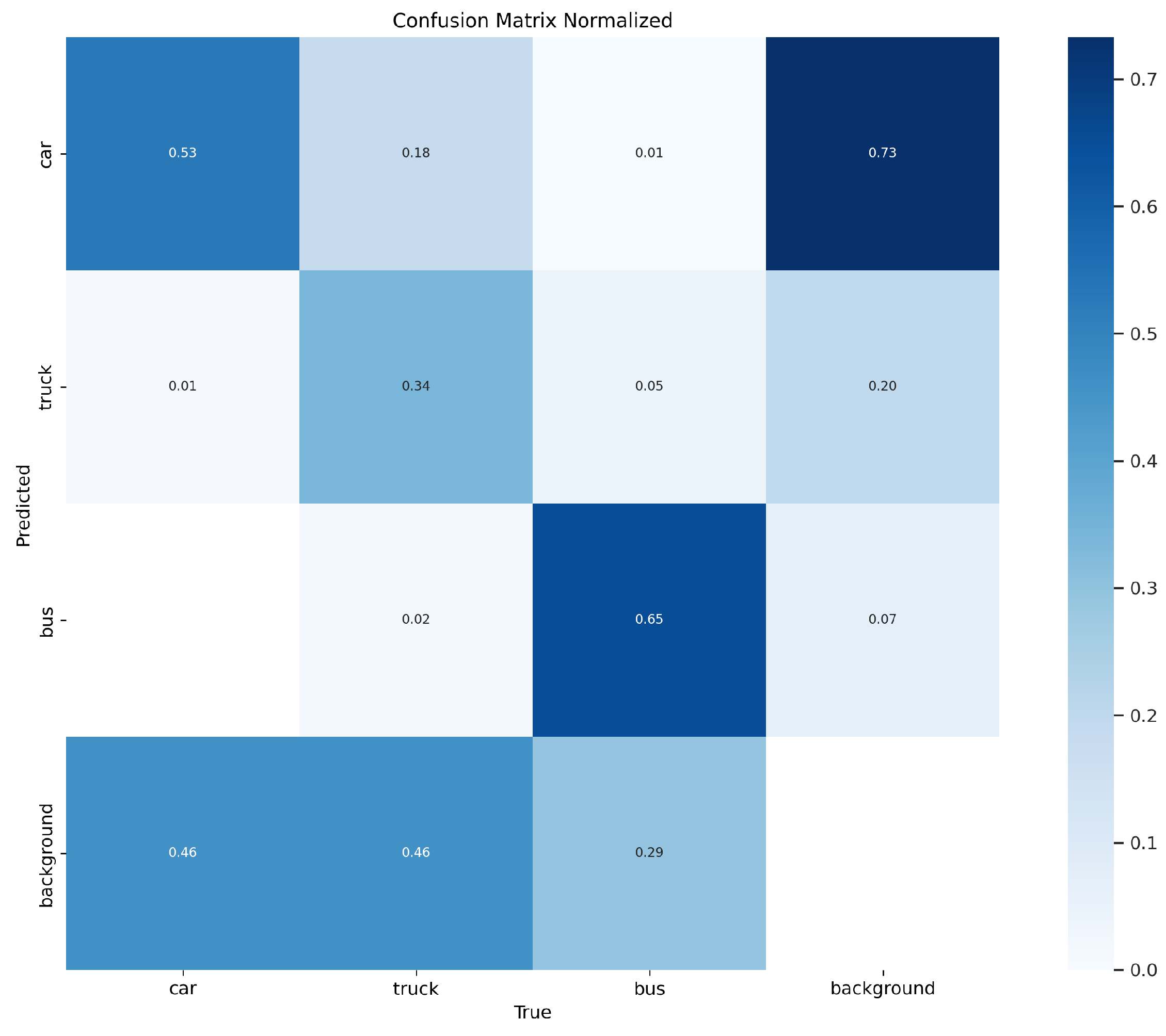
3.1. YOLOv8 Model
The network structure of YOLOv8 comprises four modules: Input, Backbone, Neck, and Head. The modular design ensures efficiency and stability in object detection, detailed as follows:
Input: The input images undergo Mosaic data augmentation to enrich the dataset. Moreover, an anchor-free strategy is employed to reduce the number of predicted boxes, thereby accelerating the Non-Maximum Suppression (NMS) process.
