1. Introduction
Autonomous driving systems rely on multimodal data, encompassing both dynamic vehicle states and static map information to predict future trajectories accurately. Dynamic inputs, such as time-series vehicle states (e.g., position and velocity), are typically computed through state estimation algorithms from data collected by onboard sensors like inertial measurement units (IMUs), cameras, and radars. In contrast, static spatial information regarding lane geometry and road layout is obtained from high-definition (HD) maps. Effectively integrating these multimodal inputs is crucial for robust trajectory prediction.
A key challenge in trajectory prediction lies in effectively capturing the evolving spatial context induced by vehicle motion while maintaining prediction accuracy and diversity. Existing methods often fail to align scene semantics with agent movement, neglecting how scene features evolve over time [
1]. Current latent variable models lack structured representations that disentangle individual-specific and scene-shared factors [
2], leading to either overly deterministic or contextually inconsistent predictions. Additionally, trajectory forecasting and lane sequence prediction are typically treated as separate tasks [
3], missing opportunities to reinforce predictive robustness through multi-task generative modeling. Addressing these limitations requires a unified framework that leverages time-indexed scene encoding, structured latent modeling, and multi-task learning to enhance prediction accuracy and diversity.
To tackle these challenges, existing work has primarily explored two aspects of multimodal trajectory prediction: enhancing input representation by unified scene encoding and employing generative models to handle multimodal outputs. Among these, recent advances have leveraged multimodal inputs, incorporating dynamic agent states and static HD map features. Existing map encoding methods typically rely on static, vectorized representations, which align well with trajectory formats [
4] but overlook the evolving spatial context induced by vehicle motion. Thus, a fundamental discrepancy arises: contextual semantics evolve as the vehicle moves, while static map features remain unchanged, limiting the model’s ability to reason over context-dependent future behaviors. To generate diverse trajectory predictions, various generative models have been employed, including Generative Adversarial Networks (GANs) [
5], Variational Autoencoders (VAEs) [
6], and Conditional VAEs (CVAEs) [
7]. Each approach exhibits notable trade-offs between prediction accuracy and trajectory diversity [
8,
9]. Specifically, the GAN-based methods lack a probabilistic framework, hindering their capacity to quantify uncertainty and limiting trajectory diversity; the VAE-based methods rely on overly simplistic assumptions, such as diagonal Gaussian distributions, which restricts their ability to effectively model complex and multimodal behavior patterns; and CVAE-based methods introduce conditional generation to address multimodality, so they often struggle to capture the intricate dependencies between dynamic vehicle motion and spatially evolving map features. Therefore, a unified framework that not only aligns dynamic inputs with evolving scene semantics but also incorporates structured latent space representations to generate diverse yet contextually consistent trajectories is still lacking.
In this paper, we propose a Multi-Source Input with Structured Latent Variable Model (MS-SLV), a unified framework that captures dynamic agent states and structured environmental semantics in a coherent spatio-temporal representation. Our contributions are summarized as follows:
(i) Time-aware scene encoding: We propose a time-indexed scene representation that encodes the scene layout at both present and future steps, aligning spatial semantics with the agent’s motion. This formulation captures how scene semantics evolve relative to vehicle movement, enhancing context-aware trajectory predictions, e.g., dynamic driving.
(ii) Structured latent variable modeling: We design a structured latent variable model that disentangles individual-specific and scene-shared factors through semantic partitioning and Kullback–Leibler divergence (KL) regularization. This structured latent space not only improves prediction accuracy but also balances trajectory diversity, addressing the trade-offs between deterministic and multimodal outputs.
(iii) Multi-task generative framework: We integrate structured latent modeling into a multi-task generative framework that unifies trajectory forecasting and lane sequence prediction. This formulation leverages structured latent spaces to reinforce prediction robustness while maintaining scene interpretability in complex traffic scenarios.
(iv) Extensive simulation: We evaluate the performance of our structured latent variable model on the nuScenes dataset using displacement-based metrics. Our method reduces the Average Displacement Error (ADE) by 12.37% and the Final Displacement Error (FDE) by 7.67% when considering the best-five predicted trajectories. This shows improvements in multimodal prediction accuracy.
2. Related Work
The state-of-the-art trajectory prediction discussed in this paper is considered from two key perspectives, i.e., multimodal input representation and generative-model-based multimodal prediction.
Effective trajectory prediction necessitates the integration of diverse contextual information, encompassing both agent dynamics and static scene features. Several studies have modeled agent–agent interactions using pooling strategies based on Long Short-Term Memory networks (LSTMs) and Convolutional Neural Networks (CNNs) [
10]. Moreover, recent methods, such as GRIP++ [
11], leverage Graph Neural Networks (GNNs) and Transformers to capture topological interactions. To better incorporate rich scene semantics, recent works [
12,
13] propose vectorized representations of HD maps—including lane centerlines and traffic signs—using points, splines, or polylines for compact encoding. Building on vectorized representations, some approaches further model map elements as graphs [
14], allowing for explicit topological reasoning but at a higher computational cost. Notably, these methods enable structural alignment with agent trajectories, with maps encoded statically. Therefore, static map encodings fail to account for dynamic scene changes induced by agent movement.
Generative models play a pivotal role in multimodal trajectory prediction. To account for the inherent uncertainty in future motion, multimodal trajectory prediction aims to generate multiple plausible future trajectories for a target agent. Generative models, particularly GANs and CVAEs, have become standard approaches for this task. GAN-based methods [
15] rely on adversarial training to learn the data distribution and often incorporate diversity-promoting objectives to mitigate mode averaging. However, they lack a principled probabilistic foundation, making it difficult to quantify uncertainty and making them prone to mode collapse, i.e., where only a narrow set of plausible outcomes is captured [
8]. CVAEs [
7] offer a more principled framework by introducing latent variables to model future uncertainty conditioned on observed context. Models such as Trajectron++ [
16] enhance CVAEs by incorporating multi-agent interactions and dynamically feasible trajectory modeling. Nevertheless, most CVAE-based methods rely on simplistic priors—typically diagonal Gaussians—that limit the latent space’s expressiveness. As a result, these models struggle to balance accuracy and diversity, especially when capturing the complex dependencies between dynamic agent behavior and structured environmental context [
9].
Forecasting future motion in structured environments often involves multiple correlated sub-tasks, such as trajectory prediction and lane or goal sequence prediction. Several prior works address this challenge through stage-wise architectures that first infer an agent’s intent and then generate trajectories accordingly. For instance, MultiPath++ [
17] and TNT [
18] follow anchor-based pipelines, while goal-driven models [
19,
20] adopt modular branches for destination and path estimation. While effective, these methods treat intent and trajectory prediction as separate stages or loosely coupled branches, which may limit mutual supervision and lead to semantic inconsistencies.
In summary, there is a need for expressive latent representations that effectively disentangle vehicle-specific intentions from scene-level semantics, thereby enhancing prediction accuracy and diversity while maintaining contextual coherence with the evolving scene.
3. Multi-Source Structured Latent Variables
In this section, we introduce the proposed MS-SLV for multitask motion forecasting. We begin by presenting the overall framework, followed by deriving the evidence lower bound (ELBO) formulation under structured latent variables.
