

A Novel Framework for Remote Sensing Image Synthesis with Optimal Transport

Abstract
1. Introduction
- We introduce two attention modules within the image encoder and generator, significantly enhancing the diversity of feature categories for RSI synthesis.
- By utilizing OT, we reformulate the loss function, ensuring that the generated images align more closely with the ground truth in terms of human perception.
- The experimental results demonstrate that our algorithm outperforms SOTA algorithms in generating RSIs.
2. Related Works
2.1. GANs in Image Generation
2.2. Diffusion Models in Image Generation
2.3. Labels to Images
2.4. Remote Sensing Images (RSIs) and Semantic Segmentation
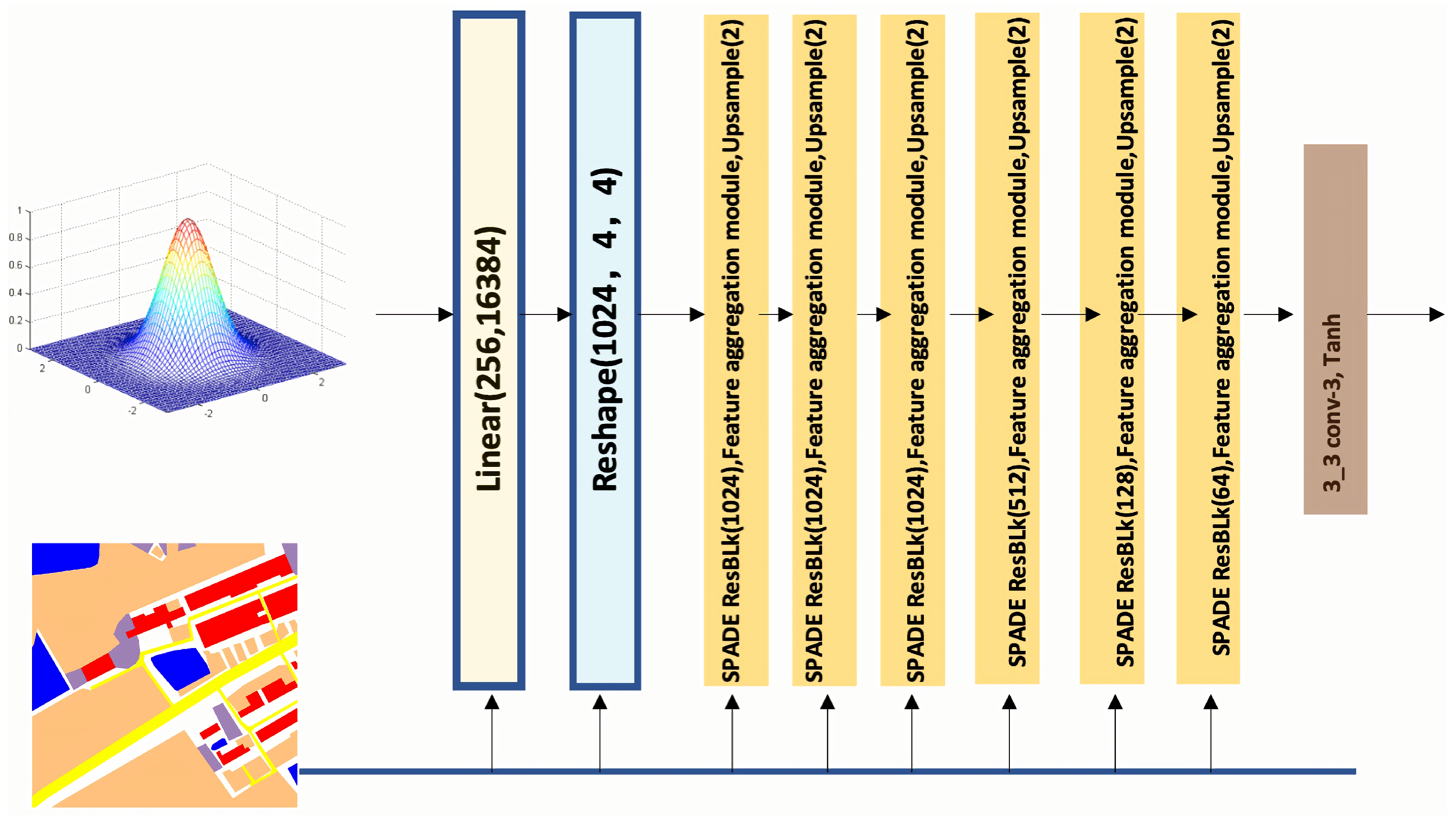
3. Methods
3.1. Algorithm Overview
- Small interclass variance: RSIs are often captured through aerial photography and exhibit minimal variation between different classes. Due to distant viewpoints, pixels from distinct objects tend to appear blurred and similar. This makes it challenging to differentiate them in the feature layer when aligning them with the label data. Image attributes from different categories have similar distributions, such as forest and agriculture in the LoveDA [37] dataset.
