1. Introduction
Anomaly detection (AD) is a data mining task that aims to identify unusual or abnormal data within a large volume of standard data. The applications of AD are numerous and diverse. They include the detection of financial fraud, as evidenced by the work of Rousseeuw et al. [
1], Sanchez et al. [
2], and Badawi et al. [
3], as well as the monitoring of machine health in industrial settings, as demonstrated by Qiao et al. [
4], de et al. [
5], and Yang et al. [
6], and the detection of seizures in medical diagnostics [
7,
8,
9]. A significant portion of these real-world systems are online in nature, with multiple sensors being used to monitor them. Each sensor generates a one-dimensional data sequence, which can then be combined and analysed to assess the overall health status of the equipment. This process is known as multivariate time series anomaly detection (MTAD).
Statistical methods for AD include the exponentially weighted moving average (EWMA), isolation forest [
10], auto-encoders [
11], and other methods [
12,
13,
14,
15]. However, when dealing with the vast amounts of MTS generated in complex environments,
these traditional methods often prove inadequate in terms of efficiency and accuracy due to interference from noisy data.Another category of AD that has gained considerable popularity employs recurrent neural networks (RNN) and variational auto-encoders (VAE) [
16] to learn temporal dependencies and the distribution of standard data sequences. Due to the unique structure of RNN, this type of network can capture short-term correlation of time series data, so it has been widely studied. The VAE-LSTM hybrid model proposed in [
17] combines a VAE to extract local features and an LSTM to capture longer temporal correlations, which allows it to detect anomalies over multiple time scales. Another RNN-based method is the LSTM-based VAE-GAN [
18], which combines LSTMs with a VAE and a generative adversarial network (GAN) framework to jointly train the encoder, generator, and discriminator, effectively reducing mapping errors and improving AD accuracy and speed. Notwithstanding their advantages,
these methods frequently encounter difficulties in capturing long-term dependency. Furthermore, VAEs are prone to difficulties such as KL diverge vanishing and over-regulation.
The advent of transformers [
19] has provided new opportunities in the AD field by enabling the exploration of correlations between distant data points using the attention mechanism. The first research that utilized a transformer to detect anomalies in time series data was Anomaly Transformer [
20]. It utilizes a stacking structure of alternating anomaly-attention blocks and feed-forward layers, with residual connections and layer normalization, to learn deep multi-level features and underlying association data. The MT-RVAE proposed in [
21] addresses the limitations of traditional transformers by incorporating global context in addition to local information for sequential analysis. The transformer model overcomes the inability of RNNs to perform parallel computations, and the number of operations required by the transformer model to compute correlations between two sequences does not increase with distance. Research on AD algorithms based on transformers has become a hot topic in recent years. However, calculating attention scores involves matrix multiplications,
resulting in a quadratic increase in temporal and spatial complexity as the length of the time series grows. This is an inherent limitation for all transformer-based AD methods [
22].
Large language models (LLMs) have garnered significant attention in recent years due to their remarkable ability to understand and generate human-like text. The foundation of LLMs lies in the transformer architecture, which replaces traditional recurrent and convolutional neural networks (CNNs) with self-attention mechanisms. This architecture enables models to capture long-range dependencies and contextual relationships within text, making them highly effective for natural language processing (NLP) tasks. The evolution of LLMs culminated in the development of autoregressive models like GPT. The GPT series, developed by OpenAI, has been instrumental in advancing the capabilities of LLMs. GPT-1 [
23] was a proof-of-concept model demonstrating the effectiveness of pre-training on vast amounts of text data followed by fine-tuning on specific tasks. GPT-2 [
24] extends this by increasing the model size and the amount of training data, leading to significant improvements in text generation quality and fluency.
Since LLM was originally designed for NLP tasks, applying it to MTS-related tasks inevitably requires leveraging knowledge transfer techniques. Upon investigation, research that applies LLM to MTAD tasks is scarce, and many questions can be explored in this direction. Ref. [
25] demonstrates that the LLM-based monitor can effectively detect semantic anomalies in a way that shows agreement with human reasoning. This work extends the application of LLM to recognize semantic anomalies, showing that LLM can be used in the AD domain,
but does not yet apply LLM to detecting anomalies in time series data. Ref. [
26] provides a detailed explanation of methods for applying GPT-2 to downstream tasks such as time-series classification, AD, imputation, long/short-term forecasting, and few/zero-shot forecasting. However,
deploying large models in practical engineering applications is challenging due to their enormous number of parameters. In this paper, the value of LLM in the MTAD field is explored while working on solving the problem of deploying large models on small devices.
One characteristic of anomalous events is their rarity. This leads to a scarcity of labels, or category imbalance. Thus, unsupervised AD methods have emerged as a prominent area of research. The goal of unsupervised tasks is to extract critical information. Consequently, MTAD based on machine learning (ML) or deep learning (DL) typically involves a feature extraction network. In most of the time series feature extraction research, like [
27,
28,
29,
30], the unit for extraction is a time window, and one window corresponds to one feature. If short time windows are adopted, the extracted features are fine-grained. Due to the length of the time series being fixed, the network will have a large number of features to deal with, leading to issues such as insufficient memory, prolonged training time, poor real-time detection, and challenges in small device deployment. Furthermore, fine-grained features may not be condensed enough. They may contain a significant amount of noise not related to anomalies. Conversely, the extracted features are coarse-grained if long time windows are used, which may result in losing key detail information. Therefore,
balancing the coarseness and fineness of feature granularity, finding a way to compensate for the loss of detailed information in coarse-grained features, and modelling cross-window dependencies are all important topics in time series feature extraction research.
