
MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network

 , , , ,
, , , , 
Abstract
1. Introduction
- (1)
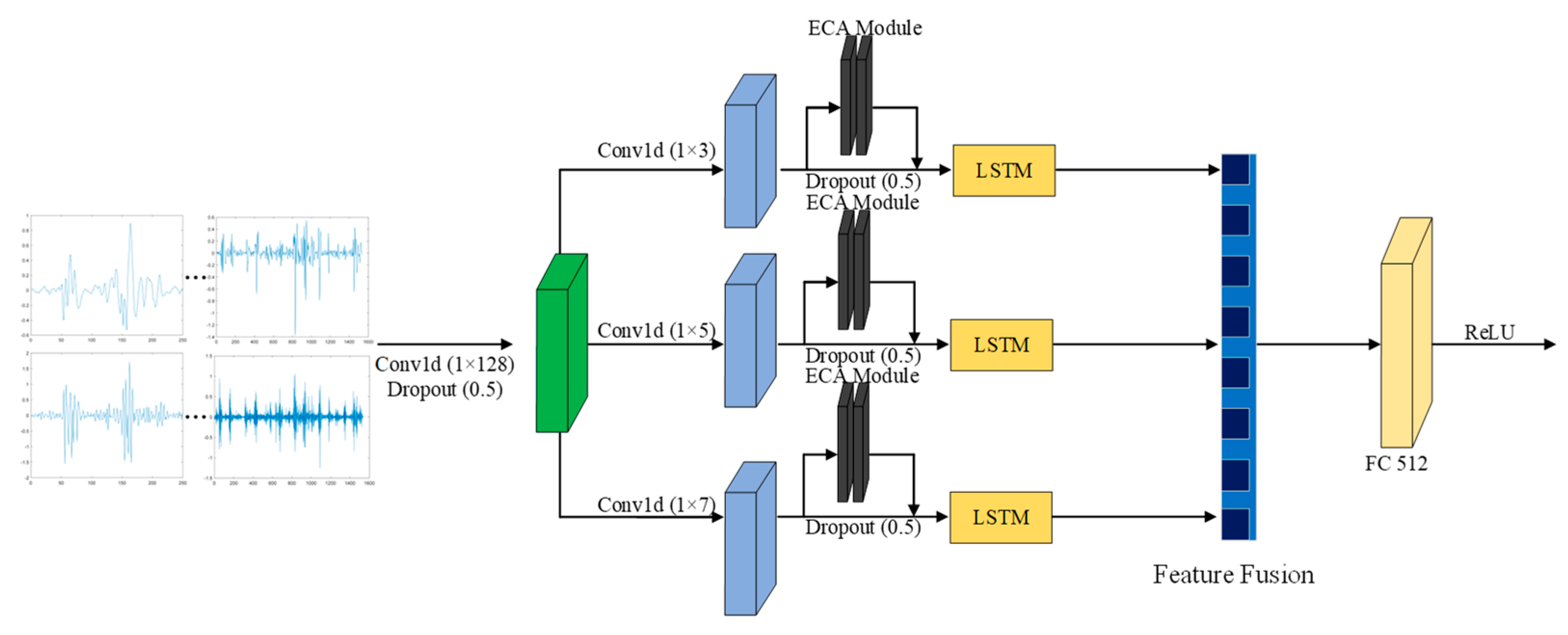
- A multi-scale parallel sub-network design is used to capture both short-range and long-range dependencies in radar signals, enabling the model to learn richer feature representations at multiple scales.
- (2)
- The cross-space learning method is employed to fuse the outputs of parallel sub-networks, effectively capturing the pairwise relationships at the sample level of radar spectrograms following PCA dimensionality reduction. This approach enhances the representation of global contextual information within the spectrogram and improves the aggregation of relevant features.
