1. Introduction
Reliable traffic data collection is essential for road planning, traffic simulation, safety analysis, and road asset management [
1]. Among the various sources for collecting traffic data [
2], camera systems have proven to be particularly advantageous when the trajectories of road users are of interest, for example, in safety analysis with surrogate safety measures (SSM) [
3]. However, optical cameras are susceptible to weather conditions, rely on external lighting, and their use may be restricted by data protection regulations. In such situations, thermal imaging technology is advantageous as it is insensitive to weather and light conditions such as precipitation, darkness, sunlight, or shadows [
4] and does not capture personal information.
There are already field solutions detecting road users in thermal images. Two well-known systems for urban real-time traffic detection are the FLIR TrafiSense2 [
5] and the FLIR TrafiSense AI [
6]. These systems can detect the presence and class of objects in predefined zones. This is sufficient for many applications, for example, for traffic light control. Applications like more detailed road-user-behavior studies call for flexible detection and tracking of objects to obtain the road users’ trajectory.
Systems enabling flexible traffic data collection beyond predefined areas rely fundamentally on effective and accurate object detection algorithms. In this context, object detection refers to the classification and concurrent pinpointing of objects within a video frame [
7]. In the literature, there is a notable emphasis on applying these algorithms to traffic detection in RGB camera images, often concentrating on real-time detection [
8] or sensor fusion [
9]. In thermal imagery, many studies focus on applications such as monitoring drivers [
10] or autonomous driving [
11]. Researchers have addressed the challenging task of object detection in infrared images, which have fewer features than RGB images, through methods like combining RGB and infrared images [
12] or enhancing established architectures by compressing channels and optimizing parameters [
13]. While there is some research on detecting pedestrians [
14] and parked cars [
15] with roadside thermal cameras, there is still a significant gap in research on algorithms for that specific application.
Traffic detection with thermal images from roadside cameras poses an additional challenge. In contrast to applications with moving cameras (e.g., autonomous driving), the images in the datasets are very similar due to the fixed cameras, which poses a significant risk of overfitting, mainly because large datasets such as COCO [
16], typically used for initial training, consist of images from RBG and, therefore, non-thermal cameras. Although Danaci et al. [
17] have compiled 109 thermal imagery datasets, it appears that only the datasets from Balon et al. [
18,
19] and the AAU RainSnow Traffic Surveillance Dataset [
20] are specifically available for this purpose. Balon et al. achieved promising results using YOLOv5 [
21] and YOLOv7 [
22] algorithms on their own dataset of infrared images from infrastructure cameras. However, both datasets contain only one location each and were recorded in half an hour and 45 min on one day [
18,
19], which is why it is to be expected that these models are overfitted to the viewing angles and environmental conditions used. In contrast, the AAU RainSnow Traffic Surveillance Dataset contains images from seven viewpoints [
20]. However, due to the small number of about 2000 images, it is not expected to be sufficient to train generalizing models.
Data collection and annotation are costly, especially for infrastructure cameras, which require complex permits and potential road closures for installation. In RGB images, the scientific community is exploring self-learning approaches, often using larger teacher networks to generate pseudo-labels for training student networks [
23], a method known as weakly supervised training [
24]. These approaches often rely on image similarities [
25] and sometimes on incorporating human knowledge [
26]. Beyond new training, certain methods apply filtering [
27] and tracking algorithms [
28] to compensate for false-positive detections and misclassifications. Those algorithms rely on rules and constraints and may lack the generalization of retrained neural networks. Although works like Tang et al. [
29] combine elements of both, there is limited research on solutions that fully leverage the unique properties of thermal roadside cameras, such as limited features and stationary cameras detecting primarily moving objects, within weakly supervised learning frameworks.
