


Cross-Modal Collaboration and Robust Feature Classifier for Open-Vocabulary 3D Object Detection


Abstract
1. Introduction
- We propose a unified open-vocabulary 3D detector contains Cross-modal Collaboration and Robust Feature Classifier. It takes advantage of the benefits of multi-sensors and excels in detecting objects of any class across diverse scenes, thus greatly enhancing the perception of real scenes in 3D vision.
- The Cross-modal Collaboration use the synergy of camera and LiDAR to pinpoint novel objects. This collaboration mechanism is superior compared with other multimodal fusions. The Robust Feature Classifier learns robust features for more accurate object classification.
- Comprehensive experiments on three datasets, including SUN RGB-D, nuScenes and KITTI, demonstrate the effectiveness of the proposed approach. Notably, our method achieves comparable performance to state-of-the-art approaches whether it is an indoor or outdoor scene.
2. Related Work
2.1. 3D Object Detection
2.2. Open-Vocabulary 2D Object Detection
2.3. Open-Vocabulary 3D Object Detection
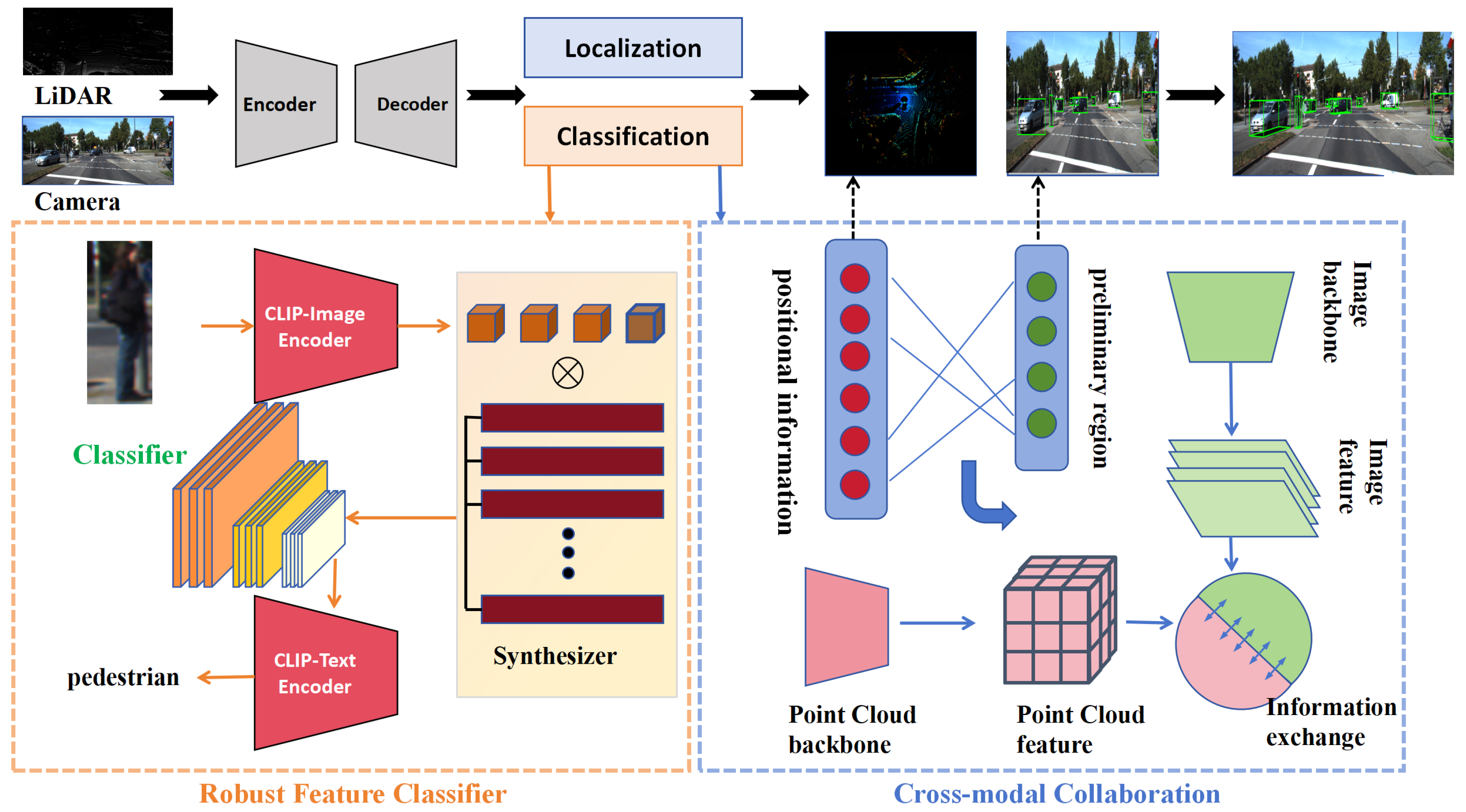
3. Methods
3.1. Framework Overview
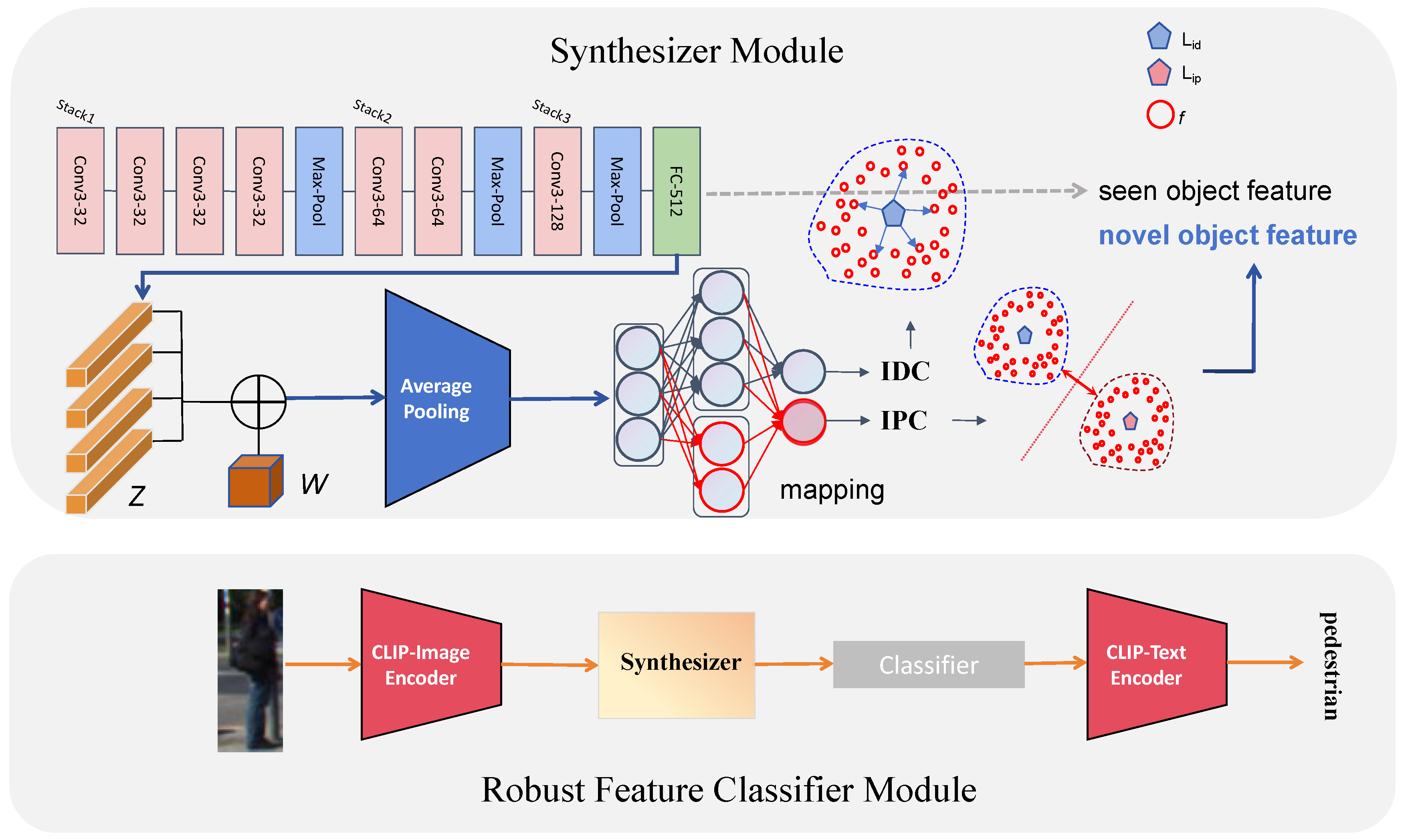
3.2. Robust Feature Classifier
3.3. Cross-Modal Collaboration
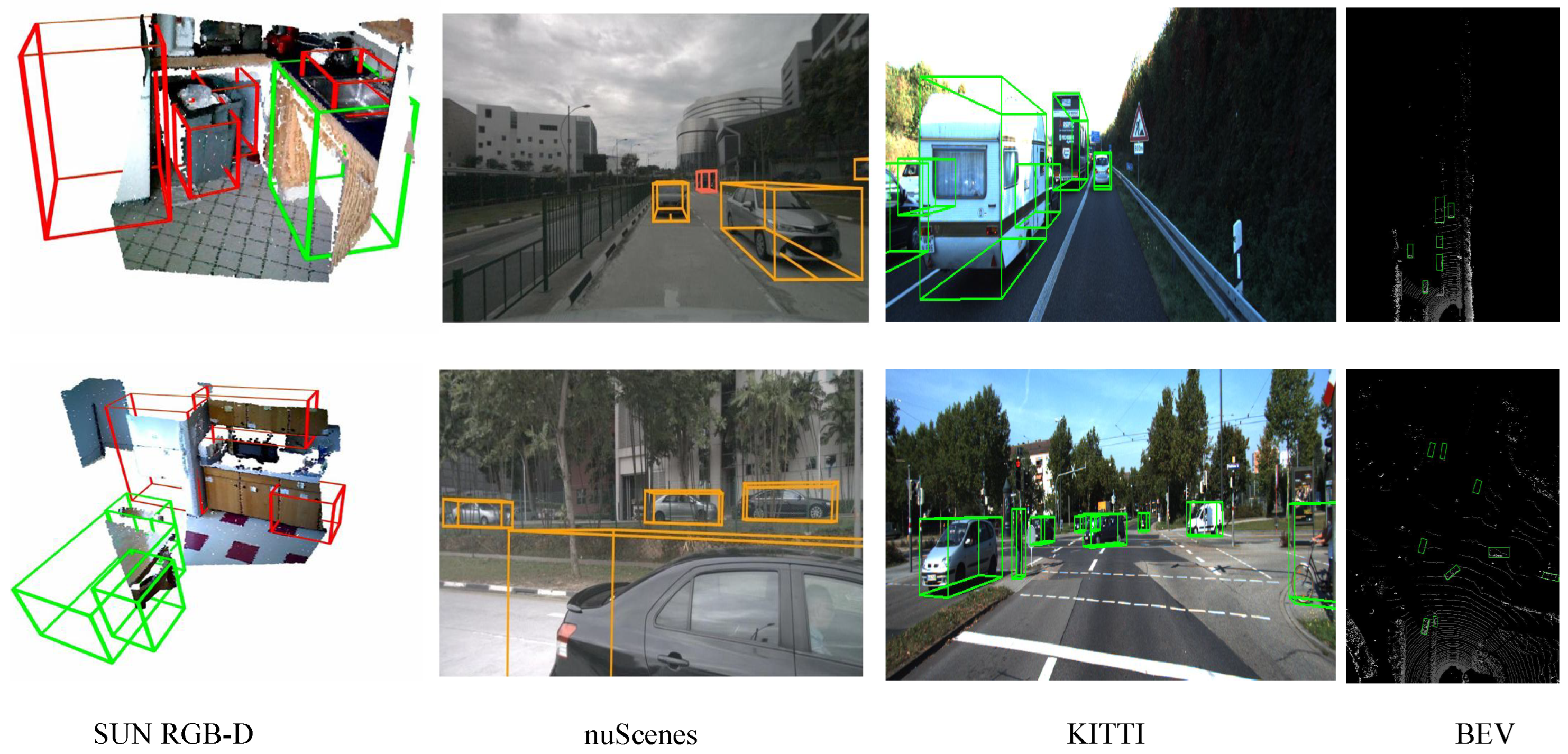
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Main Results
4.4. Ablation Study
4.5. Computational Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, P.; Han, J.; Cheng, D.; Zhang, D. Robust region feature synthesizer for zero-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 7622–7631. [Google Scholar]
- Wang, Z.; Li, Y.; Liu, T.; Zhao, H.; Wang, S. OV-Uni3DETR: Towards unified open-vocabulary 3D object detection via cycle-modality propagation. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 73–89. [Google Scholar]