- (3)
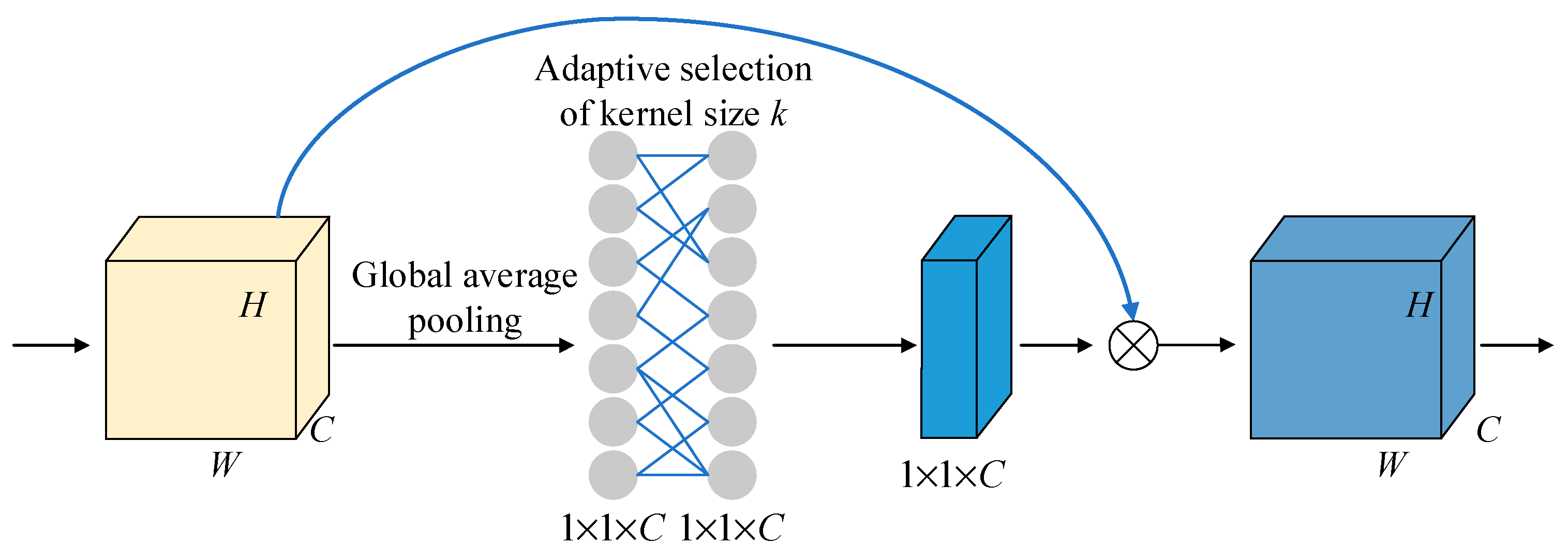
- Combined with the LSTM and ECA mechanism, it significantly enhances the performance of driving behavior detection while requiring fewer parameters. This reduction in computational complexity offers an effective solution for deploying miniaturized devices within vehicles.
- (4)
- This method is validated on real-world driving scenarios for the recognition of driver behavior, achieving a recognition accuracy of 97.3%. It can also be integrated into a miniaturized device, referred to as the MCCT Device.
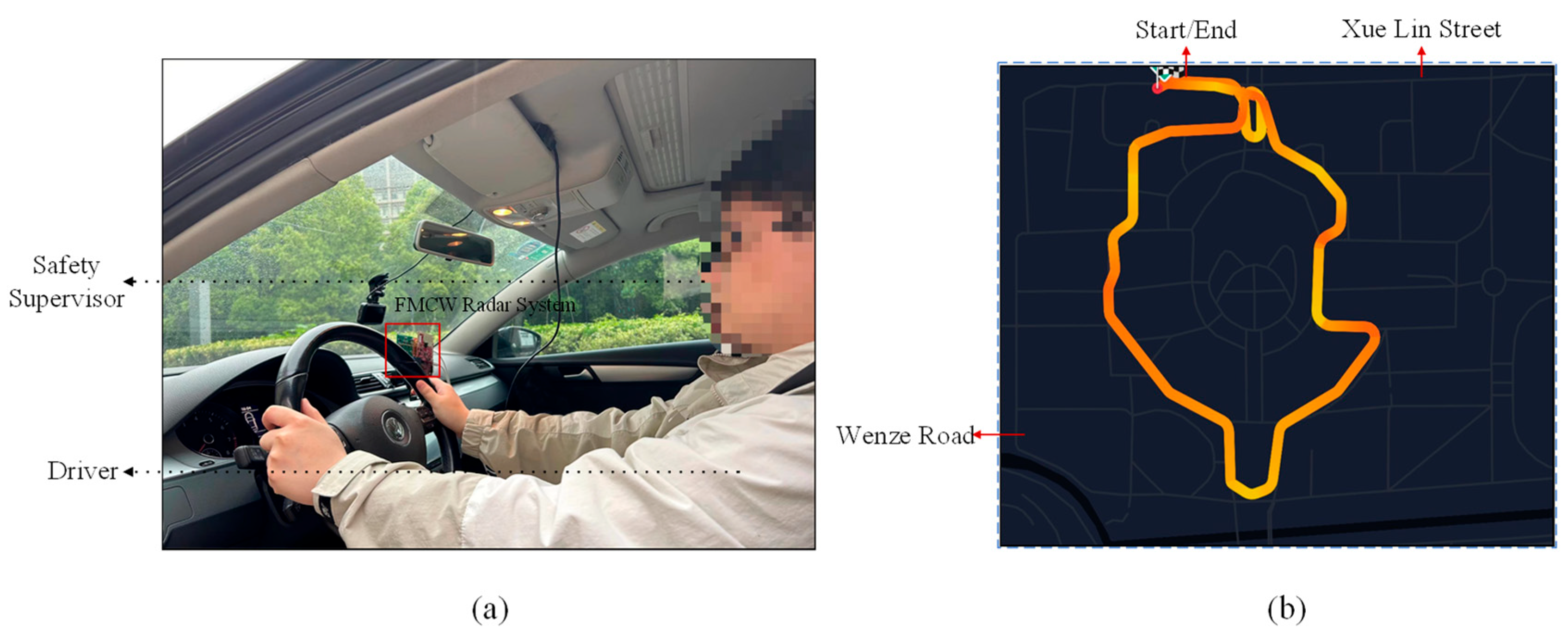
2. Measurement Setup
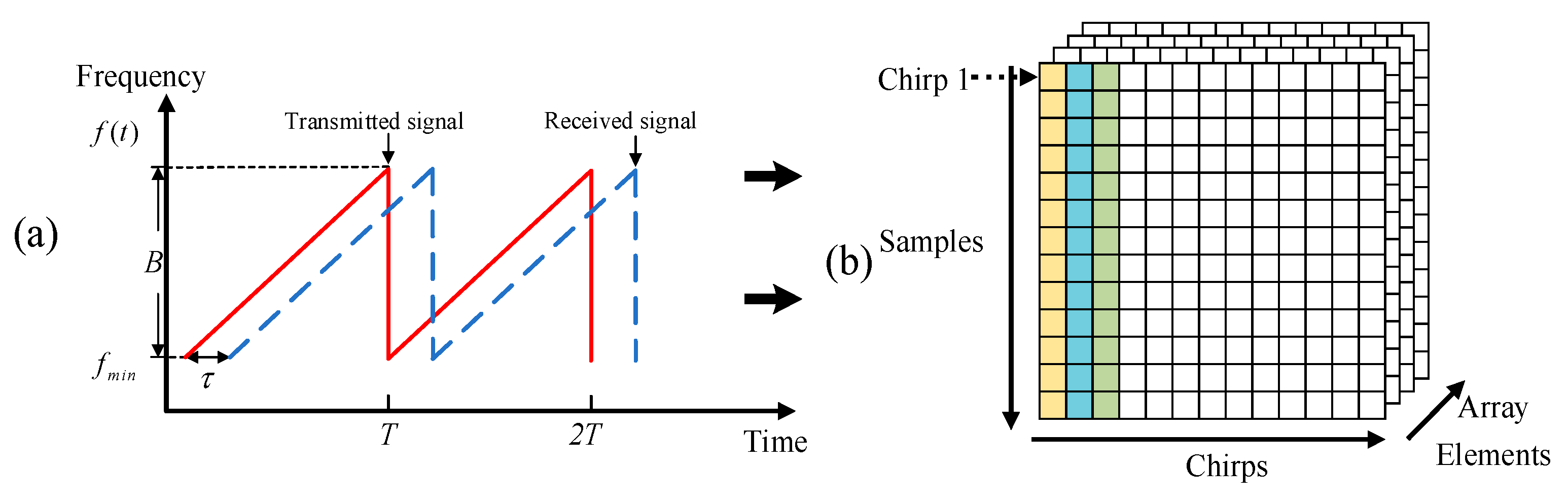
2.1. Miniaturized FMCW Radar System
2.2. Principle of FMCW Radar Transmission and Reception
3. Proposed Method
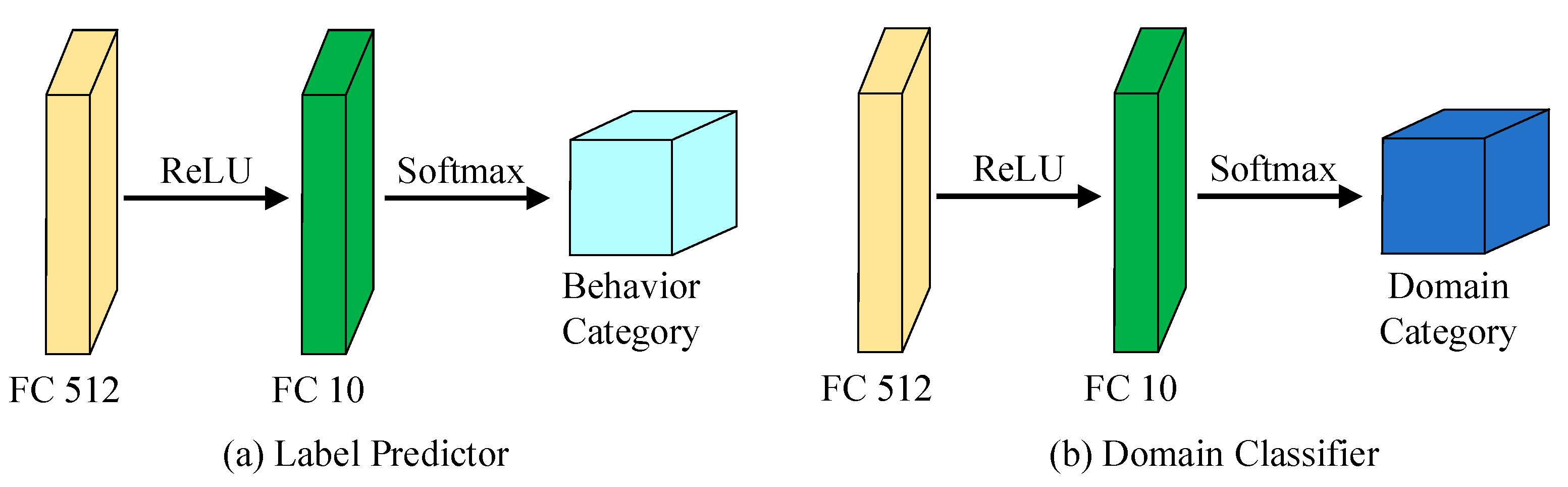
3.1. MCT-CNN-LSTM Method
3.2. Feature Extraction Module
3.3. Parameter Update of MCT-CNN-LSTM
4. Experiments
4.1. Experimental Details
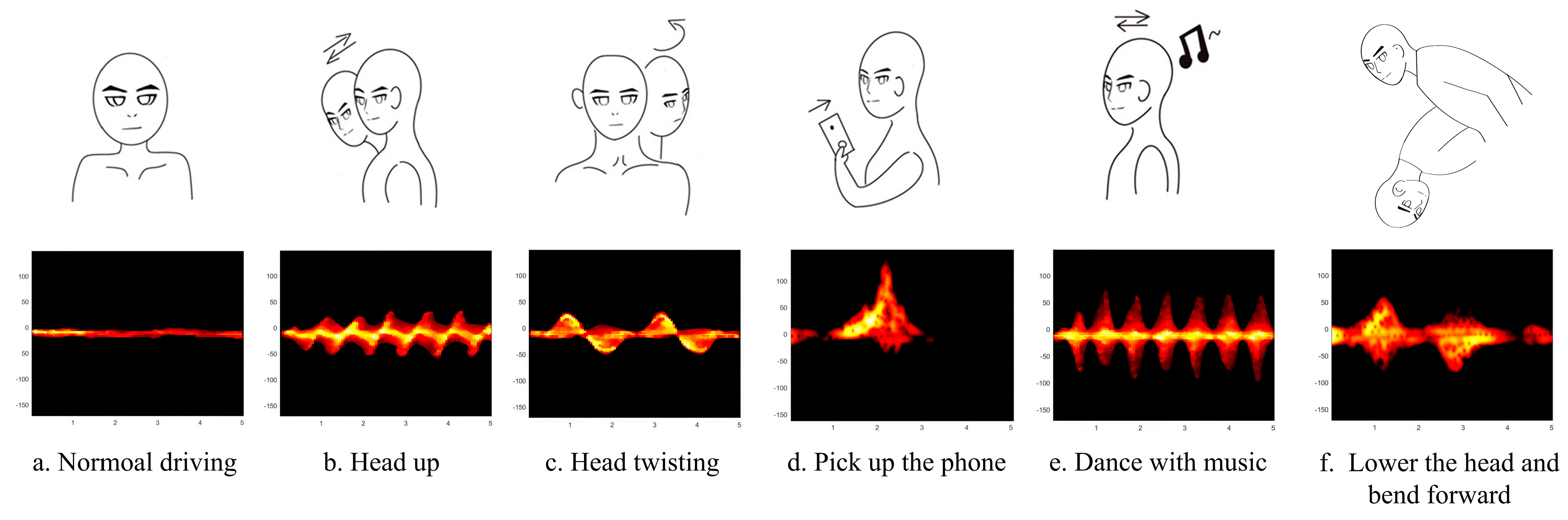
4.2. Datasets
4.3. Details of Training and Testing
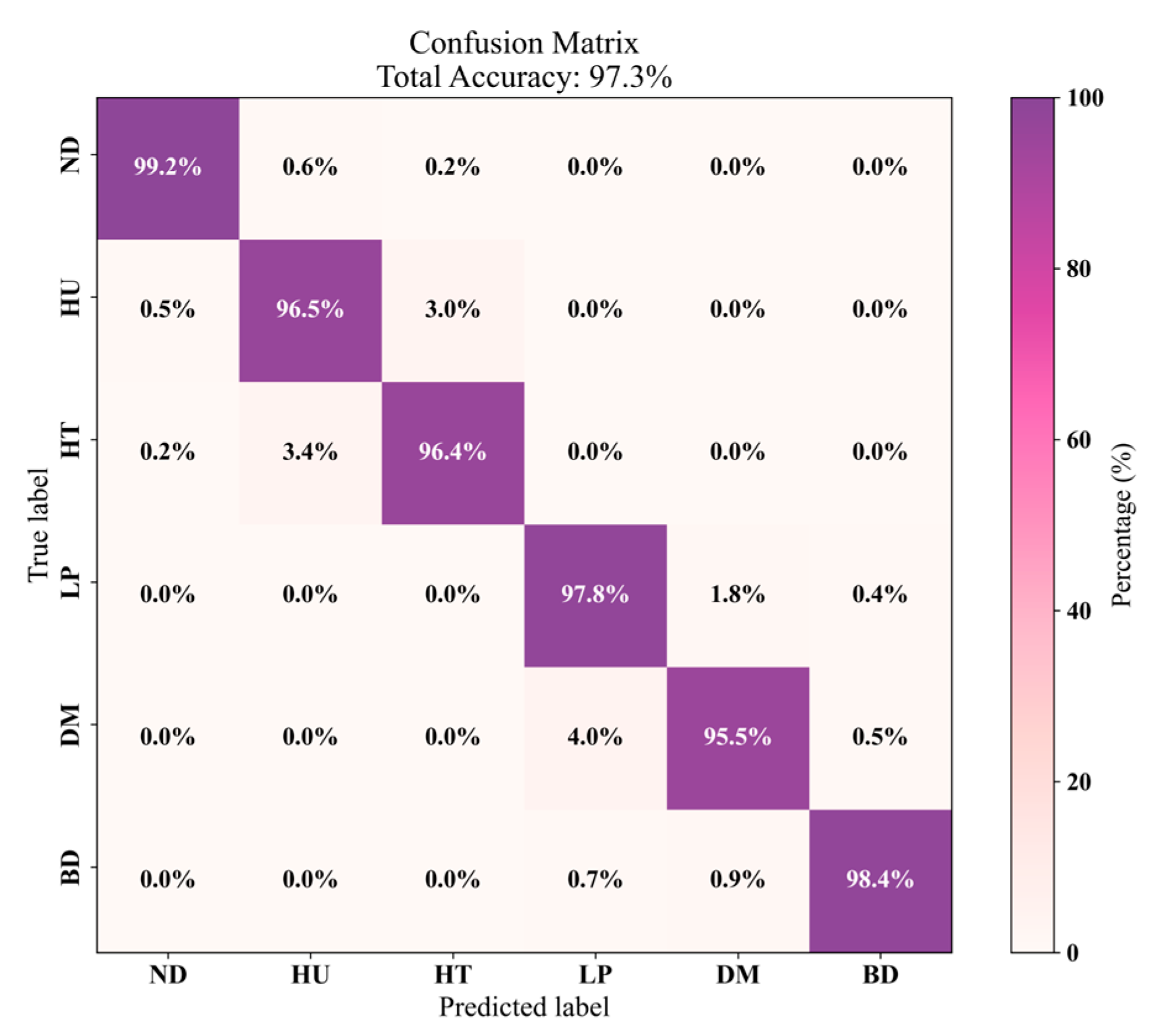
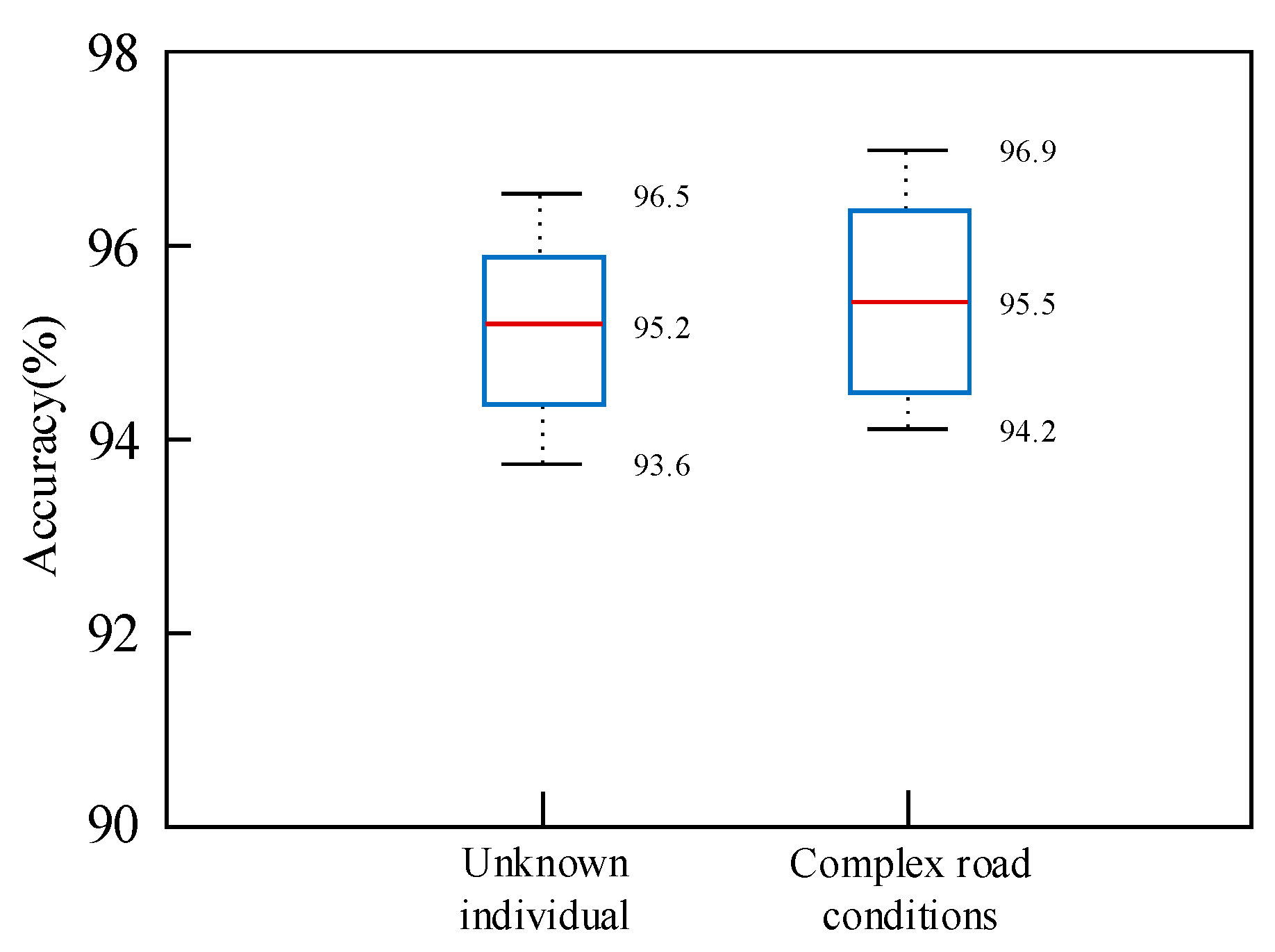
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety. Available online: https://www.who.int/teams/social-determinants-of-health/safety-and-mobility/global-status-report-on-road-safety-2023 (accessed on 13 December 2023).
