
MetaRes-DMT-AS: A Meta-Learning Approach for Few-Shot Fault Diagnosis in Elevator Systems


 , ,
, ,
Abstract
1. Introduction
1.1. Fault Prediction
1.2. Meta-Learning for Few-Shot Diagnosis
- (1)
- A better meta-learning approach for acceleration fault detection in elevators is suggested to address the problem of few-shot detection, which requires a lot of labeled data.
- (2)
- A regularization module is added to the prototype network to solve the impact of category imbalance and improve the recognition stability of the detection method.
- (3)
- The module dynamically adjusts the number of support sets and query sets by monitoring and adjusting the cycle interval and performance threshold, thus solving the difficulty of manual experience and manual setting of support sets and query sets.
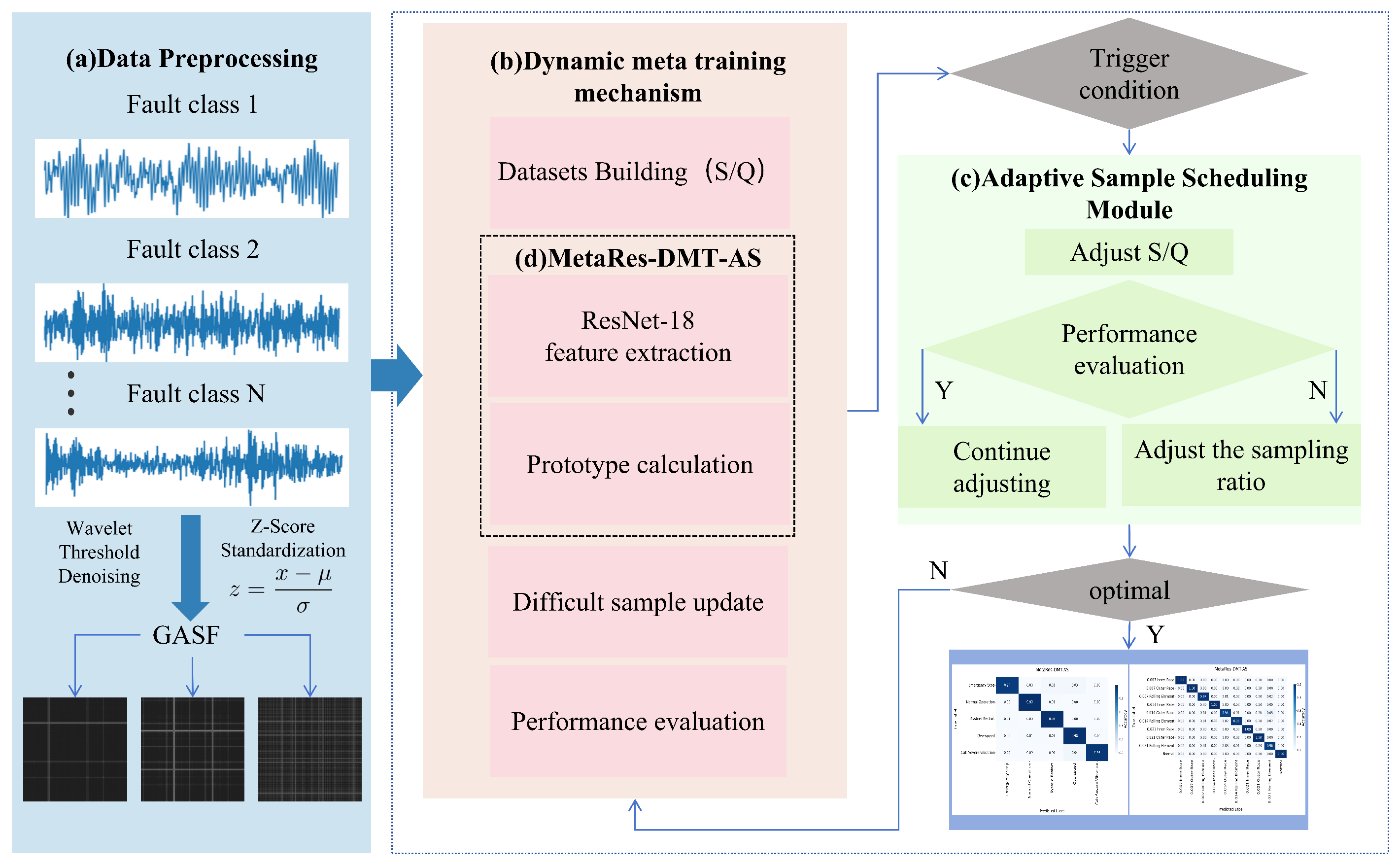
2. Methods
2.1. Data Preprocessing
2.2. Dynamic Meta-Training Mechanism
2.3. Adaptive Sample Scheduling Module
| Algorithm 1 Adaptive Sample Scheduling Module | ||
| 1: | procedure AdaptiveTraining | |
| 2: | Initialization: | |
| 3: | ▹ Model parameters | |
| 4: | ▹ Hard sample repository | |
| 5: | ||
| 6: | ▹ Initial support ratio | |
| 7: | ▹ Stagnation counter | |
| 8: | ▹ Best accuracy | |
| 9: | while not converged do | |
| 10: | MiniBatchTraining(, S, Q) | |
