
Interference Mitigation Using UNet for Integrated Sensing and Communicating Vehicle Networks via Delay–Doppler Sounding Reference Signal Approach
Abstract
1. Introduction
- Proposing a novel solution for ISAC technology in V2X networks: We introduce an innovative approach that leverages the 2D offset in the DD domain within existing 4G/5G systems. This method maximizes the utilization of SRS for both radar sensing and communications, addressing the increasing demand for high-precision and high-refresh-rate environmental perception in autonomous driving and other V2X applications.
- Addressing multi-user interference in ISAC systems: We recognize the challenge of the IUI when multiple users share limited TF resources in the SRS channel. To mitigate the IUI, we propose a deep learning (DL)-based scheme using a UNet architecture, which effectively reduces interference and enhances the accuracy of sensing in multi-user scenarios.
- Demonstrating the feasibility and effectiveness of the proposed method: Through extensive simulations, we validate the proposed method’s capability to deliver robust and reliable multi-user sensing and communications in realistic V2X environments. The results show significant improvements in the system performance, with reduced interference and enhanced sensing accuracy, making the proposed solution viable for next-generation autonomous vehicle networks.
2. System and Signal
3. Framework and Scheme
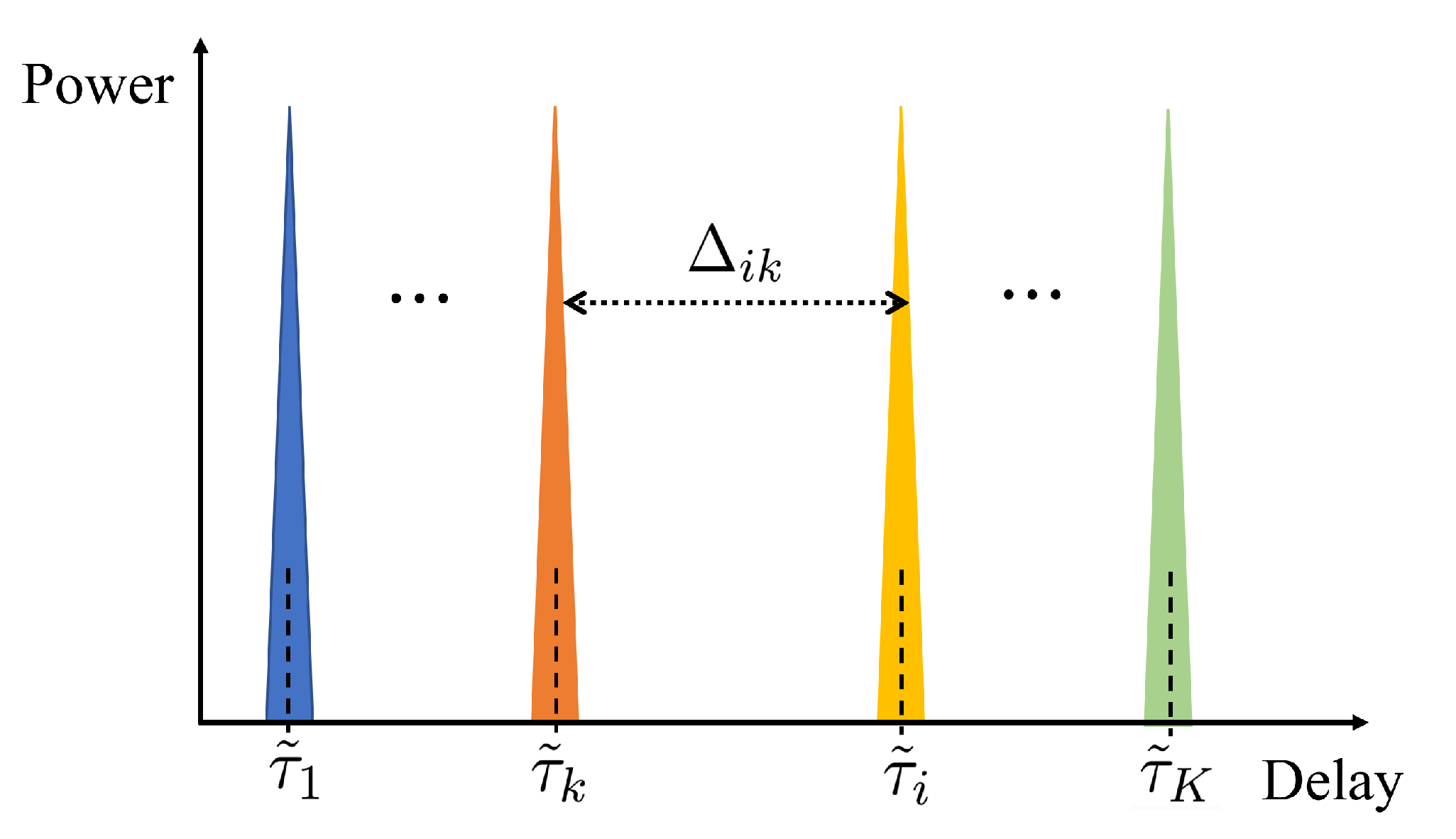
3.1. Multiple-Access ISAC Framework Based on DD-SRS
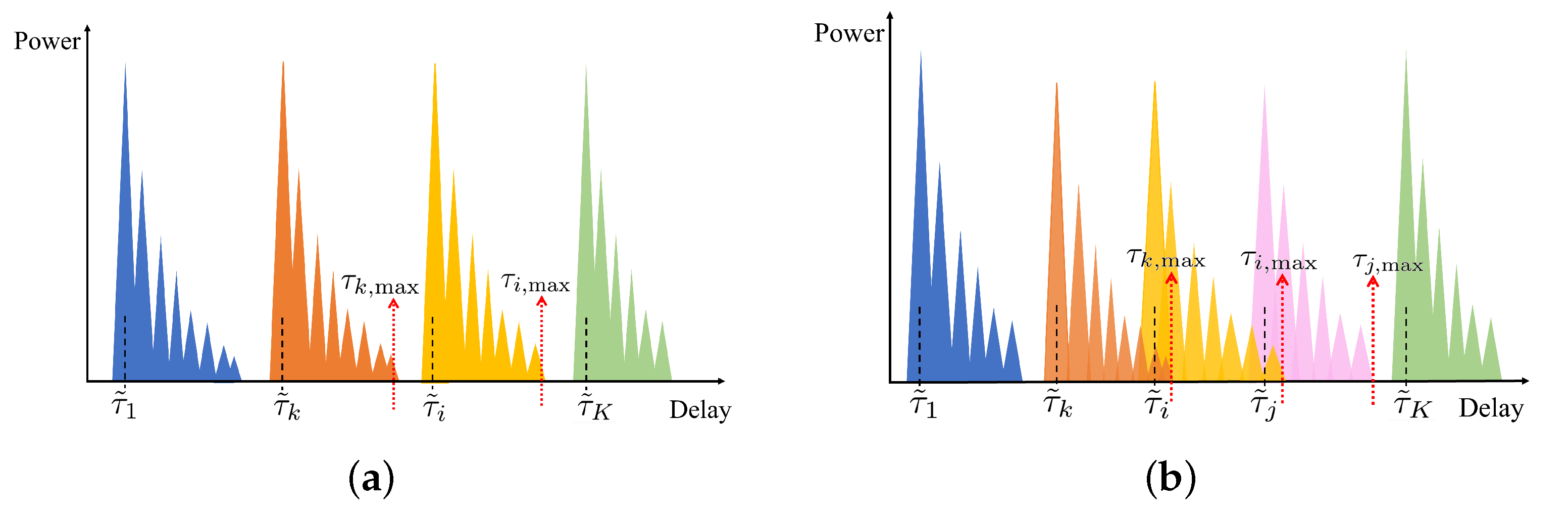
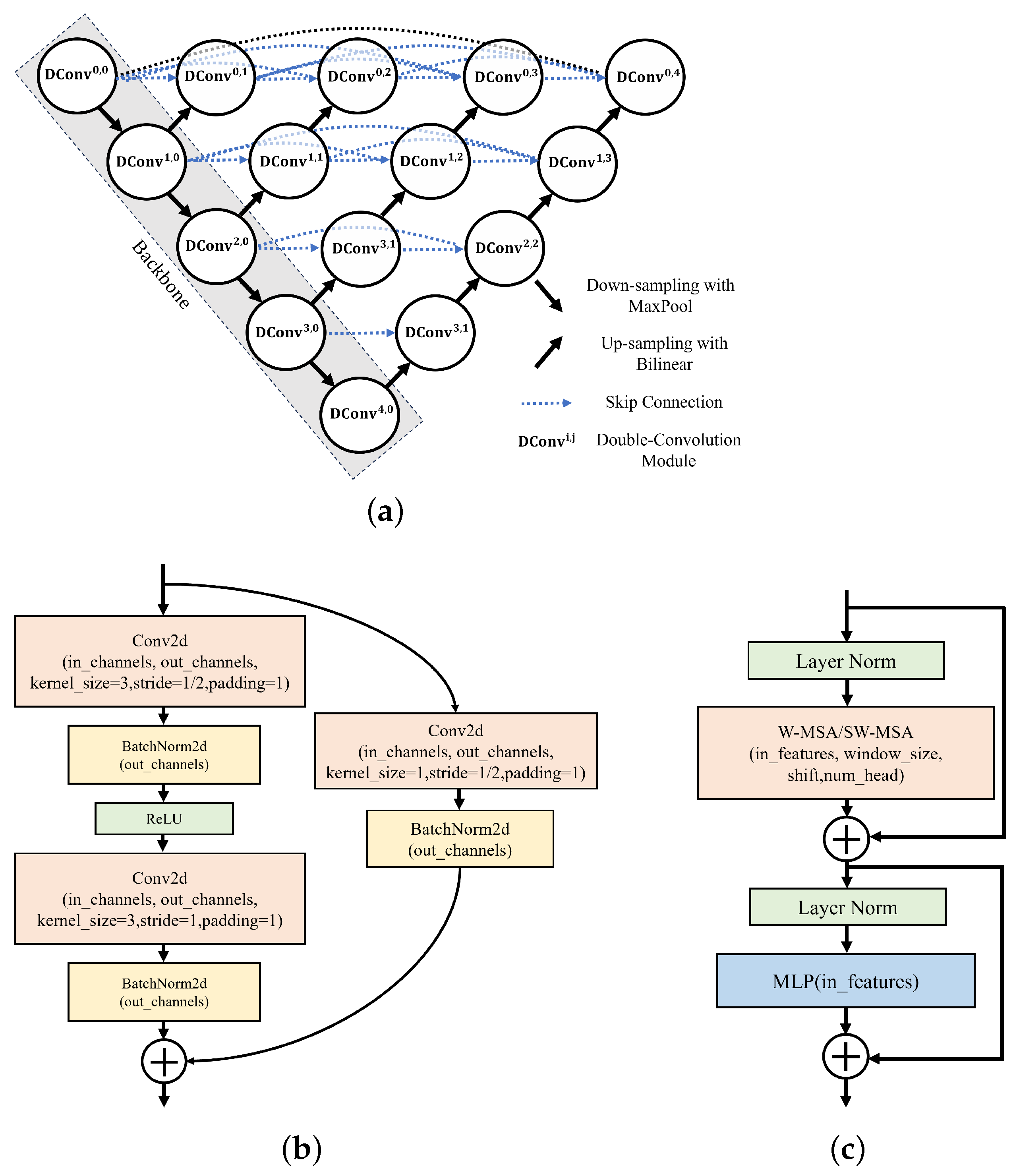
3.2. Interference Mitigation Scheme Based on Image-Pixel-Segmentation-Based Neural Network
4. Simulation and Results
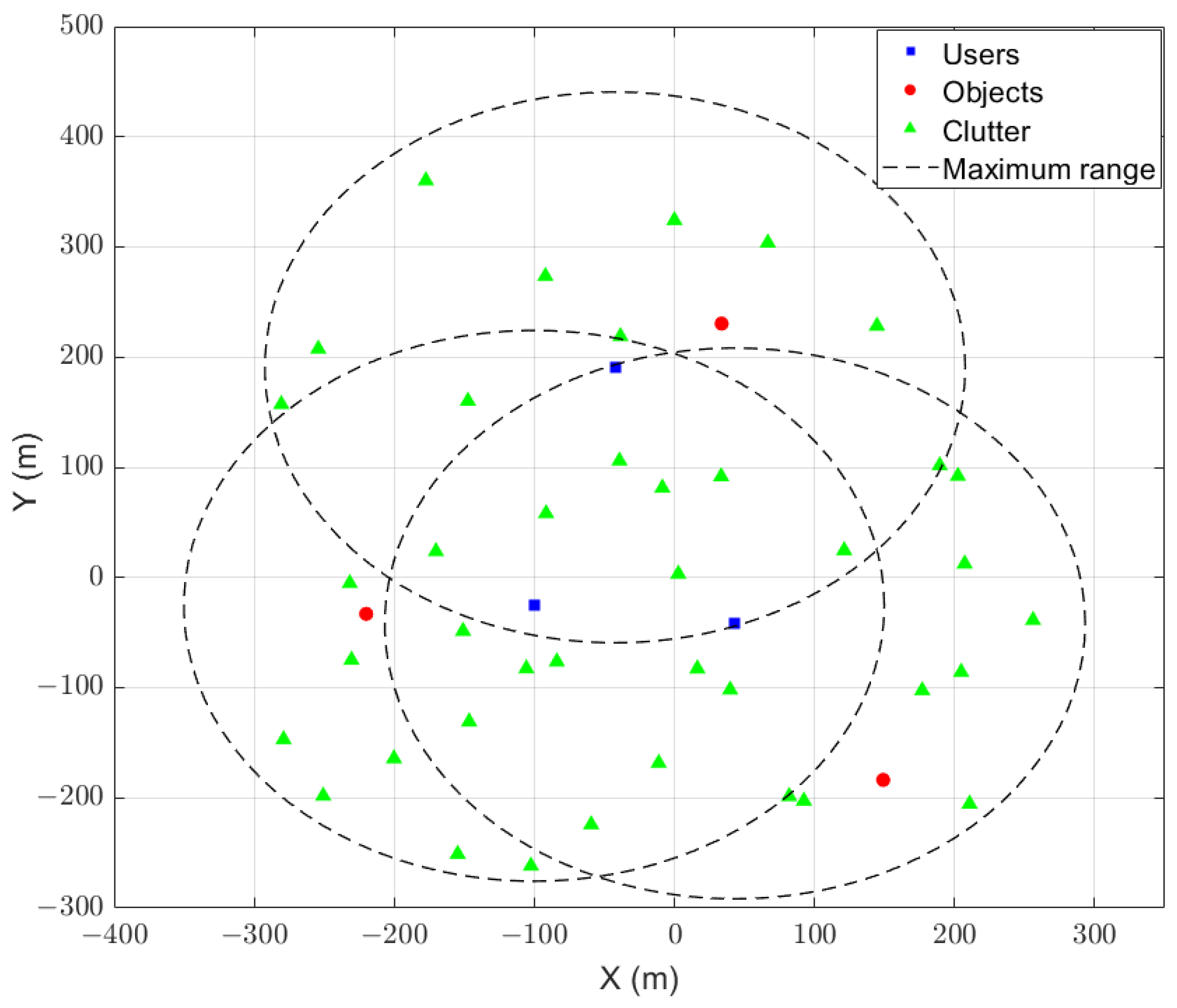
4.1. Configuration
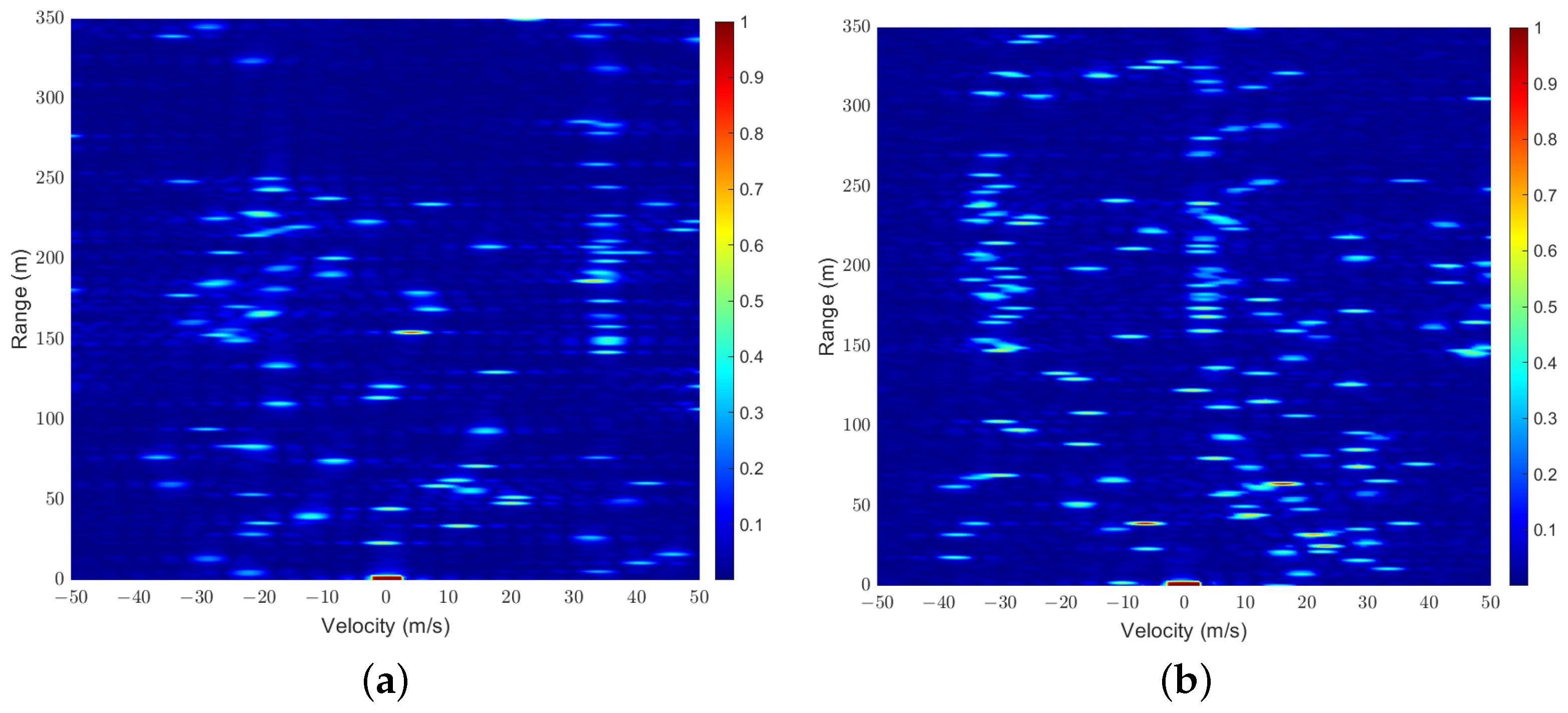
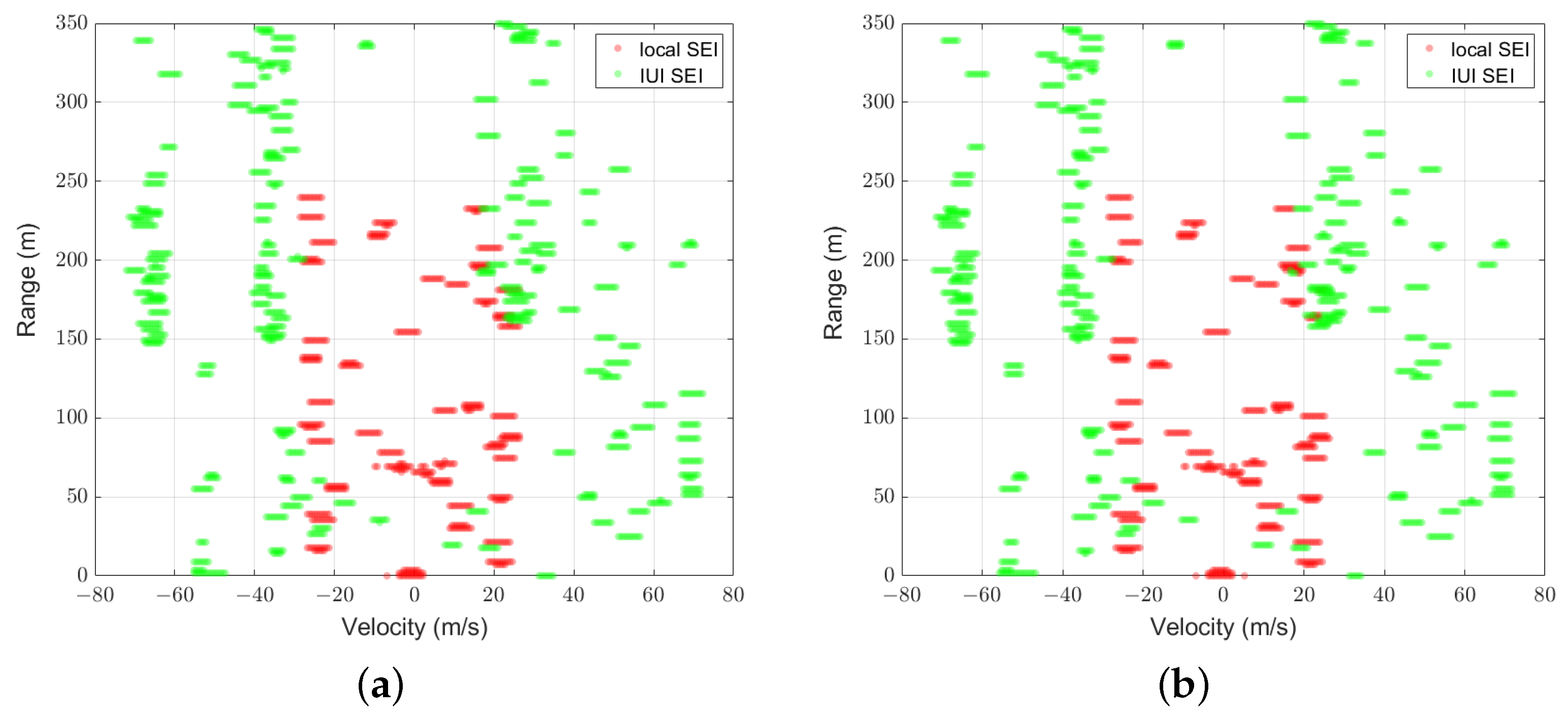
4.2. mIoU Performance of Proposed Framework and Scheme
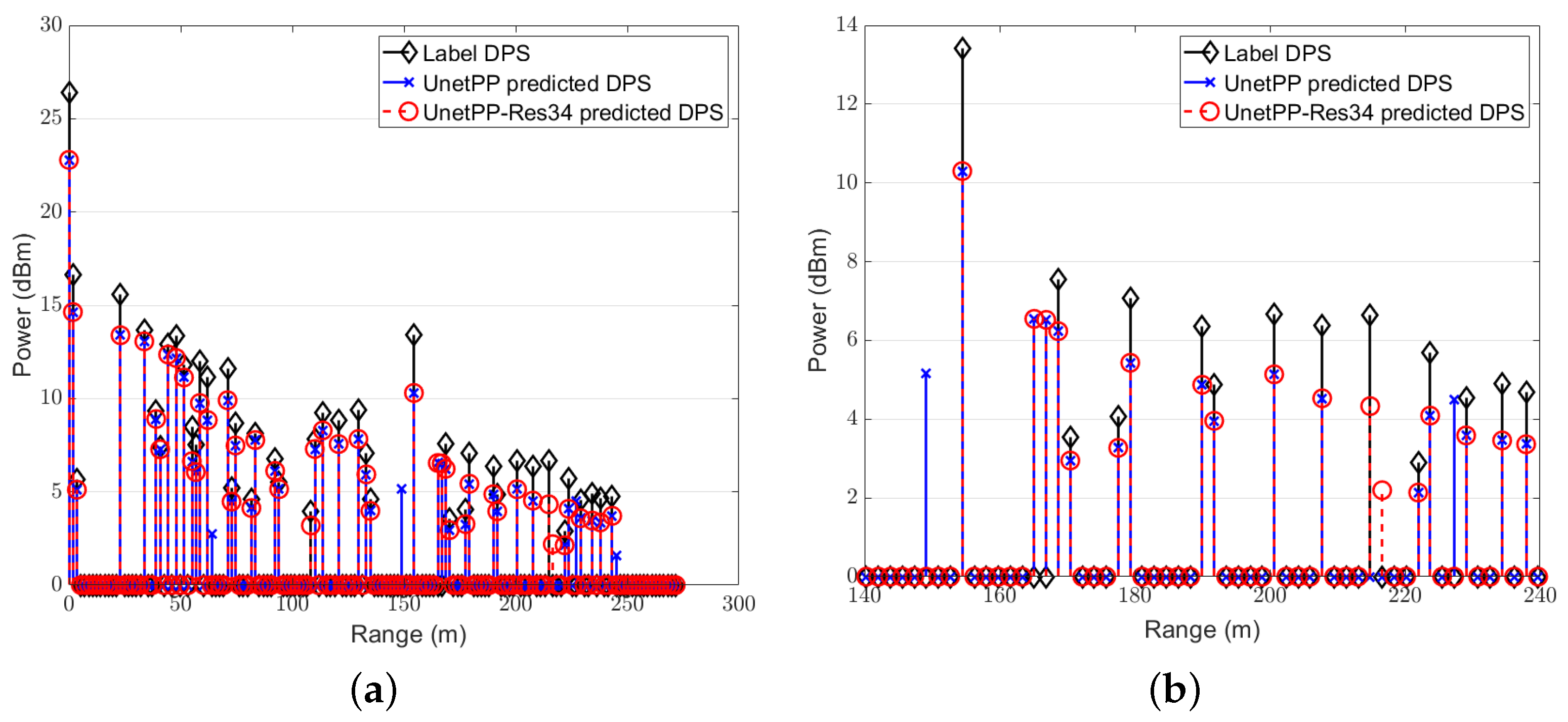
4.3. NMSE Performance of Proposed Framework and Scheme
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Analysis of the Condition of Orthogonality for the DD-SRS in (11)
Appendix A.1. Orthogonality with FT Operations
Appendix A.2. Orthogonality with DFT Operations

References
- SAAD, W.; Bennis, M.; Chen, M.Z. A Vision of 6G Wireless Systems: Applications, Trends, Technologies, and Open Research Problems. IEEE Netw. 2020, 34, 134–142. [Google Scholar] [CrossRef]
