
Automated Detection of Tailing Impoundments in Multi-Sensor High-Resolution Satellite Images Through Advanced Deep Learning Architectures

Abstract
1. Introduction
- (1)
- Current research on deep learning-based TI identification remains relatively scarce, with existing approaches demonstrating limited robustness primarily due to inadequate training data diversity. Our methodology addresses this limitation through comprehensive multi-sensor image collection across varied environments, combined with systematic data augmentation techniques. This enriched training approach enables our enhanced YOLOv7 architecture to achieve superior detection performance with minimal false positives, even when processing imagery containing complex background interference.
- (2)
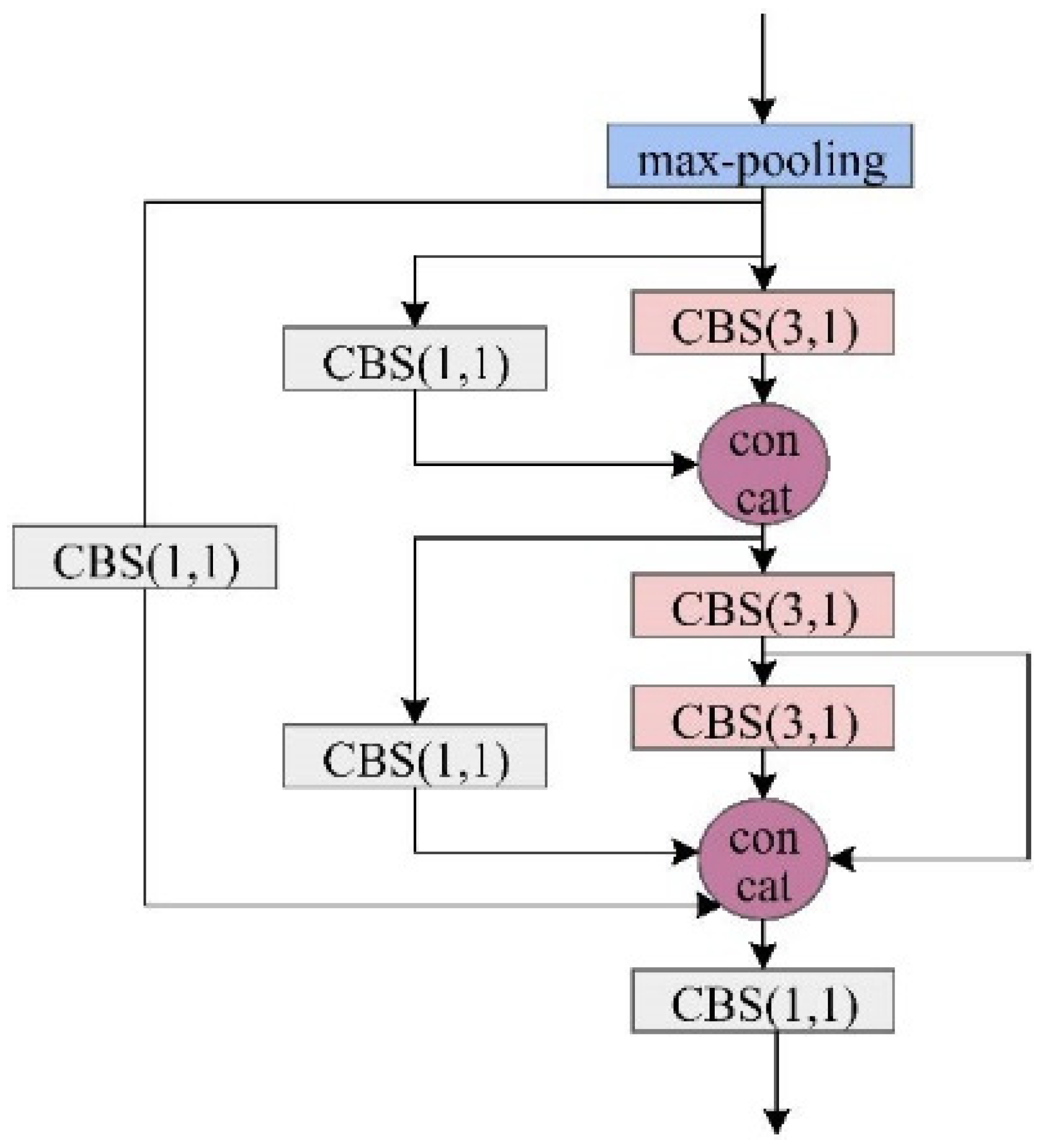
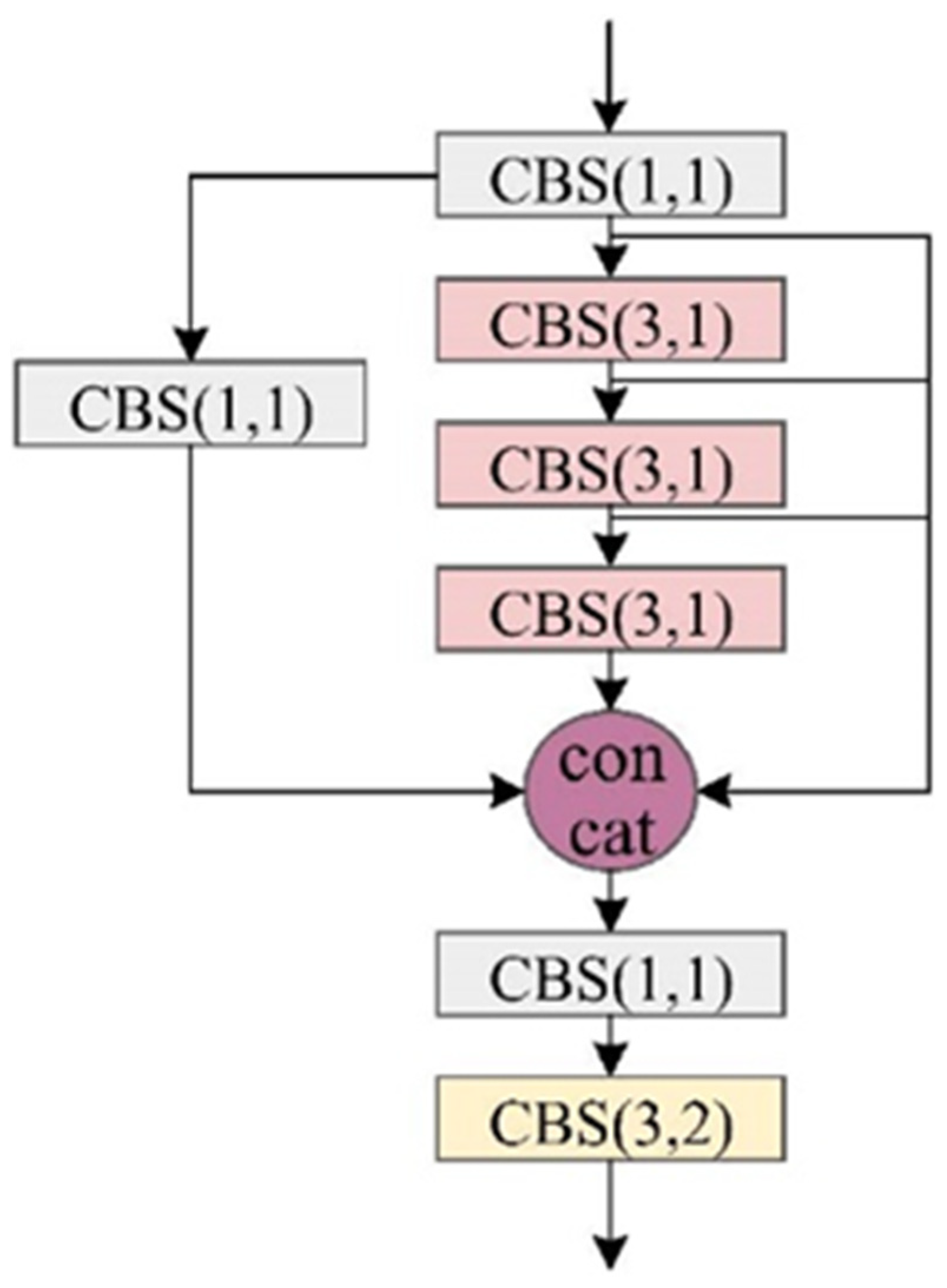
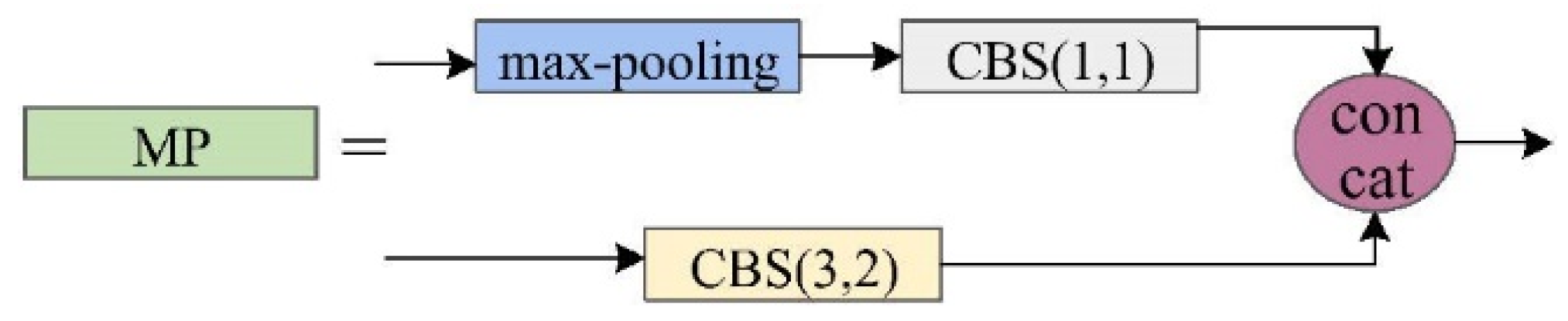
- The core feature extraction network incorporates our novel Multi-Scale Feature Aggregation (MSFA) layer, designed to simultaneously streamline the model architecture while improving its capacity to integrate comprehensive contextual information about target objects. This dual optimization enhances both computational efficiency and detection performance.
- (3)
- Within the feature fusion network, we implement a Lightweight Hierarchical Fusion (LHF) mechanism that significantly improves the model’s ability to combine multi-scale features efficiently. This lightweight design maintains computational economy while enabling more precise characterization of target attributes through optimized information integration.
- (4)
- To resolve training instability issues inherent in conventional YOLOv7 implementations, we introduce a sophisticated loss function modification. This adaptation not only prevents optimization divergence but also substantially reduces the time required for model convergence during the training phase.