3.1. Overview
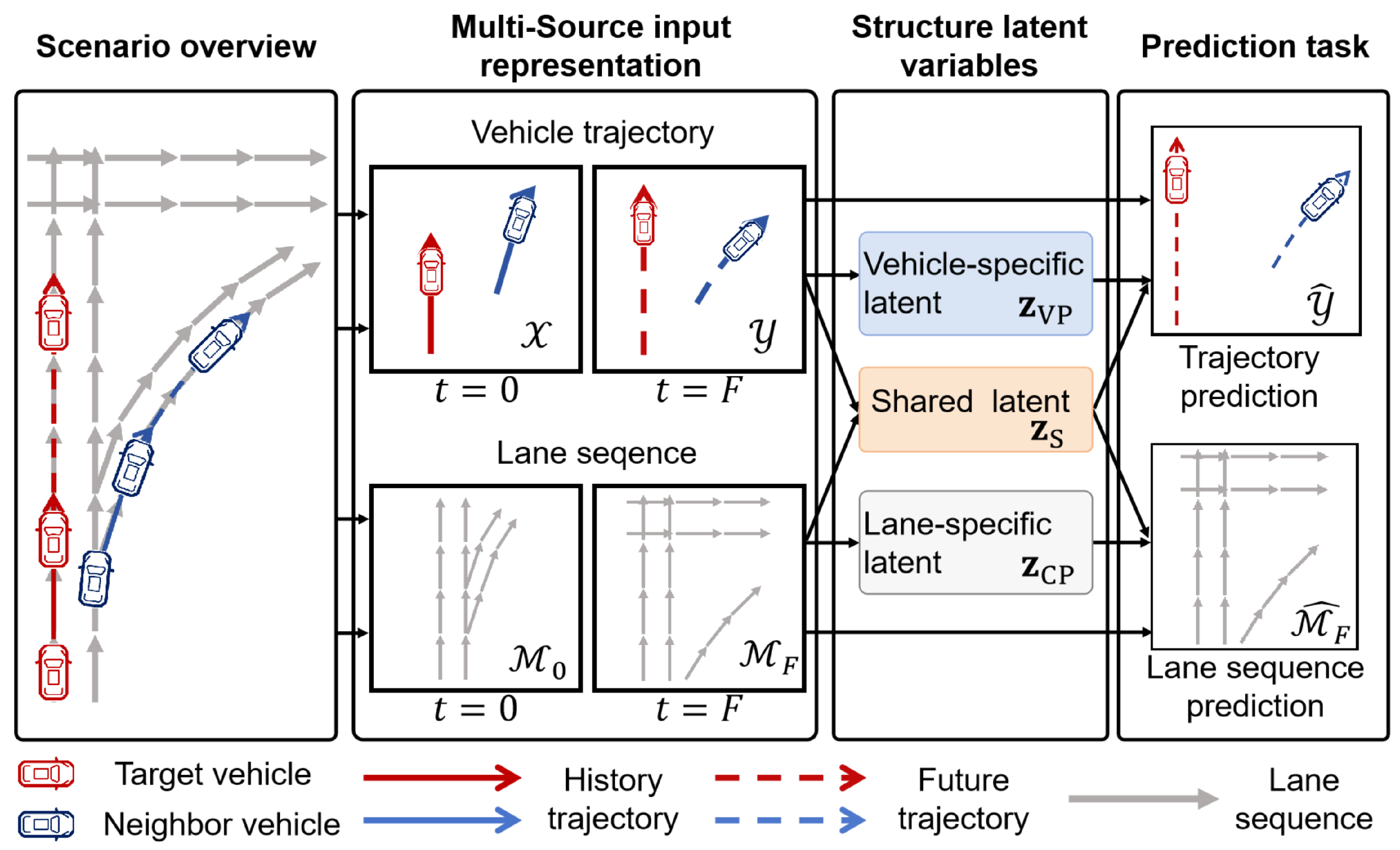
In this paper, we consider a traffic scene where vehicle information is represented as motion trajectories and map information is represented as lane centerline sequences. As illustrated in
Figure 1, vehicle trajectory information is represented as colored polylines, capturing dynamic agent states, while lane sequence information is encoded as gray polylines to reflect spatial structure. The vehicle trajectory information is represented by the observed trajectory
over the past
H steps, which captures motion dynamics and implicitly reflects interaction. In contrast, lane sequence information is represented through spatial sequences obtained by sampling lane centerlines, providing structured scene context. To account for the contextual evolution induced by vehicle motion, lane sequences are extracted at both the current and future steps, denoted as
and
, respectively, each centered around the target vehicle’s position.
The objective of the traffic scene is to predict the future trajectory of the target vehicle while concurrently forecasting the lane sequence . This dual-task setup is formulated as a joint conditional probability density . Our goal is to design a structured latent variable model to disentangle shared and modality-specific uncertainties, thereby capturing both scene-level context and vehicle-specific dynamics.
3.2. Structured Latent Variables
To address the trade-off between prediction accuracy and trajectory diversity in multimodal trajectory prediction, we introduce a structured latent variable model that decomposes trajectory uncertainty into two components: vehicle-specific latent variables
and lane-specific latent variables
, as shown in
Figure 1. Here,
and
capture vehicle- and lane-specific factors, respectively, while the shared component
encodes interactions between agent behavior and contextual scene constraints. The shared latent variable
serves to align vehicle behavior with environmental context, such as lane-following or deceleration near ramps, thereby promoting consistency across modalities. To prevent redundancy,
and
are modeled as statistically independent components, while
bridges the two modalities to ensure coherent trajectory predictions.
To further encourage latent disentanglement and mitigate mode collapse, we incorporate lane sequence prediction as an auxiliary task. This complementary supervision guides the learning of modality-specific and shared representations, effectively structuring the latent space to capture both agent-specific intentions and scene-level semantics.
3.3. ELBO with Structured Latent Variables
To model
, we propose a CVAE-based framework with a modified ELBO that explicitly reflects the structured latent space. The modified ELBO with structure latent variables is
Under the assumption of conditional independence between the two prediction targets, we decouple trajectory and lane outputs given their corresponding latent variables and observed inputs. We further factorize the ELBO into two modality-specific components and augment the latent space with a shared variable
, capturing shared scene-level uncertainty, and decompose the bound as
This decomposition supports a multi-task learning paradigm, where trajectory and lane sequence prediction are modeled as parallel tasks with disentangled uncertainty sources. To further disentangle latent variables, we introduce Total Correlation (TC) regularization [
21] to penalize dependencies between individual-specific
and shared
components. Intuitively, TC encourages independence among different latent dimensions, so that each captures a distinct factor of variation, such as individual motion intent or shared contextual information. As shown in Equation (
3), the training objective combines (i) reconstruction losses for vehicle and lane tasks
; (ii) TC terms
to reduce latent entanglement; and (iii) dimension-wise KL divergence (DW-KL)
to align each latent unit with its priors. The DW-KL term penalizes collapsed or inactive latent units by ensuring that each dimension contributes meaningful information. Together, TC and DW-KL promote a more interpretable and robust latent space for multimodal prediction. The detailed derivation of the ELBO for structured latent variables is given in
Appendix A.
4. MS-SLV Workflow
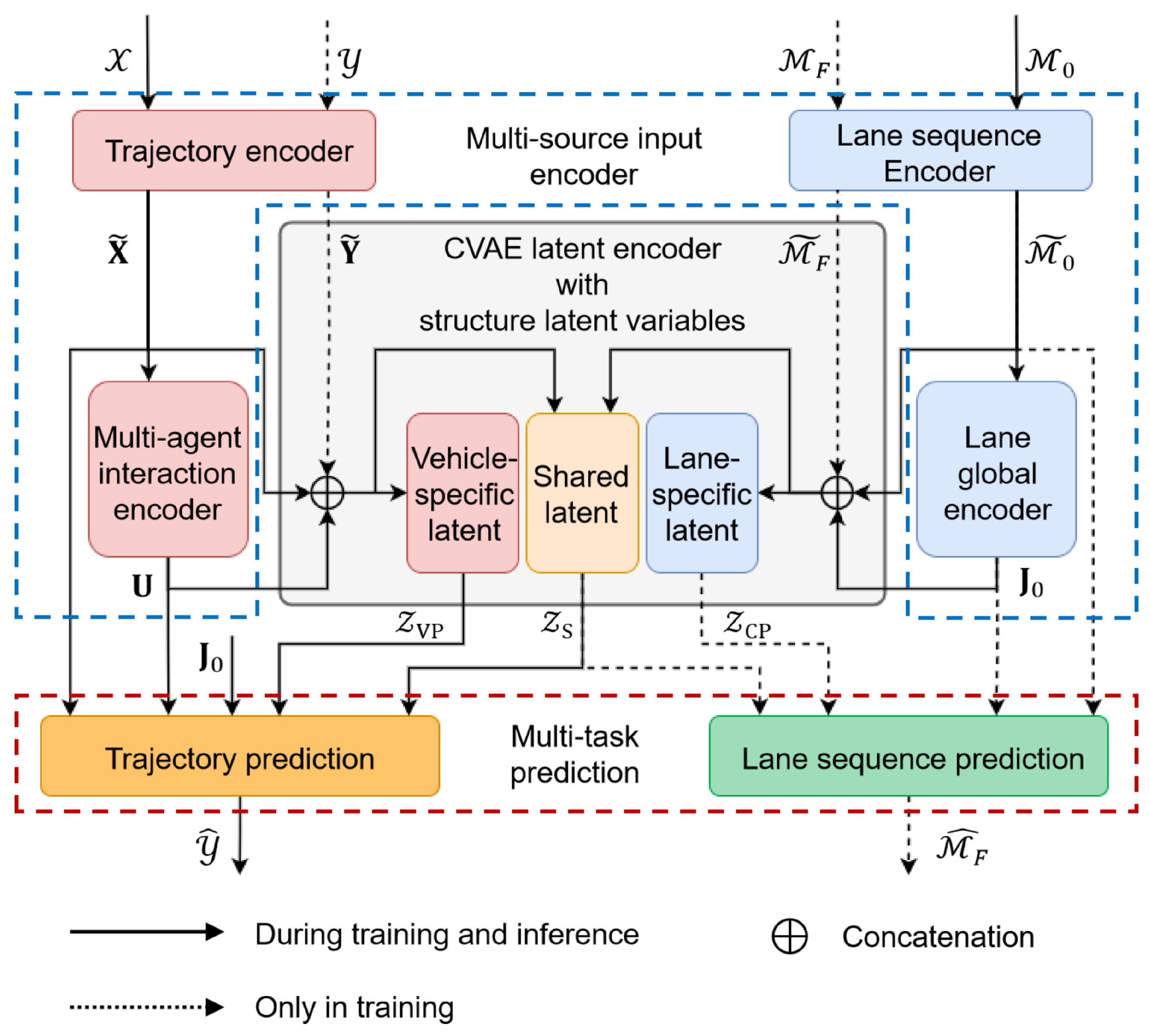
We begin this section by introducing the input representations. As illustrated in
Figure 2, MS-SLV consists of three main components: a multi-source input encoder, a structured latent variable encoder, and a multitask prediction decoder.