Most existing MTAD approaches use the reconstruction error directly as an anomaly score to detect anomalies in the original input space. However, the extracted features that represent the core information are largely overlooked. To the best of our knowledge, there is limited research on detecting anomalies in both input spaces and latent spaces.
To address the challenges mentioned above, a novel DL network called LGFN (LSTM-GPT2 Fusion Network) is proposed. This hybrid model has two main functions: multi-scale feature extraction and data reconstruction. The extracted features and reconstructed data are then utilized to detect anomalies in both the input space and the latent space. The main contributions of this work are as follows:
The proposed LGFN is a novel approach that combines the advantages of bidirectional LSTM (Bi-LSTM) and generative pre-trained transformer (GPT). It is capable of extracting features of MST at different scales and granularities.
Clustering in the latent space is conducted to unravel hidden data patterns. The resulting classification outcomes may be associated with disparate information in various windows and could potentially indicate anomalies in the original space. The outlier score is defined to quantify the extent of deviation.
An enhanced anomaly score was devised based on the reconstruction score and outlier score, which are used to detect anomalies in two distinct spaces.
A series of experiments was conducted to evaluate the effectiveness and efficiency of the proposed model. First, the results of the comparative experiment demonstrated that LGFN exhibits SOTA or comparable performance to the prevailing AD methods on a range of datasets. Second, the assessment of memory usage demonstrated the superior spatial efficiency of the proposed method. Finally, the results of the ablation experiment demonstrated the efficacy of each component of the proposed AD process.
The remainder of this paper is structured as follows:
Section 2 provides a comprehensive account of LGFN and the methodology employed in utilizing this network for AD.
Section 3 presents the results of the experiments, including the settings, the datasets, the results, and a detailed analysis. In conclusion,
Section 4 presents suggestions for future research.
2. LSTM-GPT2 Fusion Network
In this paper, LGFN is proposed to perform MTAD. The methodology encompasses multi-scale feature extraction, data reconstruction, and latent space clustering.
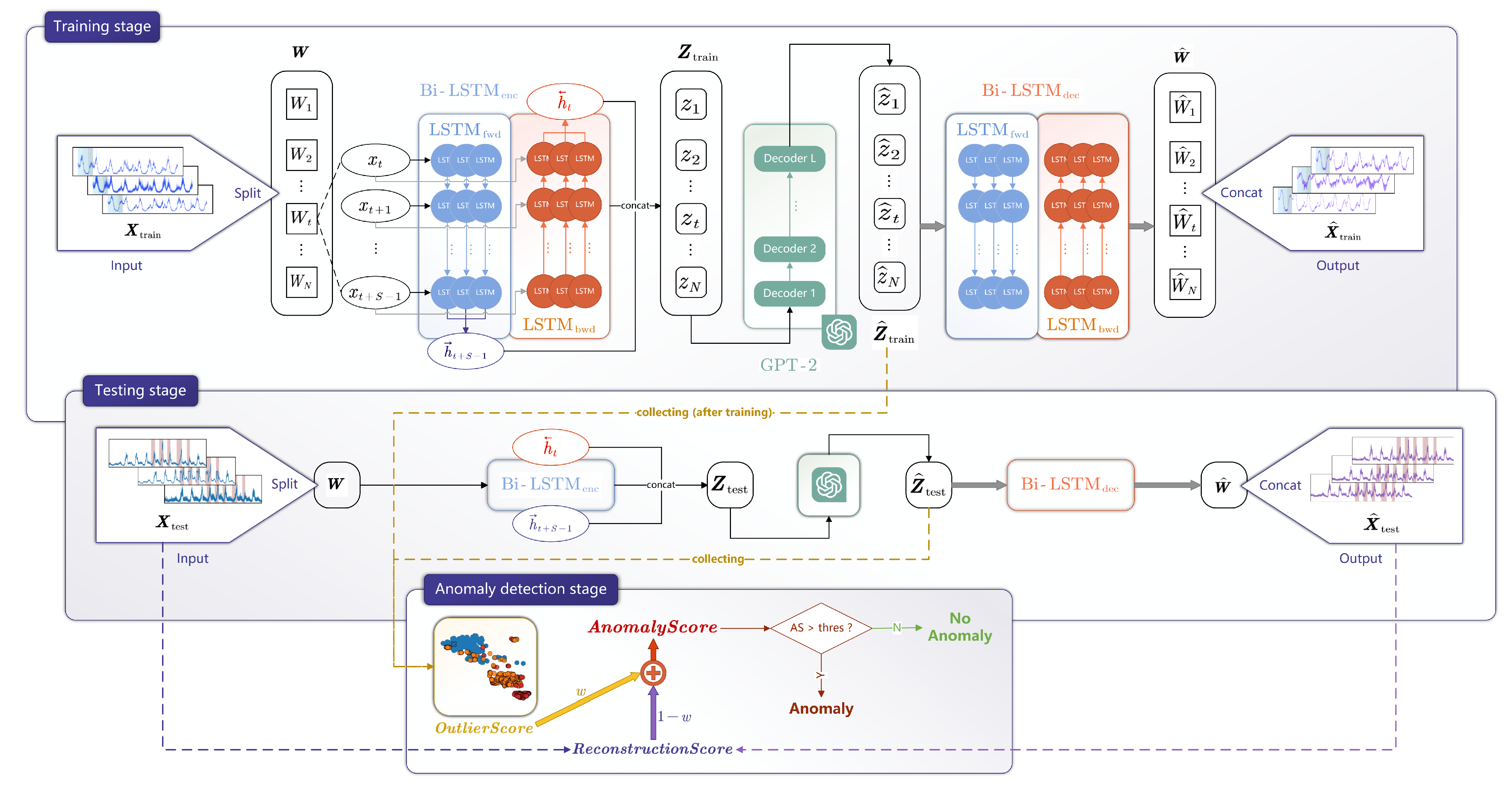
As demonstrated in
Figure 1, LGFN comprises three primary modules: a Bi-LSTM encoder, denoted as
; a decoder with an analogous structure to the encoder, denoted as
; and a GPT-2. Initially,
is employed to extract
window-level features, constituting the first stage of feature extraction. Subsequently, the GPT-2 functions as the secondary stage of feature extraction, responsible for the extraction of
batch-level features. The process involves the processing of a batch of features with consecutive windows, with the aim of adding long-term dependencies to them. Ultimately,
is employed to reconstruct the original data.
