
MEAC: A Multi-Scale Edge-Aware Convolution Module for Robust Infrared Small-Target Detection


Abstract
1. Introduction
2. Related Work
2.1. Deep Learning-Based Infrared Small-Object Detection Methods
- Adaptation and improvement of general-purpose detection/segmentation frameworksBased on classic object detection networks such as Faster R-CNN [23,24,25] and the YOLO series [26,27], Hao et al. utilized super-resolution technology for infrared image preprocessing to enhance weak target features, and then combined it with the YOLO object detection model for detection [28]. Zhang proposed a feature fusion-based infrared weak target detection method based on Faster R-CNN, which improves the performance of infrared weak target detection by integrating feature information from different scales [29].
- Feature Fusion StrategySmall targets are prone to missing information after undergoing multiple convolutions and pooling in deep networks. To address this issue, researchers have proposed multi-layer feature fusion modules that combine high-resolution detail information from the bottom layer with semantic features from the deeper layers. Tong et al. [30] introduced an enhanced asymmetric attention (EAA) module that substantially improves the feature representation of small infrared targets through same-layer feature exchanges and cross-layer feature fusion. Additionally, methods such as Experiment [31], DFN [32], and SENet [33] achieve learnable fusion at different levels. However, pure feature fusion often fails to fully recover weak signals of small targets on deep semantic maps and must be combined with targeted feature enhancement strategies.
- Introduction of Attention MechanismsThese mechanisms guide the network to focus on the most critical regions or channels in an image, thereby improving the detection of small objects. Chen et al. proposed the Local Patch Network (LPNet) [34], which integrates global and local attention within the network. Zhang et al. proposed the Infrared Shape Network (ISNet) [35], which includes a bidirectional attention aggregation (TOAA) block to enhance sensitivity to target shape edges. As Transformers have become popular in computer vision, Liu et al. [36] were the first to apply self-attention mechanisms to infrared small-object segmentation. Additionally, Wang proposed an internal attention-aware network (IAANet) [37] with a coarse-to-fine structure to improve the network’s response to weak small targets. While the aforementioned methods have partially addressed the issue of weak infrared small-target signals, most still rely on attention guidance at higher feature levels and lack specialized optimization for basic feature extraction units in convolutional layers.
2.2. Convolution Improvement Techniques and Their Applicability to the Detection of Small Targets in the Infrared Spectrum
- Spatially adaptive convolutionDeformable Convolutional Networks DCNs [16]: By learning trainable sampling offsets, the convolution kernel can dynamically align feature locations according to the target’s geometric shape. However, infrared small targets often appear as near-circular or blurry spots with limited geometric deformation potential; thus, the geometric alignment advantage of deformable convolutions has not been fully exploited.Involution [17]: This method generates independent, learnable convolution kernels for each spatial location, achieving spatially specific filtering and enhancing local flexibility. However, it has not been specifically designed for high-contrast edges or the multi-scale contexts of small infrared targets. It is also not precise enough in suppressing background noise and extracting weak signals.
- Dynamic and Conditional ConvolutionConditional convolutions (CondConv [18], Dynamic Conv [19], and ODConv [38]) achieve adaptive responses to different inputs by dynamically adjusting the convolution kernel or its weights. Such algorithms can improve the network’s robustness to diverse backgrounds. However, their dynamic mechanisms focus more on adapting overall or large-scale features. They fail to enhance local weak target signals and fully capture the high-contrast edge information of small infrared targets.
- Feature Enhancement and Fusion ConvolutionACmix [39]: This method integrates convolution operations with self-attention mechanisms within the same module to jointly model global and local features. This enhances the network’s overall feature expression capabilities; however, the module does not include a custom design for edge features or contrast information of small infrared targets. This results in insufficient sensitivity to weak targets.Selective Kernel (SK) Convolution [40]: This approach uses multi-branch parallel processing to extract features at different scales. This allows the network to dynamically select the most appropriate receptive field based on the input. However, SK convolution only optimizes the multi-scale aspect of traditional convolution and does not process feature textures.Group convolution [41] is widely used due to its low computational cost. Compared to ordinary convolution, the number of parameters and computational complexity are both reduced by a factor of G, where G is the group size. A special case of group convolution is depth separable convolution [42], where the number of groups equals the number of channels. Although group convolutions are efficient, they have limited modeling capabilities for local details and multi-scale context, making them unsuitable for edge extraction and semantic segmentation of small infrared targets.
- Local contrast edge features:Precise extraction of high-contrast edges inherent to infrared small targets.
- Multi-scale contextual information:Acquisition of rich contextual features without sacrificing spatial resolution to distinguish targets from the background.
- Preservation of original local features:Ensures that fine-grained spatial details are not overly smoothed or weakened during multiple convolutions and fusions.
