1. Introduction
Depression is a major global health challenge, and its prevalence has increased further in recent years due to the impact of the COVID-19 pandemic, as well as the current lifestyles of people, which are much more solitary and involve much less outdoor movement and therefore lower levels of vitamin D [
1,
2]. The increasing prevalence of depressive symptoms highlights the need for an objective early diagnostic method. Traditional methods, those based on subjective questionnaires, are prone to errors and delayed detection.
Electroencephalography (EEG) is now a common and reliable option for finding depression markers and making diagnosis and treatment checking more objective [
3]. Recent EEG methods use deep learning to improve depression classification accuracy. For example, EEGDepressionNet [
4] introduced a framework that mixes Self-Attention-based Gated DenseNet with a Chaos Owl Invasive Weed Search Optimization algorithm. This model extracts features from EEG signals using 3D-CNN, 1D-CNN, and spectral analysis, achieving 94% accuracy on the DepressionRest Dataset.
Another important study, EDT [
5], created a deep learning model that extracts features from the frequency domain, as well as spatial and temporal aspects of EEG data, achieving an accuracy of 92.25%. EDT focuses on exploring the frequency domain feature extraction module and attention mechanism, which effectively identify patterns specific to depression. In a third study, DCST [
6] proposed an attention network designed to use the spatial distribution characteristics of EEG data for depression recognition. The model achieved an accuracy of 89.8% with a leave-one-subject-out cross-validation method. DCST has both RegionalCalculationNet and GlobalCalculation-Net in its design, which pick up spatial and time features at both local and larger levels. But these studies also noted issues like small datasets and complicated models; they hinted that there needs to be further work performed on identifying more compact models, as well as testing on larger groups.
Previous research in the field [
7,
8] analyzed two approaches for classifying depression from EEG signals: the first involved the use of a simpler machine learning approach, such as the Multilayer Perceptron model that analyzes features extracted from the data; the second study used a basic version of the EEGNet structure applied directly to raw EEG signals. These methods have demonstrated the potential to differentiate between healthy and depressed individuals, although each had limitations in terms of noise interference, and feature selection. More recent efforts, like those of EEGDepressionNet, EDT, and DCST, have advanced feature extraction and model complexity, yet their focus on individual datasets limits their