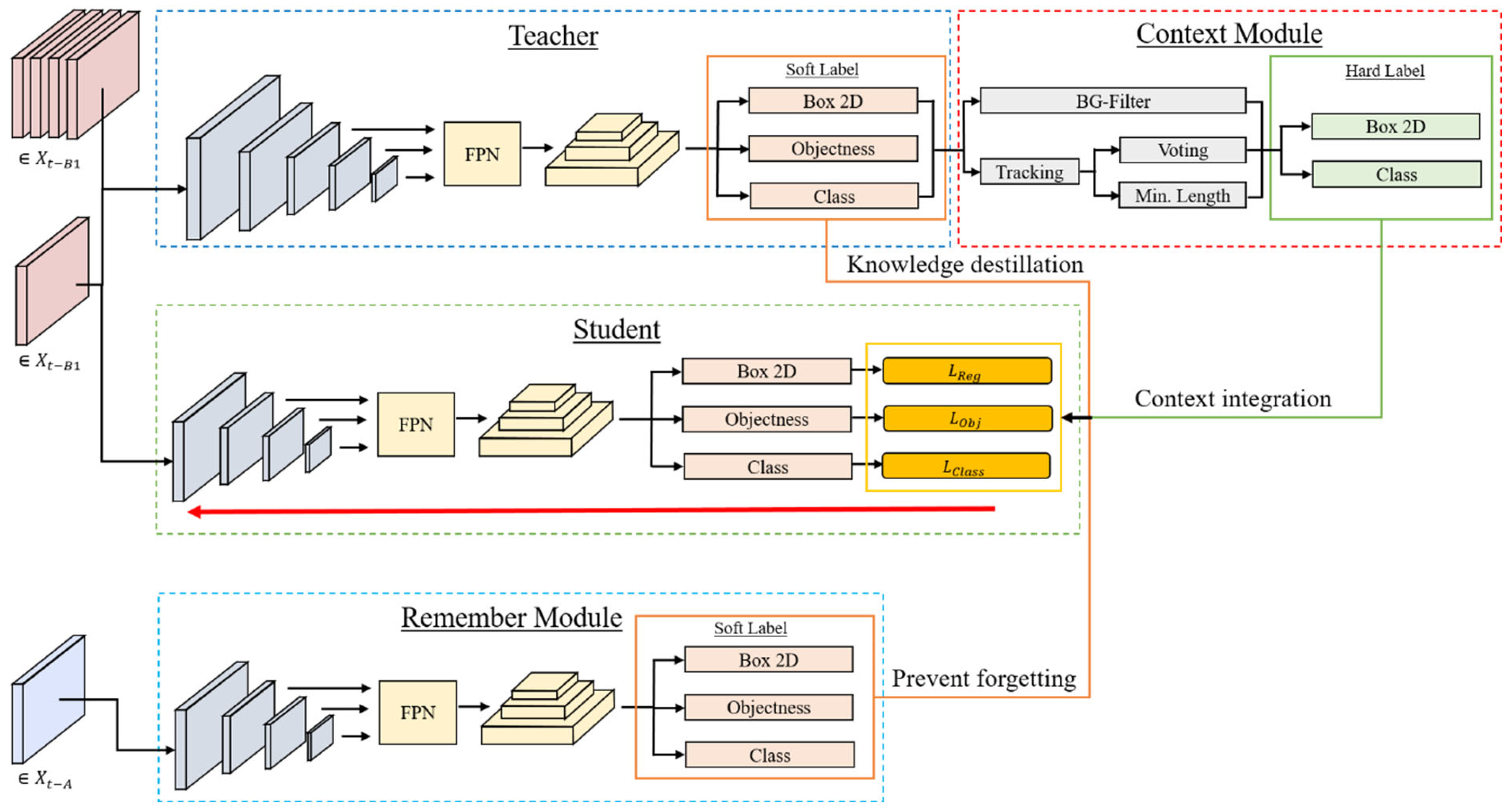
To develop a generalized algorithm for accurate traffic data collection across diverse locations, two key research areas require improvement in thermal image-based traffic detection. First, heterogeneous datasets are essential for effective viewpoint adjustment, necessitating distinct training and test data. Second, perspective adjustment methods are needed to address limited heterogeneous data, enabling universal application without additional human labeling
This paper enables reliable 2D object detection in thermal imagery from infrastructure cameras by addressing these two key gaps. First, it provides a unique dataset to address the lack of heterogeneous data in infrared images from varied traffic viewpoints. Second, it combines weakly supervised learning, incremental learning, and pseudo-label enhancement to a novel weakly supervised incremental training framework specially adapted to the challenges of roadside thermal imagery, allowing fast and robust adaptation to new camera positions and diverse traffic or environmental conditions.
