


DCN-YOLO: A Small-Object Detection Paradigm for Remote Sensing Imagery Leveraging Dilated Convolutional Networks



Abstract
1. Introduction
2. Method
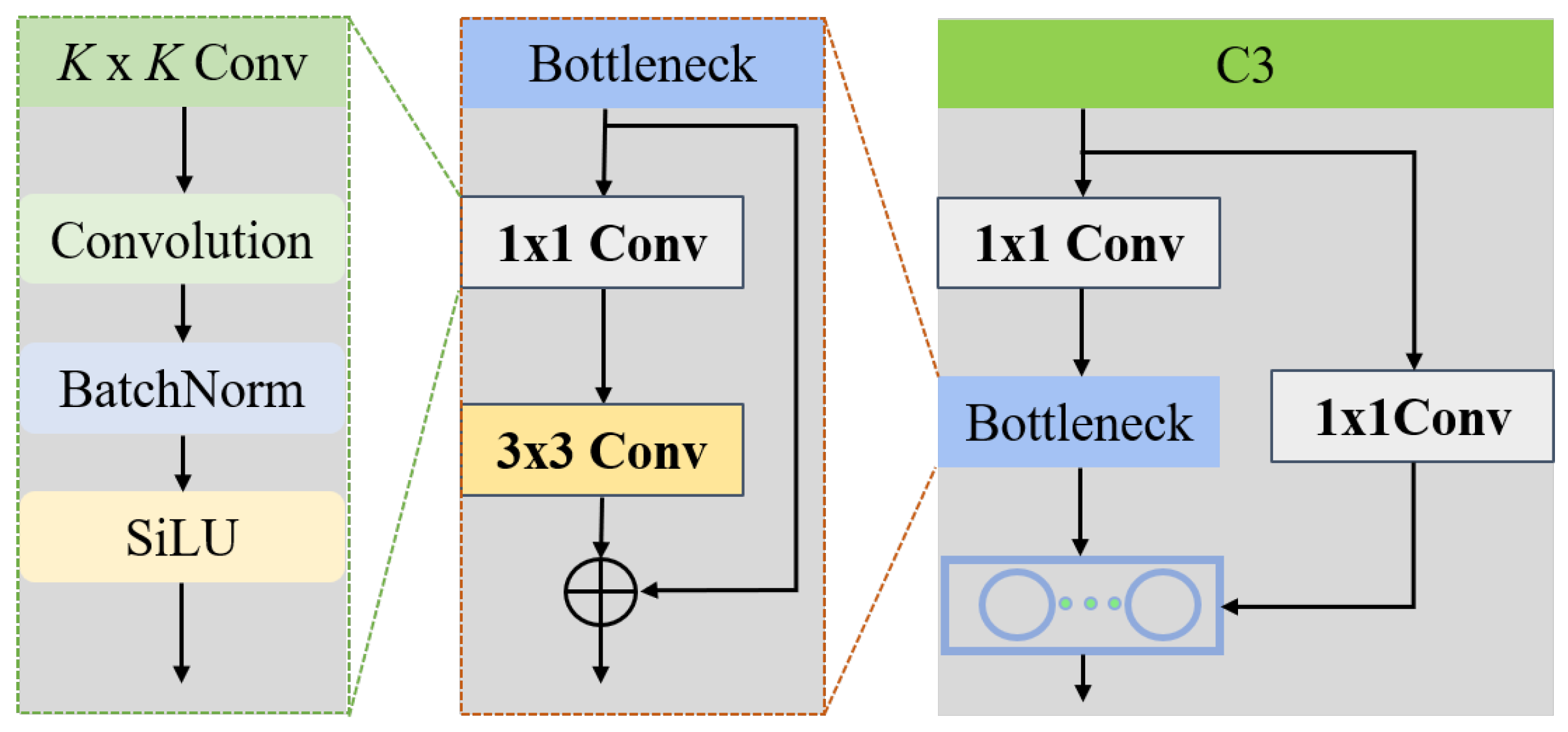
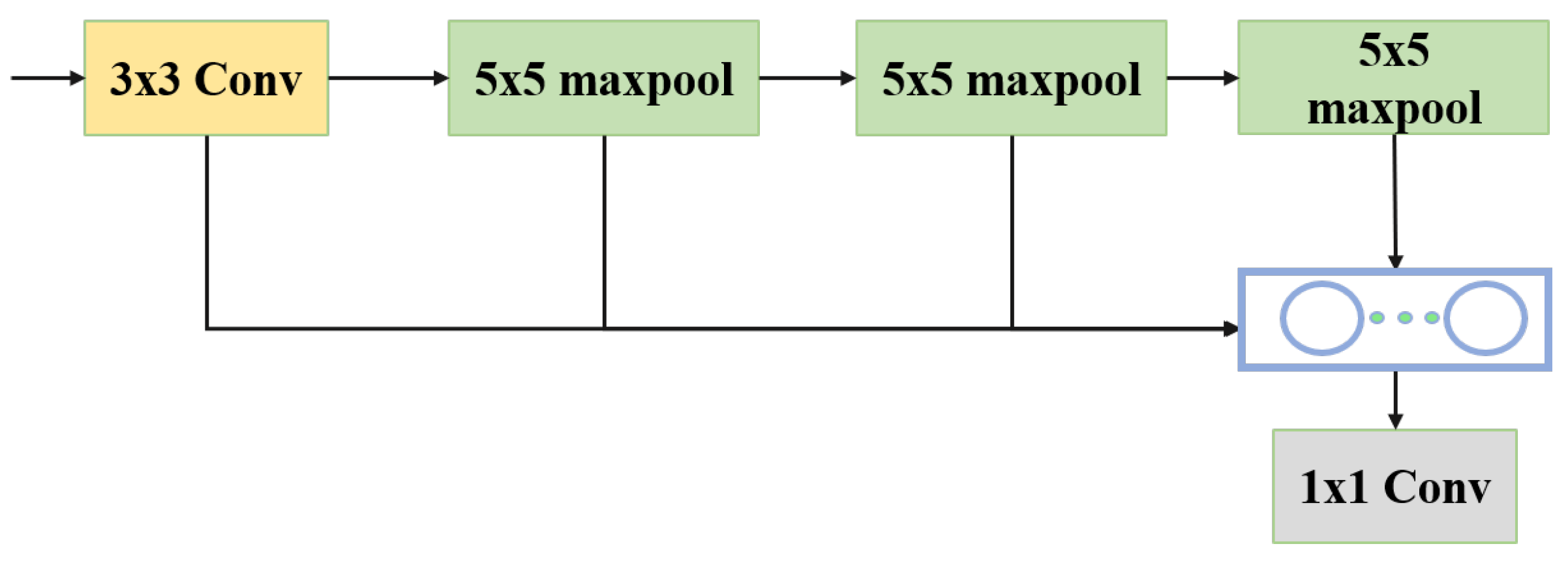
2.1. YOLOv5
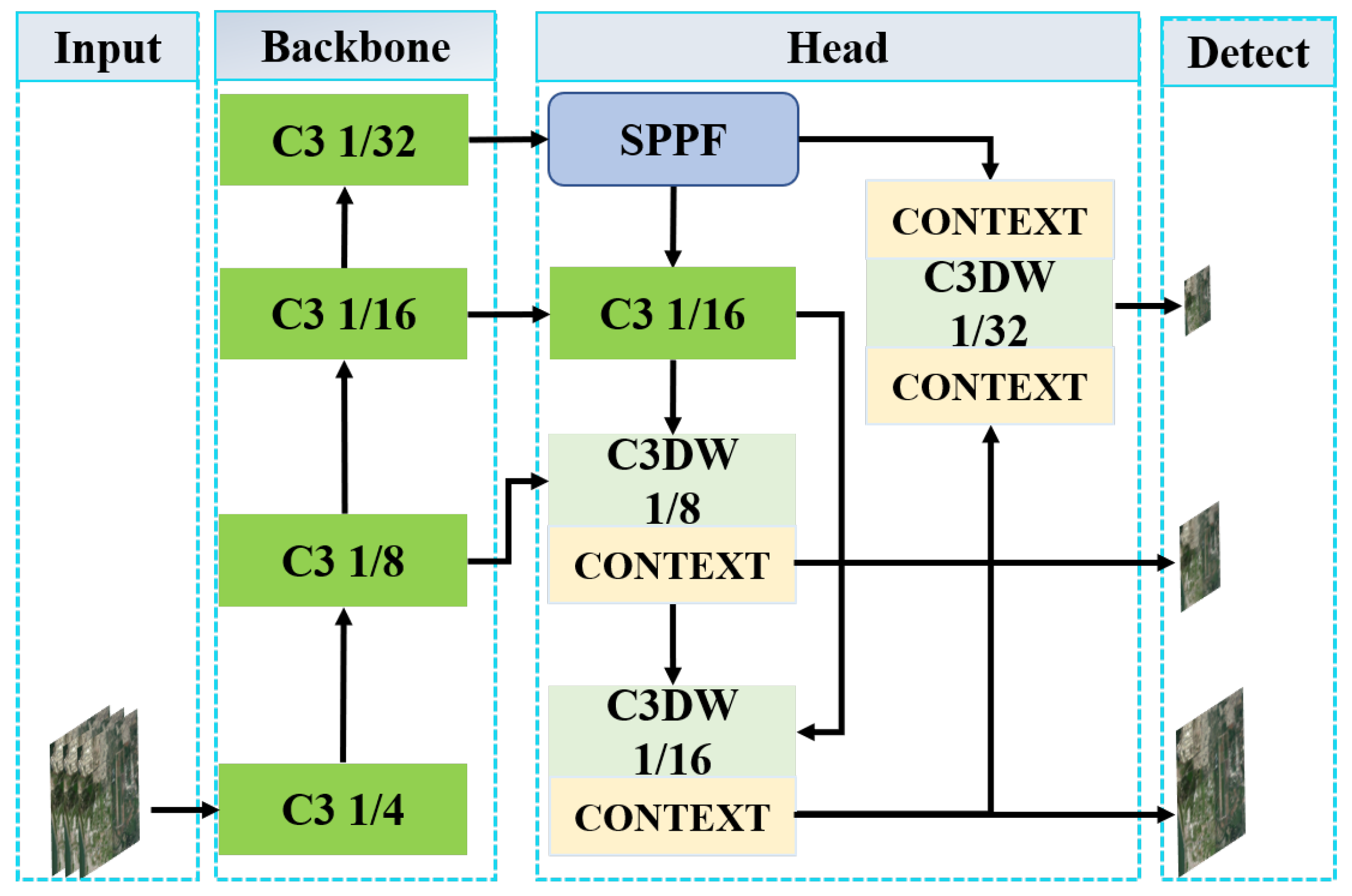
2.2. DCN-YOLO
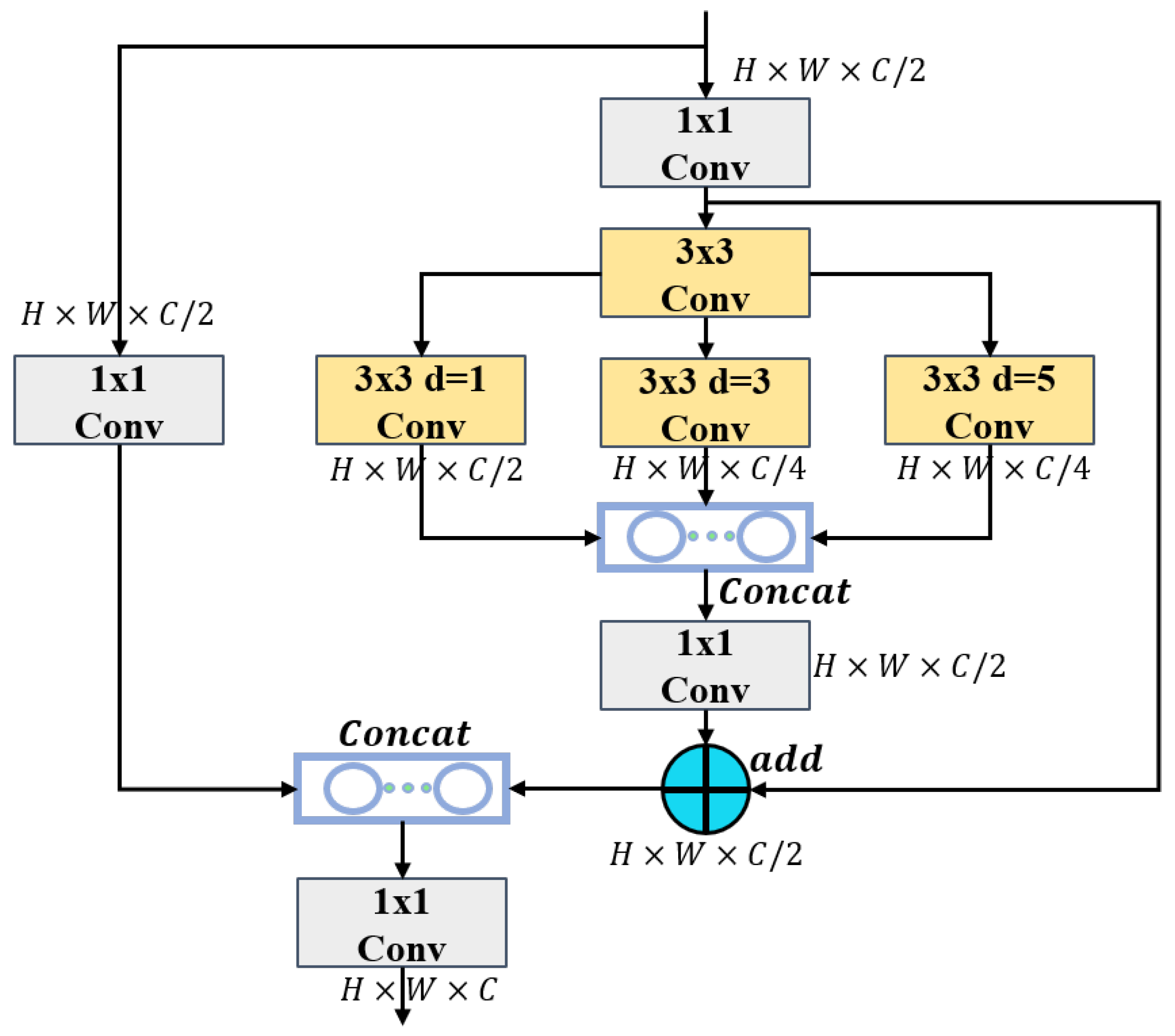
2.3. The Dilated Convolutional Residual (DCR) Module
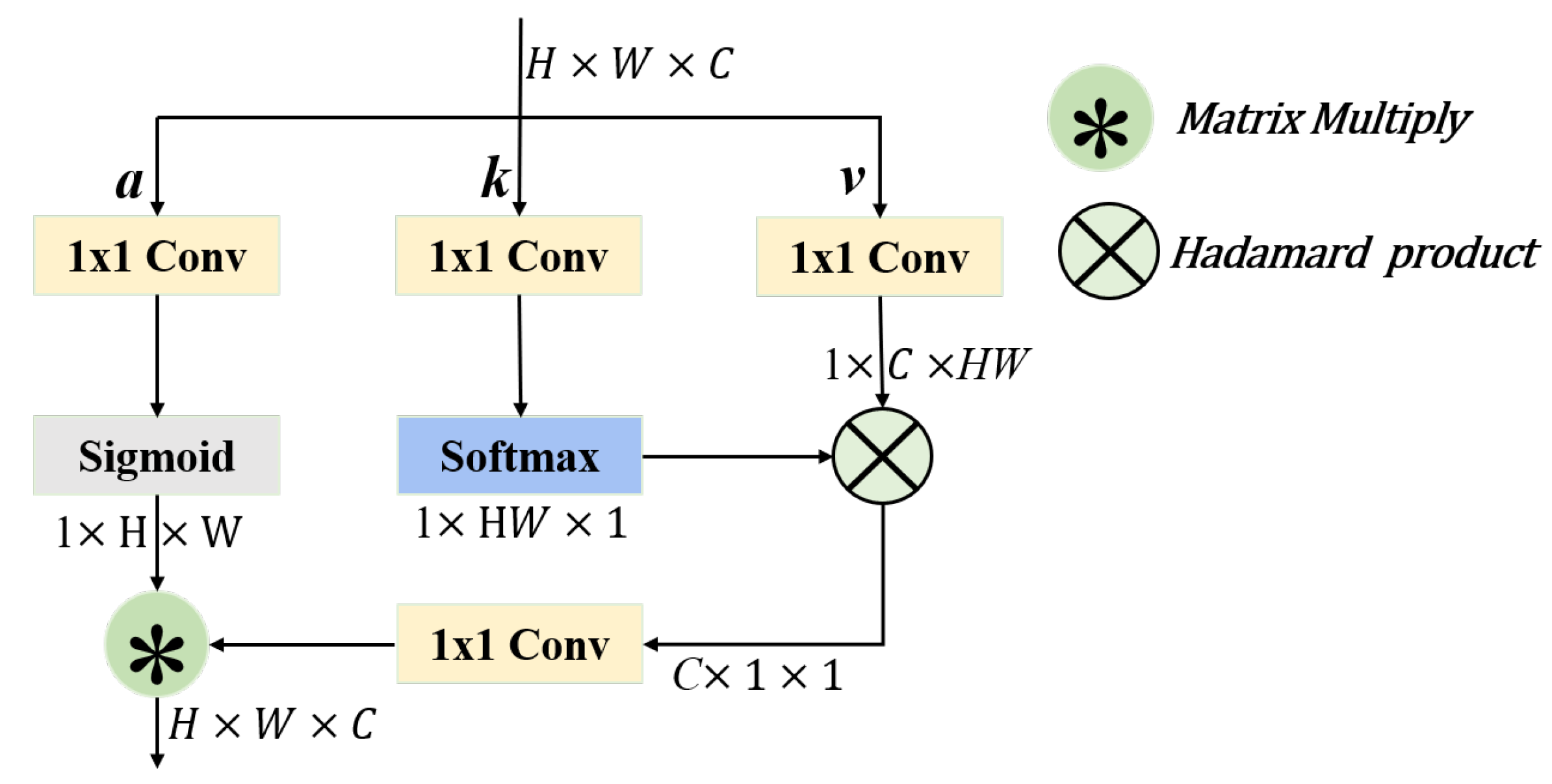
2.4. The Context Aggregation Module (CONTEXT)
2.5. Loss Function
3. Experiments
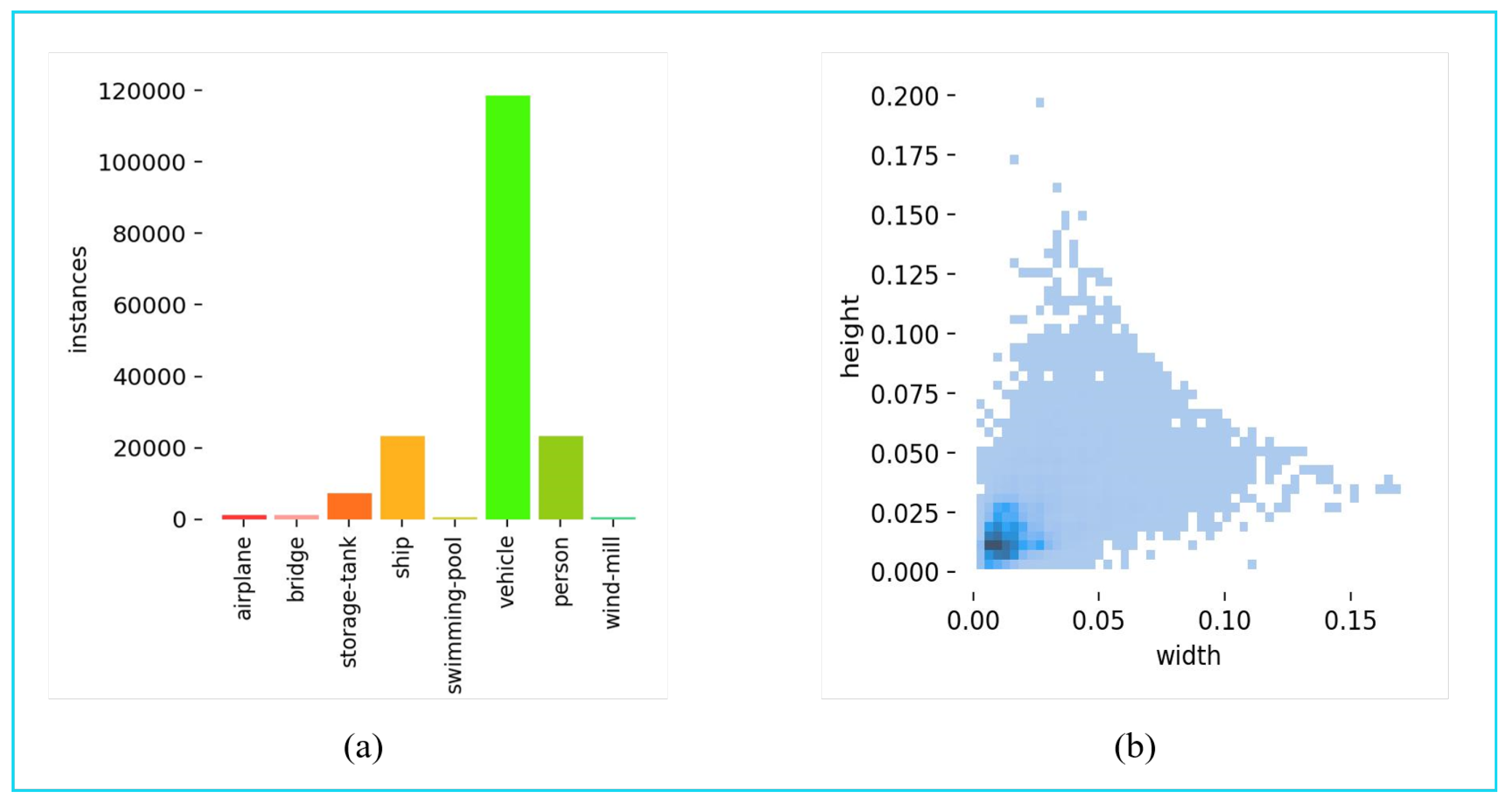
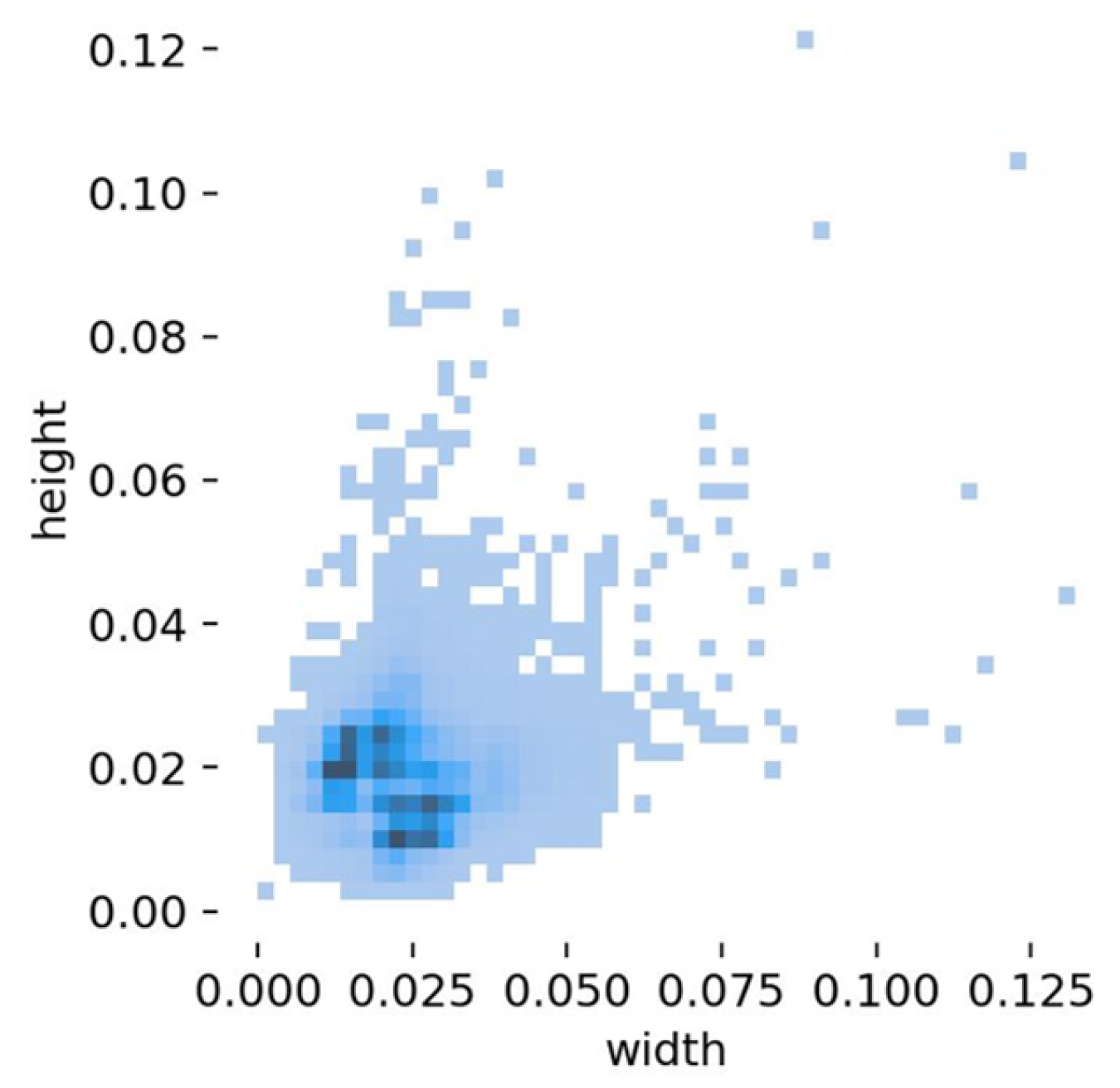
3.1. Experimental Dataset Description
3.1.1. Tiny Object Detection in Aerial Images (AI-TOD) Dataset
3.1.2. Unicorn Small Object (USOD) Dataset
3.2. Experimental Configuration and Parameter Settings
3.3. Experimental Analysis
3.3.1. Ablation Study
3.3.2. Comparative Analysis by Categories
3.3.3. DCN-YOLO Analysis on AI-TOD
3.3.4. DCN-YOLO Analysis on USOD