applicability across heterogeneous populations. This gap suggests an opportunity to integrate multiple datasets and refine model parameters to improve both accuracy and adaptability, particularly for clinical use where data variability is inevitable. Building on these foundations, the presented work aims to increase the accuracy of depression classification by pooling multiple datasets (DepressionRest along with MDD vs. Control) while tuning the hyperparameters of some networks using Optuna. The work introduces a series of improvements that aspire to improve the accuracy and generalization of depression detection, and these include noise filtering techniques to remove artifacts, feature selection to optimize classification, and hyperparameter optimization. The efficient processing of high-dimensional EEG signals is vital for real-time clinical applications. Compressed sensing techniques, such as the Adaptive Stepsize Forward-Backward Pursuit (ASFBP) method [
9] or the optimal tensor truncation approach for multichannel EEG compression [
10], offer a promising approach to enhance processing efficiency by reconstructing sparse signals using adaptive thresholds or by compressing multi-channel EEG data into a compact core tensor. While not implemented here due to our focus on raw EEG data and deep learning, CS could reduce sampling demands and computational load in future EEG frameworks, complementing our aim for lightweight, scalable depression diagnostics.
The central question guiding our research is as follows: Can combining multiple EEG datasets and optimizing deep learning model hyper-parameters with Optuna library [
11] improve the generalizability of depression classification? Our aim is to develop a robust tool for clinical applications that can accurately diagnose depression using EEG data. To achieve this, we will develop a standardized preprocessing pipeline that includes noise filtering, artifact removal using independent component analysis (ICA), and feature selection. We will optimize deep learning models using Optuna, combine multiple datasets to increase training data diversity, compare optimized and non-optimized models, and validate results using statistical tests to confirm the significance of observed improvements across different datasets and configurations.
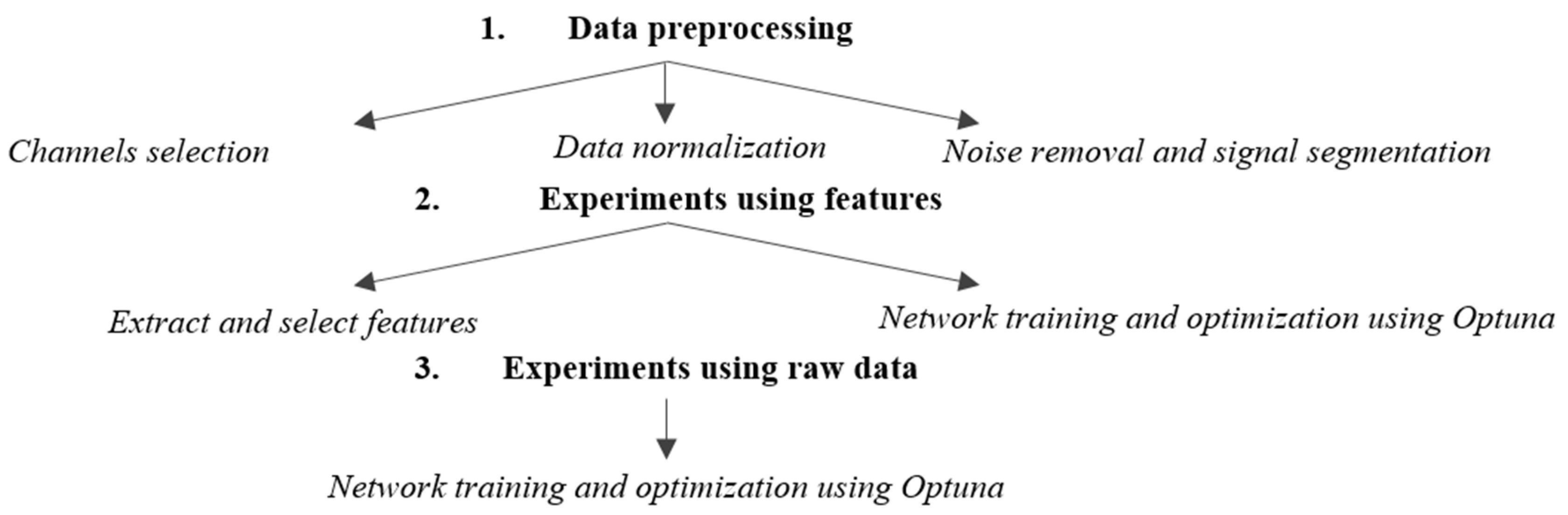
3. Results
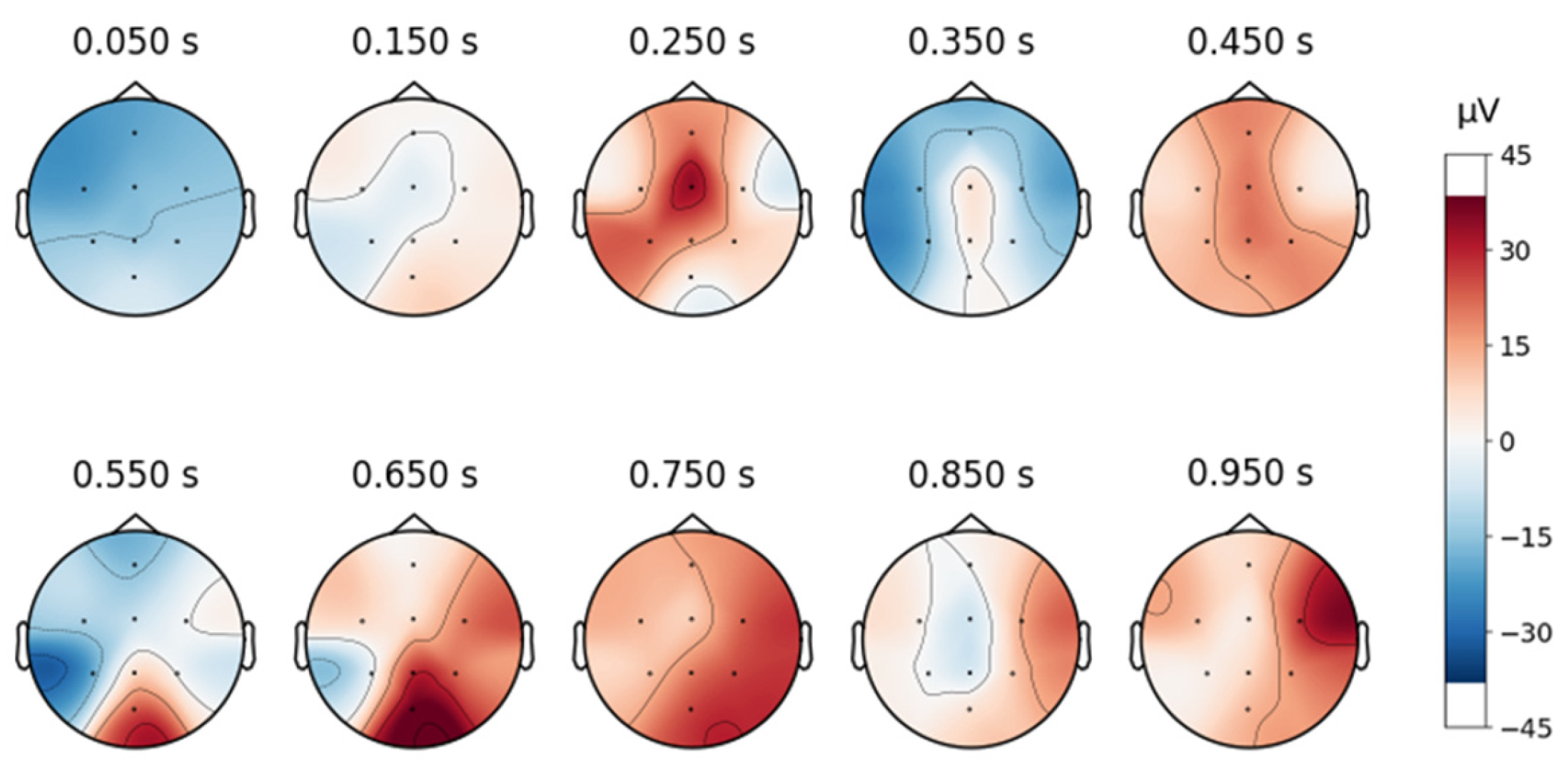
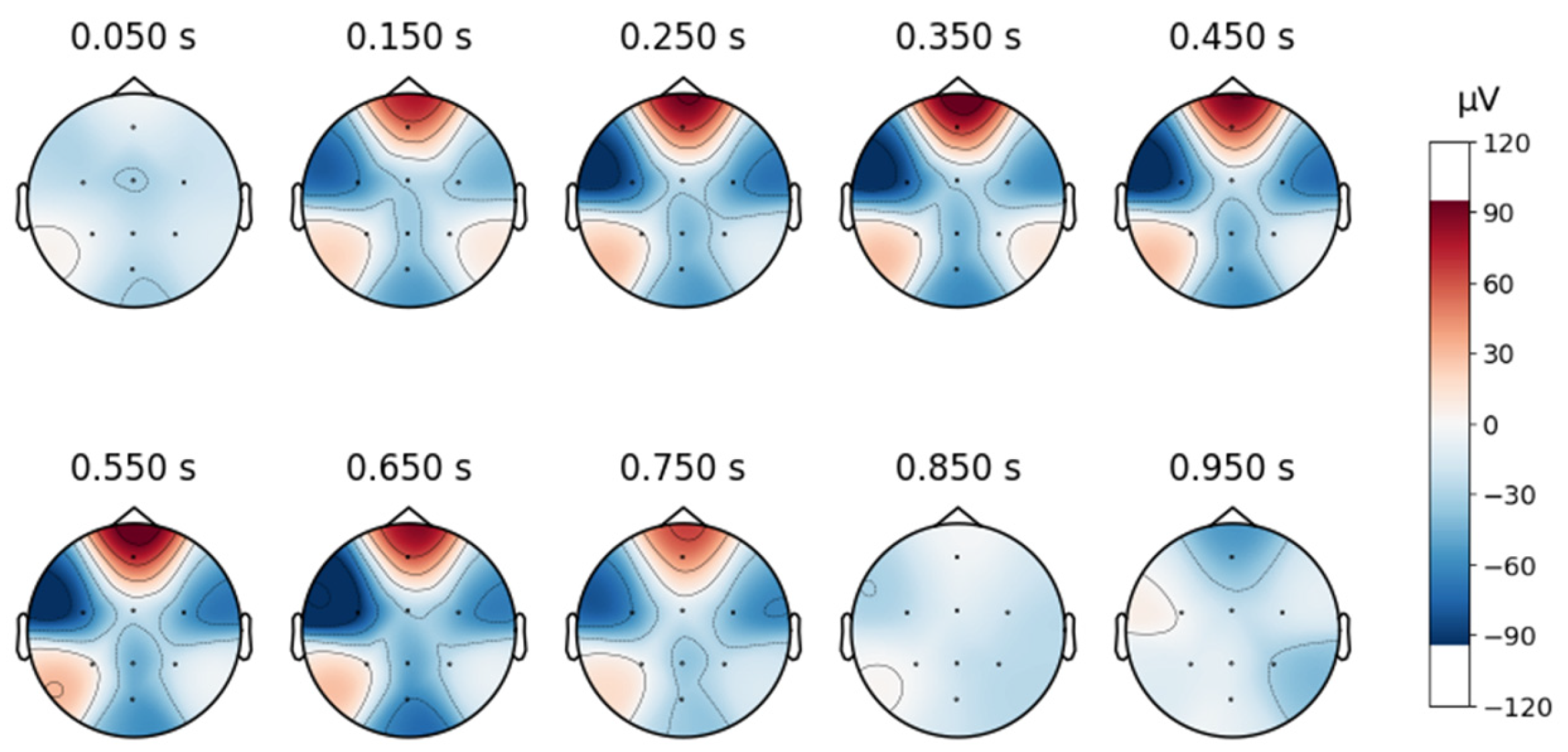
A topographic map in EEG analysis is a visual representation of brain activity across different scalp regions over time. It provides an intuitive way to examine spatial signal distribution by mapping electrode positions onto a 2D projection of the head, typically using a heatmap-style color scale to indicate signal strength in microvolts (µV).
