1. Introduction
Wi-Fi technology has advanced significantly, evolving from early standards to Wi-Fi 6 and the upcoming Wi-Fi 7, with enhanced data rates, coverage, and energy efficiency enabled by technologies like OFDMA and MU-MIMO. Beyond its traditional role in communication, Wi-Fi signals have emerged as a powerful tool for human activity recognition (HAR) [
1], leveraging channel state information (CSI) to capture subtle environmental changes caused by human movements, such as the phase shifts induced by limb motions [
2] or the amplitude variations from body pose changes [
3]. This contact-free paradigm offers unique advantages in cost, privacy, and seamless integration with existing wireless infrastructures, as it eliminates the need for dedicated sensors or user cooperation, positioning Wi-Fi-based HAR as a key enabler for smart homes, healthcare monitoring, and security systems [
2,
4,
5]. For instance, in smart elderly care, Wi-Fi systems can passively monitor daily activities, such as falls, without intrusive cameras, providing timely alerts to caregivers [
4].
While Wi-Fi sensing has enabled a wide range of human activity recognition (HAR) tasks, such as smoking detection [
6], fall detection [
4], gesture recognition [
2], tracking [
7], and keystroke recognition [
8], most existing systems are tailored to specific activities. This task-specific nature limits their flexibility in meeting evolving user demands. For example, a user may initially deploy a smoking detection system at home to support smoking cessation or fire prevention. However, when elderly family members visit or move in, the user might wish to additionally monitor fall incidents to ensure timely caregiver intervention. To accommodate this new need, current approaches typically require training and deploying a separate model specifically for fall detection. As user requirements increase, so does the number of models needed, leading to significant overhead in training, inference, and deployment. This scalability issue motivates the need for a more general and efficient solution—one that can support new activity types without continually expanding the number of models.
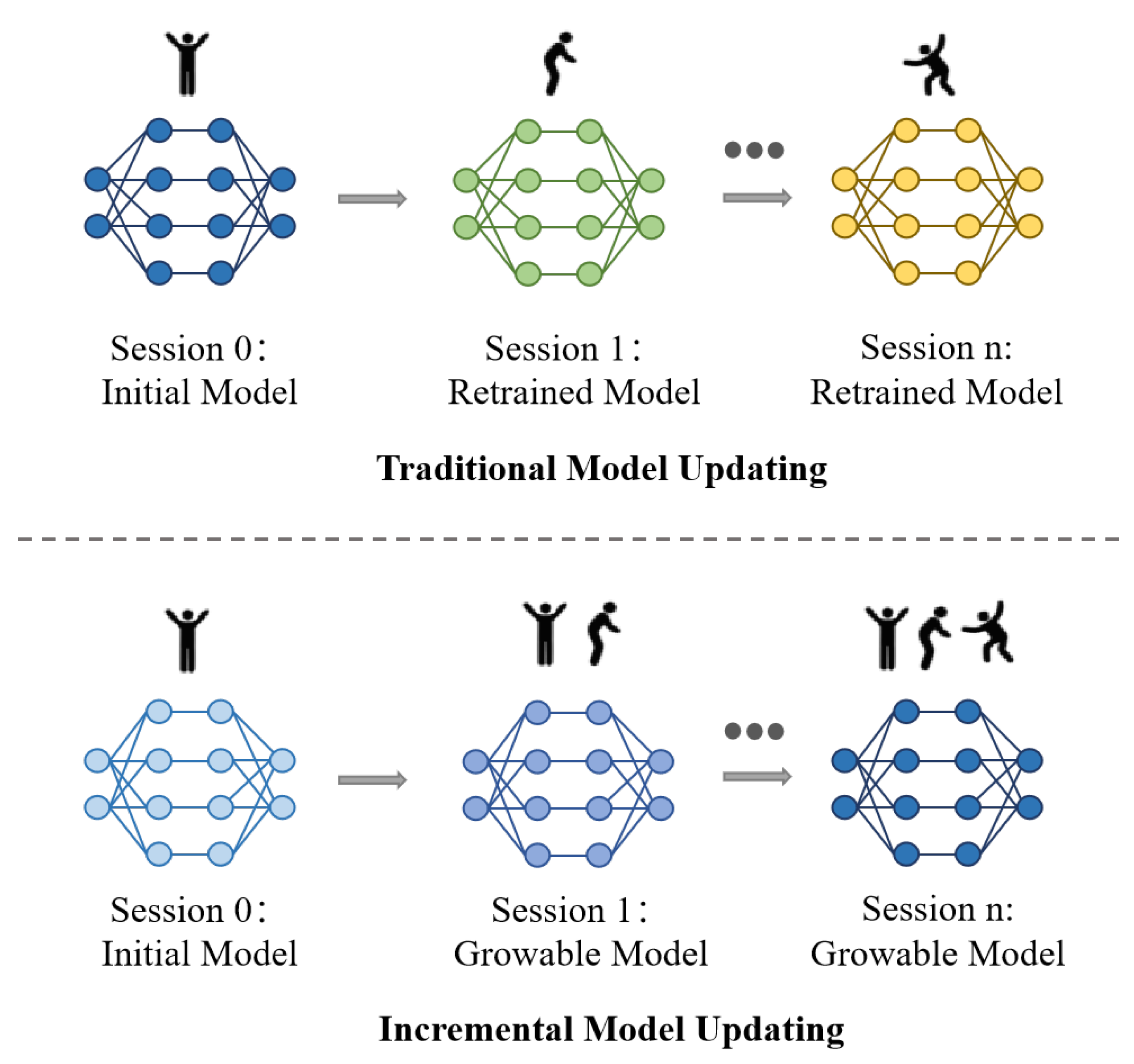
Alternatively, one may consider updating the existing model by training it with data from new activity classes, as shown in the top of
Figure 1, without increasing the number of deployed models. While this approach reduces inference and deployment costs, it suffers from severe catastrophic forgetting [