3. Results and Discussion
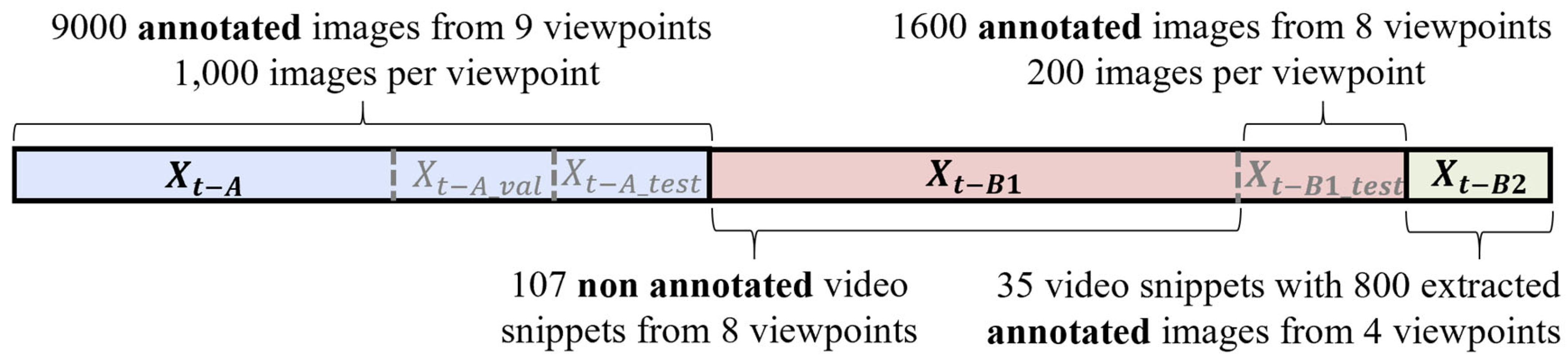
3.1. Dataset
The labeled parts used for initial neural network transfer learning
and the evaluation sets
and
are emphasized in the dataset evaluation.
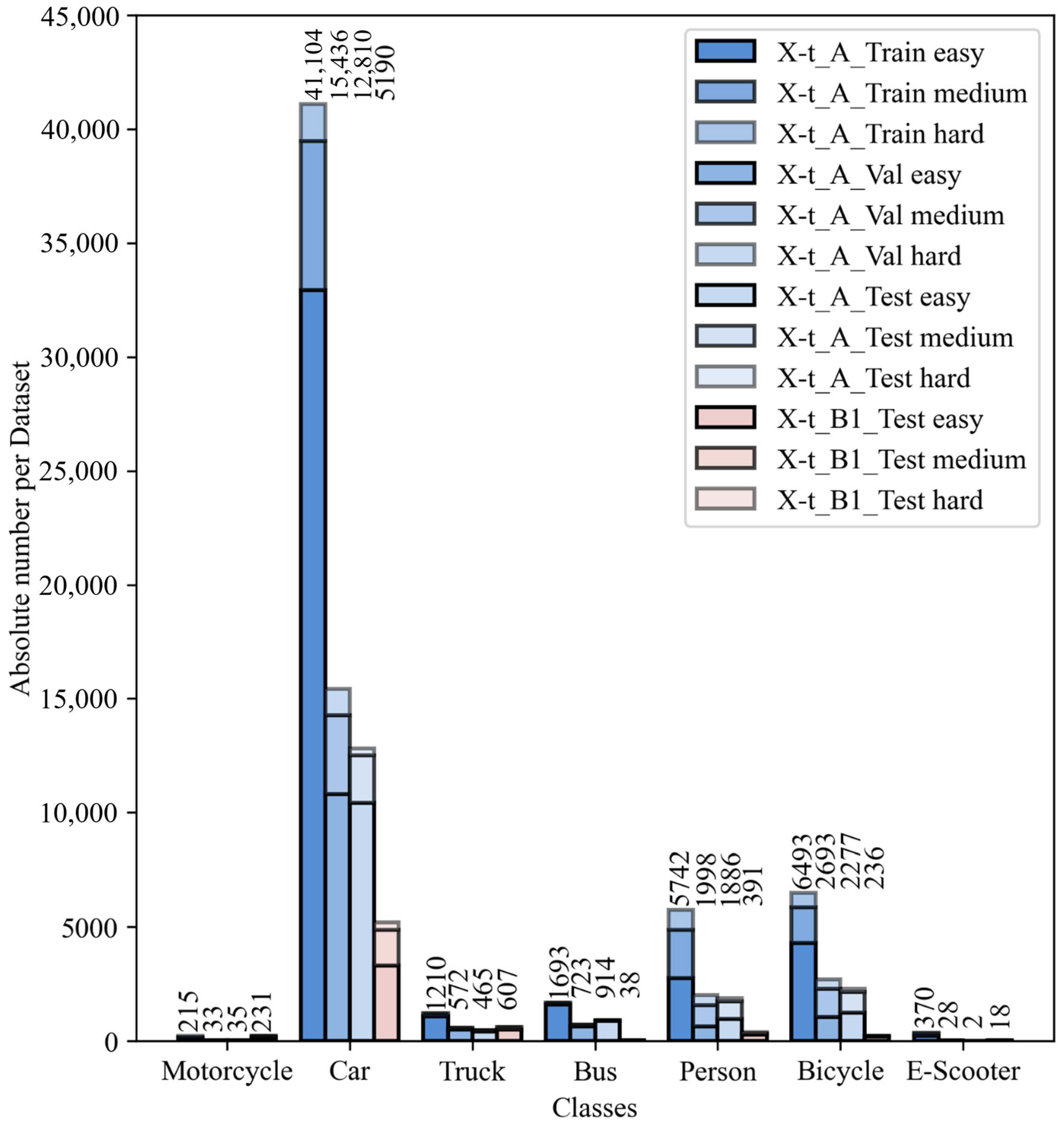
Figure 5 displays the class distribution for these parts and the distribution of objects categorized as easy, medium, and hard to detect.
Class distributions are generally uneven across all analyzed dataset parts, with the car class significantly more represented than others. This distribution reflects traffic data collection applications, as cars are the most common vehicle type. Notably, the test set , which includes heterogeneous viewpoints, contains fewer buses, pedestrians and cyclists but more motorcyclists and trucks. However, differences across difficulty levels are minor, especially in the most represented class, cars.
3.2. Performance Analysis
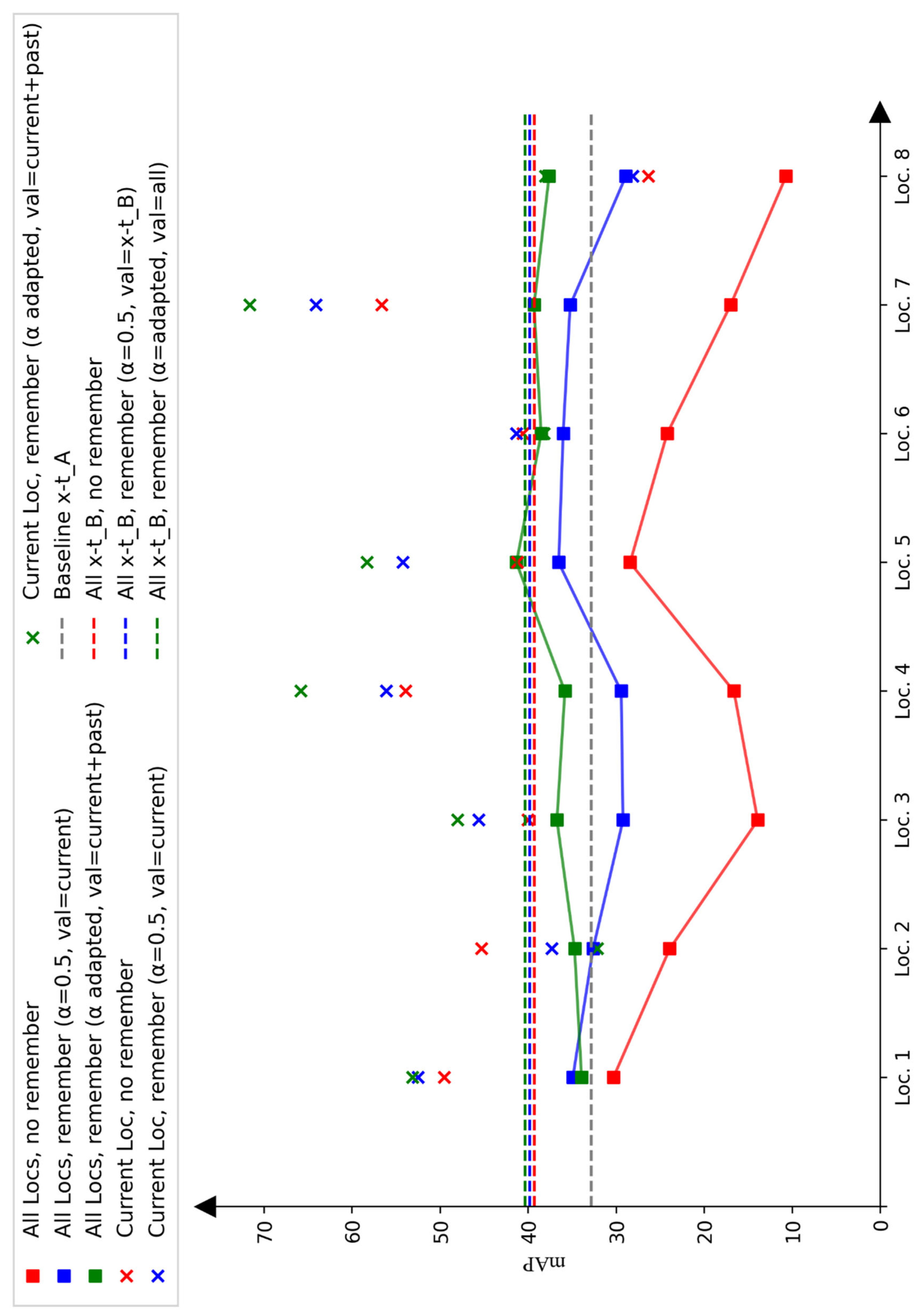
Figure 6 provides a summary of key results across experiments. The mAP on the
dataset is shown, with crosses indicating each model’s performance at specific locations. Models were trained sequentially, location by location, in random order using data from
with the proposed framework, or collectively across all locations in
. Training was conducted both without the remember module (red) and with it (blue and green). As described, two remember module options were tested: (1) α = 0.5 with validation data only from the current location or