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Mahendrakar, T.; White, R.T.; Wilde, M.; Kish, B.; Silver, I. Real-time satellite component recognition with YOLO-V5. In Proceedings of the Small Satellite Conference, Virtual, 26–27 April 2021. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote sensing image super-resolution and object detection: Benchmark and state of the art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar]
- Wang, L.; Yin, S.; Alyami, H.; Laghari, A.A.; Rashid, M.; Almotiri, J.; Alyamani, H.J.; Alturise, F. A novel deep learning-based single shot multibox detector model for object detection in optical remote sensing images. Geosci. Data J. 2024, 11, 237–251. [Google Scholar]
- Sharifuzzaman Sagar, A.S.M.; Chen, Y.; Xie, Y.; Kim, H.S. MSA R-CNN: A comprehensive approach to remote sensing object detection and scene understanding. Expert Syst. Appl. 2024, 241, 122788. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16794–16805. [Google Scholar]
- Gao, T.; Niu, Q.; Zhang, J.; Chen, T.; Mei, S.; Jubair, A. Global to local: A scale-aware network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615614. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S. A new spatial-oriented object detection framework for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4407416. [Google Scholar] [CrossRef]
- Lu, X.; Ji, J.; Xing, Z.; Miao, Q. Attention and feature fusion SSD for remote sensing object detection. IEEE Trans. Instrum. Meas. 2021, 70, 5501309. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature split–merge–enhancement network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616217. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive balanced network for multiscale object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5614914. [Google Scholar] [CrossRef]
- Liu, H.-I.; Tseng, Y.; Chang, K.; Wang, P.; Shuai, H.; Cheng, W. A denoising fpn with transformer r-cnn for tiny object detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704415. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G. RFLA: Gaussian receptive field based label assignment for tiny object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 526–543. [Google Scholar]
- Shi, Z.; Hu, J.; Ren, J.; Ye, H.; Yuan, X.; Ouyang, Y.; He, J.; Ji, B.; Guo, J. HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection. arXiv 2024, arXiv:2412.10116. [Google Scholar]
- Shi, S.; Fang, Q.; Xu, X.; Zhao, T. Similarity distance-based label assignment for tiny object detection. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 13711–13718. [Google Scholar]
- Wei, H.; Liu, X.; Xu, S.; Dai, Z.; Dai, Y.; Xu, X. DWRSeg: Rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation. arXiv 2022, arXiv:2212.01173. [Google Scholar]
- Lu, J.; Mottaghi, R.; Kembhavi, A. Container: Context aggregation networks. Adv. Neural Inf. Process. Syst. 2021, 34, 19160–19171. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G. Tiny object detection in aerial images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 9–23 September 2022; Springer Nature: Cham, Switzerland, 2022; pp. 443–459. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Tian, Z.; Chu, X.; Wang, X.; Wei, X.; Shen, C. Fully convolutional one-stage 3d object detection on lidar range images. Adv. Neural Inf. Process. Syst. 2022, 35, 34899–34911. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ross, T.-Y.; Dollár, G.K.H.P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Qiao, S.; Chen, L.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Duan, X.; Li, Z.; Zhang, J.; Li, S.; Lei, J.; Zhan, L. Weighted Learnable Recursive Aggregation Network for Visible Remote Sensing Image Detection. IEEE Trans. Geosci. Remote Sens. 2025; early access. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AP | AP50 | |
|---|---|---|
| YOLOv5s | 17.2 | 46.0 |
| v5+CONTEXT | 22.9 | 50.0 |
| v5+DCR | 23.0 | 49.3 |
| DCR+CONTEXT | 23.9 | 56.6 |
| Airplane | Bridge | Storage-Tank | Ship | Swimming-Pooi | Vehicle | Person | Wind-Will | |
|---|---|---|---|---|---|---|---|---|
