1. Introduction
In recent years, networks of distributed microphone arrays have gained popularity and have been used in various acoustic signal processing applications [
1,
2,
3,
4,
5,
6,
7,
8,
9]. One of the most important tasks of these networks is sound source localization (SSL) and tracking, which can be a primary task or support other algorithms for which the position of one or more sound sources is valuable information [
10,
11,
12,
13,
14,
15,
16,
17]. Typical application scenarios for SSL methods are audio surveillance, video conferencing, and automotive systems [
3,
18,
19].
The SSL problem has been extensively studied in the literature on distributed microphone arrays, and several approaches can be classified based on the type of
acoustic parameter used for localization [
1]. Examples of acoustic parameters used for SSL are time delay between microphones [
10,
11,
12,
16,
20], measurements of sound energy [
21,
22], power measures obtained through beamforming techniques [
13,
17,
23], and estimation of the direction of arrival (DoA) of sound sources [
14,
24,
25,
26,
27,
28,
29]. More recently, techniques based on deep learning have used latent space features to map acoustic signals to the position of sound sources [
15].
In this manuscript, we focus on SSL methods that utilize DoAs, which are defined as either one angle (in 2D space) or two angles (in 3D space), indicating the direction of a sound source with respect to a reference direction. In particular, we focus on the SSL framework introduced in [
24], which allows 3D SSL using only 2D DoA measurements. This approach is advantageous because 2D DoAs can be computed quite efficiently, and are therefore well suited for low-cost, low-power microphone arrays commonly used in microphone array networks.
Regardless of the chosen acoustic parameters for SSL, most methods are based on optimization problems, where the goal is to fit a sound propagation model with acoustic measurements or features extracted from acoustic arrays [
1]. Traditionally, SSL methods use centralized processing to solve the aforementioned optimization problems, where data from all arrays in the network are collected and processed by a dedicated node, often referred to as the Fusion Center, which then performs localization [
1]. As a result, systems of this kind have a critical point of failure (i.e., the Fusion Center) that must also guarantee a communication bandwidth high enough to process measurements from all sensor nodes [
3]. Therefore, there is a growing interest in developing computationally distributed solutions that allow for estimation of the quantities of interest (e.g., the position of a sound source) by distributing the computational load to all acoustic arrays and leveraging their cooperation to achieve better performance. In addition, distributed approaches are desirable due to their higher scalability, robustness, and low power consumption [
30].
Computationally distributed approaches in microphone array networks have been investigated for various acoustic signal processing tasks, including signal estimation [
31,
32], beamforming techniques [
5,
33], active noise control [
34], and acoustic echo cancellation [
35]. However, to the best of our knowledge, few computationally distributed SSL methods have been proposed, and they are mostly limited to 2D environments [
17,
36,
37].
Recently, the authors of the present manuscript, building on the centralized framework for 3D SSL with 2D DoAs of [
24], proposed a computationally distributed 3D SSL method [
38] that uses a network of planar microphone arrays. In [
38], SSL is described as a distributed minimization problem and is approached with an Adapt-Then-Combine (ATC) diffusion strategy [
30,
39]. This, in turn, has two major advantages over [
24]. Firstly, the approach is computationally distributed and divides the computational load across the arrays. Second, the approach is adaptive, i.e., each array handles a stream of 2D DoAs instead of single DoA measurements as in [
24]. This allows the microphone array network to adapt to changes in the distribution of DoA streams, which are usually influenced by noise and unfavorable acoustic effects, and learn their statistical moments. As a result, localization accuracy can be improved by penalizing arrays that acquire unreliable measurements. By responding to DoA streams, the tracking of sound sources is also automatically integrated into this approach, under the assumption that the sound source moves relatively slowly.
In this manuscript, we extend the work of the conference paper [
38] in several ways. With respect to [
38], which considers a simple DoA stream model based on the assumption that the acoustic environment is anechoic, this manuscript introduces more sophisticated DoA stream models, along with applications of the method in simulated reverberant environments. Building on these extensions, we propose a new set of data exchange policies between acoustic arrays that are specifically tailored to significantly improve localization accuracy in more complex acoustic scenarios. Moreover, the work in [
38] considered just a
fully connected network topology, where each node is directly connected to every other node. In this manuscript, we consider different connected topologies and investigate how performance is affected when network connectivity is gradually reduced. Our results show that the performance degradation is negligible as long as a connected network topology is considered. This emphasizes the effectiveness and resilience of the proposed distributed approach. We also test the robustness of the proposed approach at different reverberation levels and signal-to-noise ratios (SNRs). We show that our method converges even under challenging conditions and show a way to control the stability of the position estimate after convergence.
