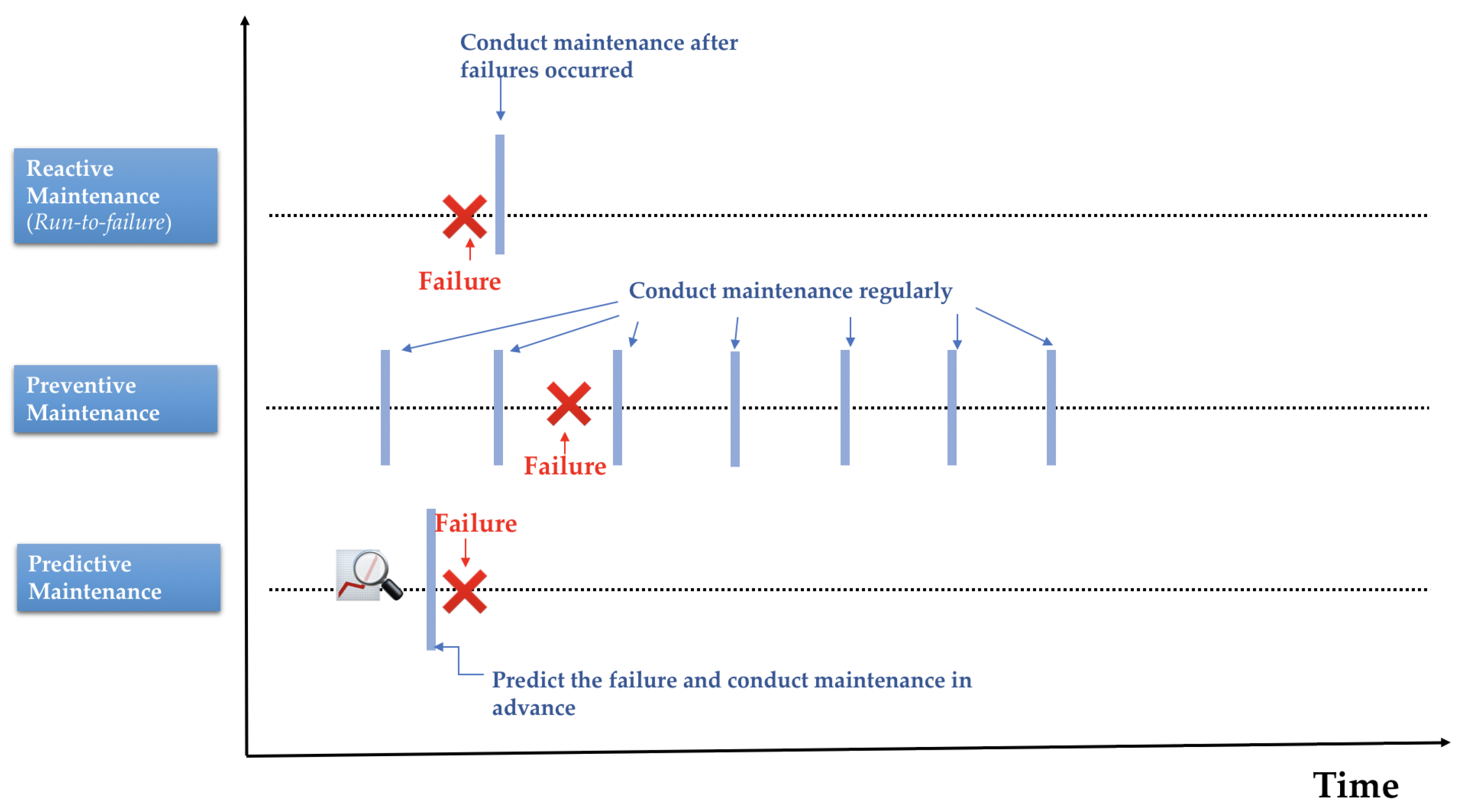
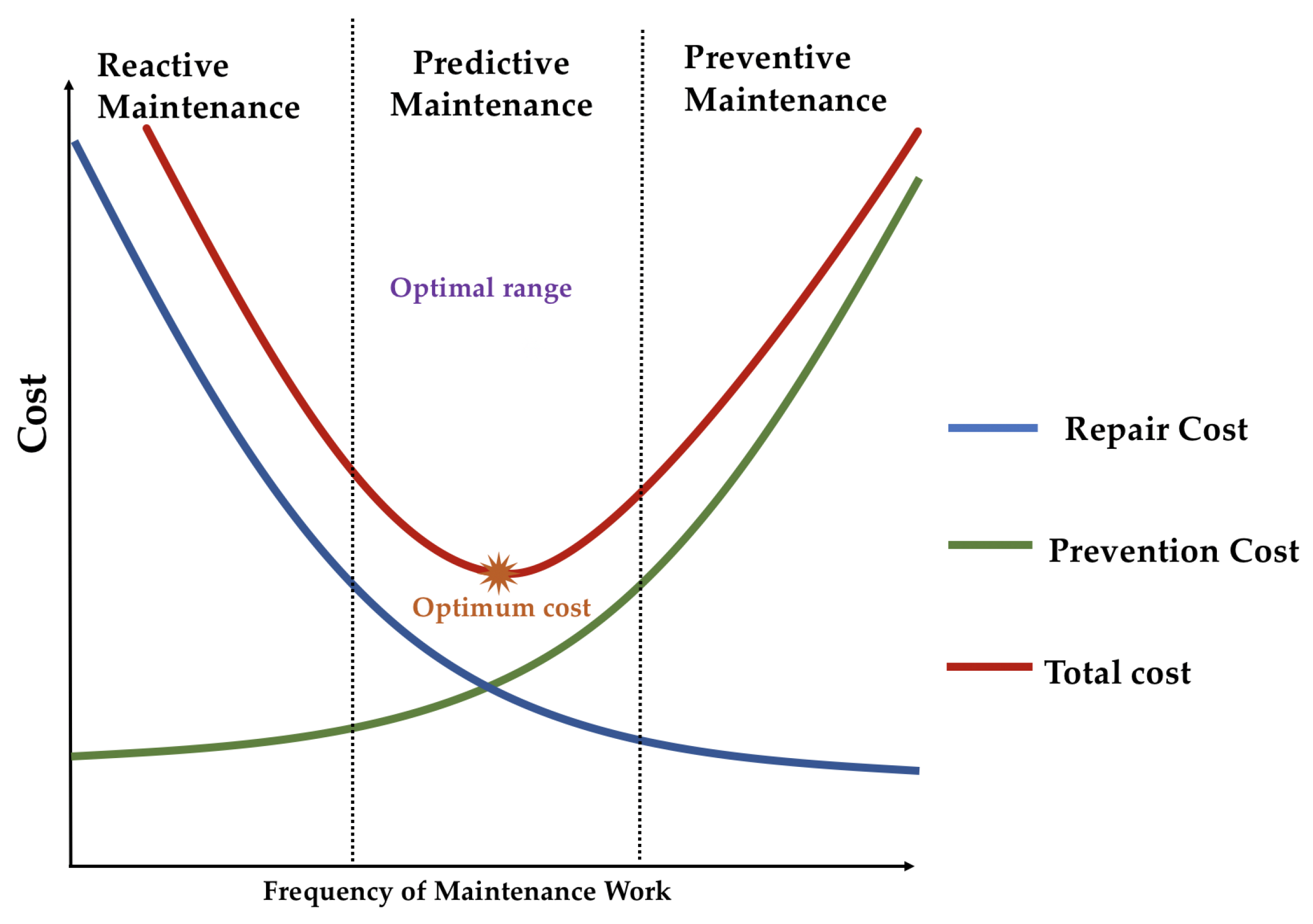
- Run-to-failure (RtF) or reactive maintenance, where maintenance interventions are performed only after the occurrence of failures. This approach is common when equipment failure does not significantly affect operations or productivity.