| 11: | if then | |
| 12: | ||
| 13: | if then | |
| 14: | ||
| 15: | ||
| 16: | ||
| 17: | else | |
| 18: | ||
| 19: | if then | |
| 20: | ||
| 21: | ▹ Maintain total samples | |
| 22: | ||
| 23: | ||
| 24: | end if | |
| 25: | end if | |
| 26: | end if | |
| 27: | end while | |
| 28: | return | |
| 29: | end procedure | |
3. Results
3.1. Dataset Introduction
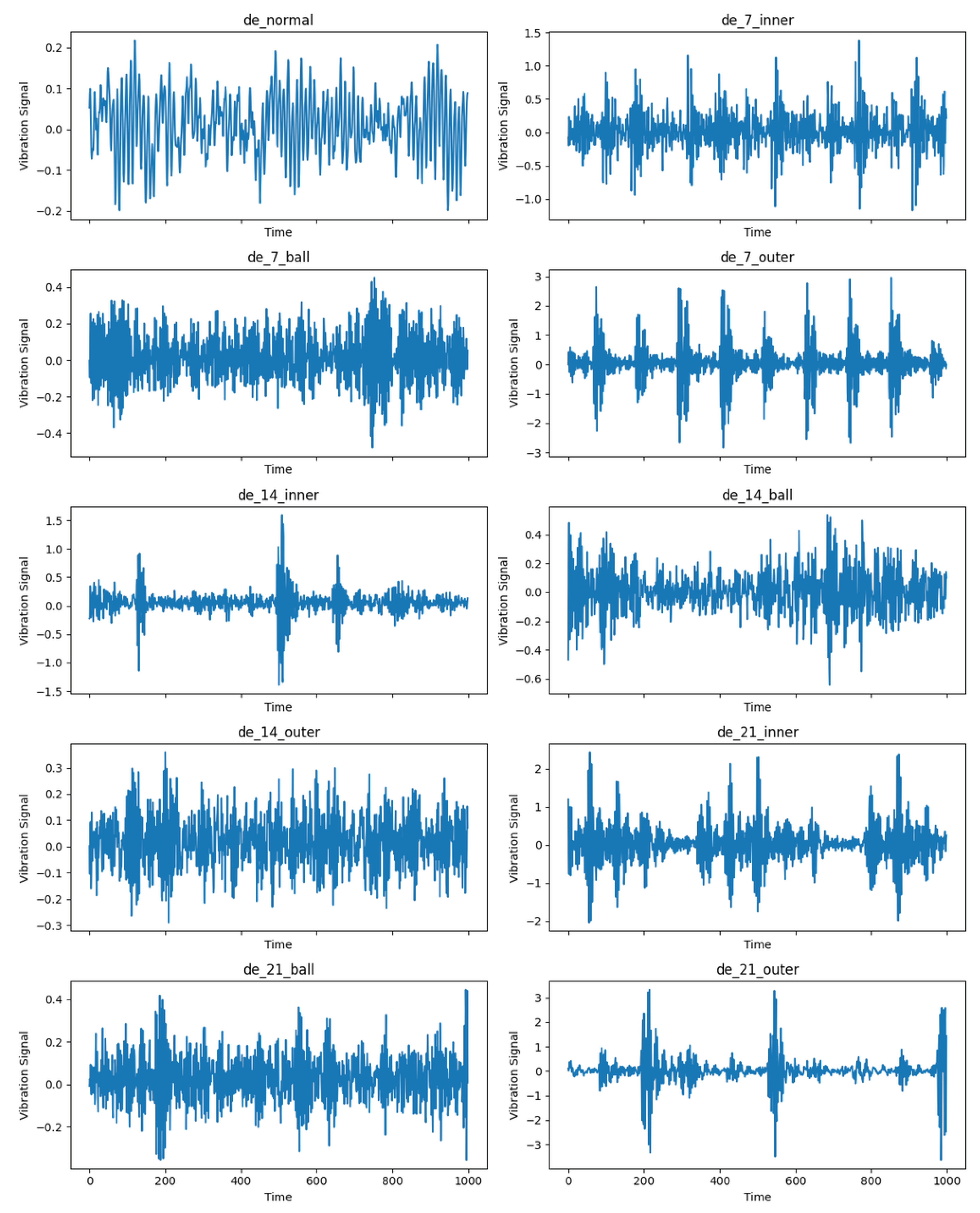
3.1.1. Cwru Dataset
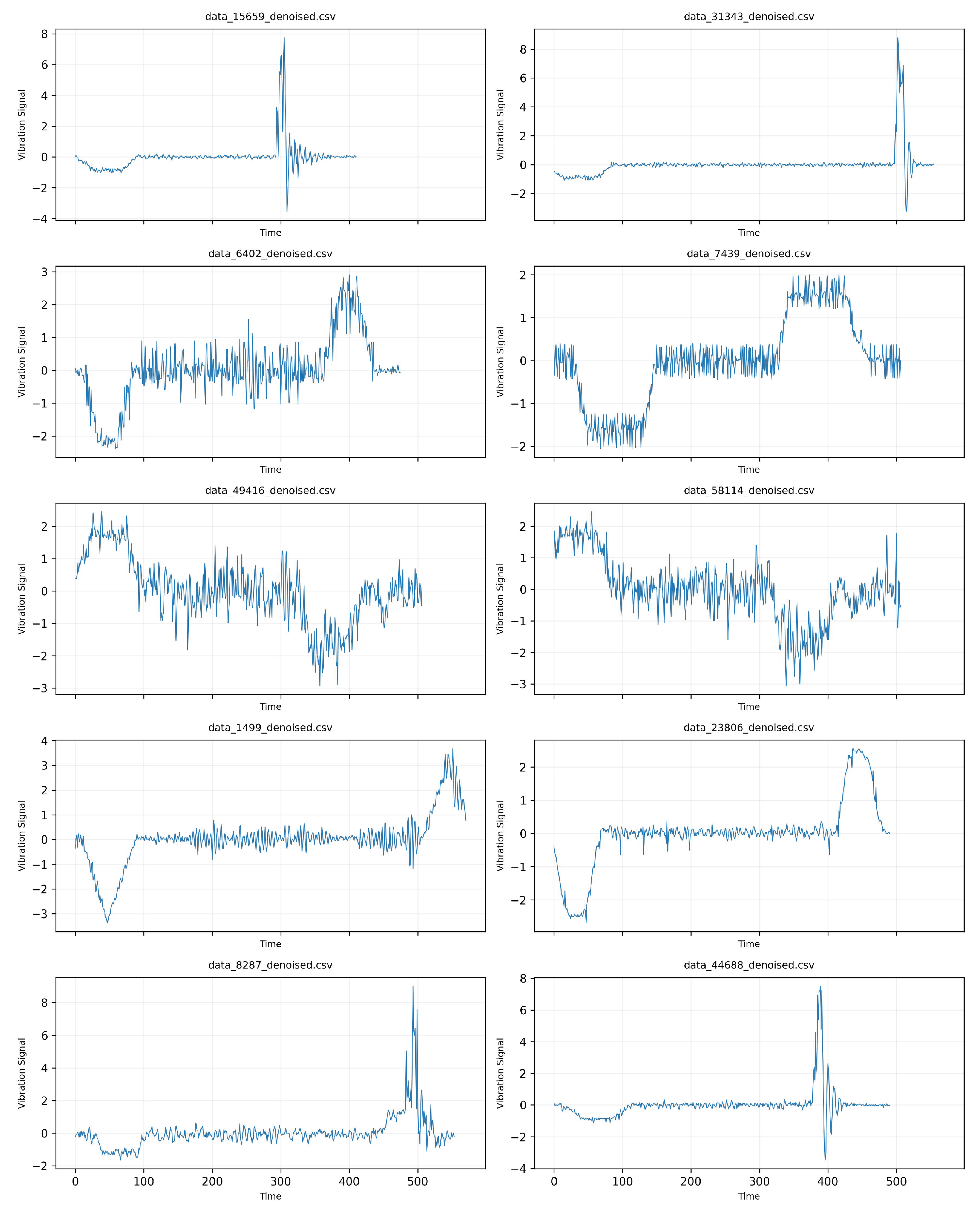
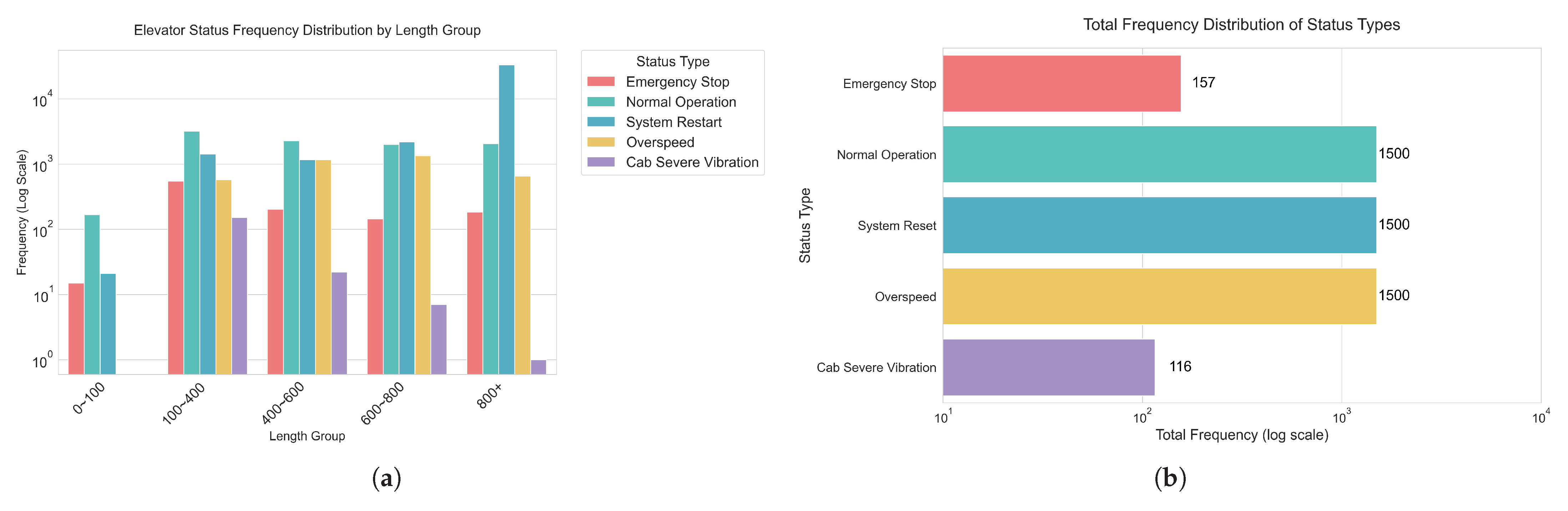
3.1.2. Elevator Fault Dataset
3.2. Experimental Settings
3.3. Performance Evaluation
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Zhang, H.; Qiu, L.; Zhang, S.; Qian, J.; Xiang, F.; Pan, Z.; Tan, J. Towards high-speed elevator fault diagnosis: A ParallelGraphNet driven multi-sensor optimization selection method. Mech. Syst. Signal Process. 2025, 228, 112450. [Google Scholar] [CrossRef]
- Lei, J.; Sun, W.; Fang, Y.; Ye, N.; Yang, S.; Wu, J. A model for detecting abnormal elevator passenger behavior based on video classification. Electronics 2024, 13, 2472. [Google Scholar] [CrossRef]
- Wang, Z. Elevator Abnormal State Detection Based on Vibration Analysis and IF Algorithm. Int. J. Adv. Comput. Sci. Appl. 2025, 16, 798. [Google Scholar] [CrossRef]
