
An Explainable LSTM-Based Intrusion Detection System Optimized by Firefly Algorithm for IoT Networks


Abstract
1. Introduction
2. Related Studies
2.1. Feature Selection in ML and DL Models for IDSs
2.2. Metaheuristic Algorithm for Feature Selection in IDSs
2.3. Explainable DL Models for IDSs
3. Theoretical Background/Preliminaries
3.1. Filter-Based Feature Selection Methods
3.1.1. Spearman’s Rank Correlation
3.1.2. Mutual Information
3.2. Firefly Algorithm (FA)
3.3. Long Short-Term Memory (LSTM)
3.4. Explainable Artificial Intelligence (XAI) Methods
3.4.1. Shapley Additive Explanation (SHAP)
3.4.2. Local Interpretable Model-Agnostic Explanations (LIME)
4. Proposed Architecture
4.1. Dataset Description
4.2. Data Preprocessing
4.3. Feature Selection
| Algorithm 1: hybrid feature selection |
| Input: feature dataset //s = total number of features, target variable , population size , maximum iteration , absorption coefficient , randomization parameter , minimum features , and maximum features . Output: optimized feature subset 1: Read original feature set 2: for 3: Compute SRC between all features and target variable using Equation (1) 4: Define a correlation threshold where = 0.2 5: // denotes a set of relevant features, signifies a set of selected features using SRC greater than the threshold 6: end for 7: Compute mutual information 8 Read original feature set 9: for 10: Compute MI between all features and target variable using Equation (2) 11: Define a threshold where = 0.1 12: // denotes a set of relevant features, signifies a set of selected features using MI greater than the threshold 13: end for 14: Optimization through firefly 15: Normalize and 16: Combine score // denotes combined scores by summing normalized SRC and MI scores 17: Generate the initial population of fireflies using uniform distribution 18: Set parameters as , , , 19: Enforce and constraints for fireflies 20: Evaluate all the fireflies by using a fitness function 21: Light intensity at is determined by the fitness function 22: 23: While do 24: 25: for I = 1 to n do 26: for j = 1 to i do 27: if then 28: Move firefly towards firefly using Equation (3) 29: end if 30: Evaluate the new solution by using the light intensity 31: Ensure respects and 32: end for 33: end for 34: Rank the fireflies based on highest fitness and find the current best 35: end while |