3. Method
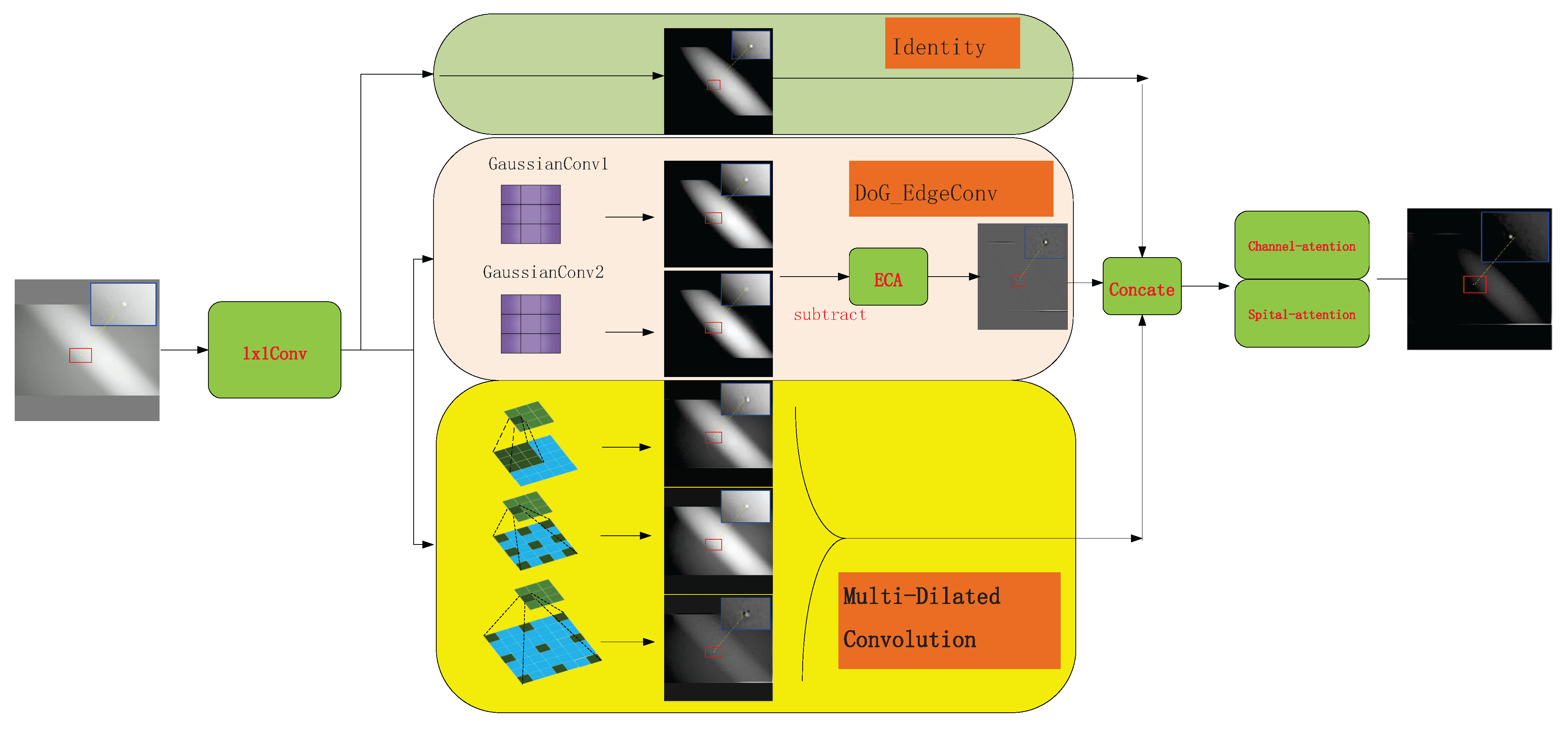
3.1. Overall Structure Design
- Initial channel mapping.
- Multi-dimensional feature extraction.
- Feature concatenation and fusion.
- Output mapping and downsampling.
3.2. Channel Mapping and Multi-Dimensional Feature Extraction
3.2.1. Channel Mapping
3.2.2. Multi-Dimensional Feature Extraction
- The feature retention branch (Equation (2)):
- Multi-scale cavity integral branch (Formula (3)):Perform parallel depth-separable convolutions in each channel of F with expansion rates of 1, 2, and 3. Denote the corresponding weights as (Equation (3)):then Concatenate along the channel dimension to obtain . Multi-scale dilated convolutions effectively expand the receptive field through a depthwise separable convolution structure, enhancing the model’s feature extraction ability while avoiding a significant increase in computational cost. The comparison of receptive fields is shown in Figure 3.
- DoG Edge Extraction Branch:Then, perform global average pooling on and use a one-dimensional convolution with a kernel size of and a sigmoid function to obtain the channel attention weights (Equation (5)):Broadcast along the spatial dimension, weighting channel-wise. Then, map back to dimensions using a convolution , yielding . At this point, the three parallel outputs are as follows:retains the original local information; extracts multi-scale spatial context; and enhances high-contrast edge features (Figure 4). Collectively, these three parallel outputs provide complementary semantic and detail information for subsequent concatenation and attention fusion.
