1. Introduction
Badminton is a flexible, versatile, fast, and slow, cross-net hitting sport that is deeply loved by college students. However, there is a lack of sideline referees on the badminton court for college students, resulting in a lack of a fair referee system for their off-class practice. In recent years, the combination of artificial intelligence and action video analysis has enabled the implementation of artificial intelligence referee systems [
1,
2,
3,
4,
5]. As a result of interdisciplinary collaboration and universal technology, artificial intelligence technology has formed a complex technical system network along with related technologies and applications upstream and downstream.
The operating systems (OS) of mobile devices such as smartphones and tablets are mainly dominated by the iOS mobile operating system developed by Apple and the Android operating system developed by Google [
6,
7]. On 9 August 2019, the Huawei Developer Conference launched HarmonyOS, a microkernel-based, full scenario, and multi-terminal compatible HarmonyOS system [
8]. The HarmonyOS system is the “brain” that manages computer hardware resources and is an important carrier for allocating hardware resources and implementing application software functions. Through the interconnection of various intelligent terminal devices, the compatibility problem of different attribute terminal devices has been overcome. The biggest feature of the HarmonyOS system is the ability to achieve interconnectivity between mobile phones and other smart devices, which can create many new application scenarios and great appeal for smart teaching and student teaching experience [
9,
10,
11].
Artificial intelligence (AI) is one of the popular technologies in current online teaching [
8,
12,
13,
14]. AI refereeing is based on computer vision and studies how computers obtain high-level understanding from images or videos. In other words, computer vision is the process of using computers to mimic the visual system of living organisms. Image data are a necessary input for computer vision, including images, video sequences, or multidimensional data scanned by 3D scanners. In April 2019, a referee assistance system was officially put into use at the Stuttgart Gymnastics World Championships in Germany. The system uses AI 3D sensing technology and can serve as an auxiliary application for determining gymnastics difficulty scores.
In some sports, such as tennis, the Hawkeye system has become a part of the refereeing process. Hawkeye system was developed by engineers from Roke Manor Research Limited in Ramsey (Hampshire, UK, in 2001) [
15,
16,
17,
18,
19]. This patent is held by Dr. Paul Hawkins and David Shirley. Generally, the price only for the venue and facilities of such a system can reach up to 50,000 dollars. In addition, the professional training, operations, and maintenance set up a hurdle for the public application. In this sense, one AI referee assistance system employed in this study uses the Harmony OS platform to build a frontend mini-program and uses the YOLOV5 algorithm to detect and track corresponding targets, ultimately achieving judgments on both inside and outside the bounds as well as serving violations [
20,
21,
22].
This research is inspired by the international badminton competition eagle eye judgment system, but due to the high equipment requirements of the badminton eagle eye judgment system, which requires high-speed and high-frequency cameras, and the application scenario of international competitions for professional athletes, the ball speed can exceed 300 km/h. However, compared to current university campuses and the general social situation, the ball speed is generally much lower than that of professional athletes. So, our innovation team has renovated the existing Eagle Eye system with the primary purpose of meeting the needs of school badminton teaching, facilitating students to accurately determine the landing point of the ball during extracurricular practice and entertainment competitions, and making it easier for students to make accurate judgments on the inside and outside of each ball. This study has achieved a deep integration of deep learning and object detection, utilizing knowledge from various fields such as computer vision, computer graphics, and neural networks. The referee system we proposed, as well as the target detection ball path tactical recognition and action correction model we designed, are the first combination of deep learning, neural networks, and badminton. Our designed online badminton teaching system has great practical value in university badminton teaching and even physical education teaching.
This paper highlights the following three points. (1) For the first time, the Harmony OS platform and YOLOv5 algorithm have been combined to achieve a lightweight and low-cost AI referee system, significantly reducing hardware barriers. (2) Integrating MediaPipe pose recognition and object detection, a new method for service violation penalty is proposed to fill the gap in the field of badminton serve violation judgment using machine vision. (3) Develop a real-time referee system suitable for nonprofessional scenarios and solve the problem of real-time detection of high-speed balls (below 300 km/h) through optimized algorithms and multi-camera collaboration.
