This section outlines the methods and models employed for predicting soil temperature. It also details the dataset, experimental procedure, and evaluation criteria applied in the present study.
2.1. Methods
Various machine learning methods can be used to predict temperature in the soil. These methods input meteorological data into an LSTM model, which is then compared with other machine learning approaches.
Table 2 presents an overview of the machine learning models reviewed in this article. Polynomial Regression (PR) is the most commonly employed prediction model and serves as a reference model. In the present study, PR uses a Linear Regression model enhanced with polynomial preprocessing to enable the processing of non-linear data [
13]. SVR, from the Support Vector Machine family, is another widely employed algorithm that is expected to yield satisfactory results. SVR is noted for its favorable balance between computational costs and performance and its capability to handle multidimensional problems [
14]. The LSTM neural network is the most versatile and generative of the approaches mentioned, offering extensive optimisation possibilities in terms of structure, penalties, and cost functions. Generally, LSTM is known to achieve lower error rates [
15] and is effective in time-series analysis problems [
16].
The configuration of PR and SVR models also depends on the number of input parameters. For PR, the degree of polynomial features must be established. In the present study, the degree range is set between one and ten. In the case of SVR, the regularisation parameter (C) and the insensitivity loss parameter () are selected. The regularisation parameter is set within a range of 1 to 100, and the insensitivity loss parameter is set within a range of 0.01 to 0.1.
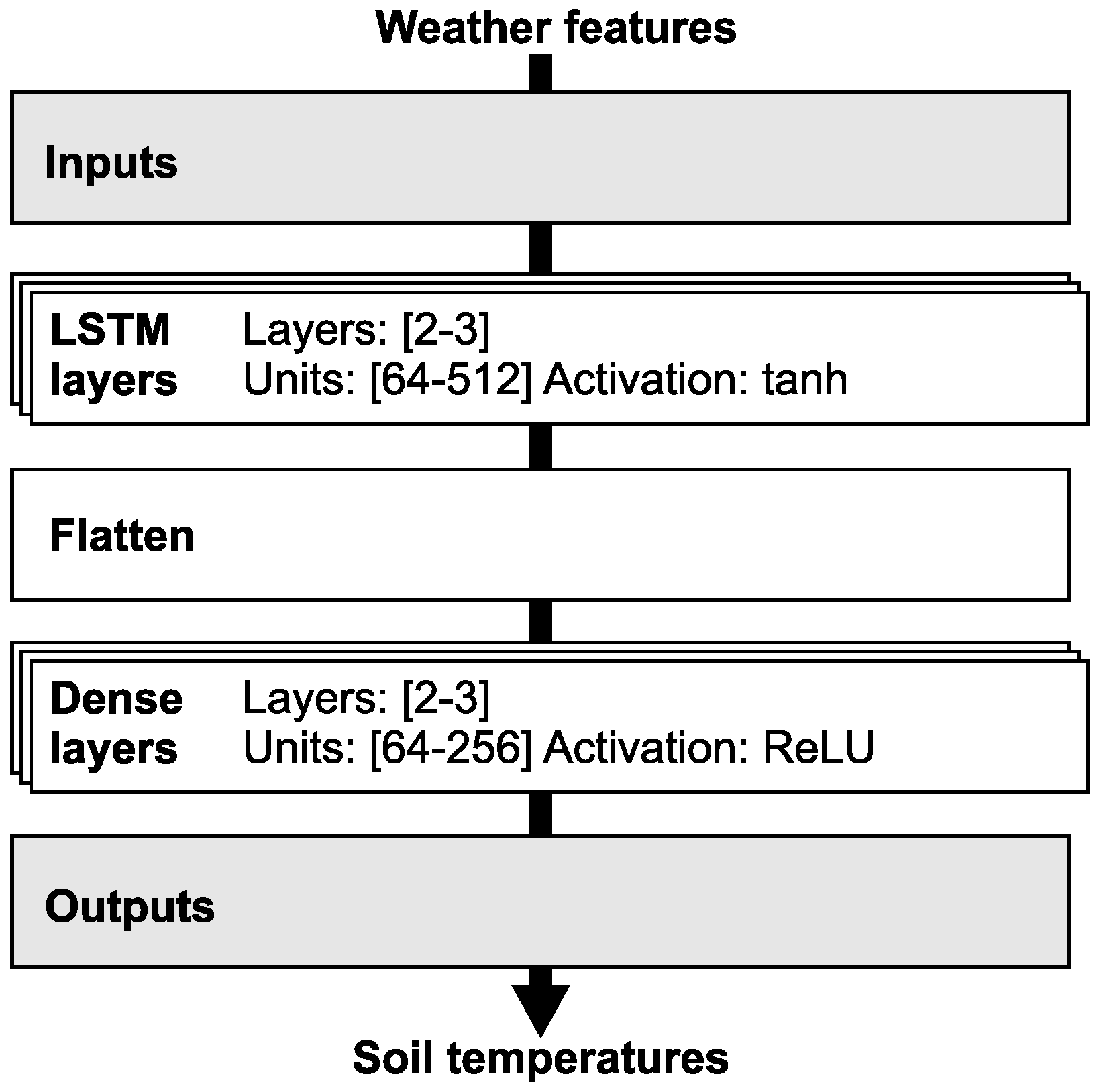
The LSTM model is a general framework that, for the purpose of soil temperature prediction, requires specific configurations in its structure, loss function, and optimizer.