4.1. Input Representation
In the proposed framework, each vehicle n at the current step is represented by a -dimensional state vector , capturing its position, velocity, and heading. The historical trajectory over past H steps is denoted as , while the future trajectory over F steps is defined as . For a scene containing N vehicles, the input and target trajectories are expressed as and , respectively. To capture spatial context, we extract the M nearest lane centerline sequences for each vehicle within a predefined region of interest. Importantly, these sequences are sampled at both and the predicted step , resulting in and . This dual temporal sampling strategy underscores the evolving relevance of static lane features as the vehicle progresses through the scene. If fewer than M lane sequences are available, zero-padding is applied to maintain consistent tensor dimensions. Each lane sequence consists of L centerline vectors, each with attributes, including geometric and semantic information. Thus, for each vehicle n, the lane representation at step t is expressed as , and the complete lane input of N vehicles is .
4.2. Multi-Source Input Encoder
To capture both dynamic agent interactions and static road semantics, we propose a two-branch encoder consisting of a trajectory encoder and a lane sequence encoder, as illustrated in
Figure 3.
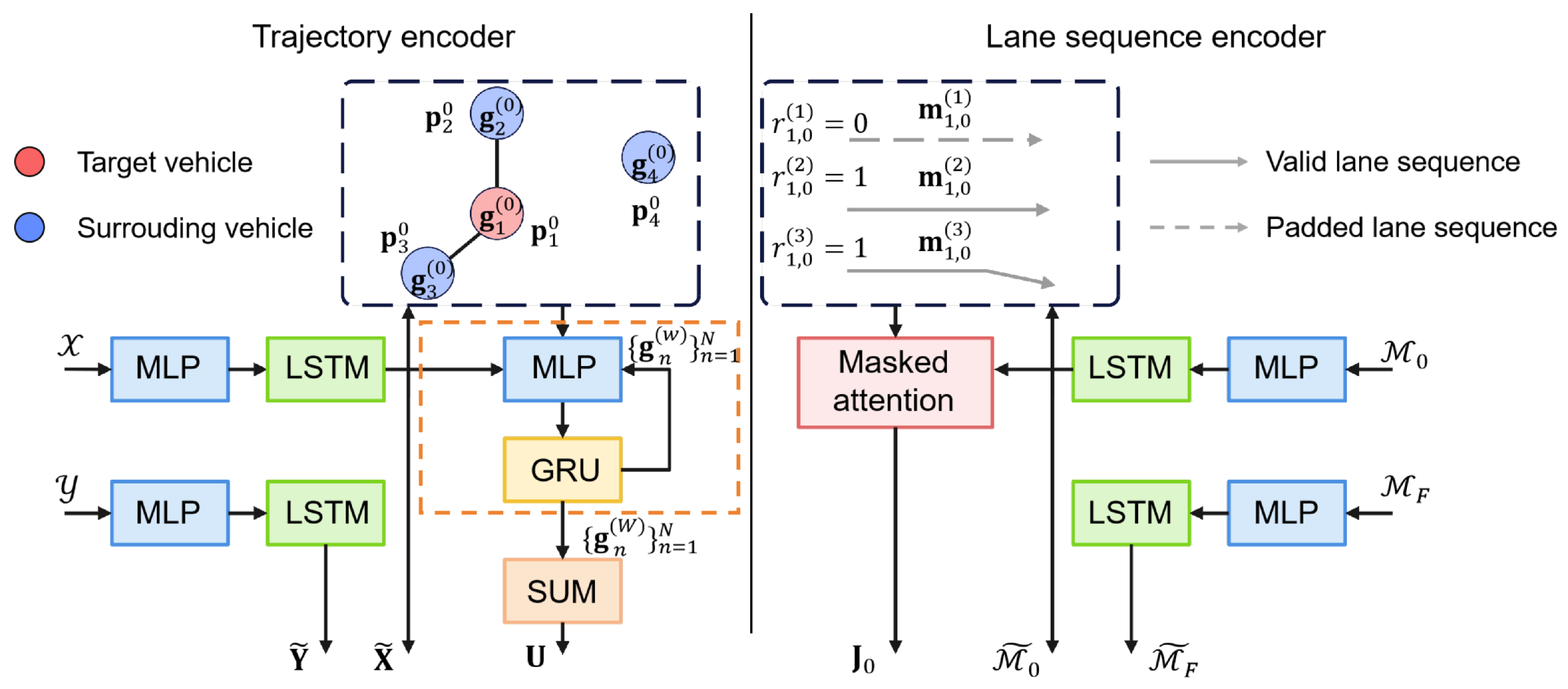
4.2.1. Trajectory Encoder
To capture both individual motion patterns and inter-agent interactions, the model adopts a two-stage encoding scheme. As illustrated in the left part of
Figure 3, it first uses LSTM networks to encode temporal trajectories, followed by a GNN that models spatial interactions through message passing over a proximity-based graph.
The motion history and future trajectory of each vehicle are represented as temporal sequences of state vectors. At each step, an Multi-Layer Perceptron (MLP) encodes the raw state information into a latent feature space of dimension . For each sequence, the final hidden state of the corresponding LSTM is extracted as a compact representation of the entire sequence. This process yields the encoded matrices and . Specifically, denotes the historical trajectory embedding of the n-th vehicle.
To model inter-vehicle interactions, we construct a proximity-based interaction graph where each vehicle is treated as a node. Vehicle
j is considered a neighbor of vehicle
n if the Euclidean distance between their positions at the initial time step satisfies
, where
and
denote the positions of vehicles
n and
j at time step
, respectively, and
is a predefined distance threshold. The neighbor set of vehicle
n is thus defined as
. The node state
is initialized with its historical trajectory embedding
and subsequently updated through
W iterations of message passing. For each node pair
at iteration
w, the message vector
is computed by applying an MLP to the concatenation of the relative position and both node features:
Here,
denotes vector concatenation. Messages from neighbors are aggregated via summation and used to update node features through a GRU-based message passing mechanism:
Finally, the interaction embedding for vehicle
n is computed by pooling the features of its spatial neighbors in the final layer:
resulting in the interaction representation matrix
for all vehicles.
4.2.2. Lane Sequence Encoder
To incorporate spatial context from road topology, the model encodes lane segments based on their geometric and semantic features. An MLP-LSTM pipeline processes these centerline sequences, followed by masked attention to derive a lane-aware context for each vehicle. This process is outlined in the right part of
Figure 3.
Each lane segment is represented as a sequence of centerline points enriched with geometric and semantic attributes. These sequences are encoded through an MLP followed by an LSTM, producing a feature vector for each lane at both time steps
and
. The resulting feature tensors are
and
. To effectively capture the spatial context around each vehicle, we compute attention weights using a masked attention mechanism among all lane embeddings at time
. Given
M lane features
, the attention score between lanes
u and
v is computed as
, and the normalized attention weight is given by
A binary mask
is applied to exclude padded inputs. The global lane-aware feature for vehicle
n is
Stacking the outputs for all vehicles yields the global context feature matrix
.