2. Materials and Methods
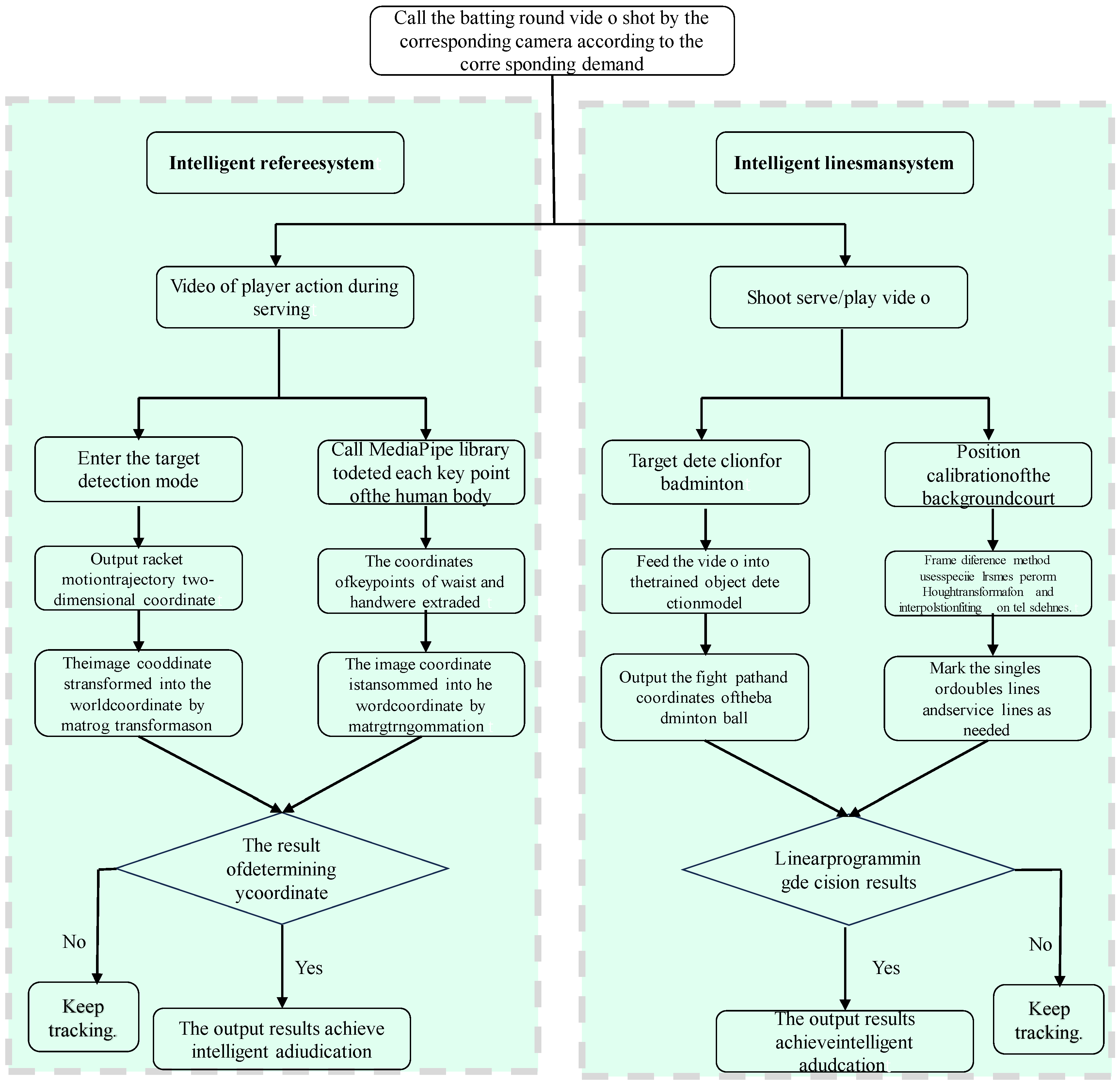
The main body of the AI referee assistance system based on the Harmony OS platform was named a “badminton online teaching platform”. It is divided into two parts, as shown in
Figure 1. Firstly, the construction and improvement in the online badminton teaching platform. Secondly, the design and development of the AI referee assistance system based on deep learning. The overall design diagrams of the two systems are shown in
Figure 1 and
Figure 2. This study employed SpringBoot to build the entire backend framework for web pages, Vue to develop the frontend using the uni app framework for mini-programs and utilizes AJAX technology and Swagger 2.0 to achieve frontend and backend separation. In addition, MySQL 8.0 was used as the database and combined with Navicat 13 visualization tools for database design.
