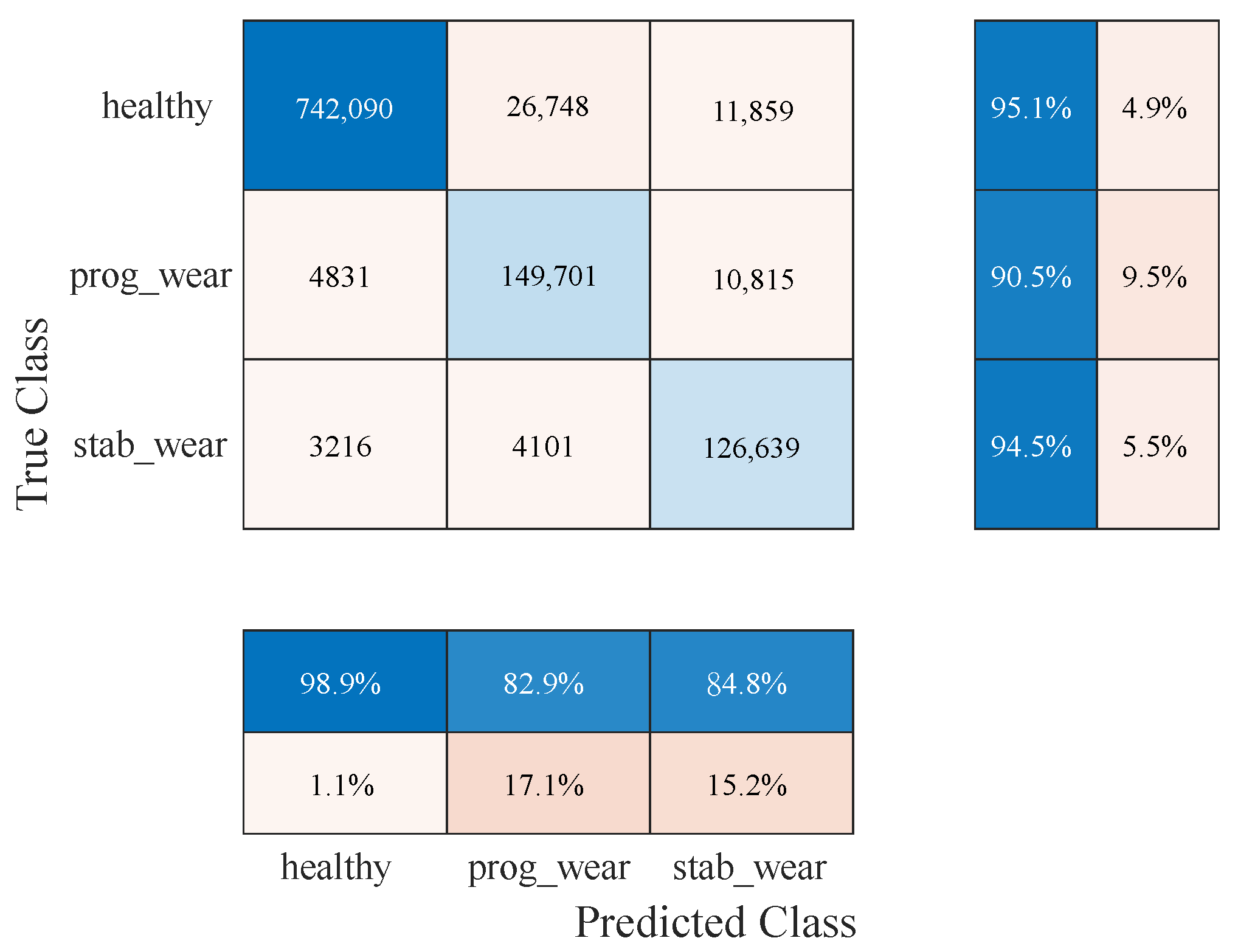1. Introduction
Monitoring failure in industrial systems is critical to ensuring their reliability and competitiveness. The task is to identify precursors of failure in the collected data, which can be used to build failure prediction models. Engineering can rely on physical models that represent the system itself, calibrated using appropriately collected data. However, many industrial models require continuous optimisation due to their inherent complexity involving non-linear relationships and numerous variables [
1]. In addition, pure physics-based modelling can be costly to implement for complex systems. Furthermore, using systems under variable conditions requires constant updating of the implemented physical models. When used beyond the conditions of implementation, behavioural laws can quickly become obsolete.
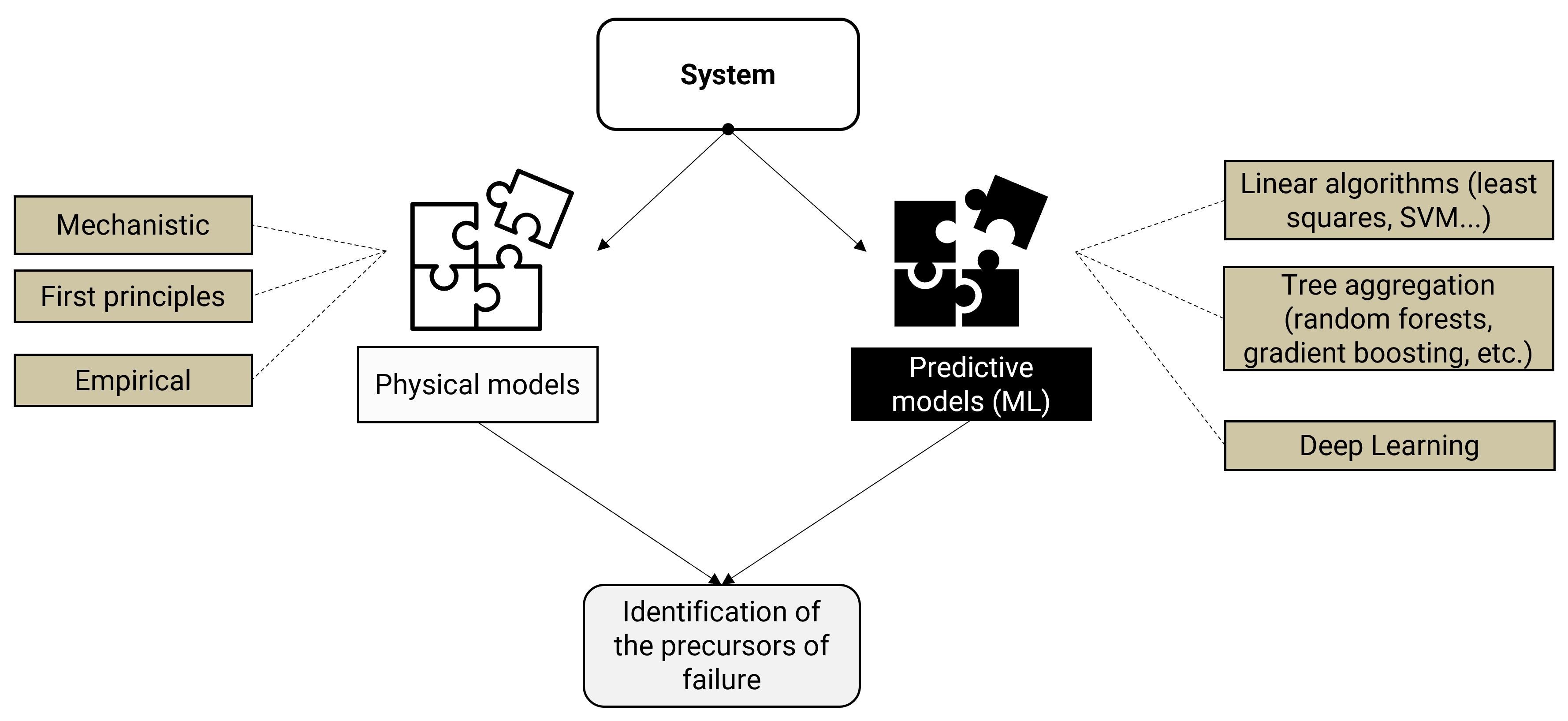
In such cases, the relationships between the inputs and outputs of these complex systems can be modelled using industrial data, fundamental principles, or a combination of both, known as hybrid modelling. Hybrid modelling, which takes advantage of both principle-based and data-driven models, provides a balance between correct process generalisation and optimised computation based on historical factory data [
2,
3]. There are several architectures in the literature that combine these different models [
4,
5,
6]. Hybridisation can be achieved by interacting between models, merging outputs from both types of models, and using outputs from one model to feed into the second [
7].