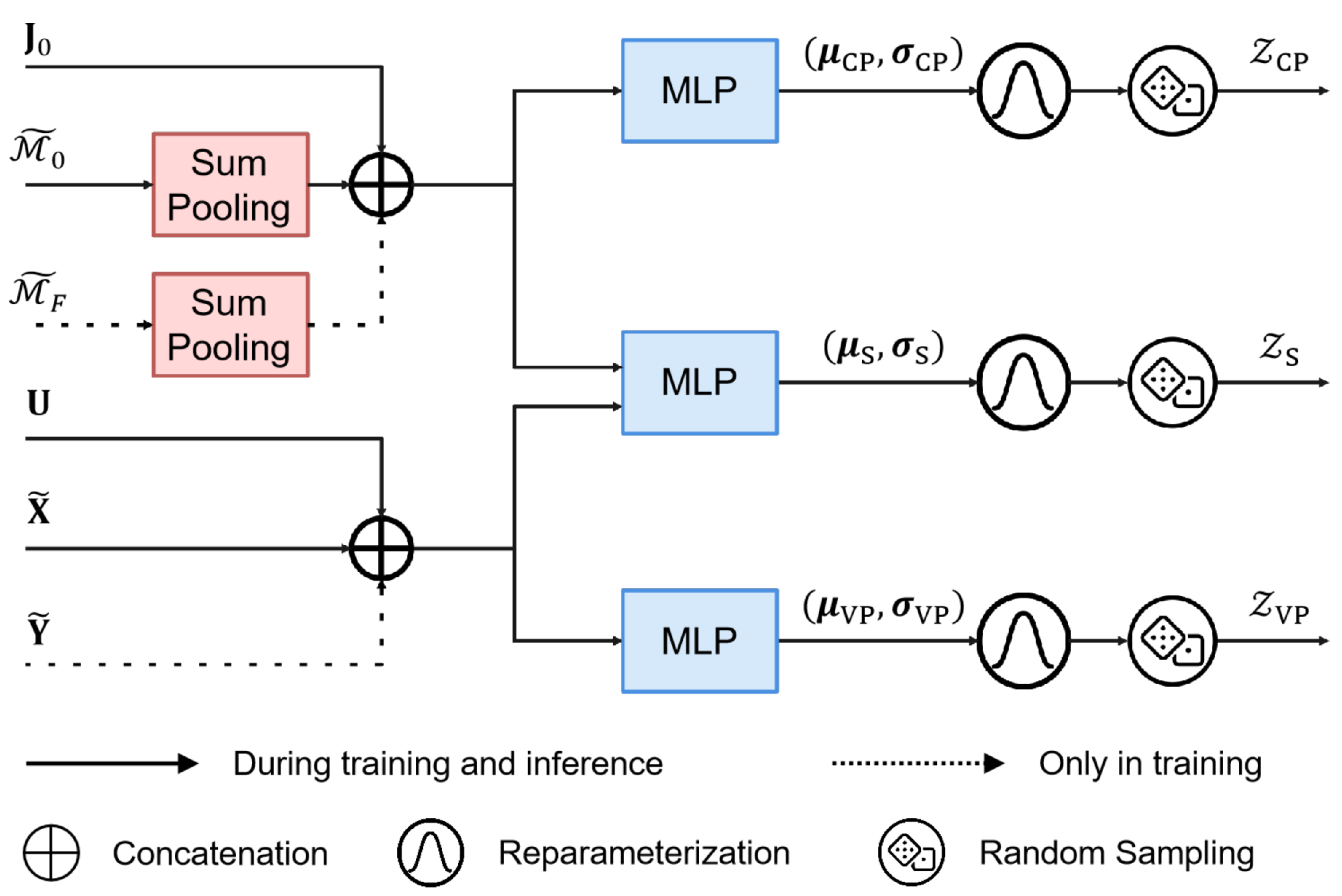
4.3. Latent Variable Encoder
To capture uncertainty and disentangle vehicle-specific and lane-specific factors, the introduced structured latent variables
,
, and
are modeled as
where the normal distributions
,
, and
correspond to the vehicle-specific, lane-specific, and shared latent variables, with each pair
denoting the mean and standard deviation of the corresponding Gaussian distribution.
Each posterior distribution is parameterized by an MLP tailored to specific input features, as illustrated in
Figure 4. The vehicle-specific latent variable
is conditioned on the encoded past and future trajectories
and
, along with the interaction-aware feature
. For the lane-specific latent variable
, lane encodings
and
are aggregated using sum pooling along the lane dimension and combined with the global context vector
. The shared latent variable
fuses vehicle and lane inputs to capture modality-independent factors. During training, latent variables are sampled using the reparameterization trick; during inference, they are drawn from priors with the same architecture, excluding future information
and
. The resulting latent tensors
,
, and
, generated via
K random samplings, serve as disentangled factors that guide both trajectory and lane sequence predictions, effectively capturing vehicle-specific, lane-specific, and shared uncertainties.
4.4. Multi-Task Prediction
We jointly predict future trajectories and corresponding lane-level motion intentions, introduced as follows.
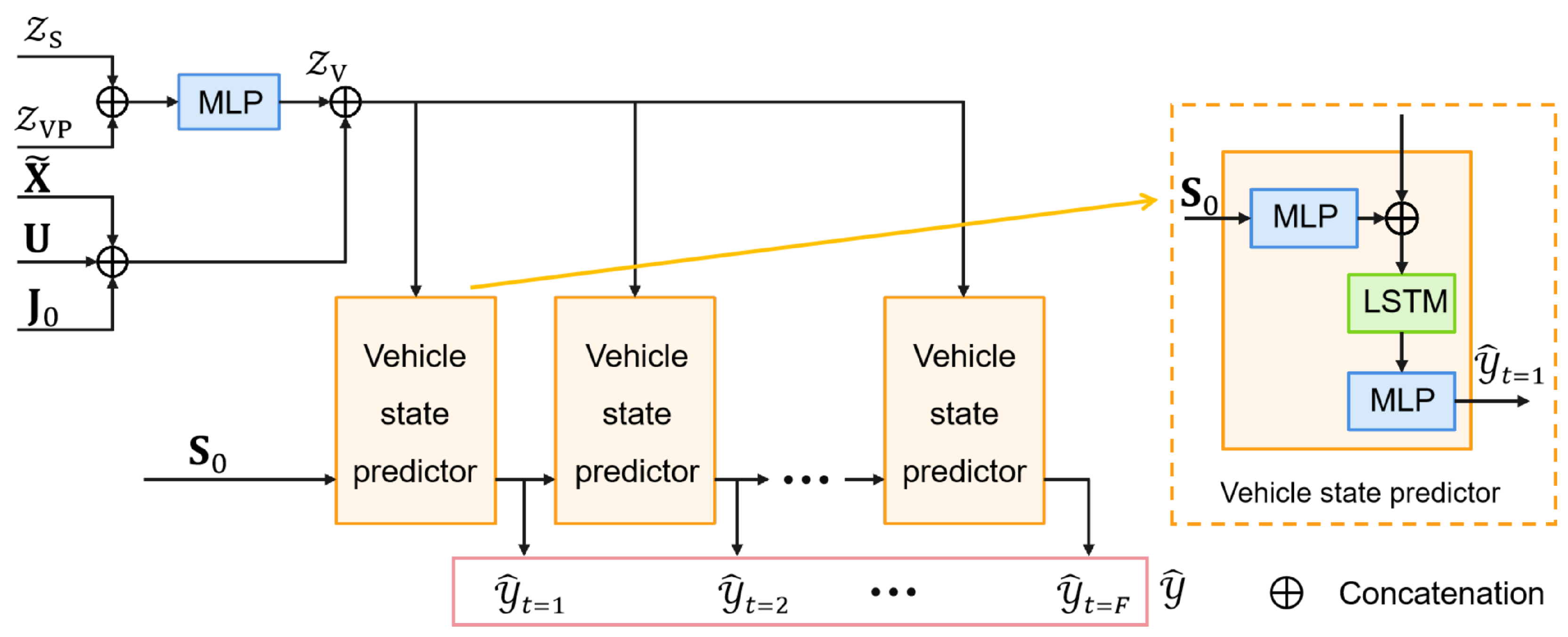
4.4.1. Trajectory Prediction
The structure of trajectory prediction component is shown in
Figure 5. To generate
K multimodal trajectories for each vehicle, the vehicle-specific latent
and shared latent
are fused through an MLP to form the complete latent feature
. This feature is combined with the historical encoding
, interaction-aware feature
, and global lane context
to construct a unified context vector for decoding. Starting from the current state
, an LSTM decoder autoregressively generates
K trajectory hypotheses
, effectively capturing multiple plausible futures under varying contextual conditions.
4.4.2. Lane Sequence Prediction
The structure of the lane sequence prediction component is illustrated in
Figure 6. To promote effective disentanglement and stable learning of latent variables, the lane sequence prediction task is introduced as an auxiliary supervision signal.
To model lane-level motion intent, the lane-specific latent and shared latent are fused through an MLP to form the composite latent vector . This vector interacts with candidate lane features via a multi-head attention (MHA) module, where the fused vehicle-lane context serves as the query and lane features as the key and value, modulated by the global lane context . For each candidate lane m, the model generates K future lane sequences of length L, forming . Aggregating over all vehicles, the predicted lane sequences are structured as , enabling to jointly reason over vehicle intent and scene topology.