- McCarty, D.; Kim, H.W. Risky Behaviors and Road Safety: An Exploration of Age and Gender Influences on Road Accident Rates. PLoS ONE 2024, 19, e0296663. [Google Scholar] [CrossRef] [PubMed]
- Lacherre, J.; Castillo-Sequera, J.L.; Mauricio, D. Factors, Prediction, and Explainability of Vehicle Accident Risk Due to Driving Behavior Through Machine Learning: A Systematic Literature Review, 2013–2023. Computation 2024, 12, 131. [Google Scholar] [CrossRef]
- He, C.; Xu, P.; Pei, X.; Wang, Q.; Yue, Y.; Han, C. Fatigue at the Wheel: A Non-Visual Approach to Truck Driver Fatigue Detection by Multi-Feature Fusion. Accid. Anal. Prev. 2024, 199, 107511. [Google Scholar] [CrossRef]
- Boboc, R.G.; Butilă, E.V.; Butnariu, S. Leveraging Wearable Sensors in Virtual Reality Driving Simulators: A Review of Techniques and Applications. Sensors 2024, 24, 4417. [Google Scholar] [CrossRef]
- Gao, H.; Hu, M.; Liu, Y. Learning Driver-Irrelevant Features for Generalizable Driver Behavior Recognition. IEEE Trans. Intell. Transp. Syst. 2024, 25, 14115–14127. [Google Scholar] [CrossRef]
- Gu, M.; Chen, K.; Chen, Z. RFDANet: An FMCW and TOF Radar Fusion Approach for Driver Activity Recognition Using Multi-Level Attention Based CNN and LSTM Network. Complex Intell. Syst. 2024, 10, 1517–1530. [Google Scholar] [CrossRef]
- Kanwal, K.; Rustam, F.; Chaganti, R.; Jurcut, A.D.; Ashraf, I. Smartphone Inertial Measurement Unit Data Features for Analyzing Driver Driving Behavior. IEEE Sens. J. 2023, 23, 11308–11323. [Google Scholar] [CrossRef]