| YOLOv6 | 11.7 | 22 | 41.8 | 38.7 | 20 | 25.3 | 10.2 | 10.9 |
| YOLOv7 | 29.9 | 22.2 | 36.7 | 33.7 | 23.3 | 24.8 | 10.5 | 5.1 |
| YOLOvR | 11.7 | 8.2 | 29 | 26.3 | 2.9 | 16.9 | 5.6 | 5.7 |
| FCOS | 0.9 | 17.4 | 29.9 | 43.5 | 4.7 | 24.5 | 4.5 | 1.1 |
| Faster R-CNN | 8.9 | 12.2 | 37.3 | 25.0 | 17.1 | 24.9 | 6.3 | 4.3 |
| TridentNet | 9.67 | 0.77 | 12.3 | 17.1 | 3.2 | 11.9 | 3.9 | 0.94 |
| M-CenterNet | 18.6 | 10.6 | 27.5 | 22.2 | 7.5 | 18.6 | 9.2 | 2.0 |
| DCN-YOLO | 27.2 | 22.9 | 40.9 | 41.9 | 25.0 | 26.4 | 11.2 | 3.9 |
| AP | AP50 | AP75 | |||||
|---|---|---|---|---|---|---|---|
| YOLOv9 | 17.9 | 40.7 | − | − | − | − | − |
| YOLOv10 | 17.8 | 39.5 | − | − | − | − | − |
| YOLOv11 | 17.9 | 41.4 | − | − | − | − | − |
| FoveBox | 8.1 | 19.8 | 5.1 | 0.9 | 5.8 | 12.6 | 15.9 |
| DoubleHead R-CNN | 10.1 | 24.3 | 6.7 | 0.0 | 7.0 | 20.0 | 30.2 |
| Faster R-CNN | 11.1 | 26.3 | 7.6 | 11.3 | 21.0 | 21.6 | 26.6 |
| YOLOv8s | 11.6 | 27.4 | 7.7 | − | − | − | − |