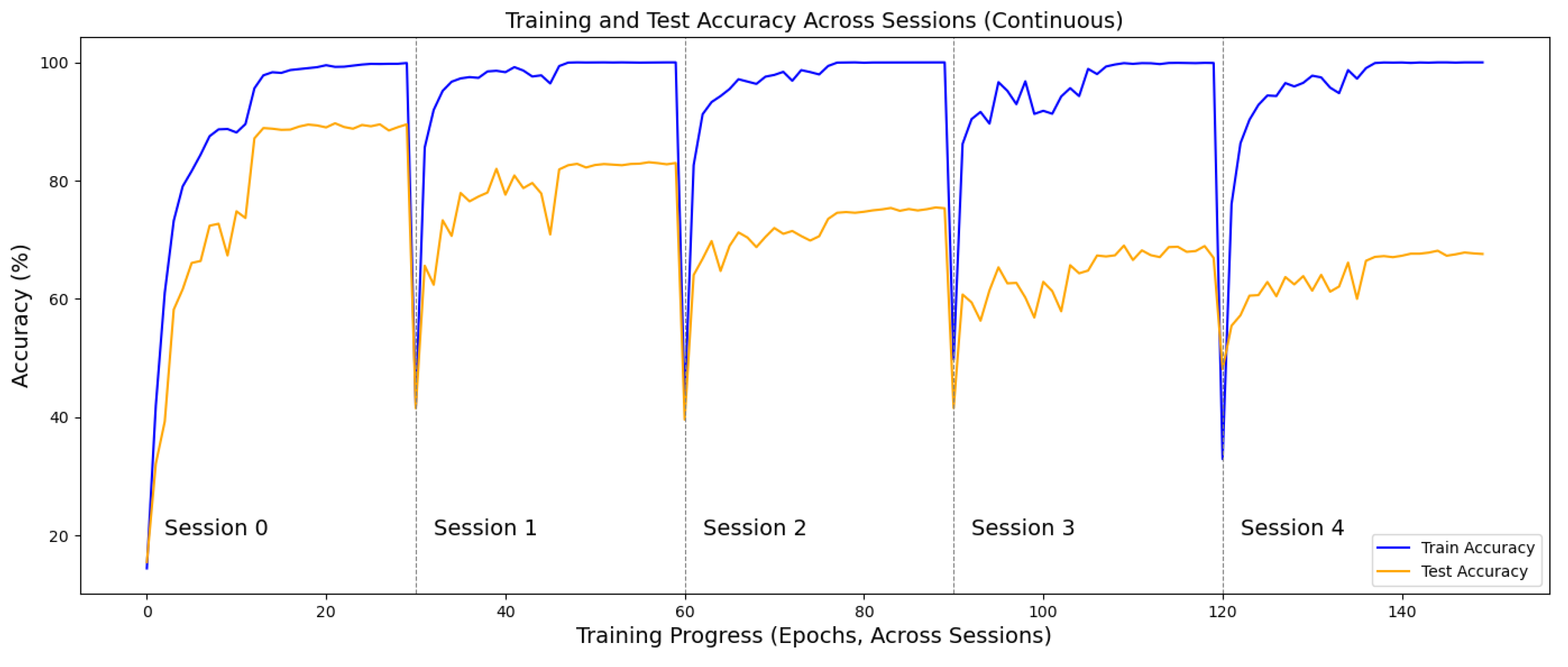
9]. That is, the model gradually loses the ability to recognize previously learned activities, retaining only the most recently trained ones. For example, as reported in CCS [
10], after five rounds of continual model updates, the recognition accuracy on previously seen classes dropped drastically—from an initial 95.07% to just 18.33% in a 55-class classification task, a decline of over 76 percentage points. In such cases, the system becomes practically unusable, as it can no longer reliably recognize earlier activities.
Several recent exploratory efforts, such as WiCAR [
11], WECAR [
12], and CCS [
10], have adopted class-incremental learning strategies to enable model updates for Wi-Fi-based human activity recognition without suffering from catastrophic forgetting, as shown in the bottom of
Figure 1. WiCAR introduces a class-incremental learning framework that takes antenna-array-fused image data as input and employs a customized backbone, Wi-RA, enhanced with parallel stacked activation functions. To mitigate forgetting, it combines replay-based training with knowledge distillation and weight alignment, thereby maintaining high recognition performance even after multiple incremental updates. WECAR further extends this idea into a practical end–edge collaborative architecture. By offloading model training and optimization to edge devices (e.g., Jetson Nano) and reserving inference for lightweight end devices (e.g., ESP32), WECAR ensures both continual learning and computational efficiency. It introduces task-specific dynamic model expansion, stability-aware retraining, and a dual-phase hierarchical distillation strategy, achieving strong accuracy while reducing parameter overhead. CCS, on the other hand, envisions a scalable user-facing sensing paradigm in which users can incrementally add new recognition capabilities (e.g., fall detection for elderly care) without uploading data to cloud servers. CCS addresses catastrophic forgetting through local knowledge distillation and weight alignment modules, and demonstrates its effectiveness across multiple wireless modalities, i.e., Wi-Fi, mmWave radar, and RFID. These works collectively highlight the promise of continual learning in wireless sensing; however, these methods either require growing model parameters or face performance degradation over time.