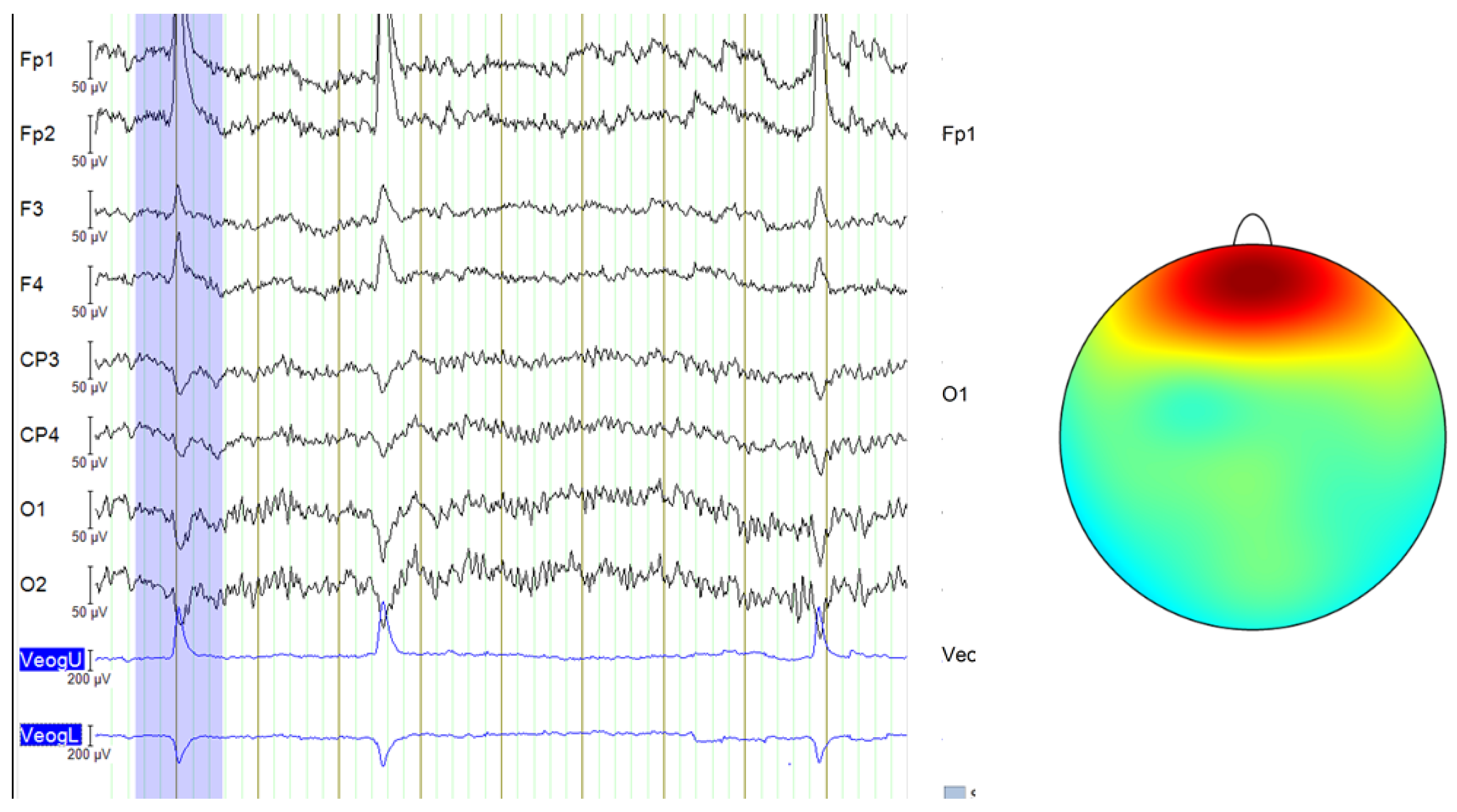
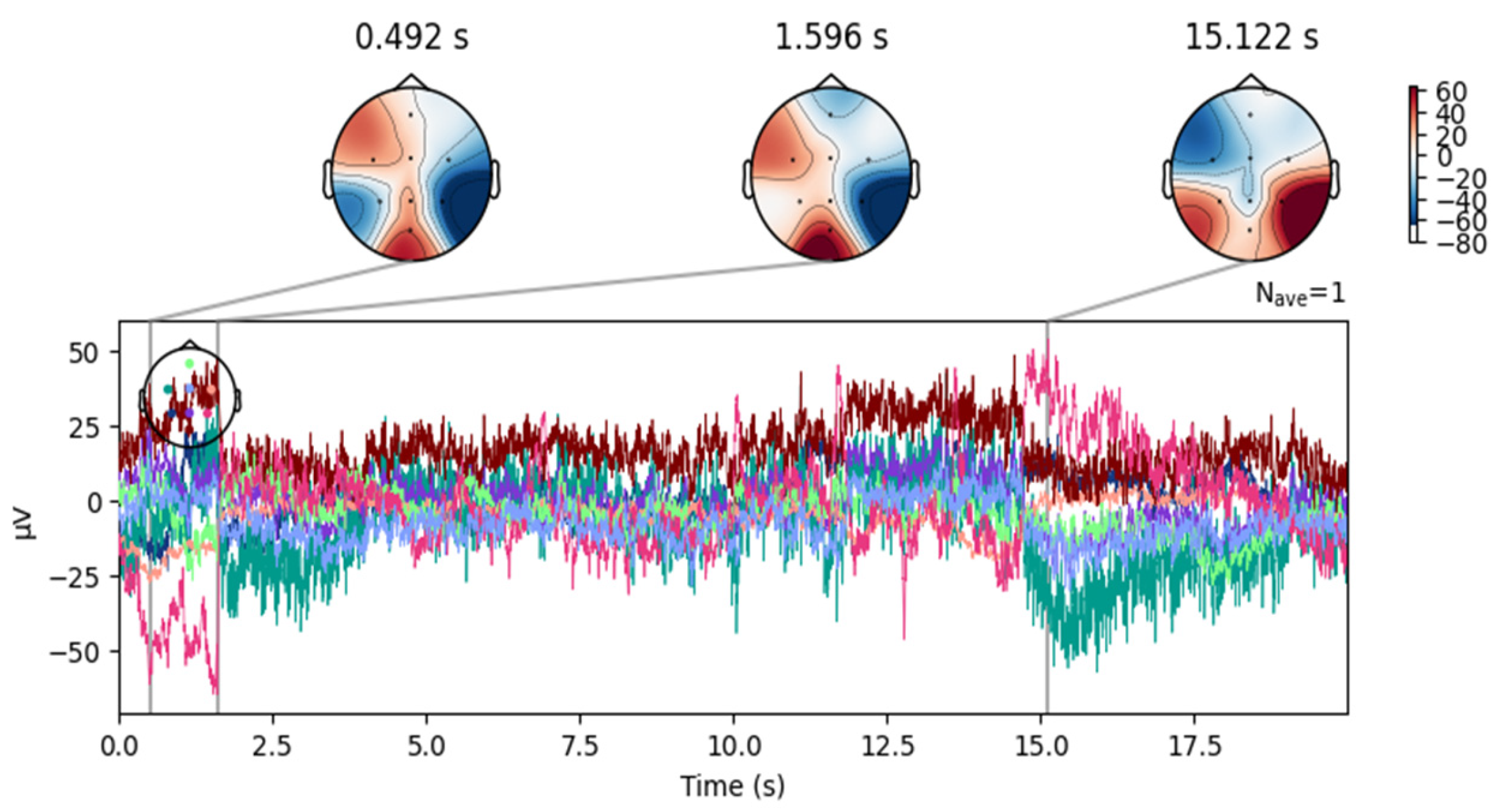
In this study, time-based topographic maps were used to identify potential artifacts in the EEG signals. These maps are constructed by capturing the electrode positions at multiple time points and visualizing the intensity of electrical activity across the scalp. Areas with stronger signals appear in warmer colors, while weaker signals are shown in cooler tones. The primary goal of this analysis was to ensure that no strong noisy sequences were present, which could disrupt multiple channels, and to check for characteristic artifact patterns, such as those caused by teeth clenching or involuntary eye movements. As shown in
Figure 4, the signals from the MDD database do not exhibit noticeable noise, particularly in the frontal lobe.
In contrast, although the DR database was collected under a closed-eye protocol, some signals still contain blinking artifacts, as illustrated in
Figure 5.
To eliminate this noise, independent component analysis (ICA) was employed.