- Lupea, I.; Lupea, M. Continuous Wavelet Transform and CNN for Fault Detection in a Helical Gearbox. Appl. Sci. 2025, 15, 950. [Google Scholar] [CrossRef]
- Shao, X.; Cai, B.; Zou, Z.; Shao, H.; Yang, C.; Liu, Y. Artificial intelligence enhanced fault prediction with industrial incomplete information. Mech. Syst. Signal Process. 2025, 224, 112063. [Google Scholar] [CrossRef]
- Cen, X.; Hong, B.; Yang, Y.; Wu, Z.; Zhao, Z.; Yang, J. A high-precision and interpretable prediction method of the gas–solid erosion rate in elbows based on hybrid mechanism-data-driven models. Measurement 2025, 251, 117251. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, C.; Li, N. Fault prediction of elevator operation system based on LSTM. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6762–6766. [Google Scholar]
- Wang, P.; Zhang, Y.; Linjama, M.; Zhao, L.; Yao, J. Fault identification and localization for the fast switching valve in the equal-coded digital hydraulic system based on hybrid CNN-LSTM model. Mech. Syst. Signal Process. 2025, 224, 112201. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Li, Y.; Shi, H. Fault diagnosis method for rolling bearings based on WDCNN-DLSTM. Sci. Technol. Eng. 2023, 23, 5522–5529. [Google Scholar]