(blue) and (2) an adapted α with validation data from all previous locations (green). Overall, performance on unseen data improved significantly. One observes that after adding five extra locations, the performance stabilizes and reaches similar results as when training on all locations. This supports the idea that more diverse locations lead to better detection quality and reduced overfitting. While
Figure 6 reports the results during the process of incremental learning,
Table 2 compares AP for the baseline model (Yv7t) trained on
, the incrementally trained model with adapted α and mixed validation data (Yv7t-PRIA), and the model trained on the entire
dataset at once using the adapted α and mixed validation set (Yv7t-PRA) after training on all locations. An increase of 8.9 percentage points in mAP was observed, with similar regression precision (78% mIoU to 79% mIoU) and a notably improved mF1-score (up by 7.5 percentage points). The analysis in
Figure 7 indicates that this improvement is mainly due to fewer false positives in the background and better classification. While nearly all classes showed improvement, detection performance remains low for some classes. For instance, poor performance on the e-scooter class suggests that more class objects in the weakly supervised training data are needed and that the teacher network must initially detect all classes reliably.
Comparing the incrementally trained version with the one trained on the entire dataset at once, a slightly lower performance is observed. Additionally, the performance curve does not consistently rise, indicating that even with the remember module, some features are forgotten, especially since not every object class appears in all locations (e.g., no pedestrians in highway camera images).
Due to the high computational cost, mAPs are only reported for a single representative run per setup, consistent with common practice in object detection such as in [
22]. Since the models were not trained from random initialization but from pretrained weights, remaining sources of randomness like the sample order are expected to have minor influence and would not explain the substantial improvement observed.
3.3. Comparison with State-of-The Art Datasets
Table 3 presents the results of the Yolov7-tiny model trained on the AAU Rain Snow Dataset (AAU) and the AutomotiveThermal Dataset (AT), evaluated on the test set of each specific dataset and the
set. Bahnsen et al. [
20] did not report specific results for object detection models on the thermal part of their dataset and did not define a test set. Therefore, 25% of each camera viewpoint was used for testing. In contrast, Baalon et al. [
18] defined a test set and reported results with an mAP of 99.2, which was approximately reproduced here (99.7 mAP). Only the first published dataset by Balon et al. was considered since the second is no longer available online [
18].
