
Optimizing Satellite Imagery Datasets for Enhanced Land/Water Segmentation

 , ,
, ,  ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
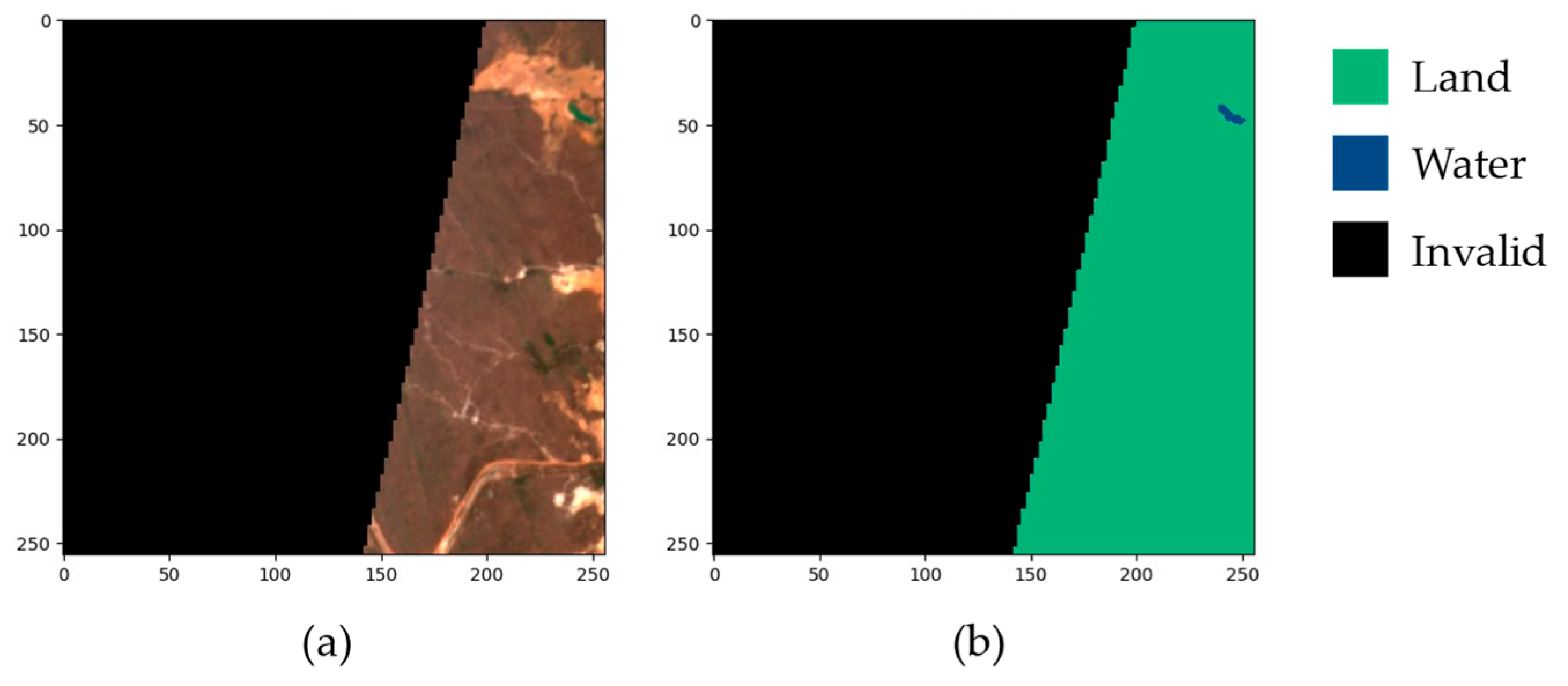
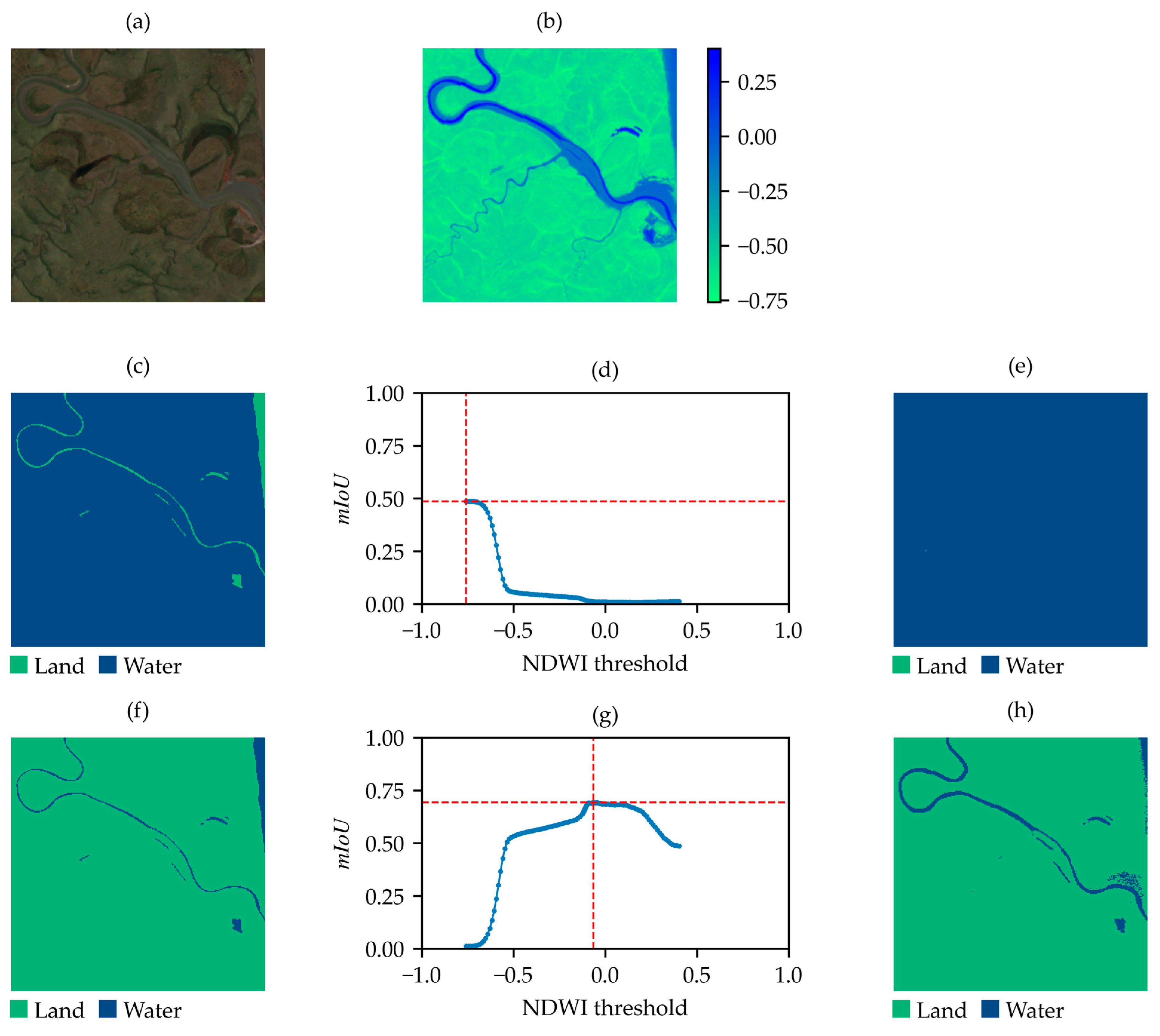
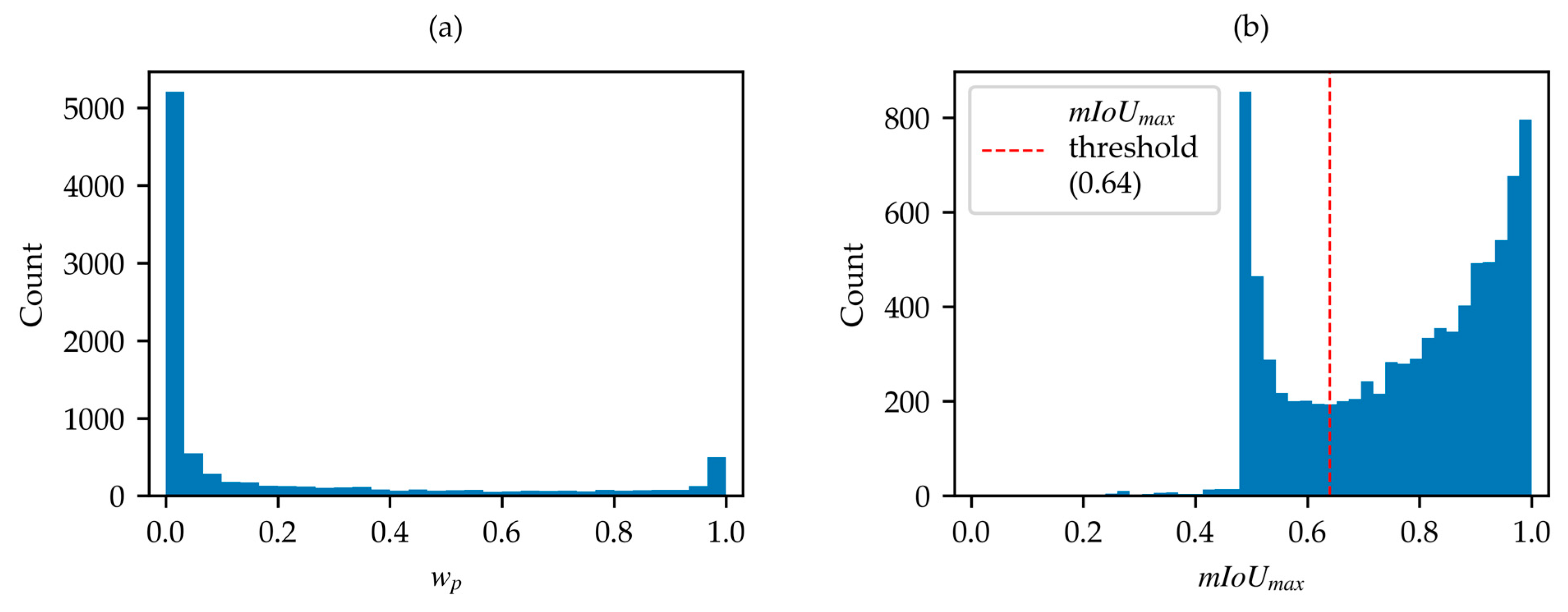
2.1. Dataset Check and Optimization Method
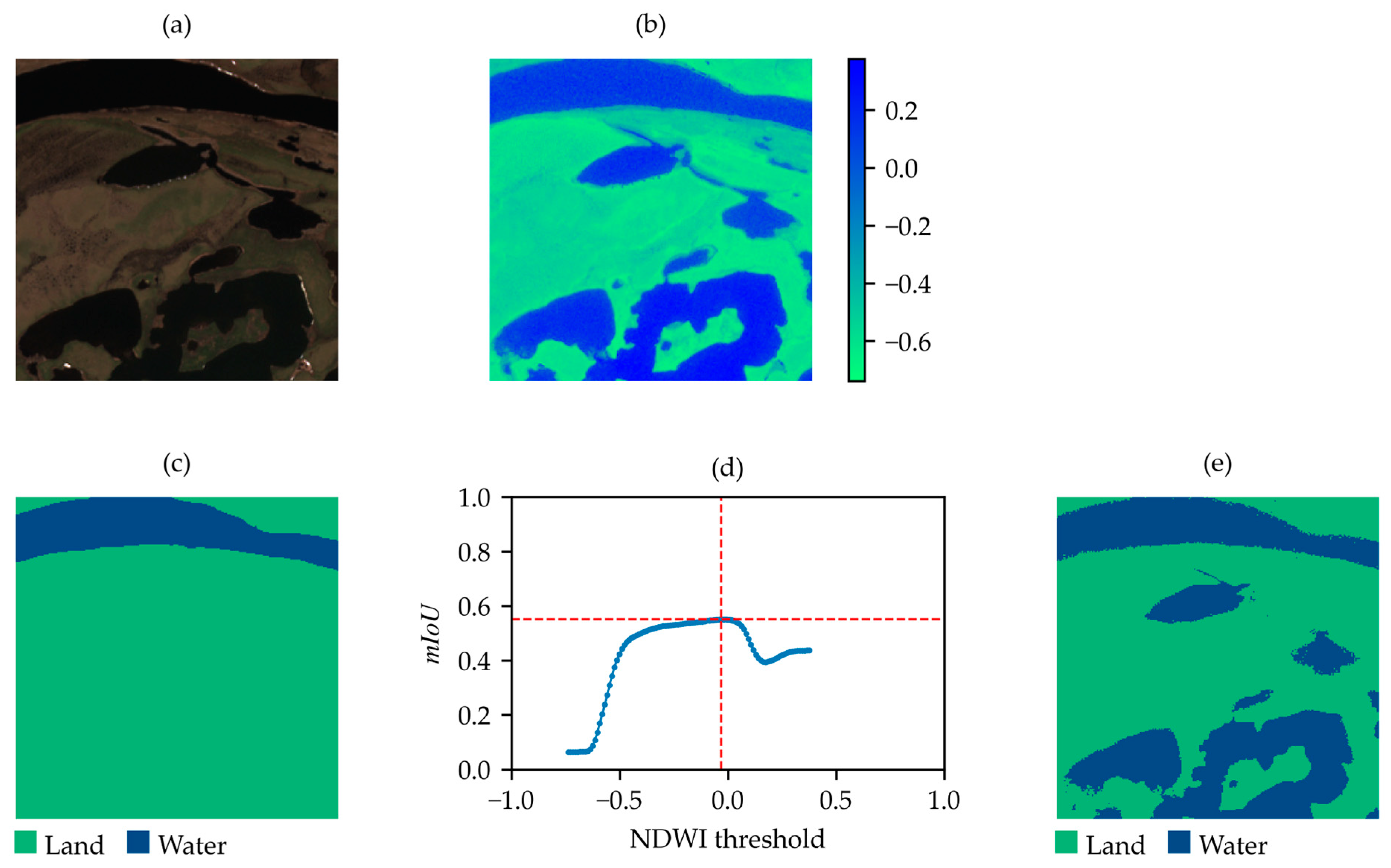
- First iteration (coarse search): 100 linearly spaced thresholds are calculated, ranging from the minimum to the maximum NDWI value for the sample. The coarse threshold estimation, , is then obtained by choosing the threshold that maximizes the .
- Second iteration (first refinement): a refined search is performed by computing an additional set of 100 linearly spaced thresholds within a narrower range. Specifically, this range extends from five values before to five values after determined in the first iteration.
- Third iteration (second refinement): the same refinement process is applied again, but now within an even smaller range around the updated , obtained from the second iteration, further improving the threshold resolution.