LGFN is initially trained on standard data to identify normal patterns; subsequently, it is tested on data that contain anomalies. As LGFN is not trained to recognize abnormal data; anomalous features manifest as outliers during the clustering-based latent space pattern mining process, and the corresponding reconstructed data exhibit significant discrepancies compared to the original. By leveraging the distinct expressions of anomalous data in both spaces, an enhanced anomaly score has been devised, enabling the effective identification of anomalies. This chapter will provide a comprehensive overview of LGFN, including its architecture, training methodologies, and application in AD.
2.1. Problem Statement
In general, an MTS dataset can be described as , where is an M-dimensional reading at the i-th time stamp that contains information about M different channels. The entire sequence is further split into several non-overlapping windows , where includes the future S readings counting forward from time stamp t. The purpose is to predict a point-wise binary output for each time stamp t with 1 indicating the reading at t is an anomaly.
2.2. A New Multi-Scale Feature Extraction Structure for MTS
In this section, the way and GPT-2 together perform multi-scale feature extraction to make LGFN a fast and accurate AD network is explained in detail.
In the data processing stage,
is split into small windows with length
S, yielding an input window sequence
.
transforms
into a sequence of latent variables
. Each
is a feature of dimension
e. The transformation process is detailed in Equations (
1) to (
3).
In the context of a specified window, denoted by
, the
is defined as follows: The forward part
computes the forward hidden state
for each time point (also known as reading)
using Equation (
1); similarly, the backward part
computes the backward hidden state
using Equation (2).
Then, the forward and backward hidden states are concatenated to form a feature:
Here, is the number of windows.
If the original input data are reconstructed using alone, as is customary in most AD networks, then the long-term relationships between windows are likely to be overlooked, restricting the time range considered to only S readings. However, since represents features from adjacent windows, it is reasonable to hypothesize that these features exhibit temporal dependencies as well. To address this, GPT-2 is introduced as a batch-level feature extractor to sequentially process these features, enabling the management of long-term dependencies in extensive time series data.
Given that GPT-2 was originally developed for the NLP domain, with the objective of adapting its pre-trained parameters for MTAD tasks, its multi-head self-attention layers and feed-forward neural networks are chosen to be frozen, thereby preserving prior knowledge. Furthermore, only the positional embeddings layer and normalization layers are fine tuned, in accordance with the approach outlined in [
26]. The detailed structure of GPT-2 is shown in
Figure 2.
Before extracting batch-level features, padding is applied to adjust the dimension of
, ensuring that it aligns with the lightweight GPT-2 model’s typical input requirement. Subsequently,
is fed into GPT-2, and only the last hidden state is drawn as
, which serves as features enriched with temporal information within a batch of
N windows. These two steps are illustrated in Equation (
5) and (6).
compresses a window of length S into a single feature . While GPT-2 processes the N features in , it in fact processes readings in the original input sequence . This strategy significantly reduces the time and space complexity of the GPT-2 inside LGFN. The subsequent subsections provide detailed analyses and experiments related to space usage.
In
Figure 2, the GPT-2 used in LGFN consists of
L transformer decoders, all of which contain a Multi-Head Self Attention layer, an Add & Layer Norm layer, a Feed Forward layer and another Add & Layer Norm layer. Before the first decoder, the Positional Embeddings layer is used to add temporal information of a bath of features. Layers indicated by blue right-angled rectangles remain unchanged during co-training with Bi-LSTM encoder-decoder architecture, and layers indicated by pink rounded rectangles are fine tuned.
2.3. Clustering-Based Latent Space Pattern Mining
In order to identify latent patterns associated with the status of MTS and enhance the interpretability of anomalies, a clustering procedure is employed on standard data. The deviation degree, denoted by , is calculated for each in , where is the number of features in the test set. Pattern mining and deviation degree calculation are conducted using the following steps:
Clustering. Perform a clustering algorithm on , obtaining clusters and their centres ;
Latent variables distribution. For each , compute its Euclidean distance to all , and assign it to the nearest cluster. is the cluster label of ;
Deviation degree computation. Define
as the Euclidean distance between
and
; then, the deviation degree
can be obtained using the following definition:
the deviation degree vector
.
The detailed calculation steps are illustrated in Algorithm 1.