The manuscript is structured as follows.
Section 2 introduces the SSL framework used throughout the paper and formulates the SSL task as an optimization problem.
Section 3 discusses a centralized solution to this optimization problem that is able to handle streams of DoAs and penalize noisy arrays.
Section 4 presents a computationally distributed approach that uses an ATC diffusion strategy to solve the SSL problem. This section also introduces new cooperation strategies between array nodes to improve performance.
Section 5 evaluates the accuracy and robustness of the proposed methods, while
Section 6 examines the convergence speed and steady-state stability of the approach.
Section 7 assesses the resilience of the method under reduced network connectivity. Finally,
Section 8 offers concluding remarks and discusses potential future developments.
2. Background on 3D Sound Source Localization with Linear Microphone Arrays
We tackle the problem of localizing a sound source in a 3D space using a network of linear microphone arrays, where each array measures a 2D DoA. Let us consider an acoustic environment in which a single sound source is located at the coordinates . Let us also consider K spatially distributed linear microphone arrays whose reference points are located at the coordinates for . Each array is oriented according to a unit vector , where and stand for the azimuth and elevation angle, respectively. The goal is to determine the position of the sound source based on the DoAs detected by the microphone arrays.
2.1. Sound Source Localization Framework
Similarly to the work in [
24], in this work we approach 3D SSL with linear arrays by performing 2D DoA triangulation in the same plane as the sound source; namely, the plane defined by
. The goal of triangulation for SSL is to determine the location of the sound source as the intersection of acoustic rays emanating from the source and passing through the microphone arrays, where the acoustic rays are parameterized by the position of the array and its DoA estimate. Since in our context the triangulation takes place on the plane
, this poses a challenge as the acoustic rays from the source to the microphone arrays do not normally lie on this plane. Therefore, we consider the projection of the microphone arrays onto the plane
. The coordinates of the projected arrays’ reference points are denoted as
. To ensure the correctness of this approach, each projected array must preserve the 2D DoA
, where
is the local DoA estimate of the array. The distance of the array to the sound source must also be preserved after projection, i.e.,
. Given these constraints, the projection of each array depends on the sound source position
, and the coordinates are computed as [
24]
where
A representation of a projected array and the corresponding local DoA is shown in
Figure 1.
Having defined the parameters of the projected arrays, we can determine the acoustic rays required for triangulation on the plane
. An acoustic ray intersecting a sound source and a projected microphone array
k is described by
where
,
, and
are parameterized in terms of the DoA
of the array as
However, in a real acoustic scenario, Equation (
2) is generally not satisfied due to the error introduced by the DoA estimation process and adverse room acoustic phenomena. Nevertheless, from Equation (
2), we can derive an error function that measures the agreement between the measurements of each array and the assumed acoustic ray propagation model. Therefore, we define the fitting error of each array DoA measure as
Employing the fitting error of each array in (
4), we can express the considered SSL task by writing the following optimization problem:
where we use
to denote the local cost function of array
k. Consequently, by minimizing the global cost
, we aim to find the source location
that best fits all measured DoAs across the network.
2.2. Centralized Resolution Approach Presented in [24]
A centralized solution to the optimization problem (
5) can be obtained by using the following Gauss–Newton iterative method [
24]:
where
,
is the position estimate at iteration index
i,
† denotes the Moore–Penrose matrix inverse operator, and
is the error gradient vector with elements
Although the approach converges to a solution quite quickly [
24], it has several limitations in terms of flexibility and localization performance. Regarding flexibility, Ref. [
24] is designed for single DoA measurements and remains an “instantaneous” approach that is not able to learn from data streams and to adapt accordingly. Moreover, since it is computationally centralized, its scalability and robustness are limited. As far as localization performance is concerned, Ref. [
24] lacks a mechanism to scale the contribution of individual array measurements, preventing the penalization of arrays that negatively impact localization accuracy.
2.3. Distributed Resolution Approach Presented in [38]
Our previous conference paper [
38] presents a computationally distributed approach based on ATC diffusion. It is designed starting from the theoretical framework established in [
24], adapting it to DoA streams while incorporating a mechanism to penalize arrays with the most detrimental effects on localization. However, Ref. [
38] is also characterized by important limitations. Firstly, only anechoic environments were considered for the performance evaluation, resulting in a simple DoA stream model. Moreover, only fully connected topologies were considered and no studies on the performance of networks with reduced connectivity were presented.