3.3. Feature Fusion
3.3.1. Feature Concatenation
3.3.2. Channel Attention
3.3.3. Spatial Attention
3.4. Output Mapping and Downsampling
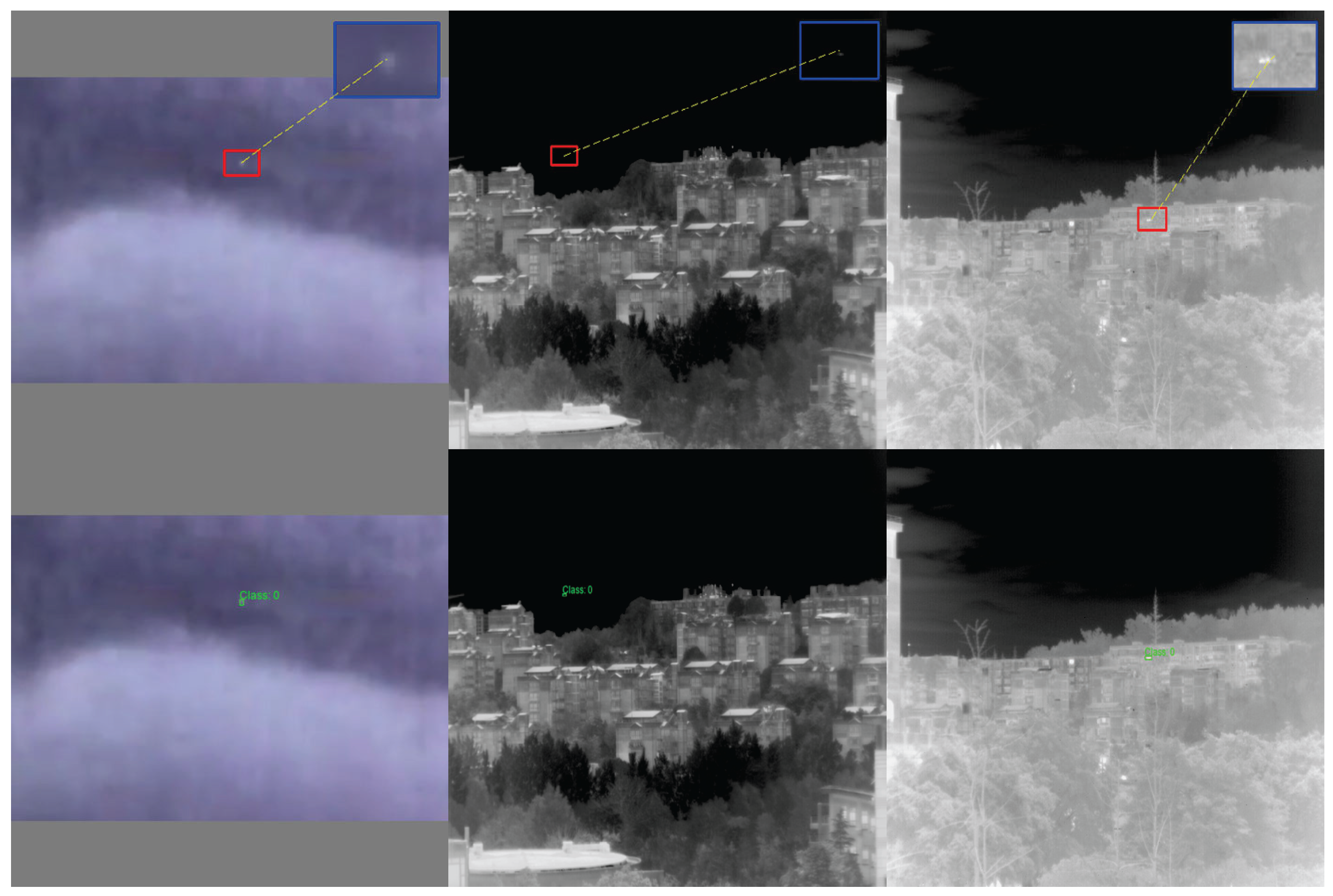
3.5. Module Visualization Results
- Enhanced feature discrimination capability: MEAC generates clearer feature maps, which makes the separation between foreground objects (objects of interest) and the background more distinct. This is evident in the higher intensity and more concentrated spatial distribution of the ’hotspot’ regions of target objects.
- Effective suppression of background noise: MEAC can significantly suppress background noise and non-critical texture information, such as complex patterns in cloudy skies or dense foliage. This greatly reduces the risk of interference from non-target elements.
- Enhanced environmental robustness: MEAC demonstrates outstanding performance in highly challenging environments, such as those with complex backgrounds (e.g., high-intensity clouds) or low visibility (e.g., nighttime scenes). It effectively avoids the performance degradation issues caused by excessive background activation in standard models.
- Optimized feature retention capability: A comparison of the first feature map clearly shows that MEAC extracts key features more effectively and ensures they are well-preserved throughout the processing workflow. This lays the foundation for more robust object detection.
4. Experiment
4.1. Experimental Environment and Evaluation Criteria
4.2. Datasets
- The IRSTD-1K [35] dataset was proposed by Zhang Mingjin et al. from Xi’an University of Electronic Science and Technology and contains 1001 infrared images with a resolution of 512 × 512. These images cover various target types, including drones, birds, ships, and vehicles. Due to the use of multispectral imaging, small targets appear extremely small and have blurred edges in environments with a low signal-to-noise ratio, creating a typical “multispectral imaging + small target” scenario with high background complexity and low contrast.
- The SIRST-UAVB [43] dataset was proposed by Yang Jiangnan et al. from Southwest University of Science and Technology. This dataset includes 3000 images with a resolution of 640 × 512 and focuses primarily on small flying targets, such as drones and birds. The scene background is similarly complex with a low signal-to-noise ratio (SNR) and signal-to-clutter ratio (SCR). This makes small targets prone to being obscured by the background, which increases detection difficulty.
- IRSTDv1 [44] was proposed by Dai Yimian et al. from Nanjing University of Aeronautics and Astronautics. This dataset includes 427 images of varying resolutions, with the highest resolution reaching 418 × 388. The targets are primarily small unmanned aerial vehicles. The main challenges of this dataset are the small target size, even at high resolutions, coupled with severe low-contrast background interference and similar textures between targets and backgrounds. Table 2 lists the basic information and main challenges of the aforementioned three datasets.
- M3FD [45] was proposed by a team from Dalian University of Technology at the 2022 CVPR conference. The dataset contains 4200 images with a resolution of 1024 × 768. It presents challenges such as low contrast at high resolution, background interference, and target shapes that are similar to the background, aiming to address the robustness of object detection in complex environments (such as at night or in foggy conditions). The primary targets include common objects such as people, cars, buses, motorcycles, streetlights, and trucks.
4.3. Ablation Experiments
- Complete model (DoGEdge + Dilated + Identity).
- Remove DoGEdge (only retain Dilated and Identity); and 3.