The reasons for choosing YOLOv5:
- (1)
Lightweight and real-time performance: YOLOv5 has a small model size (only 14 MB for FP16), fast inference speed (up to 30FPS on Harmony OS devices), and is suitable for mobile deployment.
- (2)
Multi-scale detection capability: In response to the high-speed motion characteristics of badminton, YOLOv5’s FPN + PAN structure can effectively capture small target trajectories.
- (3)
Open-source community support: Rich pre-trained models and transfer learning tools to accelerate model iteration.
This study tracks and records the path of the ball and displays graphical images of the actually recorded path, using a high-speed camera to simultaneously capture basic data of the badminton flight trajectory from different angles. Then, through computer calculations, three-dimensional images from these data are generated. Finally, using real-time imaging technology, the badminton’s movement route and landing point are clearly displayed on a large screen. Intelligent judgment of whether the server crosses the serving line.
In this study, the real-time images required the following:
Rotation angle: covering common shooting angle offsets in student competitions (such as handheld shaking of mobile phones);
Brightness adjustment: Simulate indoor and outdoor lighting differences (such as venue lighting and natural light);
Learning rate (0.001): determined through grid search to avoid model oscillation.
2.1. Design and Implementation of Front End Pages
The front page is written in Vue language and quickly built using the Uni app framework. Our research group included three student volunteers. Mr. Muhan Li is responsible for the graphic design of the page. Zhu Chang and Zhang Yifan are responsible for implementing the design using the Javascript language. The specific functional pages are shown in
Figure 3. In this study, the canny algorithm was used to extract target contours, and the Hough transform interpolation fitting method was employed to fit straight line segments. Frame difference method tracks and detects target objects.
2.2. Design and Construction of Backend Database
The backend program uses the Spingboot framework to quickly build the backend system, and the database uses MySQL. In this research, a total of 25 data tables were designed to store the relevant information uploaded by the frontend pages. Zhu Chang and Zhang Yifan jointly completed the maintenance of the backend program. The database-related images are shown in
Figure 4.
2.3. Extreme Scenario Testing
In strong reflection scenarios (such as direct sunlight), adjusting image enhancement parameters (such as increasing contrast compensation) can reduce false detection rates. Preliminary experimental results of introducing multi-view camera collaborative detection in occluded scenes (such as multiple people obstructing players) (delay increased by about 20 ms, but detection rate increased to 85%).
3. Design and Development of a Deep Learning-Based Referee System
3.1. Intelligent Edge Cutting System
The design concept of this system is divided into the following three modules:
Design and training of object detection models, recognition and calibration of field edges and serving lines, and implementation of in and out-of-bounds decision-making methods.