4.4. Training and Testing the Model
4.5. Model Interpretation
5. Experimental Results and Analysis
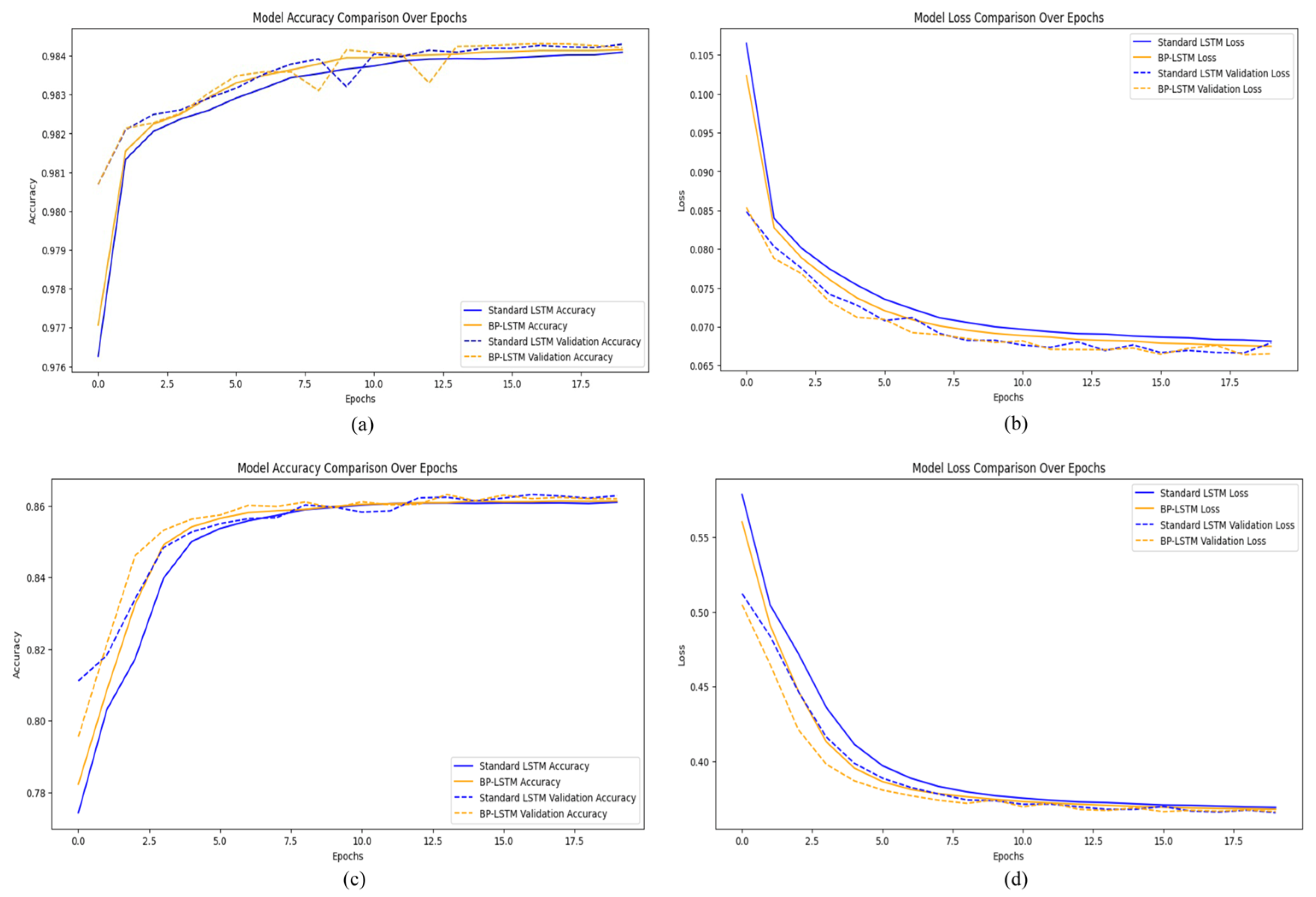
5.1. Model Evaluation
5.2. Analysis and Comparison of Results
5.3. Further Analysis of the Model
5.3.1. Ablation Study
5.3.2. Computational Analysis
5.3.3. Model Performance on Zero-Day Attack Types
5.3.4. Scalability Analysis for Larger IoT Networks
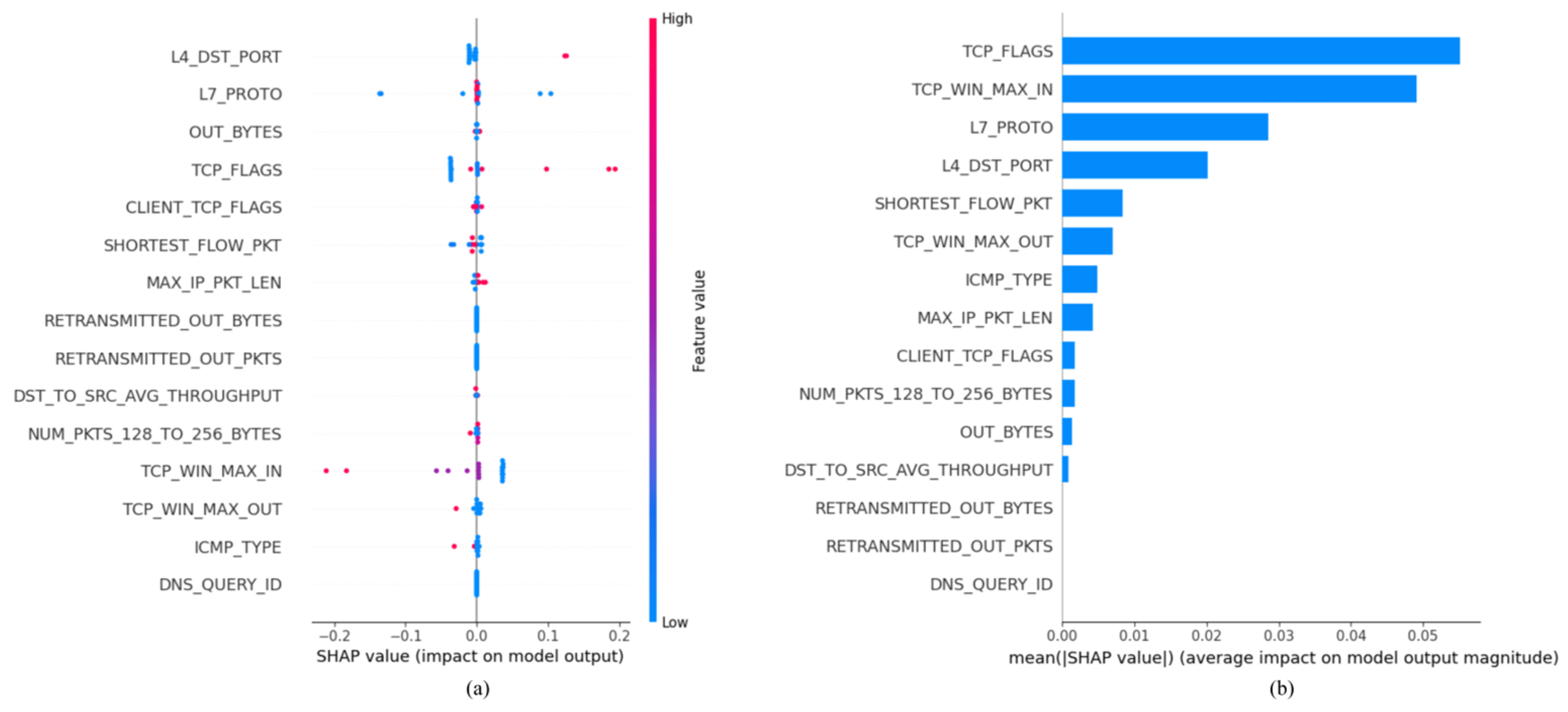
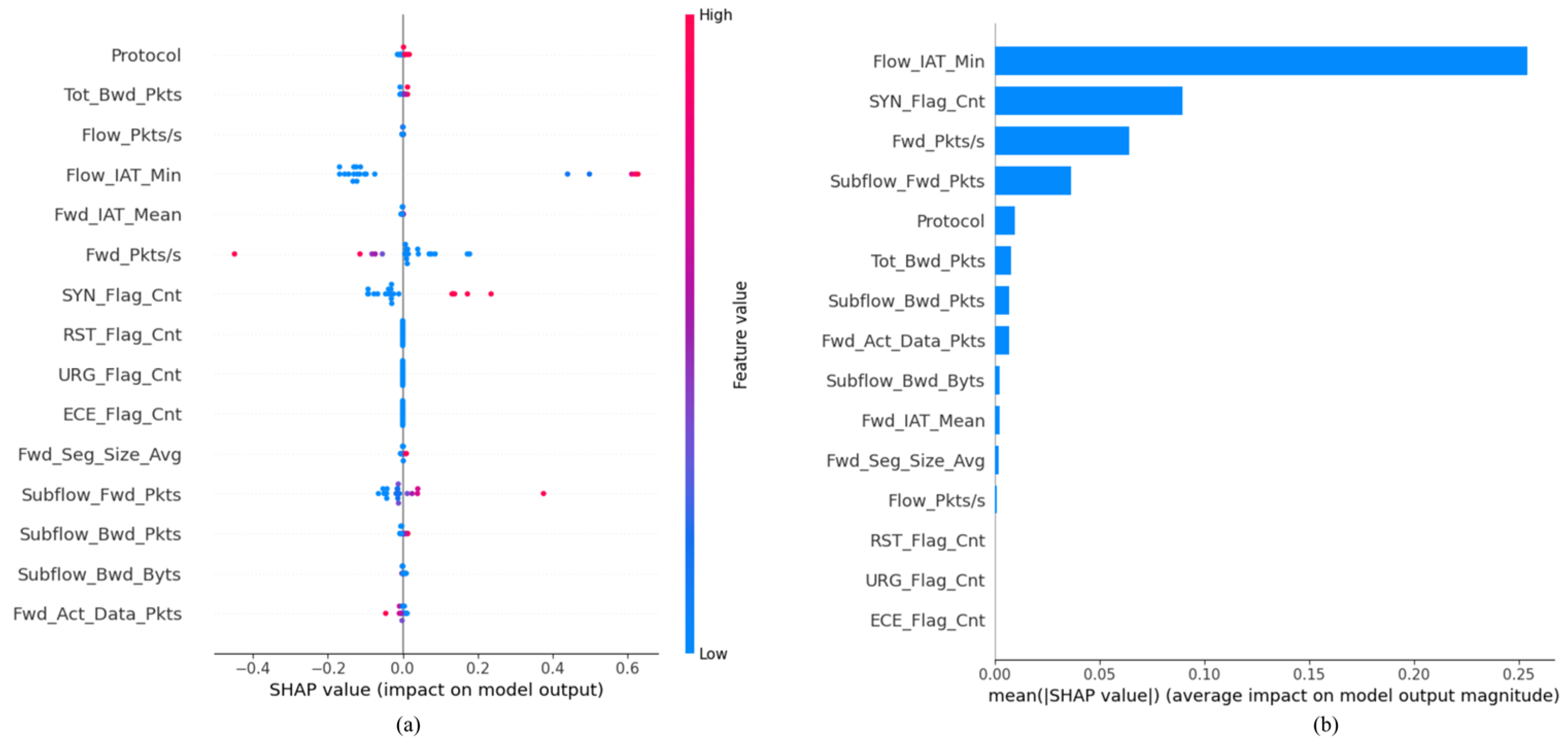
5.4. Model Explanation
6. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Verkerken, M.; D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. Towards model generalization for intrusion detection: Unsupervised machine learning techniques. J. Netw. Syst. Manag. 2022, 30, 1–25. [Google Scholar]
- Zhang, Y.; Zhang, H.; Zhang, B. An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection. Information 2022, 13, 314. [Google Scholar] [CrossRef]
- Alalhareth, M.; Hong, S.C. An improved mutual information feature selection technique for intrusion detection systems in the Internet of Medical Things. Sensors 2023, 23, 4971. [Google Scholar] [CrossRef]
- Alzaabi, F.R.; Mehmood, A. A review of recent advances, challenges, and opportunities in malicious insider threat detection using machine learning methods. IEEE Access 2024, 12, 30907–30927. [Google Scholar]
- Sulaiman, N.S.; Nasir, A.; Othman, W.R.W.; Wahab, S.F.A.; Aziz, N.S.; Yacob, A.; Samsudin, N. Intrusion detection system techniques: A review. J. Phys. Conf. Ser. 2021, 1874, 012042. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 80–89. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A review of unsupervised feature selection methods. Artif. Intell. Rev. 2020, 53, 907–948. [Google Scholar]
- Islam, M.R.; Lima, A.A.; Das, S.C.; Mridha, M.F.; Prodeep, A.R.; Watanobe, Y. A comprehensive survey on the process, methods, evaluation, and challenges of feature selection. IEEE Access 2022, 10, 99595–99632. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, Shanghai, China, 27–29 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 372–378. [Google Scholar]
