
ARM-Net: A Tri-Phase Integrated Network for Hyperspectral Image Compression


Abstract
1. Introduction
- This research proposes an innovative three-stage hyperspectral compression framework, known as ARM-Net. ARM-Net consists of an adaptive band selector (ABS), a Recurrent Spectral Attention Compression Network (RSACN), and a Multi-Scale Spatial-Spectral Attention Reconstruction Network (MSSARN).
- To alleviate the burden on the compression network, this paper introduces the ABS, which builds upon a common band selection mechanism used in hyperspectral lossless compression. By adaptively selecting band clusters with the highest information content, the ABS reduces the overall computational load of the framework.
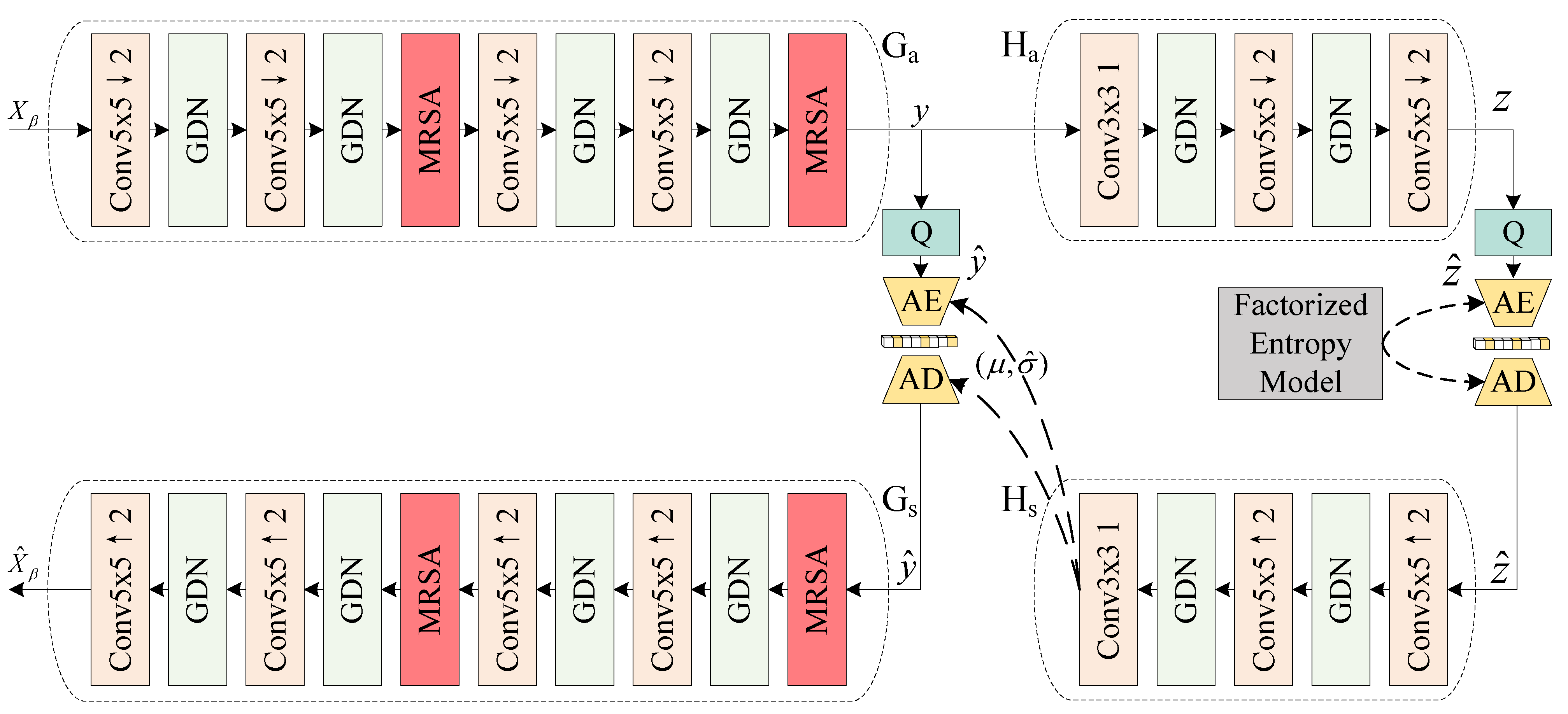
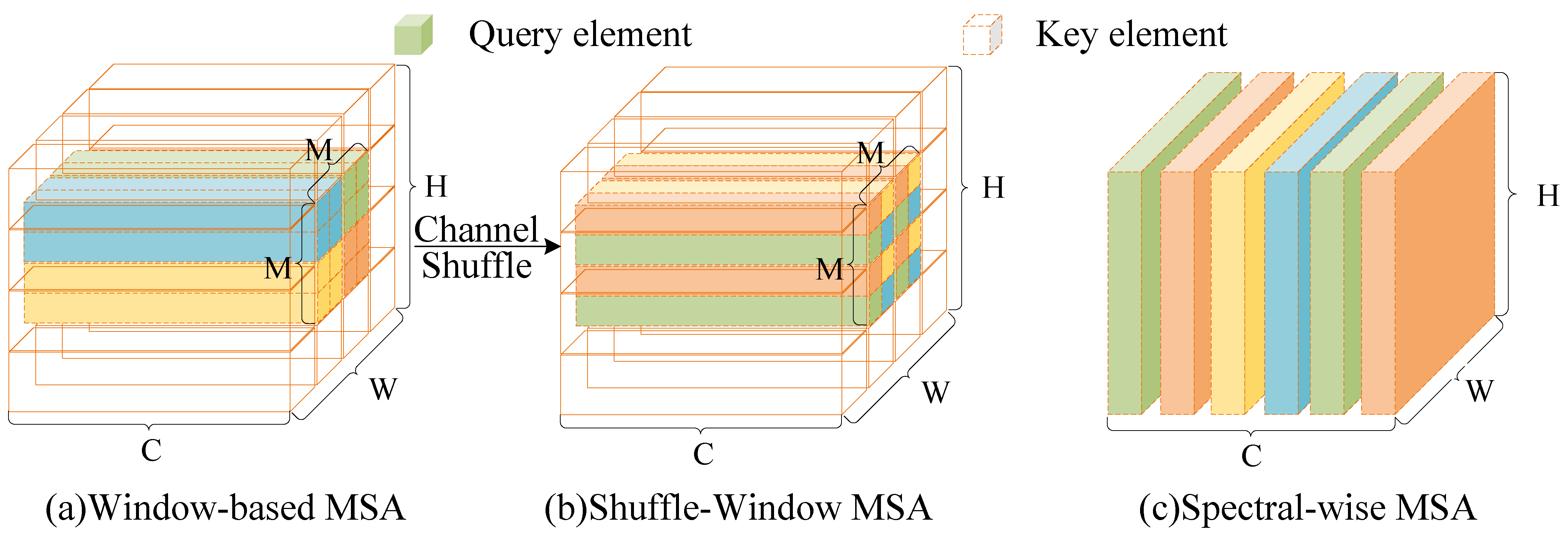
- To enhance hyperspectral compression, ARM-Net incorporates a multi-head recurrent spectral attention (MHRSA) module within its codec. MHRSA dynamically assigns attention weights to spectral bands, allowing the network to focus on the most relevant spectral features for compression. By leveraging multiple attention heads, the module captures diverse spectral interactions to preserve spectral consistency across bands, resulting in reduced redundancy and improved compression efficiency. This targeted weight adjustment approach is essential to address varying spectral pixel values, mitigating information loss that simple averaging methods may overlook.
- To optimize hyperspectral reconstruction, we propose a Spatial-Spectral Attention Block (SSAB) within the reconstruction backbone of ARM-Net. The SSAB jointly models spatial and spectral dependencies to enhance reconstruction accuracy, which compensates for spatial detail loss during compression. Spectral-Wise Multi-Head Self-Attention (Spec-MSA) and Spatial Multi-Head Self-Attention (Spa-MSA) in the SSAB are linked by residuals to effectively compensate for the lack of spatial details in HSI reconstruction through spectral reconstruction (SR) networks. This versatile and efficient plug-and-play spatial-spectral attention mechanism captures fine-grained features across both spatial and spectral dimensions while preserving a linear relationship between spatial dimensions and computational complexity.
- We comprehensively evaluate the network on our mixed hyperspectral dataset. Experimental results demonstrate that ARM-Net surpasses state-of-the-art (SOTA) approaches in terms of the peak signal-to-noise ratio (PSNR), multi-scale structural similarity index measure (MS-SSIM), and spectral angle mapper (SAM).