- Han, D.; So, J. Energy-Efficient Resource Allocation Based on Deep Q-Network in V2V Communications. Sensors 2023, 23, 1295. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Duan, D.; Gao, S.J.; Yang, L.Q. Integrated Sensing and Communications (ISAC) for Vehicular Communication Networks (VCN). IEEE Internet Things J. 2022, 9, 23441–23451. [Google Scholar] [CrossRef]
- Noor-A-Rahim, M.; Liu, Z.L.; Lee, H.Y.; Khyam, M.O.; He, J.H.; Pesch, D. 6G for Vehicle-to-Everything (V2X) Communications: Enabling Technologies, Challenges, and Opportunities. Proc. IEEE 2022, 110, 712–734. [Google Scholar] [CrossRef]
- Matricardi, E.; Favarelli, E.; Pucci, L.; Xu, W.; Paolini, E.; Giorgetti, A. Toward Intelligent Roads: Uniting Sensing and Communication in Mobile Networks. Sensors 2025, 25, 778. [Google Scholar] [CrossRef]
- Zhao, Q.M.; Li, S.Q.; Tang, A.M.; Wang, X.D. Energy-Efficient Reference Signal Optimization for 5G V2X Joint Communication and Sensing. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 1040–1045. [Google Scholar]
- Wei, Z.Q.; Wang, Y.; Ma, L.; Yang, S.S.; Feng, Z.Y.; Pan, C.K. 5G PRS-Based Sensing: A Sensing Reference Signal Approach for Joint Sensing and Communication System. IEEE Trans. Veh. Technol. 2023, 72, 3250–3263. [Google Scholar] [CrossRef]
