
Infrared and Visible Image Fusion via Residual Interactive Transformer and Cross-Attention Fusion

Abstract
1. Introduction
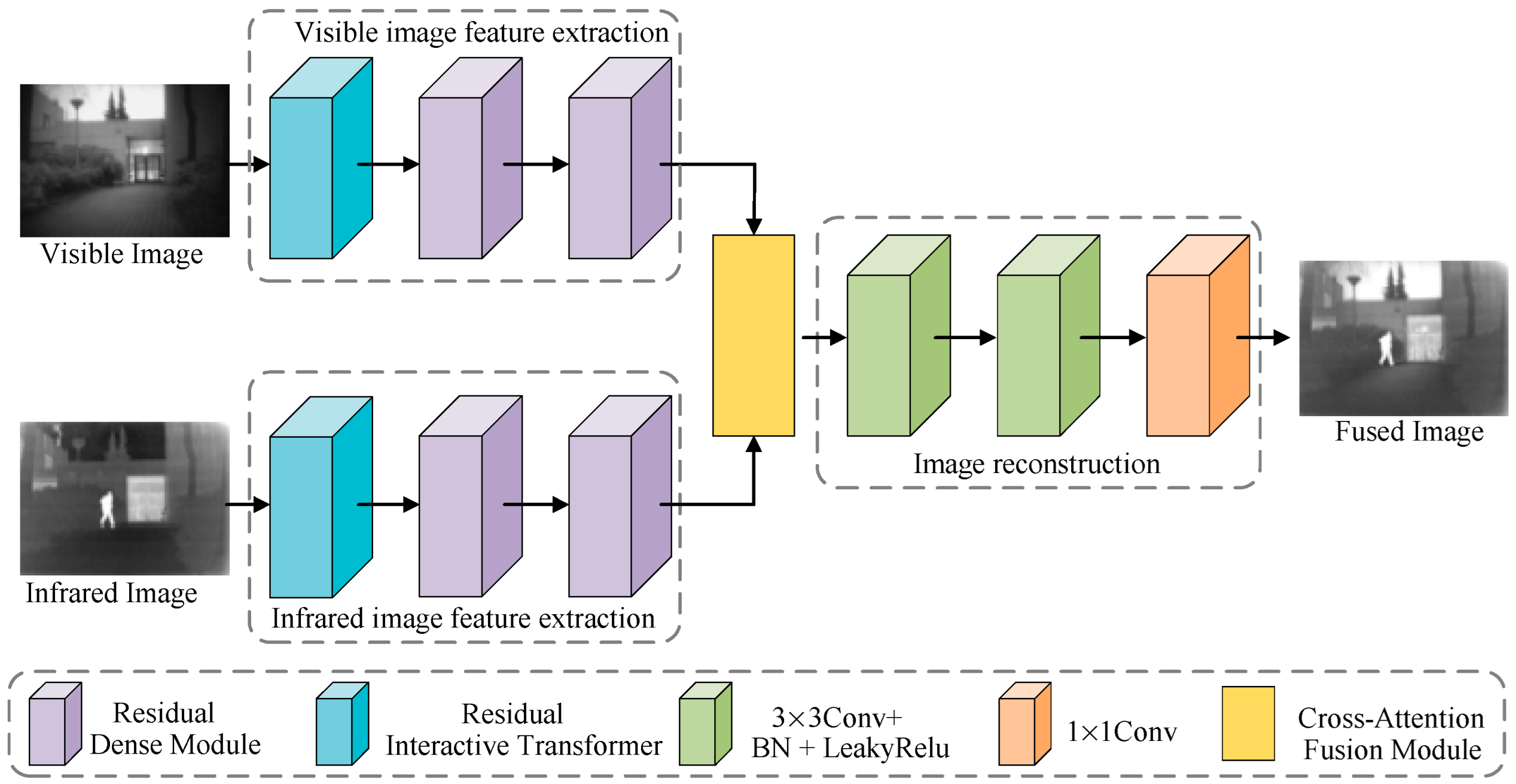
- This paper designs a residual dense module consisting of a mainstream and a residual stream. The mainstream incorporates dense connections, while the residual stream prevents information loss. This design enhances the extraction of shallow features from source images, facilitating further feature refinement;
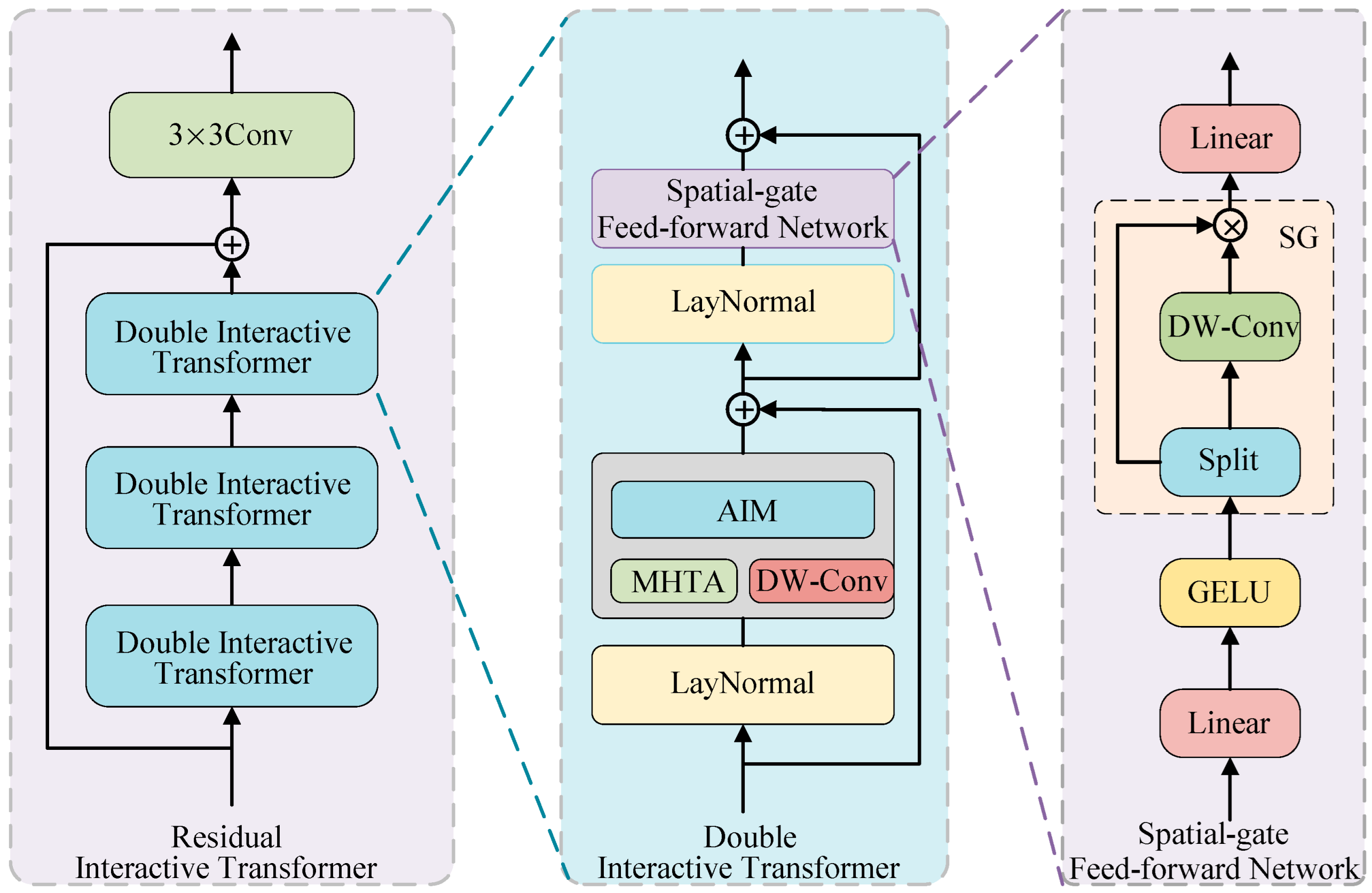
- This paper proposes a residual interactive transformer consisting of three serially connected double interactive transformers with residual connections. It extracts global and local contextual information from source images and facilitates their interaction and integration, enabling more effective feature extraction;
- This paper proposes a cross-attention fusion module, which employs a cross-attention mechanism to exchange complementary features between infrared and visible images. It also generates complementary mask maps in the spatial domain, enabling the effective fusion of infrared and visible image features.