2. Methods
2.1. The Proposed Three-Stage Compression Framework
2.2. Adaptive Band Selector (ABS)
| Algorithm 1 Adaptive band selection algorithm workflow |
|
2.3. Recurrent Spectral Attention Compression Network (RSACN)
2.4. Multi-Scale Spatial-Spectral Attention Reconstruction Network (MSSARN)
3. Results
3.1. Experimental Configurations
3.2. Training Details
3.3. Evaluation Strategies
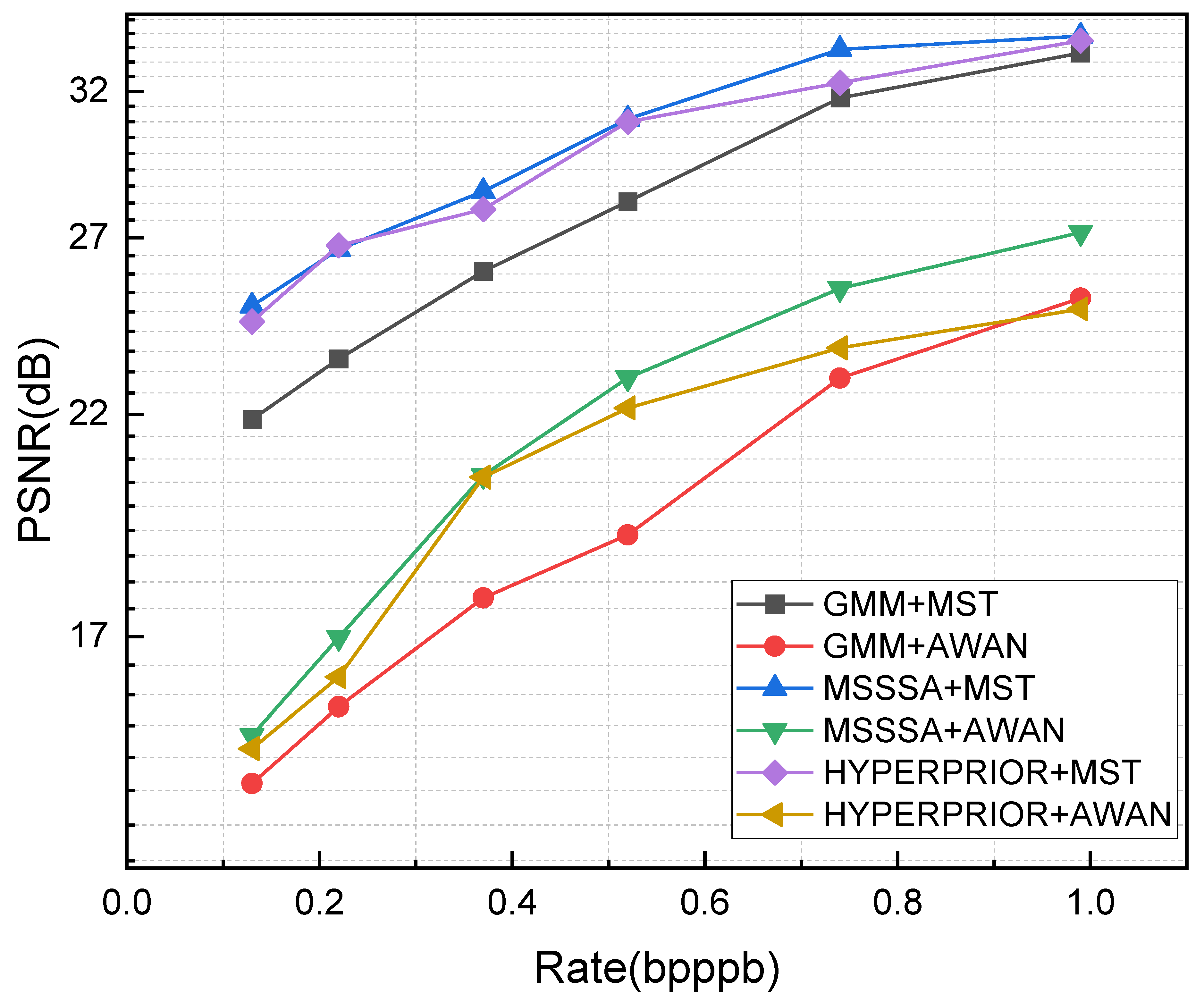
3.4. Comparative Results
3.4.1. Rate-Distortion Performance
3.4.2. Comparison of Visualization Results
3.4.3. Model Complexity Analysis
3.5. Ablation Experiments
3.5.1. Ablation Experiments on Band Selection
3.5.2. Ablation Experiments on the Attention Module
3.5.3. Ablation Experiments on the Framework
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Bian, L.; Wang, Z.; Zhang, Y.; Li, L.; Zhang, Y.; Yang, C.; Fang, W.; Zhao, J.; Zhu, C.; Meng, Q.; et al. A broadband hyperspectral image sensor with high spatio-temporal resolution. Nature 2024, 635, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Ullah, F.; Ullah, I.; Khan, R.U.; Khan, S.; Khan, K.; Pau, G. Conventional to deep ensemble methods for hyperspectral image classification: A comprehensive survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3878–3916. [Google Scholar] [CrossRef]
- Tian, Q.; He, C.; Xu, Y.; Wu, Z.; Wei, Z. Hyperspectral Target Detection: Learning Faithful Background Representations via Orthogonal Subspace-Guided Variational Autoencoder. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5516714. [Google Scholar] [CrossRef]
- Rajabi, R.; Zehtabian, A.; Singh, K.D.; Tabatabaeenejad, A.; Ghamisi, P.; Homayouni, S. Hyperspectral imaging in environmental monitoring and analysis. Front. Environ. Sci. 2024, 11, 1353447. [Google Scholar] [CrossRef]
- Li, Y.; Luo, Y.; Zhang, L.; Wang, Z.; Du, B. MambaHSI: Spatial-spectral mamba for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5524216. [Google Scholar] [CrossRef]
- García-Vera, Y.E.; Polochè-Arango, A.; Mendivelso-Fajardo, C.A.; Gutiérrez-Bernal, F.J. Hyperspectral image analysis and machine learning techniques for crop disease detection and identification: A review. Sustainability 2024, 16, 6064. [Google Scholar] [CrossRef]
- Omar, H.M.; Morsli, M.; Yaichi, S. Image compression using principal component analysis. In Proceedings of the 2020 2nd International Conference on Mathematics and Information Technology (ICMIT), Adrar, Algeria, 18–19 February 2020; pp. 226–231. [Google Scholar]
- Du, Q.; Fowler, J.E. Hyperspectral image compression using JPEG2000 and principal component analysis. IEEE Geosci. Remote Sens. Lett. 2007, 4, 201–205. [Google Scholar] [CrossRef]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end optimized image compression. arXiv 2016, arXiv:1611.01704. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. arXiv 2018, arXiv:1802.01436. [Google Scholar]
