1. Introduction
Stroke, or cerebrovascular accident (CVA), kills almost 130,000 Americans each year, which is one out of every twenty deaths. On average, an American dies of a stroke every four minutes [
1]. About 800,000 people in the United States have a stroke each year. Stroke costs the United States an estimated 34 billion USD each year. The incidence of this disease is expected to increase (due to an aging population and a rise in obesity), while the CDC reported that nearly one-fourth of the deaths due to strokes are avoidable [
1,
2]. Early identification of people at risk of stroke would allow earlier implementation of preventative strategies like medication and lifestyle changes to save lives, prevent disability, and save hundreds of thousands of dollars from each incident stroke [
1]. The 34 billion USD per year total direct cost related to stroke could be lowered by 25% with appropriate protocols for stroke prevention [
1,
2].
To our knowledge, there is no effective screening tool or a stroke risk algorithm for predicting individuals at risk of stroke which is developed based on a diverse dataset. Our literature review found a number of stroke studies on specific population groups [
3,
4,
5,
6,
7,
8]. These models, however, did not predict an individual’s 5-year or 10-year incident risk, nor were the sensitivity and specificity of the models provided. We also observed that the published risk prediction models do not adequately capture a substantial proportion of people at high risk of stroke (e.g., the Framingham score [
3] predicted only 47% of the morbidity [
9], lacked precision in risk estimation, and has other limitations [
10]). There is thus a need for greater prediction accuracy and a screening tool. Furthermore, the published stroke prediction models [
9,
10] lack innovative retinal image analysis algorithms, even though recent studies have shown that retinal vessel features (such as vessel width and focal arteriolar narrowing) are statistically significantly associated with stroke [
11,
12]. Motivated by this unmet need, our system included retinal imaging (color fundus imaging, the ophthalmoscope/fundus camera as the sensor) to improve patient awareness and potential clinical application.
4. Discussion
The application of AI to clinical medicine is in its infancy, and several steps remain for meaningful clinical use. For stroke prevention, the first step is to determine whether an AI prediction model can be developed at all which is an improvement on known clinical models. This paper has demonstrated such a system with satisfactory performance on large, well-characterized existing datasets. At this point, however, one might want to focus on people who would not otherwise have an indication for stroke risk-reducing therapy based on current guidelines (e.g., hypertension, high ASCVD risk, atrial fibrillation). Thus, an immediate application could be an advisory tool to a patient with a high risk for stroke in 5 years, which the patient and physician could accept or reject, about the modifiable risk factors: diet, exercise, and BP control, with the understanding that definitive prospective proof of benefit is pending. The same philosophy has guided our creation of a prediction model for AMD based on the AREDS dataset, with the understanding that prospective validation is still required in studies that are now ongoing.
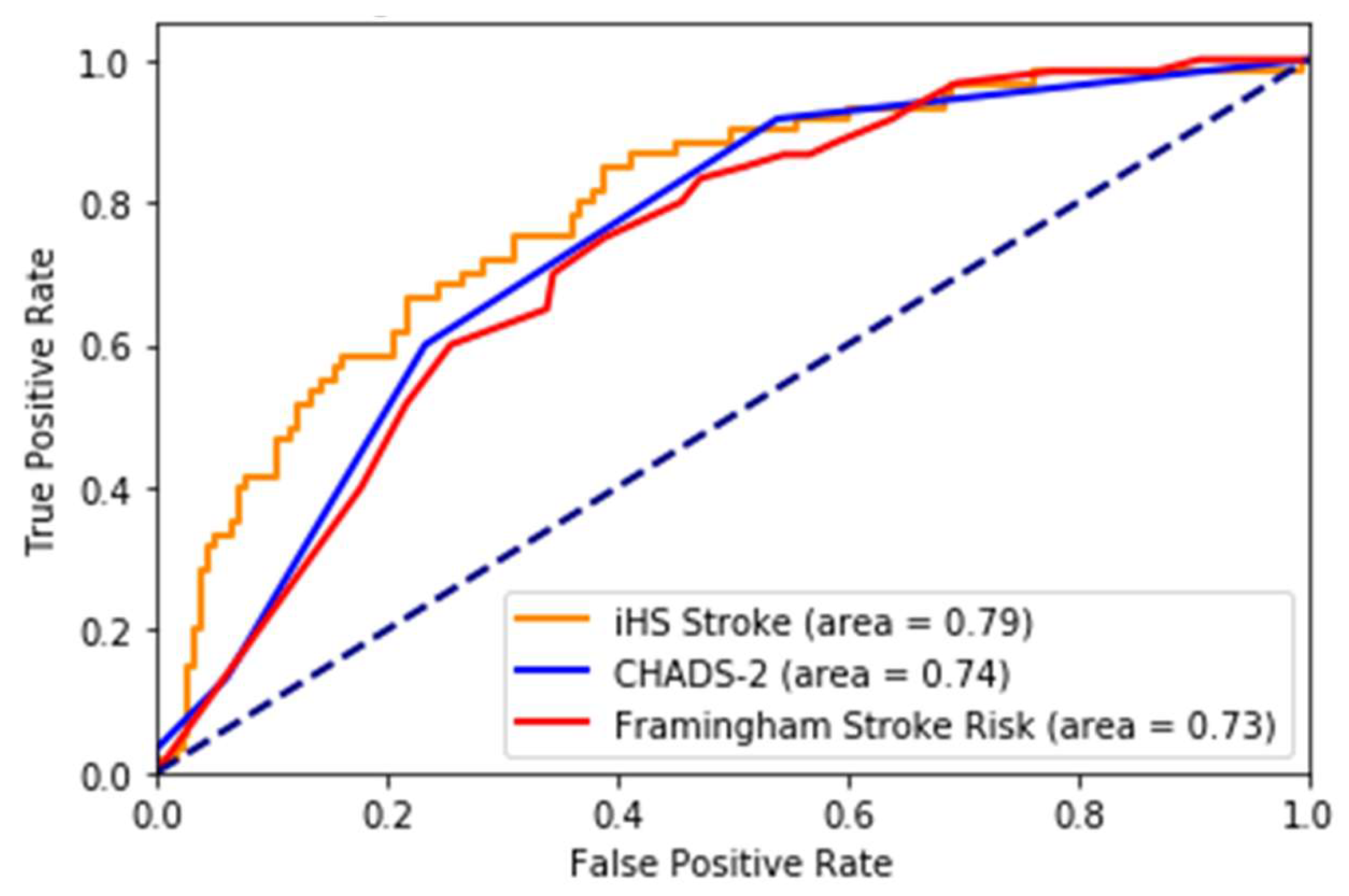
In this paper, we describe a novel and accurate artificial intelligence and retinal imaging-based stroke prediction model for screening an individual at risk of incident stroke, which offers significantly improved accuracy over traditional risk-prediction algorithms. The data from the study, which is an ongoing prospective observational study, were analyzed retrospectively to build the model. We achieved very good performance on 5-year and 10-year incident stroke prediction. While we acknowledge that the CHADS2 and Framingham scores were developed with different purposes and populations, they are the prevailing methods of stroke risk estimation and screening. We have shown that our method performs better than the Framingham score and CHADS2 score for stroke prediction, the best models among the reported stroke prediction scores.