The subsequent discussion will elucidate the merits of computing deviation degrees based on clustering standard data. In instances where data comprising consecutive anomalous windows are subjected to direct clustering, the anomalous features are likely to coalesce into a small outlier cluster, with a corresponding centre that is also an outlier. Consequently, if the deviation degree is determined by the distance between an outlier feature and its similarly outlying centre, this value may not exceed the deviation degree of normal features. Consequently, such anomalous features may not be detected in the latent space. This underscores the necessity of the proposed Algorithm 1. The algorithm first clusters standard data and then assigns test data to the nearest cluster in order to effectively measure deviation.
| Algorithm 1 Pattern mining and deviation degree calculation |
- 1:
Input: , - 2:
Output: Deviation degree vector - 3:
Initialize: , , (number of clusters) - 4:
/* Step 1: Clustering */ - 5:
/* Perform clustering on , - 6:
obtaining clusters and their centres */ - 7:
- 8:
/* Step 2: Latent variables distribution */ - 9:
- 10:
for to do - 11:
for to do - 12:
- 13:
end for - 14:
- 15:
- 16:
end for - 17:
/* Step 3: Deviation degree computation */ - 18:
- 19:
for to do - 20:
- 21:
- 22:
end for - 23:
Output:
|
2.4. Data Reconstruction
The data reconstruction module incorporates a Bi-LSTM window decoder (
) that mirrors
and incorporates a fully connected layer
to adjust the model’s output size, as shown in Equation (
8).
Here,
is the weight matrix, and
is the bias vector of
.
3. Anomaly Detection Using LGFN
As shown in
Figure 1, AD using LGFN incorporates three stages: training, testing, and detecting. The three stages are described in the following subsections.
3.1. Training Stage
In the forward pass during training,
, which includes only normal data, first passes through
to obtain
(Equation (2) to (
3)). Then, padding is applied to
, resulting in
, which converts the encoder’s output into a 768-dimensional vector, so that it meets the input requirements of the pre-trained GPT-2 (Equation (
5)). Next,
is fed into GPT-2, producing features
enriched with long-term temporal relationships (Equation (6)). Finally,
and
perform data reconstruction to obtain
(Equation (
8)).
After the forward pass, a standard MSE (mean square error) loss, as described in Equation (
9), is back-propagated through
, GPT-2, and
and updates the parameters of these three components together.
However, inside GPT-2, only the positional embeddings layer and normalization layers are fine tuned, and the multi-head self-attention layers and feed-forward neural networks are chosen to be frozen. This is because GPT-2 learns many general features of sequential data during pre-training. Freezing the multi-head self-attention layers and feed-forward neural networks helps retain these general feature learning capabilities, thus preventing catastrophic forgetting [
26]. By fine-tuning the positional embeddings and normalization layers, the model can adapt to the structure and distribution of a specific time series dataset, handling unique time intervals or periodicities more accurately while not altering its understanding of general sequential data patterns. The effectiveness of pre-training is further demonstrated in the ablation experiment in
Section 4.4. The pre-trained GPT-2 used in LGFN can be directly downloaded from [
31].
As the number of training epochs increases, the loss gradually decreases, learns the features of the time windows, GPT-2 incorporates long-term temporal relationships into the time window features, and finally, the performs precise reconstruction.
After training, the trained LGFN model is saved, and a set of standard features from the training set is collected, serving as the known normal operational state.
3.2. Testing Stage
In the testing stage, the test set , which contains anomalies, is passed through the trained LGFN, yielding test set features and reconstruction .
3.3. Detecting Stage
The detecting stage is based on , saved in the training stage, as well as , , and , saved in the testing stage. These components are collected in order to calculate the detection criterion, that is, the anomaly score (). The calculation method for () will be explained in detail below.
in Equation (12) is based on the reconstruction score (
), as outlined in Equation (
10), and the outlier score (
), as specified in Equation (11):
In Equation (11),
is the output obtained by inputting
and
into Algorithm 1. ⊗ denotes the Kronecker product;
, a vector of length
S, is used to replicate each element in
for
S times.
To improve the continuity of
across different windows, EWMA is applied as the smoothing function
in Equation (11). Before combining
and
, a scaler is applied to normalize them, ensuring comparability across metrics on the same scale. In Equation (12), the hyper-parameter
controls the relative contribution of
and
in the final calculation of
.
To evaluate the basic AD capability of LGFN, a threshold is set for using the percentile method. Any time point t where the anomaly value is marked as an anomaly, i.e., let , otherwise . The detection result of is .
4. Experiments
A series of experiments were conducted under the setup outlined in
Table 1 to comprehensively assess the efficacy of LGFN in MTAD tasks.
4.1. Baseline Methods and Datasets
4.1.1. Baseline Methods
In order to conduct a comparative experiment, a selection of baseline methods was made consisting of different types of time series AD methods. These included GPT4TS [
26], CNN-based TimesNet [
32], transformer-based Autoformer [
33], and Anomaly Transformer [
20], as well as a traditional method: LSTM-VAE [
34]. They all performed AD through reconstruction differences.