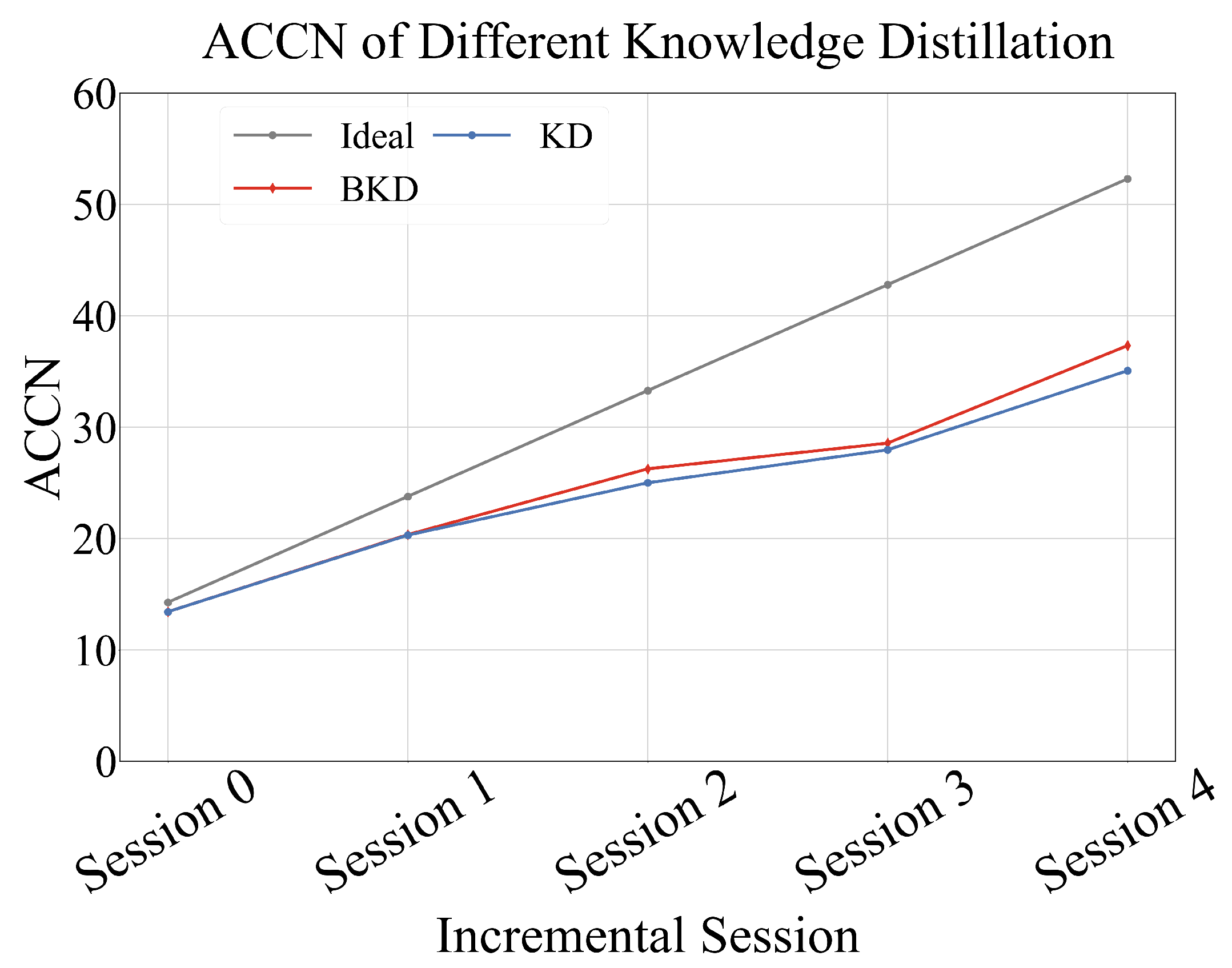
To address the challenges of maintaining performance and parameter efficiency in class-incremental learning, we propose CAREC. CAREC is designed to achieve high adaptability and accuracy in evolving environments by combining the strengths of model expansion and model compression. Specifically, when new activity categories are introduced, CAREC dynamically expands the network by adding a new backbone feature extractor initialized from the previous one. This design allows the model to quickly adapt to new categories while preserving knowledge of previously learned actions. A super-feature extractor aggregates representations from both old and new backbones, enabling rich and discriminative feature learning across tasks. However, continual expansion may lead to model bloat and inefficiency over time. To address this, CAREC introduces a compression phase that reduces the model’s complexity through balanced knowledge distillation. In this phase, a lightweight student model with a single backbone is trained to mimic the behavior of the expanded teacher network. To alleviate class imbalance caused by limited replayed samples, CAREC incorporates a reweighting scheme based on the effective number of samples, ensuring fair and balanced knowledge transfer across all classes. This adaptive expansion–compression mechanism ensures CAREC remains scalable, parameter-efficient, and high-performance in long-term deployment scenarios of Wi-Fi sensing. Our main contributions are summarized as follows:
- (1)
We introduce CAREC, a class-incremental learning framework tailored for Wi-Fi-based indoor action recognition. CAREC employs a multi-branch architecture that dynamically expands the model by adding new feature extractors while freezing existing ones, effectively preserving previously learned knowledge. To maintain model compactness, a balanced knowledge distillation strategy compresses the network by over 80% (from 105.24 M to 21.08 M parameters).
- (2)
CAREC combats catastrophic forgetting through modular network design and auxiliary classification heads, prevents uncontrolled model growth via knowledge distillation, and mitigates class imbalance during training with a sample-weighted distillation loss.