Backbone: This includes modules like Conv, C2f, and SPPF. The Conv module is responsible for operations like convolution, Batch Normalization, and SiLU activation on the input images. The C2f module allows for a richer flow of gradient information while remaining lightweight. The SPPF module extracts and encodes image features at different scales.
Neck: This comprises the FPN and PAN. FPN strengthens semantic features through a top-down propagation approach, while PAN enhances location features through a bottom-up propagation approach. The combination of FPN and PAN effectively fuses feature maps at different stages.
Head: A decoupled head strategy is adopted, separating the classification head from the detection head. The category and location information of the target are obtained based on feature maps of three different scales.
This model has five versions: n, s, m, l, x, all of which share a similar network model, with differences in network depth and width. Among these, the YOLOv8n network has the smallest depth and width. Considering the practical application scenarios of vehicle target detection, the YOLOv8n model was chosen for further improvement in this paper due to its simple network structure, minimal computational resource requirements, and fastest operation speed.
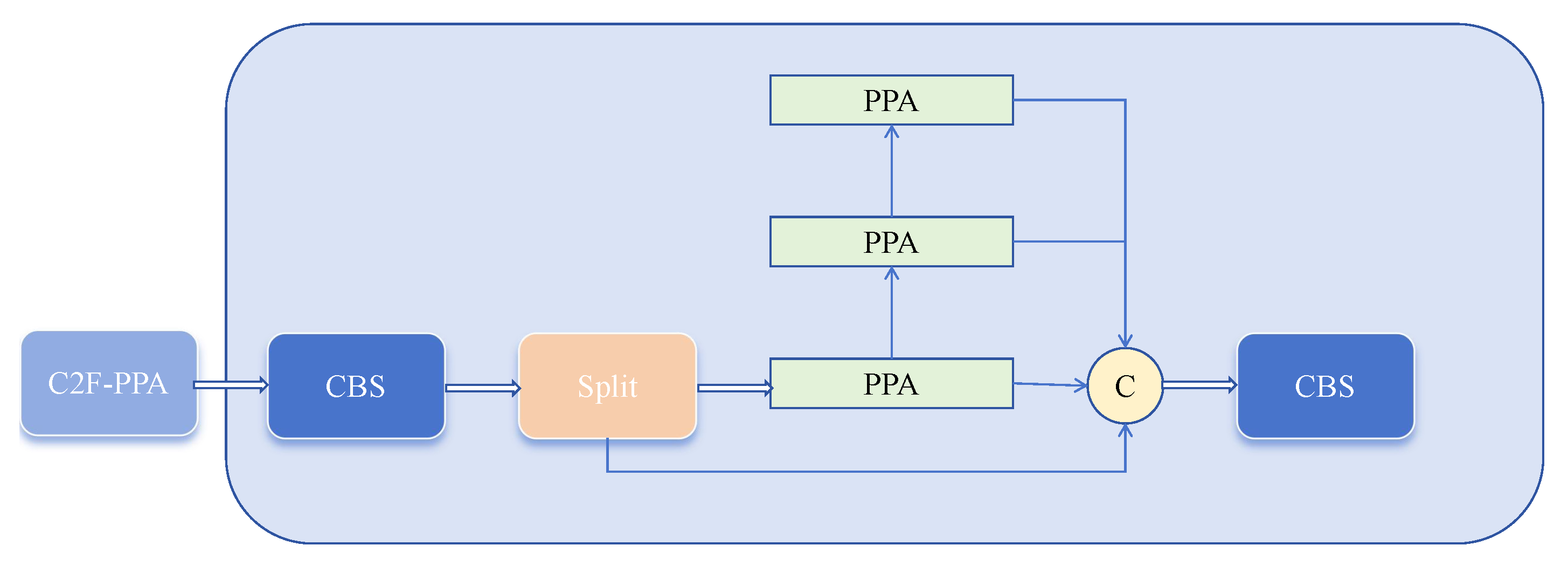
3.2. C2F-PPA Module
In YOLOv8, the C2f module is responsible for fusing high-level semantic features with low-level detail features to enhance detection accuracy. In object detection tasks, key information can be easily lost during multiple downsampling operations. To optimize vehicle detection tasks, this paper proposes the C2F-PPA module to address this issue. The C2F-PPA module incorporates an innovative network technique called the Parallelized Patch-Aware Attention (PPA) module [
25]. This module enhances network performance and efficiency by replacing traditional convolution operations in the encoder and decoder.