2. Related Work
2.1. Deep Learning-Based Fusion Methods
2.2. Vision Transformer
3. Proposed Method
3.1. The Complete Network Architecture
3.2. Residual Dense Module
3.3. Residual Interactive Transformer
3.4. Cross-Attention Fusion Moudule
3.5. Loss Function
4. Experimental Analysis
4.1. Experimental Details
4.2. Comparison with State-of-the-Art Methods
4.2.1. Simulation on RoadScene Dataset
4.2.2. Simulation on TNO Dataset
4.2.3. Simulation on M3FD Dataset
5. Ablation Study
- (1)
- To analyze the effectiveness of the residual dense module, residual interactive transformer, and cross-attention fusion module, we conducted the following ablation study:
- wo/RDM: replacing the residual dense module with standard convolution for feature extraction;
- wo/RIT: replacing the residual interactive transformer with standard convolution for feature extraction;
- wo/CAFM: without cross-attention fusion module;
- pure-CNN backbones: the residual dense module is used to replace all residual interactive transformers for feature extraction;
- pure-transformer backbones: the residual interactive transformer is used to replace all residual dense modules for feature extraction;
- 1.
- The ablation study of the residual dense module: The purpose of this study is to extract shallow features from infrared and visible light images. As shown in Figure 9, the fusion image generated without the residual dense module lacks the richness of scene texture information in the fusion image generated by our complete method. The results indicate that the residual dense module is crucial in generating high-quality fusion images in the network model;
- 2.
- The ablation study of the residual interactive transformer: The purpose of the residual interactive transformer is to establish an interactive relationship between the global and local context information extracted from the source images. As shown in Figure 9, the fusion image without the residual interactive transformer has blurred scene texture details and the image gradient structure is reduced. Additionally, the scene texture and infrared thermal targets cannot be distinguished. The results indicate that the residual interactive transformer is important in generating fusion images with precise scene texture details and infrared thermal targets in our network;
- 3.
- The ablation study of the cross-attention fusion module: This module aims to effectively fuse the complementary information of infrared and visible light image feature maps. As shown in Figure 9, the fusion image generated without the cross-attention fusion module has a lower contrast of the infrared thermal targets. The results indicate that the cross-attention fusion module significantly improves the quality of the fusion images generated by our method;
- 4.
- The study on pure-CNN backbones: When all residual interactive transformers are replaced with residual dense modules for feature extraction, the network becomes a pure-CNN backbone. Figure 9 shows that the fused image from the pure-CNN backbone lacks a clear visible texture. The contrast of the infrared thermal target is also reduced. These results indicate that the residual interactive transformer plays a key role in generating fused images with clear texture details and high-contrast infrared targets;
- 5.
- The study on pure-transformer backbones: When all residual dense modules are replaced with residual interactive transformers for feature extraction, the network becomes a pure-transformer backbone. As shown in Figure 9, the fused images generated by the pure-transformer backbone contain less visible texture information. The results show that the residual dense module plays an important role in generating high-quality fused images.
- 1.
- The ablation study of the residual dense module: As shown in Table 4, compared to the fusion images generated by our complete method, the method without the residual dense module achieves the highest SSIM value. However, it shows a decline in the other five evaluation metrics to varying degrees. The results demonstrate that the residual dense module effectively improves the performance of the network model;
- 2.
- The ablation study of the residual interactive transformer: As shown in Table 4, the fusion images without the residual interactive transformer show a decline in all six evaluation metrics. The decline is most significant across all metrics. The results show that the residual interactive transformer plays a key role in improving the network fusion performance;
- 3.
- The ablation study of the cross-attention fusion module: As shown in Table 4, the fusion images without the cross-attention fusion module achieve the highest Qabf value. However, there is a decline in the other five evaluation metrics. The results indicate that the cross-attention fusion module plays an important role in generating high-quality fusion images in the network model;
- 4.
- The study on pure-CNN backbones: Table 4 shows a performance drop. The fused images from the pure-CNN backbone score lower than those obtained using our full method. All six evaluation metrics show varying degrees of decline. The results indicate that the residual interactive transformer plays an important role in improving the fusion performance of the network;
- 5.
- The study on pure-transformer backbones: Table 4 shows that all six evaluation metrics drop. The fused images from the pure-transformer backbone perform worse than those from our complete method. The results show that the residual dense module can effectively improve the fusion performance.
