
PCAFA-Net: A Physically Guided Network for Underwater Image Enhancement with Frequency–Spatial Attention


Abstract
1. Introduction
- (1)
- We propose a novel UIE architecture, PCAFA-Net, which addresses the limitations of traditional UIE methods that are constrained to a single environment and deep learning methods that lack sufficient data, enabling effective restoration of degraded underwater images. Extensive experiments on three datasets demonstrate that PCAFA-Net outperforms other state-of-the-art methods.
- (2)
- Considering the difficulties in physical modeling of traditional UIE methods, we propose the AGSM module, which combines deep learning techniques to automatically learn underwater degradation parameters. We also introduce the ACRAM module that adaptively adjusts histogram distribution, further enhancing image contrast.
- (3)
- Addressing the uneven enhancement issue common in conventional UIE methods, we propose the FSSAM module, which incorporates frequency domain techniques to thoroughly extract degradation factors of underwater images in the frequency domain.
2. Related Work
2.1. Traditional UIE Methods
2.1.1. Physical-Model-Based Methods
2.1.2. Non-Physical-Model-Based Methods
2.2. Learning-Based UIE Methods
3. Proposed Method
3.1. Overall Pipeline
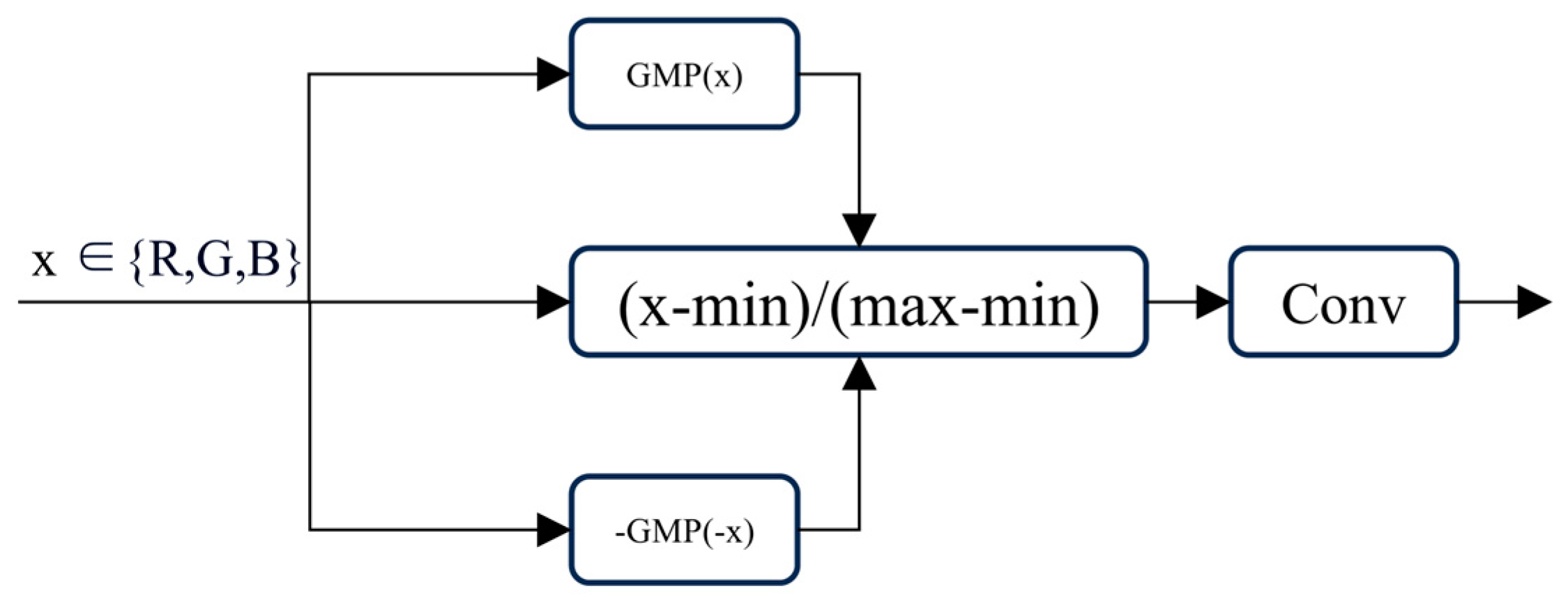
3.2. Adaptive Gradient Simulation Module (AGSM)
3.3. Adaptive Color Range Adjustment Module (ACRAM)
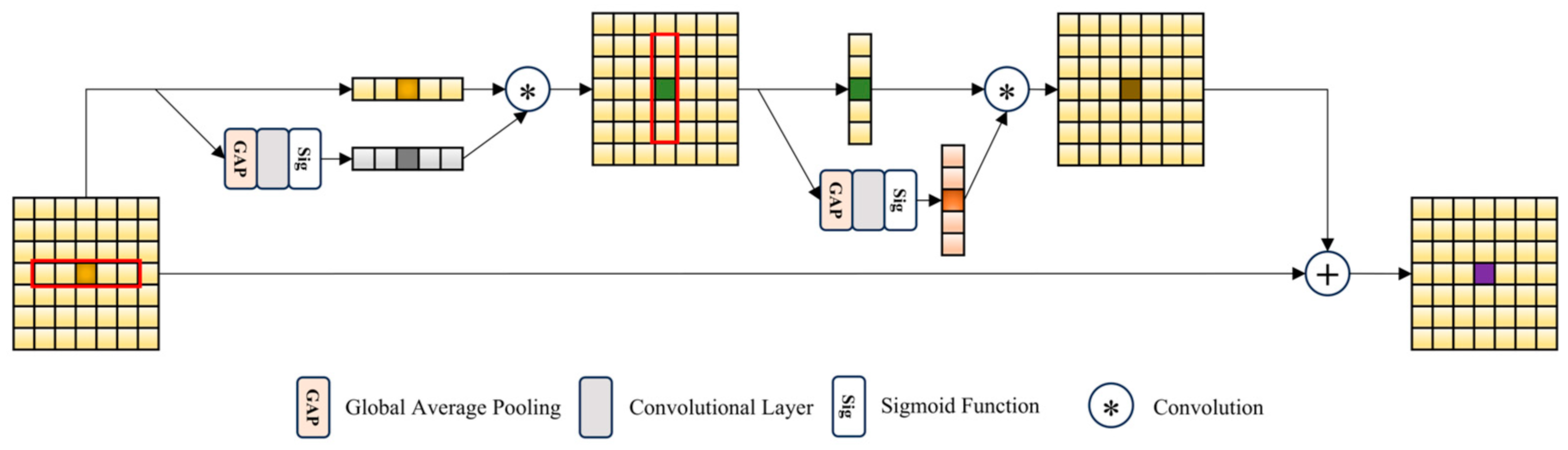
3.4. Frequency–Spatial Strip Attention Module (FSSAM)
3.5. Loss Function
4. Experimental Discussion
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Training Details
4.1.3. Evaluation Metric and Benchmark Methods
4.2. Quantitative Evaluations
4.3. Qualitative Comparsions
4.4. Ablation Analysis
5. Application
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, W.; Liu, Q.; Feng, Y.; Cai, L.; Zhuang, P. Underwater image enhancement via principal component fusion of foreground and background. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10930–10943. [Google Scholar] [CrossRef]
- Cong, X.; Zhao, Y.; Gui, J.; Hou, J.; Tao, D. A Comprehensive Survey on Underwater Image Enhancement Based on Deep Learning. arXiv 2024, arXiv:2405.19684. [Google Scholar]