- Park, G.; Koh, J.; Kim, J.; Moon, J.; Choi, J.W. LiDAR-Based 3D Temporal Object Detection via Motion-Aware LiDAR Feature Fusion. Sensors 2024, 24, 4667. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Jia, Y.; Lyu, Y.; Dong, Q.; Yang, Y. BAFusion: Bidirectional Attention Fusion for 3D Object Detection Based on LiDAR and Camera. Sensors 2024, 24, 4718. [Google Scholar] [CrossRef] [PubMed]
- McIntyre, D. Bridging the gap between research and practice. Camb. J. Educ. 2005, 35, 357–382. [Google Scholar] [CrossRef]
- Cao, Y.; Yihan, Z.; Xu, H.; Xu, D. Coda: Collaborative novel box discovery and cross-modal alignment for open-vocabulary 3d object detection. Adv. Neural Inf. Process. Syst. 2024, 36, 1–12. [Google Scholar]
- Brazil, G.; Kumar, A.; Straub, J.; Ravi, N.; Johnson, J.; Gkioxari, G. Omni3d: A large benchmark and model for 3d object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13154–13164. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2020; pp. 11621–11631. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Contributors, M. MMDetection3D: OpenMMLab Next-Generation Platform for General 3D Object Detection. San Francisco (CA): GitHub. 2020. Available online: https://github.com/open-mmlab/mmdetection (accessed on 16 May 2023).
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Du, Y.; Wei, F.; Zhang, Z.; Shi, M.; Gao, Y.; Li, G. Learning to prompt for open-vocabulary object detection with vision-language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 14084–14093. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Gu, X.; Lin, T.Y.; Kuo, W.; Cui, Y. Open-vocabulary object detection via vision and language knowledge distillation. arXiv 2021, arXiv:2104.13921. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5356–5364. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1090–1099. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Bin, Z.; Zhang, L. Fusionpainting: Multimodal fusion with adaptive attention for 3d object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Liu, H.; Duan, T. Real-Time Multimodal 3D Object Detection with Transformers. World Electr. Veh. J. 2024, 15, 307. [Google Scholar] [CrossRef]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 10965–10975. [Google Scholar]
- Li, Y.; Chen, Y.; Qi, X.; Li, Z.; Sun, J.; Jia, J. Unifying voxel-based representation with transformer for 3d object detection. Adv. Neural Inf. Process. Syst. 2022, 35, 18442–18455. [Google Scholar]
- Zhang, R.; Guo, Z.; Zhang, W.; Li, K.; Miao, X.; Cui, B.; Qiao, Y.; Gao, P.; Li, H. Pointclip: Point cloud understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8552–8562. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lu, Y.; Xu, C.; Wei, X.; Xie, X.; Tomizuka, M.; Keutzer, K.; Zhang, S. Open-vocabulary point-cloud object detection without 3d annotation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 18–22 June 2023; pp. 1190–1199. [Google Scholar]
- Kim, D.; Lin, T.Y.; Angelova, A.; Kweon, I.S.; Kuo, W. Learning open-world object proposals without learning to classify. IEEE Robot. Autom. Lett. 2022, 7, 5453–5460. [Google Scholar] [CrossRef]
- Zhu, P.; Wang, H.; Saligrama, V. Don’t even look once: Synthesizing features for zero-shot detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 11693–11702. [Google Scholar]
- Zhu, X.; Zhang, R.; He, B.; Guo, Z.; Zeng, Z.; Qin, Z.; Zhang, S.; Gao, P. Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2639–2650. [Google Scholar]