- •
- Planned preventive maintenance (PvM): Time-based maintenance or scheduled maintenance, which involves taking the necessary precautions and actions to reduce the likelihood of equipment failure, and prevent accidents or failures before they occur. It is performed regularly while the equipment is still running so that it does not fail unexpectedly. Therefore, in terms of complexity, this maintenance strategy lies between run-to-failure and predictive maintenance.
- •
- Predictive maintenance (PdM), which employs condition-monitoring technology to measure equipment performance through IoT systems that allow the connection of electronic devices to mechanical and digital machines and the collecting of a significant amount of data. Data are collected over time to monitor the state of equipment and construct models that can help prevent failures.
1.1. The Maintenance Costs
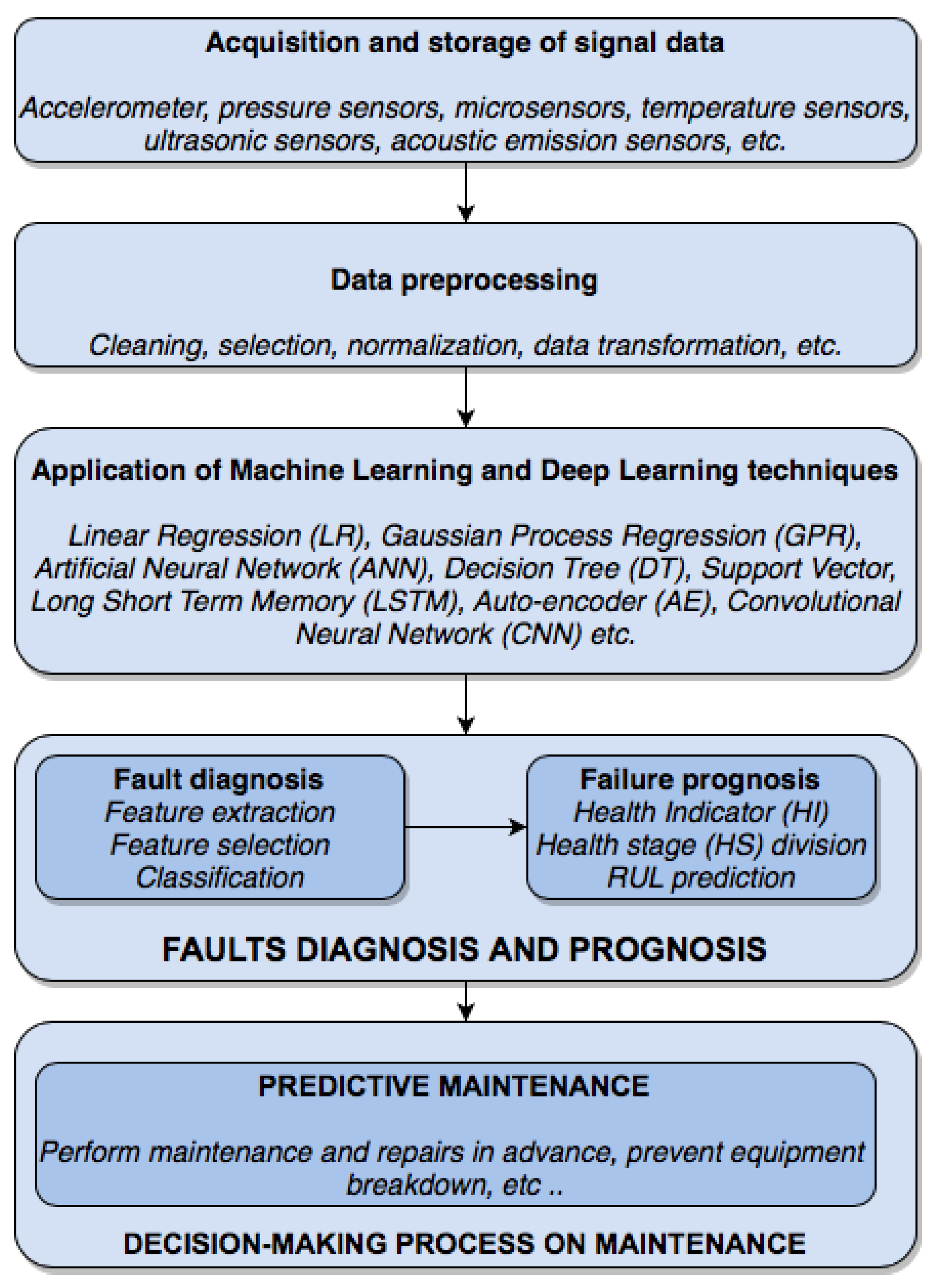
1.2. Predictive Maintenance
- (1)
- Collecting data from different sensors of the system.