5. Testing the Localization Accuracy
In this section, we evaluate the localization accuracy of the proposed diffusion-based SSL method using both DoA stream models and an acoustic simulation. The evaluation is performed under a fully connected network topology, establishing a clear baseline for assessing the impact of combination policies without the complexities introduced by sparser connectivity. The influence of partial network connectivity is explored in
Section 7. Throughout this section, we consider a room of size
, with eight microphone arrays placed near the room edges, with reference positions
and orientations
set according to
Table 1. We also consider different candidate sound source positions
placed on a uniformly distributed 2D grid of
points for two different planes:
and
. As for the diffusion-based SSL method, we consider a uniform step size across all nodes
. Sound sources are assumed to be stationary in this set of experiments.
5.1. DoA Stream Models
We begin by evaluating the accuracy of the proposed ATC diffusion SSL method using different DoA stream models. These models represent the combined effects that room acoustics and the DoA estimators used in each array have on the generation of DoA streams. This approach allows us to test the accuracy of the method in controlled, simplified scenarios and to investigate how localization accuracy is affected by factors such as biases in DoA estimation.
We employ three different DoA stream models. Each of them is a perturbed version of the actual DoA
, which we define as
The simplest DoA stream model is based on the assumption that DoAs measured by each array are drawn from the following distribution:
where
is a normal distribution with mean
and variance
. Hence, it is assumed that each agent measures unbiased DoAs with the same variance
. We will refer to this DoA measurement distribution as
model I. This was the only case considered in [
38].
A more complex DoA stream model also considers a different DoA measurement variance for each array, i.e., DoAs are generated from the distribution
We refer to this DoA stream distribution as
model II, according to which each agent has its own variance
, and
denotes a log-normal distribution with mean
and variance
.
However, in real acoustic scenarios DoA estimates are often biased, due to reverberation and a low SNR. Therefore, a more realistic DoA stream model, which we refer to as
model III, considers biased agents, each with its own measurement bias. The distribution for model III is given by
where
and
models the variance of the measurement bias, and where
has the same distribution as model II.
We now compare the localization accuracy of the proposed diffusion-based SSL with the various DoA stream models discussed above. In particular, we evaluate the accuracy by computing the localization error
according to Equation (
22) and we perform
Monte Carlo simulations for each possible source position in the grid to average the effect of the different DoA stream realizations.
The results are shown in
Figure 4, where the metric
is shown at each possible source position for all different DoA stream models. In particular, top to bottom,
Figure 4 depicts the accuracy of the proposed approach using DoA streams drawn from models I, II, and III, while different columns show different combination policies. The leftmost column shows the results when no adaptive combination policy is used and therefore all combination coefficients are set to
. The other three columns, in order from left to right, in
Figure 4 show the results obtained when the combination coefficients are set according to the distance penalty factor in Equation (
20), the error penalty factor in Equation (
18), and the cost penalty factor in Equation (
19), respectively. For this analysis, we set
,
, and
. These values were selected to ensure that, from iteration
onward, all subsequent iterations corresponded to steady-state behavior. DoA streams generated with model I were obtained by setting
, streams generated with model II were obtained by setting
, and those generated with model III were obtained by using the same
distribution and setting
. We verify that DoA measurement biases negatively impact the accuracy of the proposed method. More interestingly, we observe that the error-based policies (i.e., the ones using either the error or the cost as penalty factors) have higher accuracy when the DoA measurements on each array are unbiased (i.e., for DoA stream models I and II). This is to be expected since these policies penalize arrays with higher costs, and for unbiased DoA streams, higher costs are associated with less accurate estimates of the sound source position. However, this is no longer the case for DoA streams generated according to model III, where arrays are characterized by biased DoA estimates. Indeed, the local costs of each array may have minima at positions far from each other and from the actual source position
. In this scenario, the adaptive distance policy shows better accuracy, as distant arrays have on average the worst estimates of DoA and thus of source position. Therefore, depending on the specific DoA estimation procedure, which in turn leads to different DoA streams, it may be appropriate to choose the combination policy for diffusion-based SSL accordingly.