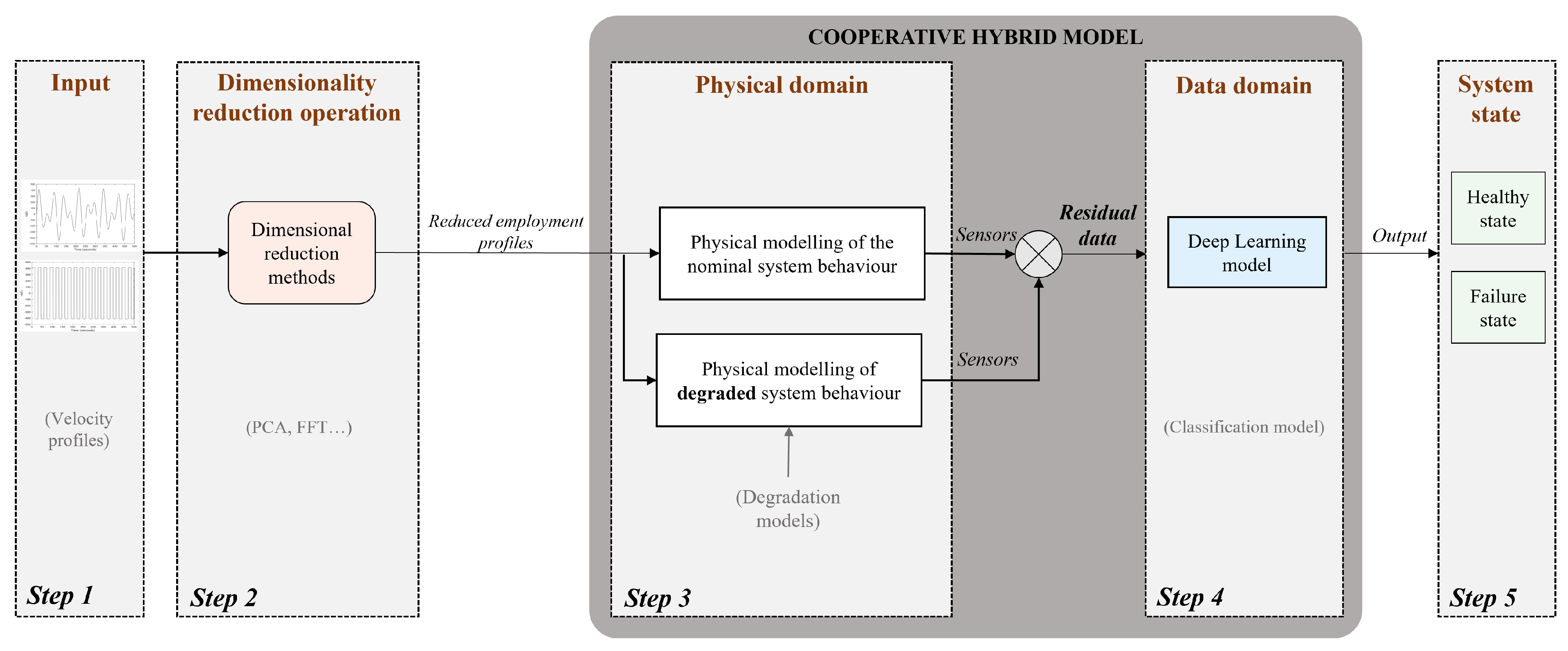
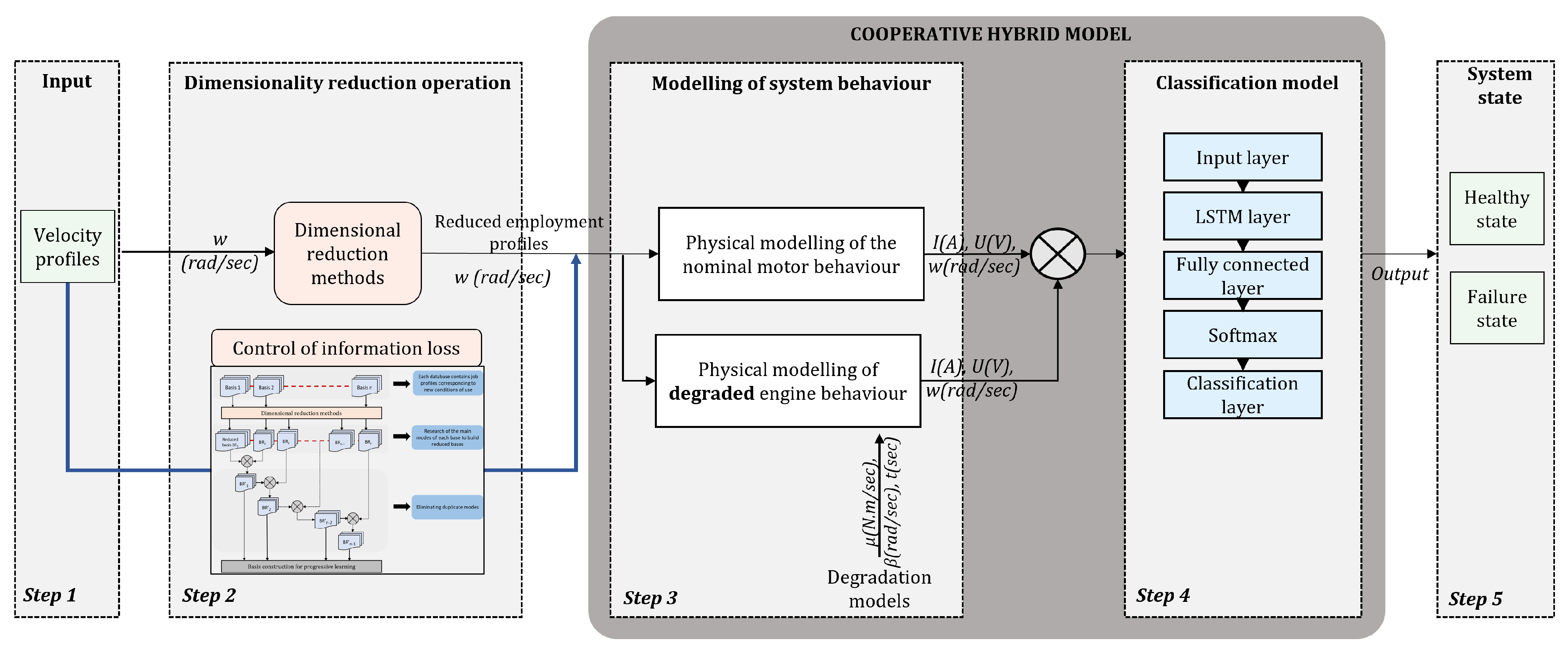
This work builds on a literature review to define and complement several existing hybrid modelling approaches. In the first part of this paper, our first contribution is described: a new type of hybridisation between deep learning and physics-based models is proposed and called cooperative hybridisation (see
Figure 1). Here, the physical knowledge model is used to simultaneously compare the nominal system behaviour with the actual behaviour derived from the system data. In this way, the physical knowledge of the nominal behaviour is integrated into the input data of the deep learning model. The deep learning model is trained solely on the difference between the behaviour of the system when it is in good condition and its behaviour when subjected to characterised disturbances.
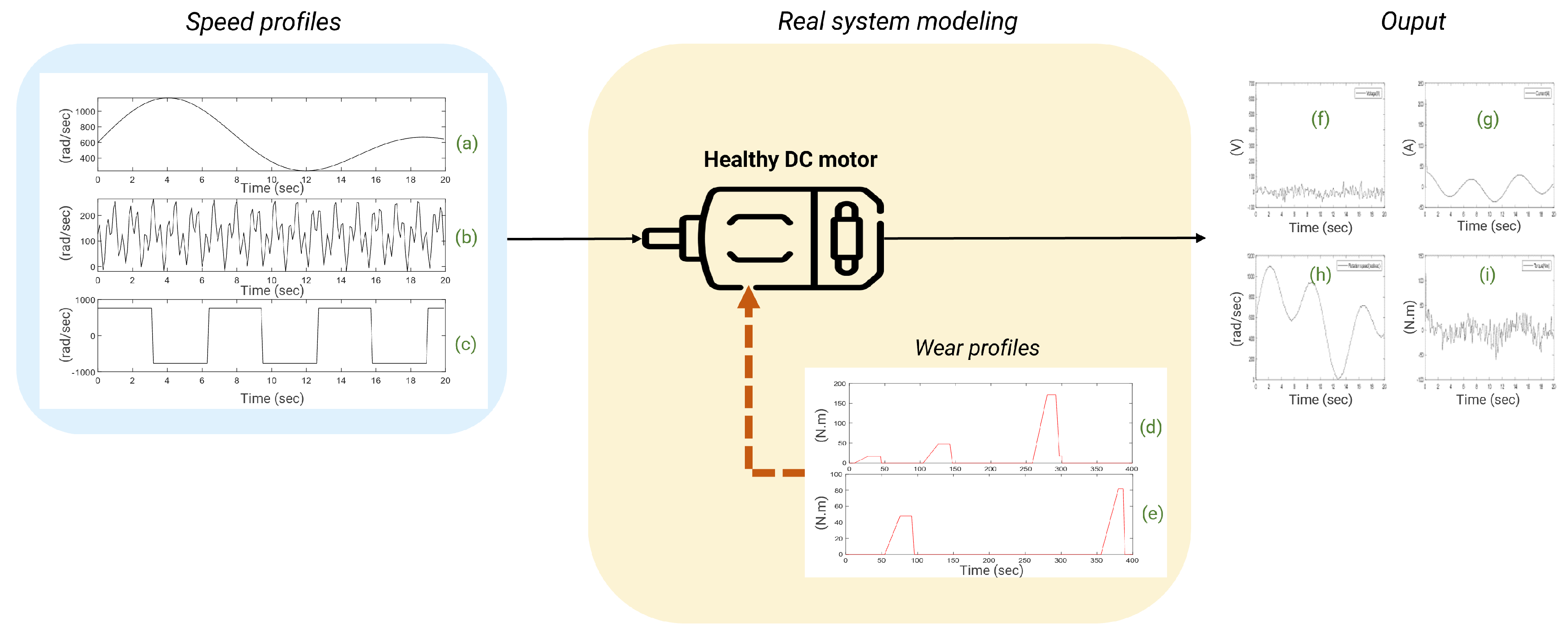
To validate the method, it is applied to the task of fault diagnosis in DC electric motors and is subsequently referred to as the Cooperative Hybrid Model for Classification (CHMC). Nevertheless, it is a methodology that can be adapted to other tasks (prediction or classification). The study of the direct-current electric motor facilitated the implementation of the method, since it is extensively studied in the literature and its physical model representing its nominal behaviour is well known. The faults studied are bearing faults, which are the most common cause of failure [
8]. The main advantage is the finer detection of bearing faults, resulting in a more pronounced drift of the signals recorded on the system.
