Abstract
The semantic segmentation (SS) of low-contrast images (LCIs) remains a significant challenge in computer vision, particularly for sensor-driven applications like medical imaging, autonomous navigation, and industrial defect detection, where accurate object delineation is critical. This systematic review develops a comprehensive evaluation of state-of-the-art deep learning (DL) techniques to improve segmentation accuracy in LCI scenarios by addressing key challenges such as diffuse boundaries and regions with similar pixel intensities. It tackles primary challenges, such as diffuse boundaries and regions with similar pixel intensities, which limit conventional methods. Key advancements include attention mechanisms, multi-scale feature extraction, and hybrid architectures combining Convolutional Neural Networks (CNNs) with Vision Transformers (ViTs), which expand the Effective Receptive Field (ERF), improve feature representation, and optimize information flow. We compare the performance of 25 models, evaluating accuracy (e.g., mean Intersection over Union (mIoU), Dice Similarity Coefficient (DSC)), computational efficiency, and robustness across benchmark datasets relevant to automation and robotics. This review identifies limitations, including the scarcity of diverse, annotated LCI datasets and the high computational demands of transformer-based models. Future opportunities emphasize lightweight architectures, advanced data augmentation, integration with multimodal sensor data (e.g., LiDAR, thermal imaging), and ethically transparent AI to build trust in automation systems. This work contributes a practical guide for enhancing LCI segmentation, improving mean accuracy metrics like mIoU by up to 15% in sensor-based applications, as evidenced by benchmark comparisons. It serves as a concise, comprehensive guide for researchers and practitioners advancing DL-based LCI segmentation in real-world sensor applications.
1. Introduction
Semantic segmentation (SS) is a computer vision technique that classifies each pixel in an image into a defined class, enabling the recognition and labeling of different regions in a scene [1]. This technique is pivotal for intelligent systems in automation and robotics, assisting in environmental understanding and supporting professionals in decision-making across applications such as autonomous navigation, medical diagnostics, and industrial quality control [2,3,4,5].
Image contrast, defined as the difference in pixel intensity, significantly influences SS performance [6]. Traditional deep learning (DL) approaches, often based on encoder–decoder architectures [7], excel when images exhibit a balanced intensity distribution, as regions are more distinguishable [8,9]. However, low-contrast images (LCIs) pose a challenge due to their diffuse boundaries and uniform tonal regions, which obscure object outlines and hinder accurate segmentation [10,11].
Conventional SS techniques, such as thresholding and edge detection, struggle in LCI scenarios because they depend on sharp intensity gradients, which are typically absent [10]. For example, in medical ultrasound imaging, tissue boundaries lack clear separation, while in autonomous navigation, low-light conditions blur object edges, often yielding segmentation accuracies below practical thresholds (e.g., Dice Similarity Coefficient (DSC) < 60%) [11]. Enhancing LCI SS is vital for critical applications, including disease diagnosis [12], remote sensing [13], defect detection [14], autonomous vehicles [15], and mineral exploration [16], where sensors like cameras, scanners, and industrial detectors frequently generate LCI, demanding advanced solutions [12,13,14,15,16]. Recent DL innovations improve performance by expanding the Effective Receptive Field (ERF), refining information flow, and capturing contextual features [17]. Techniques such as visual attention mechanisms and Atrous Spatial Pyramid Pooling (ASPP) enlarge the ERF, while dense connections preserve high-resolution details [18,19], and Vision Transformers (ViTs) enhance contextual understanding when paired with Convolutional Neural Networks (CNNs) [20].
This systematic review develops a comprehensive assessment of DL methods tailored for LCI SS, aiming to improve segmentation accuracy in sensor-driven automation and robotics applications. This work contributes a practical solution for addressing LCI challenges, enhancing segmentation performance by up to 15% in mean accuracy metrics (e.g., mIoU) compared to traditional methods, as demonstrated through benchmark evaluations. It evaluates the strengths, limitations, mechanisms, architectures, and practical implementations of these methods, serving as an essential resource for researchers and practitioners in automation and robotics seeking to apply DL to sensor-driven LCI segmentation. Unlike previous reviews that focus on general SS or specific fields (e.g., medical imaging [21]), this work uniquely bridges LCI challenges across diverse sensor-based domains, marking it as the first systematic review of its kind. We compare these DL advancements with traditional methods, assess their implications for automation systems, and propose future research directions, including integration with emerging paradigms like foundation models [3].
The review is organized into eight sections. Section 2 outlines the systematic review methodology, including the process and evaluation tools. Section 3 introduces the selected studies, followed by Section 4, which details DL techniques and their applications for LCIs. Section 5 compares the studies, Section 6 discusses key findings, Section 7 presents conclusions, and Section 8 explores future perspectives.
2. Systematic Review Methodology
This review adopts a methodology based on the framework proposed by [21], which offers a streamlined, reliable approach for conducting computer science reviews. The process follows five stages outlined in [22], summarized below:
Step 1: Framing Questions: Research questions are defined to align the review with its objectives and scope.
Step 2: Identifying Relevant Studies: Studies matching the research questions are sourced using specific inclusion and exclusion criteria.
Step 3: Assessing Study Quality: The rigor, credibility, and relevance of selected studies are evaluated with a standardized checklist.
Step 4: Summarizing Evidence: Key findings are extracted and synthesized to highlight trends, limitations, and research gaps.
Step 5: Interpreting Findings: The synthesized evidence is analyzed to answer the research questions, draw conclusions, and suggest future work.
2.1. Framing Questions for the Review
Defining research questions (RQs) ensures the review meets its goals. Using the PICOC criteria (population, intervention, comparison, outcome, context; see Appendix A), we formulated the following questions:
- RQ1: What is LCI SS?
- RQ2: How does LCI SS benefit automation applications?
- RQ3: Which DL methods are employed in these studies?
- RQ4: How do these studies compare with state-of-the-art approaches?
- RQ5: What are the strengths and weaknesses of the selected studies?
- RQ6: What results do these studies achieve?
- RQ7: What future research opportunities exist for LCI SS?
- RQ8: What dataset limitations affect LCI SS model training, and how well do they represent real-world scenarios?
2.2. Identifying Relevant Studies
Articles were retrieved from academic search engines: Bielefeld Academic Search Engine (BASE), Google Scholar, and Refseek. Search terms were derived from the PICOC criteria’s context, intervention, and population attributes (Appendix A).
Inclusion and exclusion criteria (Appendix B) guided the selection process. We focused on supervised DL methods for SS applied to LCI datasets, published between 2022 and 2024 in Q1 journals (per Journal Citation Reports (JCRs) and SCImago Journal Rank (SJR) metrics). Given the rapid evolution of DL in computer vision, this two-year window ensures that this review captures the most current advancements.
2.3. Assessing the Quality of Studies
Study quality was evaluated using a custom instrument developed by our team (Appendix C), which assesses rigor, relevance, result presentation, and credibility [23]. A Likert-type scale classified studies as high or low quality, ensuring a systematic and reproducible assessment [24].
2.4. Summary and Analysis
After selection, study data were synthesized based on mechanisms, base architectures, application domains, and segmentation performance. This synthesis enabled us to group methods, identify trends, and visualize patterns in LCI SS research, providing a foundation for subsequent analysis.
3. Selected References
This section outlines the selection process and key characteristics of the 25 studies reviewed for the DL-based SS of LCIs. The process, depicted in Figure 1, began with a bibliographic search using keywords derived from the population, intervention, and context attributes of the PICOC criteria (Appendix A). Searches were conducted across three academic engines—Bielefeld Academic Search Engine (BASE), Google Scholar, and RefSeek—with Google Scholar yielding the most results (203 publications).
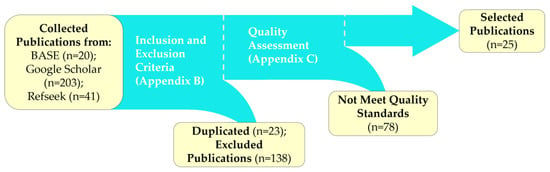
Figure 1.
Schematic of the publication selection process for LCI SS models. Numbers in parentheses indicate publications selected or excluded at each stage.
Next, duplicates were removed, and the inclusion and exclusion criteria (Appendix B) were applied to filter the initial 264 publications. Studies focusing on synthetic images, multitask architectures, 3D convolution modules, or pure machine learning models were excluded, eliminating 161 publications. The remaining 103 studies underwent quality assessment using the checklist in Appendix C. Approximately half were discarded due to misalignment with the review’s core objective—enhancing LCI SS—leaving 25 high-quality studies that specifically address this challenge. Discarded articles are listed in Appendix D.
Figure 2 illustrates the distribution of application domains before (a) and after (b) quality assessment. Medical applications dominate, comprising 45% of initial studies and 59% of final selections, followed by surface defect detection (24% and 17%, respectively). In Figure 2a, the “Others” category includes niche applications like fingerprint segmentation and mail label detection [25,26]. Notably, ref. [27] was categorized under smoke detection, as its primary focus aligns with smoke-related datasets, despite broader applicability.
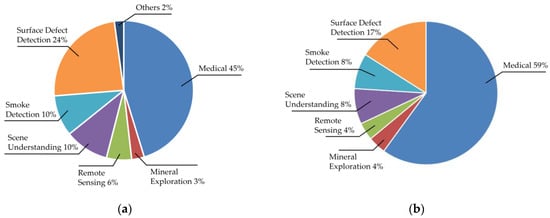
Figure 2.
Pie chart showing application distributions before (a) and after (b) applying the quality assessment checklist.
Table 1 summarizes the 25 selected studies, detailing their architectural types, mechanisms for expanding the ERF, model size (parameters in millions), maximum performance metrics, such as mean Intersection over Union (mIoU) and Dice Similarity Coefficient (DSC). It also includes information on datasets, key highlights, and limitations. (e.g., mean Intersection over Union, Dice Similarity Coefficient), datasets, highlights, and limitations. Studies are grouped by application domain—surface defect, scene understanding, mineral exploration, remote sensing, smoke detection, and medical—to highlight domain-specific trends. “NR” denotes “Not Reported” where data were unavailable. These studies primarily fall into two categories: CNN-based models and hybrid approaches combining CNNs with ViTs or Multi-Layer Perceptron (MLP).

Table 1.
Summary of the key characteristics of the reviewed methods.
4. Deep Learning Method for Low-Contrast Image Segmentation and Applications
The 25 selected studies primarily employ two design approaches: CNN-based models and hybrid architectures integrating CNNs with ViTs and MLPs. This section explores their applications, datasets, baseline architectures, and mechanisms for enhancing the ERF, focusing on how these methods address LCI segmentation challenges in sensor-driven contexts.
4.1. Applications and Datasets
LCI segmentation is critical across diverse sensor-based applications. In medical diagnostics, modalities like magnetic resonance imaging (MRI), ultrasound, and Computed Tomography (CT) produce grayscale images with similar intensities due to tissue uniformity [51]. Similarly, RGB images from colonoscopies and dermoscopy show tonal overlap between lesions and surroundings [52]. In industrial quality control, surface defects (e.g., scratches, cracks) blend with their backgrounds, forming LCIs [53]. Remote sensing images for environmental monitoring, crop analysis, and disaster assessment exhibit LCI traits due to shadows or tonal similarity [54]. Autonomous navigation struggles with nocturnal scenes under limited lighting, merging object tonalities [55]. Smoke detection systems also encounter LCIs, as smoke resembles clouds or fog [56].
Figure 3 shows examples of images and segmented masks from public datasets containing LCIs.
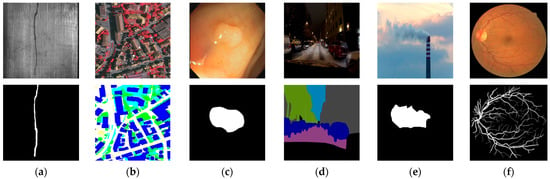
Figure 3.
Examples of LCIs (top) and segmented masks (bottom) from public datasets: (a) MT—crack on a magnetic tile; (b) ISPRS-Potsdam—satellite imagery; (c) CVC-ClinicDB—colonoscopy polyp; (d) NightCity—nighttime driving scene; (e) SmokeSeger—chimney smoke; (f) DRIVE—retinal vessels.
Public datasets with LCI characteristics underpin these applications. Examples include the following:
- AITEX [56]: 245 fabric defect images (e.g., knots, tears) from seven factories.