| QueryDet | 12.2 | 29.3 | 7.9 | 2.4 | 10.5 | 18.5 | 26.3 |
| ATSS | 12.8 | 30.6 | 8.5 | 4.0 | 14.5 | 21.5 | 31.9 |
| Cascade R-CNN | 13.8 | 30.8 | 10.5 | 9.9 | 21.3 | 24.1 | 30.3 |
| DETR | 2.7 | 10.3 | 0.7 | 0.7 | 2.1 | 3.0 | 12.4 |
| Conditional-DETR | 2.9 | 10.0 | 7.0 | 0.9 | 2.2 | 3.0 | 14.2 |
| DAB-DETR | 4.9 | 16.0 | 1.7 | 1.7 | 3.6 | 7.0 | 18.0 |
| Deformable-DETR | 17.0 | 45.9 | 8.8 | 7.2 | 17.1 | 22.7 | 28.2 |
| DABDeformable-DETR | 16.5 | 42.6 | 9.9 | 7.9 | 15.2 | 23.8 | 31.9 |
| FSANet | 20.3 | 48.1 | 14.0 | 6.3 | 19.0 | 26.8 | 36.7 |
| YOLOv5s | 17.2 | 46.0 | − | − | − | − | − |
| DCN-YOLO | 23.9 | 56.6 | 15.4 | 6.4 | 22.1 | 36.9 | 46.2 |
| Precision | AP50 | AP | Parameter | |
|---|---|---|---|---|
| DSSD | 64.5 | 53.1 | - | - |
| RefineDet | 88.1 | 85.1 | - | - |
| YOLOv3 | 71.2 | 57.5 | - | 60 M |
| YOLOv4 | 79.3 | 77.8 | - | 64 M |
| YOLOv5m | 89.2 | 87.3 | 32.3 | 20.9 M |
| YOLOv8m | 90.5 | 87.6 | 32.4 | 29.7 M |
| TPH-YOLOv5 | 91.0 | 89.5 | 32.1 | 45.4 M |