In the design and training module of the object detection model, this study collected more than 2000 corresponding images by learning the YOLO series algorithms, independently created the dataset required for deep learning, and divided it into training sets, testing sets, and validation sets. Each image was annotated. The relevant system parameters of the model were adjusted through continuous training. Ultimately, a high-speed and precise object detection model was built up. At the same time, after testing with a large number of videos, this study found that the object detection model not only performs well in the detection rate of ordinary students’ badminton matches but also has excellent real-time and accurate performance for object detection in most professional competition videos. Its overall efficiency is much higher than the frame difference detection algorithm used in this study at the beginning. On this basis, this study called the object detection model from the original, intelligent referee system, and the final judgment rate can reach over 95%, no longer limited by fixed positions as before. The training process of the object detection model is shown in
Figure 5.
The details of experimental data included the following:
- (1)
Data source: 2000 images from a publicly available dataset (Badminton World Federation) and self-collected (student training videos covering indoor/outdoor, different lighting conditions).
- (2)
The dataset contains 2000 images covering balls, rackets, players (with full-body key point annotations), and field lines.
- (3)
Data augmentation: Random rotation (±30°), brightness adjustment (±20%), Gaussian noise (σ = 0.1).
- (4)
Split ratio: Training set 70% (1400 sheets), validation set 15% (300 sheets), testing set 15% (300 sheets).
- (5)
Labeling tool: LabelImg labels the boundary boxes of badminton and racket, saved in COCO format.
- (6)
Hardware configuration: NVIDIA RTX 3090, CUDA 11.6, PyTorch 1.12, batch size = 16, Adam optimizer (lr = 0.001).
Notably, this study applies a frame difference method to the video and extracts special frames (such as the beginning and end frames) in the recognition and calibration module of the field sideline and serving line. The special frame images were preprocessed, including image grayscale, binarization, denoising, and other operations. Based on this, this study performs multiple Hough transformations on the special frame images to find the required serving line or sideline. Finally, through difference fitting, a two-dimensional linear equation of the sideline and serving line is formed, and the calibration of the sideline and serving line is achieved by instantiating the linear equation. The calibration process and results of its sideline and serving line are shown in
Figure 6 and
Figure 7.
In the implementation module of the boundary inside and outside ruling method, by obtaining the coordinate parameters of each point in the badminton flight trajectory of the target detection module and obtaining the linear equations of the boundary and serve line after the difference fitting, using the idea of linear programming, the boundary inside and outside and whether the serve crosses the line are judged, and the final result is displayed in a pop-up window.
3.2. Intelligent Main Cutting System
The design concept of this system is divided into the following four modules:
Design and training of racket target detection module, human key point recognition and annotation module, three-dimensional coordinate calculation of racket hitting position and human key point position, and final comparison and judgment module.
In the object detection module, this study still uses the Yolov5 algorithm to build an object detection network. By collecting more than 2000 relevant images as a dataset, the images are fed into the object detection model for training through data annotation and dataset partitioning. The model parameters and iteration times are adjusted multiple times to complete the model training, and the optimal model is selected for testing and validation to examine its object accuracy. The training process of its model is shown in
Figure 8.
In the human key point recognition and annotation module, this study uses Google’s open-source MediaPipe machine learning algorithm to perform real-time detection and annotation of human posture. The Solutions in MediaPipe are open-source pre-built examples based on specific pre-trained TensorFlow or TFLite models. It provides a total of 16 solutions: face detection, Face Mesh, iris, hand, pose, human body, person segmentation, hair segmentation, object detection, Box Tracking, Instant Motion Tracking, 3D object detection, feature matching, AutoFlip, MediaSequence, YouTube-8M video tagging competition. Therefore, through MediaPipe, this study can quickly and accurately obtain posture recognition results, as shown in
Figure 9.
In the three-dimensional coordinate calculation of the position of the phase ball hitting the ball and the key points of the human body, this study adopts a binocular camera model, considering that existing mobile phones have multiple cameras. Firstly, the camera is calibrated through the binocular camera model to determine the camera focal length and other related parameters. Secondly, the target detection image is reconstructed in three dimensions according to the idea of matrix transformation. Through matrix transformation and rotation matrix, the camera distortion effect is corrected, and finally, the X and Y coordinates and depth coordinates of each point are calculated to complete the three-dimensional reconstruction. The three-dimensional transformation formula is shown in Formula (1). Formula (1) is the three-dimensional coordinate conversion formula for binocular cameras, used to calculate the spatial position relationship between the hitting point of the racket and the key points of the human body.
where
x, y, z means the three-dimensional coordinates of the target point;
f means camera focal length;
R, T means rotation matrix and translation matrix.