- MT [57]: 1344 magnetic tile images with six defect types (e.g., cracks), 219 × 264 pixels, and pixel-level annotations.
- TN3K [58]: 3493 ultrasound thyroid nodule images, 421 × 345 pixels, with masks.
- CAMUS [59]: 2D echocardiographic sequences from 500 patients for cardiac analysis.
- SCD [60]: MRI images from 45 patients, segmenting left ventricles in normal and diseased states.
- ISIC-2016 [61]: 1279 dermoscopic images for skin cancer classification (malignant/benign).
- CVC-ClinicDB [62]: 612 colonoscopy images, 384 × 288 pixels, with polyp masks.
- ISPRS-Potsdam [62]: High-resolution (6000 × 6000 pixels) urban satellite images.
- NightCity [63]: 4297 nighttime driving images with pixel-level labels.
- DRIVE [64]: 40 retinal vessel images, 565 × 584 pixels.
Appendix E provides detailed dataset descriptions.
4.2. Design of Reviewed Methods and Baseline Architectures
The reviewed methods fall into two categories: CNN-based and hybrid (CNN + ViT/MLP). CNN-based methods leverage atrous convolution (AC) for ERF expansion, incorporating spatial attention via convolutional operations and channel attention via Squeeze-and-Excitation (SE) modules. Hybrid methods combine CNNs with ViTs for long-range dependencies and MLPs for complex feature representation, enhancing global context capture.
These methods build on state-of-the-art architectures—UNet, DeepLab, and Segformer [65,66,67]—illustrated in Figure 4:
- Unet: Uses skip connections between the encoder and decoder to preserve spatial details (Figure 4a), widely adopted for medical imaging and extended to remote sensing and defect detection. Eighty-seven percent of reviewed methods modify UNet, enhancing feature fusion with dense connections, attention mechanisms, or multi-scale modules.
- Deeplab: Employs an ASPP module in the encoder, merging multi-scale features with the initial feature map (Figure 4b).
- Segformer: Integrates efficient transformer modules with lightweight MLP decoders (Figure 4c).
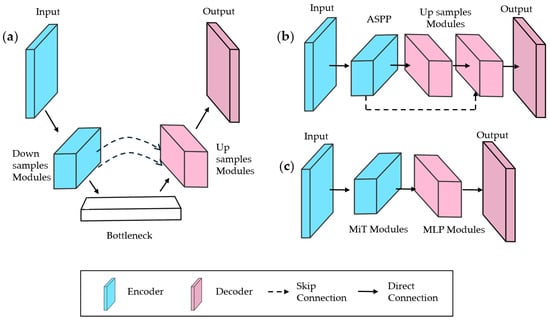
Figure 4.
Simplified schematics of baseline architectures: (a) UNet; (b) DeepLabV3; and (c) Segformer.
Hybrid methods often incorporate ViTs in deeper layers for contextual selection [30,41,42,43,47]. For instance, ref. [50] uses nnUNet [68], a self-configuring UNet variant optimizing preprocessing, training, and post-processing (e.g., resolution, learning rate). In [32], DeepLab and Segformer form a dual-branch encoder, paired with a Retinex-based decomposition decoder [69]. Similarly, ref. [35] combines Segformer and HardNet branches via an MLP, balancing global (transformer) and local (convolutional) features.
4.3. Mechanisms to Enhance the Effective Receptive Field
The ERF defines the image region influencing a pixel’s activation in deep layers, shaped by filter size, stride, and pooling [70,71]. A larger ERF improves LCI SS accuracy by capturing contextual information, reducing noise, and detecting long-range pixel relationships critical for faint edges or similar-textured regions [72,73,74]. Reviewed methods enhance ERF using two strategies: specialized convolutions and attention mechanisms.
4.3.1. Convolutions for Expanding Effective Receptive Field
Figure 5 compares convolution types used to expand ERF while minimizing computational cost [75].
- Dilated Convolution (DC): Adds spacing between kernel elements (Figure 5b), expanding ERF without extra parameters or resolution loss [76]. In [28], serial DCs with varying dilation rates at the bottleneck capture abstract features. In [31], ASPP concatenates DCs, preserving multi-resolution details.
- Depthwise Convolution (DwC): Applies convolution per channel (Figure 5c), often paired with Pointwise Convolution (PwC) in Depth Separable Convolution (DS) to reduce computation and enhance information exchange. In [38], DS with strip convolutions captures directional, multi-scale features.
- Deformable Convolution: In [48], learnable offsets adapt kernels to object shapes, improving flexibility over fixed-rate DCs [77].
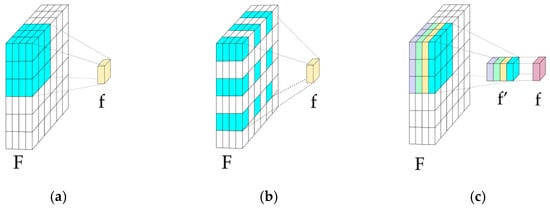
Figure 5.
Convolution types: (a) Traditional; (b) Dilated Convolution (DC); and (c) Depthwise Convolution (DwC). F = input features; f = output features; and f′ = depthwise output.
4.3.2. Attention Mechanisms
Attention mechanisms enhance LCI SS by prioritizing key features and global context, reducing noise from irrelevant regions [78,79]. They include CNN-based modules and ViT/MLP integrations.
CNN-based attention (Figure 6) includes the following:
- Squeeze-and-Excitation (SE): Implements channel attention (Figure 6a) [80]. In [33], four SE + DC branches at the bottleneck filter features, suppressing noise.
- Bottleneck Attention Module (BAM): Processes spatial and channel attention in parallel (Figure 6b), reducing background noise in [29,81].
- Channel Prior Convolutional Attention (CPCA): In [36], refines features sequentially via DwC-enhanced spatial attention (Figure 6c) [82].
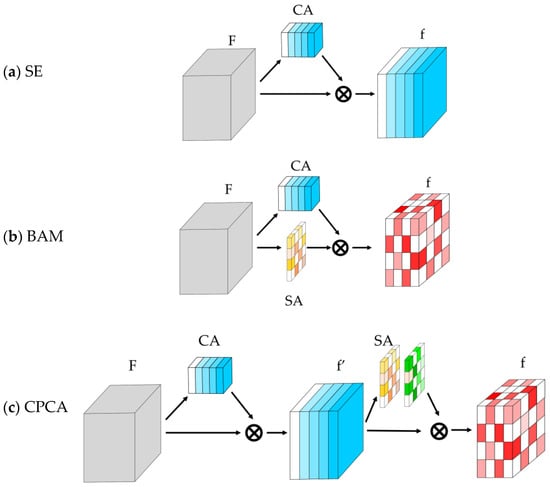
Figure 6.
CNN-based attention modules in the reviewed methods, composed by Channel Attention (CA) and Spatial Attention (SA) modules: (a) Squeeze-and-Excitation (SE); (b) Bottleneck Attention Module (BAM); (c) Channel Prior Convolutional Attention (CPCA). F = input features; f′ = intermediate features; and f = output features. The symbol ⊗ is used to represent element-wise multiplication.
ViT-based Multihead Self-Attention (MHSA) captures long-range dependencies [20]. In [41,42], MHSA applies channel attention in deep layers; Ref. [43] pairs SE with MHSA for a hybrid local–global focus. Swin Transformer variants in [40,47] use residual and star-shaped patches for efficiency [83], while [63] employs MiT for spatial parameter reduction [84]. MLP-based modules in [27] use boundary loss for edge detection, and [44] combines a Spatial Mixer MLP with PwC for channel relationships [85].
4.4. Feature Fusion
Feature fusion in semantic segmentation architectures combines information from multiple levels to boost prediction accuracy and robustness. In low-contrast image segmentation, skip connections are the most common technique, linking encoder and decoder feature maps at matching resolutions (Figure 4a). These connections preserve spatial details, mitigate vanishing gradients, and enhance fusion by integrating low- and high-level features, avoiding poor decoder interpolations [86]. Methods [28,38,39,41] use skip connections with element-wise multiplication or addition for effective feature merging.
However, skip connections face challenges, including local feature redundancy, weak long-range dependency capture, and limited cross-scale integration [87,88,89]. These limitations impair small object detection, edge delineation, and scale adaptability in LCI [34]. To address this, reviewed methods propose enhancements: attention-augmented skip connections [40,41,42] prioritize salient features; specialized blocks [18,34] enable hierarchical interactions for cross-scale fusion; frequency-domain filtering [27] reduces noise; and pyramid and multi-scale designs [29,46,47] improve local–global integration, enhancing accuracy for imbalanced or variable-scale data.
4.5. Implementation of Reviewed Methods
LCI SS methods employ techniques to optimize supervised learning, enhancing training and inference for real-world robustness. These include deep supervision in intermediate decoder layers, preprocessing during inference, and data augmentation to increase dataset diversity.
Figure 7 illustrates the LCSeg-Net model [27], which optimizes kernel weight selection through integrated strategies. These include data augmentation with synthetic masks and images, alongside deep supervision using boundary loss to enhance segmentation accuracy. This combination is reflected across reviewed models, with some adopting all techniques and others focusing on specific elements.
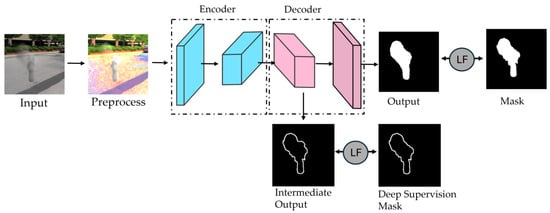
Figure 7.
LCSeg-Net implementation schematic [27]. During training, preprocessed images enter the encoder; intermediate decoder feature maps undergo deep supervision with boundary loss. The final output is refined via a Loss Function (LF) against the ground truth mask. In testing, only the encoder–decoder structure is utilized.
Data augmentation, common across reviewed methods [90], applies transformations like rotation, scaling, and tonal adjustments. Preprocessing varies by method: [48] uses wavelet transformation with multi-frequency sampling; [47] enhances contrast and brightness during inference. CASDD [28] employs a Generative Adversarial Network (GAN) to generate synthetic images, boosting dataset variety and robustness.
Deep supervision is widely adopted: [1,2] apply loss to the original mask, while [3,4] use edge masks with boundary loss. Training splits typically allocate 60–80% of data to training, with the rest for validation and testing. Five-fold cross-validation [91] is used in some studies, rotating validation sets across five cycles. Pretrained backbones (e.g., ImageNet, ADE200) are fine-tuned on study-specific datasets. NVIDIA GeForce RTX 3090 (24 GB VRAM) is the most used GPU, followed by Tesla V100 (16 GB). See Appendix F, Table A5, for details.
4.6. Training of Architectures
Most SS models use the Cross-Entropy (CE) loss function [92] for pixel-level evaluation, as it penalizes small errors heavily, accelerating optimization [31]. Methods [30,39,42] rely solely on CE, while others create hybrid loss functions: Refs. [31,36,38] combine CE with DSC (weighted) for small region emphasis; Refs. [18,33,34] add the Structural Similarity Index Measure (SSIM) or Boundary Loss (BL) for edge focus; Refs. [29,35] use mIoU alone, with [33] blending it with CE for global overlap.
Deep supervision adds auxiliary losses in intermediate layers to guide hierarchical learning [29,31,33]. In [27], it follows signal filtering, comparing features to BL. Hyperparameters include learning rates of 10−5 to 10−3 and batch sizes of 2–20, with the Adaptative Moment Estimation (ADAM) optimizer [93] used in 70% of studies. See Appendix G, Table A6, for details.
5. Study Comparison
5.1. Application Domains and Dataset Availability
LCI SS methods support diverse applications, primarily aiding human decision-making in diagnostics and risk detection. Medical diagnostics dominate, leveraging CT, MRI, and ultrasound for tasks like artery segmentation to detect cardiovascular issues. Other applications include surface defect analysis and smoke/fire detection.
Datasets focus on single-region segmentation, with MT (magnetic tiles surface defects) and ISIC (skin lesions) being the most popular public datasets. Smoke detection datasets are scarce, with only the smoke semantic segmentation (SSS) dataset noted. Four studies created custom datasets across medical, scene understanding, mineral exploration, surface defect, and smoke categories, each with one dataset, highlighting data scarcity (RQ8).