5.2. Acoustic Simulations
We now evaluate the localization performance of diffusion-based SSL in a simulated reverberant environment. To simulate the acoustic environment, microphone signals are generated using the image source method [
42]. In particular, this method is used to generate all room impulse responses (RIRs) from all the candidate source positions in the 3D grid to all microphones. Then, we convolve the sound source signal with the simulated RIRs and corrupt the resulting signals with an additive Gaussian white noise with a signal-to-noise ratio (SNR) of 20 dB to obtain the simulated microphone signals. As a sound source, we used a 30-second male speech from the TIMIT database with a sampling frequency of
kHz. It is also assumed that the sound source is omnidirectional.
Let us again consider
uniform linear arrays (ULAs) of microphones whose reference points and orientations are set again according to
Table 1. Also, each array is composed of
elements with an inter-element distance of
cm. Therefore, the 3D coordinates of the
nth microphone in array
k can be defined as
where
denotes the
nth microphone position within the
kth array, and
. To obtain a DoA stream, we divide the simulated microphone signals into frames of length 2048 samples, each of which represents the data measurement at iteration step
i. In each frame, microphone arrays estimate an “instantaneous” DoA using a beamforming technique. Specifically, we transform the received microphone signals into the time–frequency domain using the short-time Fourier transform (STFT) with a Hamming analysis window of length 256 samples overlapped by 50%. This results in a total of
time windows per frame.
Let
denote the STFT of the
nth microphone signal of the
kth array, evaluated at a time–frequency bin
, where the index
refers to the
pth time segment, and
refers to the
qth frequency bin. Note that the STFTs are calculated at each iteration index
i, but we omit this dependency to simplify the notation. The minimum variance distortionless response (MVDR) pseudospectrum at
is given by [
43]
where
is the far-field propagation vector for each microphone array, computed for a set of sampled angles
, in radians, providing the desired angular resolution. The elements of the propagation vector
are given by
On the other hand,
in Equation (
31) represents the sample estimate of the array covariance matrix, defined as
where
. Then, the DoA estimated by agent
k at iteration index
i is
where
is the geometric mean of the pseudospectrum values
along the frequency axis, with frequency bins in the range
.
We now present the localization results obtained from this acoustic simulation. First, as an illustrative example,
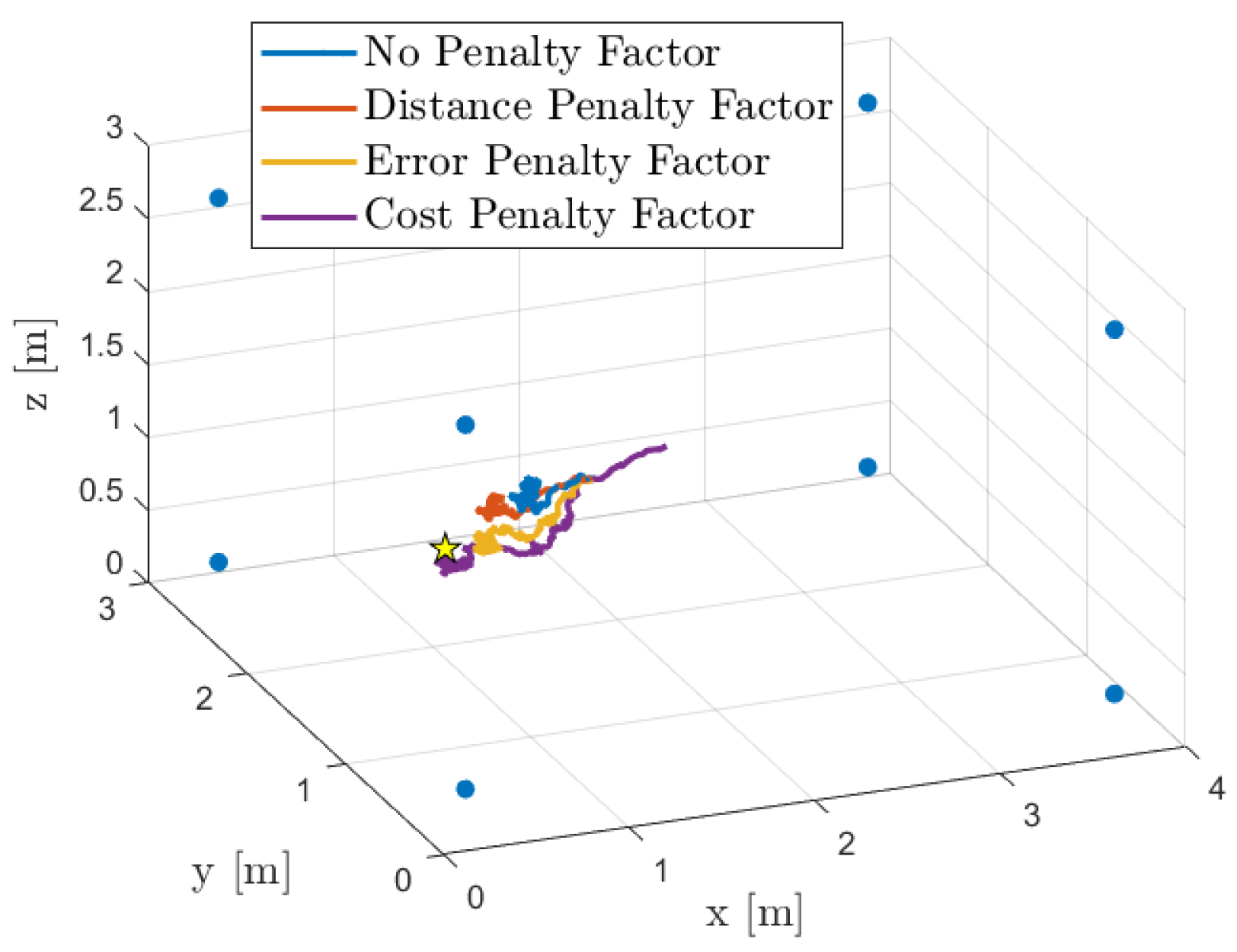
Figure 5 shows the room layout (4 m × 3 m × 3 m), the positions of the eight microphone arrays (as listed in