- (3)
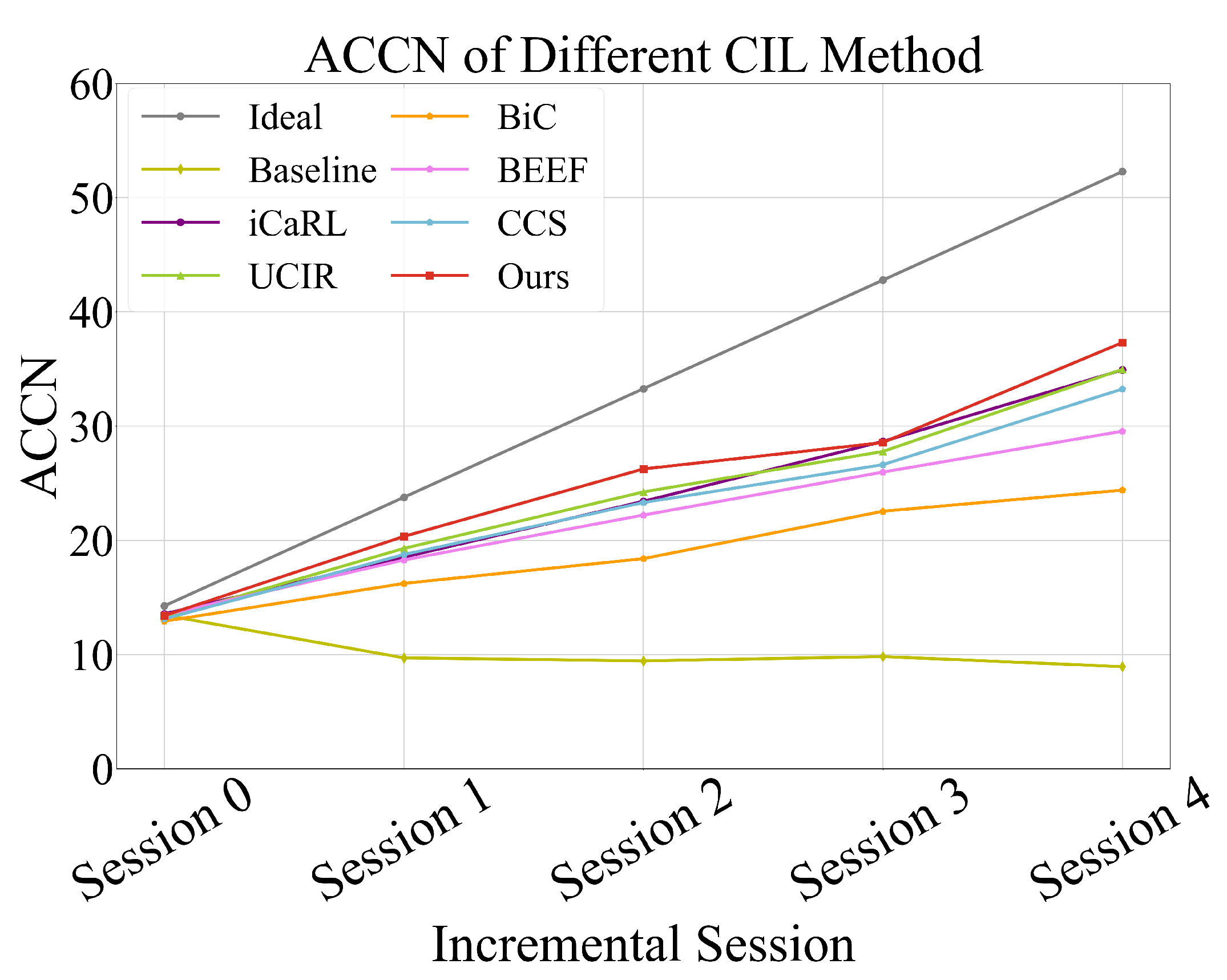
Extensive experiments on the large-scale XRF55 dataset demonstrate that CAREC consistently outperforms both classic and state-of-the-art class-incremental learning methods, including iCaRL [
11], BiC [
13], UCIR [
14], BEEF [
15], and CCS [
10]. CAREC achieves 67.84% accuracy over four incremental stages, highlighting its superior efficiency and suitability for deployment on resource-constrained devices.
The remainder of this paper is organized as follows.
Section 2 reviews the related work, covering both WiFi-based action recognition and the state of incremental learning techniques in wireless sensing.
Section 3 presents the proposed CAREC method.
Section 4 reports the evaluation experiments.
Section 5 and
Section 6 provide a discussion and the conclusion, respectively.
3. CAREC
3.1. Task Definition
We define the class-incremental learning (CIL) task using the following notation. To simulate real-world streaming data, the training process is divided into N incremental stages, with the dataset partitioned as . Each stage contains training samples, where is a data instance belonging to class , and denotes the label space of the i-th stage. For any two stages , the corresponding label spaces are disjoint, i.e., .
The training begins with an initial model trained on . At each subsequent incremental stage i, the model is updated using data from to obtain the new model . The goal of this process is to ensure that, after all incremental stages, the final model can accurately recognize all previously seen action classes. This setting reflects realistic scenarios where recognition systems must adapt to newly emerging user requirements for identifying unseen actions over time.
3.2. Methods
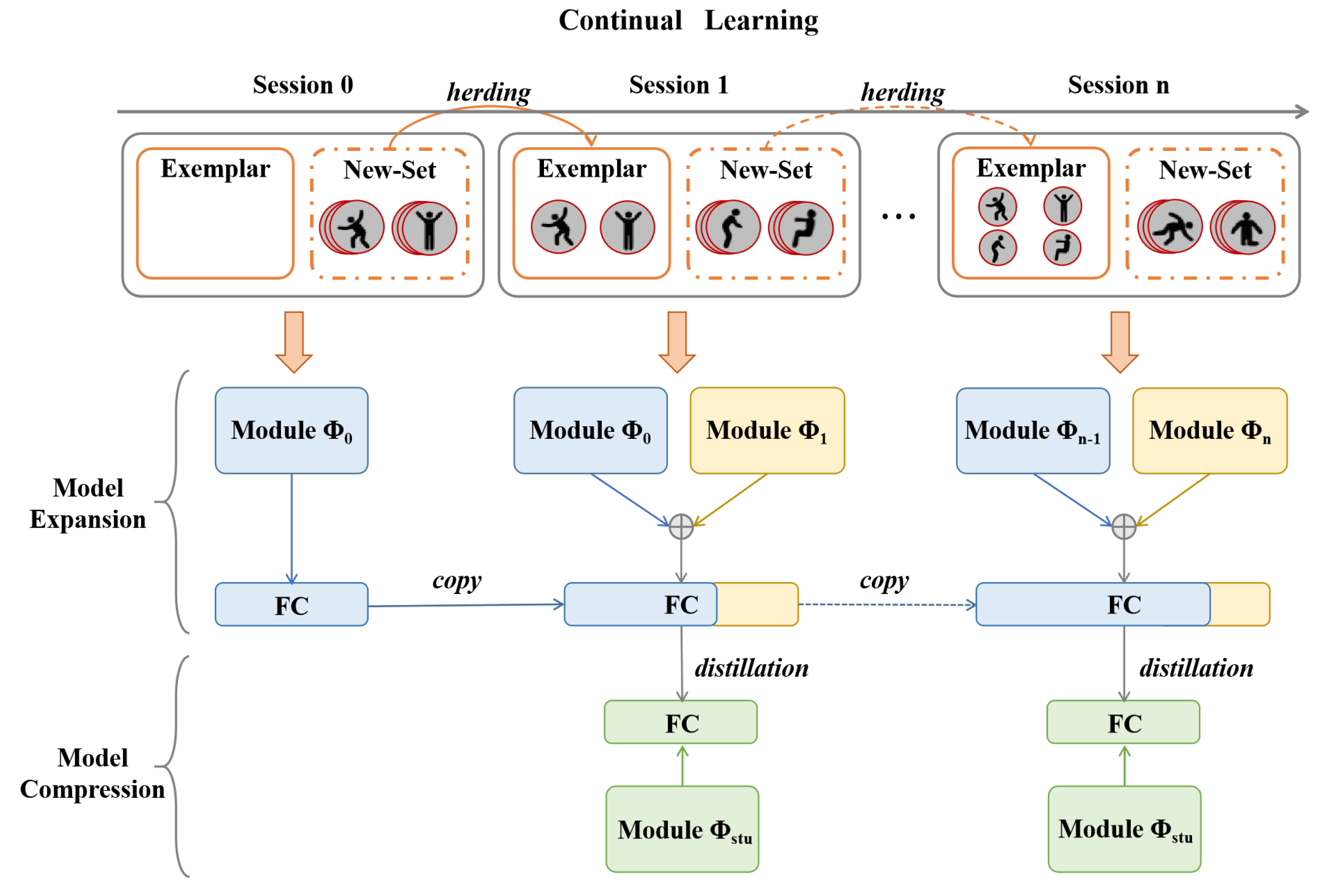
CAREC decouples the continual learning process into two alternating stages: (1) a dynamic expansion phase, which allows the model to integrate novel action classes while preserving previously acquired knowledge, and (2) a lightweight compression phase, which consolidates the learned knowledge into a compact model to ensure deployment efficiency.