5.2. Methodology and Design of the Reviewed Studies
CNN and hybrid methods adapt established architectures—UNet, DeepLab, and Segformer—to optimize LCI SS. UNet dominates, used in 87% of studies, reflecting its prevalence in medical applications, the most common domain reviewed. These DL methods enhance inference accuracy by refining base architectures with strategies that integrate local and global feature capture and fusion, often incorporating attention mechanisms to filter spatial and channel features.
Hybrid architectures combine CNNs, ViTs, and MLPs to leverage their complementary strengths. CNNs excel at local feature extraction with a high inductive bias [94], while ViTs and MLPs capture global context, offering greater implementation flexibility.
No architectural distinctions exist between single- and multi-region segmentation in either CNN or hybrid methods. The focus remains on modular techniques, such as attention and multi-scale designs, to address LCI SS challenges effectively.
5.3. Training and Implementation of the Reviewed Methods
Per [95], non-pretrained CNNs need ~10,000 samples for optimal crack segmentation performance without augmentation. LCI datasets face challenges: limited availability, sparse annotations, class imbalance, variable scales, and low resolution [96,97]. Data augmentation (e.g., 750 to 2400 samples [98]) and pretraining improve robustness and DSC (>80%). Hybrid methods benefit most from augmentation, as ViTs require large datasets due to low inductive bias.
Hybrid loss functions dominate, with CE leading for convergence and class imbalance handling. Five-fold cross-validation aids small datasets (<20 samples). GPU needs vary by model size: UNet (28 M parameters) requires 4 GB VRAM, UNETR (133 M) needs 24 GB [99]. Most reviewed methods (<45 M parameters) use 6 GB VRAM; RNightSeg [32] and FDR-TransUNet [41] (>100 M) require 24 GB (RQ5, RQ6).
5.4. Performance of the Reviewed Methods
Inference accuracy, measured primarily by mIoU and DSC, is the key evaluation metric for the reviewed methods. All 25 methods surpass their baseline architectures, achieving mIoU and DSC values above 80% in most cases, demonstrating robust LCI segmentation performance.
Figure 8 illustrates performance against UNet: CoVi-Net [39] exceeds UNet by ~15% DSC, excelling at fine corneal vessel segmentation, while TBNet [45] improves by <1%, targeting corneal endothelium cells. Both highlight strengths in fine-structure detection.
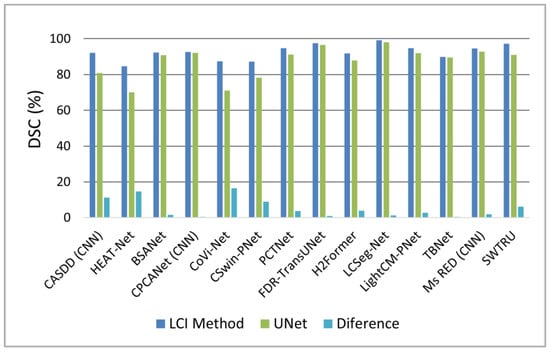
Figure 8.
Bar chart comparing chart comparing Dice Similarity Coefficient (DSC) of reviewed methods to UNet, based on the best-performing dataset for each method.
Figure 9 compares performance across public datasets: Figure 9a for surface defect datasets (MT, NEU, RSDD) shows LCSeg-Net [27] achieving DSC > 90% with <25 M parameters and Figure 9b for skin lesion datasets (ISIC, PH2) reveals SWTRU [47] surpassing 95% DSC, with Ms RED [46] being competitive at <10 M parameters despite a smaller model size.
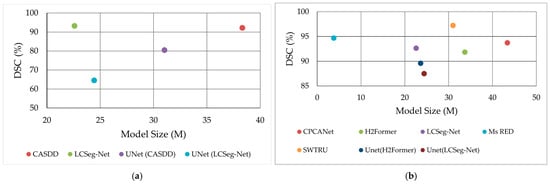
Figure 9.
Dice Similarity Coefficient (DSC) of reviewed methods on (a) surface defect (MT, NEU, RSDD) and (b) skin lesion (ISIC, PH2) datasets, plotted against model size. Datasets within each category share similar LCI characteristics.
Figure 10 presents qualitative comparisons: [42] (fine structures) and [35] (robust structures) outperform their baselines (UNet and Segformer, respectively), showing sharper LCI segmentation.

Figure 10.
Qualitative results. (1) Results presented in [42]; (2) results presented in [35]. (a) Original Image; (b) ground truth; (c) LCI method; and (d) baseline (Top: UNet; Bottom: SegFormer).
Two outliers underperform: TBNet [45] achieves 63.9% mIoU due to limited, imbalanced data; RNightSeg [32] scores 57.9% mIoU, impacted by complex night scenes with light flares and fine details. Model size typically increases over baselines, with added modules raising parameter counts, computational complexity, and training time. Inference time, reported in nine studies, varies with hardware: LCSeg-Net [27] achieves 40–70 fps (real-time), while most others average < 1 fps, reflecting GPU diversity (e.g., RTX 3090, Tesla V100).
6. Discussion
This review’s methodology, adapted from [21], ensures a systematic, efficient analysis by integrating tools for study selection, quality assessment, and data synthesis. This structured approach enhances rigor, transparency, and reproducibility, distinguishing it from narrative reviews like [100] that lack standardization. The quality assessment (Appendix C) proved critical, with criterion 1.3—requiring explicit focus on LCI segmentation—acting as the most effective filter for ensuring relevance and credibility.
DL methods outperform traditional techniques in LCI segmentation. For instance, K-means and Gaussian Mixture Models (GMMs) achieve < 70% accuracy in breast lesion segmentation [101], while thresholding maximum principal strain maps yields < 50% DSC in crack segmentation [102]. Reviewed DL methods, mostly hybrid, leverage CNNs, ViTs, and MLPs: CNNs capture local features with high inductive bias, ViTs excel at contextual understanding, and MLPs model nonlinear feature relationships, yielding DSC and mIoU > 80% (Section 5.4).
Architectural designs target LCI challenges universally, using techniques like attention mechanisms and multi-scale fusion (Section 4). Methods like PCTNet [30] and GT-DLA-dsHFF [42] excel at fine structures (e.g., vessels, cracks), yet no distinction exists between single- and multi-region segmentation designs. This flexibility, as shown in [103], allows single-region datasets to support multi-region extraction via probabilistic modules and trainable classifiers, suggesting adaptability across tasks.
Most methods use non-pretrained models, despite LCI dataset scarcity (Section 5.3). Pretrained models could enhance performance: LCSeg-Net [27] and PCTNet [30] leverage ResNet-34 pretrained on ImageNet-10K and ADE20K, though these datasets feature balanced contrast. MedSAM [104], pretrained on 1.5 million medical LCI images, offers a promising alternative for automated diagnostics, addressing data limitations (RQ8).
Ethical, social, and legal implications of AI-assisted decision-making are significant. Human–machine collaboration is growing [105], raising concerns about accountability for errors and penalty allocation [106]. Future LCI SS research must prioritize transparency to build trust in automation applications (Section 8).
7. Conclusions
This systematic review comprehensively assessed recent DL advancements for the SS of LCIs, offering a detailed evaluation of their strengths and limitations across diverse applications. Hybrid architectures integrating CNNs and ViTs, enhanced by attention mechanisms, have proven exceptionally effective at tackling the inherent challenges of LCI segmentation, such as diffuse edges and tonal similarities that obscure object boundaries. These methods leverage CNNs’ ability to extract local spatial details and ViTs’ capacity to capture global contextual relationships, resulting in superior performance over traditional approaches. Multi-scale processing and ERF expansion further boost accuracy in complex scenes (Section 4), enabling models to adapt to varying object scales and intricate backgrounds often encountered in LCI scenarios. Among the standout methods, SWTRU achieves top-tier performance in medical segmentation, excelling at delineating fine anatomical structures critical for diagnostics; Ms RED stands out with the smallest model size, offering an efficient solution without compromising accuracy; and LCSeg-Net enables real-time inference, demonstrating robustness across multiple domains with processing speeds suitable for practical deployment (Section 5.4). These examples highlight the diversity of innovations, from high-precision medical applications to resource-efficient and time-sensitive industrial or autonomous systems.
Despite significant progress in accuracy and robustness, several persistent challenges underscore the need for further development. The scarcity of diverse, large-scale LCI datasets remains a critical bottleneck, limiting model training and generalization across varied real-world conditions (RQ8). This data scarcity is particularly pronounced in domains like smoke detection and mineral exploration, where public datasets are rare, forcing reliance on small or custom datasets that may not fully represent operational complexities. Additionally, the high computational demands of transformer-based models pose a barrier, requiring substantial processing power and memory that may not be feasible in resource-constrained environments, such as edge devices or mobile platforms. The limited availability of real-time solutions exacerbates this issue, as most methods struggle to achieve the speed necessary for applications like autonomous navigation or industrial monitoring, where immediate decision-making is essential. These challenges collectively hinder the scalability and accessibility of LCI SS, particularly in settings where computational resources or annotated data are sparse.
DL significantly enhances LCI SS across a wide range of sensor-driven domains, including medical imaging, autonomous driving, industrial inspection, and remote sensing, transforming how intelligent systems interpret challenging visual data. In medical imaging, it enables the precise detection of subtle tissue boundaries, supporting earlier and more accurate diagnoses. In autonomous driving, it improves scene understanding under poor lighting, enhancing safety and reliability. Industrial inspection benefits from better defect detection on uniform surfaces, ensuring quality control, while remote sensing gains from improved environmental analysis despite shadows or tonal overlap. Yet, to fully unlock this potential, optimizations are critical in three key areas: computational efficiency, data availability, and model interpretability (Section 6). Efficiency improvements could democratize access to these technologies, making them viable for smaller organizations or low-power devices. Enhanced data availability, through expanded datasets or synthetic generation, would strengthen model robustness, reducing overfitting and improving adaptability. Greater interpretability would build trust, especially in safety-critical applications, by clarifying how models reach their segmentation decisions. Together, these advancements promise to bridge current gaps, paving the way for broader adoption and impact in automation and robotics.
8. Future Perspectives
This review identifies key research directions to advance LCI SS:
- Computational Efficiency: Developing lightweight, energy-efficient transformer architectures is essential for real-time deployment. Techniques like quantization, knowledge distillation, and pruning can cut computational costs without sacrificing performance (RQ7).
- Dataset Expansion and Augmentation: Limited high-quality, annotated LCI datasets hinder progress (Section 5.3). Future efforts should create diverse, large-scale datasets spanning multiple domains. Advanced augmentation, such as synthetic image generation, can address data scarcity, including enhancing image sharpness to aid segmentation (RQ8).
- Self-Supervised and Few-Shot Learning: Reducing reliance on labeled data, self-supervised and few-shot learning can improve generalization with minimal supervision, such as correlating pixels across classes for enhanced segmentation (RQ7).
- Real-Time and Mobile Deployment: Enhancing real-time performance on resource-limited devices is vital. Efficient baseline frameworks and mobile-optimized architectures can balance performance and deployability (RQ7).
- Integration of Multimodal Sensor Data: Fusing LCI with modalities like LiDAR, thermal, or hyperspectral data can improve accuracy in challenging conditions. Developing models to leverage multimodal inputs is a priority (RQ7).
- Ethics, Interpretability, and Explainability: As DL influences safety-critical decisions, transparency and trust are paramount. Explainable AI techniques must illuminate model decisions, especially in medical and autonomous navigation contexts (Section 6).
Addressing these gaps will drive LCI SS forward, enhancing performance and enabling broader sensor-driven applications.