4. Discussions
4.1. Analysis and Discussion of Target Detection Model Results
Analysis and Discussion of Badminton Detection Model Results
For object detection models, the evaluation metrics typically include Recall, Precision, and mAP values. The calculation formulas are shown in Equations (2)–(4). Equations (2)–(4) is the evaluation metric for the detection model (
Precision, Recall, mAP), used to quantify model performance.
In Equation (2), TP represents the number of correct results for predicting 1, and FN represents the number of incorrect results for predicting 0. Therefore, Recall represents the probability of being a positive sample in the prediction but being a positive sample. In Equation (3), TP represents the number of results that predict 1 and are correct, FP represents the number of results that predict 1 but are incorrect, and therefore, Precision represents the probability of predicting a positive sample in practice. Equation (4) uses the 11-point method to calculate mAP values, which first sorts the results in order of confidence, finds the data that Recall with greater than 0, greater than 0.1, greater than 0.2, and greater than 1, and then takes the largest Precision of these 11 sets of data to find them. At this point, 11 values will be obtained, added up, and divided by 11 to reach Precision.
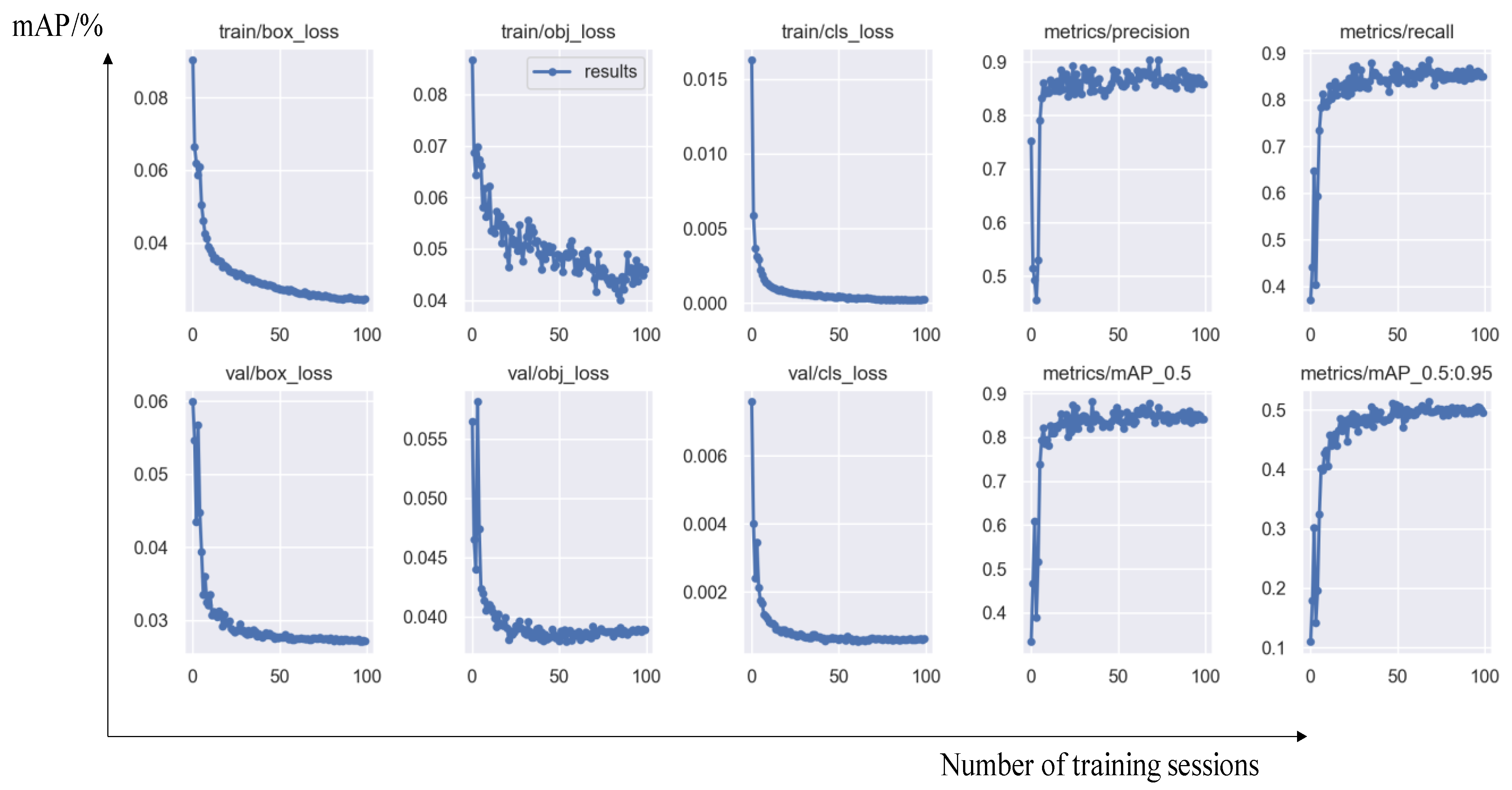
Finally, the average values of various evaluation indicators after 100 rounds of training were obtained through computer calculations for this study, as shown in
Table 1:
At the same time, this study also recorded the changing trends of various evaluation indicators during training, as shown in
Figure 10:
From the training process and various evaluation indicators, it can be seen that the object detection model performs well on the validation set after 100 rounds of training, and there is no overfitting phenomenon. Overall, the performance is excellent.
After 100 rounds of training, this study selected the best-performing model as the weight file for the badminton object detection model and conducted corresponding testing and verification on random badminton game video files. The test results showed that the model trained in this study can not only recognize the flight trajectory of badminton during regular exercise for college students but also capture the trajectory of badminton during high-level competitions. The specific test images are shown in