4.1.2. Datasets
In order to demonstrate the efficacy of the proposed AD method, experiments were conducted on five publicly available datasets. These time sequences originated from diverse real-world scenarios, encompassing internet servers (SMD), industrial sensors (SKAB), the public service domain (PSM), the space exploration field (MSL), and industrial control systems (SWaT). The detailed information related to these data sets is described as follows, and the statistics and examples of these datasets are displayed in
Table 2 and
Figure 3:
SMD (Server Machine Dataset) [
35] is an MTS dataset collected from server infrastructure, commonly used for benchmarking AD models. It includes labelled anomalies across various server metrics. Its anomaly ratio is only 4.16%, which indicates a category-imbalanced dataset;
SKAB (Skoltech Anomaly Benchmark) [
36] is a small-scale dataset designed for evaluating AD algorithms. It contains time series data from various industrial and environmental sensors, including both normal samples and anomalies;
PSM (Public Service Message) [
37] consists of multiple time series instances collected from various public service domains, and each time series captures diverse patterns and temporal dynamics. It includes training sets that only contain normal data and test sets with anomalies;
MSL (Mars Science Laboratory rover) [
38] is collected from NASA’s Curiosity rover, which is used to explore Mars. The dataset includes telemetry data from various sensors on the rover, such as temperature, voltage, and motor currents. It contains labelled anomalies that simulate potential faults or unusual behaviour in space missions;
SWaT (Secure Water Treatment) [
39] is a cybersecurity-focused dataset from a scaled-down water treatment plant designed to simulate real-world industrial control systems. It contains MTS with labelled cyber-attacks, making it a valuable resource for research on AD, system security, and resilience in industrial control systems.
Here are some explanations about all five of the datasets we used in this research:
Training/test set split. In
Table 2, the training set size
and test set size
are pre-defined, which is the same as the setting used in [
26,
32].
Handling of missing values. Some datasets, including PSM, contain values that are NaN (not a number). The occurrence of this issue is related to incomplete data collection or errors during data acquisition. To minimize the impact of these discontinuous data on the following experiments, these values are modified to 0 during preprocessing. Additionally, the labels of all missing data in the test are set to 0.
Dataset normalization. Each dimension of the MTS dataset is assumed to contribute equally to the anomalies. All datasets are normalized using StandardScaler in Equation (
14) before being fed into the LGFN model, to eliminate dimensional differences between features and prevent certain features with larger value ranges from having an undue influence on model training.
In the above equation,
and
are the mean and standard deviation of dimension
i, respectively. The normalized dataset is
.
Moreover, it is imperative to note that k-medoids clustering has been selected as the pattern mining method in Algorithm 1 to assess the AD performance of LGFN.
4.2. Method Comparison
A series of comparative experiments were conducted on the aforementioned five datasets and methods. By comparing the model prediction with the ground truth , various metrics, such as precision, recall, F1-score and accuracy, can be obtained to evaluate AD performance. It is important to note that AD frequently operates on imbalanced datasets, where anomalies are infrequent relative to normal instances. Consequently, focusing on only precision or recall can generate misleading conclusions. The F1-score provides a more comprehensive view by considering both and , rendering it especially useful when the cost of missing anomalies is as high as incorrectly flagging normal points. Consequently, F1-score is particularly well-suited for evaluating the effectiveness of AD models.
In order to ensure a fair comparison, the embedding dimensions and the length of time series processed per batch were set to be the same for each AD method, with other parameters being optimised as much as possible within the experimental setup. Following the collection of information, it was determined that a 6-layer GPT-2 strikes a good balance compared to using either more or fewer layers, and freezing the model particularly helps prevent catastrophic forgetting, allowing for fine-tuning without the risk of over-fitting. To assess the efficacy of these AD methods under constrained computational resources, a reduced 2-layer GPT-2 configuration was employed for the evaluation of both LGFN and GPT4AD(2) (GPT4AD(2) means using a two-layer GPT-2 when implementing GPT4TS for MTAD tasks).
As demonstrated in
Table 3, LGFN attained the optimal average F1-score across the five datasets among all methods. Its recall and accuracy were the second best, and its precision was only 0.88% lower than that of the best-performing method (Autoformer).
The average precision of LGFN was lower than that of Autoformer, GPT4AD, and Anomaly Transformer by 0.88%, 0.87%, and 0.27%, respectively. The following analysis will elucidate the underlying reasons for these observations. First, in terms of the calculated in Equation (12), the weighting coefficient w for is less than 0.5 across all datasets, meaning that it plays a supplementary role in detection. The dominant part is still , like in all the other methods, so is not significantly reduced in anomalous areas, and does not undergo a substantial decrease. Second, in the latent space, the clustering objects are window-level features. In the event of an outlier in a given feature, for all time points within that corresponding window is elevated, leading to an increased probability of due to normal points near the anomaly being misclassified as anomalies. Upon consideration of both factors, a slight decrease in LGFN’s precision is observed.