The identification of faults in servomotor bearings is imperative, as such failures are among the most prevalent causes of servomotor dysfunction, resulting in diminished performance and augmented downtime. The present study concentrates on Kollmorgen’s AKM42 servomotor, as it represents a paradigmatic type of servomotor employed in industrial applications [
9]. Furthermore, a test bench has been configured with this servomotor, which will facilitate the verification of the methodology on real data in future investigations.
However, the performance of hybrid modelling is highly dependent on the complexity of the hybrid architecture adopted and the extrapolation requirements specific to each application. In some cases, where hybrid models are not suitable for industrial processes, data-driven models may indeed offer better performance. However, incorporating knowledge of the physical process is crucial as it improves the transparency of machine learning algorithms [
10]. Therefore, an additional step must be added to hybrid modelling to increase the generalisation ability of the model to new scenarios and raise the extrapolation limit of the model. It is common to observe performance gaps when transferring successful data-driven or hybrid models to other applications, especially when the characteristics of the input data set differ significantly from the one on which the model was trained [
11]. This limitation is due to the inability of the model to generalise its predictions to new input data, highlighting the importance of developing methods to address this issue. The one considered hereafter is the dimensionality reduction of the input data [
12], which is our second contribution of this work.
This approach involves isolating essential information from multiple collected data to improve system fault detection. Dimensionality reduction involves projecting data from a high-dimensional space into low-dimensional representations while preserving similarities between input data. Methods fall into two categories: feature selection and feature extraction. The former selects a subset of features without transforming the data, while the latter generates new features from the original data. These techniques are crucial for analysing complex data, as demonstrated by the use of various descriptive statistical methods. In particular, feature extraction captures non-linear relationships between variables, preserving information while reducing data size [
13,
14].
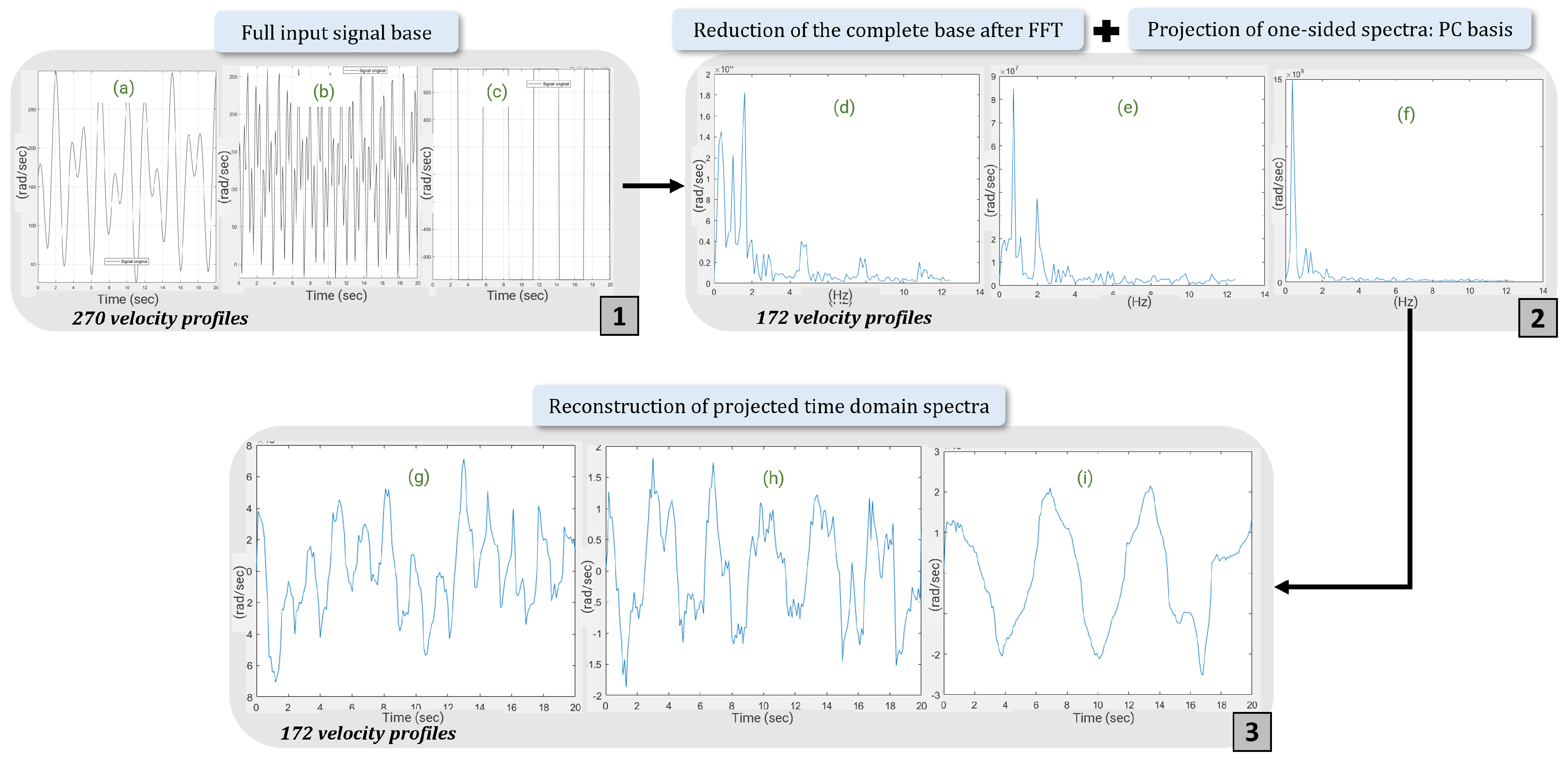
The motivation for this approach, developed in a second part, lies in the simplification of input databases to facilitate training and overcome difficulties in the generalisation of predictive models. The aim is to apply reduction methods to the input data of the hybrid model (usage profiles) in order to determine reduced bases that contribute to a satisfactory classification performance. In the case of industrial systems, in particular the direct-current electric motor, this is particularly useful when the same motor is used in more extreme conditions than those encountered in the sometimes costly modelling. Physical models then have great difficulty in adapting to real-world scenarios and produce inconsistencies.