- Islam, S.R.; Eberle, W.; Bundy, S.; Ghafoor, S.K. Infusing domain knowledge in ai-based” black box” models for better explainability with application in bankruptcy prediction. arXiv 2019, arXiv:1905.11474. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Gercia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar]
- Wang, W.; Du, X.; Wang, N. Building a Cloud IDS Using an Efficient Feature Selection Method and SVM. IEEE Access 2019, 7, 1345–1354. [Google Scholar] [CrossRef]
- Altulaihan, E.; Almaiah, M.A.; Aljughaiman, A. Anomaly Detection IDS for Detecting DoS Attacks in IoT Networks Based on Machine Learning Algorithms. Sensors 2024, 24, 713. [Google Scholar] [CrossRef]
- Albulayhi, K.; Abu Al-Haija, Q.; Alsuhibany, S.A.; Jillepalli, A.A.; Ashrafuzzaman, M.; Sheldon, F.T. IoT intrusion detection using machine learning with a novel high performing feature selection method. Appl. Sci. 2022, 12, 5015. [Google Scholar] [CrossRef]
- Sanju, P. Enhancing intrusion detection in IoT systems: A hybrid metaheuristics-deep learning approach with ensemble of recurrent neural networks. J. Eng. Res. 2023, 11, 356–361. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. Toward design of an intelligent cyber attack detection system using hybrid feature reduced approach for iot networks. Arab. J. Sci. Eng. 2021, 46, 3749–3778. [Google Scholar] [CrossRef]
- Abdo, A.; Mostafa, R.; Abdel-Hamid, L. An Optimized Hybrid Approach for Feature Selection Based on Chi-Square and Particle Swarm Optimization Algorithms. Data 2024, 9, 20. [Google Scholar] [CrossRef]
- Bacanin, N.; Venkatachalam, K.; Bezdan, T.; Zivkovic, M.; Abouhawwash, M. A novel firefly algorithm approach for efficient feature selection with COVID-19 dataset. Microprocess. Microsyst. 2023, 98, 104778. [Google Scholar] [CrossRef]
- Eşsiz, E.S.; Kılıç, V.N.; Oturakçı, M. Firefly-Based feature selection algorithm method for air pollution analysis for Zonguldak region in Turkey. Turk. J. Eng. 2023, 7, 17–24. [Google Scholar] [CrossRef]
- Sharifai, A.G.; Zainol, Z.B. Multiple filter-based rankers to guide hybrid grasshopper optimization algorithm and simulated annealing for feature selection with high dimensional multi-class imbalanced datasets. IEEE Access 2021, 9, 74127–74142. [Google Scholar] [CrossRef]