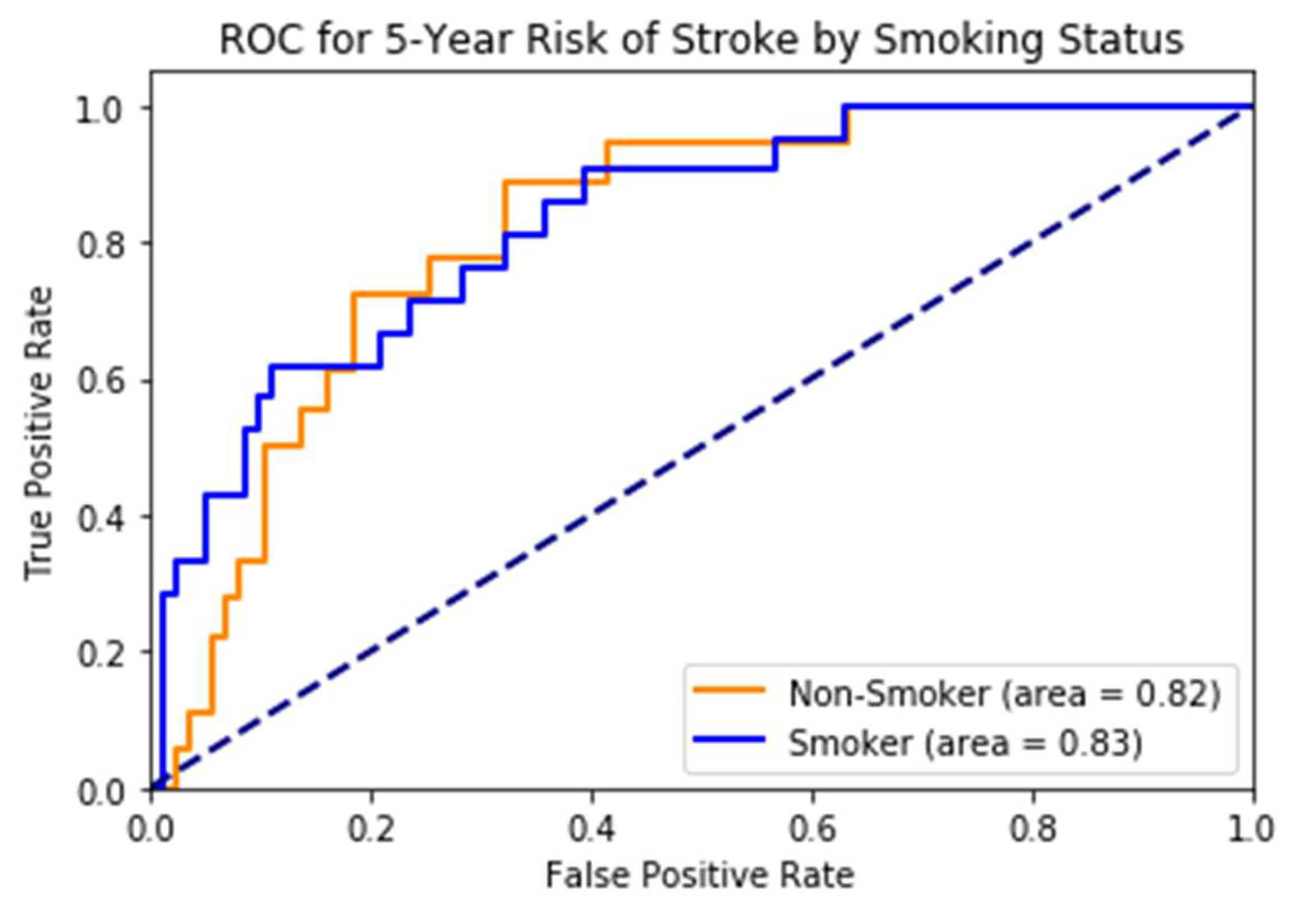
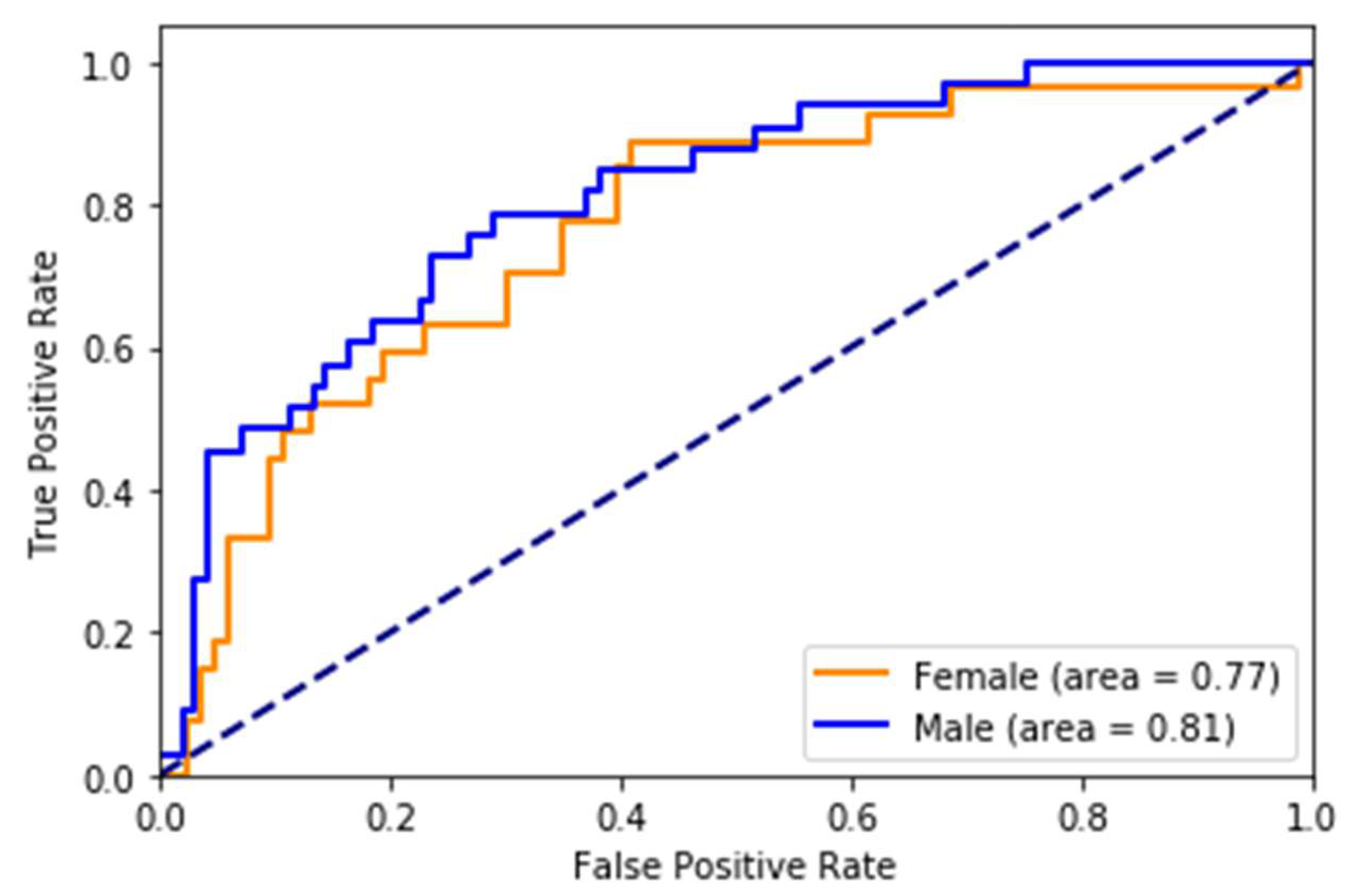
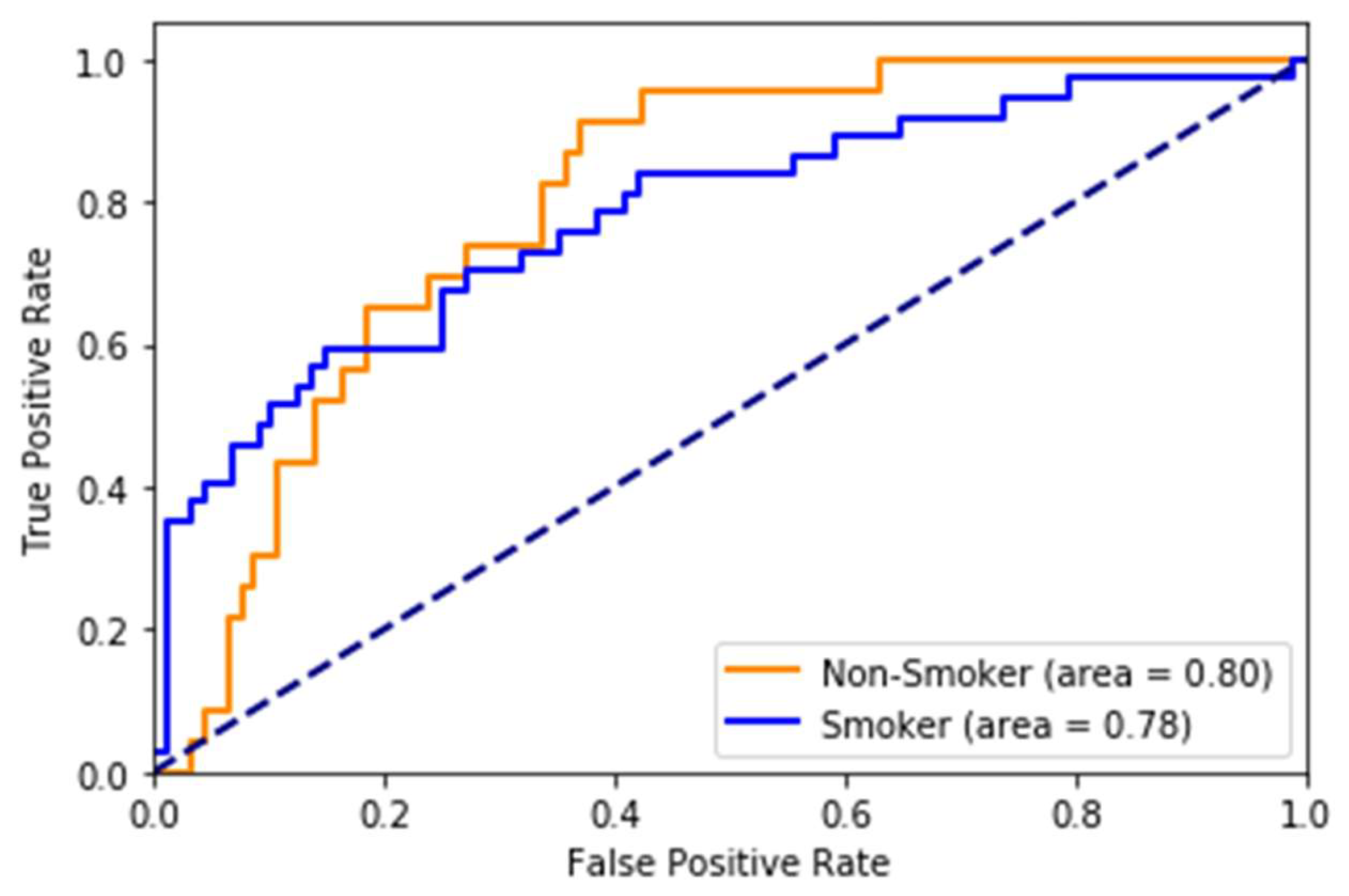
While most stroke scores are based on the white population, we used multi-ethnic population-based data, which is one of the strengths of the study. The risk scores developed on (mostly) white cohorts will probably have limited generalizability to other races/ethnicities. Therefore, it is an excellent opportunity for us to take advantage of this multi-ethnic dataset. However, there is still a lot of room for improvement in this area. The race-wise results show the model still lacks calibration to all races/ethnicities. The risk prediction system, when used to predict stroke as a binary class (yes/no), may capture a high number of false positives or a high number of false negatives depending on the threshold value. We also note while the system with eye imaging features/measures performs better than the one without, these measures are not easily obtainable. They require expert photography and ophthalmologists to grade the retinal photos. This challenge can be an area for more research into the deep learning-based automated grading of retinal pathologies.