- Golzadeh, M.; Tiirola, E.; Talvitie, J.; Anttila, L.; Hooli, K.; Tervo, O. Joint Sensing and UE Positioning in 5G-6G: PRS Range Estimation with Suppressed Ambiguity. In Proceedings of the 2024 IEEE Radar Conference (RadarConf24), Denver, CO, USA, 6–10 May 2024; pp. 1–6. [Google Scholar]
- Bednarz, M.; Zielinski, T.P. Remote Radio Frequency Sensing Based on 5G New Radio Positioning Reference Signals. Sensors 2025, 25, 337. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.Q.; Guo, J.; Wang, X.Y.; Yuan, W.J.; Fei, Z.S.; Pan, C.K. Pilot Design and Optimization for OTFS Modulation. IEEE Wirel. Commun. Lett. 2021, 10, 1742–1746. [Google Scholar] [CrossRef]
- Werf, I.V.D.; Heusdens, R.; Hendriks, C.R.; Leus, G. Optimal Pilot Design for OTFS in Linear Time-Varying Channels. arXiv 2024, arXiv:2403.19379. [Google Scholar]
- Miao, Q.; Shen, X.; Xie, C.; Gao, Y.; Chen, L. Integrated Sensing and Communication Target Detection Framework and Waveform Design Method Based on Information Theory. Sensors 2025, 25, 465. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.W.; Wen, C.K.; Jin, S.; Li, Y.G. Dual CNN-Based Channel Estimation for MIMO-OFDM Systems. IEEE Trans. Commun. 2021, 69, 5859–5872. [Google Scholar] [CrossRef]
- Guo, H.Y.; Lau, V.K.N. Robust Deep Learning for Uplink Channel Estimation in Cellular Network Under Inter-Cell Interference. IEEE J. Sel. Areas Commun. 2023, 41, 1873–1887. [Google Scholar] [CrossRef]