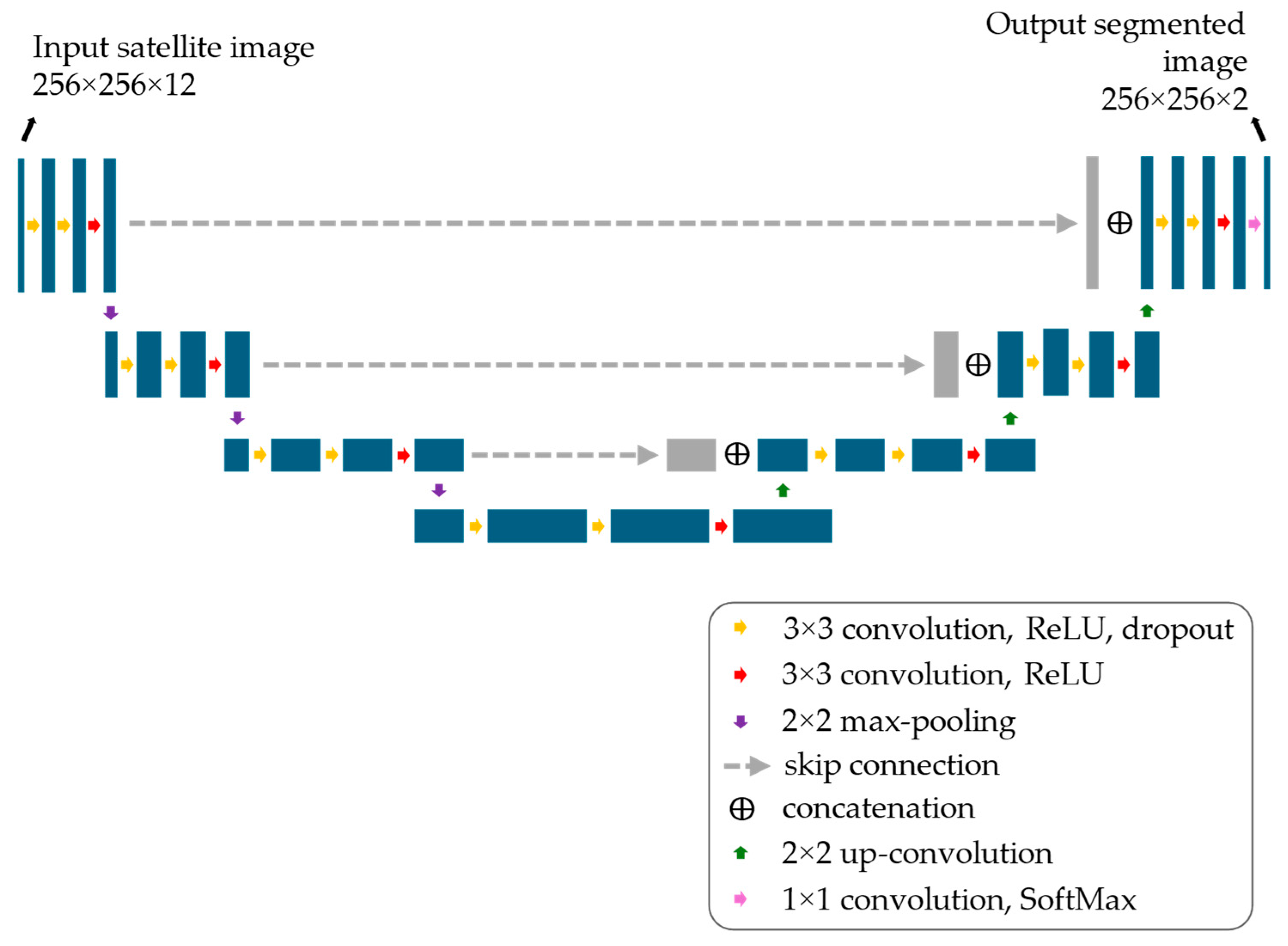
2.2. Assessment of the Performance of the Datasets
2.3. Datasets for Validation of the Optimization Procedure
2.3.1. SWED
2.3.2. SNOWED
3. Results and Discussion
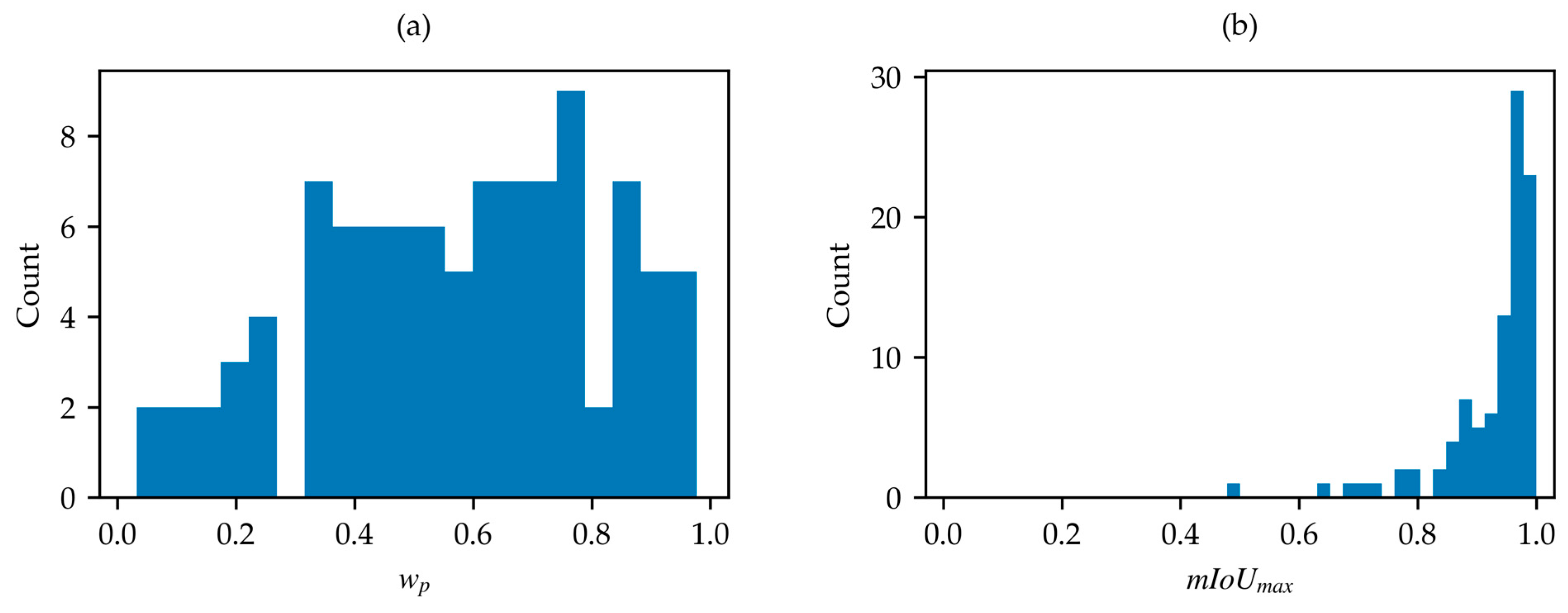
3.1. Dataset Optimization Procedure
3.1.1. SWED Optimization
- In the whole dataset, 3688 samples do not meet criterion (2) (water percentage).