Author Contributions
Conceptualization, C.U. and M.V.; methodology, C.U. and M.V.; formal analysis, C.U. and M.V.; investigation, C.U. and M.V.; resources, C.U. and M.V.; data curation, C.U. and M.V.; writing—original draft preparation, C.U. and M.V.; writing—review and editing, C.U. and M.V.; visualization, C.U. and M.V.; supervision, C.U.; project administration, C.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
This work has been supported by the Faculty of Engineering of the University of Santiago of Chile, Chile.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations, listed in alphabetical order, are used in this manuscript:
| ADAM | Adaptative Moment Estimation |
| AI | Artificial Intelligence |
| A-MLP | Axial MLP Attention |
| AC | Atrous Convolution |
| AIAB | Aggregation Inhibition Activation Block |
| ASPP | Atrous Spatial Pyramid Pooling |
| BAM | Bottleneck Attention Mechanism |
| BASE | Bielefeld Academic Search Engine |
| BCEn | Brightness and Contrast Enhancement |
| BL | Boundary Loss |
| BSANet | Boundary-aware and Scale-Aggregation Network |
| CA | Channel Attention |
| CAMUS | Cardiac Acquisitions for Multi-structure Ultrasound Segmentation |
| CASDD | Complementary Adversarial Network-Driven Surface Defect Detection |
| CBAM | Convolutional Block Attention Mechanism |
| CE | Cross Entropy |
| CED | Canny Edge Detection |
| CFD | Crack Forest Dataset |
| C-MLP | Channel MLP Attention |
| CNNs | Convolutional Neural Networks |
| CPCA | Channel Prior Convolutional Attention |
| CPCANet | Channel Prior Convolutional Attention Network |
| CSwin-PNet | CNN-Swin Transformer Pyramid Network |
| CT | Computed Tomography |
| CV | Computer Vision |
| CVC-ClinicDB | Computer Vision Center Clinic Database |
| FAM-CRFSN | Fuse Attention Mechanism’s Coal Rock Full-Scale Network |
| DA | Dual Attention |
| DCs | Dilated Convolutions |
| DeC | Deformable Convolution |
| DL | Deep Learning |
| DRIVE | Digital Retinal Images for Vessel Extraction |
| DS | Depth Separable Convolution |
| DSC | Dice Similarity Coefficient |
| DwC | Depthwise Convolution |
| EMRA-Net | Edge and Multi-scale Reverse Attention Network |
| ERF | Effective Receptive Field |
| FAM-CRFSN | Fuse Attention Mechanism’s Coal Rock Full-Scale Network |
| FDR-TransUnet | Feature double reuse Transformer Unet |
| FL | Focal Loss |
| GANs | Generative Adversarial Networks |
| GMM | Gaussian Mixture Models |
| GPU | Graphic Processing Unit |
| GT-DLA-dsHFF | Global Transformer and Dual Local Attention Network via Deep-Shallow Hierarchical Feature Fusion |
| GVANet | Grouped Multiview Aggregation Network |
| HEAT-Net | Hybrid Enhanced Attention Transformer |
| H2Former | Hierarchical Hybrid Vision Transformer |
| ISIC | International Skin Imaging Collaboration |
| ISPRS | International Society for Photogrammetry and Remote Sensing |
| JCR | Journal Citation Reports |
| LCI | Low-Contrast Images |
| LCSeg-Net | Low-Contrast Segmentation Network |
| LF | Loss Function |
| LI | Linear Interpolation |
| MC | Multi-Cross Attention |
| MF | Median Filter |
| MHSA | Multi Head Self Attention |
| mIoU | mean Intersection Over Union |
| MLP | Multi-Layer Perceptron |
| mPa | Mean Pixel Accuracy |
| MRI | Magnetic Resonance Imaging |
| Ms RED | Multi-scale Residual Encoding and Decoding Network |
| MT | Magnetic Tile |
| PCTNet | Pixel Crack Transformer Network |
| PICOC | Population/Problem, Intervention, Comparison, Outcome, Context |
| PPL | Progressive Perception Learning |
| PwC | Pointwise Convolution |
| RA | Reverse Attention |
| RQ | Research Question |
| RNightSeg | Retinex Night Segmentation |
| RMSProp | Root Mean Square Propagation |
| SA | Spatial Attention |
| SE | Squeeze-and-Excitation |
| SGD | Stochastic Gradient Descent |
| SPA | Spatial Pyramid Attention |
| SPP | Spatial Pyramid Pooling |
| SS | Semantic Segmentation |
| SSIM | Structural Similarity Index Measure |
| STCNet II | Slab Track Crack Network II |
| SJR | SCImago Journal Rank |
| SWTRU | Star-shaped Window Transformer Reinforced U-Net |
| TBNet | Transformer-embedded Boundary Perception Network |
| TD-Net | Trans-Deformer Network |
| WD | Wavelet Decomposition |
| ViTs | Visual Transformers |
Appendix A. PICOC Criteria
Table A1.
PICOC criteria implemented in the present review.
Table A1.
PICOC criteria implemented in the present review.
| Attributes | Keywords | Related |
|---|---|---|
| Population | LCI Datasets | Blurry Images, Diffuse Images, Poor Light Scenes |
| Intervention | SS Architectures with attention mechanism | Channel Attention, Spatial Attention |
| SS Architecture with skip and dense connections | Unet, DenseNet, HRNet | |
| SS Architectures with atrous convolutions | Dilatated Convolution, ASPP, Deeplab, PSPNet | |
| SS Hibrid Architecture | Unext, Swin-Unet | |
| Comparison | SS CNN-pure architectures | FCN, AlexNet, VGG |
| SS Transformer-pure architectures | ViT, EfficientViT | |
| Outcome | Inference Accuracy | mIoU, DSC |
| Inference Speed | FLOPs, Latency | |
| Context | Diseases Diagnosis | CT Images Analysis |
| Autonomous Vehicles | Scene SS | |
| Remote Sensing | Cloud and Snow SS | |
| Surface Defect Detection | Surface Anomaly Detection | |
| Mineral Exploration | Mineral Prospecting | |
| Smoke Detection | Initial Fire Detection |
Appendix B. Inclusion and Exclusion Criteria
Table A2.
Inclusion and exclusion criteria applied to publications found in the selected repositories and search engines.
Table A2.
Inclusion and exclusion criteria applied to publications found in the selected repositories and search engines.
| Criteria Type | Inclusion | Exclusion |
|---|---|---|
| Period | Publications from 2022 onwards | Publications before 2022 |
| Language | Publications in English | Publications other than English Language |
| Type of Source | Peer-reviewed journal articles | Conference proceedings, technical reports, books, dissertations, and non-peer-reviewed works |
| Impact Source | Journals ranked in Q1 (based on JCR or SJR metrics) | Journals ranked in Q2–Q4 (or not indexed in JCR or SJR) |
| Accessibility | Studies available in BASE, Google Scholar and Refseek. | Studies not available in BASE, Google Scholar and Refseek. |
| Research Focus | DL techniques | Classical machine learning techniques |
| Supervised learning approaches | Unsupervised or self-supervised learning approaches | |
| Studies focusing on image-based semantic segmentation | Studies focusing on video segmentation or synthetic data or other computer vision task |
Appendix C. Quality Assessment Checklist
Table A3.
Instrument used to evaluate the rigor, relevance, presentation of results, and credibility of the selected publications after applying the inclusion and exclusion criteria.
Table A3.
Instrument used to evaluate the rigor, relevance, presentation of results, and credibility of the selected publications after applying the inclusion and exclusion criteria.
| Judgement Criteria | Options | |
|---|---|---|
| 1. Scope and Objectives | 1.1. Is the review scope clearly defined? | Yes: The review scope is clearly defined, focusing on DL methods for low-contrast images. |
| No: The scope is unclear, other or not defined. | ||
| 1.2. Are the research questions aligned with the objectives? | Yes: The research questions align with the defined objectives and address key issues. | |
| No: The questions are not aligned with the objectives or are missing. | ||
| 1.3. Does the objective of the DL methods explicitly focus on segmenting datasets composed of low-contrast images of real-world applications? | Yes: The objective explicitly addresses the segmentation of low-contrast images using DL methods for real-world applications. | |
| No: The objective does not explicitly address the segmentation of datasets composed of low-contrast images using DL methods or focuses on other topics related to datasets composed of low-contrast images for real-world applications. | ||
| 2. Methodology | 2.1. Are the method described in sufficient detail? | Yes: The methods are well-described, highlighting key components and relevance to low-contrast images. |
| No: The architectures are not described or descriptions are incomplete. | ||
| 2.2. Are the methods compared with deep learning state-of-the-art models? | Yes: The methods are adequately compared with state-of-the-art models, with results clearly contextualized. | |
| No: No comparison is made. | ||
| 2.3 Are the selected datasets suitable for the supervised training of the models? | Yes: The selected datasets are suitable for the supervised training of the models. | |
| No: The selected datasets are not suitable for the supervised training of the models. | ||
| 3. Performance Evaluation | 3.1. Does the review discuss performance? | Yes: Performance in low-contrast scenarios is clearly discussed with relevant metrics and analysis. |
| No: This aspect is not addressed. | ||
| 3.2. Are standard semantic segmentation indexes used to evaluate the performance of the method? | Yes: Standard indexes are used for evaluation. | |
| No: Standard indexes are not used for evaluation. | ||
| 4. Challenges | 4.1. Are the proposed future directions related to the method? | Yes: Clear and relevant future directions are proposed, considering current challenges. |
| No: No future directions are proposed or are vague. | ||
| 4.2. Are the limitations of the method discussed? | Yes: Limitations are discussed. | |
| No: No limitations are discussed or are vague. | ||
| Verdict | High Quality | All judgments are Yes. |
| Low Quality | At least one of the responses is No. |
Appendix D. Publications Excluded After Quality Assessment
Table A4.
Classification of the excluded publications based on the judgment criteria number they did not meet from quality assessment checklist.
Table A4.
Classification of the excluded publications based on the judgment criteria number they did not meet from quality assessment checklist.
| Publications | Judgment Criteria Number |
|---|---|
| [107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147] | 1.3 |
| [148] | 2.1 |
| [149] | 3.2 |
| [15,150,151,152,153,154,155,156,157,158,159,160,161,162,163] | 4.1 |
| [164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184] | 4.2 |
Appendix E. Public Dataset for Low-Contrast Semantic Segmentation
Table A5.
Characteristics of some public datasets used by the methods in the reviewed publications.
Table A5.
Characteristics of some public datasets used by the methods in the reviewed publications.
| Dataset | Ref. | Utilized by | Segmentation Performance (%) | Image Resolution | Image Count | Segmented Object |
|---|---|---|---|---|---|---|
| AITEX | [56] | [29] | 82.56 (mIoU) | 4096 × 256 | 245 | Textile defect |
| MT | [57] | [29] | 83.75 (mIoU) | 219 × 264 | 1344 | Magnetic tile surface defects |
| TN3K | [58] | [36] | 89.5 (DSC) | 421 × 345 | 3493 | Thyroid nodules |
| CAMUS | [59] | [36] | 92.2 (DSC) | 512 × 512 | 2000 | Breast lesion |
| SCD | [60] | [37] | 92.39 (DSC) | 512 × 512 | 805 | Left ventricle |
| ISIC 2016 | [61] | [38] | 93.7 (DSC) | 1504 × 1129 | 1279 | Skin Lesion |
| CVC-ClinicDB | [52] | [27] | 95.82 (DSC) | 384 × 288 | 612 | Colon polyps |
| ISPRS-Potsdam | [62] | [34] | 93.29 (DSC) | 6000 × 6000 | 38 | City objects |
| Nightcity | [63] | [32] | 57.91 (mIoU) | 1024 × 512 | 4297 | City objects |
| DRIVE | [64] | [42] | 86.5 (DSC) | 565 x 684 | 40 | Retinal Vessels |
Appendix F. Implementation Details of Reviewed Methods
Table A6.
Key parameters for the implementation of the reviewed methods. In ‘Dataset division’, three values indicate the order training/validation/test, while two values represent training/validation. Minimum training set size refers to the number of samples used for training from the dataset with the fewest data. CVa indicates the cross-validation method, with the accompanying number representing the number of folds implemented. DAg: data augmentation; MF: Median Filter; LI: Linear Interpolation; CED: Canny Edge Detection; WD: Wavelet Decomposition; NR: Not Reported; NA: Not Applicable.
Table A6.