- (2)
- Data preprocessing [19].
- (3)
- Faults diagnosis and prognosis.
- (4)
- Decision-making on the maintenance strategy.
- (1)
- Feature extraction and selection: in this phase, the discriminating features of the raw data are extracted and selected.
- (2)
- Classification of faults: the main task of this phase is to classify the different faults and identify the causes of the failure using the selected discriminating characteristics.
- (1)
- Construction of the health indicator (HI): the HIs are indexes constructed to represent the health of the equipment.
- (2)
- Health stage (HS) division: the life of the equipment is divided into different HS based on the defined HI index.
- (3)
- Prediction of the machinery RUL: the RUL can be estimated through the evaluation of the health status of the equipment.
- •
- Physical model approach, which uses a physics or mathematical model of the system for assessing degradation of components. The accuracy of this approach relies on the model, and it also uses statistical methods to validate it [23].
- •
- Knowledge-based approach, which relies on some knowledge or expertise on the system to reduce its complexity. Expert systems and fuzzy logic belong to this category [24].
- •
- •
- Digital twin approach, which combines data and models and creates a link between the physical world and the digital ones [27].
2. Physics-Based Models
3. Knowledge-Based Models
4. Data-Driven Methods
- •
- Statistical approaches.
- •
- Stochastic approaches.
- •
- Machine learning techniques.
4.1. Statistical and Stochastic Approaches
4.2. Machine Learning Algorithms
4.2.1. Traditional Algorithms
Linear Regression
Gaussian Process Regression
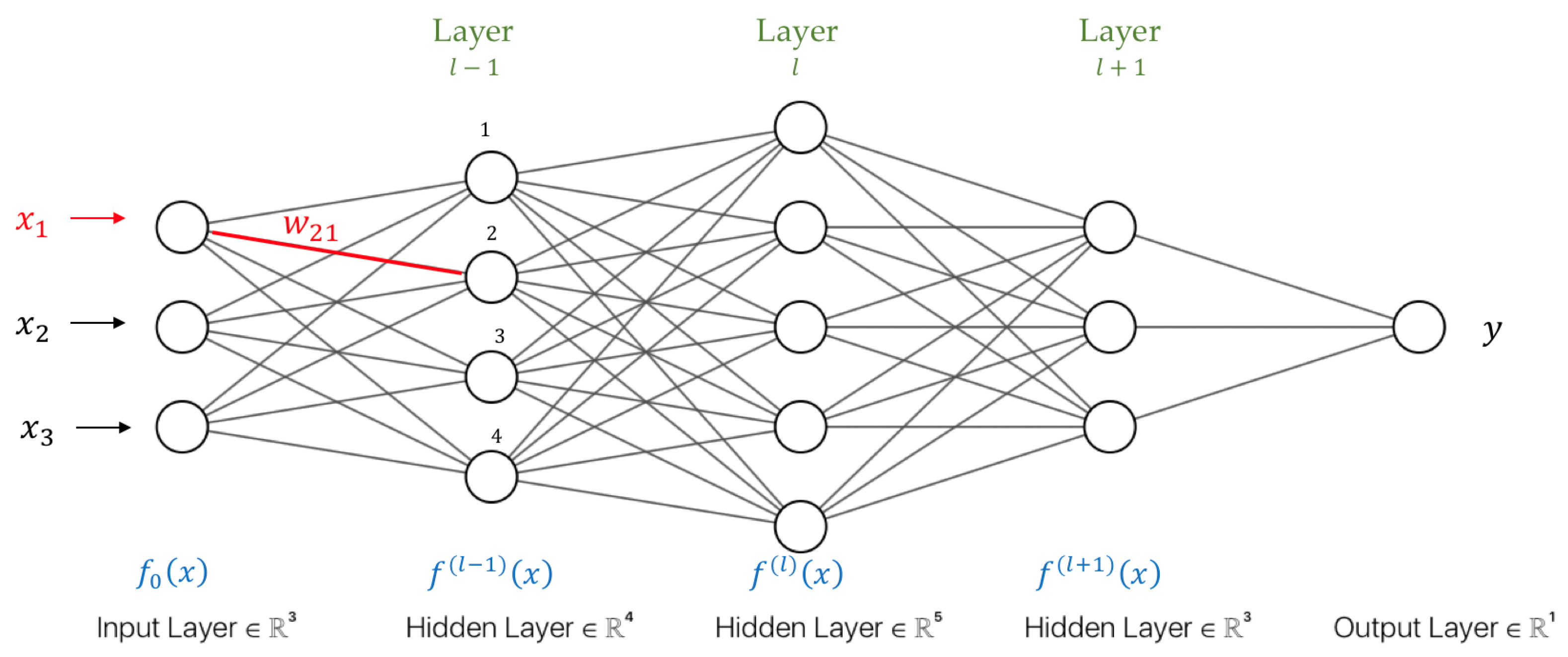
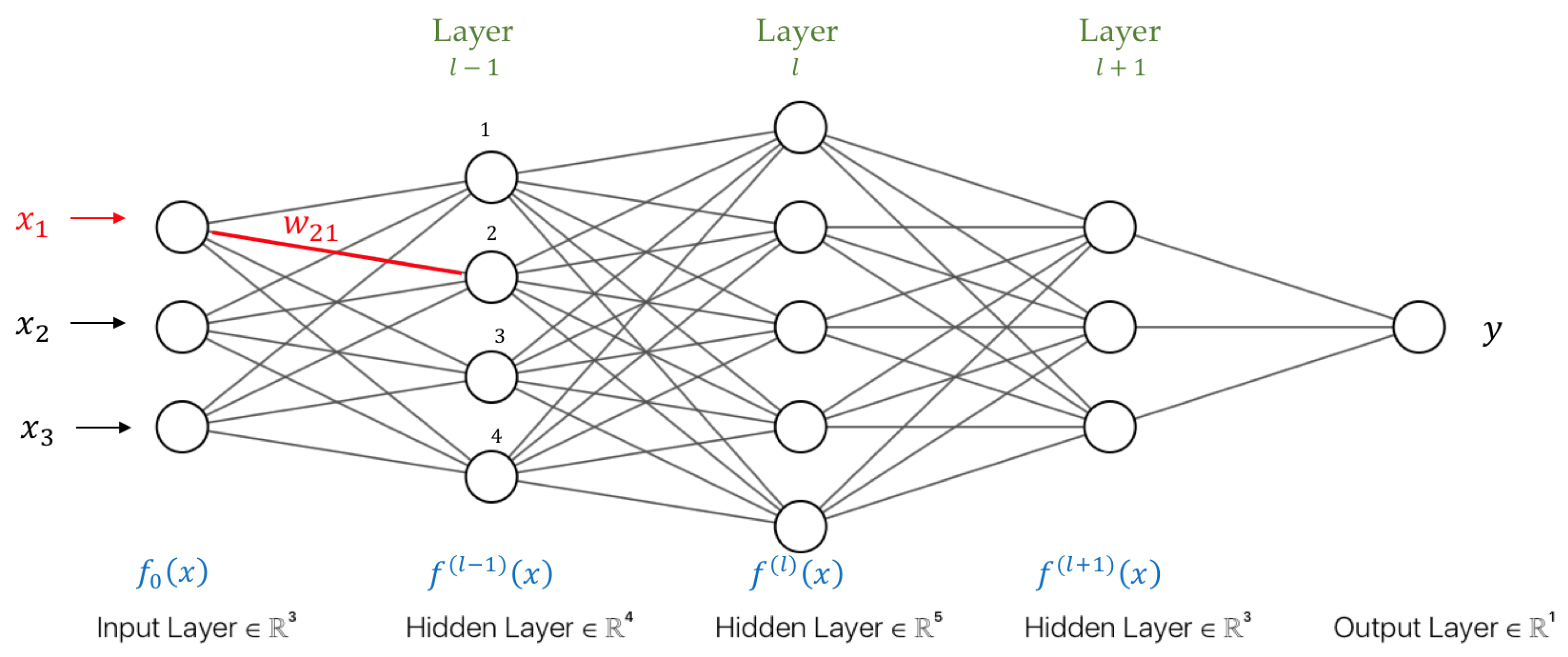
Artificial Neural Network
- 1.
- The sigmoid function .
- 2.
- The hyperbolic tangent function .
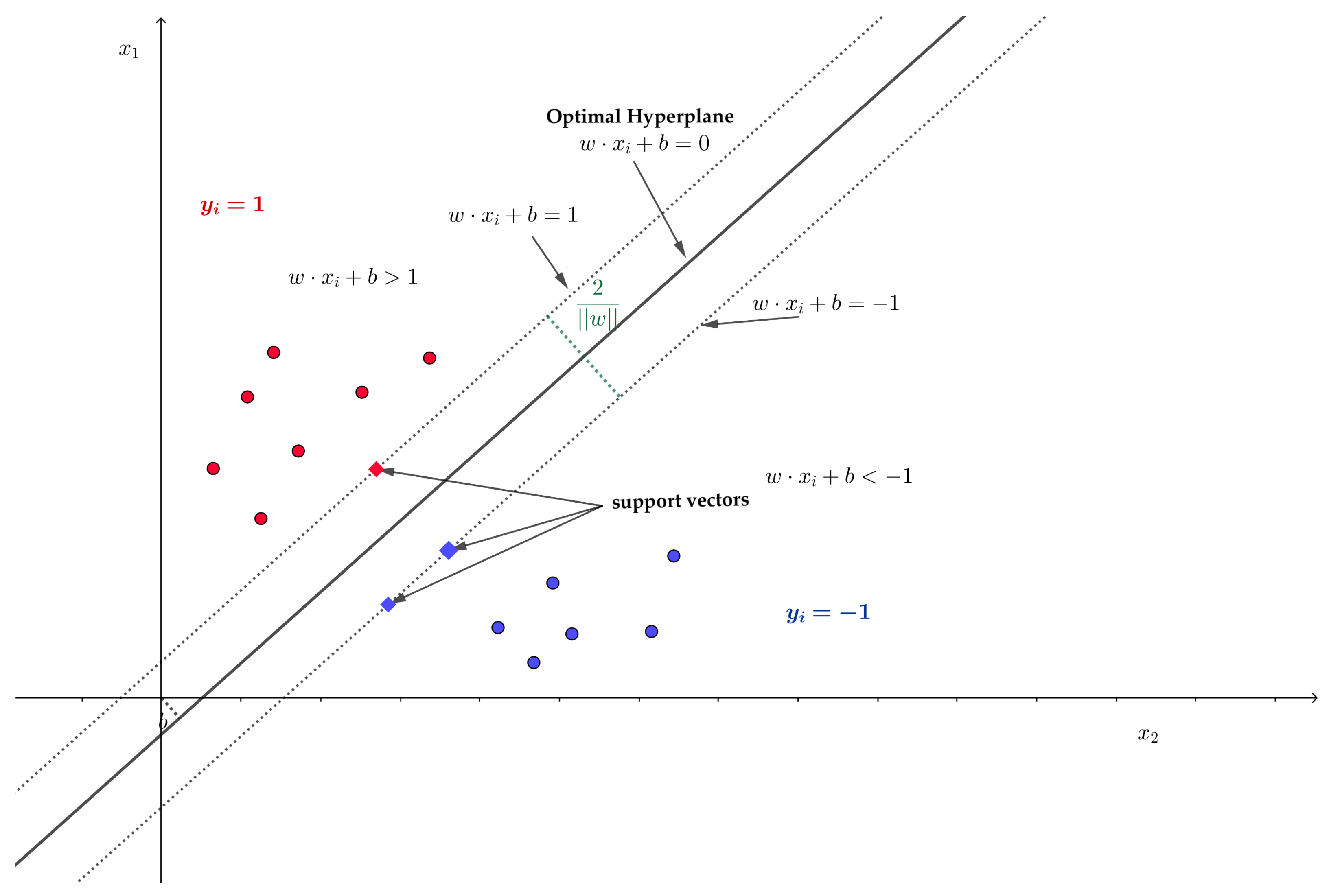
Support Vector Machine
k-Nearest Neighbors
Decision Tree
4.2.2. Deep Learning Approaches
5. Digital Twin Technology
6. Comparison among Different Approaches
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| ANNs | Artificial neural networks |
| CNN | Convolutional neural network |
| DL | Deep learning |
| DT | Decision tree |
| EBa | Ensemble bagging |
| EBo | Ensemble boosting |
| GPR | Gaussian process regression |
| k-NN | k-nearest neighbors |
| LR | Linear regression |
| LSTM | Long short-term memory |
| ML | Machine learning |
| MLR | Multiple linear regression |
| PdM | Predictive maintenance |
| PvM | Preventive maintenance |
| RNN | Recurrent neural network |
| RtF | Run-to-failure |
| SVM | Support vector machine |
References
- Redondo, R.; Herrero, Á.; Corchado, E.; Sedano, J. A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry. Appl. Sci. 2020, 10, 4355. [Google Scholar] [CrossRef]
- Rüßmann, M.; Lorenz, M.; Gerbert, P.; Waldner, M.; Justus, J.; Engel, P.; Harnisch, M. Industry 4.0: The Future of Productivity and Growth in Manufacturing Industries; Boston Consulting Group: Boston, MA, USA, 2015; Volume 9, pp. 54–89. [Google Scholar]
- Samatas, G.G.; Moumgiakmas, S.S.; Papakostas, G.A. Predictive Maintenance-Bridging Artificial Intelligence and IoT. In Proceedings of the 2021 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 10–13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 413–419. [Google Scholar]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Fernandes, J.; Reis, J.; Melão, N.; Teixeira, L.; Amorim, M. The Role of Industry 4.0 and BPMN in the Arise of Condition-Based and Predictive Maintenance: A Case Study in the Automotive Industry. Appl. Sci. 2021, 11, 3438. [Google Scholar] [CrossRef]
- Garay, J.M.; Diedrich, C. Analysis of the applicability of fault detection and failure prediction based on unsupervised learning and monte carlo simulations for real devices in the industrial automobile production. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 22–25 July 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 1, pp. 1279–1284. [Google Scholar]