- Liu, X.; MA, C.; Huang, M.; Zhang, Z. Variable speed bearings using wide convolutional kernel gated recurrent hybrid networks fault diagnosis technique research. Modul. Mach. Tool Autom. Manuf. Tech. 2025, 138–142+149. [Google Scholar] [CrossRef]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the big data paradigm with compact transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Wang, C.; Tian, X.; Zhou, F.; Wang, R.; Wang, L.; Tang, X. Current signal analysis using SW-GAT networks for fault diagnosis of electromechanical drive systems under extreme data imbalance. Meas. Sci. Technol. 2024, 36, 016140. [Google Scholar] [CrossRef]
- Wang, C.; Tian, X.; Shao, X.; Wang, R.; Wang, L. Data imbalanced fault diagnosis of gearbox transmission system under various speeds based on dynamic dual-scale normalized fusion network. Meas. Sci. Technol. 2024, 36, 016191. [Google Scholar] [CrossRef]
- Yang, W.; Wang, B.; Zhang, M.X.H.; Wang, C. Application of First-Order Meta-Learning in Rolling Bearing Fault Diagnosis under Small Sample Conditions. Mech. Sci. Technol. Aerosp. Eng. 2024, 1–9. [Google Scholar] [CrossRef]
- Adadi, A. A survey on data-efficient algorithms in big data era. J. Big Data 2021, 8, 24. [Google Scholar] [CrossRef]
- Yan, B.; Liu, Z.; Liu, Z. Research on Fault Diagnosis Method of Cross Mechanical Components Based on Meta Learning Under Small Samples. Modul. Mach. Tool Autom. Manuf. Tech. 2022, 136–140. [Google Scholar] [CrossRef]