- Berger, T. Rate-distortion theory. In Wiley Encyclopedia of Telec Ommunications; Wiley Online Library: Hoboken, NJ, USA, 2003. [Google Scholar]
- Minnen, D.; Ballé, J.; Toderici, G.D. Joint autoregressive and hierarchical priors for learned image compression. Adv. Neural Inf. Process. Syst. 2018, 31, 10771–10780. [Google Scholar]
- He, D.; Zheng, Y.; Sun, B.; Wang, Y.; Qin, H. Checkerboard context model for efficient learned image compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14771–14780. [Google Scholar]
- Qian, Y.; Tan, Z.; Sun, X.; Lin, M.; Li, D.; Sun, Z.; Li, H.; Jin, R. Learning accurate entropy model with global reference for image compression. arXiv 2020, arXiv:2010.08321. [Google Scholar]
- Jiang, W.; Yang, J.; Zhai, Y.; Ning, P.; Gao, F.; Wang, R. Mlic: Multi-reference entropy model for learned image compression. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 7618–7627. [Google Scholar]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Learned image compression with discretized gaussian mixture likelihoods and attention modules. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7939–7948. [Google Scholar]
- Han, P.; Zhao, B.; Li, X. Edge-Guided Remote Sensing Image Compression. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524515. [Google Scholar] [CrossRef]
- Dardouri, T.; Kaaniche, M.; Benazza-Benyahia, A.; Dauphin, G.; Pesquet, J.C. Joint Learning of Fully Connected Network Models in Lifting Based Image Coders. IEEE Trans. Image Process. 2023, 33, 134–148. [Google Scholar] [CrossRef]
- Kong, F.; Cao, T.; Li, Y.; Li, D.; Hu, K. Multi-scale spatial-spectral attention network for multispectral image compression based on variational autoencoder. Signal Process. 2022, 198, 108589. [Google Scholar] [CrossRef]
- Guo, Y.; Tao, Y.; Chong, Y.; Pan, S.; Liu, M. Edge-guided hyperspectral image compression with interactive dual attention. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5500817. [Google Scholar] [CrossRef]
- Guo, Y.; Chong, Y.; Pan, S. Hyperspectral image compression via cross-channel contrastive learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5513918. [Google Scholar] [CrossRef]
- Rezasoltani, S.; Qureshi, F.Z. Hyperspectral Image Compression Using Implicit Neural Representations. In Proceedings of the 2023 20th Conference on Robots and Vision (CRV), Montreal, QC, Canada, 6–8 June 2023; pp. 248–255. [Google Scholar]
- Zhang, L.; Pan, T.; Liu, J.; Han, L. Compressing Hyperspectral Images into Multilayer Perceptrons Using Fast-Time Hyperspectral Neural Radiance Fields. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5503105. [Google Scholar] [CrossRef]
- Byju, A.P.; Fuchs, M.H.P.; Walda, A.; Demir, B. Generative Adversarial Networks for Spatio-Spectral Compression of Hyperspectral Images. arXiv 2023, arXiv:2305.08514. [Google Scholar]