Table 1), and the true as well as estimated source locations. In this instance, the source is positioned at
m. Additionally, we illustrate the trajectories—the location estimates at each iteration—obtained using our diffusion-based SSL algorithm with all proposed combination policies.
Further, following the methodology in the previous subsection, we evaluate localization accuracy using the average mean absolute error (
), computed over the same 3D grid. However, in this case, we consider only a single realization, corresponding to the DoA stream obtained from the simulated acoustic environment. The results are shown in
Figure 6, where the considered diffusion SSL and the method of [
24] are compared. As we can see, the proposed approach always achieves higher accuracy than the centralized approach of [
24], since the adaptive policies aim to penalize the arrays with the most harmful effects on localization. Moreover, the combination policies always improve the results compared to the trivial ATC diffusion implementation where no combination policies are used.
We can note that the localization performance obtained by using the combination policy based on the error-based penalty factor is similar to that of the combination policy based on the distance penalty factor. The reason is that in this simulated acoustic environment, and with the chosen DoA estimator, unlike the simpler DoA stream models of the previous subsection, while the bias increases, the DoA variance increases as well.
We are interested in evaluating the robustness of the proposed method in adverse acoustic scenarios by assessing the localization accuracy when both T60 and SNR increase. Specifically, we measure the localization accuracy for different T60 values between 0 and 1 s at a fixed SNR of 20 dB. We also measure localization accuracy for a T60 of 0.4 s and varying SNR values between 10 and 35 dB. Instead of an analysis point by point, in this set of experiments we measure the average MAE over all the source positions in a subsampled grid of
points in the room, in order to have a mean volumetric localization accuracy value for each T60/SNR pair. In line with previous experiments, we assess the localization accuracy of every source location in the grid using the metric
, with
. This metric is then averaged across the grid to obtain the mean volumetric average of localization accuracy, denoted as
. These results are summarized in
Figure 7.
As expected, the performance of all methods deteriorates with increasing T60 and decreasing SNR. Nevertheless, even under the worst conditions, the diffusion-based methods outperform the centralized method proposed in [
24]. We also observe that all the proposed adaptive combination policies result in improved accuracy and stability. Notably, the policy based on the cost penalty factor consistently delivers the best performance in terms of MAE.