- Zou, Y.; Ding, L.; Zhang, H.; Zhu, T.; Wu, L. Vehicle Acceleration Prediction Based on Machine Learning Models and Driving Behavior Analysis. Appl. Sci. 2022, 12, 5259. [Google Scholar] [CrossRef]
- Doniec, R.; Konior, J.; Siecinski, S.; Piet, A.; Irshad, M.T.; Piaseczna, N.; Hasan, M.A.; Li, F.; Nisar, M.A.; Grzegorzek, M. Sensor-Based Classification of Primary and Secondary Car Driver Activities Using Convolutional Neural Networks. Sensors 2023, 23, 5551. [Google Scholar] [CrossRef]
- Yang, L.; Ma, R.; Zhang, M.; Guan, W.; Jiang, S. Driving Behavior Recognition Using EEG Data from a Simulated Car-Following Experiment. Accid. Anal. Prev. 2018, 116, 30–40. [Google Scholar] [CrossRef]
- Hasan, M.Z.; Chen, J.; Wang, J.; Rahman, M.S.; Joshi, A.; Velipasalar, S.; Hegde, C.; Sharma, A.; Sarkar, S. Vision-Language Models Can Identify Distracted Driver Behavior from Naturalistic Videos. IEEE Trans. Intell. Transp. Syst. 2024, 25, 11602–11616. [Google Scholar] [CrossRef]
- Wang, L.; Song, F.; Zhou, T.H.; Hao, J.; Ryu, K.H. EEG and ECG-Based Multi-Sensor Fusion Computing for Real-Time Fatigue Driving Recognition Based on Feedback Mechanism. Sensors 2023, 23, 8386. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Yao, H.; Qiao, F.; Ma, Y.; Wu, Y.; Lu, J. Vehicles Driving Behavior Recognition Based on Transfer Learning. Expert Syst. Appl. 2023, 213, 119254. [Google Scholar] [CrossRef]