- Kareem, S.S.; Mostafa, R.R.; Hashim, F.A.; El-Bakry, H.M. An effective feature selection model using hybrid metaheuristic algorithms for iot intrusion detection. Sensors 2022, 22, 1396. [Google Scholar] [CrossRef]
- Dey, A.K.; Gupta, G.P.; Sahu, S.P. Hybrid meta-heuristic based feature selection mechanism for cyber-attack detection in iot-enabled networks. Procedia Comput. Sci. 2023, 218, 318–327. [Google Scholar]
- Amarasinghe, K.; Kenney, K.; Manic, M. Toward Explainable Deep Neural Network Based Anomaly Detection. In Proceedings of the 2018 11th International Conference on Human System Interaction (HSI), Gdansk, Poland, 4–6 July 2018; pp. 311–317. [Google Scholar] [CrossRef]
- Abou El Houda, Z.; Brik, B.; Khoukhi, L. “Why should I trust your ids?”: An explainable deep learning framework for intrusion detection systems in internet of things networks. IEEE Open J. Commun. Soc. 2022, 3, 1164–1176. [Google Scholar] [CrossRef]
- Mane, S.; Rao, D. Explaining network intrusion detection system using explainable AI framework. arXiv 2021, arXiv:2103.07110. [Google Scholar]
- Le TT, H.; Kim, H.; Kang, H.; Kim, H. Classification and explanation for intrusion detection system based on ensemble trees and SHAP method. Sensors 2022, 22, 1154. [Google Scholar] [CrossRef]
- Ali, M.; Zhang, J. Explainable Artificial Intelligence Enabled Intrusion Detection in the Internet of Things. In International Symposium on Intelligent Computing and Networking; Springer Nature: Cham, Switzerland, 2024; pp. 403–414. [Google Scholar]
- Sen, R.; Mandal, A.K.; Goswami, S.; Chakraborty, B. A Comparative Study of the Stability of Filter-Based Feature Selection Algorithms. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and T Technology (iCAST), Morioka, Japan, 23–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Cang, S. A Mutual Information Based Feature Selection Algorithm. In Proceedings of the 2011 4th International Conference on Biomedical Engineering and Informatics (BMEI), Shanghai, China, 15–17 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly algorithms for multimodal optimization. In Stochastic Algorithms: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- Fister, I.; Fister Jr, I.; Yang, X.-S.; Brest, J. A comprehensive review of firefly algorithms. Swarm Evol. Comput. 2013, 13, 1–25. [Google Scholar] [CrossRef]