As illustrated in
Figure 2, during each incremental stage, we preserve samples from previously seen classes using data replay, specifically employing the Herding strategy [
24] to select representative exemplars (described later in
Section 3.2.3). In the expansion phase, the model adopts a multi-backbone architecture to form a modular network, where a super-feature extractor aggregates outputs from multiple feature extractors, each tailored to a specific task, enabling the model to adapt flexibly to newly added categories.
In the compression phase, we apply a balanced knowledge distillation mechanism, in which the expanded network serves as the teacher and a single-backbone student network is trained to replicate its behavior. This step effectively reduces model complexity by eliminating redundant parameters and feature dimensions, while preserving recognition performance, thus maintaining scalability and efficiency for long-term continual learning.
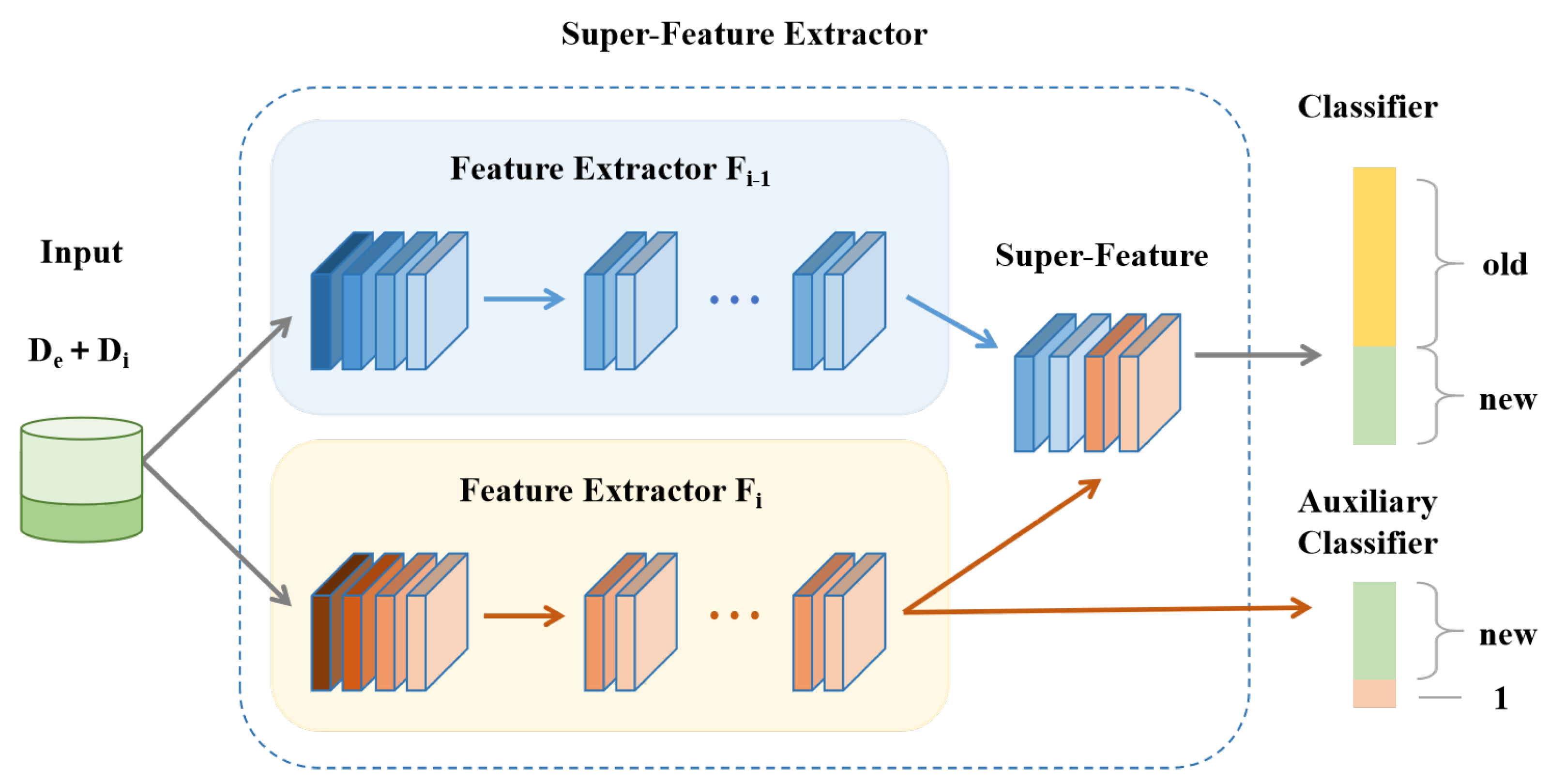
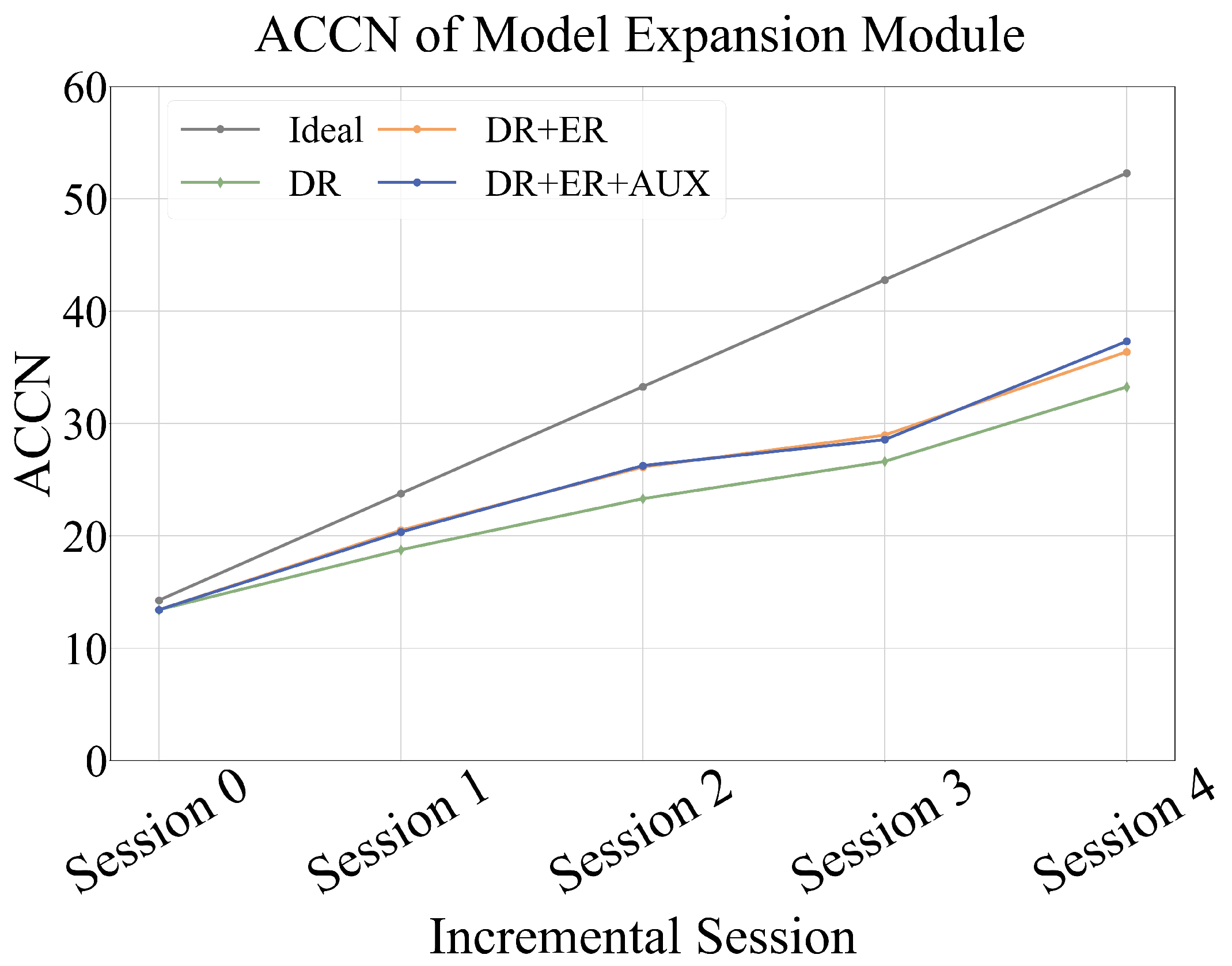
3.2.1. Dynamic Expansion with Super-Feature Extractor
The model expansion module, as depicted in
Figure 3, is designed to enhance adaptability and scalability, particularly under conditions of increasing category diversity and limited data availability. To mitigate catastrophic forgetting, the feature extractor
from the previous stage is frozen at each incremental learning step
t, preserving learned representations. A new feature extractor
is then introduced and initialized with the weights of
, allowing the model to reuse historical knowledge while adapting efficiently to newly introduced classes.
During training, the newly introduced feature extractor
and the classifier
are jointly optimized using the combined dataset
, where
contains exemplar samples from previously learned classes and
comprises data from newly introduced classes. For a given input sample
, the super-feature
is constructed by concatenating the outputs of both the frozen extractor
and the learnable extractor
:
This super-feature
is then passed to the classifier
, which produces the final class prediction via the softmax function:
To enhance the model’s ability to distinguish between newly introduced and previously learned action classes, we incorporate an auxiliary classifier alongside the primary classifier . The auxiliary classifier simplifies the representation of old classes by treating all previously seen classes as a single merged class. This design reduces complexity in handling old knowledge while encouraging the model to focus on learning fine-grained distinctions among new classes.
The auxiliary classifier is trained to promote diverse and discriminative feature learning, thereby enhancing the model’s ability in class-incremental settings. The overall loss function combines the objectives of the main and auxiliary classifiers:
where
denotes the loss from the main classifier
,
is the auxiliary classification loss from
, and
is a weighting coefficient that controls the balance between the two loss components.
This design enables the model to simultaneously leverage stable representations from earlier stages and adaptively learn new representations, improving recognition performance across both old and new action classes.