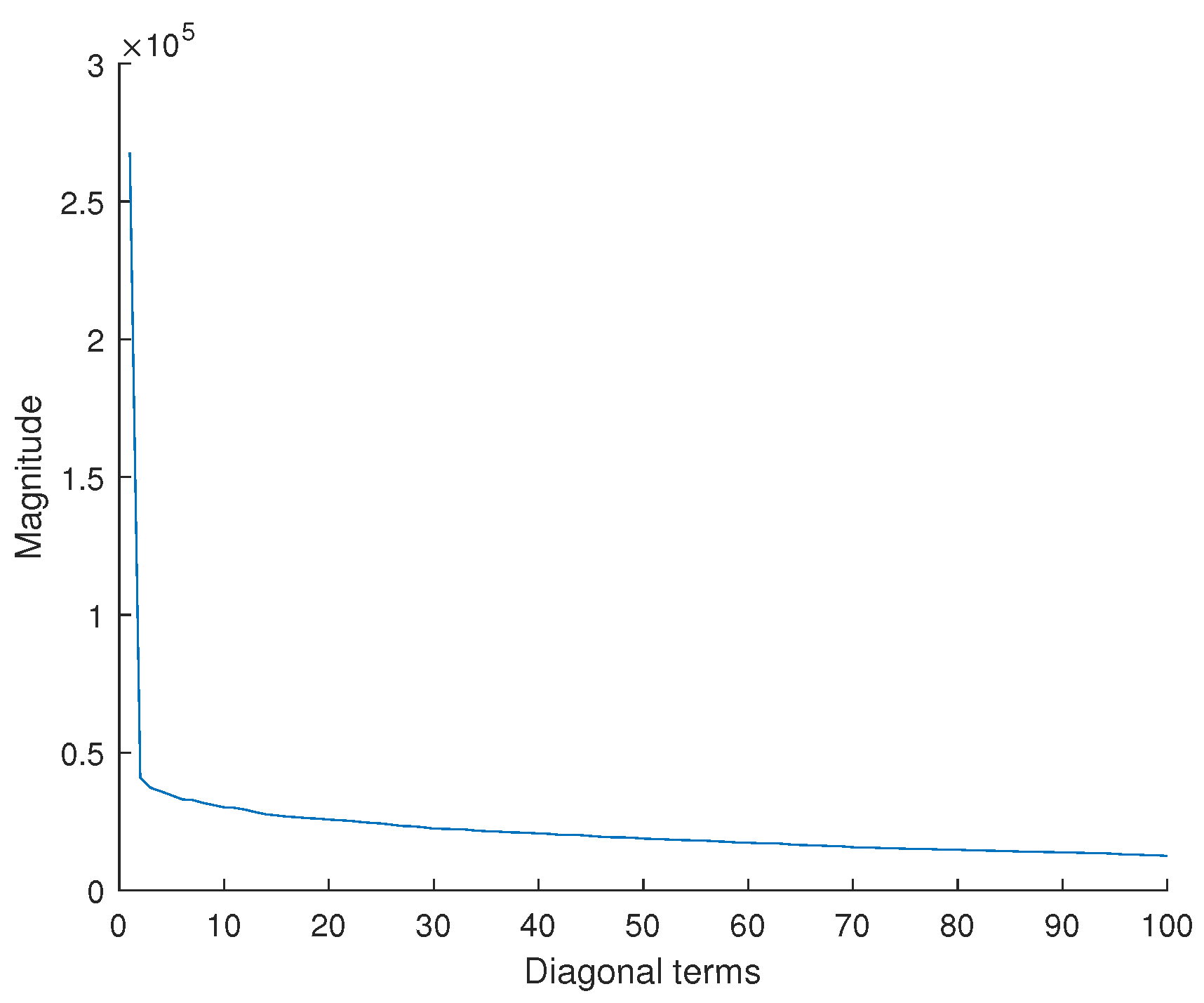
Therefore, this approach, integrated into our hybrid modelling methodology, firstly increases the relevance of our analyses and predictions for use scenarios encountered during the learning phase. Secondly, by integrating these reduction methods, the CHMC model is able to satisfactorily detect bearing failures in new extrapolated scenarios. Given the shape of the usage profiles, which are periodic with a limited variety of occurrences, we will demonstrate that the most relevant method for this use case is the singular value decomposition (SVD) method. Although the methodology is applied to a specific industrial case, namely the electric motor, each step is precisely detailed to be reproducible on another system. It will then be necessary to adapt it to the physical knowledge of the system under study and to adjust the parameters of the reduction methods according to the available databases.
The main contribution of this work is based on the implementation of the CHMC that integrates real system data via physical models, allowing rapid model construction and adaptation to new usage profiles without loss of performance. The CHMC model, then combined with dimension reduction methods, enables the extrapolation of results to novel scenarios with a reduced number of input signals during the learning phase. The document is organised as follows: in
Section 2, a review of the state-of-the-art with respect to the possibilities for the hybridisation of physical and data-driven models.
Section 3 includes a complete description of the methodology, divided into two parts (hybridisation and dimensionality reduction methods), as well as the impact of the methodology on the fault diagnosis task. Finally, the conclusions of the work and the limitations of the method are discussed in a fourth section.
4. Results and Analysis
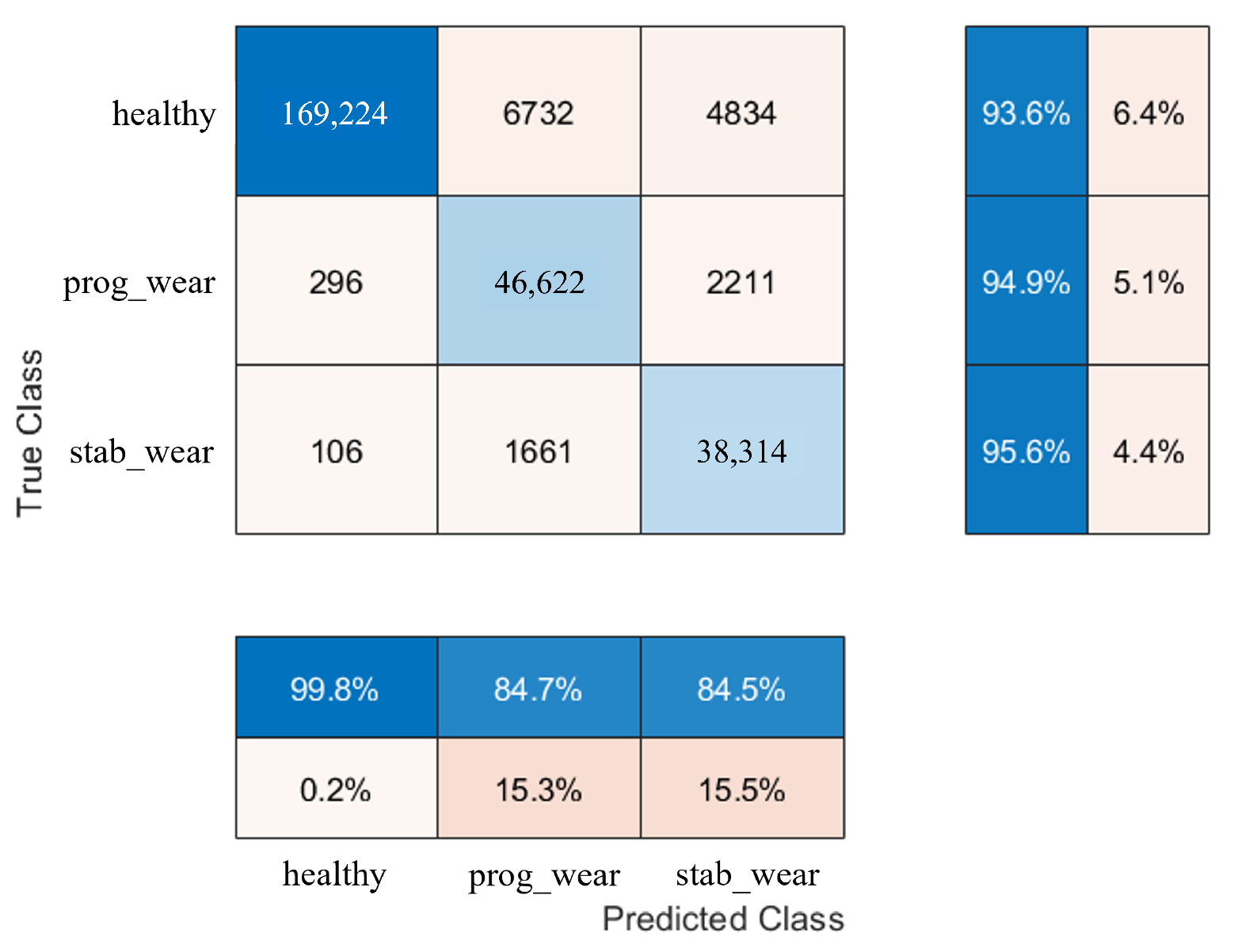
The study evaluates the performance of the CHMC model that integrates physical knowledge of an electric motor, compared to the NHMC model that does not use this information. Both models are evaluated on unbalanced data sets where the classes are distributed as 15.23% for “progressive failure”, 11.98% for “stable failure” and 72.79% for “healthy state”.