This auxiliary task encourages the lane-specific latent
to specialize in encoding road environment features, while the vehicle-specific latent
focuses on personalized vehicle dynamics. Meanwhile, the shared latent
effectively captures common features, preventing mode collapse and enhancing the interpretability of the latent space. The beneficial role of this auxiliary task is further supported by the experimental results presented in
Section 5.3.
4.5. Objective Function
Within the CVAE framework, trajectory and lane sequence prediction are formulated as reconstruction tasks, with Gaussian observation noise modeled through Mean Squared Error (MSE). For vehicle trajectories, the reconstruction loss is defined as the average MSE across all vehicles, prediction steps, and
K samples, capturing the discrepancy between predicted and ground-truth trajectories:
To account for mode coverage and mitigate the impact of outliers in lane sequence prediction, we adopt a minimum-MSE loss over
K hypotheses, following the multiple-choice learning framework [
22]:
The overall objective, as defined in Equation (
3), integrates the reconstruction terms with a KL divergence regularization, incorporating both TC and DW-KL components:
Here,
balances the importance of lane sequence reconstruction,
scales the KL term, and
and
control the contributions of TC and DW-KL terms, respectively.
5. Experiments
This section begins with the experimental settings, followed by overall performance comparison, ablation studies, and qualitative visualization.
5.1. Experiment Settings
We evaluate the proposed framework using the nuScenes dataset [
23], which comprises 1000 driving scenes with high-definition maps and annotated 3D bounding boxes. The input data consists of 2 s of historical trajectories sampled at 2 Hz, utilized to predict the 6 s of vehicle motion. For each target vehicle, we consider surrounding agents within a 50 m radius (
) and extract lane features from a
region centered on the target vehicle. The main hyperparameters of the model are set as follows: the input feature dimensions for vehicles and lanes are
and
, respectively; the vehicle and lane embedding dimensions are
and
; the dimensions of the personalized latent variables for vehicles and lanes are
and
; and the dimension of the shared latent variable is
. The KL divergence weight is gradually increased from an initial value
to
following a sigmoidal annealing schedule:
where
E is the training epoch,
controls the steepness, and
is the center of the curve.
We evaluate performance using
and
[
15], which measure the average and final displacement errors between the ground truth and the best of
K predicted trajectories per sample:
All displacement-based metrics (
,
) are reported in meters throughout the paper. In addition to evaluating the diversity and physical feasibility of predictions, we include the Miss Rate at top-
K (
) and Off-Road Rate (ORR). The Miss Rate measures the fraction of agents for which none of the predicted trajectories fall within 2 m of the ground truth at the final time step. This metric reflects the model’s ability to generate at least one accurate prediction among
K candidates:
where the indicator function
is used to count the number of missed predictions, equal to 1 if the minimum distance between any predicted trajectory and the ground truth exceeds the threshold.
The Off-Road Rate quantifies the proportion of predicted trajectories that leave the drivable area as defined by the map. This metric captures whether predictions are physically realistic and conform to road constraints:
All experiments are conducted on an Ubuntu 22.04.4 system equipped with an Intel 16-core CPU (2.3 GHz), 128 GB of RAM, and a single NVIDIA RTX 3080 Ti GPU.
5.2. Comparison Experiments
We evaluate MS-SLV against five state-of-the-art baselines, i.e., Constant Velocity and Heading Angle (CVHA) [
24] (physics-based model), Physics Oracle [
24] (heuristic approach), MTP [
25], MultiPath [
26], and AgentFormer [
2]. Specifically, CVHA assumes constant speed and heading throughout the prediction horizon and Physics Oracle selects the best outcome from four physics-driven variants based on velocity, acceleration, and angular data. MTP employs a CNN-based architecture to generate a fixed number of trajectories, optimized through regression and classification losses. MultiPath [
26] learns anchor trajectories and regresses residuals relative to these anchors to capture plausible future motions. AgentFormer [
2] combines a CVAE with Transformers to model multimodal distributions, employing a staged training approach to first learn trajectory dependencies and then refine latent distributions. To assess the robustness of performance differences, the results of the proposed method are averaged over five independent runs with different random seeds. We report the mean and standard deviation of
and
. The symbol “↓” indicates that a lower value represents better performance.
Quantitative results for predicted trajectories
are summarized in
Table 1, evaluated using
and
defined in (
13). At
, the MS-SLV achieves the lowest
and
, indicating its effectiveness in modeling dominant motion patterns such as routine driving and turning behaviors. At
, MS-SLV still outperforms all baselines, demonstrating a substantial reduction in
compared to AgentFormer and MultiPath, reflecting its ability to generate diverse yet contextually aligned trajectories. As for
, MS-SLV maintains competitive performance, achieving the lowest
and a comparable
, highlighting its robustness in multimodal prediction across varying levels of trajectory diversity.
Table 2 presents the quantitative comparison of different methods on the nuScenes dataset. The proposed method, MS-SLV, achieves the best performance in terms of both prediction accuracy and safety. Specifically, MS-SLV reduces the
to 48% and
to 40%, outperforming both MTP (74% and 67%) and MultiPath (78% and 76%). This indicates that our method better captures future trajectories within a limited number of prediction modes. In addition, the ORR is reduced to 9%, showing that MS-SLV generates more feasible and road-compliant predictions. The small standard deviations further demonstrate the consistency of our results across training runs.
5.3. Ablation Study on Modules
First, to assess the impact of lane-related components, we conduct an ablation study with two experimental settings on the nuScenes dataset. In the first setting (Group 1), only vehicle trajectories are used as input, with all lane features excluded. In the second setting (Group 2), lane features are included, but the auxiliary lane sequence prediction task is disabled. As shown in
Table 3, the exclusion of lane inputs in Group 1 leads to a marked decline in performance, particularly in
, highlighting the critical role of scene context in long-term endpoint prediction. Higher
and ORR values compared to the full model indicate more frequent prediction failures and less trajectory diversity. Comparing Group 2 with the complete model further underscores the benefits of the auxiliary lane sequence prediction task, which provides additional supervision for the lane-related latent variable
. The inclusion of this auxiliary task not only improves overall accuracy but also stabilizes training by mitigating overfitting through multi-task regularization.
Secondly, we analyze how map input availability affects model performance. The model encodes the sequence of surrounding lanes associated with the target agent at each time step, explicitly incorporating road structure and environmental constraints into trajectory and interaction representations. This design makes the model inherently reliant on complete map information. As shown in
Table 4, with full map availability (100%), the model achieves optimal accuracy by effectively modeling agent–environment interactions. In contrast, at 75% and 50% availability, multimodal prediction errors (
and
) increase notably across different values of
K, indicating that missing map context impairs the model’s ability to capture dominant motion patterns and generate diverse, plausible futures. Notably,
shows a larger relative increase than
, reflecting a greater sensitivity in long-horizon prediction to incomplete map inputs. These results underscore the importance of high-quality map data for reliable forecasting.
5.4. Ablation Analysis of Latent Variables
We investigate the design of the structured latent variables from composition and dimensionality perspectives.
5.4.1. Latent Composition
To assess the contribution of each latent component, we conduct ablation studies by selectively enabling
(vehicle-specific),
(lane-specific), and
(shared) latent variables. The results illustrated in
Table 5 reveal that using only
overlooks scene context, using only
fails to capture vehicle-specific details, and using only
lacks specificity. Incorporating all components improves performance but introduces redundancy, while the optimal configuration is achieved with the combination of
and
, showing the effectiveness of disentangled representations. Notably, the weaker performance of the
-only configuration (as shown in
Table 5 and
Table 6) stems from two factors: (i) lane-level features alone cannot differentiate vehicles with distinct motion intentions but similar spatial context; and (ii) lane encodings tend to be homogeneous across nearby agents, reducing the representational diversity of
. This leads to less personalized and sometimes mode-collapsed predictions, reflected in elevated miss rates and reduced robustness.
5.4.2. Latent Dimensionality
The impact of latent dimensionality is further examined by varying the size of each latent component, as shown in
Table 7. The dimensions
(
),
(
), and
(
) correspond to the latent variables introduced in
Section 4.3. Setting the individual-specific dimensions to four and shared dimension to eight (Group 4) achieves the best trade-off between accuracy and diversity. Reducing the dimensions constrains MS-SLV’s capacity, whereas excessively large dimensions lead to overfitting and increased noise. Expanding only
(Group 5) degrades performance due to redundant lane encoding, but this can be mitigated by increasing the size of
(Group 6). Further increasing both components simultaneously (Group 3) does not yield additional gains, indicating that the optimal latent dimensionality requires joint tuning across all components.