Key parameters for the implementation of the reviewed methods. In ‘Dataset division’, three values indicate the order training/validation/test, while two values represent training/validation. Minimum training set size refers to the number of samples used for training from the dataset with the fewest data. CVa indicates the cross-validation method, with the accompanying number representing the number of folds implemented. DAg: data augmentation; MF: Median Filter; LI: Linear Interpolation; CED: Canny Edge Detection; WD: Wavelet Decomposition; NR: Not Reported; NA: Not Applicable.
| Ref. | Name | Data Preprocessing | Dataset Division (%) | Minimum Training Set Size | Nvidia GPU Model | VRAM |
|---|---|---|---|---|---|---|
| [28] | CASDD | Dag + GAN | 80/15/5 | 750 | GeForce RTX 2060 | 6 |
| [29] | EMRANET | NA | 80/20 | 145 | GeForce GTX 1660 | 6 |
| [30] | PCTNet | DAg | 80/20 | 685 | GeForce RTX 3090 | 24 |
| [31] | STCNet II | DAg | 80/10/10 | 800 | GeForce RTX 3080Ti | 12 |
| [18] | NR | MF + LI | 70/15/15 | 2205 | GeForce rtx 2080 ti | 11 |
| [32] | RNightSeg | DAg | 70/30 | 320 | GeForce RTX 3090 | 24 |
| [33] | FAM-CRFSN | DAg | NR | NR | GTX 1650 Ti | 16 |
| [34] | GVANet | DAg | 60/40 | 19 | GeForce RTX 2080 Ti | 11 |
| [27] | LCSeg-Net | Dag + CED | 80/10/10 | 489 | GeForce RTX 3090 | 24 |
| [35] | SmokeSeger | DAg | 80/20 | 332 | Tesla V100 | 16 |
| [36] | HEAT-Net | DAg | 5 CVa | 33 | Tesla V100 | 16 |
| [37] | BSANet | DAg | 70/10/20 | 32 | GeForce RTX 3090 | 24 |
| [38] | CPCANet | DAg | 70/10/20 | 630 | GeForce RTX 3090 | 24 |
| [39] | CoVi-Net | DAg | 10 CVa | 18 | GeForce RTX 3090 | 24 |
| [40] | CSwin-PNet | NA | 60/20/20 | 754 | GeForce RTX 3080 | 10 |
| [41] | FDR-TransUNet | DAg | 60/20/20 | 1750 | GeForce RTX 3090 | 24 |
| [42] | GT-DLA-dsHFF | DAg | 4CVa | 15 | Tesla V-100 | 16 |
| [43] | H2Former | DAg | 70/10/20 | 20 | GeForce RTX 3090 | 24 |
| [44] | LightCM-PNet | IN | 5 CVa | 88 | Quadro RTX6000 | 24 |
| [45] | TBNet | Dag + CED | 5 CVa | 24 | GeForce TITAN XP | 12 |
| [46] | Ms RED | DAg | 80/20 | 80 | GeForce RTX 2080Ti | 11 |
| [47] | SWTRU | EBC | 70/20/10 | 1815 | GeForce RTX 3090 | 24 |
| [48] | TD-Net | WD | 75/25 | 80 | GeForce RTX3090 | 24 |
| [49] | PPL | DAg | 80/20 | 3712 | Tesla V100 | 32 |
| [50] | U-NTCA | NA | 5 CVa | 108 | GeForce RTX3090 | 24 |
Appendix G. Training Details of Reviewed Methods
Table A7.
Key parameters for training the reviewed methods: CE: Cross Entropy; mIoU: mean Intersection over Union; DSC: Dice Similarity Index; BL: boundary oss; SSIM: Structural Similarity Index; SGD: Stochastic Gradient Descent; RMSProp: Root Mean Square Propagation; A: Applicable; NA: Not Applicable.
Table A7.
Key parameters for training the reviewed methods: CE: Cross Entropy; mIoU: mean Intersection over Union; DSC: Dice Similarity Index; BL: boundary oss; SSIM: Structural Similarity Index; SGD: Stochastic Gradient Descent; RMSProp: Root Mean Square Propagation; A: Applicable; NA: Not Applicable.
| Ref. | Name | Loss Function | Maximum Learning Rate (10−3) | Batch Size | Epoch | Deep Supervision | Optimization Algorithms | Pretrained Model |
|---|---|---|---|---|---|---|---|---|
| [28] | CASDD | CE | 0.1 | NR | NR | NA | Adam | NA |
| [29] | EMRANET | mIoU | 0.5 | 4 | 100 | A | Adam | A |
| [30] | PCTNet | CE | 0.045 | 2 | NR | NA | Adam | A |
| [31] | STCNet II | CE + DSC | 0.1 | 10 | NR | A | Adam | NA |
| [18] | NR | CE + SSIM | 0.1 | 16 | 120 | NA | Adam | NA |
| [32] | RNightSeg | CE | 0.06 | 16 | 80,000 | NA | Adam | A |
| [33] | FAM-CRFSN | CE + mIoU + SSIM | 0.1 | NR | 50 | A | Adam | NA |
| [34] | GVANet | CE + DSC | 0.6 | NR | 105 | NA | Adam | A |
| [27] | LCSeg-Net | CE + DSC + BL | 0.1 | 8 | 50 | A | Adam | A |
| [35] | SmokeSeger | mIoU | 1 | 12 | 40,000 | A | SGD | A |
| [36] | HEAT-Net | CE + DSC | 1 | 4 | 500 | NA | NR | NA |
| [37] | BSANet | DSC | 1 | 8 | 200 | NA | Adam | NA |
| [38] | CPCANet | CE + DSC | 5 | 33 | 250 | NA | Adam | NA |
| [39] | CoVi-Net | CE | 1 | 4 | 150 | NA | Adam | NA |
| [40] | CSwin-PNet | CE + DSC | 0.1 | 4 | 200 | A | Adam | A |
| [41] | FDR-TransUNet | CE | 0.3 | 4 | 100 | A | Adam | NA |
| [42] | GT-DLA-dsHFF | CE | 1 | 2 | 100 | NA | Adam | NA |
| [43] | H2Former | CE + DSC | 0.1 | 18 | 90 | NA | Adam | A |
| [44] | LightCM-PNet | CE + DSC + BL | 1 | 8 | 100 | NA | Adam | NA |
| [45] | TBNet | CE | 0.2 | 1 | 100 | NA | RMSProp | NA |
| [46] | Ms RED | CE + DSC | 1 | NR | 250 | NA | Adam | NA |
| [47] | SWTRU | CE | 0.4 | 16 | 200 | NA | RMSProp | NA |
| [48] | TD-Net | CE + DSC | 0.1 | 8 | 30 | A | Adam | NA |
| [49] | PPL | BL | 0.2 | 8 | 50 | NA | Adam | NA |
| [50] | U-NTCA | CE + DSC | 5 | 33 | 250 | NA | Adam | NA |
References
- Lei, T.; Nandi, A.K. Image Segmentation; Wiley: Hoboken, NJ, USA, 2022; ISBN 9781119859000. [Google Scholar]
- Muhammad, K.; Hussain, T.; Ullah, H.; Ser, J.D.; Rezaei, M.; Kumar, N.; Hijji, M.; Bellavista, P.; de Albuquerque, V.H.C. Vision-Based Semantic Segmentation in Scene Understanding for Autonomous Driving: Recent Achievements, Challenges, and Outlooks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22694–22715. [Google Scholar] [CrossRef]
- Garg, S.; Sünderhauf, N.; Dayoub, F.; Morrison, D.; Cosgun, A.; Carneiro, G.; Wu, Q.; Chin, T.-J.; Reid, I.; Gould, S.; et al. Semantics for Robotic Mapping, Perception and Interaction: A Survey. Found. Trends Robot. 2020, 8, 1–224. [Google Scholar] [CrossRef]
- Yang, R.; Yu, Y. Artificial Convolutional Neural Network in Object Detection and Semantic Segmentation for Medical Imaging Analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Dong, C.-Z.; Catbas, F.N. A Review of Computer Vision–Based Structural Health Monitoring at Local and Global Levels. Struct. Health Monit. 2021, 20, 692–743. [Google Scholar] [CrossRef]
- Avatavului, C.; Prodan, M. Evaluating Image Contrast: A Comprehensive Review and Comparison of Metrics. J. Inf. Syst. Oper. Manag. 2023, 17, 143–160. [Google Scholar]
- Islam, M.M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]
- Wieland, M.; Martinis, S.; Kiefl, R.; Gstaiger, V. Semantic Segmentation of Water Bodies in Very High-Resolution Satellite and Aerial Images. Remote Sens. Environ. 2023, 287, 113452. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A Comparative Study of Semantic Segmentation Models for Identification of Grape with Different Varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- Javed, R.; Shafry Mohd Rahim, M.; Saba, T.; Mohamed Fati, S.; Rehman, A.; Tariq, U. Statistical Histogram Decision-Based Contrast Categorization of Skin Lesion Datasets Dermoscopic Images. Comput. Mater. Contin. 2021, 67, 2337–2352. [Google Scholar] [CrossRef]
- Xu, Y.; Dang, H.; Tang, L. KACM: A KIS-Awared Active Contour Model for Low-Contrast Image Segmentation. Expert Syst. Appl. 2024, 255, 124767. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, Z.; Wang, S.; Chen, X.; Lu, G. Coronary Angiography Image Segmentation Based on PSPNet. Comput. Methods Programs Biomed. 2021, 200, 105897. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Hu, C.; Luo, S.; Luo, Y.; Chen, C.W. Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 595–609. [Google Scholar] [CrossRef] [PubMed]
- Usamentiaga, R.; Lema, D.G.; Pedrayes, O.D.; Garcia, D.F. Automated Surface Defect Detection in Metals: A Comparative Review of Object Detection and Semantic Segmentation Using Deep Learning. IEEE Trans. Ind. Appl. 2022, 58, 4203–4213. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Leichter, A.; Almeev, R.R.; Wittich, D.; Beckmann, P.; Rottensteiner, F.; Holtz, F.; Sester, M. Automated Segmentation of Olivine Phenocrysts in a Volcanic Rock Thin Section Using a Fully Convolutional Neural Network. Front. Earth Sci. 2022, 10, 740638. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, J.; Han, Y. Understanding the Effective Receptive Field in Semantic Image Segmentation. Multimed. Tools Appl. 2018, 77, 22159–22171. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, S.; Gross, L.; Zhang, C.; Wang, B. Fused Adaptive Receptive Field Mechanism and Dynamic Multiscale Dilated Convolution for Side-Scan Sonar Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3201248. [Google Scholar] [CrossRef]
- Zhou, S.; Nie, D.; Adeli, E.; Yin, J.; Lian, J.; Shen, D. High-Resolution Encoder–Decoder Networks for Low-Contrast Medical Image Segmentation. IEEE Trans. Image Process. 2020, 29, 461–475. [Google Scholar] [CrossRef]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation. Proc. Med. Image Comput. Comput. Assist. Interv. 2021, LNCS, 61–71. [Google Scholar]
- Carrera-Rivera, A.; Ochoa, W.; Larrinaga, F.; Lasa, G. How-to Conduct a Systematic Literature Review: A Quick Guide for Computer Science Research. MethodsX 2022, 9, 101895. [Google Scholar] [CrossRef]
