
Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning


Abstract
1. Introduction
2. Approach
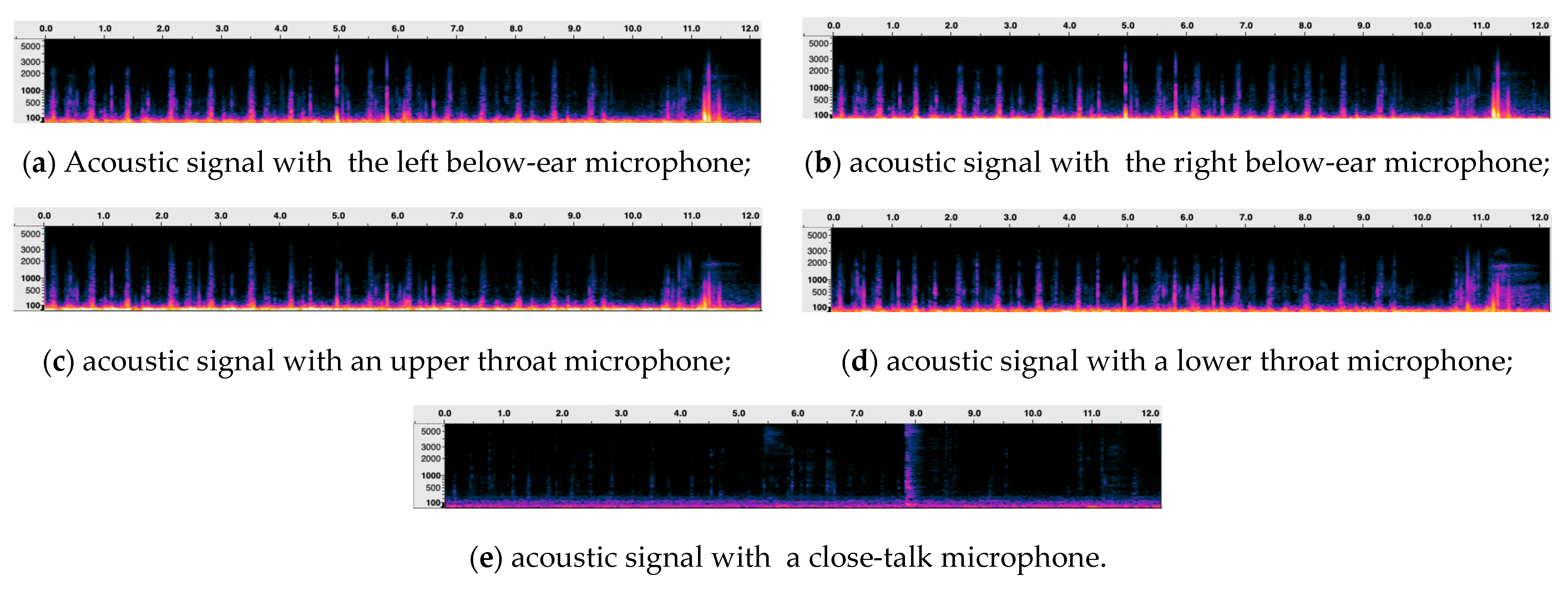
2.1. Skin-Contact Microphones
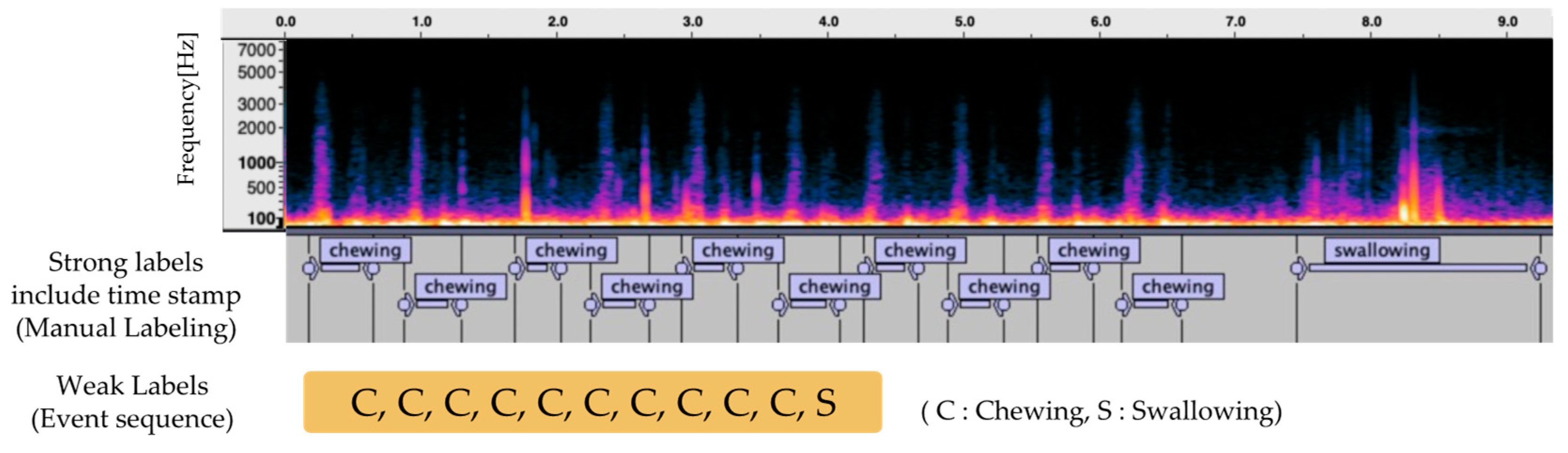
2.2. Annotation of Eating Behavior Sound Data
2.3. Proposed Method
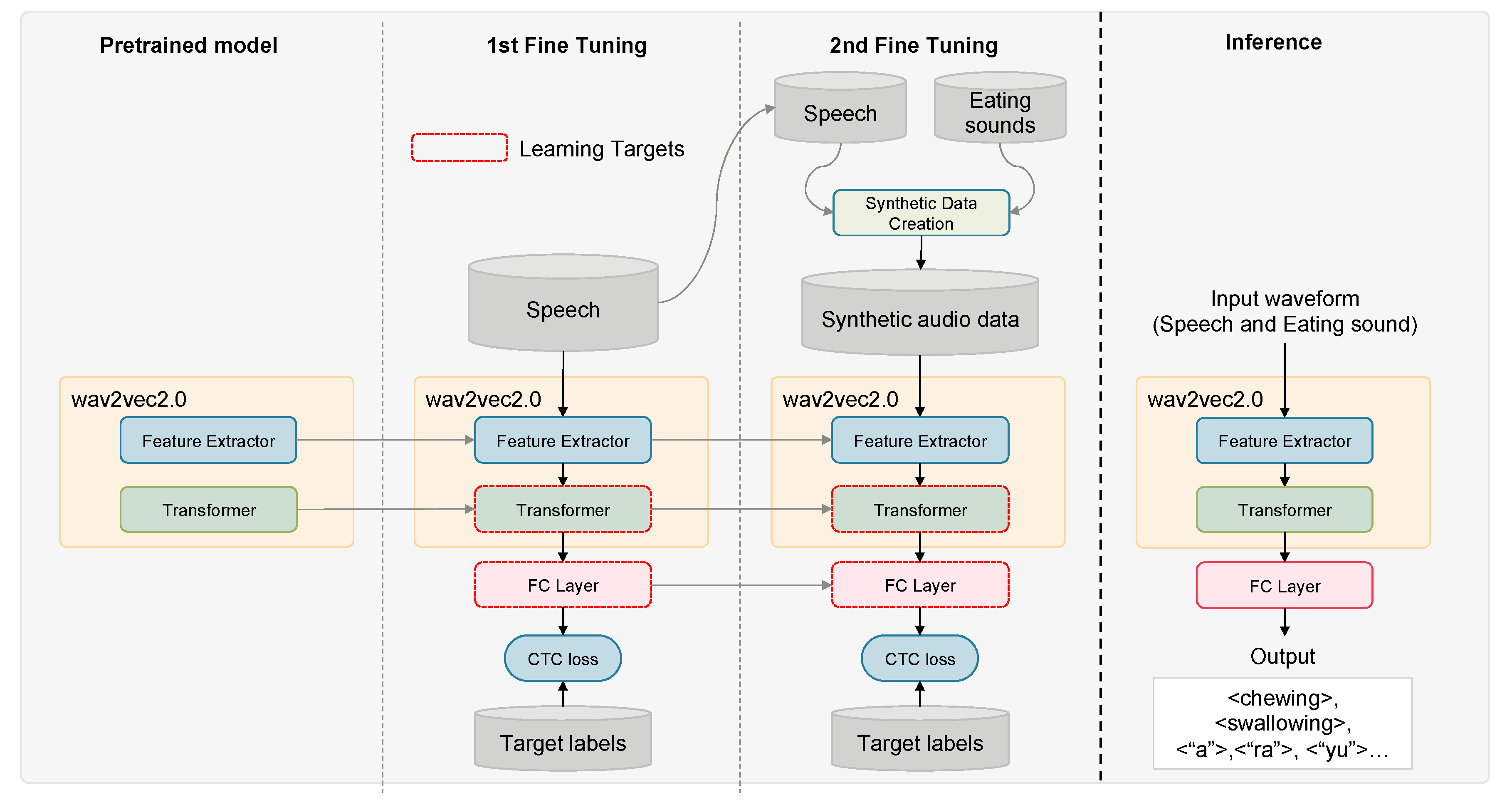
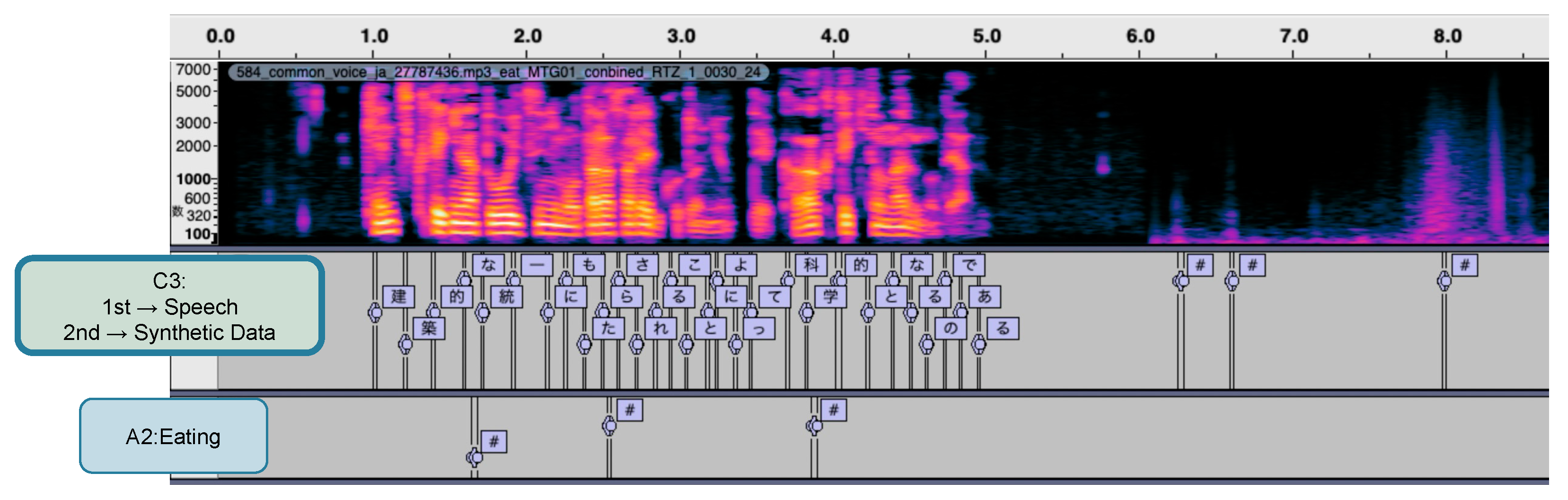
2.3.1. Two-Stage Fine-Tuning for Efficient Model Adaptation
2.3.2. Data Augmentation Using Synthetic Speech and Eating Behavior Data
- For audio clips lasting between 7 and 10 s, white noise was appended to both ends, normalizing their duration to a fixed length of 10 s. This preprocessing step ensured a consistent input length for the model.
- For audio clips shorter than 7 s, two clips were concatenated to create new data. The domain of the concatenated audio (speech or eating behavior) was carefully determined to maintain a balanced ratio of speech and eating sounds within the dataset. To fill any remaining duration, additional audio was randomly selected. White noise was then added before, between, and after the clips to ensure uniformity in the dataset.