This study has several limitations. One of the main challenges was the imbalance of stroke and non-stroke subjects, with the relatively smaller number of stroke subjects posing a significant challenge for machine learning techniques. This limitation prompted us to use a combination of the Cox proportional hazards model and traditional machine learning classifiers. We took inspiration from Transfer learning, which is a technique popular in image classification problems where knowledge/features learned from large datasets are used in problems with similar but smaller datasets.
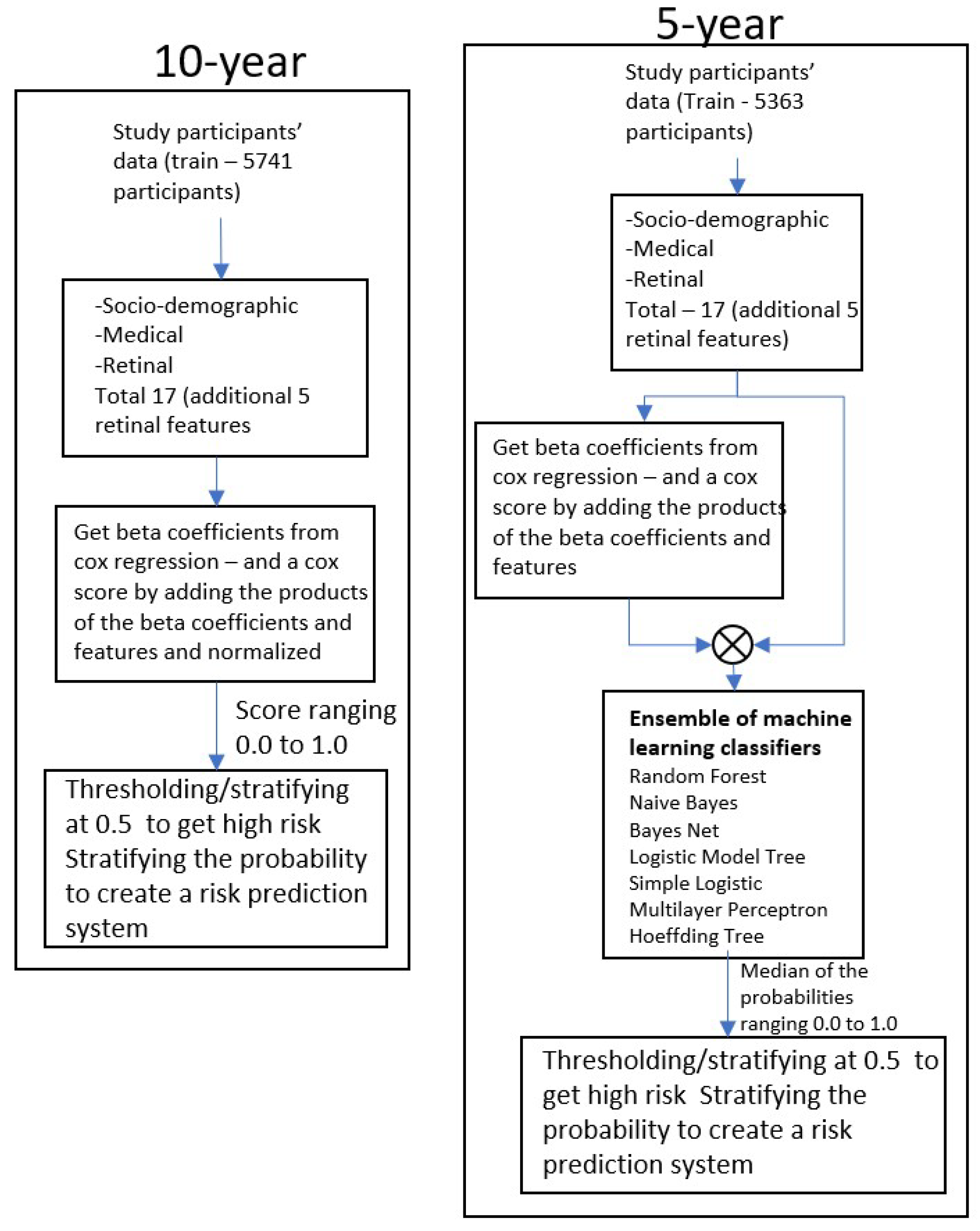
The Cox proportional hazards model was found to work better with unbalanced data than common machine learning classifiers on this data. We first extracted the significant features by applying the Cox method to the entire training data and then used them with machine learning classifiers with smaller balanced datasets. This procedure helped us keep the maximum number of sample types in each class at the beginning of training: all the 3794 subjects in the 5-year model and 4007 subjects in the 10-year model.
Another challenge was the missing features. Many data fields had an incorrect format unclear field values, or sometimes missing field values/data. The elimination of all records that have any missing or incorrect data would have resulted in significant data and information loss. Instead, we first extracted predictive features with all the features using a high threshold for p-value in the Cox proportional hazards model. Considering then only the selected features, we eliminated the records with missing or incorrect data. This allowed for a low data loss of about 15% (from 6814 records to 5741 records).
The validation dataset from UK Biobank is an extensive database covering diverse populations across the UK. The stroke prediction model proposed in this paper consistently performed on this dataset, making it viable for implementation. It also outperformed popular risk prediction scores such as the Framingham stroke risk score and CHADS-2 score for 5-year risk. With eye features, our prediction model showed an AUC of 0.83, compared to Framingham, 0.68, and CHADS2, 0.67, respectively. Because Framingham and CHADS2 do not use retinal features, this makes a good case for including them in stroke prediction models. Although our focus is mainly on 5-year stroke prediction, the results also showed that our model outperformed Framingham and CHADS2 for 10-year incident stroke risk.
Future work will focus on analyzing racial/ethnic differences in model performance, evaluating performance in specific high-risk subgroups, and incorporating additional calibration metrics. We will also explore strategies for periodic model recalibration to ensure consistent accuracy across diverse populations. Addressing these aspects will help improve the model’s generalizability and clinical utility.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}