Figure 3 illustrates the LSTM model structure adapted for use in the presented experiments. The figure outlines the main LSTM components, including its structure, layer types, activation function definitions, inputs, and outputs. LSTM layers process input data, identify patterns, and manage time series data. Dense layers translate the output from LSTM layers into output vectors. Inputs are derived from the model’s feature sets, while outputs directly correspond to the soil temperature profile at various depths. The architecture of the LSTM neural network is dependent on the number of features in its feature set; naturally, more features necessitate a more complex neural network. Based on the number of features, the number of layers and neurons is adjusted. To prevent overfitting, the model employs L1 and L2 penalties and dropout techniques.
The LSTM model uses up to seven feature sets. A soil temperature profile at four depths is predicted for each feature set.
Table 3 summarises the parameters and respective values or ranges for the LSTM model. To optimise the performance for each feature set, a bespoke model was carefully constructed to minimise loss and error rates. This approach produced seven individual LSTM model configurations, each tailored to the specifics of its corresponding feature set. The ranges listed for certain parameters in
Table 3 describe the variability and adaptability required to fine-tune the models for optimal performance.
Notably, all model configurations use the same optimiser, loss function, observed metrics, and output layer configurations. This consistency ensured a standardised approach to training and evaluating the model and permitted a coherent comparison of performance metrics across the different LSTM models. In adopting this rigorous and tailored methodology, the present study not only improves on the accuracy and reliability of soil temperature predictions, it also provides valuable insight into the effective use of LSTM networks in complex data-driven forecasting tasks.
Although many data-driven methods exist for time-series regression and environmental modelling, including Random Forest Regression (RFR), Gradient Boosting Machines (GBM), Gaussian Process Regression (GPR), or more recent Transformer-based architectures, the selection of PR, SVR, and LSTM in this study was based on a balance of model interpretability, computational cost, and prior success in similar soil temperature prediction tasks. Polynomial Regression offers a simple and interpretable baseline; SVR is known for its robustness in small-to-medium datasets with non-linear structure; and LSTM has become a standard for capturing temporal dependencies in multivariate time series. This combination allows for comparing classic regression, kernel-based learning, and deep learning approaches within a unified framework, while maintaining accessibility for deployment and further development.
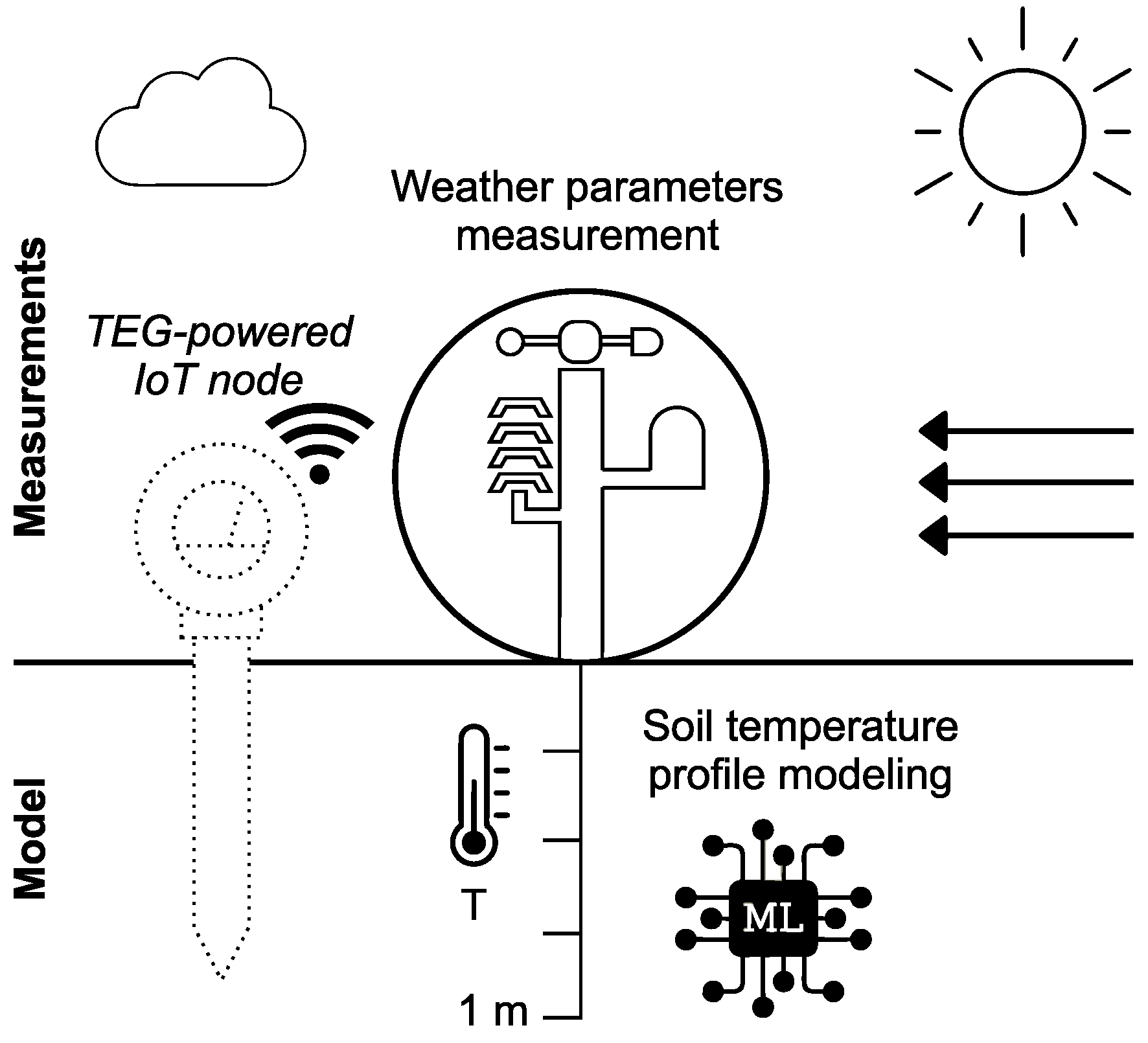
2.2. Data
The dataset for the experiments consists of meteorological variables recorded at 10-minute intervals. This dataset was professionally recorded at the Ostrava-Poruba station in the Czech Republic and acquired from the Czech Hydrometeorological Institute (CHMI); it includes weather data such as temperature, solar irradiance, precipitation, air pressure, and soil temperature. The data cover a period of four years (2016–2019) and contain a soil temperature profile used for evaluation of the experimental results. The dataset can be accessed by contacting the CHMI [
21].