- Theissler, A.; Pérez-Velázquez, J.; Kettelgerdes, M.; Elger, G. Predictive maintenance enabled by machine learning: Use cases and challenges in the automotive industry. Reliab. Eng. Syst. Saf. 2021, 215, 107864. [Google Scholar] [CrossRef]
- Sankavaram, C.; Kodali, A.; Pattipati, K. An integrated health management process for automotive cyber-physical systems. In Proceedings of the 2013 International Conference on Computing, Networking and Communications (ICNC), San Diego, CA, USA, 28–31 January 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 82–86. [Google Scholar]
- Shafi, U.; Safi, A.; Shahid, A.R.; Ziauddin, S.; Saleem, M.Q. Vehicle remote health monitoring and prognostic maintenance system. J. Adv. Transp. 2018, 2018, 8061514. [Google Scholar] [CrossRef] [Green Version]
- Killeen, P.; Ding, B.; Kiringa, I.; Yeap, T. IoT-based predictive maintenance for fleet management. Procedia Comput. Sci. 2019, 151, 607–613. [Google Scholar] [CrossRef]
- Singh, S.K.; Singh, A.K.; Sharma, A. OBD-II based Intelligent Vehicular Diagnostic System using IoT. In Proceedings of the International Semantic Intelligence Conference, Delhi, India, 25–27 February 2021. [Google Scholar]
- Tsai, M.F.; Chu, Y.C.; Li, M.H.; Chen, L.W. Smart Machinery Monitoring System with Reduced Information Transmission and Fault Prediction Methods Using Industrial Internet of Things. Mathematics 2021, 9, 3. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Grall, A.; Dieulle, L.; Bérenguer, C.; Roussignol, M. Continuous-time predictive-maintenance scheduling for a deteriorating system. IEEE Trans. Reliab. 2002, 51, 141–150. [Google Scholar] [CrossRef] [Green Version]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A survey of predictive maintenance: Systems, purposes and approaches. arXiv 2019, arXiv:1912.07383. [Google Scholar]
- Mobley, R.K. An Introduction to Predictive Maintenance; Elsevier: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Sullivan, G.; Pugh, R.; Melendez, A.P.; Hunt, W.D. Operations & Maintenance Best Practices—A Guide to Achieving Operational Efficiency (Release 3) (No. PNNL-19634); Pacific Northwest National Lab (PNNL): Richland, WA, USA, 2010. [Google Scholar]
- Xu, G.; Liu, M.; Wang, J.; Ma, Y.; Wang, J.; Li, F.; Shen, W. Data-driven fault diagnostics and prognostics for predictive maintenance: A brief overview. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 103–108. [Google Scholar]
- Bekar, E.T.; Nyqvist, P.; Skoogh, A. An intelligent approach for data pre-processing and analysis in predictive maintenance with an industrial case study. Adv. Mech. Eng. 2020, 12, 1687814020919207. [Google Scholar] [CrossRef]
- Contreras-Valdes, A.; Amezquita-Sanchez, J.P.; Granados-Lieberman, D.; Valtierra-Rodriguez, M. Predictive data mining techniques for fault diagnosis of electric equipment: A review. Appl. Sci. 2020, 10, 950. [Google Scholar] [CrossRef] [Green Version]
- Nacchia, M.; Fruggiero, F.; Lambiase, A.; Bruton, K. A Systematic Mapping of the Advancing Use of Machine Learning Techniques for Predictive Maintenance in the Manufacturing Sector. Appl. Sci. 2021, 11, 2546. [Google Scholar] [CrossRef]
- Sajid, S.; Haleem, A.; Bahl, S.; Javaid, M.; Goyal, T.; Mittal, M. Data science applications for predictive maintenance and materials science in context to Industry 4.0. Mater. Today Proc. 2021, 45, 4898–4905. [Google Scholar] [CrossRef]
- Longo, N.; Serpi, V.; Jacazio, G.; Sorli, M. Model-based predictive maintenance techniques applied to automotive industry. In Proceedings of the PHM Society European Conference, Utrecht, The Netherlands, 3–6 July 2018; Volume 4. [Google Scholar]