LGFN’s average recall ranks second best, only 0.22% lower than the top-performing TimesNet but 4.34% higher than the third-place GPT4AD. In comparison to GPT4AD, LGFN employs a Bi-LSTM encoder–decoder architecture, which has been demonstrated to capture short-term dependencies within a window with greater efficacy than the linear encoder–decoder utilised in GPT4AD. Furthermore, the GPT-2 in LGFN processes a group of time windows’ features as opposed to individual time points, thus allowing it to consider a longer time range. These factors contribute to the model’s enhanced ability to capture both short- and long-term dependencies between time points, thereby rendering it more sensitive to anomalies. Consequently, the effectiveness of the model is enhanced, as evidenced by a reduction in the
and an increase in recall when compared to GPT4AD. The recall of TimesNet is higher than that of LGFN on the SMD, PSM, and SWaT datasets. This phenomenon can be attributed to the strong periodicity exhibited by these three datasets in many of their dimensions. Specifically, in the SMD dataset, at least 25 out of 38 dimensions display visually discernible periodicity; in the PSM dataset, at least 18 out of 25 dimensions exhibit periodic patterns; and in the SWaT dataset, almost all dimensions manifest clear periodicity. Given that TimesNet incorporates a carefully designed periodic analysis mechanism, its recall outperforms LGFN on datasets with periodicity. As demonstrated in
Figure 3, the SMD, PSM, and SWaT datasets manifest more pronounced periodicity in comparison to the MSL and SKAB datasets. In MSL and SKAB, characterised by a weaker periodicity, the relationships between time points and the causes of anomalies are more obscured and profound. In terms of recall, both LGFN and GPT4AD, which use GPT-2, demonstrate superior performance on the two datasets under consideration. It is noteworthy that the SKAB dataset, comprising 11,851 time points, exhibits the highest anomaly rate (28.26%) among the five datasets, thereby establishing it as a substantial test of a model’s capacity to discern patterns and extract features from limited data. Both LGFN and GPT4AD demonstrated particularly strong performance on the SKAB dataset, attaining a recall of approximately 100%, with no missed detections. In the larger-scale MSL dataset, LGFN further distinguishes itself, underscoring the efficacy of the proposed multi-scale feature extraction approach. The GPT-2 in LGFN exhibits a longer learning range than GPT4AD while maintaining reduced spatial complexity.
The F1-score was determined by combining precision and recall. The LGFN model demonstrated the highest average F1-score among the five models, attaining 91.30%, which is a
Figure 1.08% higher than the second-best TimesNet model. This outcome suggests that the model effectively balances the two conflicting objectives of precision and recall.
In order to provide a comprehensive evaluation, the accuracy was calculated. Despite LGFN achieving a second-place ranking, it was a mere 0.39 percentage points behind the leading model, GPT4AD. Furthermore, a detailed analysis reveals that LGFN significantly outperforms GPT4AD in terms of space efficiency (see
Section 4.3 for a comprehensive analysis).
4.3. Memory Usage
It is crucial to emphasize that the aforementioned stages are entirely decoupled from the data undergoing processing. They are designed to operate independently of data size or specific properties; the only restriction is that the input must be a time-continuous and variable amount of usually numerical values. Nevertheless, it is imperative to acknowledge the pivotal role of data volume in determining the efficacy of the AD process. The entire process must be executed efficiently or, at the very least, in a scalable manner, particularly in scenarios where the objective is to cluster fine-grained features (where the window size is relatively small) or to perform AD in small processors with limited computational resources. In order to address this issue, a comprehensive analysis of the memory usage of the proposed LGFN during a single forward pass is provided, thus enabling users to better weigh the feature granularity, detection accuracy, and deployment challenges.
The analysis of LGFN’s structure enabled the calculation of its spatial complexity as
where
l is representative of the LSTM layers contained within
and
, whilst
h denotes the LSTM hidden size.
B represents the batch size during a single forward pass,
D signifies the required input dimension of GPT-2 (which is typically 768), and
L is indicative of the number of decoder layers in GPT-2.
If the considered sequence length per batch and the embed dimension were set to be the same as LGFN, then the spatial complexity of GPT4AD(
L) would be
The detailed derivation processes for Equations (
15) and (
16) are provided in
Appendix A.
In comparison with GPT4AD, given that extracts window-level features, the sequence length that GPT-2 requires for processing is altered from T to . Moreover, given that the self-attention computation within GPT-2 constitutes the primary component of the space utilisation, this reduction in length can diminish the spatial complexity to approximately of the original. Consequently, the “OUT OF MEMORY” error is effectively alleviated during the AD process.
Experiments on memory usage are conducted in a hardware environment comprising a 3.00 GHz CPU, 8 GB RAM, 6 GB GPU, and a Windows 10 OS. As illustrated in
Figure 4, the total CUDA memory utilised during a single forward pass of LGFN and GPT4AD on the SMD dataset is demonstrated. During the experiments, the variables were controlled, with
L for both models set to 6,
, and other irrelevant parameters set to constant values.
As demonstrated in
Figure 4, during the training stage, the CUDA memory usage of LGFN is considerably lower than that of GPT4AD for all sequence lengths. When sequence length
, LGFN’s memory usage is 64.86% that of GPT4AD; at a length of 200, this ratio falls below 50%. This decrease in memory usage becomes more pronounced as the sequence length increases, with LGFN’s memory usage being only 22% of GPT4AD’s at a length of 1000. When
T reaches 2000, GPT4AD encounters an “OUT OF MEMORY” error, whereas LGFN uses only 740.58 MB of GPU space.
4.4. Ablation Experiment
To emphasise the significance of each constituent element in the proposed model, each element of the AD process was systematically substituted with more elementary alternatives, and the impact of each replacement on the model’s performance was evaluated.
First, the present study employs the use of to evaluate the performance of LGFN, without adding latent space clustering. Second, is replaced with , and then a simplest , to extract window-level features. This is undertaken to investigate the impact of the bidirectionality of LSTM and the significance of incorporating short-term time dependencies within a window to enhance AD performance. Third, the multi-GPT-2 layers in LGFN are substituted with a simple transformer decoder layer in order to demonstrate the capability of LLMs and the advantages of pre-training.