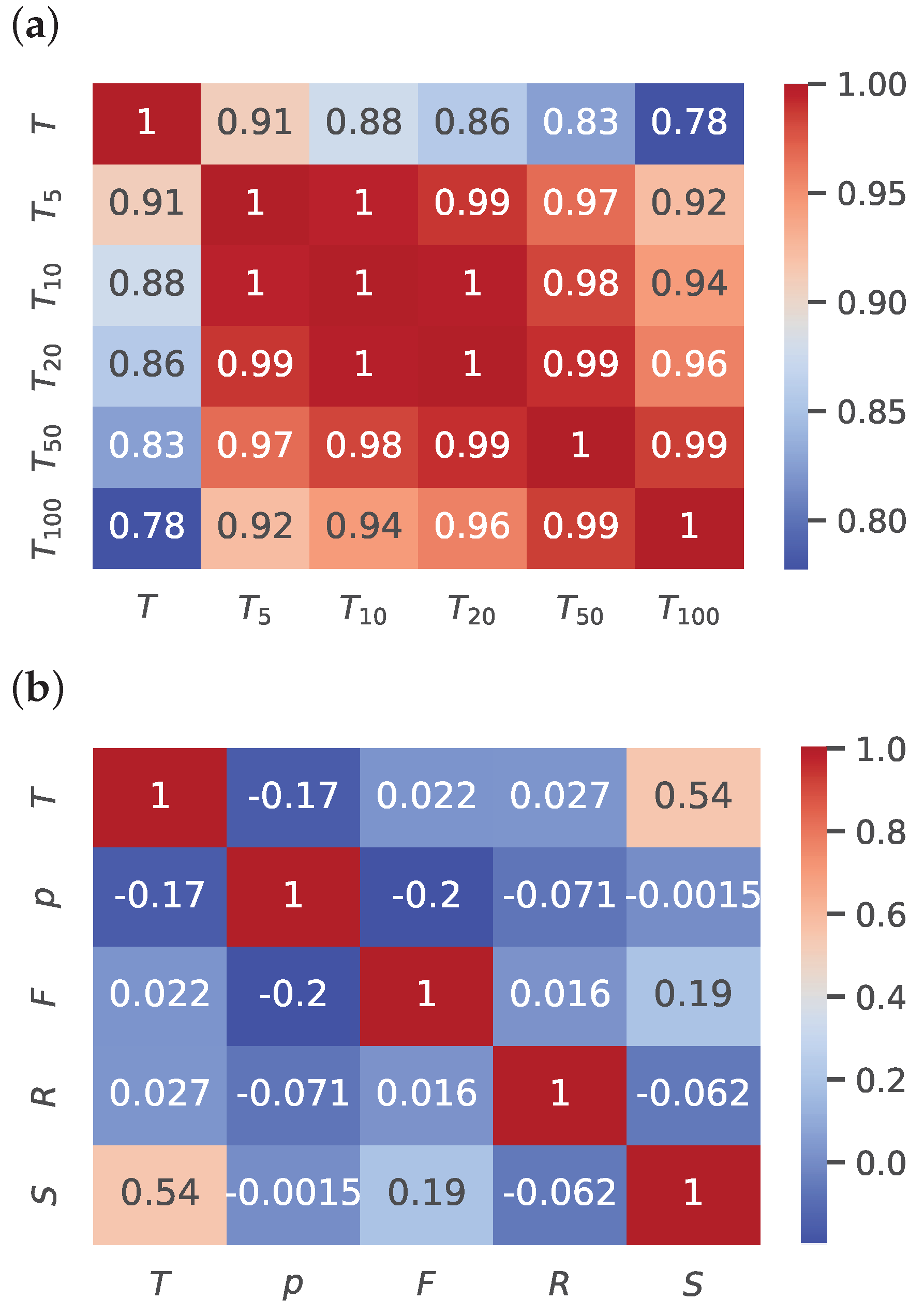
Table 4 lists the variables contained in the input dataset. The variables were recorded at 10 min intervals and specifically describe wind speed (
F), atmospheric pressure (
p), solar irradiance (
S), precipitation (
R), ambient temperature (
T), and soil temperature (
) at depths of 5 cm, 10 cm, 20 cm, 50 cm, and 100 cm. Because temperature in soil changes slowly and inertially and does not experience the same rapid changes as ambient heat, wind or solar irradiance, the dataset was resampled to a one-hour interval using an averaging window function.