- Mijares i Verdú, S.; Ballé, J.; Laparra, V.; Bartrina-Rapesta, J.; Hernández-Cabronero, M.; Serra-Sagristà, J. A Scalable Reduced-Complexity Compression of Hyperspectral Remote Sensing Images Using Deep Learning. Remote Sens. 2023, 15, 4422. [Google Scholar] [CrossRef]
- Llaveria, D.; Park, H.; Camps, A.; Narayan, R. Efficient Onboard Band Selection Algorithm for Hyperspectral Imagery in SmallSat Missions with Limited Downlink Capabilities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 8646–8661. [Google Scholar] [CrossRef]
- Xiang, X.; Jiang, Y.; Shi, B. Hyper-spectral image compression based on band selection and slant Haar type orthogonal transform. Int. J. Remote Sens. 2024, 45, 1658–1677. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Cai, X.; Xie, L. Three-Stages Hyperspectral Image Compression Sensing with Band Selection. CMES-Comput. Model. Eng. Sci. 2023, 134, 293–316. [Google Scholar] [CrossRef]
- Zhou, X.; Zou, X.; Shen, X.; Wei, W.; Zhu, X.; Liu, H. BTC-Net: Efficient bit-level tensor data compression network for hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5500717. [Google Scholar] [CrossRef]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Zhu, F.; Wang, H.; Yang, L.; Li, C.; Wang, S. Lossless compression for hyperspectral images based on adaptive band selection and adaptive predictor selection. KSII Trans. Internet Inf. Syst. (TIIS) 2020, 14, 3295–3311. [Google Scholar]
- Chen, T.; Liu, H.; Ma, Z.; Shen, Q.; Cao, X.; Wang, Y. End-to-end learnt image compression via non-local attention optimization and improved context modeling. IEEE Trans. Image Process. 2021, 30, 3179–3191. [Google Scholar] [CrossRef] [PubMed]
- Lai, Z.; Fu, Y. Mixed attention network for hyperspectral image denoising. arXiv 2023, arXiv:2301.11525. [Google Scholar]
- Gao, Z.; Yi, W. Prediction of Projectile Interception Point and Interception Time Based on Harris Hawk Optimization–Convolutional Neural Network–Support Vector Regression Algorithm. Mathematics 2025, 13, 338. [Google Scholar] [CrossRef]
- Zimerman, I.; Wolf, L. On the long range abilities of transformers. arXiv 2023, arXiv:2311.16620. [Google Scholar]
- Cai, Y.; Lin, J.; Lin, Z.; Wang, H.; Zhang, Y.; Pfister, H.; Timofte, R.; Van Gool, L. Mst++: Multi-stage spectral-wise transformer for efficient spectral reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 745–755. [Google Scholar]
- Yang, X.; Chen, J.; Yang, Z. Hyperspectral Image Reconstruction via Combinatorial Embedding of Cross-Channel Spatio-Spectral Clues. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6567–6575. [Google Scholar]
- AVIRIS-Airborne Visible/Infrared Imaging Spectrometer. 2025. Available online: https://aviris.jpl.nasa.gov/ (accessed on 4 March 2025).