- Zhou, Y.; Zhu, L.; Yi, J.; Luan, T.H.; Li, C. On Vehicle Fault Diagnosis: A Low Complexity Onboard Method. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Ashok Raj, J.; Singampalli, R.S.; Manikumar, R. Application of EMD based statistical parameters for the prediction of fault severity in a spur gear through vibration signals. Adv. Mater. Process. Technol. 2021. [Google Scholar] [CrossRef]
- Shen, D.; Wu, L.; Kang, G.; Guan, Y.; Peng, Z. A novel online method for predicting the remaining useful life of lithium-ion batteries considering random variable discharge current. Energy 2021, 218, 119490. [Google Scholar] [CrossRef]
- Bhatti, G.; Mohan, H.; Singh, R.R. Towards the future of ssmart electric vehicles: Digital twin technology. Renew. Sustain. Energy Rev. 2021, 141, 110801. [Google Scholar] [CrossRef]
- Saibannavar, D.; Math, M.M.; Kulkarni, U. A Survey on On-Board Diagnostic in Vehicles. In Proceedings of the International Conference on Mobile Computing and Sustainable Informatics, Lalitpur, Nepal, 23 January 2020; Springer: Cham, Switzerland, 2020; pp. 49–60. [Google Scholar]
- Tang, S.; Yuan, S.; Zhu, Y. Data preprocessing techniques in convolutional neural network based on fault diagnosis towards rotating machinery. IEEE Access 2020, 8, 149487–149496. [Google Scholar] [CrossRef]
- Metwally, M.; Moustafa, H.M.; Hassaan, G. Diagnosis of rotating machines faults using artificial intelligence based on preprocessing for input data. In Proceedings of the Conference of Open Innovations Association (FRUCT), Yaroslavl, Russia, 20–24 April 2020; pp. 572–582. [Google Scholar]
- Tinga, T.; Loendersloot, R. Physical model-based prognostics and health monitoring to enable predictive maintenance. In Predictive Maintenance in Dynamic Systems; Springer: Cham, Switzerland, 2019; pp. 313–353. [Google Scholar]
- Zhao, Y.; Liu, P.; Wang, Z.; Hong, J. Electric vehicle battery fault diagnosis based on statistical method. Energy Procedia 2017, 105, 2366–2371. [Google Scholar] [CrossRef]
- Ma, M.; Wang, Y.; Duan, Q.; Wu, T.; Sun, J.; Wang, Q. Fault detection of the connection of lithium-ion power batteries in series for electric vehicles based on statistical analysis. Energy 2018, 164, 745–756. [Google Scholar] [CrossRef]
- Ahmed, U.; Ha, D.; Shin, S.; Shaukat, N.; Zahid, U.; Han, C. Estimation of disturbance propagation path using principal component analysis (PCA) and multivariate granger causality (MVGC) techniques. Ind. Eng. Chem. Res. 2017, 56, 7260–7272. [Google Scholar] [CrossRef]
- Yuan, T.; Qin, S.J. Root cause diagnosis of plant-wide oscillations using Granger causality. J. Process. Control 2014, 24, 450–459. [Google Scholar] [CrossRef]
- Zuqui, G.C., Jr.; Munaro, C.J. Fault detection and isolation via Granger causality. In Proceedings of the Anais do XII Simpósio Brasileiro de Automação Inteligente (XII SBAI), Natal, Brazil, 25–28 October 2015. [Google Scholar]
- Rodriguez-Rivero, J.; Ramirez, J.; Martínez-Murcia, F.J.; Segovia, F.; Ortiz, A.; Salas, D.; Castillo-Barnes, D.; Illan, I.A.; Puntonet, C.G.; Jimenez-Mesa, C.; et al. Granger causality-based information fusion applied to electrical measurements from power transformers. Inf. Fusion 2020, 57, 59–70. [Google Scholar] [CrossRef]
- Bhat, P.; Thoduka, S.; Plöger, P. A Dependency Detection Method for Sensor-based Fault Detection. In Proceedings of the DX Workshop, Klagenfurt, Austria, 11–13 November 2019. [Google Scholar]
- Qiu, H.; Liu, Y.; Subrahmanya, N.A.; Li, W. Granger Causality for Time-Series Anomaly Detection. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 1074–1079. [Google Scholar]
- Kordes, A.; Wurm, S.; Hozhabrpour, H.; Wismüller, R. Automatic Fault Detection using Cause and Effect Rules for In-vehicle Networks. In Proceedings of the 4th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS), Funchal, Portugal, 16–18 March 2018; pp. 537–544. [Google Scholar]
- Luckow, A.; Kennedy, K.; Ziolkowski, M.; Djerekarov, E.; Cook, M.; Duffy, E.; Schleiss, M.; Vorster, B.; Weill, E.; Kulshrestha, A.; et al. Artificial intelligence and deep learning applications for automotive manufacturing. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3144–3152. [Google Scholar]