- Zheng, Y.; Huang, R.; Han, C.; Huang, X.; Cui, L. Background learnable cascade for zero-shot object detection. In Proceedings of the Asian Conference on Computer Vision, Virtual, 30 November–4 December 2020. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 1–18. [Google Scholar]
- Song, Z.; Liu, L.; Jia, F.; Luo, Y.; Jia, C.; Zhang, G.; Yang, L.; Wang, L. Robustness-aware 3d object detection in autonomous driving: A review and outlook. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15407–15436. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Gurbuz, A.C.; Ball, J.E. Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection. World Electr. Veh. J. 2024, 15, 20. [Google Scholar] [CrossRef]
- Hao, M.; Zhang, Z.; Li, L.; Dong, K.; Cheng, L.; Tiwari, P.; Ning, X. Coarse to fine-based image–point cloud fusion network for 3D object detection. Inf. Fusion 2024, 112, 102551. [Google Scholar] [CrossRef]
- Zeng, Y.; Jiang, C.; Mao, J.; Han, J.; Ye, C.; Huang, Q.; Yeung, D.Y.; Yang, Z.; Liang, X.; Xu, H. CLIP2: Contrastive language-image-point pretraining from real-world point cloud data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 15244–15253. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 720–736. [Google Scholar]
- Chen, Y.; Li, Y.; Zhang, X.; Sun, J.; Jia, J. Focal sparse convolutional networks for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5428–5437. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10386–10393. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Method | SUN RGB-D | ||
|---|---|---|---|---|
| (%) | (%) | (%) | ||
| LiDAR | PointCLIP [27] | 0.13 | 5.17 | 1.32 |
| PointCLIPv2 [32] | 0.21 | 4.72 | 1.28 | |
| Det-CLIP2 [38] | 1.07 | 23.57 | 6.02 | |
| OV-3DET [29] | 5.85 | 38.24 | 12.77 | |
| CoDA [6] | 7.05 | 41.23 | 14.96 | |