Furthermore, we observe a performance drop when the lane-specific latent becomes overly highly dimensional (e.g., Groups 5 and 6). Although is not directly used for trajectory decoding, increasing its capacity may cause the model to overfit to fine-grained lane variations—such as slight curvature or width differences—that do not generalize across scenes. This over-specialization can interfere with shared or vehicle-specific representations, leading to entangled or redundant encodings. In addition, higher-dimensional latents increase memory and compute overhead during training and inference, especially in multi-agent settings. These results highlight a key trade-off: while more expressive latents offer modeling flexibility, excessive capacity in auxiliary components like can harm generalization and efficiency. This underscores the importance of proper dimension tuning to balance flexibility and generalization.
5.5. Impact of Regularization Weight
We investigate the impact of regularization weight from KL term decomposition and KL weighting strategy aspects.
5.5.1. KL Term Decomposition
To enhance the disentanglement of structured latent variables, we decompose the KL divergence into TC and DW-KL components, each with separate regularization terms for the three latent variables. The impact of this decomposition is examined in
Table 8. The results indicate that both weighting coefficients play a crucial role in training stability and predictive performance. TC regularization appears crucial for stable training and consistent latent structuring, as evidenced by the performance with
. In contrast, DW-KL primarily contributes to improved predictive accuracy. These findings demonstrate the complementary roles of TC and DW-KL in effectively structuring the latent space.
5.5.2. KL Weighting Strategy
We further investigate the impact of static versus dynamic scheduling strategies for KL weights. The dynamic schedule follows a sigmoidal curve parameterized by
under three configurations: Fast
, High
, and Steady
. As reported in
Table 9, the Steady schedule achieves the optimal balance between reconstruction fidelity and latent structure across varying sample sizes. In contrast, overly aggressive dynamics or weak static weights degrade performance, particularly when the number of predicted samples
is small, highlighting the importance of calibrated KL weight scheduling in stabilizing training dynamics.
5.6. Computational Efficiency
To evaluate the real-time performance of the proposed MS-SLV model, we measure its per-sample inference time on an NVIDIA RTX 3080 Ti GPU. The model achieves an average inference time of 40.6 ms with a standard deviation of 3.8 ms, corresponding to a throughput of approximately 24.6 samples per second. For comparison, AgentFormer—another CVAE-based generative model for trajectory prediction—requires 99.6 ms per sample on the same hardware. This highlights the efficiency of our multi-task architecture, making it suitable for real-time deployment.
Regarding training efficiency, MS-SLV consumes around 520 MiB of GPU memory per sample during inference and requires 0.273 Giga Floating Point Operations (GFLOPs), which is lower than our reimplementation of AgentFormer (634 MiB, 3.084 GFLOPs) under the same hardware conditions. These results demonstrate that MS-SLV achieves superior runtime efficiency in both memory usage and computational complexity while remaining lightweight enough for real-time deployment.
Additionally, MS-SLV takes approximately 0.31 h per epoch on a single RTX 3080 Ti GPU and typically converges within 50 epochs. By contrast, AgentFormer requires about 0.66 h per epoch and converges within 100 epochs under identical hardware and training configurations. This demonstrates that MS-SLV achieves improved training efficiency in both per-epoch speed and total training time.
5.7. Qualitative Analysis and Visualization
To better understand the behavior of MS-SLV across diverse traffic scenarios, we qualitatively examine predicted trajectories in conjunction with lane geometry, surrounding vehicles, and temporal evolution.
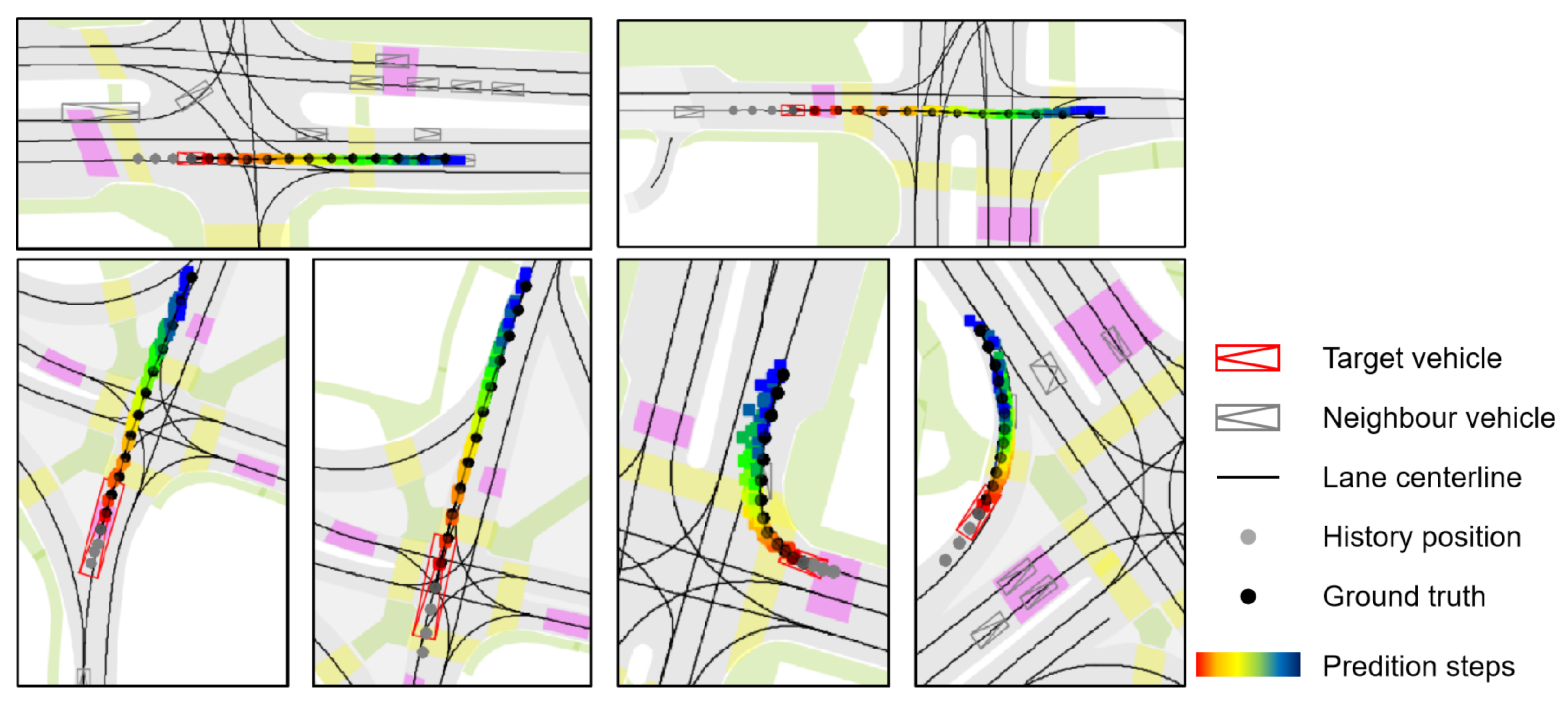
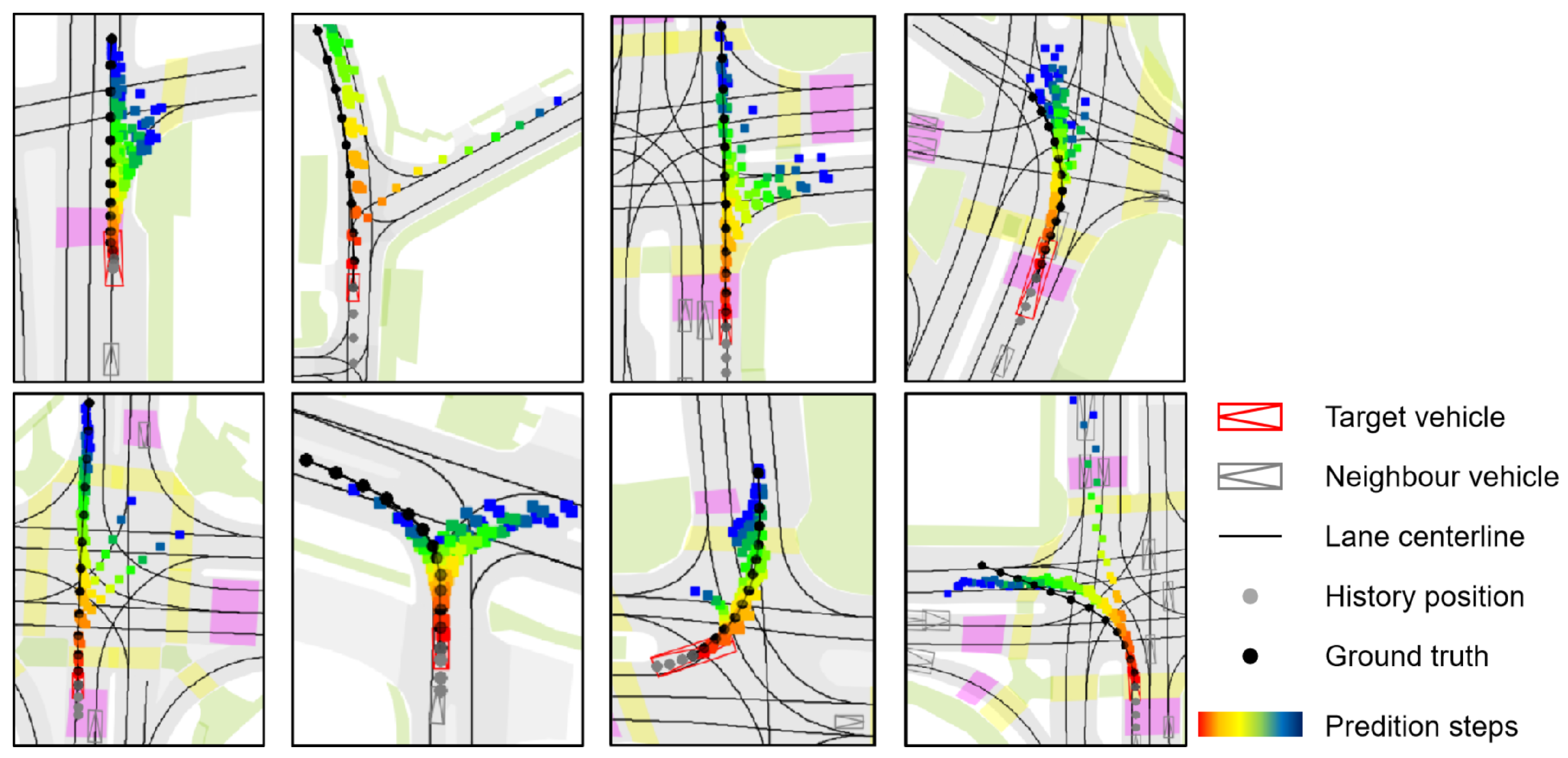
Visualization legend. In
Figure 7 and
Figure 8, vehicles are shown as composite symbols combining rectangles and triangles, with triangles indicating heading direction. The red symbol marks the target vehicle; gray symbols denote surrounding vehicles. Solid black lines represent lane centerlines from HD maps. The target vehicle’s historical trajectory is shown as gray dots and its ground-truth future trajectory as black dots. Predicted future positions use color-coded dots from red to dark blue, indicating progression over time, with red corresponding to earlier time steps and blue to later time steps.