- Li, Q.; Jin, X.; Zhang, C.; Shangguan, W.; Wei, Z.; Li, L.; Liu, P.; Dai, Y. Improving global soil moisture prediction based on Meta-Learning model leveraging Köppen-Geiger climate classification. Catena 2025, 250, 108743. [Google Scholar] [CrossRef]
- Song, W.; Wu, D.; Shen, W.; Boulet, B. Early fault detection for rolling bearings: A meta-learning approach. IET Collab. Intell. Manuf. 2024, 6, e12103. [Google Scholar] [CrossRef]
- Ma, R.; Han, T.; Lei, W. Cross-domain meta learning fault diagnosis based on multi-scale dilated convolution and adaptive relation module. Knowl.-Based Syst. 2023, 261, 110175. [Google Scholar] [CrossRef]
- Liu, B.; Liu, S.; Huang, S.; Zheng, L. An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction. Electronics 2025, 14, 1344. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. arXiv 2016, arXiv:1606.04080. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Chen, J.; Yuan, Y. Decentralized Personalization for Federated Medical Image Segmentation via Gossip Contrastive Mutual Learning. IEEE Trans. Med. Imaging 2025, 44, 2768–2783. [Google Scholar] [CrossRef] [PubMed]
- Qiao, L.; Zhang, Y.; Wang, Q.; Li, D.; Peng, S. Fault diagnosis for wind turbine generators based on Model-Agnostic Meta-Learning: A few-shot learning method. Expert Syst. Appl. 2024, 267, 126171. [Google Scholar] [CrossRef]
- Liu, X.; Aldrich, C. Recognition of flotation froth conditions with k-shot learning and convolutional neural networks. J. Process. Control 2023, 128, 103004. [Google Scholar] [CrossRef]
- Kong, X.; Cai, B.; Yu, Y.; Yang, J.; Wang, B.; Liu, Z.; Shao, X.; Yang, C. Intelligent diagnosis method for early faults of electric-hydraulic control system based on residual analysis. Reliab. Eng. Syst. Saf. 2025, 261, 111142. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Data Size |
|---|---|
| 0.007 rolling element | 969 |
| 0.007 inner race | 970 |
| 0.007 outer race | 970 |
| 0.014 rolling element | 970 |
| 0.014 inner race | 968 |
| 0.014 outer race | 969 |
| 0.021 rolling element | 970 |
| 0.021 inner race | 969 |
| 0.021 outer race | 970 |
| normal | 3388 |
| Algorithms | Emergency Stop | Normal Operation | System Restart | Overspeed | Cab Severe Vibration |
|---|---|---|---|---|---|
| STFT | 88 | 99 | 99 | 98 | 83 |
| GASF | 94 | 99 | 98 | 98 | 96 |
| Hyperparameters | Value |
|---|---|
| Learning rate | 0.001 |
| Epochs | 100 |
| Episodes per epoch | 50 |
| Batch size | 32 |
| Support | 6 |
| Query | 6 |
| Hyperparameters | Value |
|---|---|