- In the remaining samples, 533 do not meet criterion (3) ; however, swapping land and water classes, 124 of them achieve and are therefore acceptable after this correction. Hence, a total of 533 − 124 = 409 samples must be discarded on the basis of criterion (3).
- After correcting the inverted labels, the total number of acceptable samples is 8851 − 3688 − 409 = 4754.
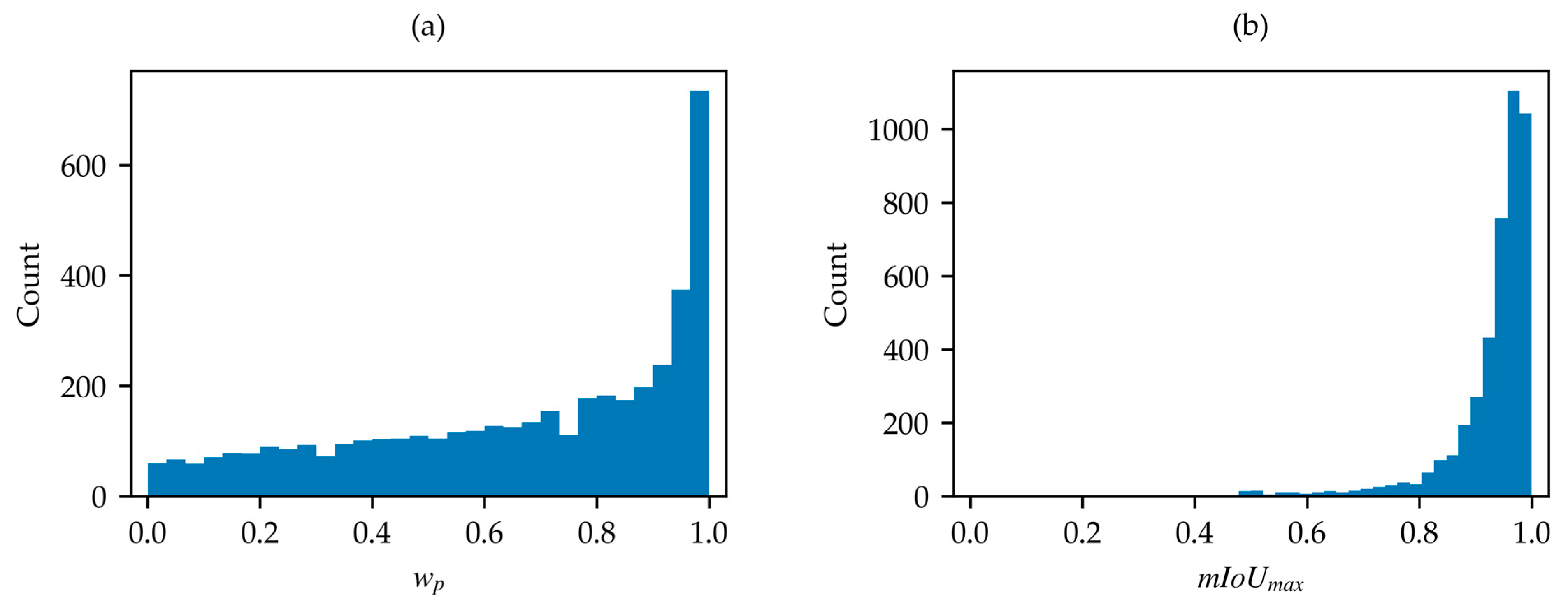
3.1.2. SNOWED Optimization
3.1.3. Summary of the Dataset Optimization Procedure
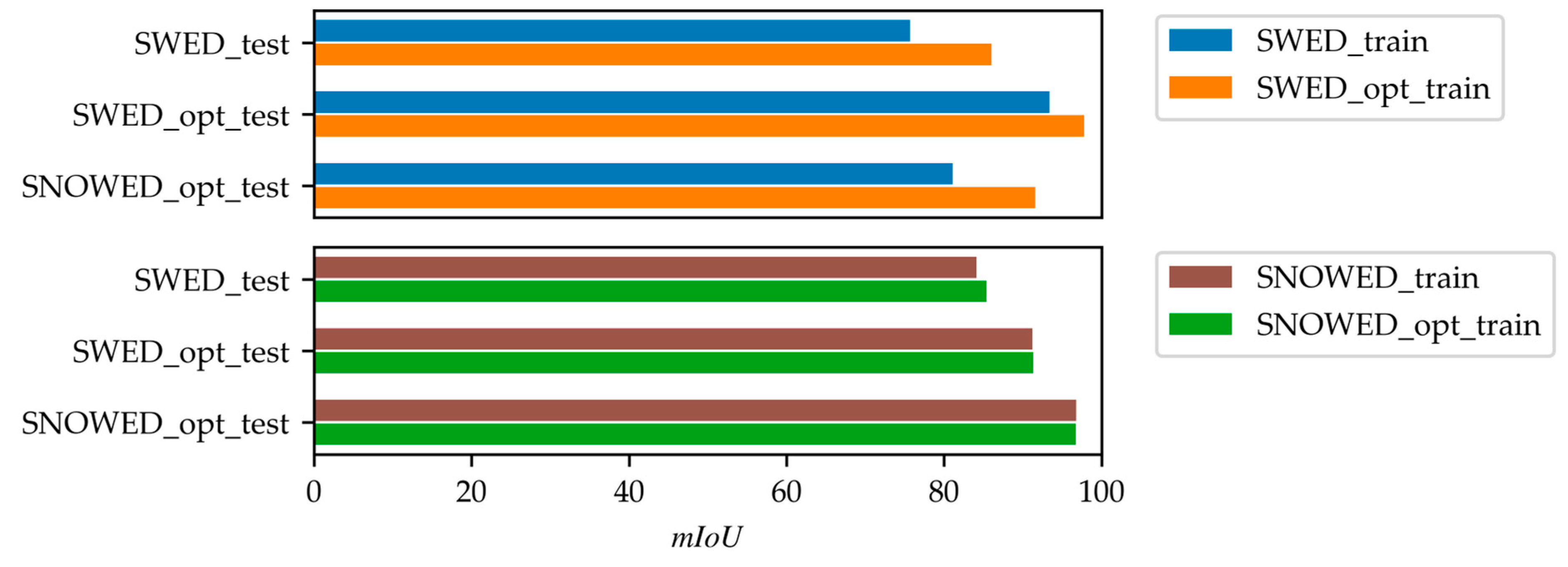
3.2. Performance of the Optimized Datasets
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Galaz, V.; Centeno, M.A.; Callahan, P.W.; Causevic, A.; Patterson, T.; Brass, I.; Baum, S.; Farber, D.; Fischer, J.; Garcia, D.; et al. Artificial Intelligence, Systemic Risks, and Sustainability. Technol. Soc. 2021, 67, 101741. [Google Scholar] [CrossRef]
- Nematzadeh, P. Recent Applications of AI to Environmental Disciplines: A Review. Sci. Total Environ. 2024, 906, 167705. [Google Scholar] [CrossRef]
- Messina, G.; Modica, G. Applications of UAV Thermal Imagery in Precision Agriculture: State of the Art and Future Research Outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Adamo, F.; Attivissimo, F.; Carducci, C.G.C.; Lanzolla, A.M.L. A Smart Sensor Network for Sea Water Quality Monitoring. IEEE Sens. J. 2015, 15, 2514–2522. [Google Scholar] [CrossRef]
- Water and Climate Change. Available online: https://www.unwater.org/water-facts/water-and-climate-change (accessed on 30 January 2025).