- Dehning, P.; Thiede, S.; Mennenga, M.; Herrmann, C. Factors influencing the energy intensity of automotive manufacturing plants. J. Clean. Prod. 2017, 142, 2305–2314. [Google Scholar] [CrossRef]
- Kong, Y.S.; Abdullah, S.; Schramm, D.; Omar, M.Z.; Haris, S.M. Development of multiple linear regression-based models for fatigue life evaluation of automotive coil springs. Mech. Syst. Signal Process. 2019, 118, 675–695. [Google Scholar] [CrossRef]
- Khoshkangini, R.; Sheikholharam Mashhadi, P.; Berck, P.; Gholami Shahbandi, S.; Pashami, S.; Nowaczyk, S.; Niklasson, T. Early prediction of quality issues in automotive modern industry. Information 2020, 11, 354. [Google Scholar] [CrossRef]
- Aye, S.A.; Heyns, P.S. An integrated Gaussian process regression for prediction of remaining useful life of slow speed bearings based on acoustic emission. Mech. Syst. Signal Process. 2017, 84, 485–498. [Google Scholar] [CrossRef]
- Tosun, E.; Aydin, K.; Bilgili, M. Comparison of linear regression and artificial neural network model of a diesel engine fueled with biodiesel-alcohol mixtures. Alex. Eng. J. 2016, 55, 3081–3089. [Google Scholar] [CrossRef] [Green Version]
- Chandran, V.; Patil, C.K.; Karthick, A.; Ganeshaperumal, D.; Rahim, R.; Ghosh, A. State of charge estimation of lithium-ion battery for electric vehicles using machine learning algorithms. World Electr. Veh. J. 2021, 12, 38. [Google Scholar] [CrossRef]
- Vasavi, S.; Aswarth, K.; Pavan, T.S.D.; Gokhale, A.A. Predictive analytics as a service for vehicle health monitoring using edge computing and AK-NN algorithm. Mater. Today Proc. 2021, 46, 8645–8654. [Google Scholar] [CrossRef]
- Tessaro, I.; Mariani, V.C.; Coelho, L.D.S. Machine Learning Models Applied to Predictive Maintenance in Automotive Engine Components. Proceedings 2020, 64, 26. [Google Scholar]
- Revanur, V.; Ayibiowu, A.; Rahat, M.; Khoshkangini, R. Embeddings Based Parallel Stacked Autoencoder Approach for Dimensionality Reduction and Predictive Maintenance of Vehicles. In Proceedings of the IoT Streams for Data-Driven Predictive Maintenance and IoT, Edge, and Mobile for Embedded Machine Learning, Ghent, Belgium, 14 September 2020; Springer: Cham, Switzerland, 2020; pp. 127–141. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Jeong, K.; Choi, S. Model-based sensor fault diagnosis of vehicle suspensions with a support vector machine. Int. J. Automot. Technol. 2019, 20, 961–970. [Google Scholar] [CrossRef]
- Biddle, L.; Fallah, S. A Novel Fault Detection, Identification and Prediction Approach for Autonomous Vehicle Controllers Using SVM. Automot. Innov. 2021, 4, 301–314. [Google Scholar] [CrossRef]
- Gong, C.S.A.; Su, C.H.S.; Tseng, K.H. Implementation of machine learning for fault classification on vehicle power transmission system. IEEE Sens. J. 2020, 20, 15163–15176. [Google Scholar] [CrossRef]
- Rubio, E.M.; Dionísio, R.P.; Torres, P.M.B. Predictive Maintenance of Induction motors in the context of Industry 4.0. Int. J. Mechatron. Appl. Mech. 2018, 4, 238–242. [Google Scholar]
- Landgrebe, S.R.; Safavian, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth, Inc.: Belmont, CA, USA, 1984. [Google Scholar]
- Chourasia, S. Survey paper on improved methods of ID3 decision tree classification. Int. J. Sci. Res. Publ. 2013, 3, 1–4. [Google Scholar]
- Quinlan, R.J. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers, Inc.: San Mateo, CA, USA, 1993. [Google Scholar]
- Singh, S.; Gupta, P. Comparative study ID3, cart and C4. 5 decision tree algorithm: A survey. Int. J. Adv. Inf. Sci. Technol. 2014, 27, 97–103. [Google Scholar]
- Sathyadevan, S.; Nair, R.R. Comparative Analysis of Decision Tree Algorithms: ID3, C4.5 and Random Forest. In Computational Intelligence in Data Mining—New Delhi: Smart Innovation, Systems and Technologies; Jain, L., Behera, H., Mandal, J., Mohapatra, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 31. [Google Scholar]