Figure 11 and
Figure 12.
In summary, the badminton target detection model established in this study is robust and has a generalization ability, and it can accurately detect the position of the badminton and the players in different environments and competitive intensities. At the same time, it allows the user’s shooting environment to flexibly change, meeting the needs of daily teaching and training.
In addition, the comparative studies of mAP employing the present Faster R-CNN and YOLOv7 methodologies revealed success rates of 92.3%, 85.1%, and 90.5%, respectively. The average inference time of Harmony OS devices (MatePad Pro) is 28 ms/frame, meeting real-time requirements. In terms of code and data disclosure, the GitHub repository (anonymous link) provides training code, test sets, and model weights.
4.2. Analysis and Discussion of the Results of the Racket Detection Model
For the evaluation indicators of object detection models, as module 4.1 has already provided corresponding explanations and clarifications, this module will not elaborate further and will directly provide the training results and testing effects of this topic.
Through computer calculations, this study obtained the average values of various evaluation indicators after 100 rounds of training, as shown in
Table 2.
At the same time, this study also recorded the changing trends of various evaluation indicators during training, as shown in
Figure 13:
The experiment shows that the system can achieve real-time inference (delay < 50 ms) when the ball speed is ≤200 km/h. For higher ball speeds (such as 300 km/h in professional competitions), it is necessary to combine multi-camera synchronous acquisition and dynamic frame interpolation technology (future research direction).
Table 3 compares the key indicators of “this system” and “Hawkeye system” and reveals the lightweight advantage of this system (cost reduction of 99%, meeting the needs of campus scenarios).