- McFeeters, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of Normalised Difference Water Index (NDWI) to Enhance Open Water Features in Remotely Sensed Imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A New Technique for Surface Water Mapping Using Landsat Imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Shen, L.; Li, C. Water Body Extraction from Landsat ETM+ Imagery Using Adaboost Algorithm. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–4. [Google Scholar]
- Guo, Z.; Wu, L.; Huang, Y.; Guo, Z.; Zhao, J.; Li, N. Water-Body Segmentation for SAR Images: Past, Current, and Future. Remote Sens. 2022, 14, 1752. [Google Scholar] [CrossRef]
- Tajima, Y.; Wu, L.; Watanabe, K. Development of a Shoreline Detection Method Using an Artificial Neural Network Based on Satellite SAR Imagery. Remote Sens. 2021, 13, 2254. [Google Scholar] [CrossRef]
- Cui, B.; Jing, W.; Huang, L.; Li, Z.; Lu, Y. SANet: A Sea–Land Segmentation Network Via Adaptive Multiscale Feature Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 116–126. [Google Scholar] [CrossRef]
- Scarpetta, M.; Spadavecchia, M.; Affuso, P.; D’Alessandro, V.I.; Giaquinto, N. Use of the SNOWED Dataset for Sentinel-2 Remote Sensing of Water Bodies: The Case of the Po River. Sensors 2024, 24, 5827. [Google Scholar] [CrossRef] [PubMed]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Budach, L.; Feuerpfeil, M.; Ihde, N.; Nathansen, A.; Noack, N.; Patzlaff, H.; Naumann, F.; Harmouch, H. The Effects of Data Quality on Machine Learning Performance. arXiv 2022, arXiv:2207.14529. [Google Scholar]
- Klie, J.-C.; Webber, B.; Gurevych, I. Annotation Error Detection: Analyzing the Past and Present for a More Coherent Future. Comput. Linguist. 2023, 49, 157–198. [Google Scholar] [CrossRef]
- Aragona, B. Algorithm Audit: Why, What, and How? Routledge: London, UK, 2021; ISBN 978-1-003-08038-1. [Google Scholar]
- Seale, C.; Redfern, T.; Chatfield, P.; Luo, C.; Dempsey, K. Coastline Detection in Satellite Imagery: A Deep Learning Approach on New Benchmark Data. Remote Sens. Environ. 2022, 278, 113044. [Google Scholar] [CrossRef]
- Andria, G.; Scarpetta, M.; Spadavecchia, M.; Affuso, P.; Giaquinto, N. SNOWED: Automatically Constructed Dataset of Satellite Imagery for Water Edge Measurements. Sensors 2023, 23, 4491. [Google Scholar] [CrossRef]
- Wieland, M.; Fichtner, F.; Martinis, S.; Groth, S.; Krullikowski, C.; Plank, S.; Motagh, M. S1S2-Water: A Global Dataset for Semantic Segmentation of Water Bodies From Sentinel- 1 and Sentinel-2 Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1084–1099. [Google Scholar] [CrossRef]
- Wieland, M.; Martinis, S.; Kiefl, R.; Gstaiger, V. Semantic Segmentation of Water Bodies in Very High-Resolution Satellite and Aerial Images. Remote Sens. Environ. 2023, 287, 113452. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Mateo-Garcia, G.; Veitch-Michaelis, J.; Smith, L.; Oprea, S.V.; Schumann, G.; Gal, Y.; Baydin, A.G.; Backes, D. Towards Global Flood Mapping Onboard Low Cost Satellites with Machine Learning. Sci. Rep. 2021, 11, 7249. [Google Scholar] [CrossRef] [PubMed]
- Drakonakis, G.I.; Tsagkatakis, G.; Fotiadou, K.; Tsakalides, P. OmbriaNet—Supervised Flood Mapping via Convolutional Neural Networks Using Multitemporal Sentinel-1 and Sentinel-2 Data Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2341–2356. [Google Scholar] [CrossRef]
- Scarpetta, M.; Di Nisio, A.; Affuso, P.; Spadavecchia, M.; Giaquinto, N. Metrology for AI: Quality Evaluation of the SNOWED Dataset for Satellite Images Segmentation. In Proceedings of the 2024 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), St Albans, UK, 21–23 October 2024; pp. 1005–1009. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical Image Segmentation Review: The Success of U-Net. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10076–10095. [Google Scholar] [CrossRef]