The conclusions that can be drawn from
Table 4 are as follows:
LGFN scores the highest in terms of F1-score, which demonstrates the indispensability of each component within the model.
The F1-score, recall and accuracy of the four component replacement methods decrease sequentially from top to bottom, while the FAR increases. This finding suggests that , the Bi-LSTM window-level feature extractor, and the GPT-2 batch-level feature extractor incrementally enhance the assistance to AD.
Precision undergoes a gradual increase, whilst MAR decreases. This phenomenon can be interpreted as evidence that the incorporation of Bi-LSTM and GPT-2 into the network has led to an enhancement in the network’s capacity to discern anomalies with greater rigour, a property that aligns with human cognitive processes. Furthermore, the minor rise in MAR is predominantly attributable to abnormal time points, which exhibit a comparatively lesser correlation with the machine’s operational health. However, the more critical abnormal time intervals remain predominantly discernible.
A comparison of rows 1 and 3 of the table indicates that LGFN, utilising Bi-LSTM as a window encoder, attains a 6.83% higher F1-score than utilising LSTM, highlighting the benefits of bidirectionality in LSTM for AD. This suggests that anomalies in time series data have two-way local dependencies within a window, meaning the points immediately before and after an anomaly are also likely to be anomalous. In practical terms, this can be interpreted as a machine malfunctioning at time t possibly being caused by a faulty state before t, which could also affect its performance after t.
Comparing rows 3 and 4 of the table, replacing LSTM with a simpler linear encoder–decoder structure results in a further decrease in F1-score, confirming that LSTM, which can account for short-term dependencies, is more effective than encoding structures that cannot.
The last row of the table shows that replacing GPT-2 with a single-layer transformer encoder–decoder results in the largest drop in F1-score (down 26.97%), emphatically demonstrating the capability of large models and the importance of pre-training, which is the most significant aid to AD.
4.5. Experiments on the Sensitivity of w
The weighting parameter
w in Equation (12) is undoubtedly crucial to the model’s AD performance. To provide a method for pre-selecting
w on a new dataset, we conducted a hyperparameter sensitivity analysis on
w and plotted the variation of the F1-score as
w fluctuates within the range [0, 1], as shown in
Figure 5. This can help justify its optimal setting.
The value of
w is changed from 0 to 1 with a step size of 0.1. Once the range where the maximum F1-score occurred is roughly identified, the step size is further reduced to 0.01 to compute a more precise
w value where the maximum occurred. As
w changes from 1 to 0, we observe two common trends in the F1-score across the five datasets: First, the F1-score reaches its maximum value when
w is in the range (0, 0.4); second, as
w continues to increase, the F1-score drops sharply. This indicates that
remains the main component for ensuring detection accuracy, while
can improve detection accuracy but only plays an auxiliary role. A closer analysis of the
w values where the maximum F1-score occurs shows that for
Figure 5a,c,d,e, the optimal
w falls within the range [0.0, 0.1]. Only
Figure 5b has its
w in the range [0.3, 0.4], but its change in F1-score across the range [0, 0.4] is relatively small, and the
w value in this range is nearly identical to the maximum value. This suggests that for a new dataset, setting
w within the range [0.0, 0.1] can improve model detection accuracy.
The auxiliary role of
w is more prominent in
Figure 5a, the SMD dataset, where the highest F1-score of 86.95% occurs at
, which is a local maximum in its neighbourhood. The F1-scores at
and
are 81.40% and 82.69%, respectively, differing from the maximum by 5.55% and 4.26%. In
Figure 5c PSM, although a relatively large drop occurs at
, the difference from the maximum F1-score does not exceed 1.2%. It should be noted that, under the step size conditions for
w in this experiment, the F1-score change curve is overall smooth, which is why no further reduction in the step size was made. As for the reasons behind the occurrence of the extreme values and the selection of more suitable clustering methods in the
calculation, further investigation is needed in future research.
4.6. Anomaly Score and Latent Space Analysis
During the AD process, both normal and abnormal samples are input into LGFN. After two-scale learning, outliers corresponding to abnormal windows will emerge and be detected in the latent space using
. Moreover,
will struggle to accurately conduct reconstruction using outlier feature vectors. Therefore,
at abnormal time points will be higher than at normal time points. In order to facilitate an intuitive and human-friendly understanding of the process by which
detects anomalies in latent space, the use of visualisation plots of the clustering results is recommended. These plots can also be used to indicate the minimum number of clusters required to effectively separate the features prior to any clustering operation [
42].
To illustrate this,
Figure 6a shows a comparison between an input sub-sequence (top) from the SMD test set and their reconstructed counterparts (bottom). The figure demonstrates that the reconstructions for normal samples closely match the original data. However, when the input contains anomalies, indicated by the red shading in the figure, the reconstructed sequences fail to replicate these abnormal points. This discrepancy facilitates AD in the original input space, as shown in
Figure 6c.
In
Figure 6b, the 2D latent space following PCA and t-SNE dimensionality reduction for the features corresponding to the subsequences depicted in
Figure 6a is shown. Orange points represent normal features, while red points denote anomalous features, both originating from the test set. The blue points correspond to features from the training set that do not contain anomalies, with blue crosses indicating the class centres of these training features obtained via k-medoids clustering. It is evident from the figure that, although both the normal and anomalous test features are assigned to the same class represented by the blue crosses, most of the red points are farther from the class centre than the orange points. This indicates that the anomalous features exhibit a higher deviation degree, which aids in AD in the latent space. It is evident that the distribution of 2D feature vectors can be influenced by dimensionality reduction methods, as demonstrated in
Figure 6b. The 2D latent space visualisations of feature vectors from the same cluster obtained using PCA and t-SNE will differ. Consequently, the 2D feature distribution should be regarded as a reference only, while
in
Figure 6d provides a clearer representation of distances from different windows to their respective class centres.