| LiDAR + RGB | 3D-CLIP [39] | 4.20 | 32.33 | 10.16 |
| Ours | 14.49 | 51.26 | 22.11 | |
| Modality | Method | KITTI | nuScenes | ||||
|---|---|---|---|---|---|---|---|
| (%) | (%) | (%) | (%) | (%) | (%) | ||
| LiDAR | PointCLIP | 0.20 | 8.56 | 3.11 | 0.37 | 8.79 | 5.19 |
| PointCLIPv2 | 0.43 | 9.50 | 5.75 | 0.59 | 9.06 | 5.25 | |
| Det-CLIP2 | 2.16 | 40.75 | 20.18 | 3.16 | 51.61 | 29.89 | |
| OV-3DET | 10.84 | 77.29 | 37.03 | 9.36 | 49.16 | 25.51 | |
| CoDA | 15.78 | 84.00 | 40.54 | 13.78 | 55.13 | 30.54 | |
| LiDAR + RGB | 3D-CLIP | 8.91 | 66.54 | 35.10 | 10.39 | 52.90 | 27.22 |
| Ours | 24.08 | 91.76 | 53.16 | 22.17 | 66.34 | 39.76 | |
| Class | Modality | Method | 3D AP(%) | BEV AP(%) | ||||
|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | |||
| Car | LiDAR | FPRCNN [13] | 74.79 | 68.26 | 60.17 | 80.09 | 76.16 | 70.37 |
| VRCNN [15] | 78.43 | 71.97 | 63.17 | 84.16 | 80.14 | 75.62 | ||
| PVRCNN [19] | 79.44 | 73.19 | 65.02 | 86.75 | 81.56 | 78.24 | ||
| LiDAR + RGB | 3dCVF [41] | 80.88 | 71.56 | 63.24 | 88.14 | 80.46 | 72.15 | |
| FConv [42] | 84.16 | 76.06 | 66.14 | 89.15 | 81.66 | 75.23 | ||
| Transfusion [18] | 86.25 | 78.91 | 70.83 | 90.15 | 82.23 | 75.80 | ||
| CLOCs [43] | 88.07 | 77.81 | 70.11 | 90.45 | 82.01 | 76.24 | ||
| Ours | 91.06 | 80.34 | 71.30 | 92.08 | 83.99 | 77.77 | ||
| Ped | LiDAR | FPRCNN | 42.76 | 35.49 | 30.79 | 50.14 | 45.26 | 38.19 |
| VRCNN | 46.45 | 40.71 | 35.19 | 51.60 | 46.97 | 42.07 | ||
| PVRCNN | 50.12 | 40.16 | 34.78 | 61.45 | 52.79 | 46.89 | ||
| LiDAR + RGB | 3dCVF | 53.44 | 46.06 | 39.99 | 65.47 | 60.72 | 53.71 | |
| FConv | 56.67 | 49.81 | 43.15 | 68.79 | 60.18 | 56.62 | ||
| Transfusion | 59.04 | 52.11 | 42.18 | 75.04 | 70.16 | 62.18 | ||
| CLOCs | 61.82 | 51.97 | 45.10 | 78.41 | 71.16 | 63.40 | ||