2.3. Evaluation Criteria
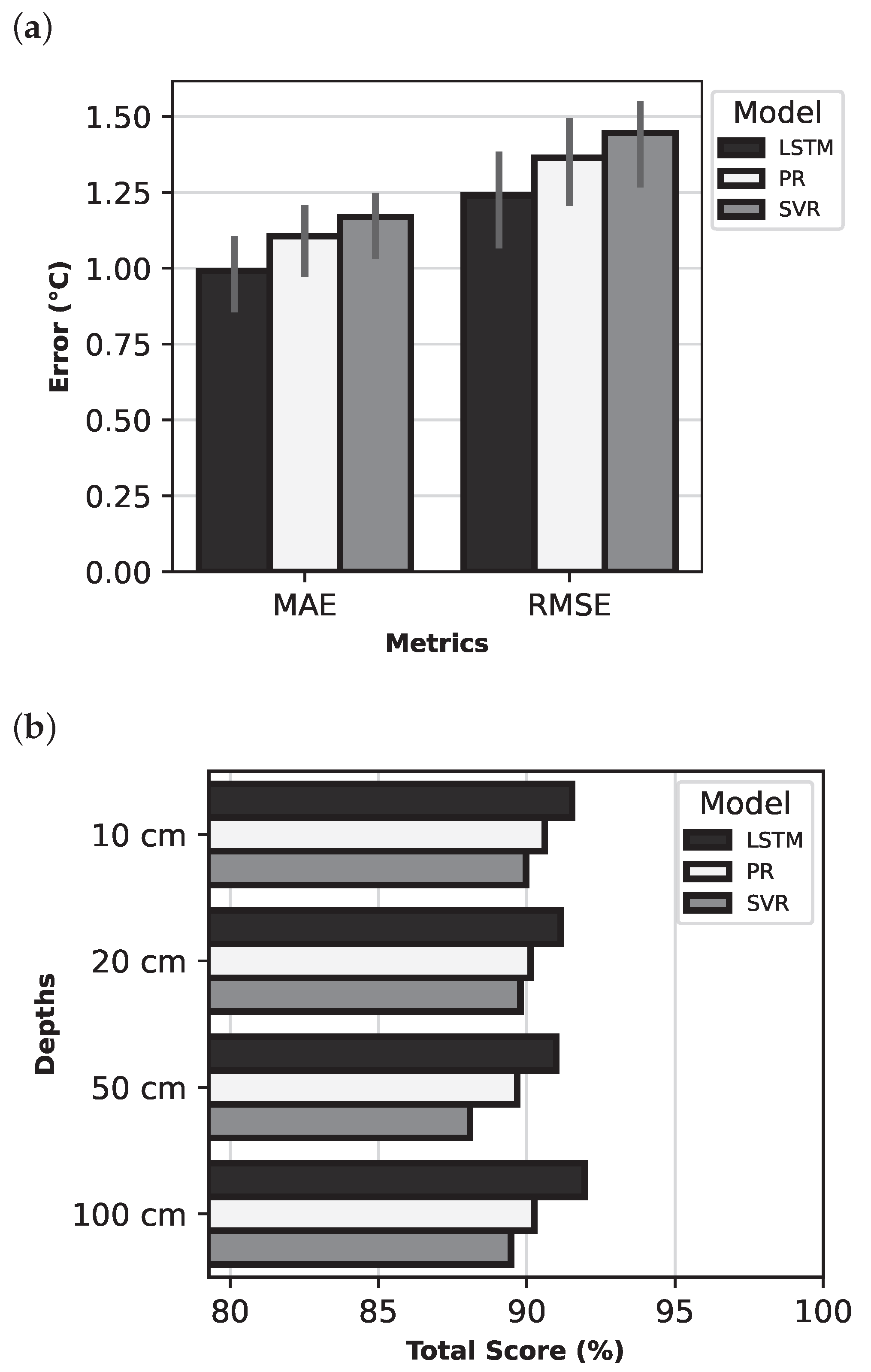
The experiments were evaluated according to several criteria essential to determining both the performance accuracy and error rate in the LSTM models. These criteria were also crucial to evaluating the effectiveness of input parameter combinations and provided insight into the effects of the variables on prediction accuracy.
Table 5 lists the evaluation criteria for the experiments, including abbreviations and units. MAE, RMSE, and
indicate the statistical properties of the presented results. Adapted from the MAE and RMSE, Error Ratio represents the model’s weighted error ratio. The Total Score is calculated from the Error Ratio and
and represents a measure of the model’s quality.
For assessing the predictive model’s performance, MAE and RMSE are key criteria for quantifying the average deviation of predicted outcomes from their actual values, expressed in degrees Celsius. The coefficient of determination, , quantifies how well the model’s predictions match the variability of the observed data and ranges from 0 to 1, where 0 indicates no explanatory power and 1 indicates complete agreement between the model’s predictions and measured results.
Building on these traditional metrics, the present study introduces Total Score, a composite metric derived from the Error Ratio and coefficient. This score synthesises the insights gained from error metrics and coefficient into a single, comprehensive evaluation metric ranging from 0 to 100.
To calculate the Total Score of a model, it is necessary to first compute its Error Ratio, which is obtained from the equation:
where ER—Error Ratio is the relative error of the model in the range 0 to 100,
and
are the weight coefficients in the range 0 to 1 (the sum of of the weights = 1), and
and
are error metrics transformed to their relative forms according to the equations:
where
and
are soil temperatures (
). This normalisation step ensures that the Error Ratio reflects the weighted contributions of both MAE and RMSE relative to the total weight. The experiment used weights of 0.2 for MAE and 0.8 for RMSE. The normalised Error Ratio is then scaled by a factor of 100 for conversion into a percentage. Finally, a Total Score is calculated:
The Total Score metric, which is critical to evaluating the model, ingeniously combines assessment of the error ratio and the data variance. It provides a comprehensive measure of the model’s ability to explain the data variance and predictive accuracy by combining the error ratio to reflect the model accuracy and the value to describe the variance. A high Total Score indicates the model’s efficiency in both aspects, indicating superior performance.