- Badriyah, T.; Syarif, I.; Prakoso DD, L. Feature Selection Implementation on High-Dimensional Data using Firefly Algorithm. In Proceedings of the 2023 Eighth International Conference on Informatics and Computing (ICIC), Manado, Indonesia, 8–9 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Althubiti, S.A.; Jones, E.M.; Roy, K. LSTM for Anomaly-Based Network Intrusion Detection. In Proceedings of the 2018 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, NSW, Australia, 21–23 November 2018. [Google Scholar] [CrossRef]
- Santos, M.R.; Guedes, A.; Sanchez-Gendriz, I. SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis. Mach. Learn. Knowl. Extr. 2024, 6, 316–341. [Google Scholar] [CrossRef]
- Ahmed, S.; Kaiser, M.S.; Hossain, M.S.; Andersson, K. A Comparative Analysis of LIME and SHAP Interpreters with Explainable ML-Based Diabetes Predictions. IEEE Access 2024, 13, 37370–37388. [Google Scholar]
- Mishra, S.; Sturm, B.L.; Dixon, S. Local interpretable model-agnostic explanations for music content analysis. In Proceedings of the 18th ISMIR Conference, Suzhou, China, 23–27 October 2017; Volume 53, pp. 537–543. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Portmann, M. Evaluating standard feature sets towards increased generalisability and explainability of ML-based network intrusion detection. Big Data Res. 2022, 30, 100359. [Google Scholar]
- Alghanam, O.A.; Almobaideen, W.; Saadeh, M.; Adwan, O. An improved PIO feature selection algorithm for IoT network intrusion detection system based on ensemble learning. Expert Syst. Appl. 2023, 213, 118745. [Google Scholar]
- Mughaid, A.; Alqahtani, A.; AlZu’bi, S.; Obaidat, I.; Alqura’n, R.; AlJamal, M.; AL-Marayah, R. Utilizing machine learning algorithms for effectively detection iot ddos attacks. In International Conference on Advances in Computing Research; Springer Nature: Cham, Switzerland, 2023; pp. 617–629. [Google Scholar]