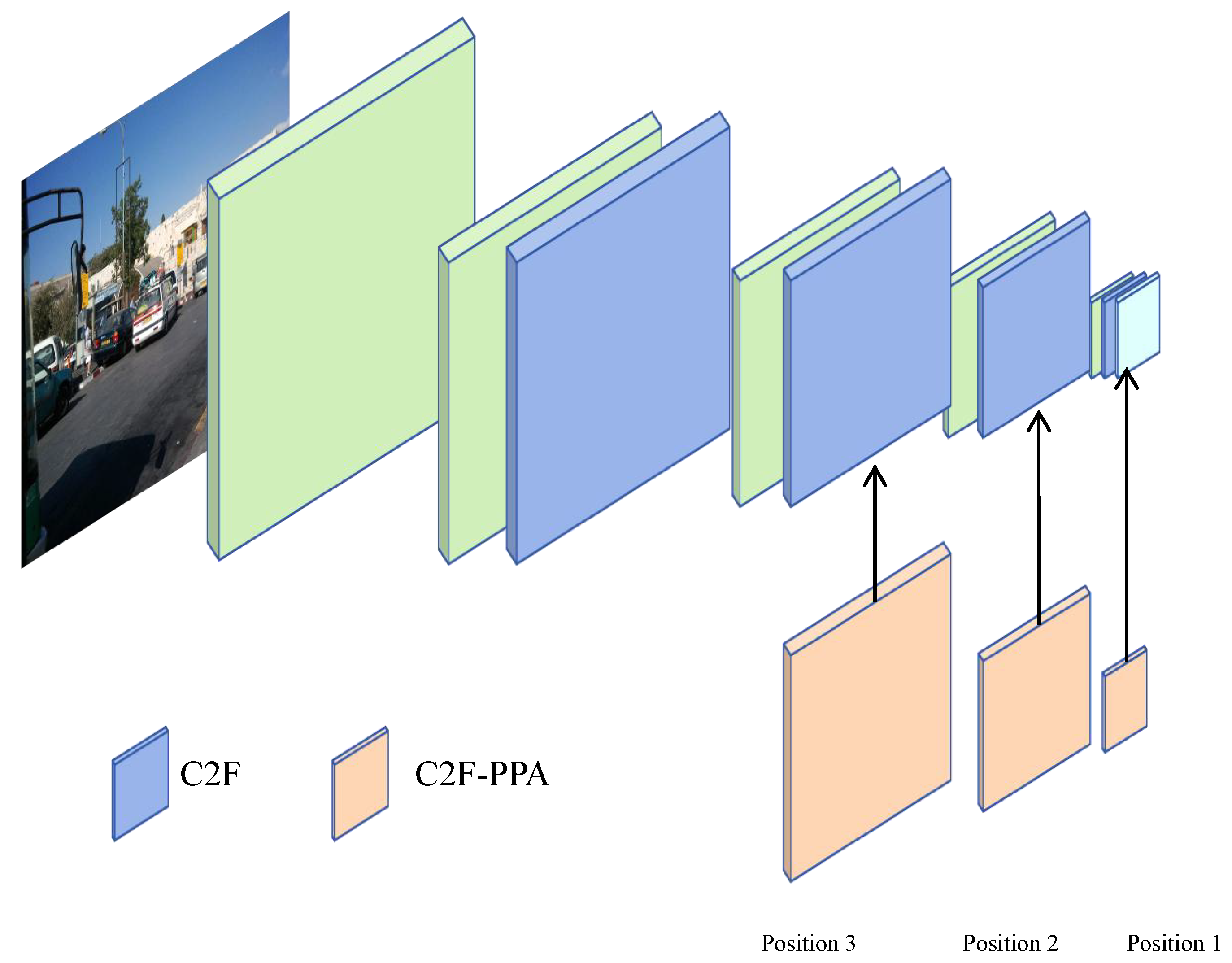
We improved the C2F structure within the Backbone by introducing the PPA module. As shown in
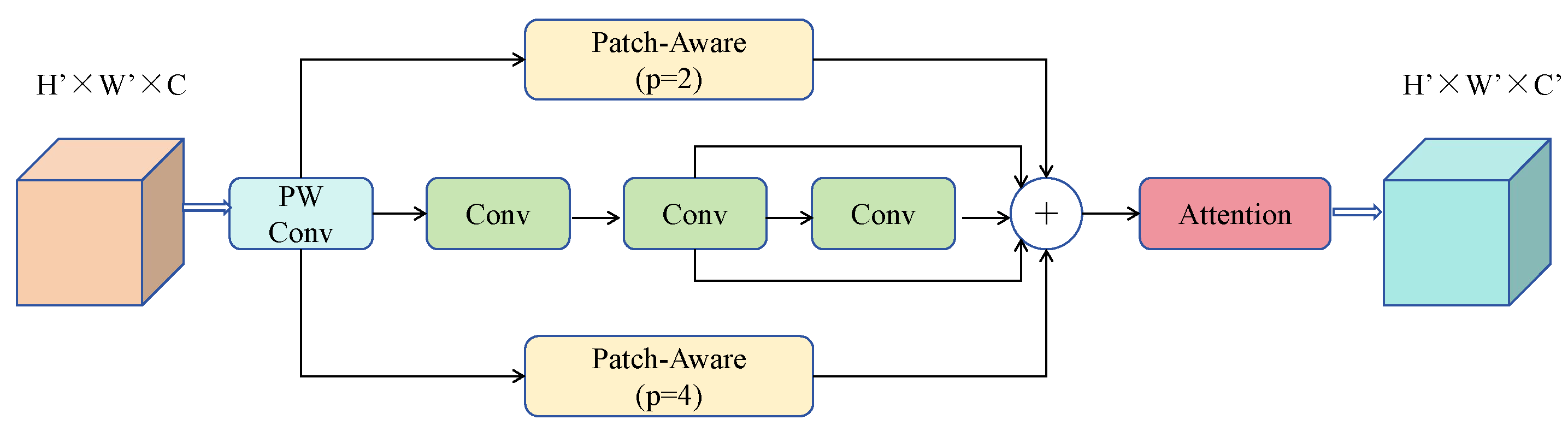
Figure 1, we use the PPA module in the middle layers of the C2F structure to generate output instead of the traditional Bottleneck module. The main advantage of the PPA module lies in its multi-branch feature extraction strategy. As illustrated in
Figure 2, PPA employs a parallel multi-branch approach, with each branch extracting features at different scales and levels, which helps capture multi-scale features of targets and thus enhances detection accuracy. In the modified C2F-PPA module, the input to the final layer includes multiple branches, forming a structure akin to a dense residual structure. This residual structure is advantageous for optimization and can improve accuracy by increasing network depth. The internal residual blocks use skip connections to mitigate gradient vanishing issues that arise in deep neural networks with increasing depth. Consequently, the C2F-PPA module, compared to the original C2F structure, has greater depth and improved accuracy.
Building on the original feature extraction mechanism, the improved C2F-PPA module adds receptive field attention, enhancing spatial feature extraction, and channel attention, which strengthens feature extraction from both spatial and channel dimensions. Additionally, the parallel multi-branch strategy of the C2F-PPA module effectively preserves the multi-scale features of the target objects.
To address this issue, we aimed to leverage the strengths of the C2F-PPA module to enhance the deep semantic feature extraction capability of CSPDarknet53. We replaced the original C2F module between the second and third output layers of CSPDarknet53 with our C2F-PPA module, aiming to enhance deep feature semantic extraction without compromising shallow feature details.
3.3. ELA-FPN
In YOLOv8’s feature fusion module, the PANet demonstrates significant advantages compared to the traditional FPN. PANet effectively enhances the fusion process across multi-scale features through its innovative bidirectional information flow mechanism. This mechanism not only facilitates the transfer of low-level detail information to higher layers but also ensures that high-level semantic information enhances the representation of lower-layer features. This advantage provides superior performance when processing images with rich detail and complex backgrounds. Although PANet has achieved considerable progress in multi-scale feature fusion, there is still room for improvement. Initially, PANet did not fully exploit its potential when handling large-scale feature maps, which may result in the loss of some critical information, ultimately affecting the overall performance of object detection. Additionally, some original information may be lost during the upsampling and downsampling processes.