| Ours | 62.04 | 54.39 | 46.32 | 80.01 | 72.93 | 64.05 | ||
| Cyc | LiDAR | FPRCNN | 60.17 | 49.73 | 43.17 | 62.19 | 50.19 | 47.26 |
| VRCNN | 65.17 | 51.47 | 46.28 | 65.79 | 53.16 | 49.69 | ||
| PVRCNN | 68.03 | 51.79 | 49.23 | 70.25 | 61.33 | 55.74 | ||
| LiDAR + RGB | 3dCVF | 68.21 | 59.14 | 50.41 | 70.14 | 59.94 | 54.62 | |
| FConv | 73.52 | 61.11 | 55.49 | 75.05 | 64.50 | 60.75 | ||
| Transfusion | 76.10 | 62.26 | 57.27 | 76.98 | 65.22 | 60.64 | ||
| CLOCs | 78.82 | 64.31 | 59.33 | 78.90 | 69.22 | 63.64 | ||
| Ours | 80.09 | 65.37 | 60.95 | 80.17 | 70.06 | 64.25 | ||
| Modality | CC | RFC | KITTI | ||
|---|---|---|---|---|---|
| (%) | (%) | (%) | |||
| LiDAR + RGB | × | × | 8.19 | 66.54 | 35.10 |
| ✓ | × | 15.73 | 79.18 | 46.29 | |
| × | ✓ | 16.91 | 84.57 | 42.91 | |
| ✓ | ✓ | 24.08 | 91.76 | 53.16 | |
| PointCLIP | PointCLIPv2 | Det-CLIP2 | OV-3DET | CoDA | 3D-CLIP | Ours | |
|---|---|---|---|---|---|---|---|
| Modality | L | L | L | L | L | L + R | L + R |
| Times (ms) | 66 | 73 | 70 | 75 | 75 | 97 | 89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Duan, T. Cross-Modal Collaboration and Robust Feature Classifier for Open-Vocabulary 3D Object Detection. Sensors 2025, 25, 553. https://doi.org/10.3390/s25020553
Liu H, Duan T. Cross-Modal Collaboration and Robust Feature Classifier for Open-Vocabulary 3D Object Detection. Sensors. 2025; 25(2):553. https://doi.org/10.3390/s25020553
Chicago/Turabian StyleLiu, Hengsong, and Tongle Duan. 2025. "Cross-Modal Collaboration and Robust Feature Classifier for Open-Vocabulary 3D Object Detection" Sensors 25, no. 2: 553. https://doi.org/10.3390/s25020553
APA StyleLiu, H., & Duan, T. (2025). Cross-Modal Collaboration and Robust Feature Classifier for Open-Vocabulary 3D Object Detection. Sensors, 25(2), 553. https://doi.org/10.3390/s25020553