- D’Alessandro, V.I.; De Palma, L.; Attivissimo, F.; Di Nisio, A.; Lanzolla, A.M.L. U-Net Convolutional Neural Network for Multisource Heterogeneous Iris Segmentation. In Proceedings of the 2023 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Jeju, Republic of Korea, 14–16 June 2023; pp. 1–5. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Scarpetta, M.; Ragolia, M.A.; Spadavecchia, M.; Affuso, P.; Giaquinto, N. The SNOWED Dataset and Its Application to Po River Monitoring Through Satellite Images. In Proceedings of the 2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Milano, Italy, 25–27 October 2023; pp. 1092–1097. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Scarpetta, M.; Spadavecchia, M.; D’Alessandro, V.I.; De Palma, L.; Giaquinto, N. A New Dataset of Satellite Images for Deep Learning-Based Coastline Measurement. In Proceedings of the 2022 IEEE International Conference on Metrology for Extended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Rome, Italy, 26–28 October 2022; pp. 635–640. [Google Scholar]
- NOAA. Shoreline Website. Available online: https://shoreline.noaa.gov/cusp.html (accessed on 29 June 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Total Number of Samples | Non-Acceptable Samples | Acceptable Samples | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Contain Invalid Classes | Contain Only One Class | Criterion (2) Not Met | Criterion (3) Not Met | Total | As Is | After Inversion | Total | ||
| SWED Test Set | 98 | 0 | 0 | 0 | 0 | 0 | 97 | 1 | 98 |
| SWED | 28,224 | 1703 | 17,670 | 3688 | 409 | 23,470 | 4630 | 124 | 4754 |
| SNOWED | 4334 | 0 | 0 | 255 | 34 | 289 | 4045 | 0 | 4045 |
| Usage | Name | Composition | Number of Samples |
|---|---|---|---|
| Testing | SWED_test | SWED test set | 98 |
| SWED_opt_test | 20% of optimized SWED | 951 | |
| SNOWED_opt_test | 20% of optimized SNOWED | 809 | |
| Training | SWED_train | All SWED samples (except for those with invalid labels and those included in the test set) | 25,570 |
| SWED_opt_train | 80% of optimized SWED | 3803 | |
| SNOWED_train | All SNOWED samples (except for those included in the test set) | 3525 | |
| SNOWED_opt_train | 80% of optimized SNOWED | 3236 |
| Training Dataset | Test Dataset | |||||
|---|---|---|---|---|---|---|
| SWED_Test | SWED_Opt_Test | SNOWED_Opt_Test | ||||
| (Pixels) | (Pixels) | (Pixels) | ||||
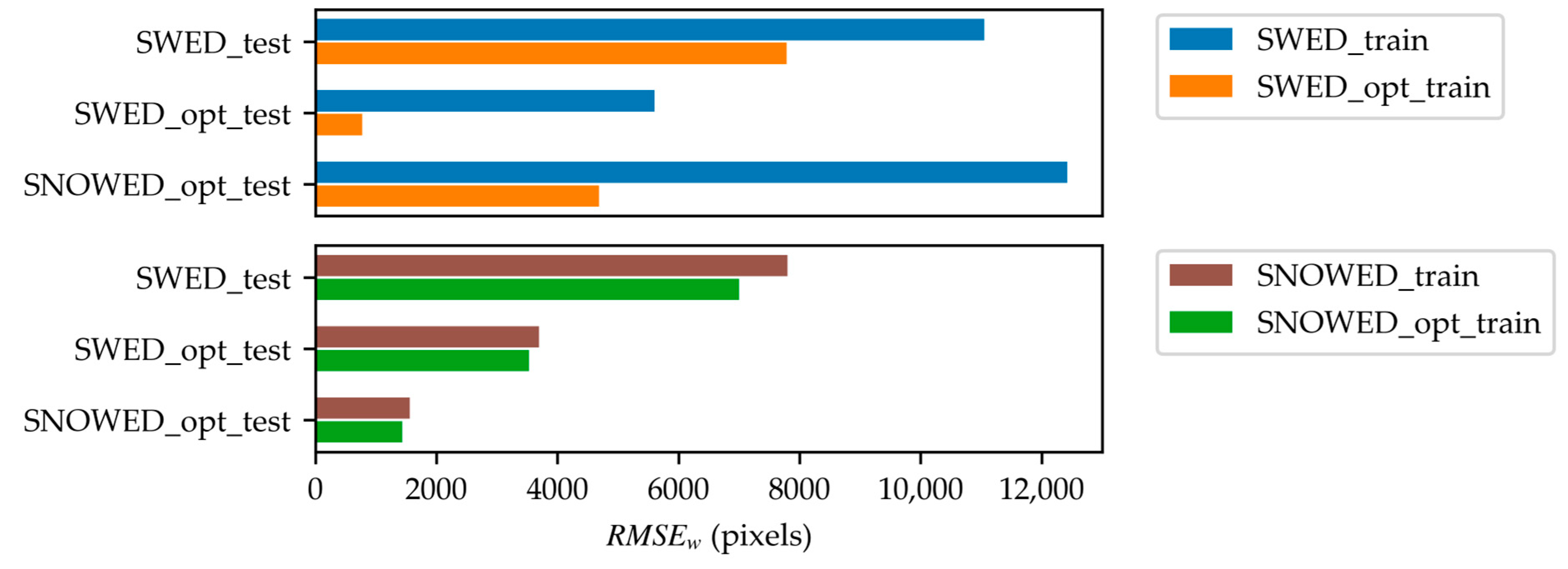
| SWED_train | 75.7% | 11,051 | 93.4% | 5603 | 81.1% | 12,425 |
| SWED_opt_train | 86.0% | 7788 | 97.8% | 775 | 91.6% | 4683 |
| Training Dataset | Test Dataset | |||||
|---|---|---|---|---|---|---|
| SWED_Test | SWED_Opt_Test | SNOWED_Opt_Test | ||||
| (Pixels) | (Pixels) | (Pixels) | ||||
| SNOWED_train | 84.1% | 7801 | 91.2% | 3693 | 96.8% | 1560 |
| SNOWED_opt_train | 85.4% | 7003 | 91.3% | 3528 | 96.7% | 1432 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scarpetta, M.; De Palma, L.; Di Nisio, A.; Spadavecchia, M.; Affuso, P.; Giaquinto, N. Optimizing Satellite Imagery Datasets for Enhanced Land/Water Segmentation. Sensors 2025, 25, 1793. https://doi.org/10.3390/s25061793
Scarpetta M, De Palma L, Di Nisio A, Spadavecchia M, Affuso P, Giaquinto N. Optimizing Satellite Imagery Datasets for Enhanced Land/Water Segmentation. Sensors. 2025; 25(6):1793. https://doi.org/10.3390/s25061793
Chicago/Turabian StyleScarpetta, Marco, Luisa De Palma, Attilio Di Nisio, Maurizio Spadavecchia, Paolo Affuso, and Nicola Giaquinto. 2025. "Optimizing Satellite Imagery Datasets for Enhanced Land/Water Segmentation" Sensors 25, no. 6: 1793. https://doi.org/10.3390/s25061793
APA StyleScarpetta, M., De Palma, L., Di Nisio, A., Spadavecchia, M., Affuso, P., & Giaquinto, N. (2025). Optimizing Satellite Imagery Datasets for Enhanced Land/Water Segmentation. Sensors, 25(6), 1793. https://doi.org/10.3390/s25061793