- Remove the Dilated layer (only retain the DoGEdge and Identity layers).
- Remove Identity (only retain DoGEdge and Dilated).
- Baseline model (conventional convolution).
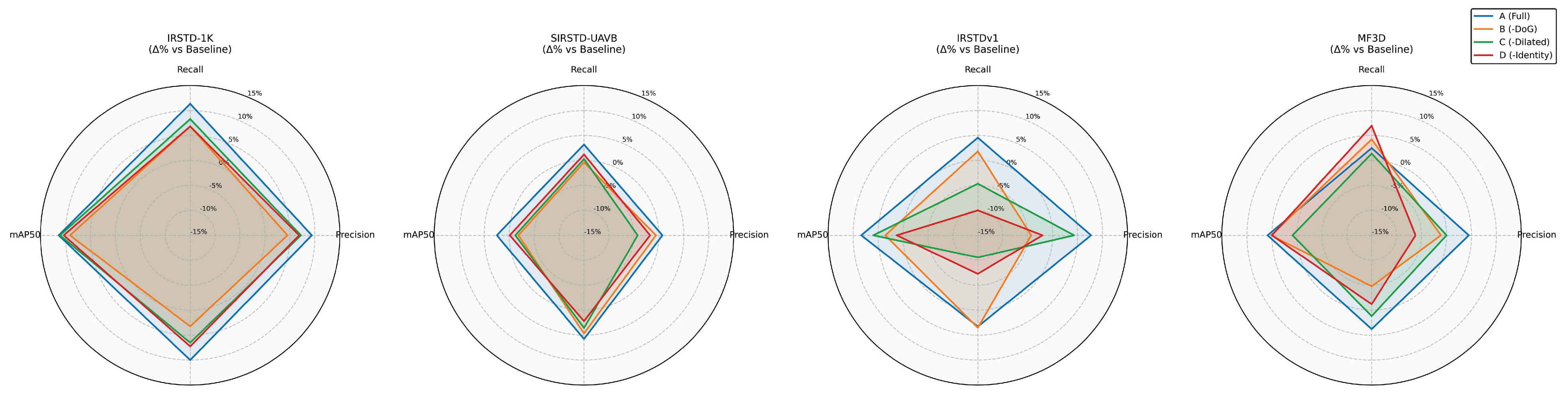
4.3.1. Quantitative Ablation Results
- Removal of DoG Edge Branches (Dilated + Identity Only)After removing the DoG edge branches, both precision and recall decreased significantly across the three datasets, particularly on IRSTD-1K. Precision dropped by 4.0%, and mAP50-95 decreased by 2.7%. This indicates that the DoG edge branches play a crucial role in amplifying high-frequency edge features. Without this branch, the model’s response to low-contrast or weakly textured small targets weakens. This leads to increased false negatives and false positives; on IRSTDv1, precision drops by 10.6%. This further demonstrates that DoGEdge is crucial for maintaining the contours of shallow targets. It significantly improves the localization accuracy and confidence of detection bounding boxes.
- Removal of the Dilated Convolution Branch (DoG Edge + Identity Only)After removing the dilated branch, recall decreased significantly across all datasets. Recall decreased by 8.1%, and mAP50-95 decreased by 5.9% on IRSTDv1. This indicates that dilated convolutions provide a larger receptive field and fuse richer contextual information at shallow layers. This effectively improves the detection capability and localization accuracy of small targets in complex backgrounds. Without this branch, the network struggles to perceive both targets and their backgrounds simultaneously at shallow layers. This leads to missed detections and localization errors in scenarios with dense multiobjects or background false hotspots.
- Removing the direct mapping branch (DoGEdge + Dilated only)Removing the identity branch significantly degrades model performance, particularly on IRSTDv1, where recall decreases by 12.8%, and precision decreases by 8.6%. The direct mapping branch provides a lossless channel between the main trunk and higher-level features. This enables the complete transmission of low-level texture details from the first layer to the second layer and beyond. When this branch is removed, small-target information in the shallow layers becomes overly compressed or smoothed. This causes small target responses to decay and edges to blur in the high-level feature maps. Consequently, detection accuracy and recall are significantly reduced.
- Baseline Model ComparisonThe complete model significantly outperforms the baseline on all three datasets. mAP50 improves by 9.1% on IRSTD-1K and by 4.0% on IRSTDv1. DoGEdge contributes most to improving precision and localization accuracy, while Dilated is most effective in improving recall and suppressing false negatives. Identity ensures the propagation of original features from the shallow layer, which is indispensable for overall training stability and detection accuracy.The results of the ablation experiment show that adding each module positively impacts model performance, especially in terms of improving accuracy, recall, and mAP50-95. The DoGEEdge module is essential for enhancing edge details and detecting small objects, while the Dilated and Identity modules are critical for multi-scale feature extraction and maintaining model stability, respectively. Integrating all modules enables the model to demonstrate strong detection capabilities across various scenarios.
- Generalization experiments on the dataset MF3DThe results of the ablation experiment show that adding each module positively impacts model performance, especially in terms of improving accuracy, recall, and mAP50-95. The DoGE module is essential for enhancing edge details and detecting small objects, while the Dilated and Identity modules are critical for multi-scale feature extraction and maintaining model stability, respectively. Integrating all modules enables the model to demonstrate strong detection capabilities across various scenarios.Overall, combining all three modules significantly enhances the model’s performance in complex scenarios, making it the recommended configuration for practical applications.