An eight-component representation was chosen, from which the component labeled “ICA000” was identified as corresponding to the blinking artifacts. This component was removed, and the signal was then reconstructed.
Despite artifact removal techniques, some regions of the EEG signals remained noisy. As shown in
Figure 6, the signal after removing the ICA component associated with blinking shows successful elimination of blinking artifacts in the frontal area. However, as shown in
Figure 7, the signals still contain moving artifacts.
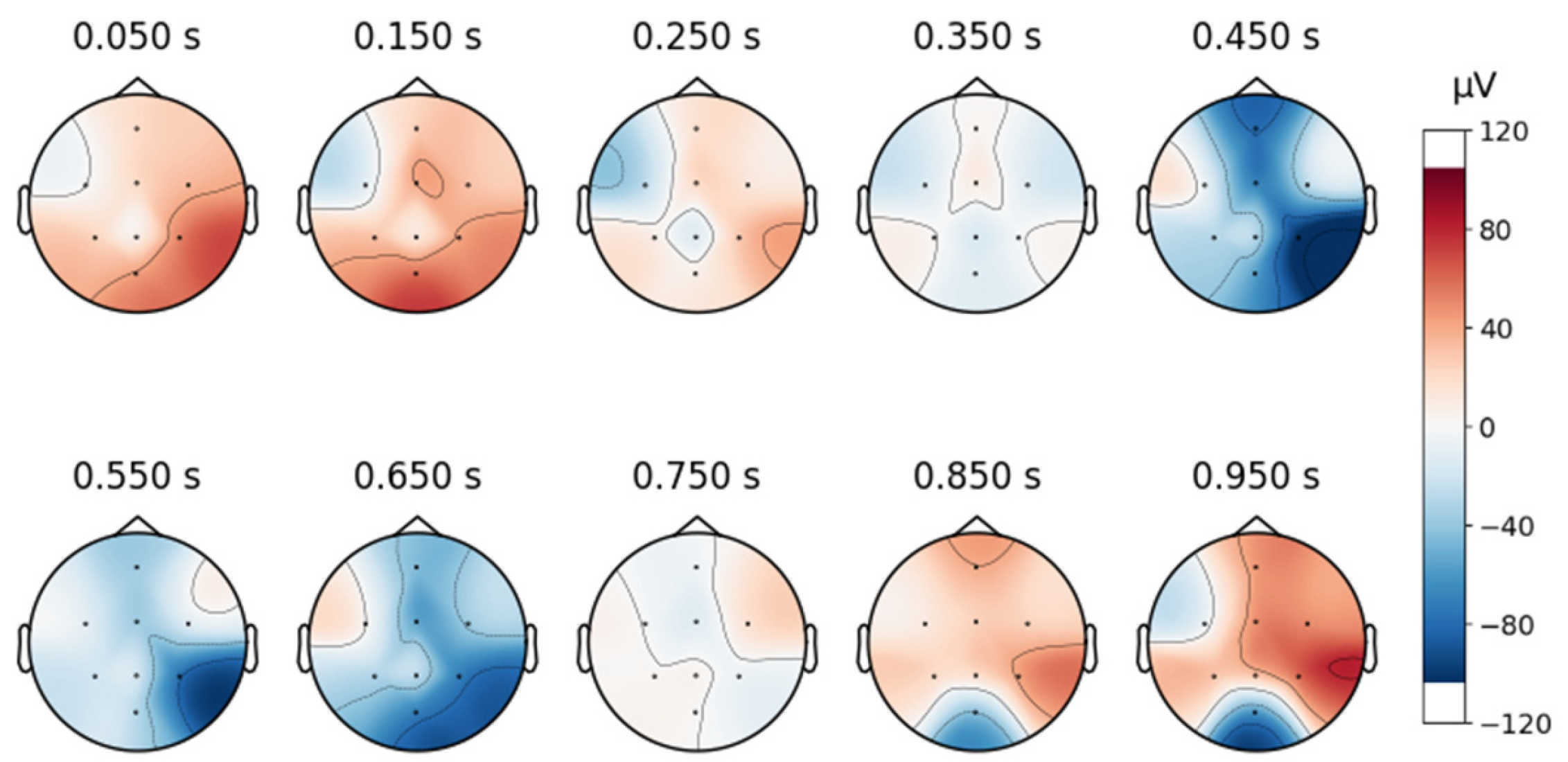
To continue analyzing the collected signal, topographic maps are created as shown below, in
Figure 8, and it can be observed that the signals are free from artifacts.
3.1. Experiments Using Features
To obtain the highest possible results, the structure of a network was searched using Optuna. With the help of the library, the model that has the best accuracy is followed. Various parameters were adjusted during experiments, including the following:
Number of convolutional layers: Between 1 and 3 layers.