- Lo, W.W.; Layeghy, S.; Sarhan, M.; Gallagher, M.; Portmann, M. E-graphsage: A graph neural network based intrusion detection system for iot. In Proceedings of the NOMS 2022–2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–9. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. A scheme for generating a dataset for anomalous activity detection in iot networks. In Proceedings of the Canadian Conference on Artificial Intelligence, Ottawa, ON, Canada, 13–15 May 2020; Springe International Publishing: Cham, Switzerland; pp. 508–520. [Google Scholar]
- Ullah, S.; Ahmad, J.; Khan, M.A.; Alkhammash, E.H.; Hadjouni, M.; Ghadi, Y.Y.; Saeed, F.; Pitropakis, N. A new intrusion detection system for the internet of things via deep convolutional neural network and feature engineering. Sensors 2022, 22, 3607. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, R.; Alsmadi, I.; Alhamdani, W.; Tawalbeh, L.A. Zero-day attack detection: A systematic literature review. Artif. Intell. Rev. 2023, 56, 10733–10811. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label name | Value | Train | Test |
|---|---|---|---|
| Label | Normal | 5439 | 1359 |
| Anomaly | 1,505,102 | 376,275 | |
| Anomaly | DDoS | 733,596 | 183,399 |
| DoS | 666,392 | 166,598 | |
| Reconnaissance | 104,959 | 26,240 | |
| Theft | 154 | 39 |
| Label name | Value | Train | Test |
|---|---|---|---|
| Label | Normal | 32,058 | 8015 |
| Anomaly | 468,568 | 117,142 | |
| Anomaly | DoS | 47,513 | 11,878 |
| Mirai | 332,542 | 83,135 | |
| MitM | 28,302 | 7075 | |
| Scan | 60,212 | 15,053 |
| Model | Datasets | Accuracy | Precision | F1-Score | Recall | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Proposed model | NF-BoT-IoT-v2 | 98.42 | 98.43 | 98.42 | 98.42 | 0.27 | 15.98 |
| IoTID20 | 89.54 | 88.78 | 85.85 | 89.54 | 3.37 | 23.15 |
| NF-BoT-IoT-v2 | IoTID20 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTHD | Acc | Prec. | F1-Score | Recall | FPR | FNR | Acc | Prec. | F1-Score | Recall | FPR | FNR |
| All features | 78.98 | 78.97 | 78.97 | 78.98 | 11.38 | 23.51 | 73.99 | 73.99 | 73.99 | 73.99 | 15.79 | 25.59 |
| Proposed | 98.42 | 98.43 | 98.42 | 98.42 | 0.27 | 15.98 | 89.54 | 88.78 | 85.85 | 89.54 | 3.37 | 23.15 |
| NF-BoT-IoT-v2 | IoTID20 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MTHD | Acc | Prec. | F1-Score | Recall | Thres | Acc | Prec. | F1-Score | Recall | Thres |
| SRC | 95.43 | 95.45 | 95.44 | 95.43 | 0.3 | 86.14 | 85.53 | 82.89 | 86.14 | 0.3 |