- Khan, K.S.; Kunz, R.; Kleijnen, J.; Antes, G. Five Steps to Conducting a Systematic Review. J. R. Soc. Med. 2003, 96, 118–121. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Zhang, H.; Shen, H.; Huang, X.; Zhou, X.; Rong, G.; Shao, D. Quality Assessment in Systematic Literature Reviews: A Software Engineering Perspective. Inf. Softw. Technol. 2021, 130, 106397. [Google Scholar] [CrossRef]
- Yaska, M.; Nuhu, B.M. Assessment of Measures of Central Tendency and Dispersion Using Likert-Type Scale. Afr. J. Adv. Sci. Technol. Res. 2024, 16, 33–45. [Google Scholar] [CrossRef]
- Liu, Y.P.; Zhong, Q.; Liang, R.; Li, Z.; Wang, H.; Chen, P. Layer Segmentation of OCT Fingerprints with an Adaptive Gaussian Prior Guided Transformer. IEEE Trans. Instrum. Meas. 2022, 71, 3212113. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, J.; Liu, W.; Yuan, H.; Tan, S.; Wang, L.; Yi, F. A Semantic Fusion Based Approach for Express Bill Detection in Complex Scenes. Image Vis. Comput. 2023, 135, 104708. [Google Scholar] [CrossRef]
- Yuan, H.; Peng, J. LCSeg-Net: A Low-Contrast Images Semantic Segmentation Model with Structural and Frequency Spectrum Information. Pattern Recognit. 2024, 151, 110428. [Google Scholar] [CrossRef]
- Tian, S.; Huang, P.; Ma, H.; Wang, J.; Zhou, X.; Zhang, S.; Zhou, J.; Huang, R.; Li, Y. CASDD: Automatic Surface Defect Detection Using a Complementary Adversarial Network. IEEE Sens. J. 2022, 22, 19583–19595. [Google Scholar] [CrossRef]
- Lin, Q.; Zhou, J.; Ma, Q.; Ma, Y.; Kang, L.; Wang, J. EMRA-Net: A Pixel-Wise Network Fusing Local and Global Features for Tiny and Low-Contrast Surface Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 3151926. [Google Scholar] [CrossRef]
- Wu, Y.; Li, S.; Zhang, J.; Li, Y.; Li, Y.; Zhang, Y. Dual Attention Transformer Network for Pixel-Level Concrete Crack Segmentation Considering Camera Placement. Autom. Constr. 2024, 157, 105166. [Google Scholar] [CrossRef]
- Ye, W.; Ren, J.; Zhang, A.A.; Lu, C. Automatic Pixel-Level Crack Detection with Multi-Scale Feature Fusion for Slab Tracks. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 2648–2665. [Google Scholar] [CrossRef]
- Sun, Z.; Zhu, H.; Xiao, X.; Gu, Y.; Xu, Y. Nighttime Image Semantic Segmentation with Retinex Theory. Image Vis. Comput. 2024, 148, 105149. [Google Scholar] [CrossRef]
- Chuanmeng, S.; Xinyu, L.; Jiaxin, C.; Zhibo, W.; Yong, L. Coal-Rock Image Recognition Method for Complex and Harsh Environment in Coal Mine Using Deep Learning Models. IEEE Access 2023, 11, 80794–80805. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Chen, Z.; Ren, L. GVANet: A Grouped Multi-View Aggregation Network for Remote Sensing Image Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 16727–16743. [Google Scholar] [CrossRef]
- Jing, T.; Meng, Q.-H.; Hou, H.-R. SmokeSeger: A Transformer-CNN Coupled Model for Urban Scene Smoke Segmentation. IEEE Trans. Ind. Inform. 2024, 20, 1385–1396. [Google Scholar] [CrossRef]
- Jiang, T.; Xing, W.; Yu, M.; Ta, D. A Hybrid Enhanced Attention Transformer Network for Medical Ultrasound Image Segmentation. Biomed. Signal Process. Control 2023, 86, 105329. [Google Scholar] [CrossRef]
- Zhang, D.; Lu, C.; Tan, T.; Dashtbozorg, B.; Long, X.; Xu, X.; Zhang, J.; Shan, C. BSANet: Boundary-Aware and Scale-Aggregation Networks for CMR Image Segmentation. Neurocomputing 2024, 599, 128125. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Z.; Zou, Y.; Lu, M.; Chen, C.; Song, Y.; Zhang, H.; Yan, F. Channel Prior Convolutional Attention for Medical Image Segmentation. Comput. Biol. Med. 2024, 178, 108784. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Zhu, Y.; Zhang, X. CoVi-Net: A Hybrid Convolutional and Vision Transformer Neural Network for Retinal Vessel Segmentation. Comput. Biol. Med. 2024, 170, 108047. [Google Scholar] [CrossRef]
- Yang, H.; Yang, D. CSwin-PNet: A CNN-Swin Transformer Combined Pyramid Network for Breast Lesion Segmentation in Ultrasound Images. Expert Syst. Appl. 2023, 213, 119024. [Google Scholar] [CrossRef]
- Chaoyang, Z.; Shibao, S.; Wenmao, H.; Pengcheng, Z. FDR-TransUNet: A Novel Encoder-Decoder Architecture with Vision Transformer for Improved Medical Image Segmentation. Comput. Biol. Med. 2024, 169, 107858. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Liu, J.Y.; Wang, K.; Zhang, K.; Zhang, G.S.; Liao, X.F.; Yang, G. Global Transformer and Dual Local Attention Network via Deep-Shallow Hierarchical Feature Fusion for Retinal Vessel Segmentation. IEEE Trans. Cybern. 2023, 53, 5826–5839. [Google Scholar] [CrossRef] [PubMed]
- He, A.; Wang, K.; Li, T.; Du, C.; Xia, S.; Fu, H. H2Former: An Efficient Hierarchical Hybrid Transformer for Medical Image Segmentation. IEEE Trans. Med. Imaging 2023, 42, 2763–2775. [Google Scholar] [CrossRef]
- Wang, W.; Pan, B.; Ai, Y.; Li, G.; Fu, Y.; Liu, Y. LightCM-PNet: A Lightweight Pyramid Network for Real-Time Prostate Segmentation in Transrectal Ultrasound. Pattern Recognit. 2024, 156, 110776. [Google Scholar] [CrossRef]
- Zhang, Y.; Xi, R.; Wang, W.; Li, H.; Hu, L.; Lin, H.; Towey, D.; Bai, R.; Fu, H.; Higashita, R.; et al. Low-Contrast Medical Image Segmentation via Transformer and Boundary Perception. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 2297–2309. [Google Scholar] [CrossRef]
- Dai, D.; Dong, C.; Xu, S.; Yan, Q.; Li, Z.; Zhang, C.; Luo, N. Ms RED: A Novel Multi-Scale Residual Encoding and Decoding Network for Skin Lesion Segmentation. Med. Image Anal. 2022, 75, 102293. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, Y.; Wu, Q.; Wang, Y.; Liu, Y.; Xu, X.; Song, B. SWTRU: Star-Shaped Window Transformer Reinforced U-Net for Medical Image Segmentation. Comput. Biol. Med. 2022, 150, 105954. [Google Scholar] [CrossRef]
- Dai, S.; Zhu, Y.; Jiang, X.; Yu, F.; Lin, J.; Yang, D. TD-Net: Trans-Deformer Network for Automatic Pancreas Segmentation. Neurocomputing 2023, 517, 279–293. [Google Scholar] [CrossRef]
- Zhang, H.; Gao, Z.; Zhang, D.; Hau, W.K.; Zhang, H. Progressive Perception Learning for Main Coronary Segmentation in X-Ray Angiography. IEEE Trans. Med. Imaging 2023, 42, 864–879. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, J.; Li, S.; Dong, Z.; Zheng, Q.; Zhang, J. U-NTCA: NnUNet and Nested Transformer with Channel Attention for Corneal Cell Segmentation. Front. Neurosci. 2024, 18, 1363288. [Google Scholar] [CrossRef]
- Shah, A.; Rojas, C.A. Imaging Modalities (MRI, CT, PET/CT), Indications, Differential Diagnosis and Imaging Characteristics of Cystic Mediastinal Masses: A Review. Mediastinum 2023, 7, 3. [Google Scholar] [CrossRef]
- Grand Challenges Sub-Challenge: Automatic Polyp Detection in Colonoscopy Videos—CVC-ClinicDB. Available online: https://polyp.grand-challenge.org/CVCClinicDB/ (accessed on 14 December 2024).
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface Defect Detection Methods for Industrial Products: A Review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Emek Soylu, B.; Guzel, M.S.; Bostanci, G.E.; Ekinci, F.; Asuroglu, T.; Acici, K. Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review. Electronics 2023, 12, 2730. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechida, A. A Review on Early Wildfire Detection from Unmanned Aerial Vehicles Using Deep Learning-Based Computer Vision Algorithms. Signal Process. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Silvestre-Blanes, J.; Albero-Albero, T.; Miralles, I.; Pérez-Llorens, R.; Moreno, J. A Public Fabric Database for Defect Detection Methods and Results. Autex Res. J. 2019, 19, 363–374. [Google Scholar] [CrossRef]
- Huang, Y.; Qiu, C.; Guo, Y.; Wang, X.; Yuan, K. Surface Defect Saliency of Magnetic Tile. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 612–617. [Google Scholar]
- Gong, H.; Chen, J.; Chen, G.; Li, H.; Li, G.; Chen, F. Thyroid Region Prior Guided Attention for Ultrasound Segmentation of Thyroid Nodules. Comput. Biol. Med. 2023, 155, 106389. [Google Scholar] [CrossRef]
- Leclerc, S.; Smistad, E.; Pedrosa, J.; Ostvik, A.; Cervenansky, F.; Espinosa, F.; Espeland, T.; Berg, E.A.R.; Jodoin, P.-M.; Grenier, T.; et al. Deep Learning for Segmentation Using an Open Large-Scale Dataset in 2D Echocardiography. IEEE Trans. Med. Imaging 2019, 38, 2198–2210. [Google Scholar] [CrossRef]
- Cardiac Atlas Project Sunnybrook Cardiac Data. Available online: https://www.cardiacatlas.org/sunnybrook-cardiac-data/ (accessed on 14 December 2024).
- ISIC Challenge ISIC Challenge Datasets. Available online: https://challenge.isic-archive.com/data/ (accessed on 14 December 2024).
- International Society for Photogrammetry and Remote Sensing (ISPRS). 2D Semantic Labeling Contest—Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 14 December 2024).
- Tan, X.; Xu, K.; Cao, Y.; Zhang, Y.; Ma, L.; Lau, R.W.H. Night-Time Scene Parsing With a Large Real Dataset. IEEE Trans. Image Process. 2021, 30, 9085–9098. [Google Scholar] [CrossRef] [PubMed]
- DRIVE: Digital Retinal Images for Vessel Extraction. Available online: https://drive.grand-challenge.org/ (accessed on 14 December 2024).