2. Datasets and Samples
2.1. Datasets
2.2. Sample Generation
3. Method
4. Experimental Part
4.1. Evaluation Metric
4.2. Ablation Experiments
4.3. Comparison Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, S.Q.; Wang, G.J.; Liu, W.L.; Zhao, B.; Shen, Y.M.; Wang, M.L.; Li, X.S. Regional Distribution and Causes of Global Mine Tailings Dam Failures. Metals 2022, 12, 905. [Google Scholar] [CrossRef]
- Zhang, C.Y.; Xing, J.H.; Li, J.; Sang, X. Recognition of the spatial scopes of tailing impoundments based on U-Net and GF-6 images. Remote Sens. Nat. Resour. 2021, 33, 252–257. [Google Scholar]
- Yan, D.; Zhang, H.; Li, G.; Li, X.; Lei, H.; Lu, K.; Zhang, L.; Zhu, F. Improved Method to Detect the Tailings Ponds from Multispectral Remote Sensing Images Based on Faster R-CNN and Transfer Learning. Remote Sens. 2021, 14, 103. [Google Scholar] [CrossRef]
- Mezned, N.; Mechrgui, N.; Abdeljaouad, S. Mine Wastes Environmental Impact Mapping Using Landsat ETM+ and SPOT 5 Data Fusion in the North of Tunisia. J. Indian. Soc. Remote Sens. 2016, 44, 451–455. [Google Scholar] [CrossRef]
- Ma, B.; Chen, Y.; Zhang, S.; Li, X. Remote Sensing Extraction Method of Tailings Ponds in Ultra-Low-Grade Iron Mining Area Based on Spectral Characteristics and Texture Entropy. Entropy 2018, 20, 345. [Google Scholar] [CrossRef] [PubMed]
- Hao, L.; Zhang, Z.; Yang, X. Mine Tailing Extraction Indexes and Model Using Remote-Sensing Images in Southeast Hubei Province. Environ. Earth Sci. 2019, 78, 493. [Google Scholar] [CrossRef]
- Ma, X.; Wang, C.; Yin, Z.; Wu, P. SAR Image Despeckling by Noisy Reference-Based Deep Learning Method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8807–8818. [Google Scholar] [CrossRef]
- Ma, X.; Xu, J.; Pan, J.; Yang, J.; Wu, P.; Meng, X. Detection of Marine Oil Spills from Radar Satellite Images for the Coastal Ecological Risk Assessment. J. Environ. Manag. 2023, 325, 116637. [Google Scholar] [CrossRef]
- Xu, Z.; Geng, J.; Jiang, W. MMT: Mixed-Mask Transformer for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3289408. [Google Scholar] [CrossRef]
- Chen, X.; Li, D.; Liu, M.; Jia, J. CNN and Transformer Fusion for Remote Sensing Image Semantic Segmentation. Remote Sens. 2023, 15, 4455. [Google Scholar] [CrossRef]
- Lyu, J.; Hu, Y.; Ren, S.; Yao, Y.; Ding, D.; Guan, Q.; Tao, L. Extracting the Tailings Ponds from High Spatial Resolution Remote Sensing Images by Integrating a Deep Learning-Based Model. Remote Sens. 2021, 13, 743. [Google Scholar] [CrossRef]
- Yan, D.; Li, G.; Li, X.; Zhang, H.; Lei, H.; Lu, K.; Cheng, M.; Zhu, F. An Improved Faster R-CNN Method to Detect Tailings Ponds from High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 2052. [Google Scholar] [CrossRef]
- Dimitrovski, I.; Spasev, V.; Loshkovska, S.; Kitanovski, I. U-Net Ensemble for Enhanced Semantic Segmentation in Remote Sensing Imagery. Remote Sens. 2024, 16, 2077. [Google Scholar] [CrossRef]
- Huang, L.; Jiang, B.; Lv, S.; Liu, Y.; Fu, Y. Deep-Learning-Based Semantic Segmentation of Remote Sensing Images: A Survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 8370–8396. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tao, R.; Li, H.; Wang, T.; Wei, Y.; Ding, Y.; Jin, B.; Zhi, H.; Liu, X.; Liu, A. Exploring Endogenous Shift for Cross-Domain Detection: A Large-Scale Benchmark and Perturbation Suppression Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21157–21167. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Qian, X.; Zhang, N.; Wang, W. Smooth Giou Loss for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2023, 15, 1259. [Google Scholar] [CrossRef]