To address these issues effectively, this study reconstructs YOLOv8’s feature fusion module based on the High-level Screening-feature Pyramid Network (HS-FPN) framework [
26]. HS-FPN processes input feature maps with a CA module [
27], utilizing the Sigmoid activation function to determine the weight of each channel and ultimately obtain the weight of each channel. The filtered feature maps are generated by multiplying these weight values with the corresponding scale feature maps, and then dimension matching is performed across different scales. Through a Selective Feature Fusion mechanism, high-level and low-level information from these feature mappings is integrated synergistically. This fusion yields features rich in semantic content, which aids in detecting subtle details within images, thereby enhancing the model’s detection capabilities.
In the original HS-FPN, we observed limitations in the CA module, such as the restrictive use of 1 × 1 convolutions that hinder its feature extraction capability and prevent it from fully capturing complex spatial information. Additionally, CA has limitations in handling long-range dependencies, especially within deeper network layers, and Batch Normalization sometimes adversely affects model generalization.
To address these issues, we propose an ELA-FPN to optimize the feature fusion process. ELA-FPN replaces the CA module with an Enhanced Local Attention (ELA) mechanism [
28] to handle multi-scale features more effectively. As shown in
Figure 3, the ELA mechanism uses 1D convolutions to improve positional information along both horizontal and vertical axes. By incorporating larger convolution kernels (such as five or seven), ELA improves feature selection and fusion, allowing it to better handle long-range dependencies and enhance feature extraction. Additionally, ELA replaces Batch Normalization with Group Normalization, which enhances the model’s generalization capacity, particularly when processing diverse vehicle images. This adjustment allows the model to capture vehicle feature information more precisely, improving detection performance. The structure of ELA-FPN, as shown in
Figure 4, consists of two main components: (1) a feature selection module and (2) a feature fusion module.
Feature Selection Module: The ELA module play important roles in this process. The ELA module initially processes the input feature map , where C represents the number of channels, H represents the height of the feature map, and W represents the width of the feature map.
To prompt the attention module to capture long-range interactions with precise positional information in space, we decompose global pooling into a pair of 1D feature encoding operations. Given the input
x, we employ two pooling kernels with different spatial extents,
and
, to encode each channel along the horizontal and vertical coordinate directions, respectively. Thus, the output at height h for the c-th channel can be expressed as:
Similarly, the output at width w for the c-th channel can be represented as:
The ELA enhances positional information in the horizontal and vertical directions through 1D convolution and processes these enhanced information using Group Normalization to generate positional attention maps
and
:
where
is the nonlinear activation function,
and
represent 1D convolutions with kernel sizes of five or seven. The final output of the ELA module
Y is obtained through Equation (
5):
By multiplying the positional attention map with the feature map at the corresponding scale, a filtered feature map is generated. Then, a 1 × 1 convolution is applied to reduce the number of channels for each scale feature map to 256, ensuring dimensional consistency across different scales.
Feature Fusion Module: The multi-scale feature maps generated by the Backbone network present high-level features with rich semantic information but relatively coarse target localization. In contrast, low-level features provide precise target location but contain limited semantic information. A common solution is to directly add the high-level features with the low-level features pixel-by-pixel after upsampling to enrich the semantic information of each layer. However, this technique only performs pixel-wise addition between feature layers without feature selection. To address this limitation, the Selective Feature Fusion (SFF) module is used.