| Learning rate | 0.001 |
| Epochs | 100 |
| Episodes per epoch | 50 |
| Batch size | 32 |
| Support | 3 |
| Query | 3 |
| Model | Inference Time (ms) | Peak Memory (MB) |
|---|---|---|
| WDCNN | 2.10 | 2.00 |
| MAML | 2.83 | 2.00 |
| CCT | 3.61 | 5.99 |
| Prototypical Network | 4.85 | 6.00 |
| MetaRes-DMT-AS | 4.97 | 6.00 |
| Vision Transformer (ViT) | 6.01 | 2.00 |
| WDCNN-GRU | 47.31 | 2.00 |
| WDCNN-DLSTM | 48.38 | 2.00 |
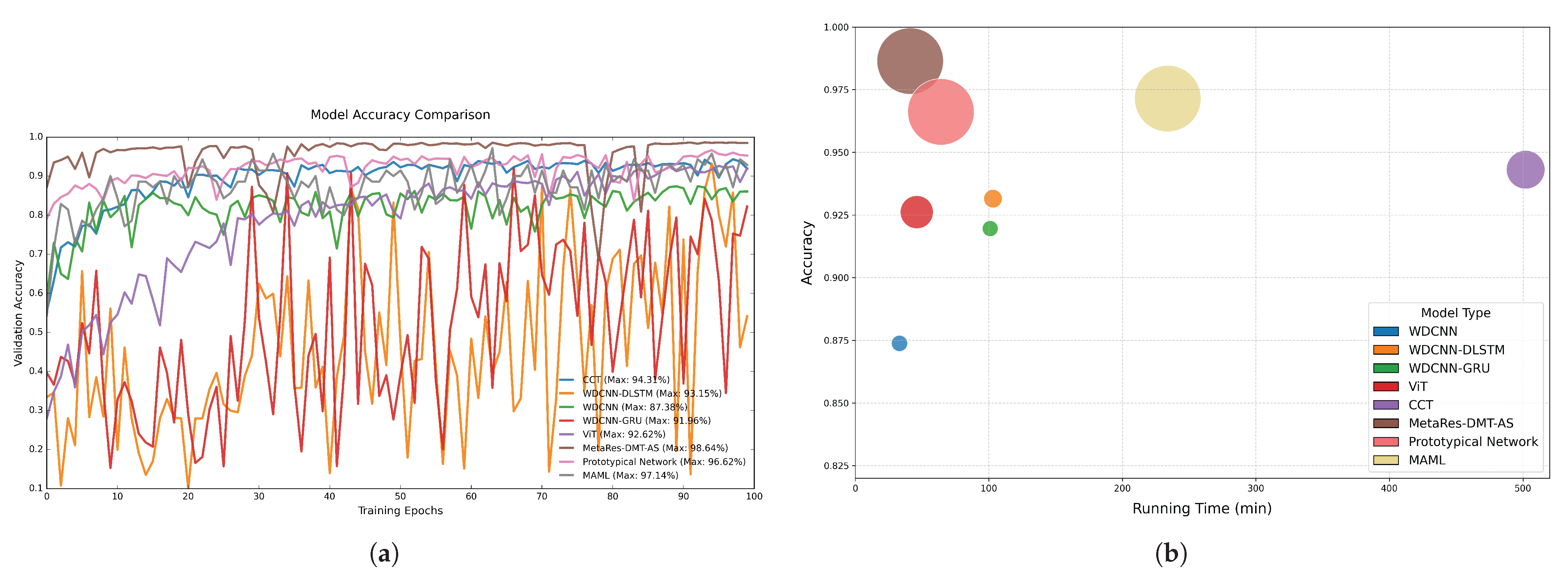
| Model | Accuracy/% |
|---|---|
| CCT | 94.31 |
| WDCNN | 87.38 |
| ViT | 92.62 |
| WDCNN-DLSTM | 93.15 |
| WDCNN-GRU | 91.96 |
| Prototypical Network | 96.62 |
| MAML | 97.14 |
| MetaRes-DMT-AS | 98.64 |
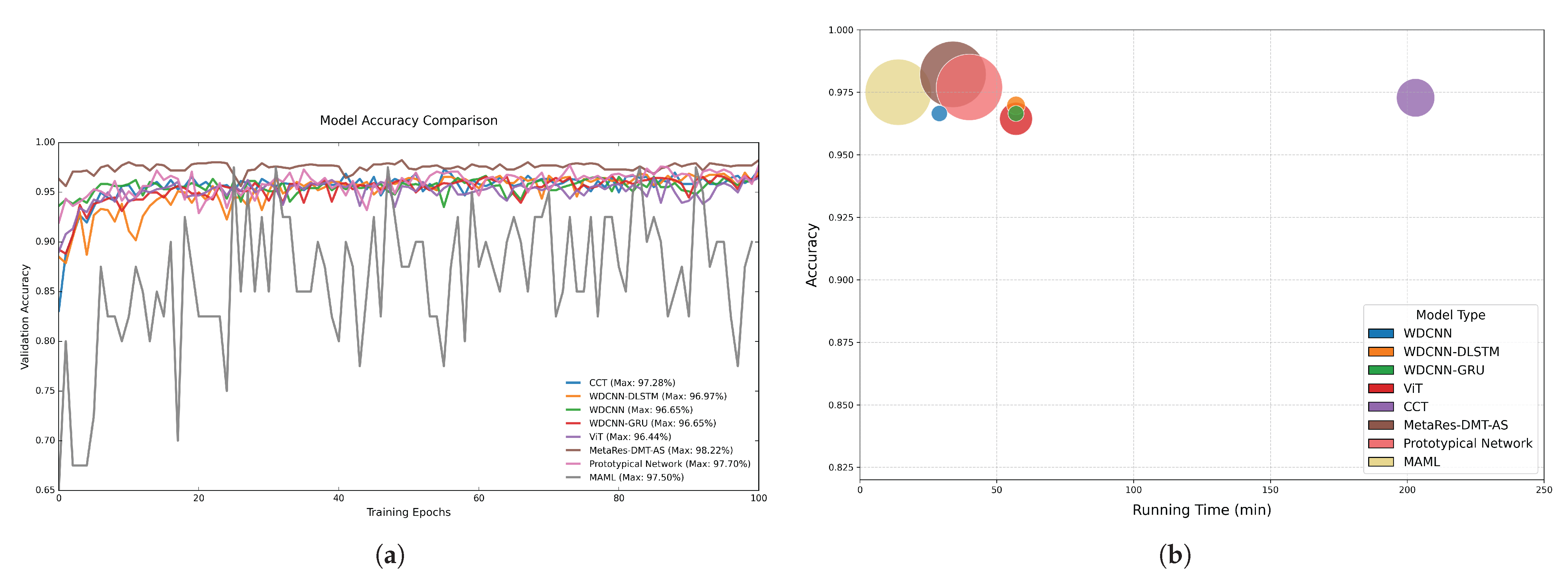
| Model | Accuracy/% |
|---|---|
| CCT | 97.28 |
| WDCNN | 96.65 |
| ViT | 96.44 |
| WDCNN-DLSTM | 96.97 |
| WDCNN-GRU | 96.65 |
| Prototypical Network | 97.70 |
| MAML | 97.50 |
| MetaRes-DMT-AS | 98.22 |
| Method Configuration | Detection Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Prototypical Networks | Adaptive Sampling | Overall | 0.014 Inner Race | 0.014 Outer Race | 0.014 Rolling Element | 0.021 Rolling Element |
| 97.36 | 98 | 91 | 92 | 87 | ||
| ✓ | 98.43 | 100 | 93 | 96 | 93 | |
| ✓ | 97.61 | 98 | 92 | 94 | 90 | |
| ✓ | ✓ | 98.64 | 100 | 94 | 96 | 96 |