- Tang, G.; Wu, T.; Li, C. Dynamic Gesture Recognition Based on FMCW Millimeter Wave Radar: Review of Methodologies and Results. Sensors 2023, 23, 7478. [Google Scholar] [CrossRef]
- Gharamohammadi, A.; Khajepour, A.; Shaker, G. In-Vehicle Monitoring by Radar: A Review. IEEE Sens. J. 2023, 23, 25650–25672. [Google Scholar] [CrossRef]
- Fang, Z.; Jian, P.; Zhang, H.; Yao, Y.; Geng, F.; Liu, C.; Yan, B.; Wang, P.; Du, L.; Chen, X. Review of Noncontact Medical and Health Monitoring Technologies Based on FMCW Radar. J. Radars 2022, 11, 499–516. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D.; Fu, Y.; Yao, D.; Xie, L.; Zhou, M. Multi-Hand Gesture Recognition Using Automotive FMCW Radar Sensor. Remote Sens. 2022, 14, 2374. [Google Scholar] [CrossRef]
- Hao, Z.; Wang, R.; Peng, J.; Dang, X. Static Hand Gesture Recognition Based on Millimeter-Wave Near-Field FMCW-SAR Imaging. Electronics 2023, 12, 4013. [Google Scholar] [CrossRef]
- Raeis, H.; Kazemi, M.; Shirmohammadi, S. CAE-MAS: Convolutional Autoencoder Interference Cancellation for Multiperson Activity Sensing with FMCW Microwave Radar. IEEE Trans. Instrum. Meas. 2024, 73, 8001710. [Google Scholar] [CrossRef]
- Faisal, K.N.; Mir, H.S.; Sharma, R.R. Human Activity Recognition from FMCW Radar Signals Utilizing Cross-Terms Free WVD. IEEE Internet Things J. 2024, 11, 14383–14394. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, H.; Liu, C.; Geng, F.; Wang, P.; Du, L.; Chen, X.; Han, B.; Yang, T.; Fang, Z. Unsupervised-Learning-Based Unobtrusive Fall Detection Using FMCW Radar. IEEE Internet Things J. 2024, 11, 5078–5089. [Google Scholar] [CrossRef]