3.2.2. Lightweight Compression via Balanced Knowledge Distillation
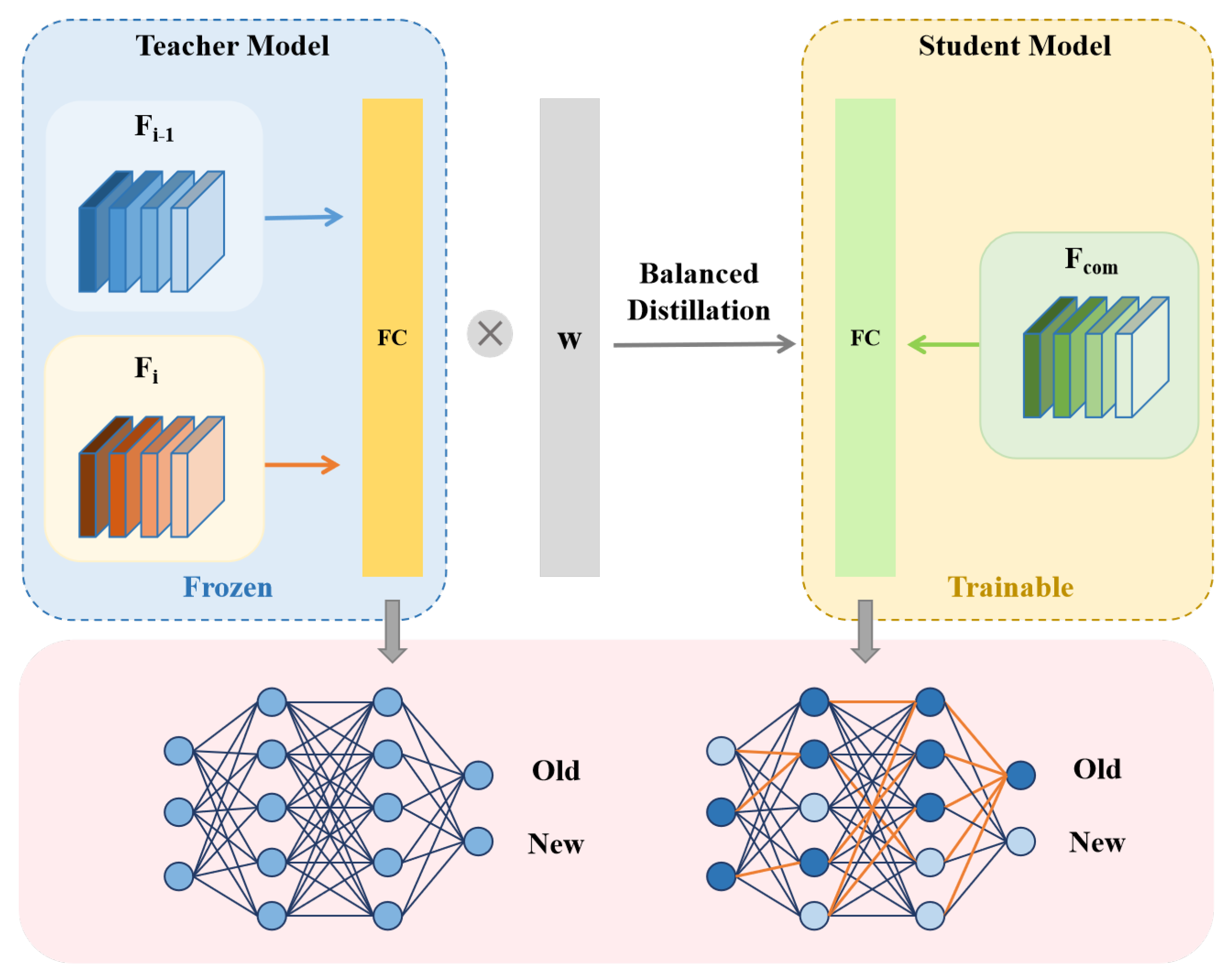
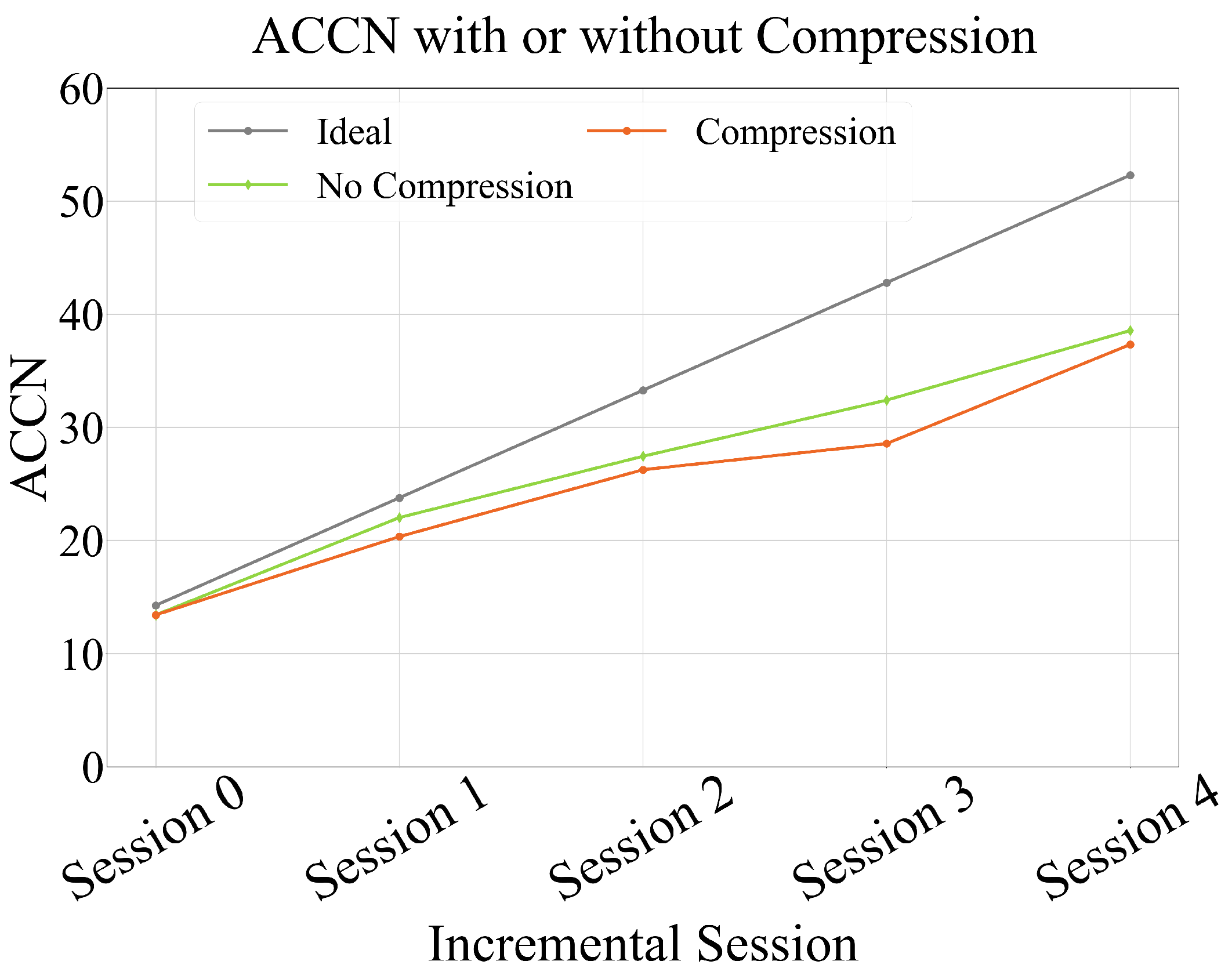
While the model expansion phase effectively preserves performance in class-incremental learning, it inevitably increases the number of model parameters as incremental stages accumulate. To address this scalability issue, we introduce a lightweight compression phase to control model complexity without sacrificing recognition accuracy.