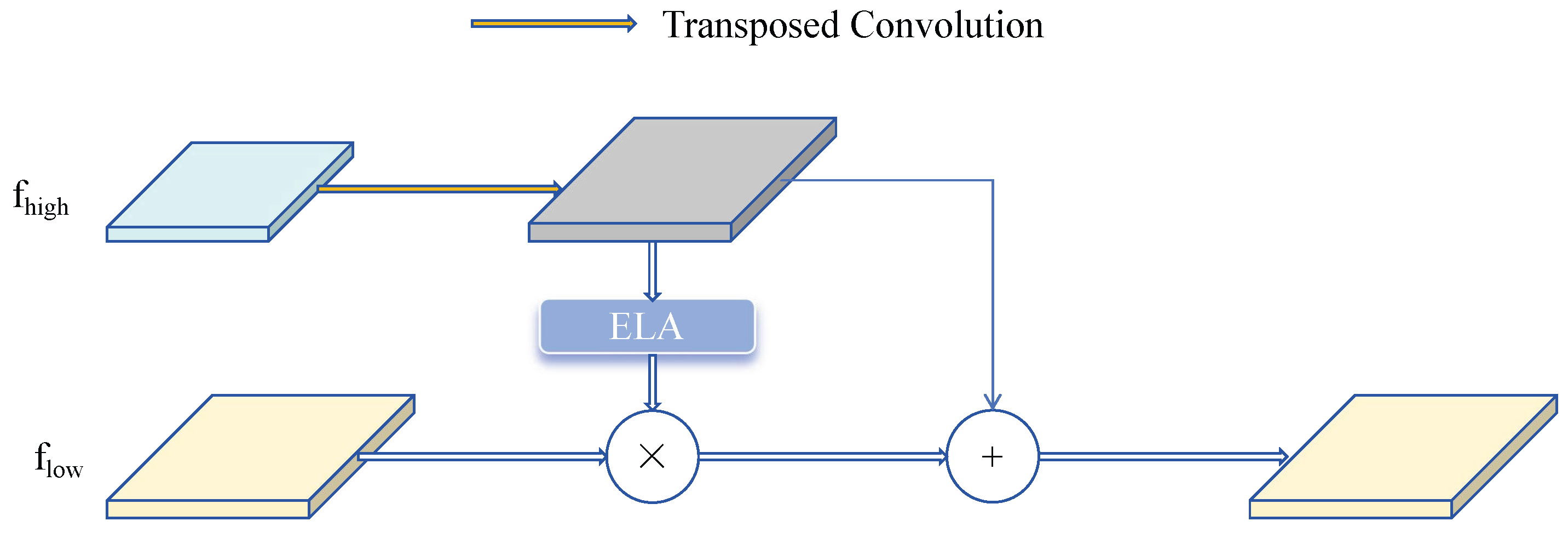
The SFF module filters key semantic information embedded in low-level features using high-level features as weights and strategically fuses features. As shown in
Figure 5, given the input high-level feature
and the input low-level feature
, the high-level features are first expanded through transposed convolution with a stride of 2 and a kernel size of 3 × 3, obtaining feature size
. The ELA module converts high-level features into corresponding attention weights to filter low-level features, obtaining features of consistent dimensions. Finally, the filtered low-level features are fused with high-level features, enhancing the model’s feature representation, obtaining
.
The enhanced feature representation significantly improves the model’s ability to detect fine features in vehicle images, thereby enhancing detection capability. ELA-FPN effectively addresses the multi-scale challenges in vehicle detection by introducing the Enhanced Local Attention mechanism and strategic feature fusion based on HS-FPN. This approach not only overcomes the limitations of the CA module but also significantly improves the accuracy and robustness of vehicle recognition tasks. By more comprehensively capturing vehicle feature information, ELA-FPN demonstrates great potential in practical applications.
3.4. Optimizing the Loss Function
The magnitude of the loss value reflects the discrepancy between the predicted value and the true value; the smaller the loss, the better the network’s regression capability. The IoU loss function is as shown in Equation (
6):
In the equation,
represents the Intersection over Union between the predicted box and the actual box.
and
denote the width and height of the intersecting rectangle between the actual box and the predicted box, while
w and
h represent the width and height of the predicted box, and
and
denote the width and height of the actual box. The original model’s loss function utilizes the CIOU [
29]. The computation is as shown in Equation (
8):
Within the formula, v denotes the aspect ratio consistency between the predicted box and the true box. and represent the width and height of the smallest enclosing rectangle around the actual and predicted boxes, while (x, y) indicates the center point of the predicted box, and (, ) represents the center point of the actual box.