- Ma, L.; Li, X.; Liu, G.; Cai, Y. Fall Direction Detection in Motion State Based on the FMCW Radar. Sensors 2023, 23, 5031. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Liu, B.; Kernec, J.L.; Yang, S. A Holistic Human Activity Recognition Optimisation Using AI Techniques. IET Radar Sonar Navig. 2024, 18, 256–265. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Torres-Ruiz, M.; Arya, V.; Alhalabi, W.; Zamzami, I.F. A Convolutional Neural Network-Based Feature Extraction and Weighted Twin Support Vector Machine Algorithm for Context-Aware Human Activity Recognition. Electronics 2023, 12, 1915. [Google Scholar] [CrossRef]
- Waghumbare, A.; Singh, U. Diat-Separable-CNN-ECA-Harnet: A Lightweight and Explainable Model for Efficient Human Activity Recognition. Signal Image Video Process. 2025, 19, 245. [Google Scholar] [CrossRef]
- Mehta, R.; Sharifzadeh, S.; Palade, V.; Tan, B.; Daneshkhah, A.; Karayaneva, Y. Deep Learning Techniques for Radar-Based Continuous Human Activity Recognition. Mach. Learn. Knowl. Extr. 2023, 5, 1493–1518. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Gender | Age | ND | HU | HT | LP | DM | BD |
|---|---|---|---|---|---|---|---|---|
| 1 | Male | 26 | 199 | 195 | 195 | 195 | 195 | 200 |