As shown in
Figure 4, we employ a newly initialized single-backbone network
as the student model, while the super-feature extractor
, composed of two backbone networks, serves as the teacher model. During training, the parameters of
are fully frozen, and knowledge distillation is applied as a simple yet effective means of achieving model compression.
In the context of class-incremental learning, the exemplar set
contains only a small number of samples from previously learned classes, while the current stage dataset
is relatively large. This imbalance naturally leads to a long-tailed distribution across classes. However, traditional knowledge distillation frameworks, although effective in general settings, tend to exhibit bias toward head classes on imbalanced datasets [
28]. In such cases, the predictive knowledge from tail classes is overwhelmed, causing the student model to perform suboptimally under the influence of a biased teacher model.
To address the classification bias caused by the imbalance between new and old class sample counts in
, we introduce a reweighting scheme based on the effective number of samples. This scheme adjusts the distillation process to emphasize under-represented classes, thereby producing a class-balanced loss. Specifically, we compute the effective number of samples
for each class as follows:
where
n is the number of training samples for a given class, and
is a hyperparameter that controls the smoothness of the weighting curve. Based on this, we construct a weight vector
, where each class
k is assigned a weight inversely proportional to its effective sample size.
The resulting balanced knowledge distillation (BKD) loss is defined as follows:
where
denotes the teacher’s output, and
denotes the student’s output. The element-wise product
reweights the soft targets class-wise. The weight
is monotonically decreasing with the number of samples
n, meaning that classes with fewer samples are assigned larger weights. This weighting mechanism ensures that minority classes receive larger gradients during training, thus mitigating bias toward dominant classes.
By applying this balanced distillation strategy, the compressed model maintains only a single backbone, making it comparable in parameter count to conventional single-backbone architectures. This not only ensures efficient storage and computation but also prevents performance degradation on new classes due to interference from redundant components retained in previous stages.
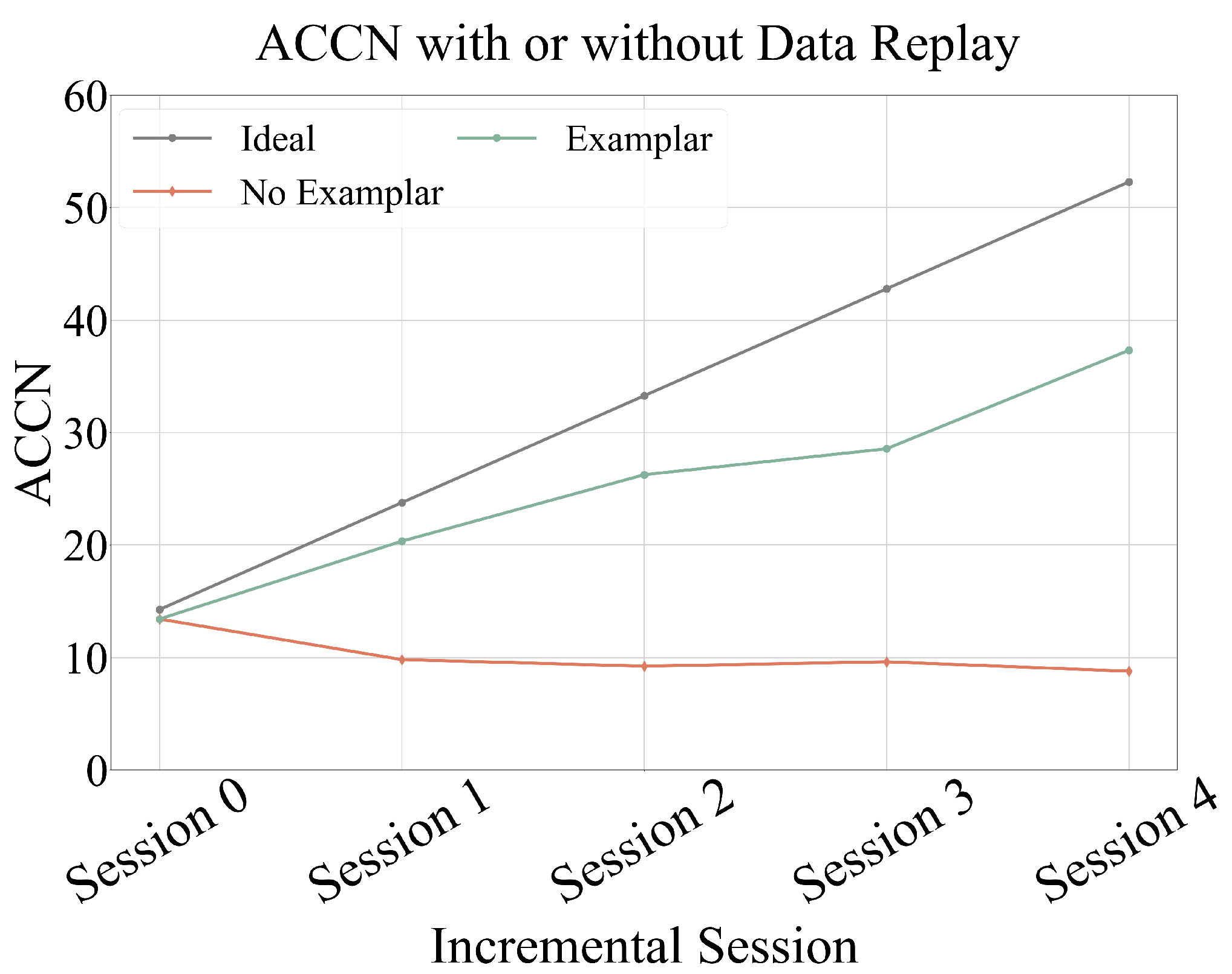
3.2.3. Data Replay
Data replay is an implementation detail of our proposed CAREC, used to select representative data from the previous stage to mitigate the model’s forgetting of old action classes. CAREC adopts the Herding strategy [
24] as the data replay method. For an action class with samples
from the previous stage, the mean feature vector
of the class is calculated as follows:
Considering memory constraints in real-world terminal systems, we retain only
m exemplars per class. To select the
m samples closest to the class mean
, we apply Equations (
7) and (
8) to recursively select the top
m representative samples as exemplars.
For each class in the previous-stage training set , we select m such samples, denoted as . The exemplar set is then combined with the new training data to form the training set for the i-th incremental stage.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}