2.3.3. Model Architecture
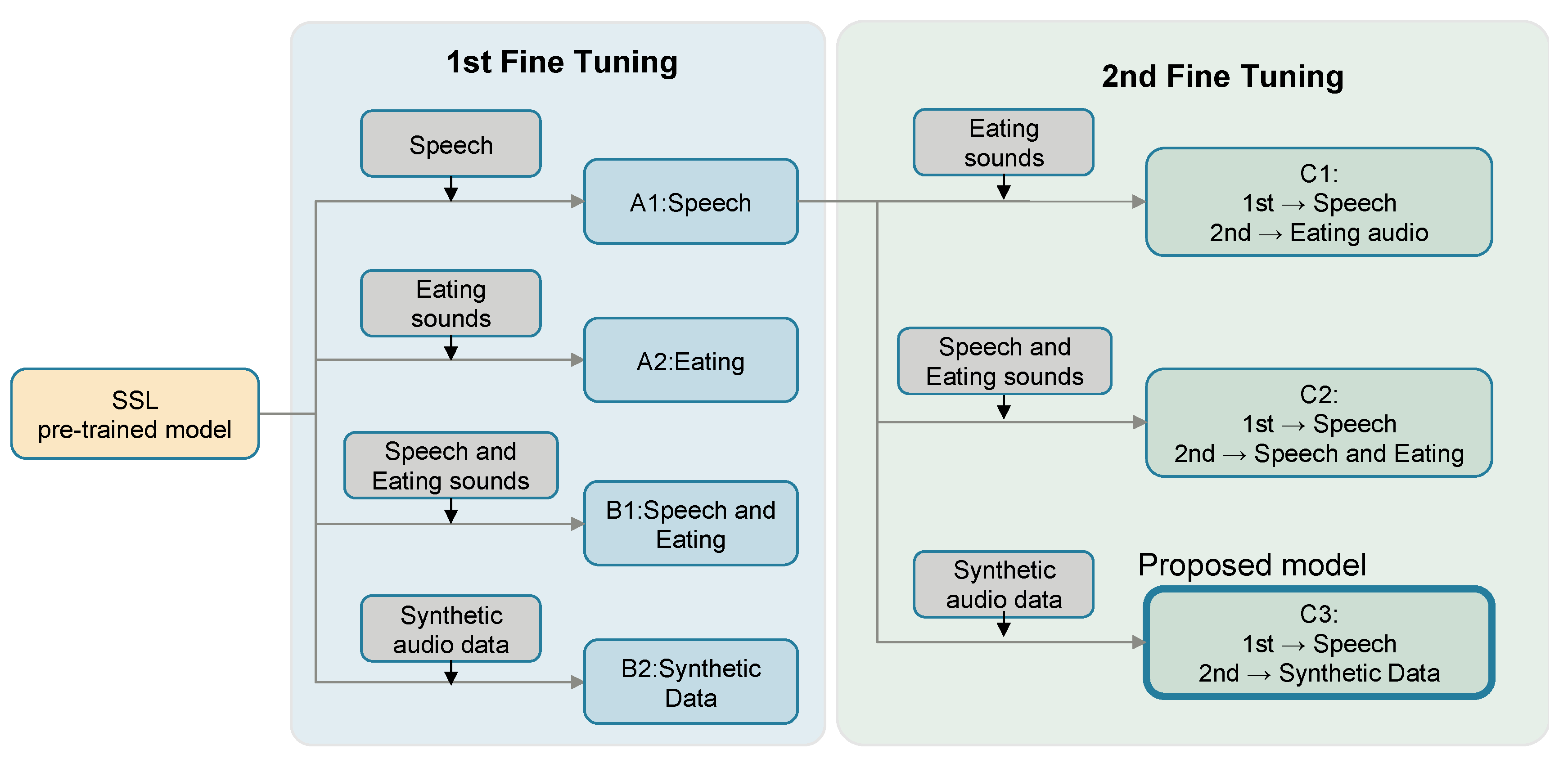
2.4. Comparative Methods
3. Experiments
3.1. Training Datasets—Speech
- Speed modulation [29]: The sampling rate of the original waveform is adjusted to alter the speed without distorting the pitch.
- Time-domain dropout [30]: This method replaces random time intervals in the waveform with zeros.
- Frequency-domain dropout [31]: This masks specific frequency bands in the audio signal.