| 2 | Male | 46 | 99 | 100 | 105 | 105 | 100 | 100 |
| 3 | Male | 29 | 102 | 105 | 100 | 100 | 105 | 100 |
| 4 | Female | 32 | 201 | 200 | 140 | 160 | 200 | 180 |
| 5 | Male | 22 | 199 | 200 | 220 | 230 | 200 | 210 |
| 6 | Female | 23 | 200 | 200 | 240 | 210 | 200 | 210 |
| Models | (a) ND | (b) HU | (c) HT | (d) LP | (e) DM | (f) BD | Avg |
|---|---|---|---|---|---|---|---|
| AlexNet | 84.5% | 79.5% | 80.2% | 80.7% | 71.4% | 72.6% | 78.2% |
| 1-D CNN | 97.0% | 82.4% | 81.7% | 83.7% | 73.2% | 76.1% | 82.4% |
| DANN | 97.5% | 83.1% | 81.9% | 84.2% | 78.6% | 80.3% | 84.3% |
| CNN-ECA | 97.3% | 81.6% | 82.4% | 84.5% | 79.8% | 78.2% | 84.0% |
| CNN-LSTM | 98.0% | 84.4% | 82.6% | 84.2% | 82.9% | 82.5% | 85.8% |
| CNN-LSTM-ECA | 98.4% | 96.6%* | 96.2% | 86.5% | 84.5% | 85.1% | 91.2% |
| CNN-Channel Attention | 99.0% | 85.2% | 87.1% | 90.4% | 88.3% | 89.6% | 89.9% |
| RFDANet | 99.0% | 92.8% | 92.6% | 97.4% | 90.8% | 93.2% | 94.3% |
| MCT-CNN-LSTM | 99.2% * | 96.5% | 96.4% * | 97.8% * | 95.5% * | 98.4% * | 97.3% * |
| Models | Params (M) | FLOPs (G) | Size (MB) | Speed (ms) | Acc./Speed |
|---|---|---|---|---|---|
| AlexNet | 18.3 | 1.5 | 58.4 | 42 | 1.9 |
| 1-D CNN | 5.5 | 0.4 * | 8.9* | 20.5 * | 4.0 |
| DANN | 3.4 | 0.6 | 5.6 | 25.9 | 3.3 |
| CNN-ECA | 5.8 | 0.5 | 9.4 | 21.5 | 3.9 |
| CNN-LSTM | 6.5 | 0.4 * | 26.2 | 24.4 | 3.5 |
| CNN-LSTM-ECA | 10.3 | 0.5 | 25.9 | 26.7 | 3.4 |