- Wang, Y.; Han, S.; Xue, Q.; Wang, X.Y. CNN Based OTFS Channel State Discrimination and Recognition. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–6. [Google Scholar]
- Mattu, S.R.; Chockalingam, A. Learning in Time-Frequency Domain for Fractional Delay-Doppler Channel Estimation in OTFS. IEEE Wirel. Commun. Lett. 2024, 13, 1245–1249. [Google Scholar] [CrossRef]
- Sakhnini, A.; Bourdoux, A.; Pollin, S. Range-Doppler Division Multiple Access for Joint Radar and Communication. In Proceedings of the ICC 2023—IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 3534–3539. [Google Scholar]
- Hsu, H.W.; Lin, Y.C.; Lee, M.C.; Lin, C.H.; Lee, T.S. Deep Learning-Based Range-Doppler Map Reconstruction in Automotive Radar Systems. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25 April–19 May 2021; pp. 1–7. [Google Scholar]
- Jeong, T.; Lee, S. Resource-Efficient Range-Doppler Map Generation Using Deep Learning Network for Automotive Radar Systems. IEEE Access 2023, 11, 55965–55977. [Google Scholar] [CrossRef]
- Xu, Y.; Li, W.; Yang, Y.; Ji, H.; Li, B.; Lang, Y. Multiple Targets Echo Separation on Radar Range–Doppler Maps via Dual Decoupling Perception. IEEE Sensors J. 2022, 22, 20797–20804. [Google Scholar] [CrossRef]