Number of dense layers: Between 1 and 3 layers.
Number of convolutional filters: Choices of 32, 64, or 128 filters.
Kernel size: Dimensions of 3 or 5.
Pooling size: Dimensions of 2 or 3.
Number of dense units: Between 32 and 512 units.
Dropout rate: Between 0.2 and 0.5.
Learning rate: Between 10−5 and 10−1 and on a logarithmic scale.
An example of an experiment with 10 trials using Optuna is presented in
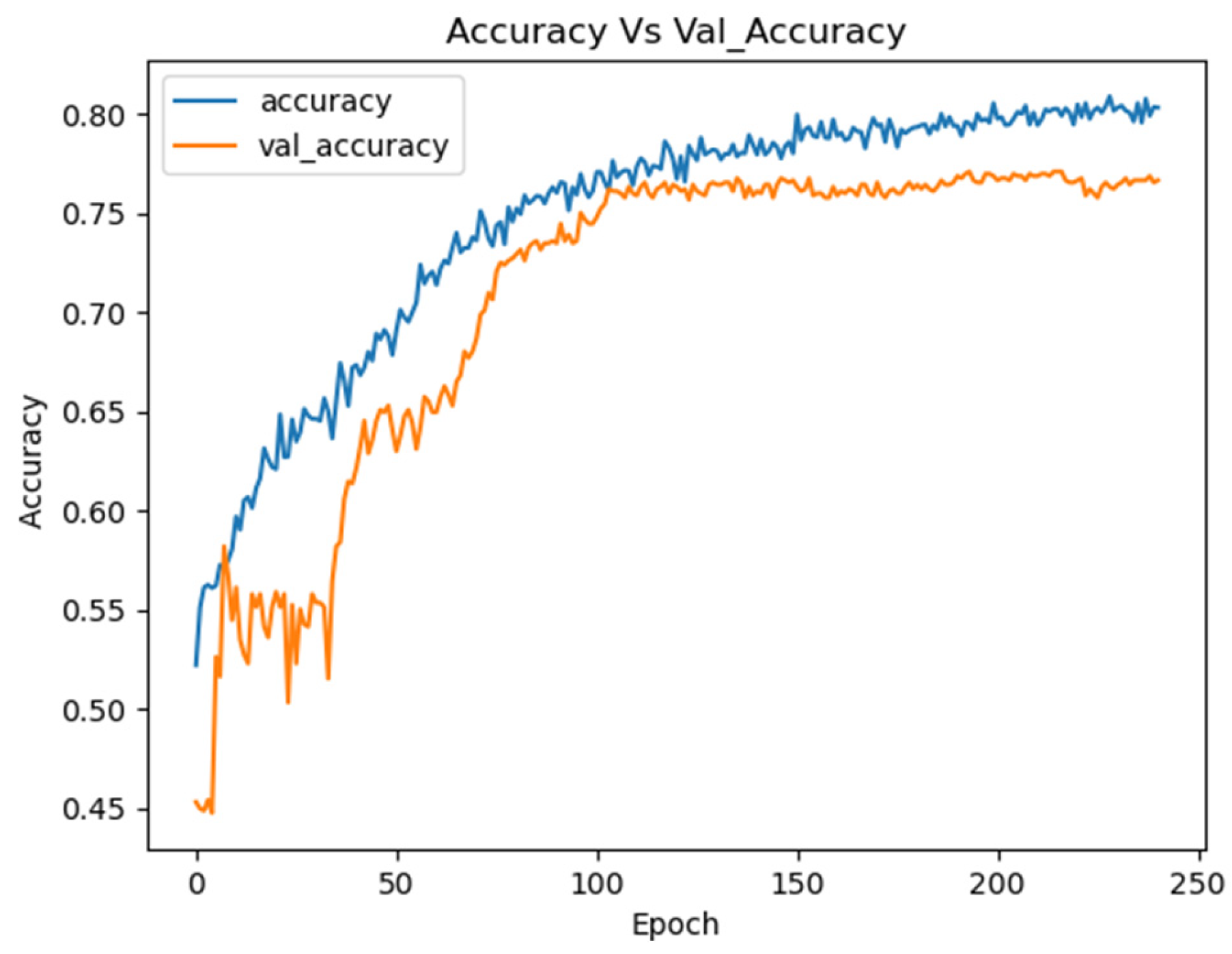
Table 1, detailing the hyperparameters and resulting accuracies. The Optimized CNN achieved an accuracy of 75.49%, with training and loss curves demonstrating stability and effective learning throughout the process (
Figure 9). These results highlight the model’s ability to learn consistently, avoiding overfitting or underfitting.
Table 2 presents the confusion matrix for the CNN tested on the combined dataset. In this context, the labels used in the confusion matrix correspond to the classification of the subjects based on their health status. Label 0 represents the healthy class, while label 1 corresponds to the depressive class.
The model correctly classified 233 out of 302 instances labeled as 0 and 145 out of 208 instances labeled as 1, with false negatives and false positives of 63 and 69, respectively. The classification metrics are detailed in
Table 3.
The CNN trained on the combined dataset was further evaluated on the Depression Rest dataset to assess its performance on noisier data. This test aimed to determine whether training on a combined dataset could enhance the model’s generalization to a dataset with lower quality or higher noise levels. The results are summarized in
Table 4.