4.3.2. Qualitative Analysis
- The DoG edge branches amplify shallow, high-frequency information. After removing the DoG Edge branch and retaining only the Dilated + Identity branch, the edge signals in the second-layer feature maps at the same positions are significantly weakened (Figure 9, no edge column). This makes small targets prone to blending with the background and causes subsequent layers to more easily lose the target. In other experiments with the DoG Edge branch enabled, the contours of small targets in the second-layer feature maps are presented in high-contrast, bright colors (Figure 9), even when target contrast is extremely low. This allows clear edges to be retained in the shallow layers.
- Multi-scale fusion is realized without downsampling by the hollow roll integral branch. After removing Dilated (while retaining DoG Edge + Identity), the activation of small targets in the second-layer feature map becomes loose and fragmented (Figure 9, noDilate), and the contrast between targets and their surroundings decreases. This indicates that the lack of cross-regional context leads to incomplete responses to weak, small targets in shallow layers. When Dilated is enabled, the second-layer feature map can simultaneously “see” small targets and the surrounding, larger background without reducing resolution. This forms concentrated, coherent activation regions.
- Direct mapping branches ensure low-level detail propagation. After removing Identity (while retaining DoGEdge and Dilated), the target response in the second-layer feature map significantly decreases, and the edges become blurred (Figure 9, noiden). This leads to over-smoothing in subsequent layers, resulting in missed detections or inaccurate localization. When Identity is enabled, the low-level details extracted in the first layer can be directly transferred to the second layer. This enables small targets to retain geometric structure and contour information in higher layers.
4.3.3. Summary
4.4. Comparison of MEAC Module Insertion in Different Models and Positions
Conclusion Analysis
- YOLOv10n: Inserting MEAC between the end of the backbone and the beginning of the neck (place2) yields the most balanced and significant improvements. In particular, mAP50 increases by approximately +6.77% on IRSTDv1 and +5.13% on IRSTD-1k, and by +2.80% on SIRST-UAVB. Recall and mAP50-95 also reach their highest values. When placed at the network front (place1), gains in Precision are the most consistent (approximately +3.37% and +4.18%), whereas placing MEAC at the rear of the neck (place3) yields slightly better improvements in mAP50 and Recall on the UAVB scenario.
- YOLOv11n: The optimal insertion shifts to the network front (place1). On IRSTDv1, all four metrics achieve their maximum gains: Precision +4.85%, Recall +11.66%, mAP50 +4.45%, and mAP50-95 +4.54%. On SIRST-UAVB, performance improvements are even more pronounced (Precision +9.44%, Recall +10.11%, mAP50 +9.67%, mAP50-95 +5.79%). Although place2 yields the highest mAP50 gain (+3.31%) on IRSTD-1k, the overall performance remains inferior to place1.
- YOLOv12n: Likewise, inserting MEAC at the network front (place1) provides the most significant absolute gains. On IRSTDv1: Precision +1.24%, Recall +1.58%, mAP50 +5.92%, mAP50-95 +6.71%. On IRSTD-1k: Precision +1.13%, Recall +3.55%, mAP50 +3.78%, mAP50-95 +5.15%. On SIRST-UAVB: Precision +3.06%, Recall +3.10%, mAP50 +2.89%, mAP50-95 +1.98%. In contrast, the gains at place3 are weakest, and place2 occasionally even shows slight negative improvements in some scenarios.
4.5. Comparison with Common Convolution Modules
4.5.1. Quantitative Analysis of Comparative Experiments
- Edge Perception and Multi-Scale Fusion:MEAC combines DoG edge responses with multi-scale dilated convolutions to extract target contours in low-contrast and low-SNR environments.
- Lightweight Design:With 2.92 million parameters and a computational load of only 6.8 GFlops, MEAC is highly efficient. It maintains a lightweight structure while achieving an FPS of 191.6, which is significantly higher than that of similar operators, such as ACmix (87.8 FPS) and Involution (110.1 FPS). MEAC also maintains good inference speed among mainstream operators, demonstrating good real-time performance and deployment friendliness.
- High-Precision Localization:At high IoU thresholds, MEAC’s mAP50-95 significantly outperforms other operators, indicating its heightened sensitivity to the boundaries of small infrared targets.
4.5.2. Qualitative Analysis of Comparative Experiments
- IRST-UAVB Dataset. MEAC achieves nearly perfect detection of extremely small targets, even when target sizes are only a few pixels. Their contours are amplified and correctly localized in shallow features. Other operators are prone to false negatives or misclassifying background as targets amidst complex background artifacts.
- IRSTD-1K Dataset. Due to the low signal-to-noise ratio of multi-spectral imaging, conventional operators often overlook weak signals. However, MEAC accurately detects most targets with high confidence through the synergistic effects of the DoG branch, which enhances edges, and the Dilated branch, which captures multi-scale context.
- IRSTDv1 Dataset. The target-to-background contrast is extremely low, and edge blurring is severe. Other operators often misclassify weak signals as noise and fail to detect them in this scenario. MEAC uses a multi-scale edge perception mechanism to accurately capture target contours while maintaining a low false detection rate. This demonstrates its robustness and generalization capability in extreme scenarios.
5. Conclusions
- Using pruning, quantization, or depth separability techniques reduces model size and computational overhead, meeting the requirements of embedded or real-time systems. These optimizations allow MEAC to maintain high performance while adapting to resource constraints in practical applications.
- Integrate the MEAC module with long-range dependency modeling architectures, such as Transformers, to enhance cross-scale information interaction and global context understanding.