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Ehab, W.; Huang, L.; Li, Y. UNet and Variants for Medical Image Segmentation. Int. J. Netw. Dyn. Intell. 2024, 3, 100009. [Google Scholar] [CrossRef]
- Liu, F.; Fang, M. Semantic Segmentation of Underwater Images Based on Improved Deeplab. J. Mar. Sci. Eng. 2020, 8, 188. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. NnU-Net: A Self-Configuring Method for Deep Learning-Based Biomedical Image Segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Wu, L.; Chen, Y.; Wang, G.; Weng, G. An Active Contour Model Based on Retinex and Pre-Fitting Reflectance for Fast Image Segmentation. Symmetry 2022, 14, 2343. [Google Scholar] [CrossRef]
- Kim, B.J.; Choi, H.; Jang, H.; Lee, D.G.; Jeong, W.; Kim, S.W. Dead Pixel Test Using Effective Receptive Field. Pattern Recognit. Lett. 2023, 167, 149–156. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Jiang, J.; Han, Z.; Deng, S.; Li, Z.; Fang, T.; Huo, H.; Li, Q.; Liu, M. Adaptive Effective Receptive Field Convolution for Semantic Segmentation of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3532–3546. [Google Scholar] [CrossRef]
- Loos, V.; Pardasani, R.; Awasthi, N. Demystifying the Effect of Receptive Field Size in U-Net Models for Medical Image Segmentation. J. Med. Imaging 2024, 11, 054004. [Google Scholar] [CrossRef]
- Kumar Singh, V.; Abdel-Nasser, M.; Pandey, N.; Puig, D. LungINFseg: Segmenting COVID-19 Infected Regions in Lung CT Images Based on a Receptive-Field-Aware Deep Learning Framework. Diagnostics 2021, 11, 158. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, C.; Gao, Y.; Shi, Z.; Xie, F. Semantic Segmentation of Remote Sensing Image Based on Regional Self-Attention Mechanism. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8010305. [Google Scholar] [CrossRef]
- Ferdaus, M.M.; Abdelguerfi, M.; Niles, K.N.; Pathak, K.; Tom, J. Widened Attention-Enhanced Atrous Convolutional Network for Efficient Embedded Vision Applications under Resource Constraints. Adv. Intell. Syst. 2024; early view. [Google Scholar] [CrossRef]
- Pan, B.; Xu, X.; Shi, Z.; Zhang, N.; Luo, H.; Lan, X. DSSNet: A Simple Dilated Semantic Segmentation Network for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1968–1972. [Google Scholar] [CrossRef]
- Chen, F.; Wu, F.; Xu, J.; Gao, G.; Ge, Q.; Jing, X.-Y. Adaptive Deformable Convolutional Network. Neurocomputing 2021, 453, 853–864. [Google Scholar] [CrossRef]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual Attention Methods in Deep Learning: An in-Depth Survey. Inf. Fusion 2024, 108, 102417. [Google Scholar] [CrossRef]
- Li, Y.; Liang, M.; Wei, M.; Wang, G.; Li, Y. Mechanisms and Applications of Attention in Medical Image Segmentation: A Review. Acad. J. Sci. Technol. 2023, 5, 237–243. [Google Scholar] [CrossRef]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.-S.; Li, J.; Wong, A. Squeeze-and-Attention Networks for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13062–13071. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. A Simple and Light-Weight Attention Module for Convolutional Neural Networks. Int. J. Comput. Vis. 2020, 128, 783–798. [Google Scholar] [CrossRef]
- Ye, Y.; Chen, Y.; Wang, R.; Zhu, D.; Huang, Y.; Huang, Y.; Liu, J.; Chen, Y.; Shi, J.; Ding, B.; et al. Image Segmentation Using Improved U-Net Model and Convolutional Block Attention Module Based on Cardiac Magnetic Resonance Imaging. J. Radiat. Res. Appl. Sci. 2024, 17, 100816. [Google Scholar] [CrossRef]
- Papa, L.; Russo, P.; Amerini, I.; Zhou, L. A Survey on Efficient Vision Transformers: Algorithms, Techniques, and Performance Benchmarking. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7682–7700. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-Mixer: An All-Mlp Architecture for Vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Krithika alias AnbuDevi, M.; Suganthi, K. Review of Semantic Segmentation of Medical Images Using Modified Architectures of UNET. Diagnostics 2022, 12, 3064. [Google Scholar] [CrossRef] [PubMed]
- Fan, X.; Yan, C.; Fan, J.; Wang, N. Improved U-Net Remote Sensing Classification Algorithm Fusing Attention and Multiscale Features. Remote Sens. 2022, 14, 3591. [Google Scholar] [CrossRef]
- Wang, H.; Cao, P.; Yang, J.; Zaiane, O. Narrowing the Semantic Gaps in U-Net with Learnable Skip Connections: The Case of Medical Image Segmentation. Neural Networks 2024, 178, 106546. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A Review: Data Pre-Processing and Data Augmentation Techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Pious, I.K.; Srinivasan, R. Segnet Unveiled: Robust Image Segmentation via Rigorous K-Fold Cross-Validation Analysis. Technol. Health Care 2024, 33, 863–876. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yu, L.; Chang, D.; Ma, Z.; Cao, J. Dual Cross-Entropy Loss for Small-Sample Fine-Grained Vehicle Classification. IEEE Trans. Veh. Technol. 2019, 68, 4204–4212. [Google Scholar] [CrossRef]
- Yaqub, M.; Feng, J.; Zia, M.; Arshid, K.; Jia, K.; Rehman, Z.; Mehmood, A. State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images. Brain Sci. 2020, 10, 427. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.-H.; Liu, Z.-N.; Mu, T.-J.; Liang, D.; Martin, R.R.; Hu, S.-M. Can Attention Enable MLPs to Catch up with CNNs? Comput. Vis. Media 2021, 7, 283–288. [Google Scholar] [CrossRef]
- Panella, F.; Lipani, A.; Boehm, J. Semantic Segmentation of Cracks: Data Challenges and Architecture. Autom. Constr. 2022, 135, 104110. [Google Scholar] [CrossRef]
- Xun, S.; Li, D.; Zhu, H.; Chen, M.; Wang, J.; Li, J.; Chen, M.; Wu, B.; Zhang, H.; Chai, X.; et al. Generative Adversarial Networks in Medical Image Segmentation: A Review. Comput. Biol. Med. 2022, 140, 105063. [Google Scholar] [CrossRef]
- Iman, M.; Arabnia, H.R.; Rasheed, K. A Review of Deep Transfer Learning and Recent Advancements. Technologies 2023, 11, 40. [Google Scholar] [CrossRef]
- Alomar, K.; Aysel, H.I.; Cai, X. Data Augmentation in Classification and Segmentation: A Survey and New Strategies. J. Imaging 2023, 9, 46. [Google Scholar] [CrossRef]
- Archit, A.; Pape, P. ViM-UNet: Vision Mamba for Biomedical Segmentation. In Proceedings of the Medical Imaging with Deep Learning, Paris, France, 2–4 July 2024. [Google Scholar]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical Image Segmentation Using Deep Learning: A Survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Baid, U.; Talbar, S.; Talbar, S. Comparative Study of K-Means, Gaussian Mixture Model, Fuzzy C-Means Algorithms for Brain Tumor Segmentation. In Proceedings of the International Conference on Communication and Signal Processing 2016 (ICCASP 2016), Melmaruvathur, India, 6–8 April 2016; Atlantis Press: Paris, France, 2017. [Google Scholar]
- Rezaie, A.; Achanta, R.; Godio, M.; Beyer, K. Comparison of Crack Segmentation Using Digital Image Correlation Measurements and Deep Learning. Constr. Build. Mater. 2020, 261, 120474. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, Y.; Chen, M.; Zhang, Q. Multi-Region Radiomics for Artificially Intelligent Diagnosis of Breast Cancer Using Multimodal Ultrasound. Comput. Biol. Med. 2022, 149, 105920. [Google Scholar] [CrossRef]
- Ma, J.; He, Y.; Li, F.; Han, L.; You, C.; Wang, B. Segment Anything in Medical Images. Nat. Commun. 2024, 15, 654. [Google Scholar] [CrossRef] [PubMed]
- Cartolovni, A.; Tomičić, A.; Lazić Mosler, E. Ethical, Legal, and Social Considerations of AI-Based Medical Decision-Support Tools: A Scoping Review. Int. J. Med. Inform. 2022, 161, 104738. [Google Scholar] [CrossRef] [PubMed]
- Cunneen, M.; Mullins, M.; Murphy, F.; Shannon, D.; Furxhi, I.; Ryan, C. Autonomous Vehicles and Avoiding the Trolley (Dilemma): Vehicle Perception, Classification, and the Challenges of Framing Decision Ethics. Cybern. Syst. 2020, 51, 59–80. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Al-antari, M.A.; AL-Jarazi, R.; Zhai, D. A Hybrid Deep Learning Pavement Crack Semantic Segmentation. Eng. Appl. Artif. Intell. 2023, 122, 106142. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Shao, X. A Lightweight Network for Real-Time Smoke Semantic Segmentation Based on Dual Paths. Neurocomputing 2022, 501, 258–269. [Google Scholar] [CrossRef]
- Hu, X.; Jiang, F.; Qin, X.; Huang, S.; Yang, X.; Meng, F. An Optimized Smoke Segmentation Method for Forest and Grassland Fire Based on the UNet Framework. Fire 2024, 7, 68. [Google Scholar] [CrossRef]
- Zhou, Q.; Situ, Z.; Teng, S.; Liu, H.; Chen, W.; Chen, G. Automatic Sewer Defect Detection and Severity Quantification Based on Pixel-Level Semantic Segmentation. Tunn. Undergr. Space Technol. 2022, 123, 104403. [Google Scholar] [CrossRef]
- Li, Y.; Ouyang, S.; Zhang, Y. Combining Deep Learning and Ontology Reasoning for Remote Sensing Image Semantic Segmentation. Knowl. Based Syst. 2022, 243, 108469. [Google Scholar] [CrossRef]
- Wang, R.; Zheng, G. CyCMIS: Cycle-Consistent Cross-Domain Medical Image Segmentation via Diverse Image Augmentation. Med. Image Anal. 2022, 76, 102328. [Google Scholar] [CrossRef]
- Muksimova, S.; Mardieva, S.; Cho, Y.I. Deep Encoder–Decoder Network-Based Wildfire Segmentation Using Drone Images in Real-Time. Remote Sens. 2022, 14, 6302. [Google Scholar] [CrossRef]
- Ling, Z.; Zhang, A.; Ma, D.; Shi, Y.; Wen, H. Deep Siamese Semantic Segmentation Network for PCB Welding Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 3154814. [Google Scholar] [CrossRef]
- Fu, Y.; Gao, M.; Xie, G.; Hu, M.; Wei, C.; Ding, R. Density-Aware U-Net for Unstructured Environment Dust Segmentation. IEEE Sens. J. 2024, 24, 8210–8226. [Google Scholar] [CrossRef]
- Priyanka; Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DIResUNet: Architecture for Multiclass Semantic Segmentation of High Resolution Remote Sensing Imagery Data. Appl. Intell. 2022, 52, 15462–15482. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Dual Attention Deep Learning Network for Automatic Steel Surface Defect Segmentation. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1468–1487. [Google Scholar] [CrossRef]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast Forest Fire Smoke Detection Using MVMNet. Knowl. Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Liang, H.; Zheng, C.; Liu, X.; Tian, Y.; Zhang, J.; Cui, W. Super-Resolution Reconstruction of Remote Sensing Data Based on Multiple Satellite Sources for Forest Fire Smoke Segmentation. Remote Sens. 2023, 15, 4180. [Google Scholar] [CrossRef]
- Wang, P.; Shi, G. Image Segmentation of Tunnel Water Leakage Defects in Complex Environments Using an Improved Unet Model. Sci. Rep. 2024, 14, 24286. [Google Scholar] [CrossRef]
- Xiong, Y.; Xiao, X.; Yao, M.; Cui, H.; Fu, Y. Light4Mars: A Lightweight Transformer Model for Semantic Segmentation on Unstructured Environment like Mars. ISPRS J. Photogramm. Remote Sens. 2024, 214, 167–178. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Li, Q.; Wang, P.; Guo, D.; Lu, L.; Jin, D.; Zhang, Y.; Hong, Q. LViT: Language Meets Vision Transformer in Medical Image Segmentation. IEEE Trans. Med. Imaging 2024, 43, 96–107. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Gao, G.; Xu, G.; Yu, Y.; Xie, J.; Yang, J.; Yue, D. MSCFNet: A Lightweight Network With Multi-Scale Context Fusion for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25489–25499. [Google Scholar] [CrossRef]
- Ding, L.; Xia, M.; Lin, H.; Hu, K. Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation. Remote Sens. 2024, 16, 112. [Google Scholar] [CrossRef]
- Yang, L.; Bai, S.; Liu, Y.; Yu, H. Multi-Scale Triple-Attention Network for Pixelwise Crack Segmentation. Autom. Constr. 2023, 150, 104853. [Google Scholar] [CrossRef]
- Zheng, C.; Liu, L.; Meng, Y.; Wang, M.; Jiang, X. Passable Area Segmentation for Open-Pit Mine Road from Vehicle Perspective. Eng. Appl. Artif. Intell. 2024, 129, 107610. [Google Scholar] [CrossRef]
- Liu, H.; Yao, M.; Xiao, X.; Xiong, Y. RockFormer: A U-Shaped Transformer Network for Martian Rock Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3235525. [Google Scholar] [CrossRef]