The study observed a notable decrease in model performance on the DR dataset, with the Optimized CNN achieving an F1-score of 0.56 for the depressive class (Class 1), as shown in
Table 4. This contrasts with higher performance on the combined dataset (F1-score of 0.70,
Table 3) and the Proprietary dataset (F1-score of 0.73,
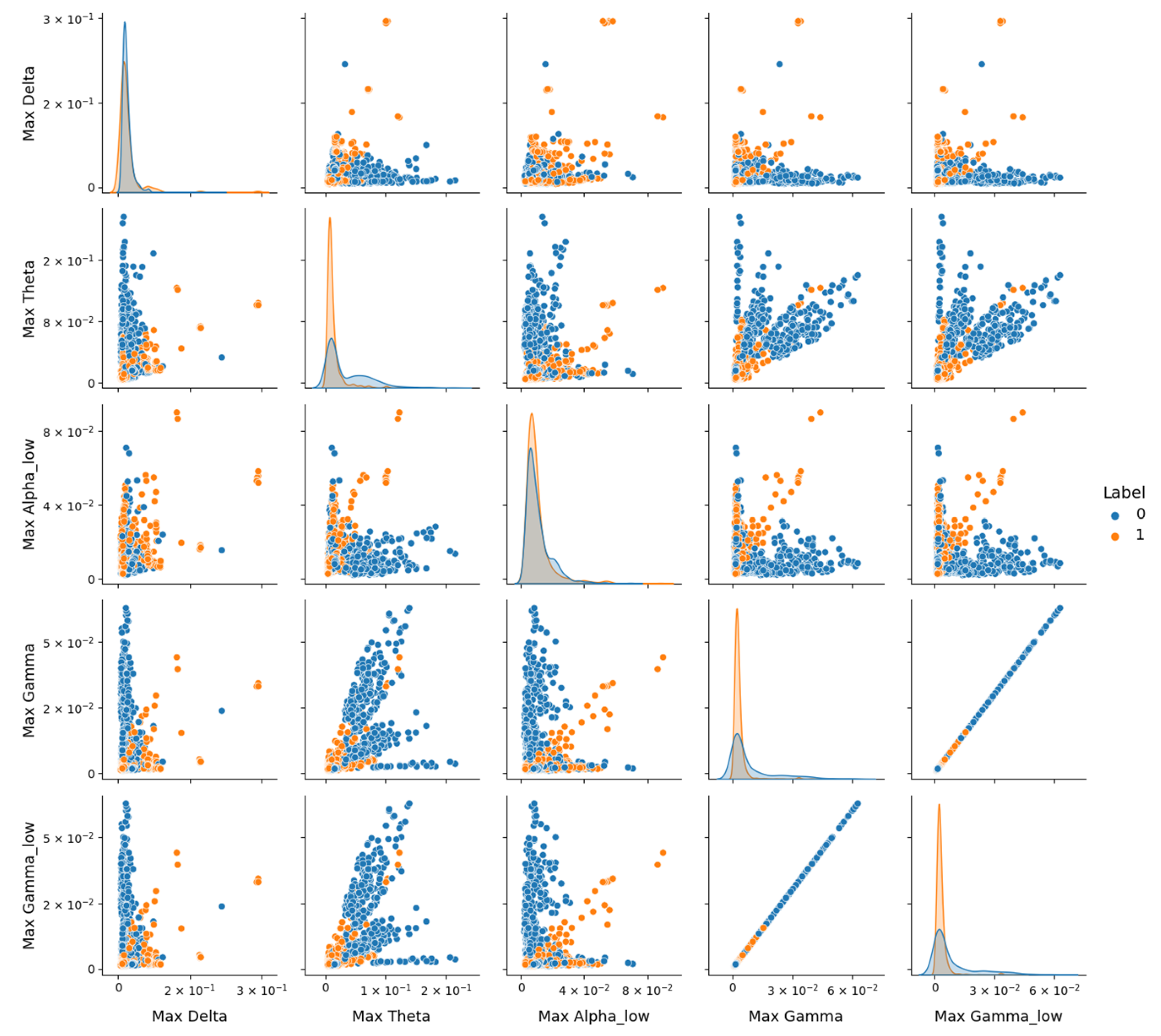
Table 5). To investigate this performance drop, pairplot visualizations using the version 0.12.2 of Seaborn library, as depicted in
Figure 10, were employed to explore feature distributions in the DR dataset. Pairplot function creates a grid of scatter plots showing pairwise relationships between variables, with diagonal histograms illustrating individual feature distributions.
However,
Figure 10 reveals significant overlap between the healthy (Class 0) and depressive (Class 1) classes across these features, despite their statistical relevance. Notably, depressive signals tend to exhibit higher amplitudes (e.g., in Max_Theta, Max_Gamma, and Max_Gamma_low), but the lack of clear separation suggests that noise or variability within the DR dataset may obscure class-specific patterns. The diagonal contains histograms of each feature’s distribution, highlighting the overlap between classes and the tendency of depressive signals to exhibit higher amplitudes in certain frequency bands.
In contrast,
Figure 11 for the MDD vs. Control dataset shows a more pronounced distinction between classes, indicating that these features better capture depression-related differences in a less noisy context. Electrode configuration differences further complicate generalization. DR’s original 64-channel setup was reduced to eight common channels to align with other datasets, potentially discarding spatial information critical for depression markers, as seen in the topographic variability. The Proprietary dataset, natively collected with eight electrodes, and MDD, adjusted similarly, retained more relevant spatial data within this configuration, supporting higher performance.
These findings underscore the need for strategies to enhance robustness when dealing with datasets containing significant noise or variability.
To complete the analysis, testing was performed on the Proprietary dataset. The model achieved an accuracy of 72.87%, indicating consistent performance in classifying the depression state. However, for a more detailed evaluation, the results from
Table 5 were also analyzed, showing balanced classification.
Although satisfactory results were obtained on the Proprietary dataset, the model could not generalize well on the Depression Rest database. As a result, alternative approaches are being explored. After analyzing the characteristics, no similar models were found, so the next approach uses raw EEG data.
3.2. Experiments Using Raw Data
The hyperparameter optimization for the EEGNet model was conducted using the Optuna library. An example of an experiment with 10 trials is presented in
Table 6, detailing the hyperparameters and resulting accuracies.
Trial 5 achieved the best performance, with an accuracy of 0.7844, using a kernel size of 64, F1 (number of filters in the first convolutional block) of 16, D (depth multiplier) of 4, and F2 (number of filters in the second separable convolutional block) of 48. This suggests that a more complex and deeper network improved performance. Trial 9 had the lowest performance, with an accuracy of 0.6501, using a kernel size of 16, F1 of 4, D of 2, and F2 of 32. This indicates that the selected parameters were suboptimal, as the network was too small.
The Optimized EEGNet achieved a mean test accuracy of 80.85% (±0.0138) on the combined dataset, with float32 accuracy of 80.85% and int8 quantized accuracy of 77.40%. The inference time was 44.86 ms, and the int8 model size was 28.94 KB.
Figure 12 illustrates the training curves for the EEGNet model optimized with Optuna on the combined dataset.
These curves demonstrate the stability of the model during training, showing continuous improvement in performance for both the training and validation sets.
The confusion matrix presented in
Table 7 highlights the number of correct and incorrect predictions for each class.
This table shows that the Optimized EEGNet model correctly classified 1094 instances as label 0 and 1086 instances as label 1. The relatively low number of misclassifications (288 false negatives and 294 false positives) underscores the model’s solid performance in distinguishing between the two classes.
Table 8 provides a detailed evaluation of the Optimized EEGNet model’s performance, showing precision, recall, and F1-score for both classes.
The network was further evaluated on the Depression Rest (DR) dataset, achieving a mean test accuracy of 85.71% (±0.0142), float32 accuracy of 85.71%, and int8 quantized accuracy of 83.20%, with an inference time of 49.80 ms and an int8 model size of 28.94 KB. The results are summarized in
Table 9.
The confusion matrix of the optimized model tested on proprietary dataset is presented in
Table 10.
Testing on the Proprietary (Augmented) dataset yielded a mean test accuracy of 93.27% (±0.0610), float32 accuracy of 93.27%, and an impressive int8 quantized accuracy of 98.00%, with an inference time of 45.26 ms and an int8 model size of 28.94 KB. The results are detailed in
Table 11.