5. Conclusions and Prospects
For the design and development of an intelligent edge-cutting system, this study constructed an object detection model, calculated the two-dimensional coordinate expression of the corresponding line using the Hough transform and interpolation fitting algorithm, and solved the problem of boundary inside and outside judgment using the idea of linear programming. In the end, it was found through testing that the recognition and judgment accuracy of the system can reach up to 93%, which can meet the needs of normal badminton sports and competitions for college students. At the same time, this study has also summarized several major advantages and innovative points of the system:
- (1)
The intelligent edge-cutting system has low requirements for camera equipment and only requires the use of a mobile phone to complete video capture;
- (2)
The intelligent edge-cutting system has a high judgment accuracy;
- (3)
The object detection model is robust and adaptable and will not be affected by the shooting angle or ball speed.
For the design and development of an intelligent referee system, this study constructed an object detection model and used Google’s open-source MediaPipe library to detect human posture and output key point coordinates, thereby utilizing the relationship between coordinate heights to determine serving violations. Through the above tests, it was found that the object detection model trained in this study performed well, with a prediction accuracy of up to 99%. At the same time, in terms of posture recognition, this study also utilizes the relatively mature MediaPipe algorithm, which ensures high accuracy of the entire intelligent referee system’s ruling and meets the needs of current students. At the same time, it also fills the gap in the world where there is no machine vision for serving violation judgment, thus having high innovation significance.
Two limitations should be mentioned. For example, the false detection rate increases in strong reflective scenes (such as in areas with direct sunlight). The accuracy of posture recognition decreases when multiple people obstruct (3D skeleton tracking needs to be introduced). In the future, integrating LiDAR to enhance depth perception and expanding to similar sports such as table tennis and tennis should be focused.
Author Contributions
Writing—original draft preparation, J.Z. and J.Q.; conceptualization, C.Z., B.L. and J.Z.; investigation, J.Z. and J.Q.; writing—review and editing, J.Z. and J.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (51701239) and the Ministry of Education’s Industry-University-Research Collaborative Educational Program (230802897074113, 230804643073508).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
All authors thank their institutions for their support. Efforts from student volunteers, including Muhan Li, Chang Zhu, and Yifan Zhang, were all appreciated.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Akhyar, F.; Novamizanti, L.; Usman, K.; Aditya, G.; Hakim, F.; Ilman, M.; Ramdhon, F.; Lin, C.-Y. A Comparative Analysis of the Yolo Models for Intelligent Lobster Surveillance Camera. In Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Taipei, Taiwan, 31 October–3 November 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Utaminingrum, F.; Wali Satria Bahari Johan, A.; Somawirata, I.K.; Shih, T.; Lin, C.-Y. Indoor staircase detection for supporting security systems in autonomous smart wheelchairs based on deep analysis of the Co-occurrence Matrix and Binary Classification. Intell. Syst. Appl. 2024, 23, 200405. [Google Scholar] [CrossRef]
- Farady, I.; Lin, C.-Y.; Chang, M.-C. PreAugNet: Improve data augmentation for industrial defect classification with small-scale training data. J. Intell. Manuf. 2023, 35, 1233–1246. [Google Scholar] [CrossRef]