- (2)
- To test the effect of double interactive transformer quantity, we set the number n to 1, 2, 3, 4, and 5. All image pairs in the RoadScene test set were input into each model for evaluation. Table 5 shows the six evaluation metrics. When n = 3, the fused images do not achieve the highest SSIM, but they reach the best values in MI, SF, AG, VIF, and Qabf. Therefore, we set n = 3 for the double interactive transformer.
6. Parameter Analysis
7. Efficiency Comparison
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Wang, Y.; Xu, K.; Chai, Y.; Jiang, Y.; Qi, G. Semantic consistent feature construction and multi-granularity feature learning for visible-infrared person re-identification. Vis. Comput. 2024, 40, 2363–2379. [Google Scholar] [CrossRef]
- Zhou, A.; Xie, W.; Pei, J. Background modeling in the Fourier domain for maritime infrared target detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2634–2649. [Google Scholar] [CrossRef]
- Tang, H.; Liu, G.; Qian, Y.; Wang, J.; Xiong, J. EgeFusion: Towards edge gradient enhancement in infrared and visible image fusion with multi-scale transform. IEEE Trans. Comput. Imaging 2024, 10, 385–398. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef] [PubMed]
- Fu, Z.; Wang, X.; Xu, J.; Zhou, N.; Zhao, Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys. Technol. 2016, 77, 114–123. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Liu, J.; Wu, G.; Liu, Z.; Wang, D.; Jiang, Z.; Ma, L.; Zhong, W.; Fan, X.; Liu, R. Infrared and visible image fusion: From data compatibility to task adaption. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2349–2369. [Google Scholar] [CrossRef]
- Tang, L.; Zhang, H.; Xu, H.; Ma, J. Deep learning-based image fusion: A survey. J. Image Graph. 2023, 28, 3–36. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification saliency-based rule for visible and infrared image fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Xu, H.; Gong, M.; Tian, X.; Huang, J.; Ma, J. CUFD: An encoder–decoder network for visible and infrared image fusion based on common and unique feature decomposition. Comput. Vis. Image Underst. 2022, 218, 103407. [Google Scholar] [CrossRef]
- Wang, D.; Liu, J.; Fan, X.; Liu, R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. arXiv 2022, arXiv:2205.11876. [Google Scholar]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; Luo, Z.; Fan, X. Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion. Int. J. Comput. Vis. 2024, 132, 1748–1775. [Google Scholar] [CrossRef]
- Chen, G.; Jia, Y.; Yin, Y.; Fu, S.; Liu, D.; Wang, T. Remote sensing image dehazing using a wavelet-based generative adversarial networks. Sci. Rep. 2025, 15, 3634. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; Wu, H.; He, D.; Lan, R.; Liu, Z.; Pan, X. AcFusion: Infrared and visible image fusion based on self-attention and convolution with enhanced information extraction. IEEE Trans. Consum. Electron. 2023, 70, 4155–4167. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Z.; Qi, W.; Yang, F.; Xu, J. FreqGAN: Infrared and Visible Image Fusion via Unified Frequency Adversarial Learning. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 728–740. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A residual swin transformer fusion network for infrared and visible images. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, F.; Sun, J.; Xu, J.; Yang, F.; Yan, X. AITFuse: Infrared and visible image fusion via adaptive interactive transformer learning. Knowl. Based Syst. 2024, 299, 111949. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y. ITFuse: An interactive transformer for infrared and visible image fusion. Pattern Recognit. 2024, 156, 110822. [Google Scholar] [CrossRef]
- Cai, Z.; Ma, Y.; Huang, J.; Mei, X.; Fan, F.; Zhao, Z. CMFuse: Cross-Modal Features Mixing via Convolution and MLP for Infrared and Visible Image Fusion. IEEE Sens. J. 2024, 24, 24152–24167. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12484–12491. [Google Scholar]
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 2002, 43, 2959–2965. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Petrovic, V.; Xydeas, C. Objective image fusion performance characterization. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 1866–1871. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MI | SF | AG | VIF | Qabf | SSIM |
|---|---|---|---|---|---|---|
| RFN-Nest | 2.7597 | 8.3796 | 3.5902 | 0.4977 | 0.316 | 0.7745 |
| CSF | 2.7798 | 13.6697 | 5.4602 | 0.5768 | 0.4535 | 0.9543 |
| GANMcC | 2.7138 | 9.4399 | 3.9562 | 0.4906 | 0.3339 | 0.7958 |
| UMF-CMGR | 2.8249 | 11.4767 | 4.3617 | 0.5569 | 0.4356 | 0.9683 |
| CUFD | 3.7637 | 14.4622 | 5.4819 | 0.5831 | 0.4262 | 0.8068 |
| DATfuse | 3.7459 | 11.2871 | 3.9895 | 0.5955 | 0.4674 | 0.9258 |
| AITFuse | 3.7316 | 14.4117 | 5.2680 | 0.5633 | 0.4593 | 0.9601 |
| ITFuse | 2.594 | 5.0221 | 2.0809 | 0.396 | 0.2035 | 0.6488 |
| FreqGAN | 2.7569 | 5.7747 | 2.1374 | 0.3916 | 0.201 | 0.6239 |
| Ours | 3.7683 | 14.9984 | 5.4874 | 0.668 | 0.5315 | 0.9626 |
| Methods | MI | SF | AG | VIF | Qabf | SSIM |
|---|---|---|---|---|---|---|
| RFN-Nest | 2.1131 | 5.8745 | 2.6693 | 0.5593 | 0.3346 | 0.7954 |
| CSF | 2.0630 | 8.7505 | 3.7214 | 0.5862 | 0.3963 | 0.9363 |
| GANMcC | 2.2679 | 6.1610 | 2.5442 | 0.5297 | 0.2806 | 0.8438 |
| UMF-CMGR | 2.2092 | 8.1747 | 2.9727 | 0.5946 | 0.4104 | 1.0107 |
| CUFD | 3.4071 | 9.9678 | 4.0435 | 0.6667 | 0.3910 | 0.8076 |
| DATfuse | 3.1270 | 9.6057 | 3.5602 | 0.683 | 0.4997 | 0.9379 |
| AITFuse | 3.3258 | 9.8566 | 3.9624 | 0.6532 | 0.4876 | 1.0069 |
| ITFuse | 2.1492 | 3.9478 | 1.6959 | 0.4462 | 0.2076 | 0.7233 |
| FreqGAN | 2.4291 | 4.1177 | 1.6108 | 0.4425 | 0.1865 | 0.6736 |
| Ours | 3.7109 | 10.5687 | 4.0814 | 0.7950 | 0.5438 | 1.0512 |
| Methods | MI | SF | AG | VIF | Qabf | SSIM |
|---|---|---|---|---|---|---|
| RFN-Nest | 2.8497 | 7.7418 | 2.8696 | 0.5782 | 0.4027 | 0.7849 |
| CSF | 2.8694 | 9.6908 | 3.525 | 0.6265 | 0.4644 | 0.9064 |
| GANMcC | 2.7648 | 7.4739 | 2.6841 | 0.5368 | 0.3158 | 0.8192 |
| UMF-CMGR | 3.0393 | 8.7829 | 2.9443 | 0.6055 | 0.3947 | 0.9194 |
| CUFD | 3.7450 | 10.8490 | 3.8212 | 0.5623 | 0.3907 | 0.7854 |
| DATfuse | 4.1299 | 10.4667 | 3.4430 | 0.6444 | 0.4936 | 0.9193 |
| AITFuse | 3.9831 | 10.412 | 3.6911 | 0.5948 | 0.5988 | 0.9071 |
| ITFuse | 2.7781 | 5.1975 | 1.9410 | 0.4504 | 0.1960 | 0.7165 |