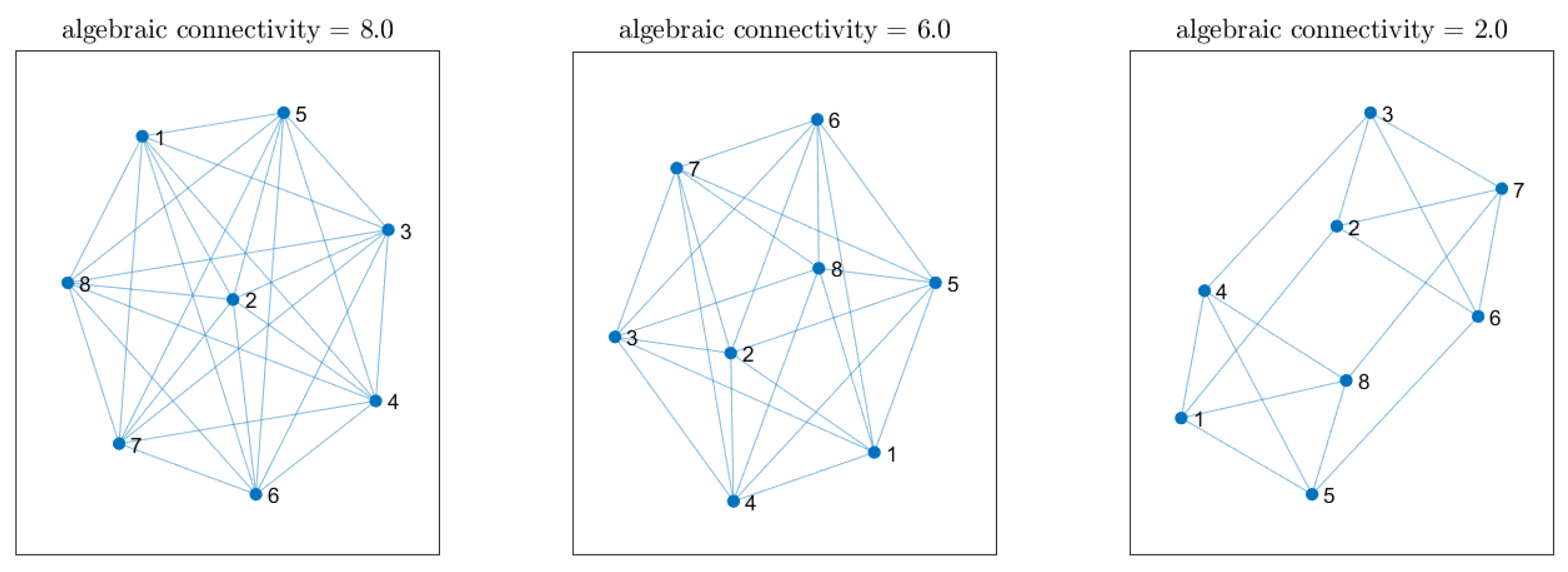
7. Impact of Network Connectivity on Localization Accuracy
We now investigate how the localization performance is influenced by reduced network connectivity. Specifically, we modify the network by reducing the number of neighbors that each node has based on their Euclidean distance. In other words, if the distance between nodes
exceeds a certain threshold, both combination weights
and
are set to zero. Starting from the same array network configuration as in
Section 5.2, we can find three distinct network topologies by gradually decreasing this distance threshold before the network splits into two separate subnetworks. These topologies are depicted in
Figure 11, where self-loops have been omitted to avoid clutter. Their degree of connectivity is quantified by the well-known algebraic connectivity, which is defined as the second smallest eigenvalue of the Laplacian of the combination matrix
[
46]. To assess the overall localization accuracy across different network connectivities, we computed the average MAE as described in the previous section, further averaging the error over every point in a
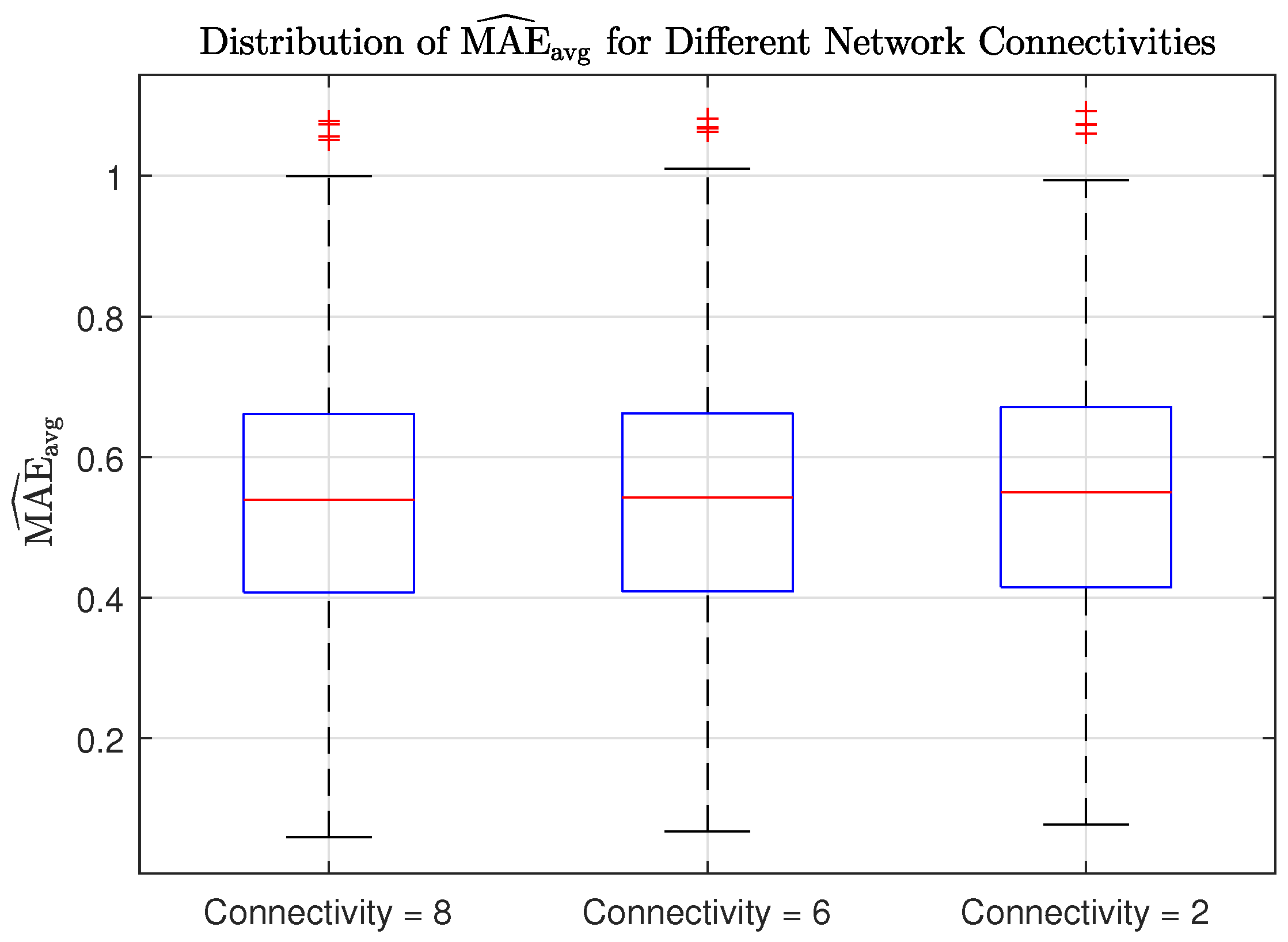
grid of possible source locations. For this experiment, we applied the cost penalty factor.
Figure 12 shows the distribution of MAE values for each network connectivity. The results show that the localization accuracy is not significantly affected by sparser topologies, highlighting the effectiveness of the proposed method. Interestingly, the fully connected networked topology serves as the performance benchmark as it exhibits the highest accuracy.
8. Conclusions and Future Work
In this work, we reformulated the general problem of sound source localization for a network of acoustic arrays as a distributed optimization problem, where the arrays measure streams of acoustic parameters and cooperate to localize a sound source. In particular, we proposed ATC diffusion as a technique for localizing acoustic sources through cooperation between microphone arrays. We also discussed how localization performance can be improved by using different weighting schemes for communication between arrays, which we call combination policies.
As an example, we presented an ATC diffusion-based SSL method that enables 3D localization of a single sound source using 2D direction-of-arrival (DoA) measurements obtained from spatially distributed linear microphone arrays. This approach extends the work in [
38]. Ad hoc combination policies were developed to improve localization accuracy, and all demonstrated superior performance compared to uniform combination policies, where communication links between agents are uniformly weighted. These results hold true for both statistical DoA stream models and simulated acoustic environments. We also showed that stability and convergence properties of the proposed approach can be controlled by the step-size parameters.
Future work will address more complex scenarios with multiple sound sources and different cost functions based on other sound propagation models and acoustic parameters, e.g., TDOAs, acoustic energy, and sound intensity.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}