- Extend the application of the module to different small-target detection domains, such as medical imaging and aerial remote sensing, to validate its generalizability and practical benefits. Through these improvements and extensions, MEAC is expected to enhance small-target detection performance in complex environments and advance the practical application of related technologies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A Thermal Infrared Video Benchmark for Visual Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 201–208. [Google Scholar] [CrossRef]
- Wu, P.; Huang, H.; Qian, H.; Su, S.; Sun, B.; Zuo, Z. SRCANet: Stacked Residual Coordinate Attention Network for Infrared Ship Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Ying, X.; Liu, L.; Wang, Y.; Li, R.; Chen, N.; Lin, Z.; Sheng, W.; Zhou, S. Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 15528–15538. [Google Scholar] [CrossRef]
- Zhang, C.; He, Y.; Tang, Q.; Chen, Z.; Mu, T. Infrared Small Target Detection via Interpatch Correlation Enhancement and Joint Local Visual Saliency Prior. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Yang, H.; Mu, T.; Dong, Z.; Zhang, Z.; Wang, B.; Ke, W.; Yang, Q.; He, Z. PBT: Progressive Background-Aware Transformer for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Bai, X.; Zhou, F. Analysis of New Top-Hat Transformation and the Application for Infrared Dim Small Target Detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Peng, Z.; Zhao, Z.; Chen, Y.; Han, J.; Huang, F.; Yu, Y.; Fu, Q. Infrared Small Target Segmentation Networks: A Survey. Pattern Recognit. 2023, 143, 109788. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Liu, C.; Zhang, H.; Zhao, Q. A Local Contrast Method for Infrared Small-Target Detection Utilizing a Tri-Layer Window. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1822–1826. [Google Scholar] [CrossRef]
- Xia, C.; Li, X.; Zhao, L.; Shu, R. Infrared Small Target Detection Based on Multiscale Local Contrast Measure Using Local Energy Factor. IEEE Geosci. Remote Sens. Lett. 2019, 17, 157–161. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Song, Y.; Guo, J. Non-Negative Infrared Patch-Image Model: Robust Target-Background Separation via Partial Sum Minimization of Singular Values. Infrared Phys. Technol. 2017, 81, 182–194. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11215, pp. 404–419. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z.X. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12316–12325. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally Parameterized Convolutions for Efficient Inference. In Proceedings of the 33rd International Conference on Neural Information Processing System, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention over Convolution Kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 3–19 June 2020; pp. 11030–11039. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef]
- Elhanashi, A.; Dini, P.; Saponara, S.; Zheng, Q. Integration of Deep Learning into the IoT: A Survey of Techniques and Challenges for Real-World Applications. Electronics 2023, 12, 4925. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Yeh, J.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer International Publishing: Cham, Switzerland, 2025; Volume 15089, pp. 1–21. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–32 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Hao, X.; Luo, S.; Chen, M.; He, C.; Wang, T.; Wu, H. Infrared Small Target Detection with Super-Resolution and YOLO. Opt. Laser Technol. 2024, 177, 111221. [Google Scholar] [CrossRef]
- Zhang, P.; Jing, Y.; Liu, G.; Chen, Z.; Wu, X.; Sasaki, O.; Pu, J. Infrared Dim Tiny-Sized Target Detection Based on Feature Fusion. Appl. Sci. 2024, 15, 4355. [Google Scholar] [CrossRef] [PubMed]
- Tong, X.; Sun, B.; Wei, J.; Zuo, Z.; Su, S. EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection. Remote Sens. 2021, 13, 3200. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing Feature Fusion for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1857–1866. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, F.; Gao, C.; Liu, F.; Zhao, Y.; Zhou, Y.; Meng, D.; Zuo, W. Local Patch Network with Global Attention for Infrared Small Target Detection. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3979–3991. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar] [CrossRef]