Figure 7 illustrates MS-SLV’s predictions in simple driving scenarios, such as straight driving or gentle turns. The predicted trajectories align closely with the ground truth, indicating high precision and temporal consistency. The model captures variations in vehicle speed, lane curvature, and local agent interactions, maintaining accuracy even in denser contexts. This confirms MS-SLV’s ability to model deterministic behavior patterns when the motion intent is relatively unambiguous.
Figure 8 focuses on more complex and uncertain driving situations, including intersections, merges, and multi-path zones. In these cases, the model produces multiple plausible futures, with distinct trajectory branches clearly visible through their diverging spatial paths and temporal color gradients. This reflects MS-SLV’s capacity to capture multimodal intent and leverage lane semantics to generate scene-consistent alternatives. The predicted modes respect road structure and remain feasible under dynamic constraints, highlighting the model’s robustness in uncertain environments.
Overall, these visualizations reinforce our quantitative findings: MS-SLV generates accurate predictions in low-uncertainty settings and maintains high diversity in ambiguous scenarios, supporting safe and reliable motion forecasting across varied traffic contexts.
5.8. Result and Discussion
We conduct comprehensive experiments on the nuScenes dataset to assess the performance, component contributions, regularization effects, and deployment practicality of the proposed MS-SLV model.
Overall performance. MS-SLV achieves state-of-the-art results across all core metrics on the nuScenes dataset (
Table 1). It consistently outperforms five strong baselines in both accuracy (e.g., lowest
and
) and diversity (notably lower
,
, and ORR). These improvements validate the effectiveness of its structured latent design and auxiliary scene supervision.
Ablation study on model components. We ablate lane-related components to assess the role of scene context and auxiliary supervision. Removing lane inputs or disabling the auxiliary lane sequence task (
Table 3) leads to clear drops in accuracy and diversity, especially in long-horizon
, confirming the value of spatial cues and multi-task learning for structured latent modeling. Additionally, map availability experiments (
Table 4) show that performance deteriorates as lane context decreases, with larger impacts on
. This highlights the model’s strong reliance on complete map inputs.
Latent variable structure and regularization. We evaluate how latent composition and regularization affect performance. Combining vehicle-specific and shared achieves the best results, validating the benefit of disentangled latent modeling. Lane-specific alone is less effective due to limited agent discrimination. Moderate latent dimensions (e.g., , ) strike a good balance between expressiveness and generalization. Regularizing KL divergence via TC and DW-KL further improves stability and accuracy. A steady KL annealing schedule proves most robust across sampling settings, highlighting the importance of calibrated regularization in latent space learning.
Computational efficiency and qualitative insights. MS-SLV demonstrates real-time performance, with 40.6 ms inference time per sample, while maintaining low memory and computational cost. Compared to baseline, it offers faster inference, a reduced GPU memory footprint, and more efficient training. These results collectively validate MS-SLV’s suitability for real-time applications under hardware constraints.
In summary, the proposed MS-SLV framework achieves state-of-the-art performance through effective integration of structured latent variables, auxiliary supervision, and scene-aware reasoning. Each component—from model architecture to regularization and input encoding—contributes meaningfully to accurate, diverse, and reliable trajectory prediction.
6. Conclusions
To achieve both accuracy and diversity in trajectory prediction, it is essential to capture the evolving spatial context induced by vehicle motion, which depends critically on the effective fusion of multimodal inputs—including dynamic vehicle states and static HD map features. To this end, we propose MS-SLV, a unified framework that leverages time-aware scene encoding, structured latent space modeling, and multi-task generative learning. MS-SLV disentangles vehicle-specific and scene-shared factors and incorporates lane sequence prediction to improve multimodal trajectory forecasting performance. Comparison experiments on the nuScenes dataset demonstrate consistent improvements over baselines in multimodal prediction accuracy, with up to a 12.37% reduction in ADE and 7.67% in FDE, as well as 26% and 33% reductions in and , respectively, and a 3% drop in ORR. These results demonstrate that MS-SLV achieves accurate, diverse, and physically plausible trajectory predictions. The model also maintains robust performance across varying numbers of predicted trajectories, highlighting its strong mode coverage. Extensive ablation studies validate the effectiveness of structural latent modeling, joint trajectory and lane sequence prediction, and the regularization terms in shaping the latent space. Furthermore, our qualitative results confirm that the proposed MS-SLV framework is capable of generating diverse and scene-compliant future trajectories. Visualizations in complex scenarios, including intersections, demonstrate its potential to capture multimodal futures consistent with the scene context, indicating robustness in challenging conditions.
While MS-SLV demonstrates strong performance, it has several limitations. The framework involves relatively high computational complexity due to latent variable sampling and lane sequence prediction. It also relies heavily on accurate HD map data, which may not always be available or up-to-date in real-world scenarios. Moreover, although evaluated on the nuScenes dataset, further assessment on diverse datasets is necessary to verify the model’s generalization capabilities. Future work may explore incorporating environmental factors such as weather conditions (e.g., rain, snow, fog) and road surface states (e.g., wet or icy surfaces), which significantly affect vehicle behavior and trajectory prediction accuracy. Our framework naturally supports the integration of these factors as additional input modalities, such as through sensor data or external environmental information, which can enhance context-aware trajectory prediction. Moreover, the model’s robustness and generalizability can be further assessed by testing it under diverse scenarios, including complex traffic patterns and adverse weather conditions, through the use of broader datasets and simulation environments. Additionally, efforts to reduce prediction latency will be essential for enabling real-time deployment in safety-critical applications. Incorporating these factors into the MS-SLV framework could improve prediction accuracy and applicability across varied driving scenarios.