- Ouyang, W.; Liu, J.; Wei, Y. An Underwater Image Enhancement Method Based on Balanced Adaption Compensation. IEEE Signal Process. Lett. 2024, 31, 1034–1038. [Google Scholar] [CrossRef]
- Xiao, Z.; Han, Y.; Rahardja, S.; Ma, Y. USLN: A statistically guided lightweight network for underwater image enhancement via dual-statistic white balance and multi-color space stretch. arXiv 2022, arXiv:2209.02221. [Google Scholar]
- Lei, Y.; Yu, J.; Dong, Y.; Gong, C.; Zhou, Z.; Pun, C.-M. UIE-UnFold: Deep Unfolding Network with Color Priors and Vision Transformer for Underwater Image Enhancement. In Proceedings of the 2024 IEEE 11th International Conference on Data Science and Advanced Analytics (DSAA), San Diego, CA, USA, 6–10 October 2024; pp. 1–10. [Google Scholar]
- Han, D.; Qi, H.; Wang, S.X.; Hou, D.; Wang, C. Adaptive stepsize forward–backward pursuit and acoustic emission-based health state assessment of high-speed train bearings. Struct. Health Monit. 2024, 14759217241271036. [Google Scholar] [CrossRef]
- Cui, Y.; Knoll, A. Dual-domain strip attention for image restoration. Neural Netw. 2024, 171, 429–439. [Google Scholar] [CrossRef]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef]
- Liu, R.; Jiang, Z.; Yang, S.; Fan, X. Twin adversarial contrastive learning for underwater image enhancement and beyond. IEEE Trans. Image Process. 2022, 31, 4922–4936. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef]
- Liang, Z.; Ding, X.; Wang, Y.; Yan, X.; Fu, X. GUDCP: Generalization of underwater dark channel prior for underwater image restoration. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4879–4884. [Google Scholar] [CrossRef]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Ghani, A.S.A.; Isa, N.A.M. Enhancement of low quality underwater image through integrated global and local contrast correction. Appl. Soft Comput. 2015, 37, 332–344. [Google Scholar] [CrossRef]
- Ghani, A.S.A.; Isa, N.A.M. Automatic system for improving underwater image contrast and color through recursive adaptive histogram modification. Comput. Electron. Agric. 2017, 141, 181–195. [Google Scholar] [CrossRef]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Garg, D.; Garg, N.K.; Kumar, M. Underwater image enhancement using blending of CLAHE and percentile methodologies. Multimed. Tools Appl. 2018, 77, 26545–26561. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Cao, Y.; Wang, Z. A deep CNN method for underwater image enhancement. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1382–1386. [Google Scholar]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Li, K.; Wu, L.; Qi, Q.; Liu, W.; Gao, X.; Zhou, L.; Song, D. Beyond single reference for training: Underwater image enhancement via comparative learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2561–2576. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ertan, Z.; Korkut, B.; Gördük, G.; Kulavuz, B.; Bakırman, T.; Bayram, B. Enhancement of underwater images with artificial intelligence. The International Archives of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2024, 48, 149–156. [Google Scholar]
- Zhou, J.; Li, B.; Zhang, D.; Yuan, J.; Zhang, W.; Cai, Z.; Shi, J. UGIF-Net: An efficient fully guided information flow network for underwater image enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4206117. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wang, W. A fusion adversarial underwater image enhancement network with a public test dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- Peng, W.; Zhou, C.; Hu, R.; Cao, J.; Liu, Y. Raune-Net: A residual and attention-driven underwater image enhancement method. In Proceedings of the International Forum on Digital TV and Wireless Multimedia Communications; Springer Nature: Singapore, 2023; pp. 15–27. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.-L.; Huang, Q.; Kwong, S. Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. LiteEnhanceNet: A lightweight network for real-time single underwater image enhancement. Expert Syst. Appl. 2024, 240, 122546. [Google Scholar] [CrossRef]
- Zhang, B.; Fang, J.; Li, Y.; Wang, Y.; Zhou, Q.; Wang, X. GFRENet: An Efficient Network for Underwater Image Enhancement with Gated Linear Units and Fast Fourier Convolution. J. Mar. Sci. Eng. 2024, 12, 1175. [Google Scholar] [CrossRef]
- Yeh, C.H.; Lai, Y.W.; Lin, Y.Y.; Chen, M.-J.; Wang, C.-C. Underwater image enhancement based on light field-guided rendering network. J. Mar. Sci. Eng. 2024, 12, 1217. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | LSUI | UIEB | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| FUnIEGAN | 23.054 | 0.822 | 19.013 | 0.793 |