- Xu, Y.; Li, W.; Yang, Y.; Ji, H.; Lang, Y. Superimposed Mask-Guided Contrastive Regularization for Multiple Targets Echo Separation on Range–Doppler Maps. IEEE Trans. Instrum. Meas. 2023, 72, 5028712. [Google Scholar] [CrossRef]
- Keskin, M.F.; Wymeersch, H.; Koivunen, V. Monostatic Sensing with OFDM Under Phase Noise: From Mitigation to Exploitation. IEEE Trans. Signal Process. 2023, 71, 1363–1378. [Google Scholar] [CrossRef]
- Tigrek, R.F.; De Heij, W.J.A.; Van Genderen, P. OFDM Signals as the Radar Waveform to Solve Doppler Ambiguity. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 130–143. [Google Scholar] [CrossRef]
- Keskin, M.F.; Koivunen, V.; Wymeersch, H. Limited Feedforward Waveform Design for OFDM Dual-Functional Radar-Communications. IEEE Trans. Signal Process. 2021, 69, 2955–2970. [Google Scholar] [CrossRef]
- 3GPP. TS 36.211: Evolved Universal Terrestrial Radio Access (E-UTRA); Physical channels and modulation. In Technical Specification; 3rd Generation Partnership Project: Valbonne, France, 2020; Volume V15.8.0. [Google Scholar]
- Sesia, S.; Toufik, I.; Baker, M. LTE—The UMTS Long Term Evolution: From Theory to Practice, 2nd ed.; John Wiley & Sons: Chichester, UK, 2011; pp. 145–146. [Google Scholar]
- 3GPP. TS 38.211: NR; Physical channels and modulation. In Technical Specification; 3rd Generation Partnership Project: Valbonne, France, 2020; Volume V16.4.0. [Google Scholar]