| Method Configuration | Detection Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|
| Prototypical Networks | Adaptive Sampling | Overall | Emergency Stop | Normal Operation | System Restart | Overspeed | Cab Severe Vibration |
| 97.59 | 84 | 99 | 97 | 99 | 83 | ||
| ✓ | 98.01 | 84 | 99 | 99 | 99 | 88 | |
| ✓ | 97.91 | 88 | 99 | 99 | 99 | 83 | |
| ✓ | ✓ | 98.22 | 94 | 99 | 98 | 98 | 96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.; Yang, S.; Zhang, Y.; Wu, J.; He, L.; Lei, J. MetaRes-DMT-AS: A Meta-Learning Approach for Few-Shot Fault Diagnosis in Elevator Systems. Sensors 2025, 25, 4611. https://doi.org/10.3390/s25154611
Hu H, Yang S, Zhang Y, Wu J, He L, Lei J. MetaRes-DMT-AS: A Meta-Learning Approach for Few-Shot Fault Diagnosis in Elevator Systems. Sensors. 2025; 25(15):4611. https://doi.org/10.3390/s25154611
Chicago/Turabian StyleHu, Hongming, Shengying Yang, Yulai Zhang, Jianfeng Wu, Liang He, and Jingsheng Lei. 2025. "MetaRes-DMT-AS: A Meta-Learning Approach for Few-Shot Fault Diagnosis in Elevator Systems" Sensors 25, no. 15: 4611. https://doi.org/10.3390/s25154611
APA StyleHu, H., Yang, S., Zhang, Y., Wu, J., He, L., & Lei, J. (2025). MetaRes-DMT-AS: A Meta-Learning Approach for Few-Shot Fault Diagnosis in Elevator Systems. Sensors, 25(15), 4611. https://doi.org/10.3390/s25154611