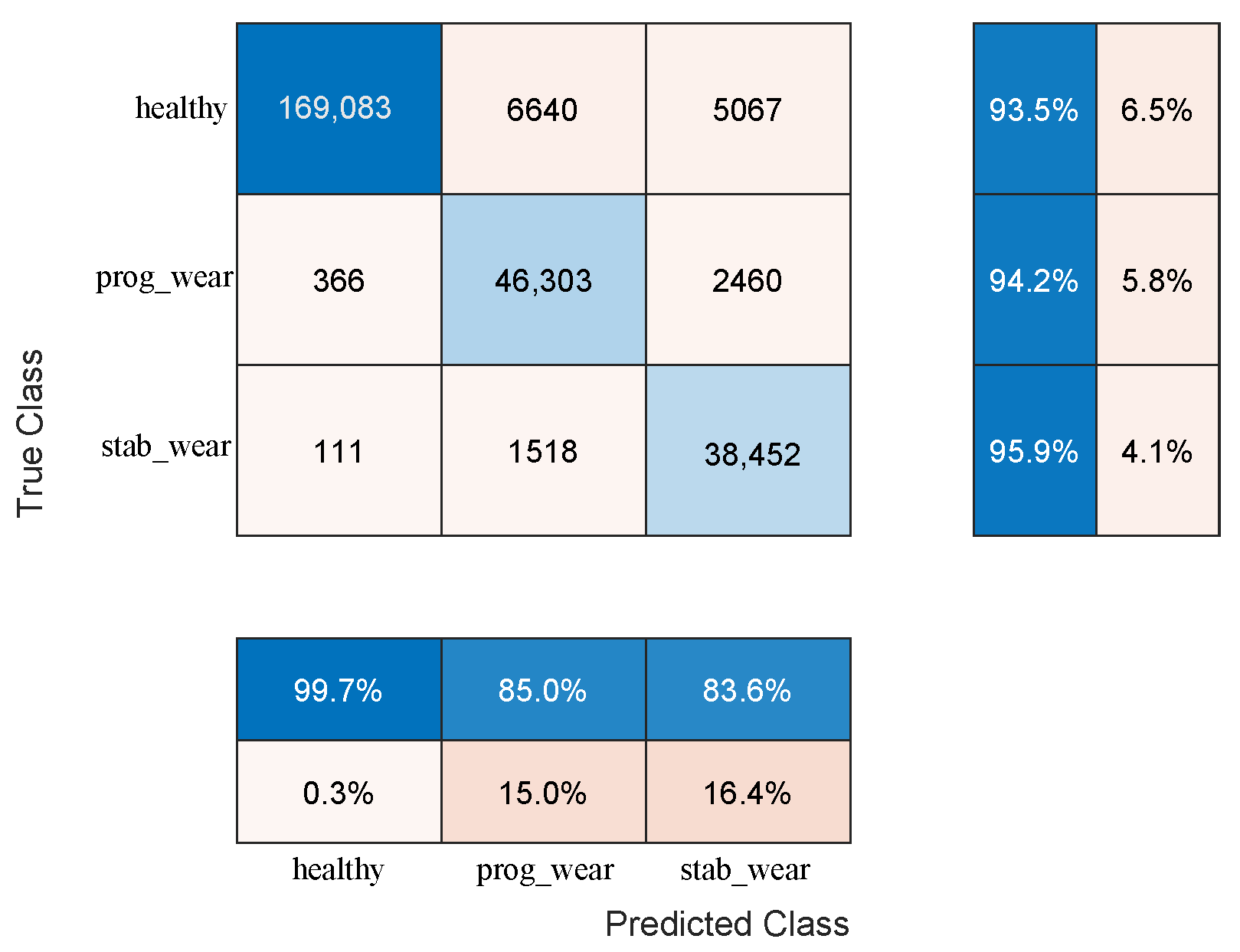
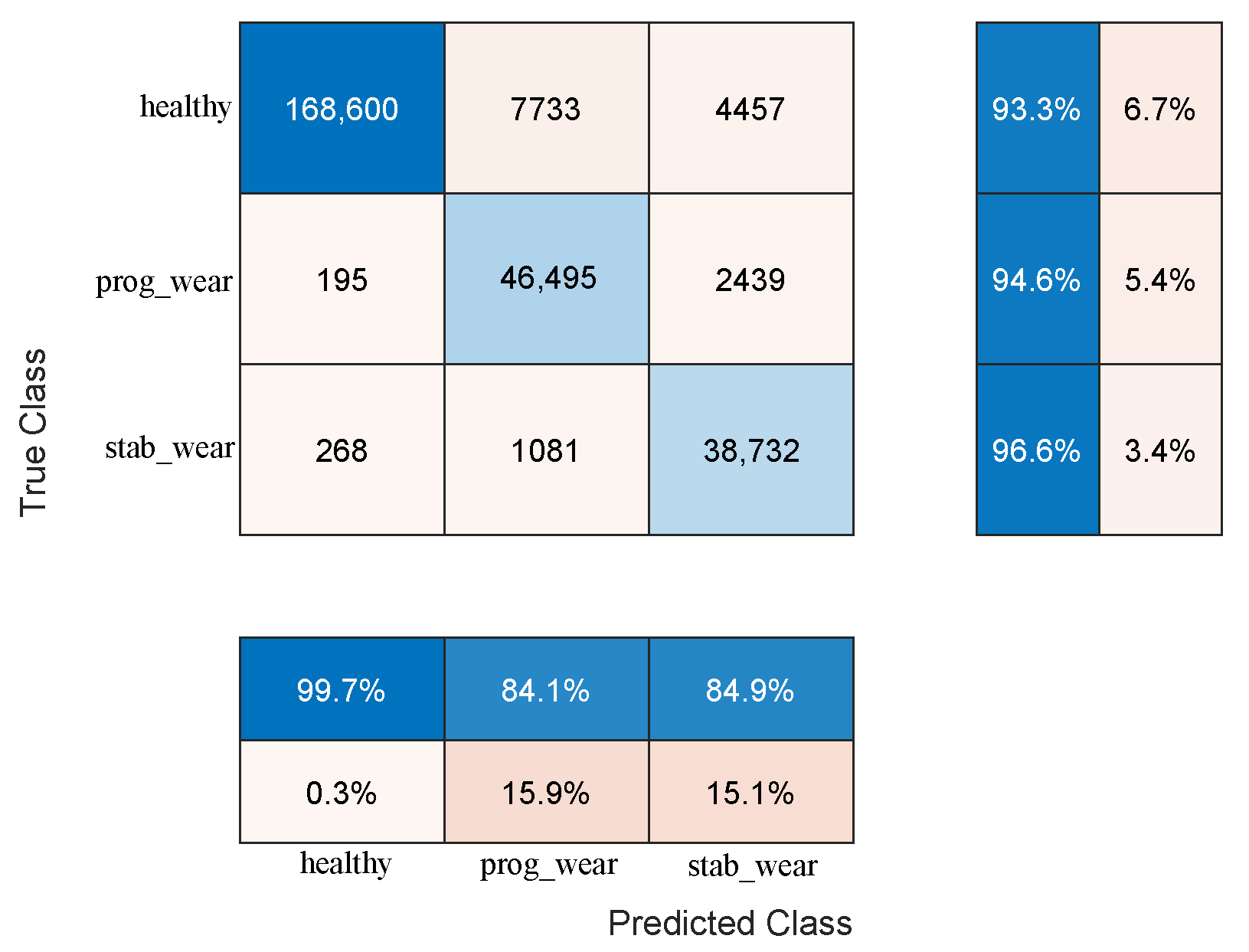
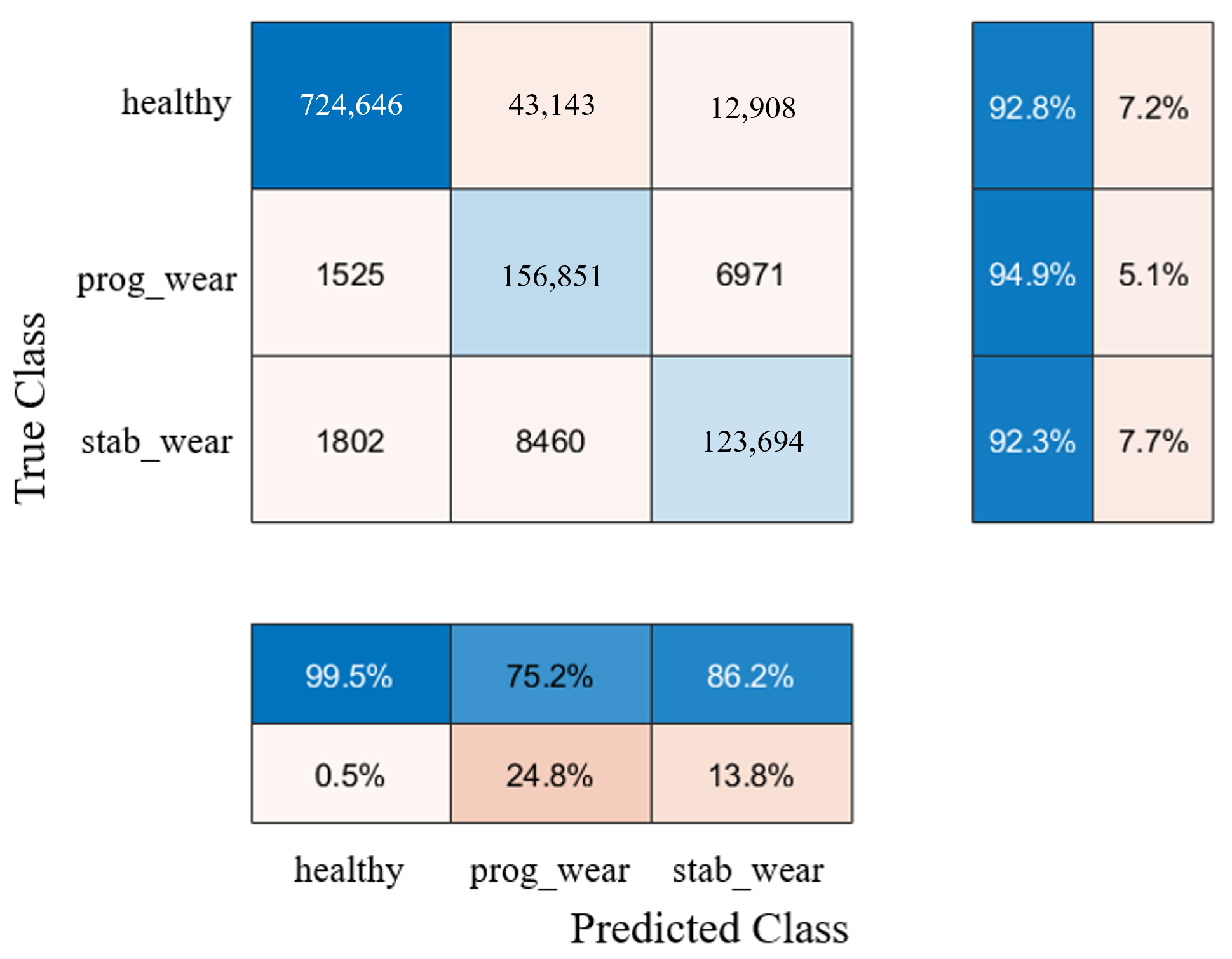
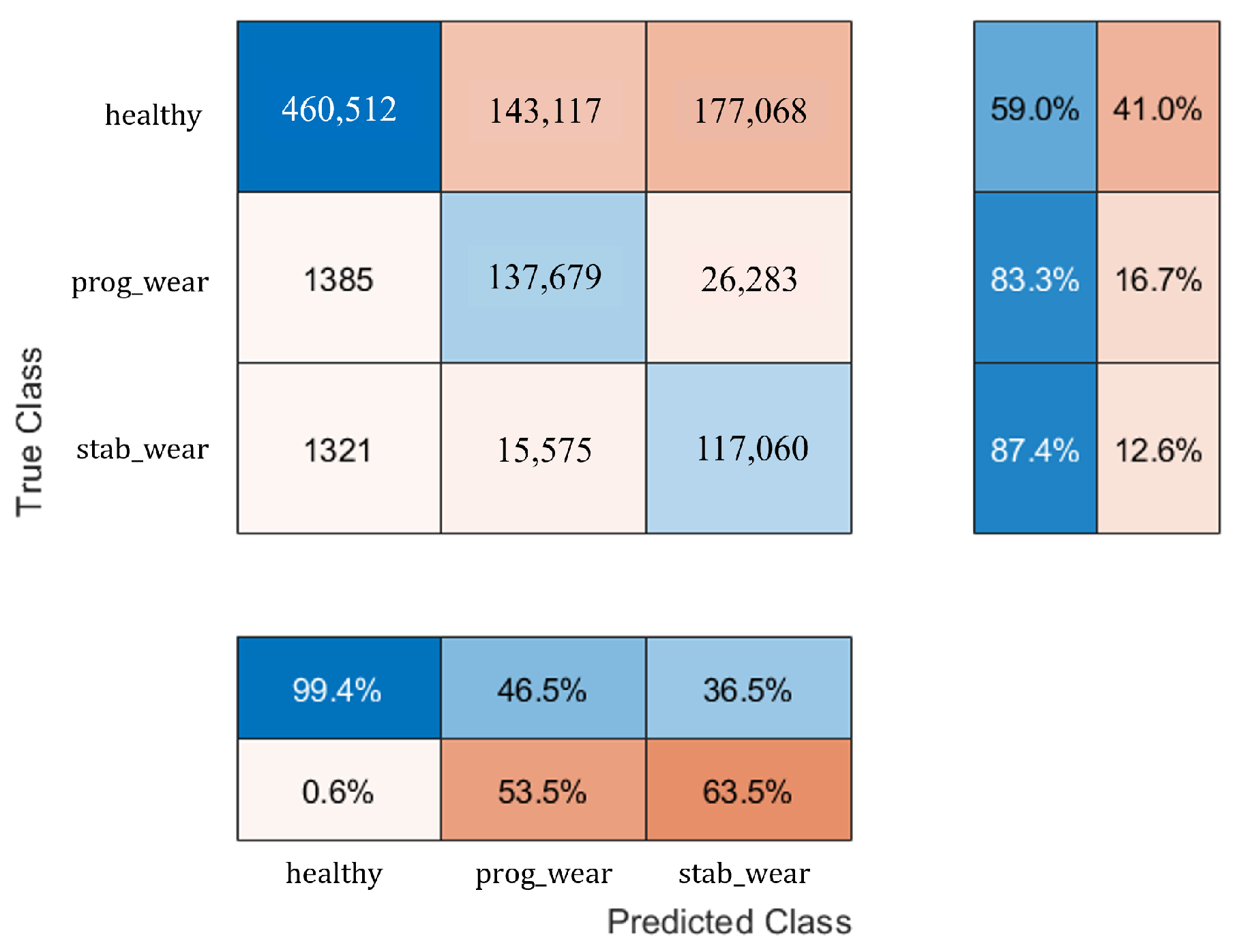
For usage profiles analogous to those in the training set, both models demonstrate comparable performance without reduction (see
Table 2). However, the CHMC model exhibits superiority over the NHMC model in detecting true negatives (90% against 89%), as it is capable of leveraging the motor’s nominal physical behaviour to more effectively differentiate between the healthy and failure states (see
Figure 3). The NHMC model encounters greater difficulty in distinguishing between the two failure states (83.92% against 86.56% for progressive failure and 89.14% against 89.41% for stabilized failure), resulting in less precise failure detection. Consequently, the CHMC model is more appropriate for predictive maintenance, where minimising false failure warnings is paramount.