As illustrated in
Figure 6c, the area delineated by the two green dashed lines signifies FNs when employing solely
for detection. Conversely, the corresponding segment in (b) exhibits a higher
, suggesting that the features of this segment are more distant from the centre of their class in the latent space. Consequently, in (e), the weighted average of both scores exceeds the threshold, accurately identifying these points as anomalies and categorising them as TP. This finding underscores the efficacy of
in enhancing
’s capacity for precise detection.
Figure 7 shows windows corresponding to parts of features from four different clusters of the SMD test set, with anomalous time points highlighted in red and enclosed with red boxes. In one window, different MTS channels are distinguished using different colours. From this figure, the following two phenomena can be summarized:
Most of the windows assigned to the same cluster come from adjacent periods; even windows separated by some time intervals exhibit certain similarities in trends and states. Other windows in this subplot, such as 4544 in the first row, third column, and 4614 in the first row, fourth column, although not continuous in time, exhibit strong similarity. Specifically, the features corresponding to these two windows are very close in the latent space, which is why they are grouped into the same class.
Windows belonging to the same cluster exhibit clear visual similarities, while the differences between anomalous and normal windows within the same cluster are significant. For example, the windows in
Figure 7b share a common and obvious characteristic: two peaks appear at the 7th and 17th time steps across multiple dimensions, while the other dimensions remain relatively smooth. However, the two anomalous windows, 5617 and 5618, exhibit different characteristics: in window 5617, at least two dimensions show anomalous peaks at the 15th time step; in window 5618, a particular red dimension shows a significant decrease in value. These unique behaviours lead to their features being outliers in the latent space.
These two phenomena visually demonstrate the effectiveness of clustering-based pattern mining in latent space, and they further suggest that is indeed helpful to AD.
5. Conclusions and Future Work
In this paper, a model called the LSTM-GPT2 Fusion Network (LGFN) is proposed for solving MTAD tasks. The model provides an effective solution to address the limitations of existing AD methods, including a lack of robustness to noisy data, inability to effectively capture long-term temporal relationships, insufficient utilization of latent space features, and challenges in deployment on small-scale devices.
The model has two functions: multi-scale feature extraction and data reconstruction. AD using LGFN can be divided into three stages: the training stage, the testing stage, and the anomaly detection stage. In the training stage, the model is forced to learn normal behaviours using reconstruction error between the original input and the network output. After training, are collected for the later AD stage. In the testing stage, the test set interoperates both normal and anomalous data, generated under the same operating conditions as the training set. and are collected as well. In the anomaly detection stage, is calculated using and . Pattern mining is conducted by latent space clustering on . The obtained centres represent standard working patterns. is then distributed to these known clusters. Using the distribution results, is calculated based on the distance between each feature in and its centre. Next, by using the hyperparameter w to weight and sum these two scores, an enhanced is obtained. Finally, a percentile-based threshold is applied to produce a binary output for each data point in the test set. Metrics of AD can be calculated using the model prediction and the test set ground truth .
Upon comparison with five advanced AD methods under five widely recognised MTS datasets, it can be seen that utilising LGFN to perform AD can achieve state-of-the-art performance or comparable results. In memory usage analysis, the spatial complexity of LGFN is theoretically calculated, and experiments demonstrate that the GPU usage of LGFN is much lower than that of GPT-2 when processing raw time series data, thus alleviating the “OUT OF MEMORY” error that often occurs during the training of large models. In the context of ablation studies, all primary components are systematically removed or replaced, with a subsequent decline in most metrics indicating the indispensability of each module in the proposed AD process. The final experiment section provides a latent space visualisation, elucidating the manner in which can assist in achieving a more accurate detection.
Despite the efficacy of the proposed methodology in accurately and expeditiously detecting anomalies in time series, it is important to acknowledge the limitations inherent to the approach. One such limitation pertains to the improvement in AD efficiency, which results in a marginal decline in precision. Another is the requirement of datasets from calculation. Specifically, the data employed for network training and testing must be sourced from the same operational environment. To illustrate, if the training data consist of vibration signals from Engine No.1 during normal operation, captured by 11 different sensors (, with all labels being 0), then the test data must also be vibration signals from the same 11 sensors, capturing the machine’s behaviour during both normal and abnormal operations (M must remain 11, with alternating 0/1 labels). These 11 sensors can be deployed on different machines, but it is essential that the machines are of the same type (for example, all engines, such as Engine No. 2, No. 3, etc., but not hydraulic presses or CNC machines). Ideally, the sensor placement should also be consistent across machines. In the event of non-consistency, the entirety of the features from the designated test set would be classified as outliers, consequently resulting in a high deviation degree across all metrics.
The present study acknowledges the potential for further development in this area of research. In the present state, the method utilises a static threshold of . This approach is limited in its capacity to demonstrate the advanced AD capabilities of the proposed model. In order to address this limitation, it is necessary to employ a well-designed method to obtain a dynamic threshold that can adapt to the fluctuations in . This would allow the performance of LGFN to be enhanced, with all metrics surpassing those of state-of-the-art methods.




 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}