- Gao, C.; Wang, L.; Xiao, Y.; Zhao, Q.; Meng, D. Infrared Small-Dim Target Detection Based on Markov Random Field Guided Noise Modeling. Pattern Recognit. 2018, 76, 463–475. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-Dimensional Dynamic Convolution. arXiv 2022. [Google Scholar] [CrossRef]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the Integration of Self-Attention and Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-Shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection. arXiv 2024. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 949–958. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-Aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5792–5801. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. AKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters. arXiv 2023. [Google Scholar] [CrossRef]
- Chen, J.; Wang, X.; Guo, Z.; Zhang, X.; Sun, J. Dynamic Region-Aware Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8064–8073. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- Tan, M.; Le, Q.V. MixConv: Mixed Depthwise Convolutional Kernels. arXiv 2019. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating System | Ubuntu 22.04 |
| GPU | RTX 4090 (24 GB) |
| CPU | 16 VCPU Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10 GHz |
| Memory | 120 GB |
| Programming Languages | Python 3.10 |
| Frameworks | PyTorch 2.1.0 + CUDA 12.1 |
| IDE | JupyterLAb |
| Training/Validation/Test Split | Random Seed |
|---|---|
| 80%/10%/10% | seed: 0 |
| Data Augmentation | Initialization |
| YOLO official Closmic settings (set to 10) | Random Initialization |
| DoGE | Dilated | Identity | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 89.8% | 83.4% | 89.3% | 44.0% |
| ✓ | ✓ | 85.8% | 80.0% | 87.5% | 41.3% | |
| ✓ | ✓ | 88.0% | 81.1% | 89.1% | 42.6% | |
| ✓ | ✓ | 87.7% | 80.0% | 88.5% | 42.9% | |
| - | - | - | 82.1% | 74.9% | 80.2% | 40.0% |
| DoGE | Dilated | Identity | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 85.5% | 77.6% | 82.9% | 38.5% |
| ✓ | ✓ | 84.4% | 74.9% | 79.4% | 38.1% | |
| ✓ | ✓ | 81.3% | 75.4% | 79.9% | 37.7% | |
| ✓ | ✓ | 83.4% | 76.1% | 80.8% | 37.2% | |
| - | - | - | 84.9% | 75.2% | 80.9% | 36.4% |
| DoGE | Dilated | Identity | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 95.2% | 91.8% | 94.7% | 44.0% |
| ✓ | ✓ | 84.6% | 89.4% | 90.5% | 44.1% | |
| ✓ | ✓ | 92.2% | 83.7% | 92.6% | 38.1% | |
| ✓ | ✓ | 86.6% | 79.0% | 88.5% | 39.5% | |
| - | - | - | 88.4% | 87.8% | 87.4% | 42.6% |
| DoGE | Dilated | Identity | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 84.1% | 64.7% | 74.2% | 52.1% |
| ✓ | ✓ | - | 75.5% | 67.5% | 73.6% | 49.6% |
| ✓ | - | ✓ | 80.5% | 64.0% | 70.7% | 50.8% |
| - | ✓ | ✓ | 79.6% | 65.8% | 73.7% | 47.8% |
| - | - | - | 80.5% | 63.13% | 70.1% | 50.2% |
| IRSTDv1 | |||||||
|---|---|---|---|---|---|---|---|
| Model | Configuration | Precision | Recall | mAP50 | mAP50-95 | GFLOPs | Params (M) |
| YOLOv10n | Baseline | 79.5% | 76.8% | 78.9% | 32.2% | 7.8 | 2.83 |
| MEAC_place1 | 82.9% | 72.6% | 82.2% | 36.9% | 8.5 | 2.83 | |
| MEAC_place2 | 73.0% | 85.9% | 85.7% | 37.2% | 8.6 | 2.82 | |
| MEAC_place3 | 80.8% | 79.6% | 84.0% | 34.5% | 8.3 | 2.84 | |
| YOLOv11n | Baseline | 83.8% | 76.8% | 84.5% | 36.0% | 5.2 | 2.66 |
| MEAC_place1 | 88.7% | 88.5% | 89.0% | 40.5% | 5.8 | 2.67 | |
| MEAC_place2 | 87.9% | 82.2% | 88.5% | 37.4% | 5.5 | 2.77 | |
| MEAC_place3 | 85.8% | 85.5% | 88.8% | 38.3% | 5.3 | 2.62 | |
| YOLOv12n | Baseline | 87.3% | 83.3% | 83.9% | 34.5% | 6.4 | 2.73 |
| MEAC_place1 | 88.5% | 84.9% | 89.8% | 41.2% | 7.1 | 2.73 | |
| MEAC_place2 | 89.0% | 84.0% | 84.3% | 37.3% | 6.7 | 2.83 | |
| MEAC_place3 | 81.4% | 90.5% | 86.1% | 37.2% | 6.6 | 2.68 | |
| IRSTD-1K | |||||||
| YOLOv10n | Baseline | 78.6% | 78.6% | 81.2% | 37.9% | 7.8 | 2.83 |
| MEAC_place1 | 82.8% | 76.4% | 86.2% | 41.6% | 8.5 | 2.83 | |
| MEAC_place2 | 85.2% | 77.9% | 86.4% | 42.5% | 8.6 | 2.82 | |
| MEAC_place3 | 81.3% | 77.9% | 83.6% | 39.0% | 8.3 | 2.84 | |
| YOLOv11n | Baseline | 87.5% | 83.5% | 87.4% | 40.9% | 5.2 | 2.66 |
| MEAC_place1 | 88.6% | 82.1% | 89.3% | 42.6% | 5.8 | 2.67 | |
| MEAC_place2 | 87.3% | 85.6% | 90.7% | 41.1% | 5.5 | 2.77 | |
| MEAC_place3 | 83.4% | 85.5% | 88.4% | 41.8% | 5.3 | 2.62 | |
| YOLOv12n | Baseline | 86.1% | 81.0% | 84.1% | 38.6% | 6.4 | 2.73 |