When applying the models trained on their original datasets to the set, a significant performance decrease was observed. The performance drop was particularly notable for the model trained on the AT dataset. This decrease reflects the homogeneous composition of Baalon et al.’s dataset, which resulted in poor detection quality on unknown data but exceptionally high performance on the original dataset. Such good performance indicates that both training and test sets within this dataset were too similar, leading to severe overfitting. This drop in performance provides a clear quantitative measure of overfitting, demonstrating how models trained on less-diverse locations fail to generalize to more varied data.
The AAU-trained model showed better performance on unseen data due to its more diverse dataset composition. However, the poor results on unknown data still suggest that the AAU dataset’s relatively small size of about 2000 images is insufficient for developing robust, generalizing algorithms.
3.4. Detailed Performance Analysis
3.4.1. Performance of the Base Models
Comparing the performance of the larger YoloV7 model (Yv7) and the target model YoloV7-tiny (Yv7t) in
Table 4, using the dataset
for initial training on
and the more heterogeneous dataset
, leads to several conclusions. First, the significant drop in mAP and mF1 metrics highlights the generalization problem addressed by this work. Additionally, the use of the larger YoloV7 model as a teacher network is justified, as it performs better on unseen data (32.8 mAP vs. 31.4 mAP). Furthermore, the similar or better mIoU on
reinforces that no additional bounding box regression improvements are necessary, as the teacher model’s bounding boxes with a high mIoU of 0.78 effectively guide the student.
Several factors could explain the lower performance on the more heterogeneous test dataset , One reason may be the dataset composition itself, where class distribution influences performance. False positives have a higher impact on underrepresented classes, such as person, bicycle, and bus. For more represented classes, like motorbike and truck, one would expect an opposite effect, but the lack of this effect, combined with a generally similar distribution across difficulty levels (easy, medium, and hard), suggests other factors, such as insufficient training data. The high performance of the car class in also indicates that generalization may strongly depend on the quantity of training examples. These results further demonstrate the overfitting issue, as models trained on a more homogeneous dataset show significant performance drops when tested on more diverse and challenging data.
3.4.2. Remember Module
Influence During Incremental Training
Figure 7 highlights the impact of the remember module in a general manner during the incremental learning process. Generalization performance is notably higher than that of the framework without this module across all training steps. Additionally, even on specific current training data, performance is superior for most locations. This improvement likely stems from learning more robust features due to training with diverse data (different viewing angles, objects, etc.) labeled by the remember module. Furthermore, the influence of human-annotated data enhances performance since
images are part of the training, and the loss function is structured to match previous outputs on human-labeled data.
Influence During Training on All Locations at Once
Table 5 compares the results of training on all locations in
at once, with and without the remember module, on
and
. Notably, similar performance is observed on
, but there is a significant difference on
. This highlights the importance of the remember module, even with a larger, multi-location dataset, in achieving better performance on all data without compromising on new locations. Thus, performance even surpasses the baseline, which was trained only on
. data. However, overall performance on
is lower than on
, likely because strong supervision generally yields better results than weak supervision. Additionally, the diversity in weather, traffic, and backgrounds in
likely increases its complexity.
3.4.3. Incremental Learning
The comparison of the blue and green data points in
Figure 6 shows that both the scaling factor α and the validation dataset choice significantly affect incremental learning performance. Except for the first location, where only 1/8 of
locations were included in the validation set, the model with adapted α and mixed validation sets performed best.
Incremental learning without a remember module results in a sharp performance drop, likely because unlearned features are not relearned, and no loss term manages forgetting. The remember module with α = 0.5 helps mitigate this, but generalization performance still declines at some training steps. First, α = 0.5 may overweight new data, leading to overfitting. Second, generalization properties may be missing from the validation set, preventing the model from saving the best generalizing training state.
3.4.4. Training and Inference Times
Table 6 shows the inference times with a batch size of 1 on Nvidia Jetson Xavier NX and the GPU server. On the server, model size has minimal impact on inference speed, particularly for efficient YOLO models, and YOLOv7 operates well above real-time speed (30 FPS). However, on the edge device, the difference is more substantial, with only YOLOv7-tiny achieving adequate speed (~25 FPS). On the edge device, the model was executed with onnx-runtime. Although further optimizations are possible, the general trend favors YOLOv7-tiny.