Although the current evaluation is based on aggregated metrics such as MAE, RMSE, and a composite Total Score, alternative multi-criteria decision-making (MCDM) approaches, such as the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS), could also be applied. These methods may offer complementary insights when comparing models across multiple evaluation dimensions, especially in scenarios where trade-offs between different performance metrics are important. Exploring such approaches could be a subject of future research, particularly for model selection under uncertainty or deployment constraints.
2.4. Experimental Methodology
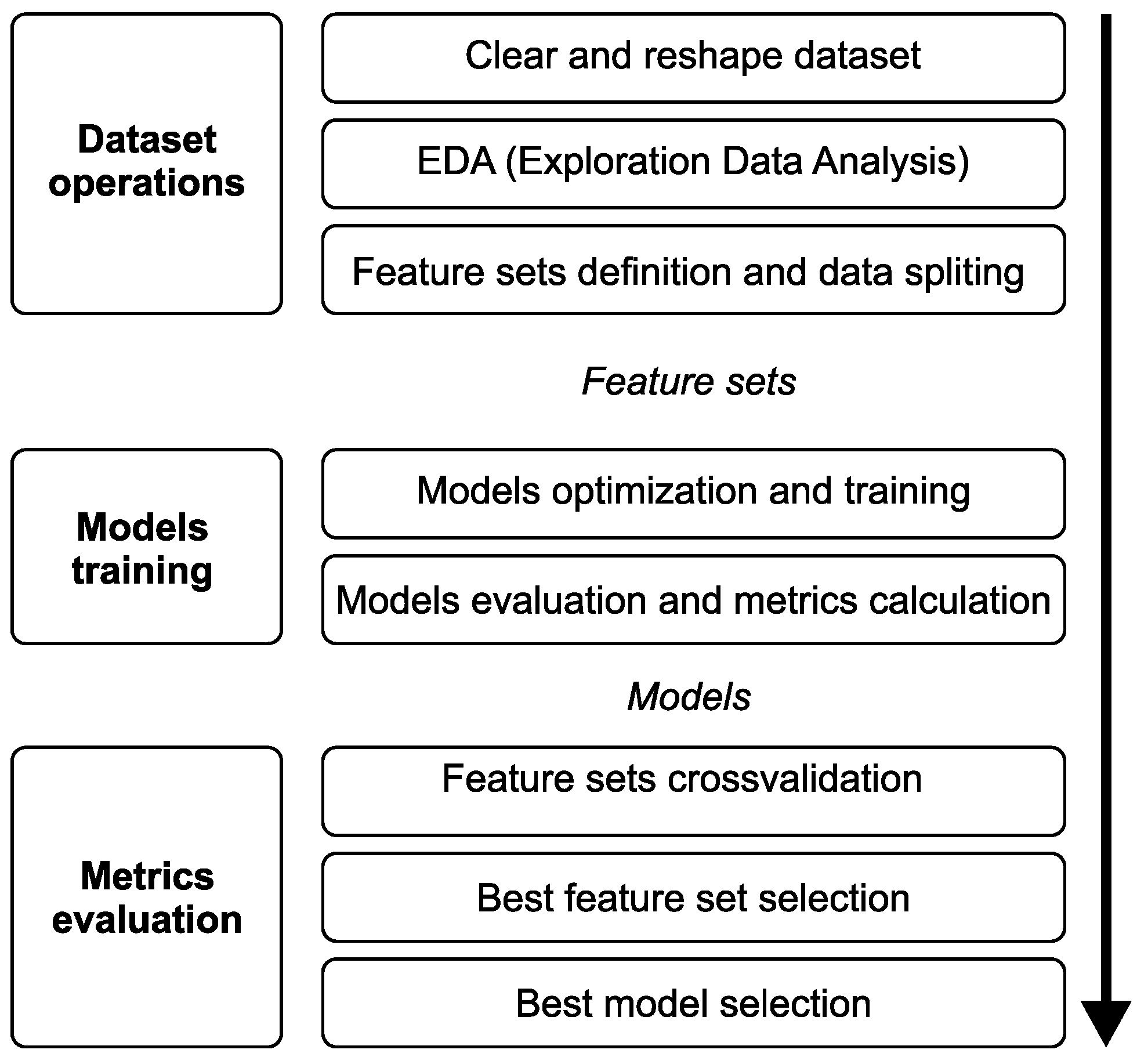
This section provides a detailed overview of the experimental process and outlines the comprehensive methodology used to achieve the study’s aims. The primary aim of the experiment was to identify the optimal feature set and machine learning model for predicting soil temperature using the supplied dataset. This involved not only careful selection and evaluation of various prediction models but also careful identification of the features relevant and instrumental to soil temperature prediction accuracy.
Figure 4 details the workflow and specific steps of the experiment. The procedure began with an Exploratory Data Analysis (EDA), a phase essential to acquiring a deep understanding of the characteristics of the dataset and the intricate patterns it contains. This initial analysis was critical to revealing the data structure, discovering potential correlations, and identifying any anomalies or outliers with a potential impact on the study’s results. After the EDA, the feature sets were identified and prepared. These sets were selected carefully according to their relevance and potential impact on the predictive capabilities of the models and served as the building blocks for creating other models with improved accuracy and predictive power.