- Large intraclass variance: RSIs exhibit significant intraclass variance. This means that even within the same label group, objects can appear differently due to varying scenarios and different collection devices. Furthermore, the same class in RSIs often contains uneven elements in addition to distinguishable objects. Thus, a single category can have different distributions in images and feature spaces depending on label position and label structure.
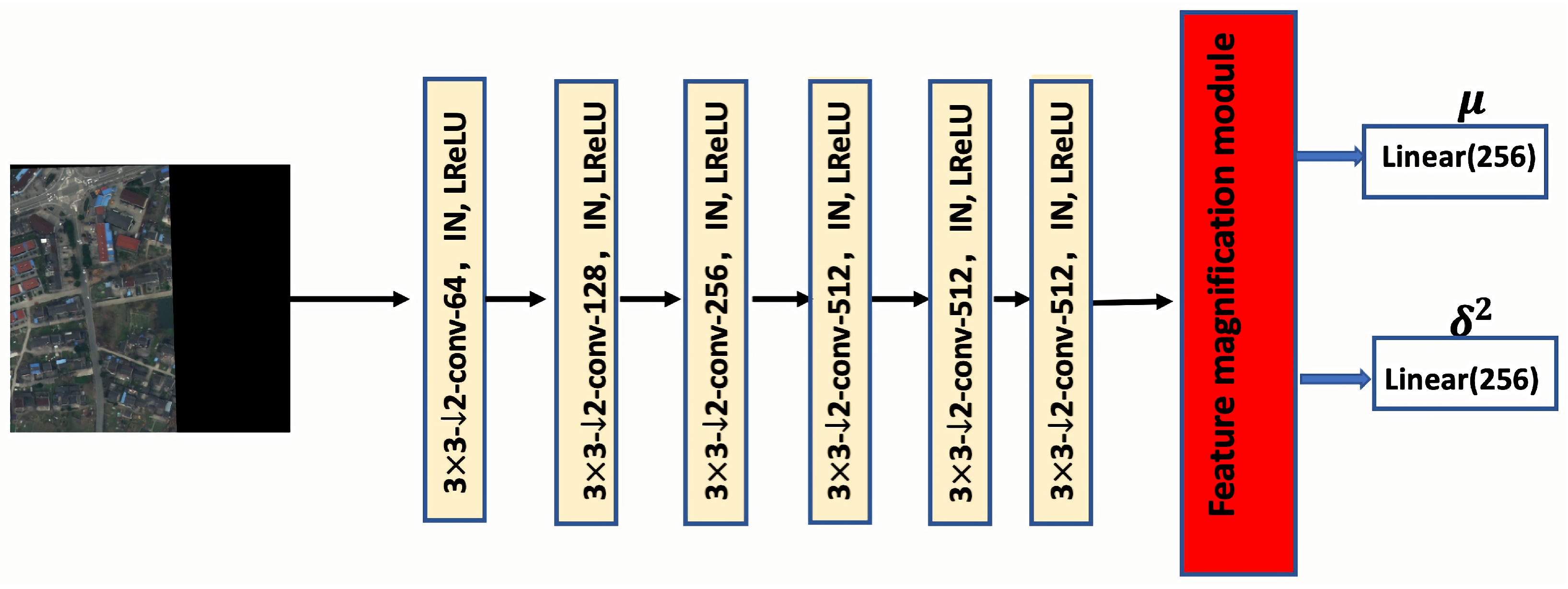
3.2. Feature Magnification Module
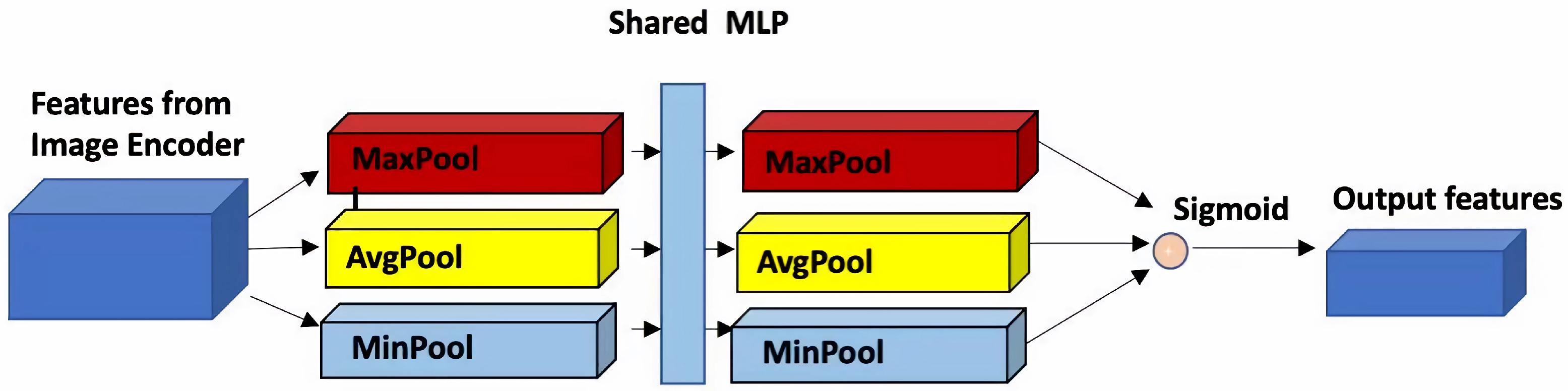
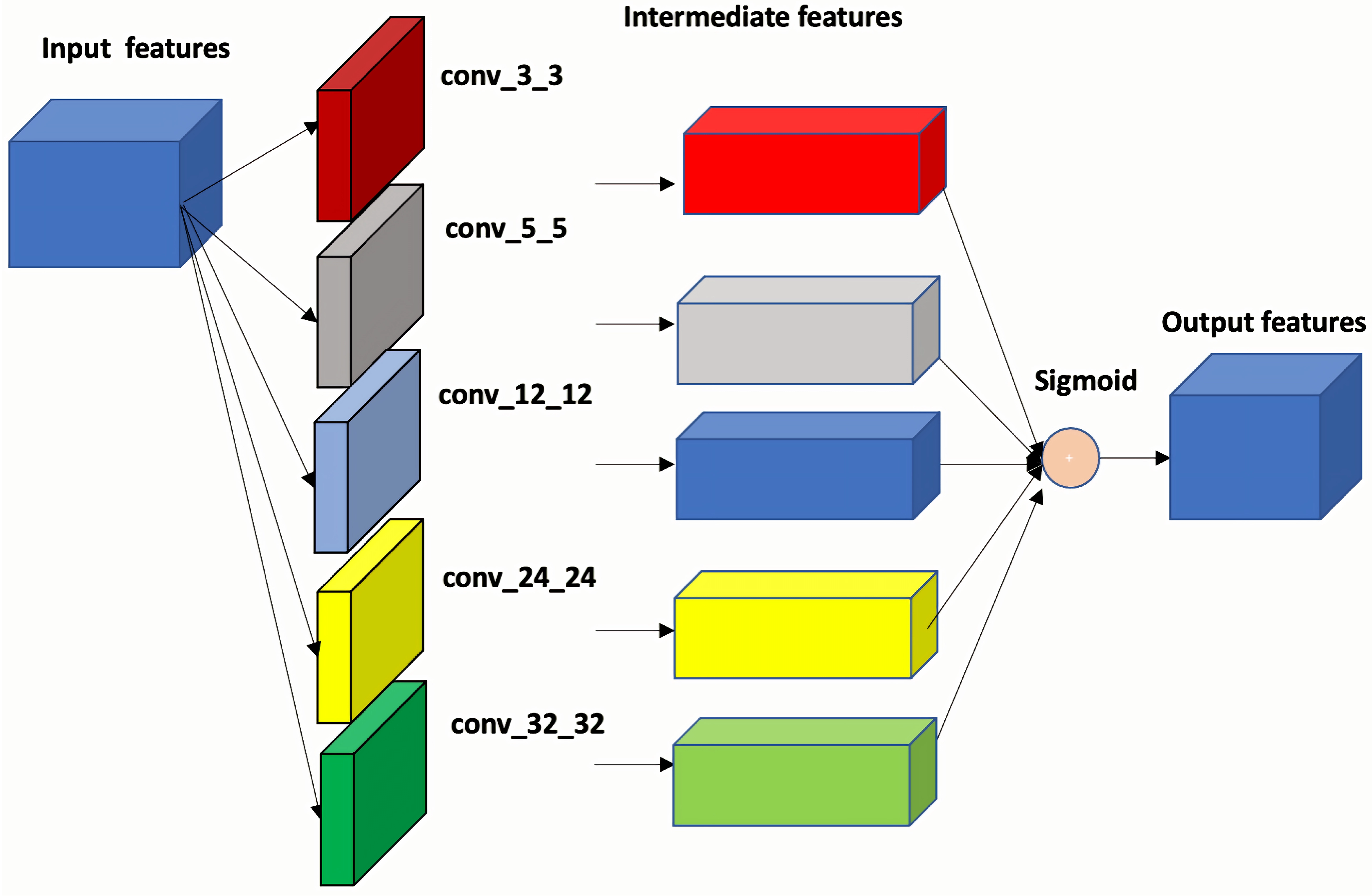
3.3. Feature Aggregation Module
3.4. OT Loss
4. Experiments and Analysis
4.1. Experimental Setup
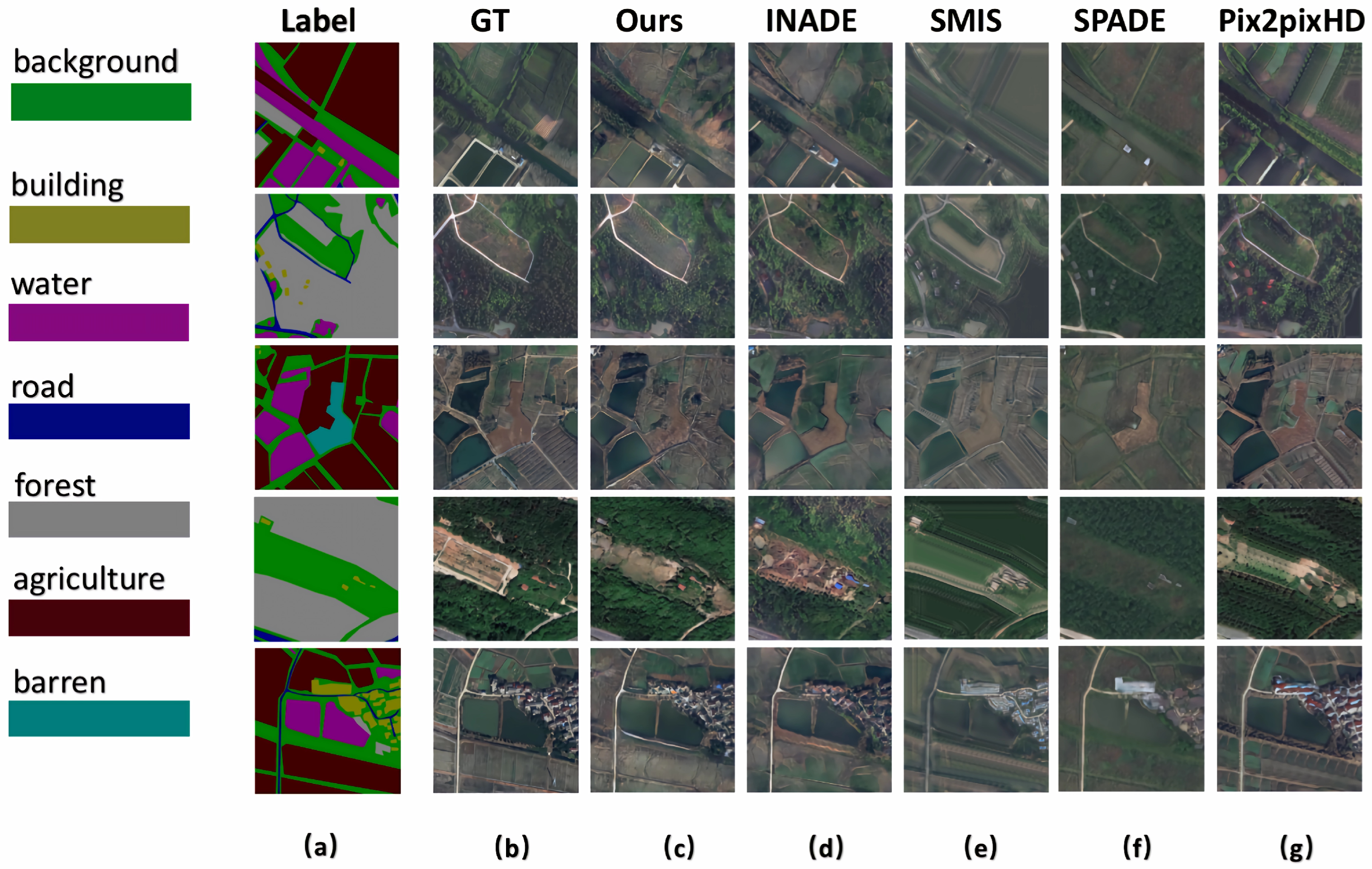