3.2. Training Datasets—Eating Behavior Sounds
3.3. Training Datasets—Generation of Synthetic Data
3.4. Test Dataset
3.5. Evaluation Metrics
3.6. Model Training Configuration
4. Results
4.1. Baseline Model Performance Evaluation
4.2. Evaluation of Single-Stage Fine-Tuning
4.3. Evaluation of the Two-Stage Fine-Tuning
5. Discussion
5.1. Effect of Synthetic Data Use
5.2. Effect of Two-Stage Fine-Tuning
5.3. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fukuda, H.; Saito, T.; Mizuta, M.; Moromugi, S.; Ishimatsu, T.; Nishikado, S.; Takagi, H.; Konomi, Y. Chewing number is related to incremental increases in body weight from 20 years of age in Japanese middle-aged adults. Gerodontology 2013, 30, 214–219. [Google Scholar] [CrossRef] [PubMed]
- Otsuka, R.; Tamakoshi, K.; Yatsuya, H.; Murata, C.; Sekiya, A.; Wada, K.; Zhang, H.; Matsushita, K.; Sugiura, K.; Takefuji, S.; et al. Eating fast leads to obesity: Findings based on self-administered questionnaires among middle-aged Japanese men and women. J. Epidemiol. 2006, 16, 117–124. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Yang, K.; Huang, F.; Liu, X.; Li, X.; Luo, Y.; Wu, L.; Guo, X. Association between self-reported eating speed and metabolic syndrome in a Beijing adult population: A cross-sectional study. BMC Public Health 2018, 18, 855. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, H.; Fukushima, M.; Okamoto, S.; Takahashi, O.; Shimbo, T.; Kurose, T.; Yamada, Y.; Inagaki, N.; Seino, Y.; Fukui, T. Effects of thorough mastication on postprandial plasma glucose concentrations in nonobese Japanese subjects. Metabolism 2005, 54, 1593–1599. [Google Scholar] [CrossRef] [PubMed]
- Horiguchi, S.; Suzuki, Y. Screening tests in evaluating swallowing function. JMA J. 2011, 54, 31–34. [Google Scholar]
- Curtis, J.A.; Borders, J.C.; Perry, S.E.; Dakin, A.E.; Seikaly, Z.N.; Troche, M.S. Visual analysis of swallowing efficiency and safety (vases): A standardized approach to rating pharyngeal residue, penetration, and aspiration during FEES. Dysphagia 2022, 37, 417–435. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.T.; Cohen, E.; Pourhomayoun, M.; Alshurafa, N. SwallowNet: Recurrent neural network detects and characterizes eating patterns. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 401–406. [Google Scholar] [CrossRef]
- Nakamura, A.; Saito, T.; Ikeda, D.; Ohta, K.; Mineno, H.; Nishimura, M. Automatic detection of chewing and swallowing. Sensors 2021, 21, 3378. [Google Scholar] [CrossRef] [PubMed]
- Papapanagiotou, V.; Diou, C.; Delopoulos, A. Self-supervised feature learning of 1D convolutional neural networks with contrastive loss for eating detection using an in-ear microphone. In Proceedings of the 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual Conference, 1–5 November 2021; pp. 7186–7189. [Google Scholar] [CrossRef]
- Dupont, S.; Ris, C.; Bachelart, D. Combined use of close-talk and throat microphones for improved speech recognition under non-stationary background noise. In Proceedings of the COST278 and ISCA Tutorial and Research Workshop (ITRW) on Robustness Issues in Conversational Interaction, Norwich, UK, 30–31 August 2004. [Google Scholar]
- Heracleous, P.; Even, J.; Ishi, C.T.; Miyashita, T.; Hagita, N. Fusion of standard and alternative acoustic sensors for robust automatic speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4837–4840. [Google Scholar] [CrossRef]
- Ilias, L.; Askounis, D. Explainable identification of dementia from transcripts using transformer networks. IEEE J. Biomed. Health Inform. 2022, 26, 4153–4164. [Google Scholar] [CrossRef] [PubMed]
- Lam, G.; Huang, D.; Lin, W. Context-aware deep learning for multi-modal depression detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3946–3950. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 12449–12460. [Google Scholar] [CrossRef]
- Hsu, W.-N.; Bolte, B.; Tsai, Y.-H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Soky, K.; Li, S.; Chu, C.; Kawahara, T. Domain and language adaptation using heterogeneous datasets for wav2vec2.0-based speech recognition of low-resource language. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Gao, Y.; Chu, C.; Kawahara, T. Two-stage finetuning of wav2vec 2.0 for speech emotion recognition with ASR and gender pretraining. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Dublin, Ireland, 20–24 August 2023; pp. 3637–3641. [Google Scholar]