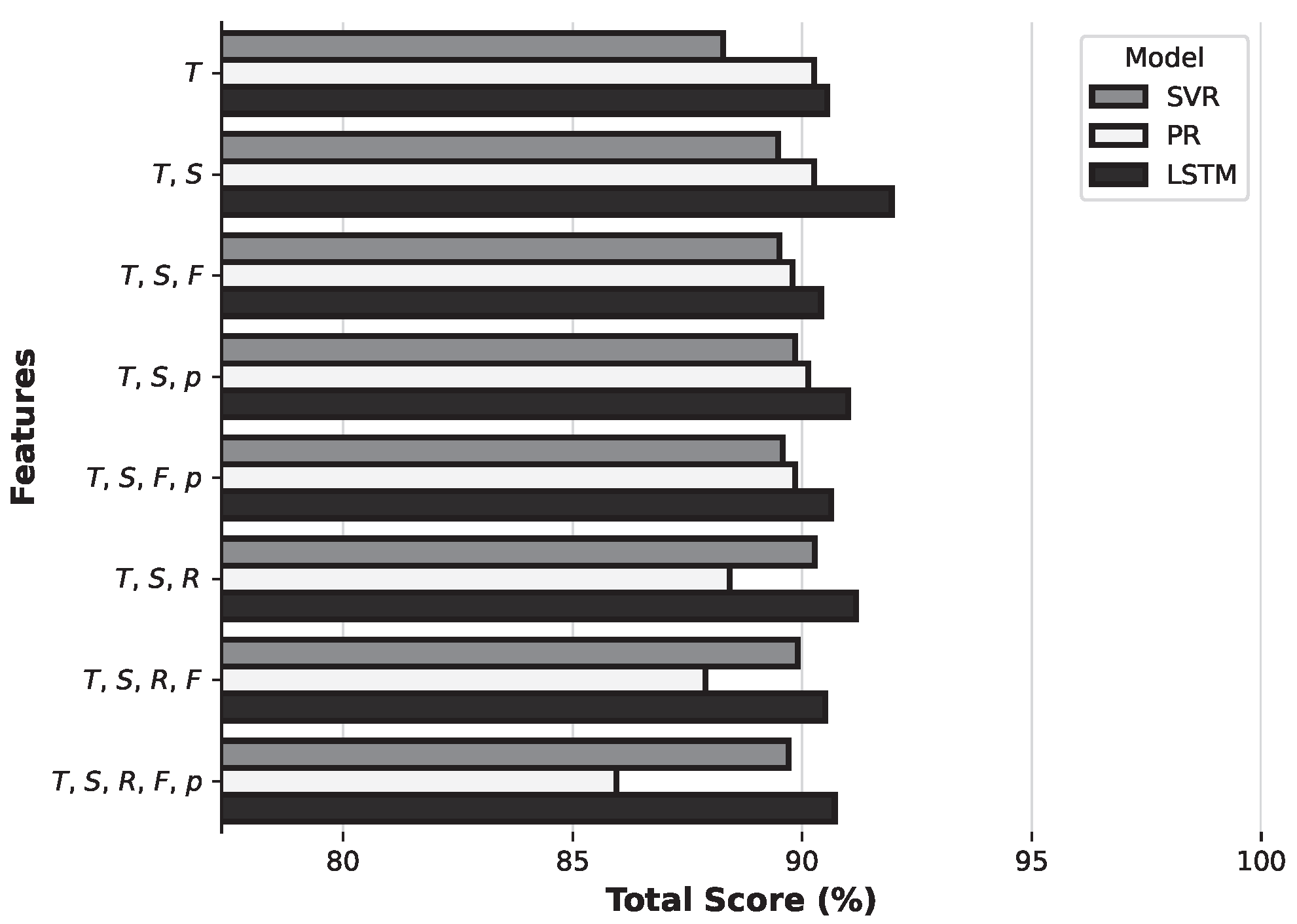
The next phase of the experiment involved producing a detailed design and fine tuning and testing three predictive models (PR, SVR, and LSTM) on each of the selected feature sets. This phase identified the most effective configurations and performed a thorough search for the optimal hyperparameters of each model. Adjustments were made according to the specific feature set by creating a parameter grid of different suitable hyperparameter combinations for each model, and for each of these combinations, the model was trained and tested on a small fraction of the real dataset. The results were then processed, and the combination which produced the lowest error rate was selected for additional processing. Each model was then fine-tuned, followed by testing and calculation of the models’ metrics. This systematic approach enabled a comprehensive evaluation of each model’s predictive accuracy, and crucially, its ability to generalise to unseen data.