- Pan, T.; Zhang, L.; Song, Y.; Liu, Y. Hybrid attention compression network with light graph attention module for remote sensing images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6005605. [Google Scholar] [CrossRef]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Liu, F. Adaptive weighted attention network with camera spectral sensitivity prior for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 462–463. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages | Applicability | Limitations |
|---|---|---|---|---|
| ARM-Net (ours) | Spatial and spectral feature fusion | Framework dependency issues | General hyperspectral images | Slow decoding speed |
| FHNeRF (2024) | Implicit transform coding | Limited generalizability | General hyperspectral images | Training relies on specific images |
| Verdú (2024) | Channel clustering reduces complexity | Spectral channel dependence | General hyperspectral images | Limited by embedded architecture |
| CHENG (2020) | Accurate modeling of discrete Gaussian mixture models | High computational complexity | General still images | Weak spectral information representation |
| Pan (2023) | Focuses on content and texture branches | High computational complexity | General still images | May introduce artifacts |
| Hyperprior (2017) | Accurate modeling of hyperprior entropy model | Insufficient adaptability | General still images | Weak spectral information representation |
| PCA | Reduces feature dimensionality | Sensitive to data accuracy | Pre-compression of small-sized and high-relevance images | Complex decompression |
| BPG | High dynamic range | Low codec performance | High-quality, low-bandwidth transmission | Poor compatibility |
| JPEG2000 | Transparent progressive | Low bit-rate blur | Medical/Satellite images | Limited adaptability to complex scenarios |
| Method | Parameters (M) | FLOPs (G) | Enc-Times (s) | Dec-Times (s) |
|---|---|---|---|---|
| ARM-Net | 9.3 | 7.9 | 0.16 | 0.29 |
| FHNeRF | 0.004785 | 1.7 | 0.11 | 0.14 |
| Pan | 21.0 | 55.6 | 0.42 | 0.40 |
| Cheng | 18.0 | 61.1 | 0.40 | 1.50 |
| Hyperprior | 7.1 | 28.7 | 0.12 | 0.15 |
| Verdú | 7.1 | 28.7 | 0.13 | 0.16 |
| Compression Ratio | 1.0/16 | 0.8/16 |
|---|---|---|
| PSNR with adaptive band selection algorithm | 34.14 dB | 33.11 dB |
| PSNR for equally spaced samples | 32.07 dB | 31.66 dB |
| 2 | 3 | 4 | |
|---|---|---|---|
| PSNR (bpppb = 1.0) | 28.14 | 34.14 | 34.21 |
| PSNR (bpppb = 0.8) | 26.11 | 33.11 | 33.06 |
| Methods | Parameters | FLOPs | Times |
|---|---|---|---|
| Hyperprior+MST | 8.6 M | 8.0 G | 16.8 ms |
| MSSSA+MST | 38.7 M | 45.5 G | 30.8 ms |
| Cheng+MST | 11.2 M | 11.5 G | 21.6 ms |
| Hyperprior+AWAN | 7.5 M | 9.9 G | 17.9 ms |
| MSSSA+AWAN | 37.5 M | 47.2 G | 34.1 ms |
| Cheng+AWAN | 10.1 M | 13.6 G | 22.6 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Q.; Wang, Z.; Wang, J.; Zhang, L. ARM-Net: A Tri-Phase Integrated Network for Hyperspectral Image Compression. Sensors 2025, 25, 1843. https://doi.org/10.3390/s25061843
Fang Q, Wang Z, Wang J, Zhang L. ARM-Net: A Tri-Phase Integrated Network for Hyperspectral Image Compression. Sensors. 2025; 25(6):1843. https://doi.org/10.3390/s25061843
Chicago/Turabian StyleFang, Qizhi, Zixuan Wang, Jingang Wang, and Lili Zhang. 2025. "ARM-Net: A Tri-Phase Integrated Network for Hyperspectral Image Compression" Sensors 25, no. 6: 1843. https://doi.org/10.3390/s25061843
APA StyleFang, Q., Wang, Z., Wang, J., & Zhang, L. (2025). ARM-Net: A Tri-Phase Integrated Network for Hyperspectral Image Compression. Sensors, 25(6), 1843. https://doi.org/10.3390/s25061843