Author Contributions
Conceptualization, H.C. and N.L.; Methodology, H.C. and H.S.; Software, H.C.; Validation, H.C.; Formal analysis, H.C. and H.S.; Writing—original draft preparation, H.C.; Writing—review and editing, H.C., N.L., H.S., E.L., and Z.X.; Visualization, H.C.; Supervision, H.S.; Funding acquisition, H.S. and Z.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (NSFC) under Grants U21B2029 and U21A20456, in part by the Zhejiang Provincial Natural Science Foundation of China under Grant LR23F010006, in by Zhejiang Province Key R&D programs of China under Grant No. 2025C01039, in part by the Science and Technology Development Fund (SKLIOTSC(UM)-2024-2026), and in part by the State Key Laboratory of Internet of Things for Smart Cities (University of Macau) (Ref. No.: SKL-IoTSC(UM)-2024-2026/ORP/GA01/2023).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in this study are publicly available as part of the nuScenes dataset, which can be accessed at
https://www.nuscenes.org (accessed on 10 June 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IMUs | Inertial Measurement Units |
| HD | High Definition |
| MS-SLV | Multi-Source Input with Structured Latent Variable Model |
| CNNs | Convolutional Neural Networks |
| GNNs | Graph Neural Networks |
| LSTMs | Long Short-Term Memory networks |
| GANs | Generative Adversarial Networks |
| VAEs | Variational Autoencoders |
| CVAEs | Conditional Variational Autoencoders |
| MLP | Multi-Layer Perceptron |
| GRUs | Gated Recurrent Units |
| ELBO | Evidence Lower Bound |
| KL | Kullback–Leibler Divergence |
| ADE | Average Displacement Error |
| FDE | Final Displacement Error |
| MR | Miss Rate |
| ORR | Off-Road Rate |
| TC | Total Correlation |
| GFLOPs | Giga Floating Point Operations |
| DW-KL | Dimension-Wise KL Divergence |
Appendix A. Derivation of the ELBO with Structured Latent Variables
Appendix A.1. Evidence for Lower Bound CVAE with Structured Latent Variables
To address the limitations of simplistic priors and insufficient dependency modeling between motion and spatial context, we enhance the standard CVAE by incorporating structured latent variables, as introduced in Equation (
1).
Given the inputs
and
and the latent variables
and
, we assume that the vehicle motion modality output
and the map information modality output
are conditionally independent. Under this assumption, the reconstruction error in the first term on the right-hand side of Equation (
1) can be decomposed into two separate parts. Based on the above assumption, the reconstruction error term can be rewritten as follows:
Equation (
A1) decomposes the original joint probability density function into two independent conditional probability density functions, demonstrating that the decomposition of the vehicle trajectory prediction task and the lane sequence prediction task is feasible. This supports the use of two independent decoders or functions to separately predict
and
.
Considering the decomposition of latent variables
and
introduced in
Section 3.2, we let
and
where
and
encode the factors specific to vehicle dynamics and lane-level map semantics and
represents the latent features shared between the two modalities. Based on this decomposition, we now revisit the reconstruction term in Equation (
A1), which expresses the expected log-likelihood of motion prediction conditioned on the latent variables. Substituting the structured form of the latent space yields
Given the conditional independence assumption that
we can simplify the above expression to
Similarly, since the scene map output
and the vehicle-specific latent variable
are conditionally independent given
and
, the second term in the decomposition of Equation (
A1) can be simplified as follows:
To complete the derivation, we next consider the KL term in the ELBO, where the independence assumption allows for a tractable decomposition. Assuming independence between
and
, the KL term in Equation (
1) can be decomposed as follows:
Combining the results from Equations (
A1) to (
A6), the lower bound for the multi-source CVAE with structured latent variables is given by Equation (
2) in
Section 3.3.
Appendix A.2. Incorporating Total Correlation Regularization
Despite the inductive bias introduced by the structured latent variable model to separate individual-specific (, ) and shared () representations, residual statistical entanglement may still persist among these latent components. Such dependencies can result in redundant encoding and compromise the disentanglement of the latent space.
To further encourage independent factorization, we incorporate a TC decomposition term into the variational objective. The TC regularizer penalizes mutual dependence among the latent dimensions, promoting a more disentangled and interpretable latent structure.
The KL term related to
in Equation (
2) can be expressed in its TC-decomposed form:
Similarly, the KL term related to
in Equation (
2) can be decomposed as follows:
Considering the independence between
and the map information
, the terms in Equations (
A7) and (
A8) that involve only the latent variable
are not conditional on
or
. Similarly, given the independence between
and vehicle motion, the terms involving only
do not depend on
or
. Incorporating the decompositions from Equations (
A7) and (
A8) into Equation (
2) yields the ELBO with TC regularization shown in Equation (
3).
References
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12118–12126. [Google Scholar]
- Yuan, Y.; Weng, X.; Ou, Y.; Kitani, K. AgentFormer: Agent-aware transformers for socio-temporal multi-agent forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9793–9803. [Google Scholar]
- Liang, M.; Yang, B.; Hu, R.; Chen, Y.; Liao, R.; Feng, S.; Urtasun, R. Learning lane graph representations for motion forecasting. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 541–556. [Google Scholar]
- Ngiam, J.; Caine, B.; Vasudevan, V.; Zhang, Z.; Chiang, H.L.; Ling, J.; Roelofs, R.; Bewley, A.; Liu, C.; Venugopal, A.; et al. Scene transformer: A unified architecture for predicting multiple agent trajectories. arXiv 2021, arXiv:2106.08417. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Kingma, D.P. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Adv. Neural Inf. Process. Syst. 2015, 2, 3483–3491. [Google Scholar]
- Huang, R.; Xue, H.; Pagnucco, M.; Salim, F.; Song, Y. Multimodal trajectory prediction: A survey. arXiv 2023, arXiv:2302.10463. [Google Scholar]
- Kim, H.; Mnih, A. Disentangling by factorising. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1549–15498. [Google Scholar]
- Li, X.; Ying, X.; Chuah, M.C. Grip++: Enhanced graph-Based interaction-aware trajectory prediction for autonomous driving. arXiv 2020, arXiv:1907.07792. [Google Scholar]
- Gao, J.; Sun, C.; Zhao, H.; Shen, Y.; Anguelov, D.; Li, C.; Schmid, C. Vectornet: Encoding HD maps and agent dynamics from vectorized representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11522–11530. [Google Scholar]
- Zhou, Z.; Ye, L.; Wang, J.; Wu, K.; Lu, K. Hivt: Hierarchical vector transformer for multi-agent motion prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8813–8823. [Google Scholar]
- Deo, N.; Wolff, E.; Beijbom, O. Multimodal trajectory prediction conditioned on lane-Graph traversals. In Proceedings of the 5th Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021; Faust, A., Hsu, D., Neumann, G., Eds.; Proceedings of Machine Learning Research (PMLR): Cambridge, MA, USA, 2021; Volume 164, pp. 203–212. [Google Scholar]
- Gupta, A.; Johnson, J.; Li, F.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2255–2264. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. arXiv 2021, arXiv:2001.03093. [Google Scholar]
- Varadarajan, B.; Hefny, A.; Srivastava, A.; Refaat, K.S.; Nayakanti, N.; Cornman, A.; Chen, K.; Douillard, B.; Lam, C.P.; Anguelov, D.; et al. Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 7814–7821. [Google Scholar]
- Zhao, H.; Gao, J.; Lan, T.; Sun, C.; Sapp, B.; Varadarajan, B.; Shen, Y.; Shen, Y.; Chai, Y.; Schmid, C.; et al. TNT: Target-driven trajectory prediction. In Proceedings of the Conference on Robot Learning (CoRL), Virtual, 16–18 November 2020; Kober, J., Ramos, F., Tomlin, C., Eds.; PMLR: Cambridge, MA, USA, 2021; Volume 155, pp. 895–904. [Google Scholar]
- Chiara, L.F.; Coscia, P.; Das, S.; Calderara, S.; Cucchiara, R.; Ballan, L. Goal-driven self-attentive recurrent networks for trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2518–2527. [Google Scholar]
- Zhang, Y.; Su, J.; Guo, H.; Li, C.; Lv, P.; Xu, M. S-CVAE: Stacked CVAE for trajectory prediction with incremental greedy region. IEEE Trans. Intell. Transp. Syst. 2024, 25, 20351–20363. [Google Scholar] [CrossRef]
- Chen, R.T.Q.; Li, X.; Grosse, R.; Duvenaud, D. Isolating Sources of Disentanglement in Variational Autoencoders. In Advances in Neural Information Processing Systems 31, Proceedings of the International Conference on Neural Information Processing Systems 2018, Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Guzmán-rivera, A.; Batra, D.; Kohli, P. Multiple choice learning: Learning to produce multiple structured outputs. In Advances in Neural Information Processing Systems 25, Proceedings of the Advances in Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25, pp. 1799–1807. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. NuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Phan-Minh, T.; Grigore, E.C.; Boulton, F.A.; Beijbom, O.; Wolff, E.M. Covernet: Multimodal behavior prediction using trajectory sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14062–14071. [Google Scholar]
- Cui, H.; Radosavljevic, V.; Chou, F.; Lin, T.; Nguyen, T.; Huang, T.; Schneider, J.; Djuric, N. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Chai, Y.; Sapp, B.; Bansal, M.; Anguelov, D. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. In Proceedings of the Conference on Robot Learning, Osaka, Japan, 30 October–1 November 2019; pp. 86–99. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}