| FreqGAN | 3.1391 | 4.7506 | 1.6387 | 0.4124 | 0.1433 | 0.6093 |
| Ours | 4.0136 | 13.5104 | 4.6549 | 0.7682 | 0.6003 | 0.9926 |
| MI | SF | AG | VIF | Qabf | SSIM | |
|---|---|---|---|---|---|---|
| wo/RDM | 3.4304 | 14.3128 | 5.3157 | 0.6309 | 0.5155 | 0.9758 |
| wo/RIT | 3.1398 | 13.8430 | 5.0639 | 0.5678 | 0.4764 | 0.9126 |
| wo/CAFM | 3.7347 | 14.6095 | 5.4633 | 0.6627 | 0.5467 | 0.9618 |
| pure-CNN | 3.3436 | 13.7614 | 5.1882 | 0.5571 | 0.4464 | 0.9471 |
| Pure-transformer | 3.2154 | 13.0047 | 4.9606 | 0.5820 | 0.4477 | 0.9749 |
| ours | 3.7683 | 14.9984 | 5.4874 | 0.6680 | 0.5315 | 0.9626 |
| n | MI | SF | AG | VIF | Qabf | SSIM |
|---|---|---|---|---|---|---|
| 1 | 3.0924 | 10.7666 | 4.1437 | 0.5241 | 0.4034 | 0.8998 |
| 2 | 3.5052 | 11.9063 | 4.5684 | 0.5872 | 0.4527 | 1.0069 |
| 3 | 3.7683 | 14.9984 | 5.4874 | 0.6680 | 0.5315 | 0.9626 |
| 4 | 3.5114 | 12.4069 | 4.6689 | 0.5835 | 0.4550 | 0.9632 |
| 5 | 3.3465 | 13.3152 | 5.113 | 0.5751 | 0.4559 | 0.9669 |
| α, λ, γ | MI | AG | VIF | Qabf | SSIM |
|---|---|---|---|---|---|
| 10, 20, 8 | 3.2023 | 4.7193 | 0.5396 | 0.4484 | 0.9779 |
| 30, 20, 8 | 3.3806 | 4.6288 | 0.5548 | 0.4387 | 0.9782 |
| 40, 20, 8 | 3.5584 | 4.6197 | 0.5859 | 0.4433 | 0.9482 |
| 20, 10, 8 | 3.5366 | 4.7582 | 0.5875 | 0.4424 | 1.025 |
| 20, 30, 8 | 3.3382 | 4.9995 | 0.5646 | 0.4595 | 0.9749 |
| 20, 40, 8 | 3.1524 | 4.7623 | 0.5333 | 0.4456 | 0.9514 |
| 20, 20, 7 | 3.4037 | 4.8326 | 0.5694 | 0.4524 | 0.9904 |
| 20, 20, 9 | 3.3322 | 4.8708 | 0.5566 | 0.4510 | 0.9938 |
| 20, 20, 10 | 3.3480 | 4.8318 | 0.5539 | 0.4497 | 0.9968 |
| 20, 20, 8 | 3.7683 | 5.4874 | 0.668 | 0.5315 | 0.9626 |
| Methods | Size(M) | FLOPs(G) | RoadScene(s) | TNO(s) | M3FD(s) |
|---|---|---|---|---|---|
| RFN-Nest | 1.0225 | 32.85 | 0.2746 | 0.2361 | 0.2962 |
| CSF | 1.2277 | 70.32 | 2.6985 | 2.2154 | 2.9851 |
| GANMcC | 0.7251 | 23.59 | 0.1965 | 0.1852 | 0.2295 |
| UMF-CMGR | 0.6826 | 16.03 | 0.1953 | 0.1719 | 0.2082 |
| CUFD | 0.9854 | 29.32 | 0.2484 | 0.2043 | 0.2879 |
| DATfuse | 0.0886 | 3.79 | 0.1276 | 0.1143 | 0.1489 |
| AITFuse | 0.7633 | 10.56 | 0.1682 | 0.1366 | 0.1935 |
| ITFuse | 0.2336 | 7.96 | 0.1523 | 0.1371 | 0.1625 |
| FreqGAN | 0.1026 | 4.35 | 0.1432 | 0.1221 | 0.1601 |
| Ours | 0.1282 | 4.46 | 0.1309 | 0.1206 | 0.1573 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Ke, C.; Jia, Y.; Xu, C.; Teng, Z. Infrared and Visible Image Fusion via Residual Interactive Transformer and Cross-Attention Fusion. Sensors 2025, 25, 4307. https://doi.org/10.3390/s25144307
Zhao L, Ke C, Jia Y, Xu C, Teng Z. Infrared and Visible Image Fusion via Residual Interactive Transformer and Cross-Attention Fusion. Sensors. 2025; 25(14):4307. https://doi.org/10.3390/s25144307
Chicago/Turabian StyleZhao, Liquan, Chen Ke, Yanfei Jia, Cong Xu, and Zhijun Teng. 2025. "Infrared and Visible Image Fusion via Residual Interactive Transformer and Cross-Attention Fusion" Sensors 25, no. 14: 4307. https://doi.org/10.3390/s25144307
APA StyleZhao, L., Ke, C., Jia, Y., Xu, C., & Teng, Z. (2025). Infrared and Visible Image Fusion via Residual Interactive Transformer and Cross-Attention Fusion. Sensors, 25(14), 4307. https://doi.org/10.3390/s25144307