| MI | 94.91 | 94.91 | 94.85 | 94.91 | 0.2 | 86.14 | 84.92 | 83.44 | 86.14 | 0.2 |
| Firefly | 97.47 | 97.48 | 97.47 | 97.47 | 12 | 87.58 | 86.61 | 83.45 | 87.58 | 12 |
| Proposed | 98.07 | 98.13 | 98.08 | 98.07 | - | 88.73 | 82.20 | 84.07 | 88.73 | - |
| Dataset | Model & Ref. | Accuracy (%) | Precision (%) | F1-Score (%) | Recall (%) |
|---|---|---|---|---|---|
| NF-BoT-IoT-v2 | LS-PIO [40] | 97.3 | - | 94.4 | - |
| RF [41] | 98.96 | 84.80 | 89.20 | 90.20 | |
| E-GraphSAGE [42] | 93.57 | 100 | 97 | 93.43 | |
| Proposed model | 98.42 | 98.43 | 98.42 | 98.42 | |
| IoTID20 | Ensemble [43] | 87 | 87 | 87 | 87 |
| DCNN [44] | 77.55 | 78.76 | 73.43 | 76 | |
| Proposed model | 89.54 | 88.78 | 85.85 | 89.54 |
| NF-BoT-IoT-v2 | IoTID20 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTHD | Acc | Prec. | F1-Score | Recall | FPR | FNR | Acc | Prec. | F1-Score | Recall | FPR | FNR |
| SRC + Firefly | 97.16 | 97.16 | 97.16 | 97.16 | 0.38 | 21.51 | 85.27 | 76.34 | 80.25 | 85.27 | 6.79 | 45.59 |
| MI + Firefly | 97.99 | 98.02 | 97.99 | 97.99 | 0.36 | 17.47 | 85.38 | 84.14 | 80.46 | 85.38 | 6.67 | 44.98 |
| SRC + MI | 98.01 | 97.99 | 97.99 | 98.01 | 0.46 | 13.83 | 87.76 | 86.25 | 87.87 | 87.76 | 4.62 | 33.5 |
| Proposed | 98.42 | 98.43 | 98.42 | 98.42 | 0.27 | 15.98 | 89.54 | 88.78 | 85.85 | 89.54 | 3.37 | 23.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ogunseyi, T.B.; Thiyagarajan, G. An Explainable LSTM-Based Intrusion Detection System Optimized by Firefly Algorithm for IoT Networks. Sensors 2025, 25, 2288. https://doi.org/10.3390/s25072288
Ogunseyi TB, Thiyagarajan G. An Explainable LSTM-Based Intrusion Detection System Optimized by Firefly Algorithm for IoT Networks. Sensors. 2025; 25(7):2288. https://doi.org/10.3390/s25072288
Chicago/Turabian StyleOgunseyi, Taiwo Blessing, and Gogulakrishan Thiyagarajan. 2025. "An Explainable LSTM-Based Intrusion Detection System Optimized by Firefly Algorithm for IoT Networks" Sensors 25, no. 7: 2288. https://doi.org/10.3390/s25072288
APA StyleOgunseyi, T. B., & Thiyagarajan, G. (2025). An Explainable LSTM-Based Intrusion Detection System Optimized by Firefly Algorithm for IoT Networks. Sensors, 25(7), 2288. https://doi.org/10.3390/s25072288