When the values of
and
are equal,
,
and
cannot be stably expressed. Moreover, the aspect ratio variation trend of CIOU is generally negatively correlated, easily causing target prediction box mismatch issues during boundary box prediction. The existing dataset lacks research on foreign objects in railway contact networks, and this experiment’s dataset is self-labeled, inevitably containing some low-quality labeled boxes. Therefore, we use the WIoU loss function [
30] to optimize the model by introducing gradient gain and proposing a dynamic non-monotonic mechanism, focusing on ordinary anchor boxes. The computation is as shown in Equation (
11):
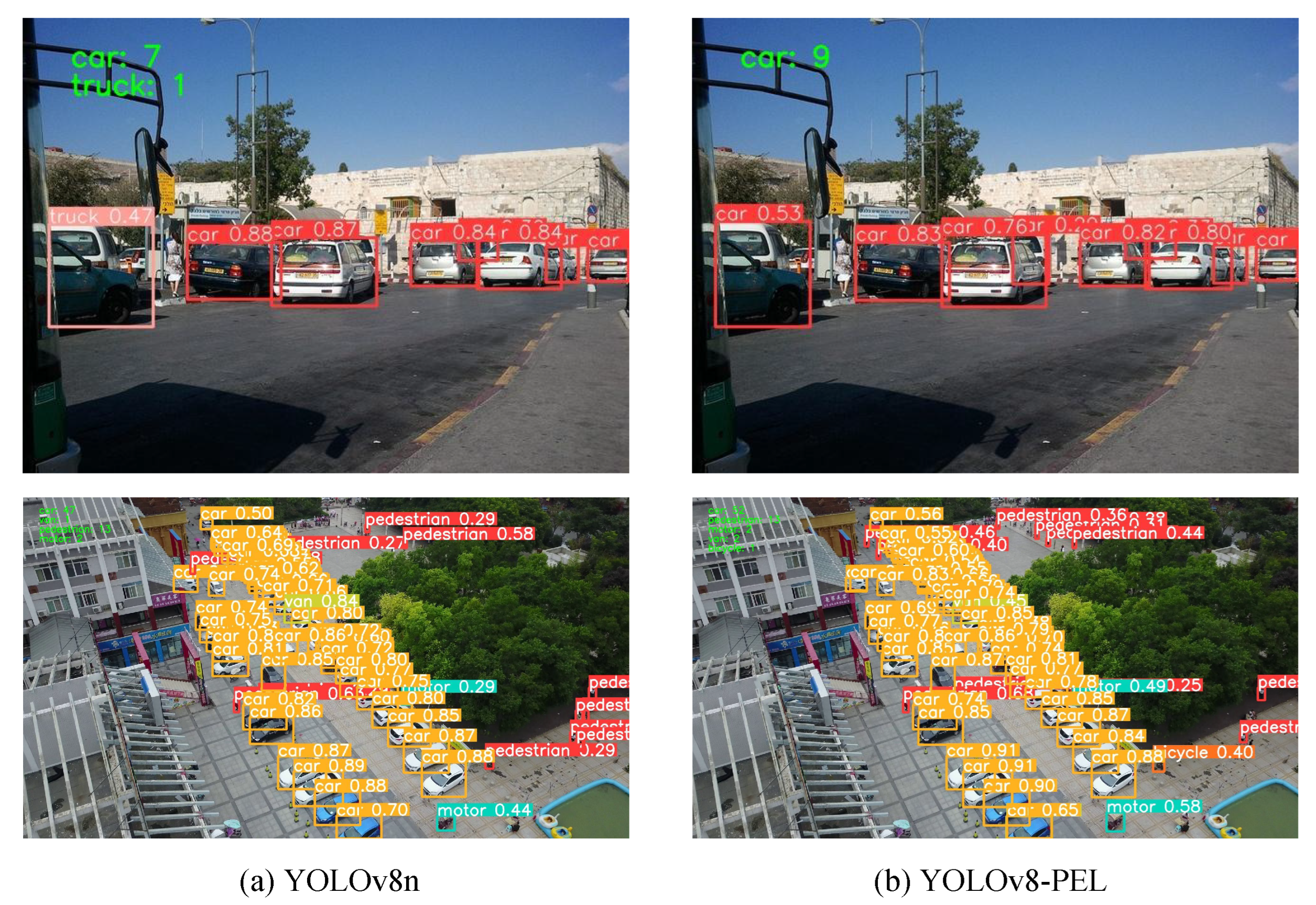
Within the equation, and are hyperparameters, and is an adjustment parameter used to control the rate of change in weight r. To effectively prevent the generation of gradients that hinder convergence, the superscript “*” signifies the exclusion of Wg and Hg from gradient calculations. represents the outlier degree, while signifies a dynamic variable. On one hand, this loss function assesses the quality of anchor boxes through the outlier degree, allocating smaller gradient enhancements when the value is significantly large or small, thereby diminishing the influence on bounding box regression. This approach enables the model to concentrate on anchor boxes of average quality to avoid excessive penalties due to geometric factors such as distance and aspect ratio. The refined loss function mitigates the detrimental gradients associated with extreme samples in vehicle detection—where the vehicle targets are exceedingly small or blurred—balances the model training outcomes across various image categories, and enhances the generalizability of the training results, leading to precise detection performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}