| MEAC_place1 | 87.2% | 84.6% | 87.9% | 43.8% | 7.1 | 2.73 | |
| MEAC_place2 | 83.9% | 82.9% | 86.9% | 41.9% | 6.7 | 2.83 | |
| MEAC_place3 | 85.8% | 81.4% | 87.1% | 40.7% | 6.6 | 2.68 | |
| SIRST-UAVB | |||||||
| YOLOv10n | Baseline | 70.9% | 67.6% | 71.8% | 33.0% | 7.8 | 2.83 |
| MEAC_place1 | 71.8% | 66.0% | 73.3% | 33.6% | 8.5 | 2.83 | |
| MEAC_place2 | 72.8% | 68.0% | 74.6% | 34.0% | 8.6 | 2.82 | |
| MEAC_place3 | 76.9% | 67.4% | 75.1% | 36.3% | 8.3 | 2.84 | |
| YOLOv11n | Baseline | 76.7% | 62.8% | 69.6% | 29.9% | 5.2 | 2.66 |
| MEAC_place1 | 86.1% | 72.9% | 79.3% | 35.7% | 5.8 | 2.67 | |
| MEAC_place2 | 80.3% | 69.0% | 74.4% | 33.3% | 5.5 | 2.77 | |
| MEAC_place3 | 80.0% | 65.8% | 73.6% | 33.3% | 5.3 | 2.62 | |
| YOLOv12n | Baseline | 75.3% | 62.9% | 68.3% | 31.1% | 6.4 | 2.73 |
| MEAC_place1 | 78.4% | 66.0% | 71.2% | 33.1% | 7.1 | 2.73 | |
| MEAC_place2 | 75.1% | 65.6% | 69.8% | 32.1% | 6.7 | 2.83 | |
| MEAC_place3 | 67.4% | 61.7% | 66.1% | 29.9% | 6.6 | 2.68 | |
| Module | Params(M) | Gflops/G | FPS | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| ACmix | 2.92 | 6.7 | 99.8 | 88.1% | 80.0% | 87.6% | 39.6% |
| AKConv | 3.60 | 24.2 | 213.6 | 81.2% | 83.7% | 85.9% | 39.9% |
| DRConv | 3.11 | 6.7 | 274.9 | 87.1% | 82.1% | 87.6% | 42.1% |
| DSConv | 2.92 | 6.0 | 308.5 | 92.8% | 77.9% | 87.9% | 39.9% |
| LSKConv | 3.10 | 6.5 | 243.4 | 84.2% | 84.7% | 85.3% | 40.9% |
| MixConv | 2.93 | 6.3 | 239.4 | 85.2% | 79.6% | 86.0% | 40.2% |
| PConv | 3.09 | 6.3 | 205.8 | 86.4% | 84.8% | 86.8% | 41.7% |
| Conv | 2.92 | 6.2 | 290.2 | 82.1% | 74.9% | 80.2% | 40.6% |
| ODConv | 2.96 | 6.1 | 204.1 | 86.7% | 80.7% | 84.8% | 39.9% |
| GConv | 2.92 | 6.2 | 259.9 | 85.1% | 86.4% | 87.7% | 43.5% |
| Involution | 2.94 | 6.2 | 217.8 | 89.3% | 71.7% | 86.1% | 38.4% |
| Ours (MEAC) | 2.92 | 6.8 | 200.4 | 89.8% | 83.4% | 89.3% | 44.0% |
| Module | Params(M) | Gflops/G | FPS | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| ACmix | 2.92 | 6.7 | 104.0 | 84.1% | 72.7% | 78.7% | 36.3% |
| AKConv | 3.60 | 24.2 | 194.5 | 84.0% | 70.3% | 76.4% | 33.9% |
| DRConv | 3.11 | 6.7 | 294.1 | 77.5% | 77.8% | 78.4% | 35.4% |
| DSConv | 2.92 | 6.0 | 337.6 | 77.8% | 72.3% | 74.9% | 33.1% |
| LSKConv | 3.10 | 6.5 | 260.7 | 81.3% | 76.4% | 79.5% | 35.7% |
| MixConv | 2.93 | 6.3 | 311.0 | 83.0% | 75.4% | 79.9% | 36.3% |
| PConv | 3.09 | 6.3 | 274.4 | 83.2% | 73.8% | 78.5% | 35.5% |
| Conv | 2.92 | 6.2 | 331.8 | 80.4% | 75.7% | 80.5% | 36.7% |
| ODConv | 2.96 | 6.1 | 246.8 | 82.4% | 75.2% | 80.5% | 36.3% |
| GConv | 2.92 | 6.2 | 332.1 | 84.6% | 76.0% | 80.5% | 36.5% |
| Involution | 2.94 | 6.2 | 265.4 | 84.6% | 63.2% | 68.2% | 29.7% |
| Ours (MEAC) | 2.92 | 6.8 | 221.8 | 85.5% | 77.6% | 82.9% | 38.5% |
| Module | Params(M) | Gflops/G | FPS | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| ACmix | 2.92 | 6.7 | 87.8 | 76.6% | 75.9% | 77.7% | 29.5% |
| AKConv | 3.60 | 24.2 | 224.4 | 85.4% | 75.9% | 83.5% | 27.4% |
| DRConv | 3.11 | 6.7 | 253.8 | 80.7% | 87.0% | 86.3% | 31.8% |
| DSConv | 2.92 | 6.0 | 222.0 | 79.9% | 75.9% | 76.9% | 34.0% |
| LSKConv | 3.10 | 6.5 | 193.7 | 81.3% | 76.4% | 79.5% | 35.7% |
| MixConv | 2.93 | 6.3 | 249.3 | 81.5% | 81.5% | 84.9% | 30.8% |
| PConv | 3.09 | 6.3 | 242.3 | 92.1% | 85.8% | 89.6% | 33.4% |
| Conv | 2.92 | 6.2 | 261.0 | 79.5% | 83.7% | 86.6% | 42.6% |
| ODConv | 2.96 | 6.1 | 195.9 | 86.5% | 82.8% | 84.3% | 35.1% |
| GConv | 2.92 | 6.2 | 275.7 | 83.6% | 75.5% | 80.0% | 33.0% |
| Involution | 2.94 | 6.2 | 110.1 | 84.8% | 77.8% | 81.5% | 32.5% |
| Ours (MEAC) | 2.92 | 6.8 | 191.6 | 95.2% | 91.8% | 94.7% | 44.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Zhang, T.; Zhao, M. MEAC: A Multi-Scale Edge-Aware Convolution Module for Robust Infrared Small-Target Detection. Sensors 2025, 25, 4442. https://doi.org/10.3390/s25144442
Hu J, Zhang T, Zhao M. MEAC: A Multi-Scale Edge-Aware Convolution Module for Robust Infrared Small-Target Detection. Sensors. 2025; 25(14):4442. https://doi.org/10.3390/s25144442
Chicago/Turabian StyleHu, Jinlong, Tian Zhang, and Ming Zhao. 2025. "MEAC: A Multi-Scale Edge-Aware Convolution Module for Robust Infrared Small-Target Detection" Sensors 25, no. 14: 4442. https://doi.org/10.3390/s25144442
APA StyleHu, J., Zhang, T., & Zhao, M. (2025). MEAC: A Multi-Scale Edge-Aware Convolution Module for Robust Infrared Small-Target Detection. Sensors, 25(14), 4442. https://doi.org/10.3390/s25144442