| CNN-Channel Attention | 7.8 | 0.7 | 25.3 | 25.6 | 3.5 |
| RFDANet | 8.3 | 1.3 | 21.1 | 31.2 | 3.0 |
| MCT-CNN-LSTM | 5.1 * | 0.6 | 28.3 | 23.1 | 4.2 * |
| ID | Age | TND | THU | THT | TLP | TDM | TBD |
|---|---|---|---|---|---|---|---|
| Tester-1 | 22 | 100 | 100 | 100 | 100 | 99 | 100 |
| Tester-2 | 41 | 100 | 100 | 98 | 100 | 97 | 100 |
| Tester-3 | 27 | 100 | 100 | 99 | 100 | 98 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Diao, Y.; Wang, Y.; Zhang, X.; Zhou, Y.; Gu, M.; Zhang, B.; Hu, B.; Li, M.; Li, W.; et al. MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network. Sensors 2025, 25, 2268. https://doi.org/10.3390/s25072268
Chen K, Diao Y, Wang Y, Zhang X, Zhou Y, Gu M, Zhang B, Hu B, Li M, Li W, et al. MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network. Sensors. 2025; 25(7):2268. https://doi.org/10.3390/s25072268
Chicago/Turabian StyleChen, Kaiyu, Yue Diao, Yucheng Wang, Xiafeng Zhang, Yannian Zhou, Minming Gu, Bo Zhang, Bin Hu, Meng Li, Wei Li, and et al. 2025. "MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network" Sensors 25, no. 7: 2268. https://doi.org/10.3390/s25072268
APA StyleChen, K., Diao, Y., Wang, Y., Zhang, X., Zhou, Y., Gu, M., Zhang, B., Hu, B., Li, M., Li, W., & Wang, S. (2025). MCT-CNN-LSTM: A Driver Behavior Wireless Perception Method Based on an Improved Multi-Scale Domain-Adversarial Neural Network. Sensors, 25(7), 2268. https://doi.org/10.3390/s25072268