- Ma, X.; Huang, Z.; Zhu, S.; Fang, W.; Wu, Y. Rice Planting Area Identification Based on Multi-Temporal Sentinel-1 SAR Images and an Attention U-Net Model. Remote Sens. 2022, 14, 4573. [Google Scholar] [CrossRef]
- Wang, Q.; Feng, W.; Yao, L.; Zhuang, C.; Liu, B.; Chen, L. TPH-YOLOv5-Air: Airport Confusing Object Detection via Adaptively Spatial Feature Fusion. Remote Sens. 2023, 15, 3883. [Google Scholar] [CrossRef]
- Hussain, M. Yolov1 to v8: Unveiling Each Variant–a Comprehensive Review of Yolo. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. Image Process. Comput. Vision. Pattern Recognit. Graph. 2020, 12346, 213–229. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Lists |
|---|---|
| satellites | Gaofen series and ZY-3 |
| spatial Resolution | better than 3 m |
| geographical coverage | Shaanxi and Gansu Provinces, China |
| acquisition time | 2017/2019 |
| Model | OA | F1-Score | mAP50 | mAP75 |
|---|---|---|---|---|
| the baseline YOLOv7 (without sample augmentation) | 0.772 | 0.808 | 0.451 | 0.398 |
| the baseline YOLOv7 (with sample augmentation) | 0.851 | 0.830 | 0.523 | 0.401 |
| YOLOv7 with MSFA | 0.884 | 0.871 | 0.588 | 0.487 |
| YOLOv7 with LHF | 0.862 | 0.887 | 0.539 | 0.440 |
| YOLOv7 with DIoU loss | 0.866 | 0.859 | 0.540 | 0.416 |
| the enhanced model | 0.903 | 0.897 | 0.646 | 0.555 |
| Model | OA | F1-Score | mAP | Par | EPS |
|---|---|---|---|---|---|
| R-CNN | 0.764 | 0.709 | 0.447 | 141.3 M | 17.5 |
| YOLO Version 5 | 0.820 | 0.789 | 0.469 | 82.1 M | 50.1 |
| YOLO Version 6 | 0.844 | 0.823 | 0.504 | 69.8 M | 72.4 |
| YOLO Version 8 | 0.891 | 0.856 | 0.592 | 66.6 M | 41.3 |
| DETR | 0.855 | 0.840 | 0.531 | 41.2 M | 48.1 |
| the proposed one | 0.903 | 0.897 | 0.646 | 17.3 M | 137.7 |
| Model | OA | F1-Score | mAP | Par | EPS |
|---|---|---|---|---|---|
| R-CNN | 0.640 | 0.512 | 0.300 | 141.3 M | 17.5 |
| YOLO Version 5 | 0.711 | 0.645 | 0.383 | 82.1 M | 50.1 |
| YOLO Version 6 | 0.777 | 0.712 | 0.424 | 69.8 M | 72.4 |
| YOLO Version 8 | 0.800 | 0.787 | 0.498 | 66.6 M | 41.3 |
| DETR | 0.781 | 0.750 | 0.466 | 41.2 M | 48.1 |
| the proposed one | 0.813 | 0.791 | 0.555 | 17.3 M | 137.7 |
| TI Categories | OA | F1-Score |
|---|---|---|
| V-TI | 0.941 | 0.913 |
| S-TI | 0.899 | 0.870 |
| F-TI | 0.854 | 0.827 |
| OA | F1 | mAP50 | mAP75 |
|---|---|---|---|
| 0.831 | 0.802 | 0.567 | 0.485 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, L.; Song, W. Automated Detection of Tailing Impoundments in Multi-Sensor High-Resolution Satellite Images Through Advanced Deep Learning Architectures. Sensors 2025, 25, 4387. https://doi.org/10.3390/s25144387
Qin L, Song W. Automated Detection of Tailing Impoundments in Multi-Sensor High-Resolution Satellite Images Through Advanced Deep Learning Architectures. Sensors. 2025; 25(14):4387. https://doi.org/10.3390/s25144387
Chicago/Turabian StyleQin, Lin, and Wenyue Song. 2025. "Automated Detection of Tailing Impoundments in Multi-Sensor High-Resolution Satellite Images Through Advanced Deep Learning Architectures" Sensors 25, no. 14: 4387. https://doi.org/10.3390/s25144387
APA StyleQin, L., & Song, W. (2025). Automated Detection of Tailing Impoundments in Multi-Sensor High-Resolution Satellite Images Through Advanced Deep Learning Architectures. Sensors, 25(14), 4387. https://doi.org/10.3390/s25144387