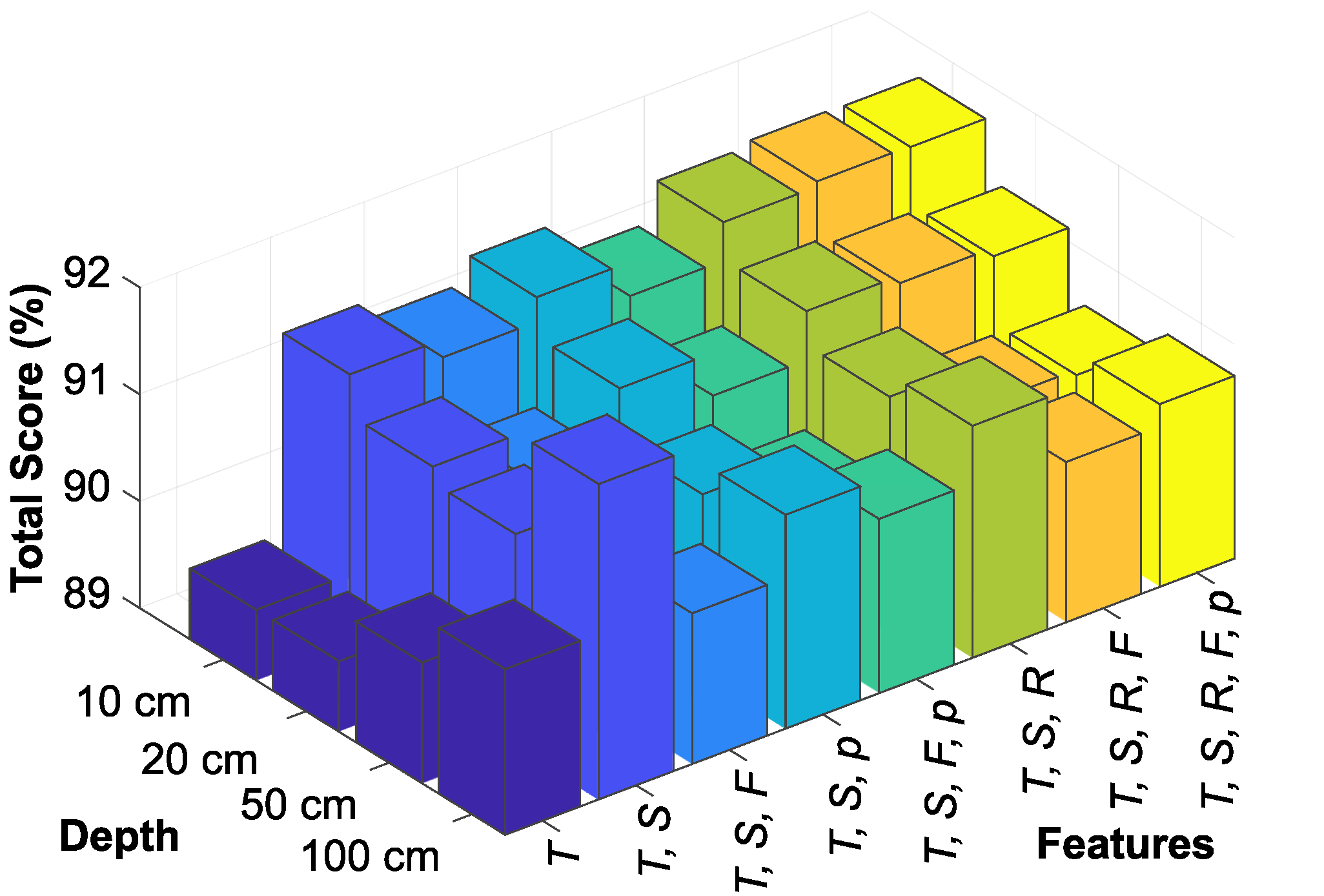
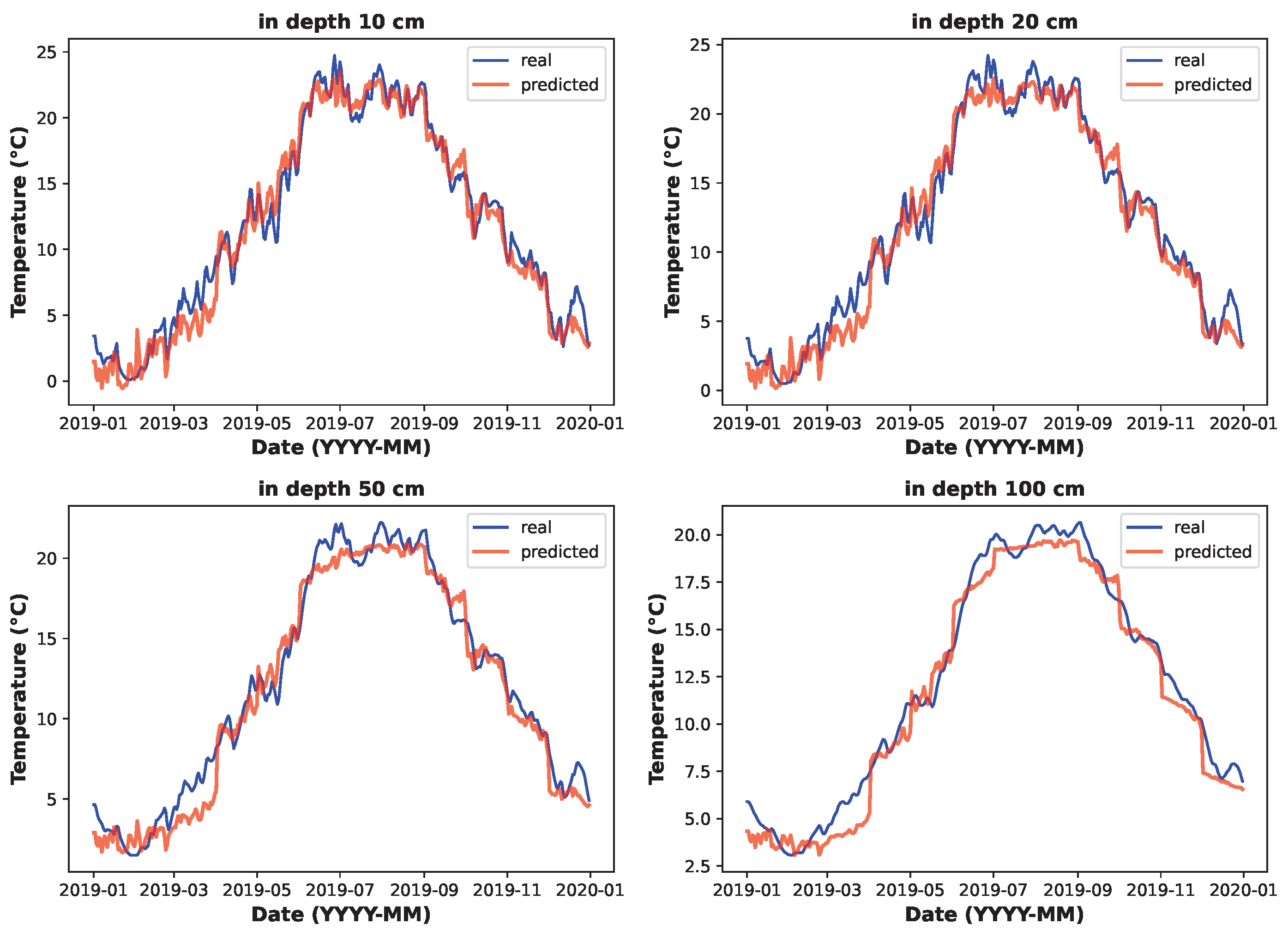
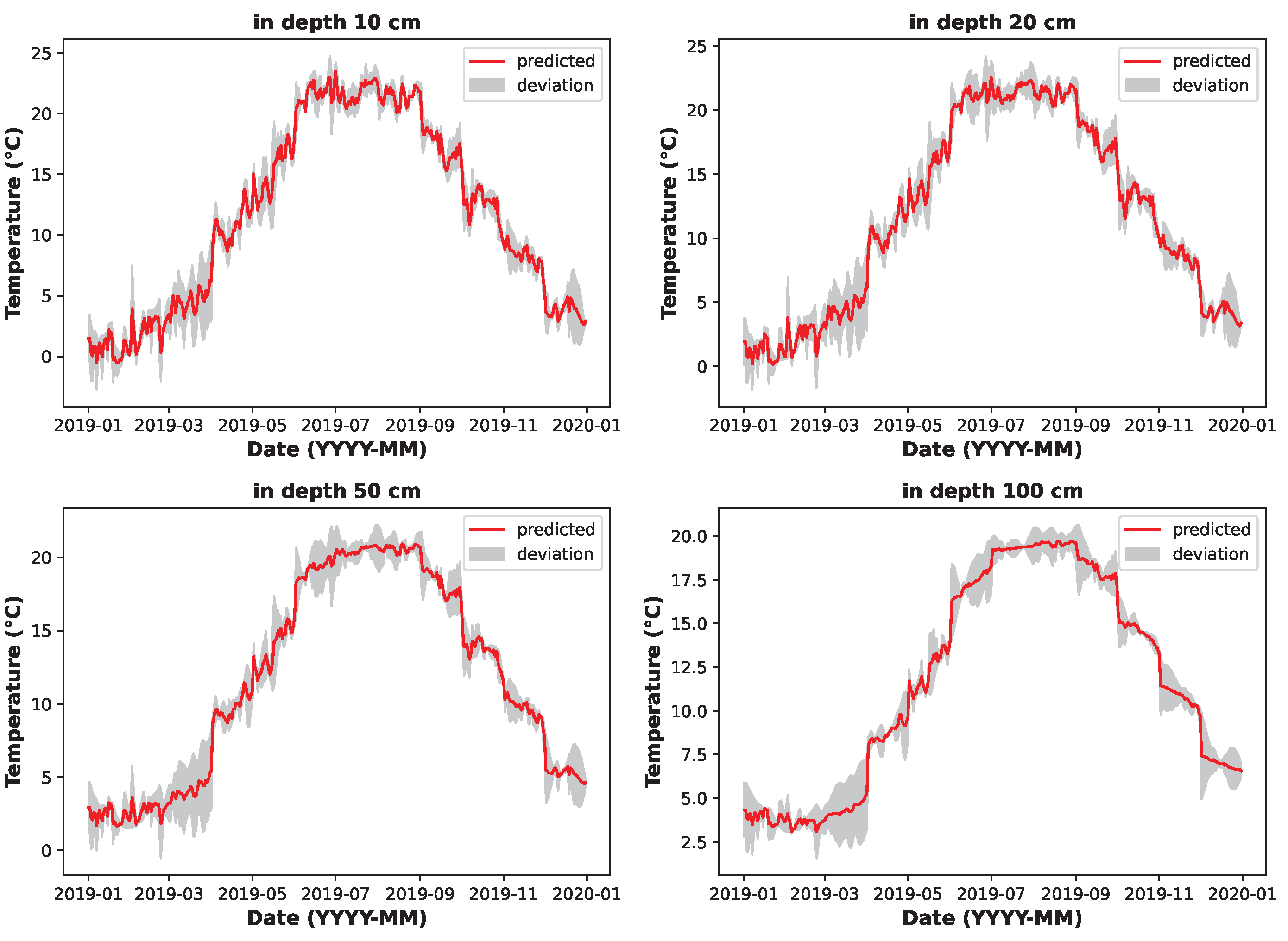
Finally, the experiment moved into a cross-validation phase where each feature set was compared to determine the most effective combination and best respective predictive model. This phase examined the suitability of each feature set from multiple analytical perspectives, including a comprehensive comparison of the overall average total score, identification of the highest total score, assessment of the effectiveness of the feature set at different soil depths, and a detailed analysis of both the average and highest total scores, specifically at the 50 and 100 cm depths. This multi-faceted assessment provided an overall understanding of the predictive power of each feature set and its impact on model performance in different scenarios. Once the most appropriate feature set was identified, the best overall model with the highest total and average achieved jump was selected.




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}