The EEGNet model optimized with Optuna demonstrated excellent performance on the Proprietary dataset, confirming that the optimizations led to a robust and efficient model. The outstanding results indicate that the model not only trained well on the combined dataset but also managed to maintain its performance in the specific context of the Proprietary dataset. This suggests that the model is well-adapted for real-world applications, offering confidence in its practical use.
A summary of the results is presented in
Table 12 and
Table 13, detailing the computational efficiency and performance of the Baseline and Optimized EEGNet models across three datasets: Combined, Depression Rest (DR), and Proprietary.
Table 12 describes the Baseline model, an EEGNet network without hyperparameter optimization, with a lightweight architecture of 2450 parameters and 6.94 MFLOPs. It achieves a consistent inference time of 44.84 ms on an NVIDIA Tesla P100 GPU, with model sizes of 13.92 KB (float32) and 9.59 KB (int8), yielding a 31.1% size reduction. The float accuracies were 72.83% (Combined), 71.88% (DR), and 82.90% (Proprietary), with quantized accuracies of 74.60%, 66.60%, and 91.40%, respectively. Mean test accuracies from 5-fold cross-validation were 72.83% (±0.0138), 71.88% (±0.0142), and 82.90% (±0.0610), reflecting moderate performance with higher variability on the smaller Proprietary dataset.
Table 13 presents the Optimized EEGNet model, enhanced via Optuna hyperparameter tuning, featuring 19,650 parameters and 60.13 MFLOPs. Inference times average 46.17 ms (44.86 ms Combined, 49.80 ms DR, 46.26 ms Proprietary), with model sizes of 80.86 KB (float32) and 34.16 KB (int8), achieving a 57.8% size reduction. Float accuracies improved to 80.85% (Combined), 85.71% (DR), and 93.27% (Proprietary), with quantized accuracies of 77.40%, 83.20%, and 98.00%, respectively, the latter possibly enhanced by quantization’s regularization effects. Mean test accuracies were 80.85% (±0.0138), 85.71% (±0.0142), and 93.27% (±0.0610), demonstrating superior performance and stability. These results support the study’s aim of unifying diverse EEG datasets for scalable, portable diagnostics, with the Optimized model balancing accuracy and efficiency for clinical use.
3.3. Computational Efficiency for Portable Applications
The int8 quantization reduced the Optimized model’s size by 57.8%, from an average float32 size of 80.86 KB to 34.16 KB across all datasets. This compact size is ideal for deployment on resource-constrained devices like the ESP32 microcontroller, which has 4 MB of FLASH memory. Inference times ranged from 44.86 ms (Combined) to 49.80 ms (DR) on a GPU, specifically the NVIDIA Tesla P100 provided by Kaggle Notebooks, a platform owned by Google LLC (Mountain View, CA, USA), which uses hardware from multiple vendors (e.g., NVIDIA (Santa Clara, CA, USA), Intel (Santa Clara, CA, USA)), where training and evaluation were conducted, suitable for many clinical applications, though sub-10 ms latency may require further optimization. Quantized accuracy occasionally exceeds float32 due to regularization effects during int8 calibration.
These results are summarized in
Table 14.
3.4. Statistical Signifiance of Results—Baseline (Eegnet) vs. Optimized Model
The statistical tests provide a robust evaluation of the Optimized model’s performance relative to the Baseline and across datasets. Paired t-tests were as follows:
Combined dataset: t-stat = −4.59 and p-value = 0.0118—On the combined dataset, the Optimized model significantly outperforms the Baseline model (p < 0.05), with a moderate-to-large effect size. The negative t-statistic confirms higher accuracy for the Optimized model, likely due to hyperparameter tuning via Optuna enhancing generalization across the merged dataset.
DR dataset: t-stat = −21.3149, p-value = 0.0017 (highly significant)—highly significant improvement (p < 0.01) with an extremely large effect size (t ≈ −21.31). This suggests that the Optimized model markedly outstrips the Baseline on DR, possibly due to better handling of noise.
Proprietary (Augmented): t-stat = −2.2022, p-value = 0.0924 (not significant)—the difference is not statistically significant (p > 0.05), with a small-to-moderate effect size (t ≈ −2.20). Despite the Optimized model achieving higher accuracy, it does not reliably outperform the Baseline model. The p-value (0.0924) is close to significance, suggesting a trend toward improvement, but variability (high SD = ±0.0921) or small sample size (6 subjects, augmented to ~2×) may weaken statistical power.
The ANOVA tested differences in Optimized model accuracies across the three datasets, yielding a highly significant result (p < 0.001). The large F-statistic (19.53) confirms substantial variability in performance, rejecting the null hypothesis that accuracies are equal. This suggests dataset-specific factors (e.g., noise levels, electrode configurations, sample sizes) strongly influence the Optimized model’s effectiveness, necessitating post hoc analysis to pinpoint differences.
The Tukey HSD test identified pairwise differences between datasets, adjusting for multiple comparisons (alpha = 0.05). Negative meandiff values indicate the second dataset has higher accuracy.
Combined vs. DR: meandiff = 0.0486, p-adj = 0.0274 (significant)—this modest gap may reflect DR’s cleaner signal post-ICA and better alignment with the training data (partly DR-derived), despite the combined dataset’s broader scope.
Combined vs. Proprietary: meandiff = −0.0978, p-adj = 0.0022 (significant)—this large difference underscores Proprietary’s advantage, likely its native 8-channel setup and lower noise
DR vs. Proprietary: meandiff = −0.1333, p-adj = 0.0002 (significant).
4. Discussion
This project discusses the issue of combining datasets from different sources to improve the classification of the level of depression using artificial intelligence. The findings argue that the joint training of several datasets improves the strength of the classifier while also enhancing its performance on sets of data that differ from the training set in real life. The Optimized EEGNet model achieved mean test accuracies of 80.85% (±0.0138) on the combined dataset, 85.71% (±0.0142) on Depression Rest (DR), and 93.27% (±0.0610) on the Proprietary dataset, with float32 accuracies of 80.85%, 85.71%, and 93.27%, and int8 quantized accuracies of 77.40%, 83.20%, and 98.00%, respectively. All these advances have important implications for the clinical use of these models, as they prove their feasibility for such scenarios where accuracy and repeatability are necessary. This can also be achieved in other biomedical research areas, which attests to its usefulness and importance.