| U-Trans | 25.151 | 0.838 | 20.747 | 0.830 |
| WaterNet | 24.748 | 0.861 | 21.153 | 0.847 |
| UGAN | 24.991 | 0.850 | 21.442 | 0.811 |
| PUGAN | 23.895 | 0.849 | 21.670 | 0.818 |
| LiteEnhance | 22.502 | 0.816 | 22.133 | 0.883 |
| Proposed | 27.744 | 0.887 | 22.801 | 0.890 |
| Method | C60 | U45 | ||
|---|---|---|---|---|
| UIQM | UCIQE | UIQM | UCIQE | |
| FUnIEGAN | 3.067 | 0.586 | 3.208 | 0.607 |
| U-Trans | 2.861 | 0.576 | 3.175 | 0.571 |
| WaterNet | 2.763 | 0.570 | 2.899 | 0.577 |
| UGAN | 3.175 | 0.595 | 3.167 | 0.609 |
| PUGAN | 2.899 | 0.598 | 3.189 | 0.606 |
| LiteEnhance | 2.956 | 0.596 | 3.093 | 0.579 |
| Proposed | 3.008 | 0.603 | 3.269 | 0.616 |
| Method | Parameters | FLOPs | Time |
|---|---|---|---|
| FUnIEGAN | 7.01 M | 10.23 G | 0.02 s |
| U-Trans | 65.6 M | 66.2 G | 0.04 s |
| WaterNet | 24.81 M | 193.70 G | 0.55 s |
| UGAN | 57.17 M | 38.97 G | 0.06 s |
| PUGAN | 95.66 M | 72.05 G | 0.23 s |
| LiteEnhance | 0.05 M | 2.32 G | 0.02 s |
| Proposed | 36.83 M | 96.45 G | 0.08 s |
| Setting | PSNR | SSIM |
|---|---|---|
| (w/o) AGSM | 24.075 | 0.856 |
| (w/o) ACRAM | 25.329 | 0.872 |
| (w/o) FSSAM | 24.670 | 0.862 |
| Complete proposed method | 27.744 | 0.887 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, K.; Zhao, L.; Xue, X.; Liu, J.; Li, H.; Liu, H. PCAFA-Net: A Physically Guided Network for Underwater Image Enhancement with Frequency–Spatial Attention. Sensors 2025, 25, 1861. https://doi.org/10.3390/s25061861
Cheng K, Zhao L, Xue X, Liu J, Li H, Liu H. PCAFA-Net: A Physically Guided Network for Underwater Image Enhancement with Frequency–Spatial Attention. Sensors. 2025; 25(6):1861. https://doi.org/10.3390/s25061861
Chicago/Turabian StyleCheng, Kai, Lei Zhao, Xiaojun Xue, Jieyin Liu, Heng Li, and Hui Liu. 2025. "PCAFA-Net: A Physically Guided Network for Underwater Image Enhancement with Frequency–Spatial Attention" Sensors 25, no. 6: 1861. https://doi.org/10.3390/s25061861
APA StyleCheng, K., Zhao, L., Xue, X., Liu, J., Li, H., & Liu, H. (2025). PCAFA-Net: A Physically Guided Network for Underwater Image Enhancement with Frequency–Spatial Attention. Sensors, 25(6), 1861. https://doi.org/10.3390/s25061861