- Zhao, X.; Qin, Y.; Kou, L.; Liu, Z. Understanding real faults of axle box bearings based on vibration data using decision tree. In Proceedings of the 2018 IEEE International Conference on Prognostics and Health Management (ICPHM), Seattle, WA, USA, 11–13 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Voronov, S.; Krysander, M.; Frisk, E. Predictive maintenance of lead-acid batteries with sparse vehicle operational data. Int. J. Progn. Health Manag. 2020, 11. [Google Scholar] [CrossRef]
- Hu, H.; Luo, H.; Deng, X. Health Monitoring of Automotive Suspensions: A LSTM Network Approach. Shock Vib. 2021, 2021, 6626024. [Google Scholar] [CrossRef]
- Al-Zeyadi, M.; Andreu-Perez, J.; Hagras, H.; Royce, C.; Smith, D.; Rzonsowski, P.; Malik, A. Deep Learning Towards Intelligent Vehicle Fault Diagnosis. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 1–34. [Google Scholar]
- Guo, J.; Lao, Z.; Hou, M.; Li, C.; Zhang, S. Mechanical fault time series prediction by using EFMSAE-LSTM neural network. Measurement 2021, 173, 108566. [Google Scholar] [CrossRef]
- Wang, H.; Peng, M.J.; Miao, Z.; Liu, Y.K.; Ayodeji, A.; Hao, C. Remaining useful life prediction techniques for electric valves based on convolution auto encoder and long short term memory. ISA Trans. 2021, 108, 333–342. [Google Scholar] [CrossRef]
- Chen, C. Deep Learning for Automobile Predictive Maintenance under Industry 4.0. Ph.D. Thesis, Cardiff University, Cardiff, UK, 2020. [Google Scholar]
- Safavi, S.; Safavi, M.A.; Hamid, H.; Fallah, S. Multi-Sensor Fault Detection, Identification, Isolation and Health Forecasting for Autonomous Vehicles. Sensors 2021, 21, 2547. [Google Scholar] [CrossRef]
- Xu, P.; Wei, G.; Song, K.; Chen, Y. High-accuracy health prediction of sensor systems using improved relevant vector-machine ensemble regression. Knowl.-Based Syst. 2021, 212, 106555. [Google Scholar] [CrossRef]
- Madni, A.M.; Madni, C.C.; Lucero, S.D. Leveraging digital twin technology in model-based systems engineering. Systems 2019, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Ezhilarasu, C.M.; Skaf, Z.; Jennions, I.K. Understanding the role of a digital twin in integrated vehicle health management (IVHM). In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019. [Google Scholar]
- Rajesh, P.K.; Manikandan, N.; Ramshankar, C.S.; Vishwanathan, T.; Sathishkumar, C. Digital twin of an automotive brake pad for predictive maintenance. Procedia Comput. Sci. 2019, 165, 18–24. [Google Scholar] [CrossRef]
- Magargle, R.; Johnson, L.; Mandloi, P.; Davoudabadi, P.; Kesarkar, O.; Krishnaswamy, S.; Pitchaikani, A. A simulation-based digital twin for model-driven health monitoring and predictive maintenance of an automotive braking system. In Proceedings of the 12th International Modelica Conference, Prague, Czech Republic, 15–17 May 2017; Linköping University Electronic Press: Linköping, Sweden, 2017. [Google Scholar]
- Yujun, L.; Zhichang, Z.; Wei, W.; Kui, Z. Digital twin product lifecycle system dedicated to the constant velocity joint. Comput. Electr. Eng. 2021, 93, 107264. [Google Scholar] [CrossRef]
- Liu, K.; Shang, Y.; Ouyang, Q.; Widanage, W.D. A data-driven approach with uncertainty quantification for predicting future capacities and remaining useful life of lithium-ion battery. IEEE Trans. Ind. Electron. 2020, 68, 3170–3180. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Method(s) | Main Applications | Data Types Used |
|---|---|---|---|---|
| Physics-Based Models | ||||
| [23] | 2018 | Description of a compact angular head (roller hemming) | SD | |
| [31] | 2019 | Vibration-based machinery health monitoring techniques | RD | |
| Knowledge-Based Models | ||||
| [24] | 2020 | Fuzzy logic | Evaluation of vehicle state to prevent anomalies and malfunctions | RD |