- LoveDA [37]: A remote sensing image dataset that focuses on different geographical environments, including urban and rural areas. We train the models with seven semantic classes, including background, building, road, water, barren, forest, and agriculture.
- Gaofen-2 (GID-15) [41]: A satellite image dataset that consists of 15 semantic classes with low resolution, non-uniform hue, and unstable picture quality.
4.2. Results and Comparison
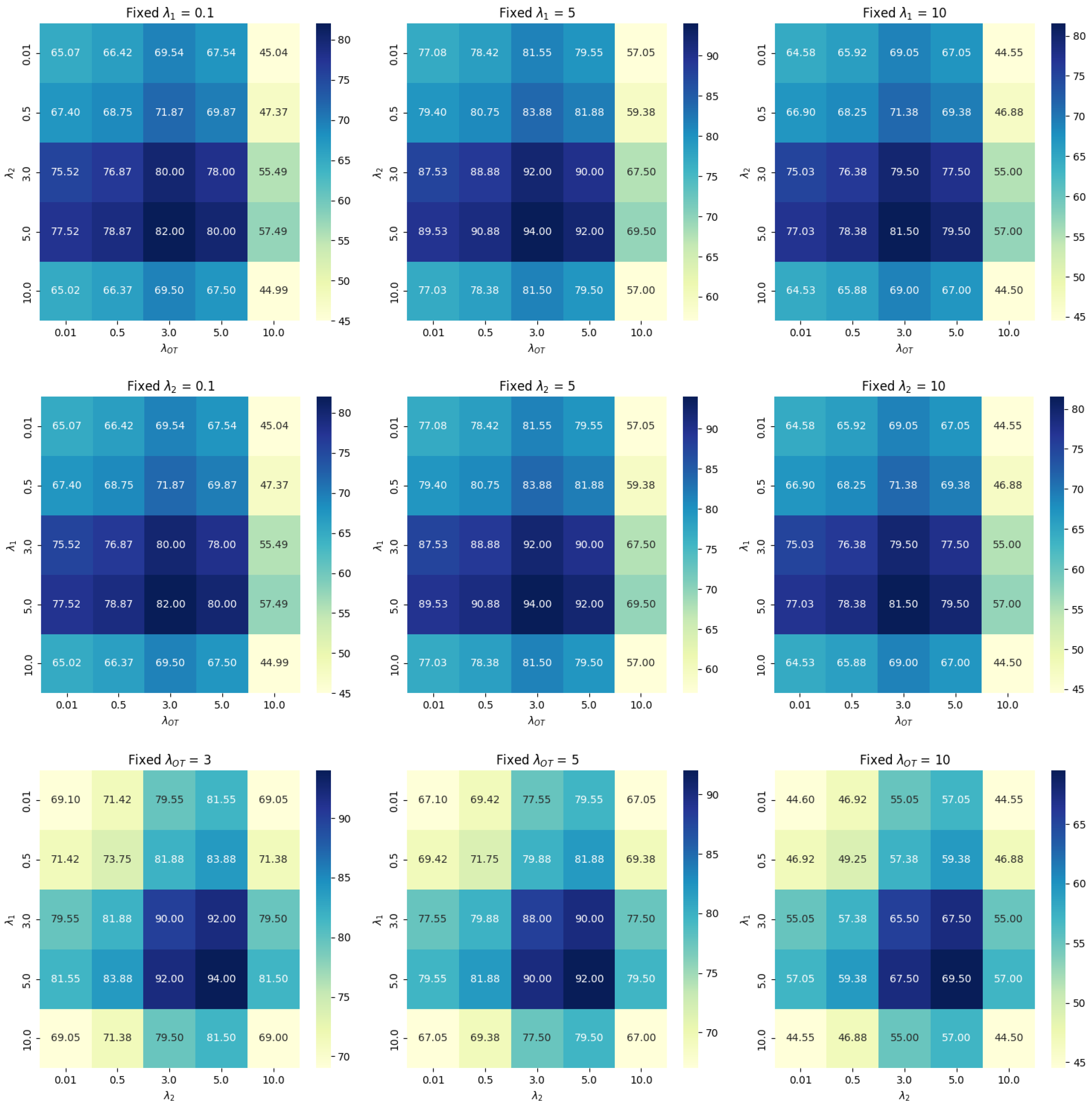
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, B.; Zhang, S.; Xu, C.; Sun, Y.; Deng, C. Deep fake geography? When geospatial data encounter Artificial Intelligence. Cartogr. Geogr. Inf. Sci. 2021, 48, 338–352. [Google Scholar] [CrossRef]
- Bredemeyer, S.; Ulmer, F.G.; Hansteen, T.H.; Walter, T.R. Radar path delay effects in volcanic gas plumes: The case of Láscar Volcano, Northern Chile. Remote Sens. 2018, 10, 1514. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A superpixelwise PCA approach for unsupervised feature extraction of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef]
- Li, C.; Ma, Y.; Mei, X.; Liu, C.; Ma, J. Hyperspectral unmixing with robust collaborative sparse regression. Remote Sens. 2016, 8, 588. [Google Scholar] [CrossRef]
- Available online: https://www.nvidia.com/en-us/research/ai-playground/ (accessed on 3 February 2025).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhu, P.; Abdal, R.; Qin, Y.; Wonka, P. Sean: Image synthesis with semantic region-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5104–5113. [Google Scholar]
- Khanna, S.; Liu, P.; Zhou, L.; Meng, C.; Rombach, R.; Burke, M.; Lobell, D.; Ermon, S. DiffusionSat: A Generative Foundation Model for Satellite Imagery. arXiv 2023, arXiv:2312.03606. [Google Scholar]
- Tang, D.; Cao, X.; Hou, X.; Jiang, Z.; Liu, J.; Meng, D. Crs-diff: Controllable remote sensing image generation with diffusion model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5638714. [Google Scholar] [CrossRef]
- Sastry, S.; Khanal, S.; Dhakal, A.; Jacobs, N. GeoSynth: Contextually-Aware High-Resolution Satellite Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 460–470. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Neural Networks for Image Processing. arXiv 2015, arXiv:1511.08861. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Bissoto, A.; Perez, F.; Valle, E.; Avila, S. Skin lesion synthesis with generative adversarial networks. In Proceedings of the OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis: First International Workshop, OR 2.0 2018, 5th International Workshop, CARE 2018, 7th International Workshop, CLIP 2018, Third International Workshop, ISIC 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16–20 September 2018; Proceedings 5. Springer: Berlin/Heidelberg, Germany, 2018; pp. 294–302. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Wu, J.; Huang, Z.; Thoma, J.; Acharya, D.; Van Gool, L. Wasserstein divergence for gans. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 653–668. [Google Scholar]
- Liu, H.; Gu, X.; Samaras, D. Wasserstein GAN with quadratic transport cost. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4832–4841. [Google Scholar]
- An, D.; Guo, Y.; Lei, N.; Luo, Z.; Yau, S.T.; Gu, X. AE-OT: A new generative model based on extended semi-discrete optimal transport. ICLR 2020 2019, 1–19. Available online: https://par.nsf.gov/biblio/10185286 (accessed on 3 February 2025).