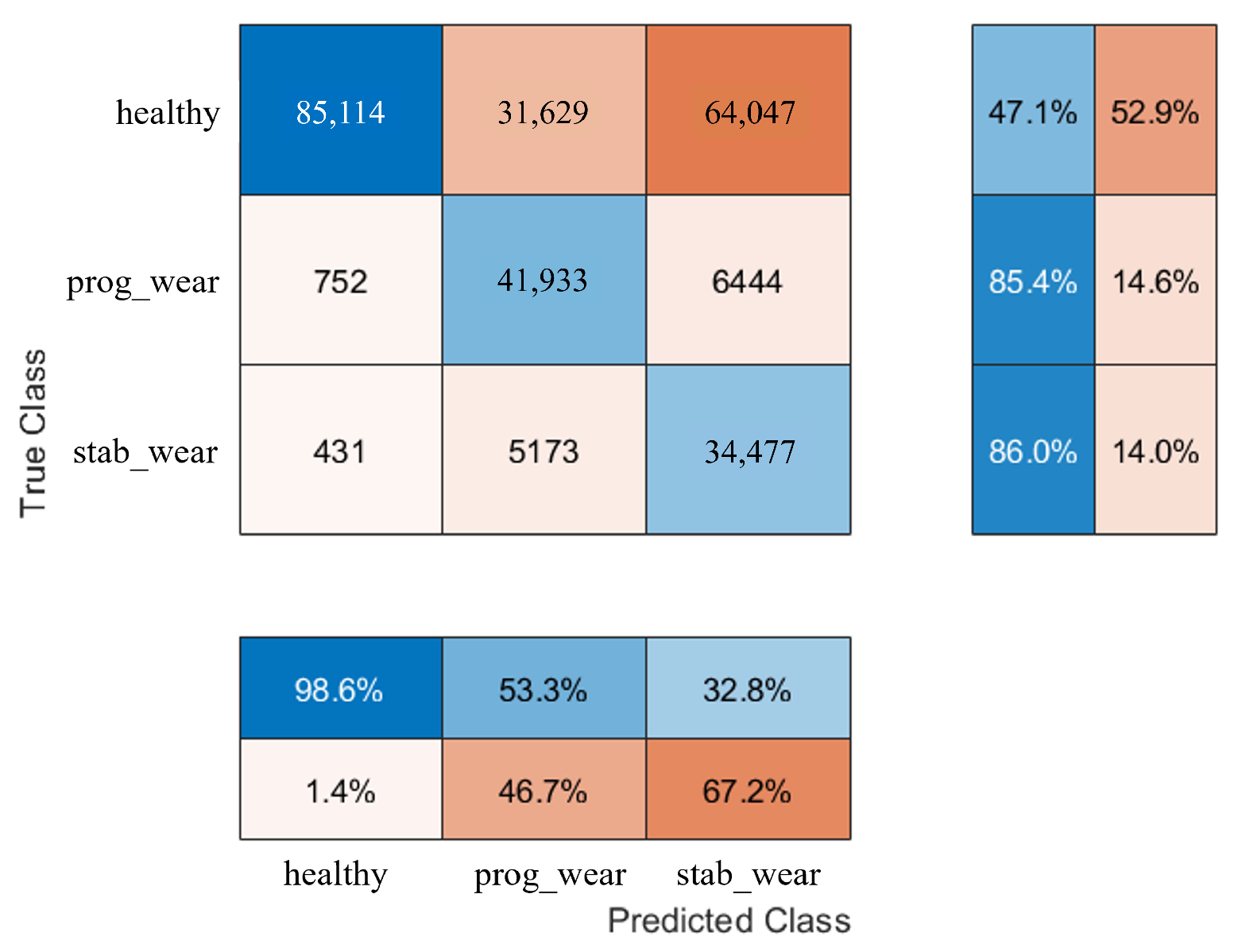
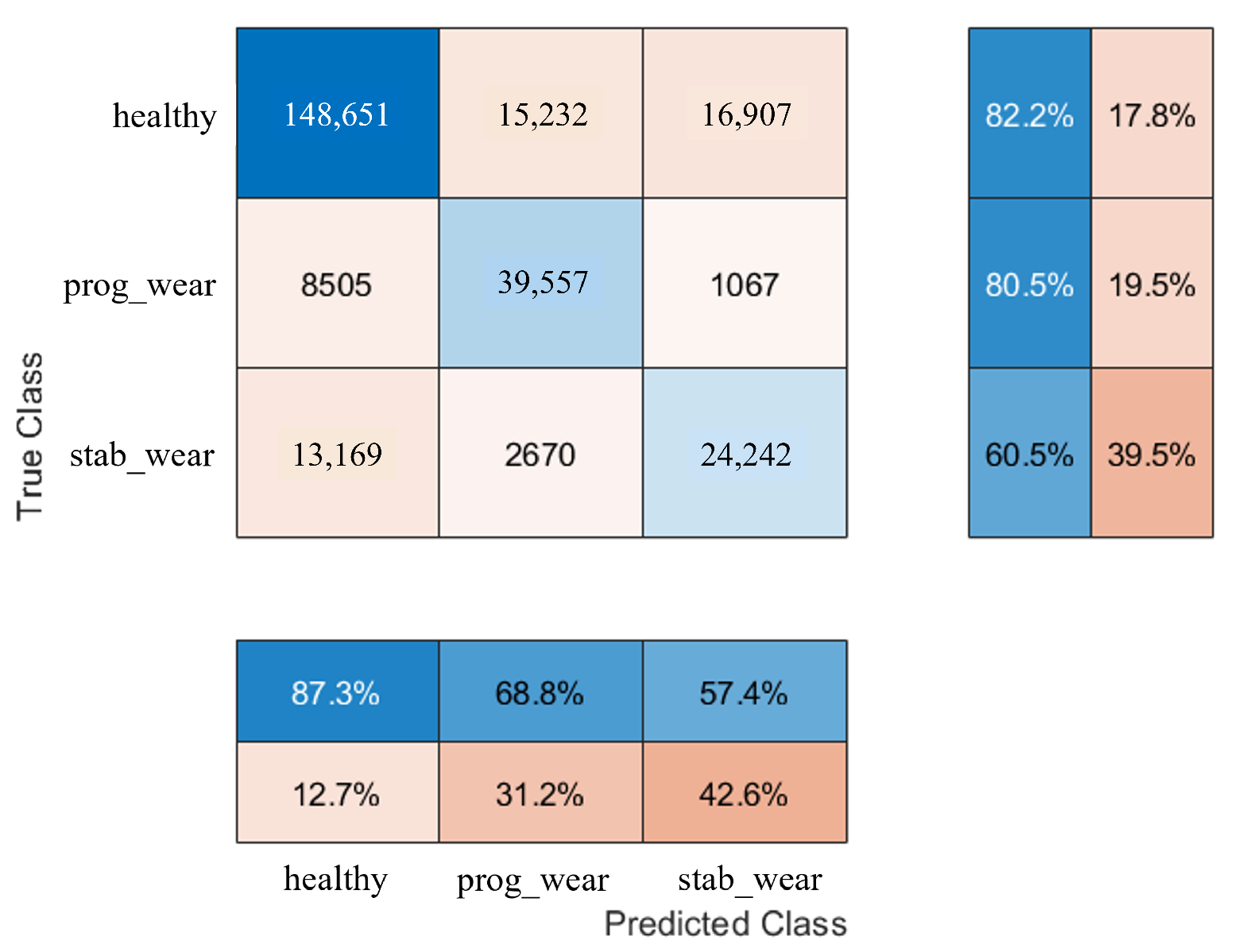
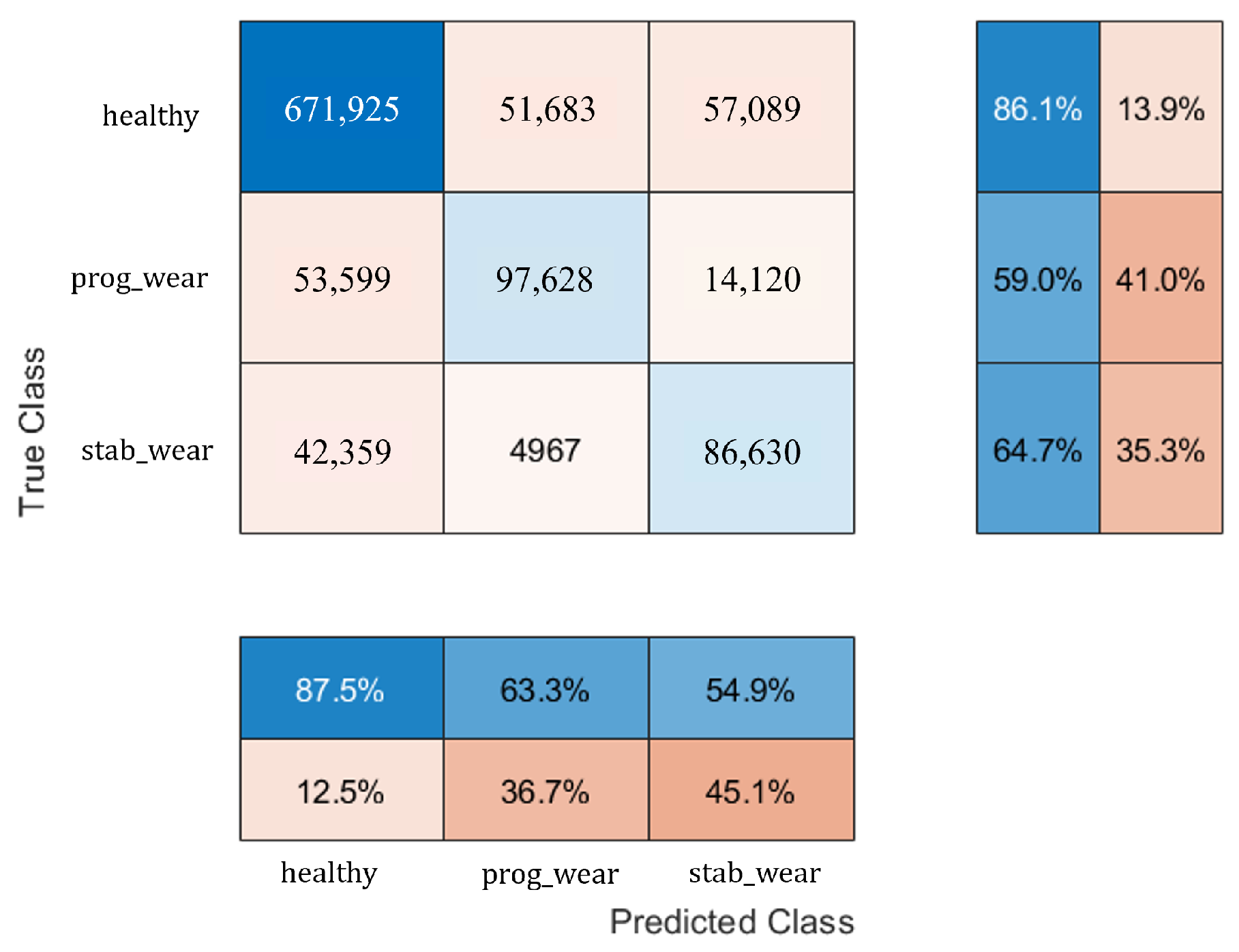
When exposed to new usage profiles, the CHMC model adapts well, although it struggles slightly more than the NHMC model in detecting true negatives. The study tests the models on new input signals with a 42% increase in frequency range and a 2.5% increase in amplitude compared to the training data. The CHMC model still performs better in detecting true positives and handling new data, showing its greater extrapolation capability (see
Figure 11 and
Figure 12).