| Statistical and Stochastic Approaches | ||||
| [32] | 2017 | Diagnosis of battery faults | RD | |
| [33] | 2018 | Diagnosis of the connection of lithium-ion battery in series | RD | |
| [40] | 2018 | Modeling of all possible causal relationships between sensor signals recorded directly from CAN bus in-vehicle networks | RD | |
| [6] | 2019 | Description of degradation processes | RD | |
| [26] | 2021 | Description of lithium-ion batteries’degradation | RD | |
| [25] | 2021 | Identification of defects in a spur gear system | RD | |
| Traditional Machine Learning Approaches | ||||
| [46] | 2016 | LR, ANN | Diesel engine fueled with biodiesel alcohol mixtures | RD |
| [42] | 2017 | MLR | Energy intensity of new automotive plants | RD |
| [45] | 2017 | GPR | RUL prediction for slow speed bearings | RD |
| [55] | 2018 | k-NN | Classification of vibration gravity to predict anomalies in electric inductive motors | RD |
| [62] | 2018 | DT | Identification of different fault types of axle box bearings | RD |
| [9] | 2018 | DT, SVM, RF, k-NN | Monitoring and fault predicting system in vehicle | RD |
| [43] | 2019 | MLR | Fatigue life evaluation of automotive coil springs | RD |
| [52] | 2019 | SVM | Fault diagnosis of vehicle suspensions | SD |
| [49] | 2020 | RF, SVM, ANN, GP | Fault diagnosis in turbocharged petrol engine systems | SD |
| [44] | 2020 | LR | Failures prediction of a given vehicle component | RD |
| [47] | 2021 | ANN, SVM, LR, GPR | State of charge Estimation of lithium-ion battery for electric vehicles | RD |
| [48] | 2021 | ANN + k-NN | Vehicle health monitoring | RD |
| [53] | 2021 | SVM | Fault detection, identification, and prediction for autonomous vehicle controllers | SD |
| Deep Learning Approaches | ||||
| [80] | 2020 | LSTM+GPR | RUL prediction for lithium-ion (Li-ion) batteries with reliable uncertainty management | RD |
| [50] | 2020 | AE | Prediction of upcoming failures in trucks | RD |
| [66] | 2020 | LSTM, RF | Heavy medium lead-acid battery prognosis | RD |
| [72] | 2020 | Merged-LSTM | Time-between-failure (TBF) prediction modeling based on multisource data | RD |
| [71] | 2021 | CAE+LSTM | RUL prediction for electric valves | SD |
| [47] | 2021 | EBa, EBo | State of charge estimation of lithium-ion battery for electric vehicles | RD |
| [70] | 2021 | EFMSAE-LSTM | Prediction of mechanical fault time series | RD |
| [67] | 2021 | LSTM | Remaining fatigue life of automotive suspension | RD |
| [73] | 2021 | CNN | Multisensor fault detection for autonomous vehicles | RD |
| [74] | 2021 | Ensemble method | Health prediction for sensor systems | RD |
| Digital Twin Technology | ||||
| [78] | 2017 | Prediction of brake pad wear in a car | SD | |
| [77] | 2019 | Predictive maintenance of an automotive braking system | SD | |
| [79] | 2021 | Maintenance of the constant velocity joint of a car | SD | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arena, F.; Collotta, M.; Luca, L.; Ruggieri, M.; Termine, F.G. Predictive Maintenance in the Automotive Sector: A Literature Review. Math. Comput. Appl. 2022, 27, 2. https://doi.org/10.3390/mca27010002
Arena F, Collotta M, Luca L, Ruggieri M, Termine FG. Predictive Maintenance in the Automotive Sector: A Literature Review. Mathematical and Computational Applications. 2022; 27(1):2. https://doi.org/10.3390/mca27010002
Chicago/Turabian StyleArena, Fabio, Mario Collotta, Liliana Luca, Marianna Ruggieri, and Francesco Gaetano Termine. 2022. "Predictive Maintenance in the Automotive Sector: A Literature Review" Mathematical and Computational Applications 27, no. 1: 2. https://doi.org/10.3390/mca27010002
APA StyleArena, F., Collotta, M., Luca, L., Ruggieri, M., & Termine, F. G. (2022). Predictive Maintenance in the Automotive Sector: A Literature Review. Mathematical and Computational Applications, 27(1), 2. https://doi.org/10.3390/mca27010002