Hyperparameter optimization via Optuna proved to be pivotal, enabling exploration of a vast parameter space—kernel length (16–64), filters (4–16, 8–48), dropout (0.2–0.5)—to refine the EEGNet architecture. Paired t-tests reveal significant improvements over the Baseline model, with t = −4.59 (p = 0.0118) on combined and t = −21.3149 (p = 0.0017) on DR datasets, indicating moderate-to-large and extremely large effect sizes, respectively. These gains likely stem from enhanced generalization and noise handling, as the Optimized model markedly outperforms the Baseline’s 72.83% (±0.0138) and 71.88% (±0.0142) on these datasets. However, on the Proprietary dataset, the improvement from 82.90% (±0.0610) to 93.27% yielded t = −2.2022 (p = 0.0924), a non-significant result despite a small-to-moderate effect size. This p-value, hovering near the 0.05 threshold, suggests a trend toward improvement, but its lack of significance warrants scrutiny. The Proprietary dataset’s small sample size—only six subjects (two depressed, four healthy), augmented three-fold via Gaussian noise and time shifts—may have contributed to this outcome, as limited data reduces statistical power and increases variability (±0.0610), the highest among datasets. Augmentation, while enhancing robustness testing, could introduce artificial patterns or overfitting to the augmented test set, particularly with the int8 model’s 98.00% accuracy, potentially inflating performance without corresponding statistical confidence in the float32 comparison. This contrasts with combined and DR datasets, where larger, more diverse samples (122 and 64 subjects, respectively) yield significant results. The Proprietary dataset’s clinical efficacy shines through its 98.00% int8 accuracy, validated across DR and combined testing, suggesting the model is finely tuned for depression diagnosis despite these statistical caveats. Collaboration with healthcare professionals during deployment could amplify these benefits, integrating new data to bolster sample size and clarify augmentation’s impact.
Comparative with other works that typically rely on individual datasets, this study offers a novel protocol for unifying and processing EEG data from multiple sources. The proposed method effectively addresses the challenge of dataset integration, ensuring the model is more robust and generalizable. For instance, EEGDepressionNet [
4] achieves 94% accuracy on the Depression Rest dataset using a complex architecture combining 3D-CNN and 1D-CNN with spectral analysis, requiring approximately 1.2 million parameters and 2.5 billion FLOPs due to its Self-Attention-based Gated DenseNet structure. EDT [
5] leverages multi-domain feature extraction (frequency, spatial, temporal) with an attention mechanism, employing around 800,000 parameters and 1.8 billion FLOPs, while DCST [
6] uses a spatial attention network with roughly 600,000 parameters and 1.4 billion FLOPs, achieving 89.8% accuracy. In contrast, our Optimized EEGNet, with just 19,650 parameters and 60.13 MFLOPs, delivers a competitive 93.27% accuracy on the Proprietary dataset. This stark reduction in complexity—over 30 times fewer parameters and 40 times fewer FLOPs than EEGDepressionNet—highlights the proposed model’s simplicity and efficiency, making it more suitable for resource-constrained clinical applications.
Sharma et al. [
17] (98.8%) similarly rely on extensive preprocessing and larger architectures, whereas our lightweight approach (34.16 KB int8) balances performance with practicality. DR’s lower accuracy reflects noise (micro-blinks, muscle artifacts) and electrode reduction, reducing spatial resolution critical for depression markers, as seen in pairplot overlaps versus MDD’s clearer separation. ANOVA confirms dataset-specific performance variations (F = 19.5329,
p = 0.0002), rejecting equal accuracy across datasets, while Tukey HSD pinpoints Proprietary’s edge over combined (meandiff = −0.0978,
p-adj = 0.0022) and DR (meandiff = −0.1333,
p-adj = 0.0002), and DR’s modest superiority over combined (meandiff = 0.0486,
p-adj = 0.0274). The Proprietary dataset’s native 8-channel setup and lower noise likely drive its advantage, contrasting with DR’s reduced 64-to-8 channels and noise challenges (micro-blinks, muscle artifacts) as seen in pairplot, overlaps versus MDD’s clearer separation.
The model’s lightweight design—int8 size of 34.16 KB (57.8% reduction from 80.86 KB float32)—and inference times of 46.17 ms across datasets on an NVIDIA Tesla P100 make it ideal for portable devices like the ESP32, enhancing clinical accessibility. The Baseline’s 72.83%, 71.88%, and 82.90% float32 accuracies rise to 74.60%, 66.60%, and 91.40% with int8, but the Optimized model’s 98.00% int8 on Proprietary outstrips these, though its >10 ms latency suggests optimization needs for real-time use (<10 ms). DR’s lower performance reflects noise and spatial resolution loss, a challenge not fully mitigated by ICA, unlike Proprietary’s cleaner native data.
The most important contribution of this work remains the fact that all models were trained on a very small number of electrodes, which is the configuration of most readily available EEG headsets. The fact that the Optimized EEGNet model performs well with a small dataset and no other requirement except for an EEG device makes the model capable and efficient for clinical testing. This enhances the applicability of the model in clinical settings, especially where resources are constrained. Ultimately, the goal of this study was not just to improve accuracy but to establish a scalable and efficient pipeline that unifies multiple EEG datasets, addressing the challenges of dataset variability and complex preprocessing. The results of this study confirm that the proposed method was successful in achieving these goals. Statistical tests (ANOVA:
p = 0.0002) confirm dataset-specific performance, with Tukey HSD showing Proprietary’s superiority (
p-adj = 0.0022 vs. Combined), likely due to native 8-electrode data versus DR’s reduced 64-to-8 channels, echoing noise challenges. The model’s compact size and 44.86–49.80 ms inference time suit portable devices like the ESP32, aligning with clinical needs for accessible diagnostics [
3]. Int8 quantization (
p = 0.0825, Proprietary) enhances efficiency without significant accuracy loss, contrasting with resource-heavy models [
4,
5]. By integrating several diverse datasets and optimizing hyperparameters, we not only enhanced the model’s generalization capabilities but also ensured its practicality for clinical environments where real-world data often varies. The proposed pipeline offers a robust solution for EEG data processing and classification, laying the foundation for future work in this field, particularly in expanding the model’s applicability across a wider range of clinical scenarios.
5. Conclusions
The research has presented advanced techniques for the diagnosis of depression utilizing EEG signals and machine learning models. There is an emphasis on collection and preprocessing methods that guarantee high-quality data.
The paper addressed the design and optimization of neural networks for EEG signal analysis, including the selection of models and initial hyperparameter values. Optuna was utilized for hyperparameter optimization, facilitating the efficient exploration of a large hyperparameter space. To discover the optimal parameter combinations, several experimental rounds were conducted. The methodology used in this study highlights the advantages and disadvantages of the approach, particularly regarding the classification of EEG features that distinguish between normal and depressive conditions.
Although the results are encouraging, several problems remain, particularly the need for additional data for testing and training, along with the challenges associated with processing EEG data. To enhance diagnostic precision, upcoming studies could explore the combination of various types of biometric data. Furthermore, in line with data protection laws, ethical issues regarding the utilization of EEG data, including confidentiality and the necessity for informed patient consent, need to be considered.
The enhanced EEGNet network will be incorporated into specialized devices for clinical applications in depression diagnosis in the future. A portable and adaptable processing module that can connect to different models of EEG headsets might be created to ensure compatibility with current models. Connecting to existing EEG headsets, developing suitable software for data collection and model operation, and presenting the findings in a manner that healthcare professionals can easily comprehend are all essential to implementing this strategy. This solution must be validated and supported in clinical settings to ensure its accuracy and reliability.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}