| DCN-YOLO | 91.2 | 88.5 | 48.1 | 7.6 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, M.; Tang, Q.; Tian, Y.; Feng, X.; Shi, H.; Hao, W. DCN-YOLO: A Small-Object Detection Paradigm for Remote Sensing Imagery Leveraging Dilated Convolutional Networks. Sensors 2025, 25, 2241. https://doi.org/10.3390/s25072241
Xie M, Tang Q, Tian Y, Feng X, Shi H, Hao W. DCN-YOLO: A Small-Object Detection Paradigm for Remote Sensing Imagery Leveraging Dilated Convolutional Networks. Sensors. 2025; 25(7):2241. https://doi.org/10.3390/s25072241
Chicago/Turabian StyleXie, Meilin, Qiang Tang, Yuan Tian, Xubin Feng, Heng Shi, and Wei Hao. 2025. "DCN-YOLO: A Small-Object Detection Paradigm for Remote Sensing Imagery Leveraging Dilated Convolutional Networks" Sensors 25, no. 7: 2241. https://doi.org/10.3390/s25072241
APA StyleXie, M., Tang, Q., Tian, Y., Feng, X., Shi, H., & Hao, W. (2025). DCN-YOLO: A Small-Object Detection Paradigm for Remote Sensing Imagery Leveraging Dilated Convolutional Networks. Sensors, 25(7), 2241. https://doi.org/10.3390/s25072241