Examining training times, the teacher model and context module have little impact and, in some cases, even reduce training time. This is due to fast inference by the teacher model and prior labeling from the context module. Notably, only one measurement was taken, so shorter times may result from external factors, but the overall trend remains relevant. The remember module with both large and small validation datasets noticeably increases training time, likely due to an additional data loader for prior location images. The extended training time with larger validation sets indicates a bottleneck in data loading.
Incremental learning times per location are much faster on average, scaling with the volume of new data (images per new location, number of locations), which further demonstrates the advantages of this approach.
3.5. Evaluation of the Context Module
3.5.1. Filtering Algorithms
The larger teacher model, together with tracking and filtering algorithms, was applied on the dataset to analyze these algorithms’ ability to improve pseudo labels. Although includes only four viewpoints, which raises overfitting risks, the dataset contains over 3000 objects, making the evaluations reasonably valid. The results do not rely on class-wise mean values of F1, precision, and recall when evaluating filter and voting algorithms, as these metrics should remain unaffected by class distribution in . For pseudo-labels, the focus is on overall counts rather than class-wise details.
All evaluations in
Table 7 were conducted only on images with detections, as only these detections are used as pseudo labels for model retraining. This leads to a different object count across algorithms. The first observation is that neither the PDBE method based on [
27] nor the SRRS method based on [
37] worked effectively, especially when applying thresholds reported in [
27,
37] (PDBE thresh: 6, SRRS thresh 0.08). PDBE resulted in no filtering, while SRRS nearly filtered out all detections at these thresholds. A likely reason is thermal images’ generally lower feature density. Both methods rely on box density, which may not suit thermal images. Presumably, the lower feature density and pretraining on optical images cause certain areas in the image (e.g., some bright spots, even in the background) to register higher box density.
The TMF-based background filter and the minimum track length filter showed improved results, especially in precision, indicating that both algorithms significantly reduce false positive detections. However, both filters also reduce true positive detections, leading to a decrease in recall. As shown in
Figure 8, true objects typically have a high probability score from the teacher network, so falsely filtered objects are unlikely to impact the student’s loss significantly. Since the background filter combined with the minimum track length filter achieves the highest F1 score, this combination is chosen as the filtering algorithm for this work.
3.5.2. Voting Strategies for Tracking Objects
Comparing the different voting strategies (see
Table 8), it is observed that soft vote and max score vote produce the worst results, likely due to a comparatively high number of false detections with high scores. Major vote proves more reliable as it includes all detections in the decision process. However, the minor change in the number of TPs indicates a low number of identity switches in the dataset
, so the comparison is not entirely conclusive. Combined with the chosen filtering algorithms described above, the overall F1 score improves significantly by 6.4 percentage points.
3.6. Future Application
This methodology enables reliable, scalable traffic detection through thermal imaging in diverse environments, addressing the traditional limitations of location-specific training data and high retraining costs. By introducing a framework that quickly adapts to new viewpoints, this approach achieves high detection accuracy and broad generalizability with minimal human intervention.
The system provides dual advantages: quick adaptation to novel sites without the need for retraining from scratch and long-term performance enhancement through cumulative learning. Critically, it supports rapid updates for deployed systems, accommodating new locations or changing environmental conditions without compromising existing performance—a significant advancement for maintaining system reliability over time. Using video data collected under varied conditions, this framework demonstrates consistently improved detection across both new and previously seen viewpoints. Future implementations could further enhance generalizability by training on data from multiple new locations simultaneously, comparable to training on the whole dataset. Additionally, the system’s ability to be deployed on edge devices such as the Jetson Xavier NX and powered by street lamps ensures low-power consumption, cost-effectiveness, and scalability, making it suitable for wide-scale urban deployment. This approach also holds promise for integration with smart city infrastructures, enabling real-time traffic monitoring and more efficient management of urban traffic systems.
Future applications could address the need for sensor failure detection, such as camera misalignment or thermal sensor issues, which are not automatically detected in the current framework. However, the architecture of the system is flexible, and these mechanisms can be incorporated in future versions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}