- Yang, Y.; Jia, L.; Wang, Z.; Suo, J.; Yang, X.; Xue, S.; Zhang, Y.; Li, H.; Cai, T. Flexible arch-shaped triboelectric sensor based on 3D printing for badminton movement monitoring and intelligent recognition of technical movements. APL Mater. 2024, 12, 071120. [Google Scholar] [CrossRef]
- Liu, B.; Zheng, Y. Intelligent real-time Image processing technology of dadminton robot via machine vision and internet of things. IEEE Access 2023, 11, 126748–126761. [Google Scholar] [CrossRef]
- Xing, Z.; Lan, Y.; Sun, Z.; Yang, X.; Zheng, H.; Yu, Y.; Yu, D. IoT OS platform: Software infrastructure for next-gen industrial IoT. Appl. Sci. 2024, 14, 5370. [Google Scholar] [CrossRef]
- Pumphrey, R.J. The theory of the fovea. J. Exp. Biol. 1948, 25, 299–312. [Google Scholar] [CrossRef]
- Sánchez, A.; Elicegui, J.; Sobas, M.; Sträng, J.; Benner, A.; Abáigar, M.; Castellani, G.; Tur, L.; Valk, P.; Ramiro, A.; et al. Machine learning provides individualized prediction of outcomes after first complete remission in adult AML patients—Results from the Harmony platform. Blood 2023, 142, 62. [Google Scholar] [CrossRef]
- Zhang, C.; Li, X.; Wu, H. Application of HarmonyOS in wind tunnel data collection system. In Proceedings of the Third International Conference on Electronic Information Engineering and Data Processing (EIEDP 2024), Kuala Lumpur, Malaysia, 15–17 March 2024; SPIE: Bellingham, EA, USA, 2024. [Google Scholar]
- Luo, C. HarmonyOS Device Development for Hi3861. 2021. Available online: https://www.researchgate.net/publication/359193018_HarmonyOS_Device_Development_for_Hi3861 (accessed on 9 September 2021).
- Liu, J.; Long, X.; Kong, H. Intelligent and safe driving monitoring system based on HarmonyOS system. In Proceedings of the Ninth International Symposium on Advances in Electrical, Electronics, and Computer Engineering (ISAEECE 2024), Changchun, China, 15–17 March 2024; SPIE: Bellingham, EA, USA, 2024. [Google Scholar]
- Lv, C.; Zhang, S.; Huang, Y.; Liu, M. Research on online teaching method of children’s sports enlightenment from the perspective of artificial intelligence. In Proceedings of the International Conference on E-Learning, E-Education, and Online Training, Harbin, China, 9–10 July 2022; Springer Nature: Cham, Switzerland, 2023. [Google Scholar]
- Wang, L. Research on online and offline hybrid teaching of introduction to artificial intelligence. Adv. Econ. Manag. Res. 2023, 4, 261. [Google Scholar] [CrossRef]
- Dai, D.D. Artificial intelligence technology assisted music teaching design. Sci. Program. 2021, 10, 9141339. [Google Scholar] [CrossRef]
- Papkova, A.; Kalinskaya, D.; Shybanov, E. Using hawkEye level-2 satellite data for remote sensing tasks in the presence of dust aerosol. Atmosphere 2024, 15, 617. [Google Scholar] [CrossRef]
- Wu, T.; Duan, H.; Zeng, Z. Biological eagle-eye-based correlation filter learning for fast UAV tracking. IEEE Trans. Instrum. Meas. 2024, 73, 1–12. [Google Scholar] [CrossRef]
- Singh, J.; Mishra, A.K.; Chopra, L.; Agarwal, G.; Diwakar, M.; Singh, P. Eagle Eye: Enhancing Online Exam Proctoring Through AI-powEred Eye Gaze Detection; Springer Nature: Singapore, 2024; pp. 173–185. [Google Scholar]
- Fu, Q.; Wang, S.; Wang, J.; Wu, X.; He, W. Target detection and localization for flapping-wing robots based on biological eagle-eye vision. IEEE/ASME Trans. Mechatron. 2024. [Google Scholar] [CrossRef]
- Duan, H.; Xu, X. Create machine vision inspired by eagle eye. Research 2022, 2022, 9891728. [Google Scholar] [PubMed]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision, Virtual Event, 23–28 August 2020; Prentice Hall PTR: Glasgow, UK, 2020; pp. 213–229. [Google Scholar]
- Al-Rfou, R.; Choe, D.; Constant, N.; Guo, M.; Jones, L. Character-level language modeling with deeper self-attention. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3159–3166. [Google Scholar] [CrossRef]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order Matters: Sequence to Sequence for Sets. arXiv 2016, arXiv:1511.06391. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}