- Su, Y.; Cheng, J.; Bai, H.; Liu, H.; He, C. Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sens. 2022, 14, 533. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Yuan, F.; Fang, Y. Smoke-Aware Global-Interactive Non-Local Network for Smoke Semantic Segmentation. IEEE Trans. Image Process. 2024, 33, 1175–1187. [Google Scholar] [CrossRef]
- Tao, H. Smoke Recognition in Satellite Imagery via an Attention Pyramid Network With Bidirectional Multi-level Multigranularity Feature Aggregation and Gated Fusion. IEEE Internet Things J. 2024, 11, 14047–14057. [Google Scholar] [CrossRef]
- Xie, X.; Cai, J.; Wang, H.; Wang, Q.; Xu, J.; Zhou, Y.; Zhou, B. Sparse-Sensing and Superpixel-Based Segmentation Model for Concrete Cracks. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1769–1784. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, Q.; Ye, Q.; Ruan, T. ST-Unet: Swin Transformer Boosted U-Net with Cross-Layer Feature Enhancement for Medical Image Segmentation. Comput. Biol. Med. 2023, 153, 106516. [Google Scholar] [CrossRef]
- Ma, J.; Yuan, G.; Guo, C.; Gang, X.; Zheng, M. SW-UNet: A U-Net Fusing Sliding Window Transformer Block with CNN for Segmentation of Lung Nodules. Front. Med. 2023, 10, 1273441. [Google Scholar] [CrossRef]
- Lin, X.; Yu, L.; Cheng, K.T.; Yan, Z. The Lighter the Better: Rethinking Transformers in Medical Image Segmentation Through Adaptive Pruning. IEEE Trans. Med. Imaging 2023, 42, 2325–2337. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Z.; Nan, N.; Wang, X. TranSegNet: Hybrid CNN-Vision Transformers Encoder for Retina Segmentation of Optical Coherence Tomography. Life 2023, 13, 976. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y.; et al. TransUNet: Rethinking the U-Net Architecture Design for Medical Image Segmentation through the Lens of Transformers. Med. Image Anal. 2024, 97, 103280. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Lin, X.; Yang, X.; Yu, L.; Cheng, K.T.; Yan, Z. UCTNet: Uncertainty-Guided CNN-Transformer Hybrid Networks for Medical Image Segmentation. Pattern Recognit. 2024, 152, 110491. [Google Scholar] [CrossRef]
- Bencević, M.; Habijan, M.; Galić, I.; Babin, D.; Pižurica, A. Understanding Skin Color Bias in Deep Learning-Based Skin Lesion Segmentation. Comput. Methods Programs Biomed. 2024, 245, 108044. [Google Scholar] [CrossRef]
- Wang, J.J.; Liu, Y.F.; Nie, X.; Mo, Y.L. Deep Convolutional Neural Networks for Semantic Segmentation of Cracks. Struct. Control Health Monit. 2022, 29, e2850. [Google Scholar] [CrossRef]
- Pozzer, S.; De Souza, M.P.V.; Hena, B.; Hesam, S.; Rezayiye, R.K.; Rezazadeh Azar, E.; Lopez, F.; Maldague, X. Effect of Different Imaging Modalities on the Performance of a CNN: An Experimental Study on Damage Segmentation in Infrared, Visible, and Fused Images of Concrete Structures. NDT E Int. 2022, 132, 102709. [Google Scholar] [CrossRef]
- Jin, K.; Huang, X.; Zhou, J.; Li, Y.; Yan, Y.; Sun, Y.; Zhang, Q.; Wang, Y.; Ye, J. FIVES: A Fundus Image Dataset for Artificial Intelligence Based Vessel Segmentation. Sci Data 2022, 9, 475. [Google Scholar] [CrossRef]
- Zheng, J.; Tang, C.; Sun, Y. Thresholding-Accelerated Convolutional Neural Network for Aeroengine Turbine Blade Segmentation. Expert Syst. Appl. 2024, 238, 122387. [Google Scholar] [CrossRef]
- Song, L.; Sun, H.; Liu, J.; Yu, Z.; Cui, C. Automatic Segmentation and Quantification of Global Cracks in Concrete Structures Based on Deep Learning. Measurement 2022, 199, 111550. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Jin, D.; Wang, Y.; Yang, F.; Bai, X. Light Transport Induced Domain Adaptation for Semantic Segmentation in Thermal Infrared Urban Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23194–23211. [Google Scholar] [CrossRef]
- Ashraf, H.; Waris, A.; Ghafoor, M.F.; Gilani, S.O.; Niazi, I.K. Melanoma Segmentation Using Deep Learning with Test-Time Augmentations and Conditional Random Fields. Sci. Rep. 2022, 12, 3948. [Google Scholar] [CrossRef]
- Tani, T.A.; Tešić, J. Advancing Retinal Vessel Segmentation With Diversified Deep Convolutional Neural Networks. IEEE Access 2024, 12, 141280–141290. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, W. A New Regularization for Deep Learning-Based Segmentation of Images with Fine Structures and Low Contrast. Sensors 2023, 23, 1887. [Google Scholar] [CrossRef]
- Chen, Y.; Gan, H.; Chen, H.; Zeng, Y.; Xu, L.; Heidari, A.A.; Zhu, X.; Liu, Y. Accurate Iris Segmentation and Recognition Using an End-to-End Unified Framework Based on MADNet and DSANet. Neurocomputing 2023, 517, 264–278. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. A Nondestructive Automatic Defect Detection Method with Pixelwise Segmentation. Knowl. Based Syst. 2022, 242, 108338. [Google Scholar] [CrossRef]
- Hekal, A.A.; Elnakib, A.; Moustafa, H.E.D.; Amer, H.M. Breast Cancer Segmentation from Ultrasound Images Using Deep Dual-Decoder Technology with Attention Network. IEEE Access 2024, 12, 10087–10101. [Google Scholar] [CrossRef]
- Li, S.; Feng, Y.; Xu, H.; Miao, Y.; Lin, Z.; Liu, H.; Xu, Y.; Li, F. CAENet: Contrast Adaptively Enhanced Network for Medical Image Segmentation Based on a Differentiable Pooling Function. Comput. Biol. Med. 2023, 167, 107578. [Google Scholar] [CrossRef]
- Luo, Q.; Su, J.; Yang, C.; Gui, W.; Silven, O.; Liu, L. CAT-EDNet: Cross-Attention Transformer-Based Encoder-Decoder Network for Salient Defect Detection of Strip Steel Surface. IEEE Trans. Instrum. Meas. 2022, 71, 3165270. [Google Scholar] [CrossRef]
- Lin, J.; Lin, J.; Lu, C.; Chen, H.; Lin, H.; Zhao, B.; Shi, Z.; Qiu, B.; Pan, X.; Xu, Z.; et al. CKD-TransBTS: Clinical Knowledge-Driven Hybrid Transformer with Modality-Correlated Cross-Attention for Brain Tumor Segmentation. IEEE Trans. Med. Imaging 2023, 42, 2451–2461. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.; Dong, Z.; Zhang, L.; Xia, X.; Shi, J. Cubic-Cross Convolutional Attention and Count Prior Embedding for Smoke Segmentation. Pattern Recognit. 2022, 131, 108902. [Google Scholar] [CrossRef]
- Yang, L.; Gu, Y.; Bian, G.; Liu, Y. DRR-Net: A Dense-Connected Residual Recurrent Convolutional Network for Surgical Instrument Segmentation From Endoscopic Images. IEEE Trans. Med. Robot. Bionics 2022, 4, 696–707. [Google Scholar] [CrossRef]
- Xiao, Z.; Zhang, Y.; Deng, Z.; Liu, F. Light3DHS: A Lightweight 3D Hippocampus Segmentation Method Using Multiscale Convolution Attention and Vision Transformer. Neuroimage 2024, 292, 120608. [Google Scholar] [CrossRef] [PubMed]
- Radha, K.; Karuna, Y. Modified Depthwise Parallel Attention UNet for Retinal Vessel Segmentation. IEEE Access 2023, 11, 102572–102588. [Google Scholar] [CrossRef]
- Feng, K.; Ren, L.; Wang, G.; Wang, H.; Li, Y. SLT-Net: A Codec Network for Skin Lesion Segmentation. Comput. Biol. Med. 2022, 148, 105942. [Google Scholar] [CrossRef]
- Li, E.; Zhang, W. Smoke Image Segmentation Algorithm Suitable for Low-Light Scenes. Fire 2023, 6, 217. [Google Scholar] [CrossRef]
- Üzen, H.; Türkoğlu, M.; Yanikoglu, B.; Hanbay, D. Swin-MFINet: Swin Transformer Based Multi-Feature Integration Network for Detection of Pixel-Level Surface Defects. Expert Syst. Appl. 2022, 209, 118269. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, J.; Shi, J. TSCA-Net: Transformer Based Spatial-Channel Attention Segmentation Network for Medical Images. Comput. Biol. Med. 2024, 170, 107938. [Google Scholar] [CrossRef]
- Banerjee, S.; Lyu, J.; Huang, Z.; Leung, F.H.F.; Lee, T.; Yang, D.; Su, S.; Zheng, Y.; Ling, S.H. Ultrasound Spine Image Segmentation Using Multi-Scale Feature Fusion Skip-Inception U-Net (SIU-Net). Biocybern. Biomed. Eng. 2022, 42, 341–361. [Google Scholar] [CrossRef]
- Yamuna Devi, M.M.; Jeyabharathi, J.; Kirubakaran, S.; Narayanan, S.; Srikanth, T.; Chakrabarti, P. Efficient Segmentation and Classification of the Lung Carcinoma via Deep Learning. Multimed. Tools Appl. 2024, 83, 41981–41995. [Google Scholar] [CrossRef]
- Wang, J.; Xu, G.; Yan, F.; Wang, J.; Wang, Z. Defect Transformer: An Efficient Hybrid Transformer Architecture for Surface Defect Detection. Measurement 2023, 211, 112614. [Google Scholar] [CrossRef]
- Song, J.; Chen, X.; Zhu, Q.; Shi, F.; Xiang, D.; Chen, Z.; Fan, Y.; Pan, L.; Zhu, W. Global and Local Feature Reconstruction for Medical Image Segmentation. IEEE Trans. Med. Imaging 2022, 41, 2273–2284. [Google Scholar] [CrossRef]
- Periyasamy, M.; Davari, A.; Seehaus, T.; Braun, M.; Maier, A.; Christlein, V. How to Get the Most out of U-Net for Glacier Calving Front Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1712–1723. [Google Scholar] [CrossRef]
- Liu, X.; Hu, Y.; Chen, J. Hybrid CNN-Transformer Model for Medical Image Segmentation with Pyramid Convolution and Multi-Layer Perceptron. Biomed. Signal Process. Control 2023, 86, 105331. [Google Scholar] [CrossRef]
- Yazdi, R.; Khotanlou, H. MaxSigNet: Light Learnable Layer for Semantic Cell Segmentation. Biomed. Signal Process. Control 2024, 95, 106464. [Google Scholar] [CrossRef]
- Wu, R.; Liang, P.; Huang, X.; Shi, L.; Gu, Y.; Zhu, H.; Chang, Q. MHorUNet: High-Order Spatial Interaction UNet for Skin Lesion Segmentation. Biomed. Signal Process. Control 2024, 88, 105517. [Google Scholar] [CrossRef]
- Chen, Z.; Bian, Y.; Shen, E.; Fan, L.; Zhu, W.; Shi, F.; Shao, C.; Chen, X.; Xiang, D. Moment-Consistent Contrastive CycleGAN for Cross-Domain Pancreatic Image Segmentation. IEEE Trans. Med. Imaging 2024, 44, 422–435. [Google Scholar] [CrossRef]
- Li, G.; Han, C.; Liu, Z. No-Service Rail Surface Defect Segmentation via Normalized Attention and Dual-Scale Interaction. IEEE Trans. Instrum. Meas. 2023, 72, 3293561. [Google Scholar] [CrossRef]
- Lang, C.; Wang, J.; Cheng, G.; Tu, B.; Han, J. Progressive Parsing and Commonality Distillation for Few-Shot Remote Sensing Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3286183. [Google Scholar] [CrossRef]
- Chen, W.; Mu, Q.; Qi, J. TrUNet: Dual-Branch Network by Fusing CNN and Transformer for Skin Lesion Segmentation. IEEE Access 2024, 12, 144174–144185. [Google Scholar] [CrossRef]
- Liu, W.; Yang, H.; Tian, T.; Cao, Z.; Pan, X.; Xu, W.; Jin, Y.; Gao, F. Full-Resolution Network and Dual-Threshold Iteration for Retinal Vessel and Coronary Angiograph Segmentation. IEEE J. Biomed. Health Inform. 2022, 26, 4623–4634. [Google Scholar] [CrossRef]
- Liu, W.; Li, W.; Zhu, J.; Cui, M.; Xie, X.; Zhang, L. Improving Nighttime Driving-Scene Segmentation via Dual Image-Adaptive Learnable Filters. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5855–5867. [Google Scholar] [CrossRef]
- Bi, L.; Zhang, W.; Zhang, X.; Li, C. A Nighttime Driving-Scene Segmentation Method Based on Light-Enhanced Network. World Electr. Veh. J. 2024, 15, 490. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, H.; Liang, W.; Wang, S.; Zhang, Y. Cross-Convolutional Transformer for Automated Multi-Organs Segmentation in a Variety of Medical Images. Phys. Med. Biol. 2023, 68, 035008. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Ma, Z.; He, N.; Duan, W. DCSAU-Net: A Deeper and More Compact Split-Attention U-Net for Medical Image Segmentation. Comput. Biol. Med. 2023, 154, 106626. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Zhang, X.; Zhang, X.; Lu, Y.; Huang, S.; Yang, D. EANet: Iterative Edge Attention Network for Medical Image Segmentation. Pattern Recognit. 2022, 127, 108636. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Chen, J.; Yu, S.; Li, K. Region-to-Boundary Deep Learning Model with Multi-Scale Feature Fusion for Medical Image Segmentation. Biomed. Signal Process. Control 2022, 71, 103165. [Google Scholar] [CrossRef]
- Liu, Y.; Shen, J.; Yang, L.; Bian, G.; Yu, H. ResDO-UNet: A Deep Residual Network for Accurate Retinal Vessel Segmentation from Fundus Images. Biomed. Signal Process. Control 2022, 79, 104087. [Google Scholar] [CrossRef]
- Ding, H.; Cen, Q.; Si, X.; Pan, Z.; Chen, X. Automatic Glottis Segmentation for Laryngeal Endoscopic Images Based on U-Net. Biomed. Signal Process. Control 2022, 71, 103116. [Google Scholar] [CrossRef]
- Luo, F.; Cui, Y.; Liao, Y. MVRA-UNet: Multi-View Residual Attention U-Net for Precise Defect Segmentation on Magnetic Tile Surface. IEEE Access 2023, 11, 135212–135221. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).