- Cai, X.; Yuan, J.; Zheng, R.; Huang, L.; Church, K. Speech emotion recognition with multi-task learning. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Brno, Czech Republic, 30 August–3 September 2021; pp. 4508–4512. [Google Scholar] [CrossRef]
- Kunešová, M.; Zajíc, Z. Multitask detection of speaker changes, overlapping speech and voice activity using wav2vec 2.0. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, C.; Woodland, P.C. Tandem multitask training of speaker diarisation and speech recognition for meeting transcription. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Incheon, Republic of Korea, 18–22 September 2022; pp. 1–5. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar] [CrossRef]
- Wang, Y.; Metze, F. A first attempt at polyphonic sound event detection using connectionist temporal classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2986–2990. [Google Scholar] [CrossRef]
- Tsukagoshi, K.; Koiwai, K.; Nishida, M.; Nishimura, M. SSL-based chewing and swallowing detection using multiple skin-contact microphones. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC 2024), Macau, China, 3–6 December 2024; Available online: http://www.apsipa2024.org/files/papers/424.pdf (accessed on 27 December 2024).
- Tsukagoshi, K.; Koiwai, K.; Nishida, M.; Nishimura, M. Simultaneous speech and eating behavior recognition using multitask learning. In Proceedings of the IEEE 13th Global Conference on Consumer Electronics (GCCE), Kitakyushu, Japan, 29 October–1 November 2024; Available online: https://ieeexplore.ieee.org/document/10760452 (accessed on 27 December 2024).
- Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; et al. SpeechBrain: A general-purpose speech toolkit. arXiv 2021, arXiv:2106.04624. Available online: https://arxiv.org/pdf/2106.04624 (accessed on 27 December 2024).
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020), Marseille, France, 11–16 May 2020; pp. 4218–4222. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH 2015), Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Islam, M.; Glocker, B. Frequency dropout: Feature-level regularization via randomized filtering. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 281–295. [Google Scholar] [CrossRef]
- Itahashi, S.; Yamamoto, M.; Takezawa, T.; Kobayashi, T. Nihon Onkyo Gakkai Shinbun Kiji Yomiage Onsei Kōpasu no Kōchiku [Development of ASJ Japanese newspaper article sentences corpus]. In Proceedings of the Autumn Meeting of the Acoustical Society of Japan, Sapporo, Japan, 17–19 September 1997; pp. 187–188. (In Japanese). [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data | CER ↓ [%] | F1 Score ↑ | |||
|---|---|---|---|---|---|
| 1st Fine-Tuning | 2nd Fine-Tuning | Test: Speech | Event: Chewing (Allowance = 0.05 s) | Event: Swallowing (Allowance = 0.01 s) | |
| A1 | Speech (baseline) | - | 15.19 | - | - |
| A2 | Eating (baseline [25]) | - | - | 0.905 | 0.963 |
| B1 | Speech and Eating 2 | - | 17.13 | 0.769 | 0.961 |
| B2 | Synthetic Data 3 | - | 16.38 | 0.835 | 0.654 |
| C1 | Speech | Eating | 87.45 | 0.903 | 0.825 |
| C2 | Speech | Speech and Eating 2 | 16.22 | 0.243 | 0.514 |
| C3 1 | Speech | Synthetic Data 3 | 16.24 | 0.918 | 0.926 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsukagoshi, T.; Nishida, M.; Nishimura, M. Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning. Sensors 2025, 25, 1544. https://doi.org/10.3390/s25051544
Tsukagoshi T, Nishida M, Nishimura M. Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning. Sensors. 2025; 25(5):1544. https://doi.org/10.3390/s25051544
Chicago/Turabian StyleTsukagoshi, Toshihiro, Masafumi Nishida, and Masafumi Nishimura. 2025. "Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning" Sensors 25, no. 5: 1544. https://doi.org/10.3390/s25051544
APA StyleTsukagoshi, T., Nishida, M., & Nishimura, M. (2025). Simultaneous Speech and Eating Behavior Recognition Using Data Augmentation and Two-Stage Fine-Tuning. Sensors, 25(5), 1544. https://doi.org/10.3390/s25051544