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; Mcdonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Gu, X.; Luo, F.; Sun, J.; Yau, S.T. Variational Principles for Minkowski Type Problems, Discrete Optimal Transport, and Discrete Monge-Ampere Equations. arXiv 2013, arXiv:1302.5472. [Google Scholar] [CrossRef]
- Brenier, Y. Polar factorization and monotone rearrangement of vector-valued functions. Commun. Pure Appl. Math. 1991, 44, 375–417. [Google Scholar] [CrossRef]
- Available online: https://www.satimagingcorp.com/satellite-sensors/gaofen-2/ (accessed on 3 February 2025).
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying MMD GANs. arXiv 2018, arXiv:1801.01401. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhu, Z.; Xu, Z.; You, A.; Bai, X. Semantically multi-modal image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5467–5476. [Google Scholar]
- Tan, Z.; Chai, M.; Chen, D.; Liao, J.; Chu, Q.; Liu, B.; Hua, G.; Yu, N. Diverse semantic image synthesis via probability distribution modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7962–7971. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Ours | INADE | SMIS | SPADE | PixPixHD |
|---|---|---|---|---|---|
| ISC | 4.7683 | 4.76 | 4.768 | 4.7683 | 4.768 |
| KID | 0.0316 | 0.04983 | 0.0436 | 0.05867 | 0.03796 |
| FID | 73.53 | 95.46 | 82.10 | 107.338 | 87.27 |
| Dataset | Ours | INADE | SMIS | SPADE | PixPixHD |
|---|---|---|---|---|---|
| ISC | 6.993 | 6.993 | 6.993 | 6.997 | 7.093 |
| KID | 0.04678 | 0.05098 | 0.0530 | 0.05201 | 0.04980 |
| FID | 170.79 | 169.43 | 261.83 | 210.42 | 199.86 |
| Dataset | Ours | INADE | SMIS | SPADE | PixPixHD |
|---|---|---|---|---|---|
| LoveDA | 73.53 | 63.08 | 45.9 | 69.98 | 47.0 |
| GID-15 | 80.0 | 75.5 | 53.76 | 67.07 | 39.86 |
| Dataset | Ours | INADE | SPADE | Ours-2 |
|---|---|---|---|---|
| LoveDA | 159.33 | 167.05 | 191.27 | 198.24 |
| GID-15 | 170.79 | 169.43 | 210.42 | 225.67 |
| Training Accuracy (%) | Validation Accuracy (%) | Testing Accuracy (%) | |||
|---|---|---|---|---|---|
| 0.01 | 0.01 | 0.01 | 85.0 | 83.0 | 82.5 |
| 0.01 | 0.01 | 1 | 86.5 | 84.5 | 84.0 |
| 0.01 | 0.01 | 5 | 87.0 | 85.0 | 84.5 |
| 0.5 | 0.5 | 0.5 | 87.5 | 85.5 | 85.0 |
| 0.5 | 0.5 | 3 | 88.5 | 86.5 | 86.0 |
| 1 | 1 | 1 | 89.0 | 87.0 | 86.5 |
| 1 | 1 | 5 | 90.0 | 88.0 | 87.5 |
| 3 | 3 | 3 | 92.5 | 90.0 | 89.5 |
| 5 | 5 | 3 | 94.0 | 91.5 | 91.0 |
| 3 | 3 | 10 | 93.0 | 90.5 | 90.0 |
| 10 | 10 | 10 | 88.0 | 86.0 | 85.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Yuan, X.; Kou, Y.; Zhang, Y. A Novel Framework for Remote Sensing Image Synthesis with Optimal Transport. Sensors 2025, 25, 1792. https://doi.org/10.3390/s25061792
He J, Yuan X, Kou Y, Zhang Y. A Novel Framework for Remote Sensing Image Synthesis with Optimal Transport. Sensors. 2025; 25(6):1792. https://doi.org/10.3390/s25061792
Chicago/Turabian StyleHe, Jinlong, Xia Yuan, Yong Kou, and Yanci Zhang. 2025. "A Novel Framework for Remote Sensing Image Synthesis with Optimal Transport" Sensors 25, no. 6: 1792. https://doi.org/10.3390/s25061792
APA StyleHe, J., Yuan, X., Kou, Y., & Zhang, Y. (2025). A Novel Framework for Remote Sensing Image Synthesis with Optimal Transport. Sensors, 25(6), 1792. https://doi.org/10.3390/s25061792