The employment of dimensionality reduction techniques, especially SVD, serves to reduce the complexity of the input data. As shown on
Table 5, the CHMC model consistently outperforms the NHMC model when applied to reduced data, thereby demonstrating the efficacy of integrating physical models and dimensionality reduction in enhancing the model’s capacity to generalise, detect faults, and adapt to novel scenarios. This approach reduces the need for retraining, making the CHMC model a cost-effective and efficient solution for motor fault classification in industrial settings. In conclusion, the CHMC model, through the integration of physical knowledge and dimensionality reduction, provides a significant advantage in fault detection, model adaptation, and performance across varying usage profiles, ensuring more reliable and efficient predictive maintenance.
5. Conclusions and Future Works
5.1. Conclusions
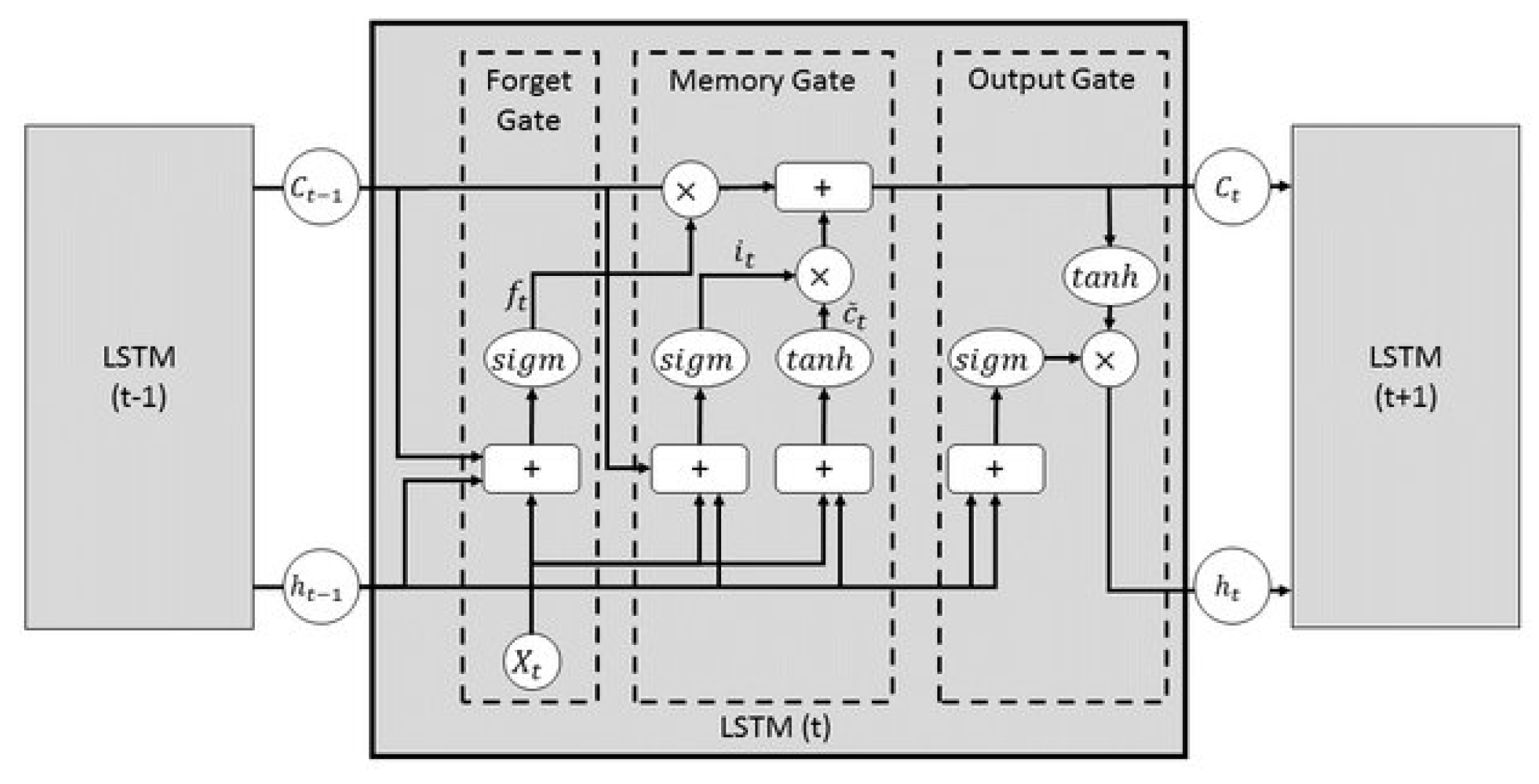
In this study, a Cooperative Hybrid Model of Classification was explained in detail. The CHMC model offers a new approach to the challenges posed by conventional modelling when it comes to handling data from multiple system usage profiles at in a cost-effective manner. Such models require, first and foremost, access to real system data, as well as to part of the system’s physical models. Thus, one of the main results presented is the rapid construction of the hybrid model, provided that the system knowledge is accessible and/or implemented. This model has the advantage of being enriched over time, as new usage profiles appear.
As a first step, the newly implemented hybrid architecture was verified on the motor use case. The cooperative hybrid model slightly improves the classification of motor faults artificially injected into the simulated physical model. On known usage profiles, the performance improvement of the CHMC model is not significant compared with modelling without model hybridisation. However, no loss of performance is observed. The strength of the CHMC model lies above all in its ability to extrapolate when faced with new usage profiles. Indeed, the integration of the system’s physical models enables it to easily distinguish between the onset of abnormal behaviour, and, in particular, the onset of component failure. Since performance is preserved without the need to train again, even in the presence of new unknown data for the model, this could save time when monitoring a system in real time. The proposed approach based on dimensional reduction has shown that the model implemented is able to achieve equivalent performance by reducing the number of input data. This means that when a new usage profile is applied to the motor, the model seeks to break it down into the several profiles it has already encountered during its training period, in order to first identify and localize the fault. This type of modelling also provides a better understanding of the decisions made by the CHMC model. If the residuals do not oscillate around zero, the model will tend to indicate the onset of failure. In future work, we plan to implement a complementary algorithm to recognize whether high residuals reflect failure or a usage profile that is too far removed from the initial base of usage profiles. The CHMC model thus provides a starting point for measuring the explicability of predictive models.
In summary, the CHMC model provides an innovative approach to efficiently process data from multiple system usage profiles by facilitating the learning process and combining physical models of the system with real data. It is characterised by its ability to extrapolate to new scenarios, enabling effective monitoring and a better understanding of the model’s decisions.
5.2. Limitations and Future Works
For future endeavours, several limitations within the scope of this study warrant investigation. One of the main limitations relates to the methodology’s reliance on the fusion of existing physical models with a recurrent neural network (RNN), suggesting a presumption of familiarity or partial understanding of said physical models. Should this prerequisite not be met, the substitution of empirically derived knowledge from expert feedback on healthy behaviours may be warranted. Furthermore, the existing literature highlights the prevalence and efficacy of hybridising deep learning models, a prospect to be considered by integrating such hybridisation with the methodology established here.
Another limitation lies in the deliberate initial selection of reduction methods commonly used by physicists. An ongoing exploration involves juxtaposing the dimensionality reduction methods evaluated in this study with more advanced techniques such as kernel principal component analysis (k-PCA), linear discriminant analysis (LDA), t-distributed stochastic neighbour embedding (t-SNE), or locally linear embedding (LLE).
Although K-PCA and more complex structures, such as autoencoders, have been tested without significant improvements in model performance, this remains a promising avenue for future research, particularly for more complex systems with multiple interlocking subsystems.
In addition, while noise in the output data of physical models has been acknowledged, quantifying the resilience to noise and outliers remains a prospect for future investigations.
Finally, while the use case chosen in this study has potential applicability across different domains, careful analysis is essential to adapt the model to alternative systems. Indeed, while the overarching methodology aims for deployment across different systems, the direct transferability of expert physical knowledge (physical models, reduction base profiles) between systems is not guaranteed. Therefore, a comprehensive review is essential to ensure the adaptability and effectiveness of the model in different contexts.
As part of future work, the present methodology is to be evaluated through experimentation on authentic data from an alternative motor, characterised by divergent nominal properties when compared with a test bench and an additional modelled system.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}