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA 2018, ML-CDS 2018), Granada, Spain, 20 September 2018; Volume 11045, pp. 3–11. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Su, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Wei, Y.X.; Zhang, Z.; Lin, S.; Guo, B.N. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV 2016), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalized Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA 2017), Quebec City, QC, Canada, 14 September 2017; pp. 240–248. [Google Scholar]
- Molisch, A. Wireless Communications, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2010; pp. 104–106. [Google Scholar]
- Richards, M.A. Fundamentals of Radar Signal Processing, 2nd ed.; McGraw-Hill Education: New York, NY, USA, 2014; pp. 238–239. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of subcarriers | |
| Number of symbols | |
| Carrier frequency | GHz |
| Subcarrier spacing | kHz |
| Total bandwidth | MHz |
| OFDM effective symbol duration | µs |
| OFDM CP duration | µs |
| OFDM symbol duration | µs |
| Size of the RD Map | |
| Number of users | |
| m | |
| m/s |
| Models | SNR = 5 dB | SNR = 15 dB | |
|---|---|---|---|
| UNet-Res34 | |||
| UNetPP | |||
| SwinUNetPP | |||
| UNetPP-Res34 | |||
| Models | K | SNR = 5 dB | SNR = 10 dB | SNR = 20 dB |
|---|---|---|---|---|
| UNetPP-Res34 | 25 | −13.278 | −16.2 | −17.954 |
| 36 | −8.18047 | −11.2551 | −13.4811 | |
| UNetPP | 25 | −9.73 | −13.55 | −15.207 |
| 36 | −3.6609 | −7.7904 | −9.7965 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Zhu, Y. Interference Mitigation Using UNet for Integrated Sensing and Communicating Vehicle Networks via Delay–Doppler Sounding Reference Signal Approach. Sensors 2025, 25, 1902. https://doi.org/10.3390/s25061902
Tang Y, Zhu Y. Interference Mitigation Using UNet for Integrated Sensing and Communicating Vehicle Networks via Delay–Doppler Sounding Reference Signal Approach. Sensors. 2025; 25(6):1902. https://doi.org/10.3390/s25061902
Chicago/Turabian StyleTang, Yuanqi, and Yu Zhu. 2025. "Interference Mitigation Using UNet for Integrated Sensing and Communicating Vehicle Networks via Delay–Doppler Sounding Reference Signal Approach" Sensors 25, no. 6: 1902. https://doi.org/10.3390/s25061902
APA StyleTang, Y., & Zhu, Y. (2025). Interference Mitigation Using UNet for Integrated Sensing and Communicating Vehicle Networks via Delay–Doppler Sounding Reference Signal Approach. Sensors, 25(6), 1902. https://doi.org/10.3390/s25061902