

Adaptive Autoencoder-Based Intrusion Detection System with Single Threshold for CAN Networks



Abstract
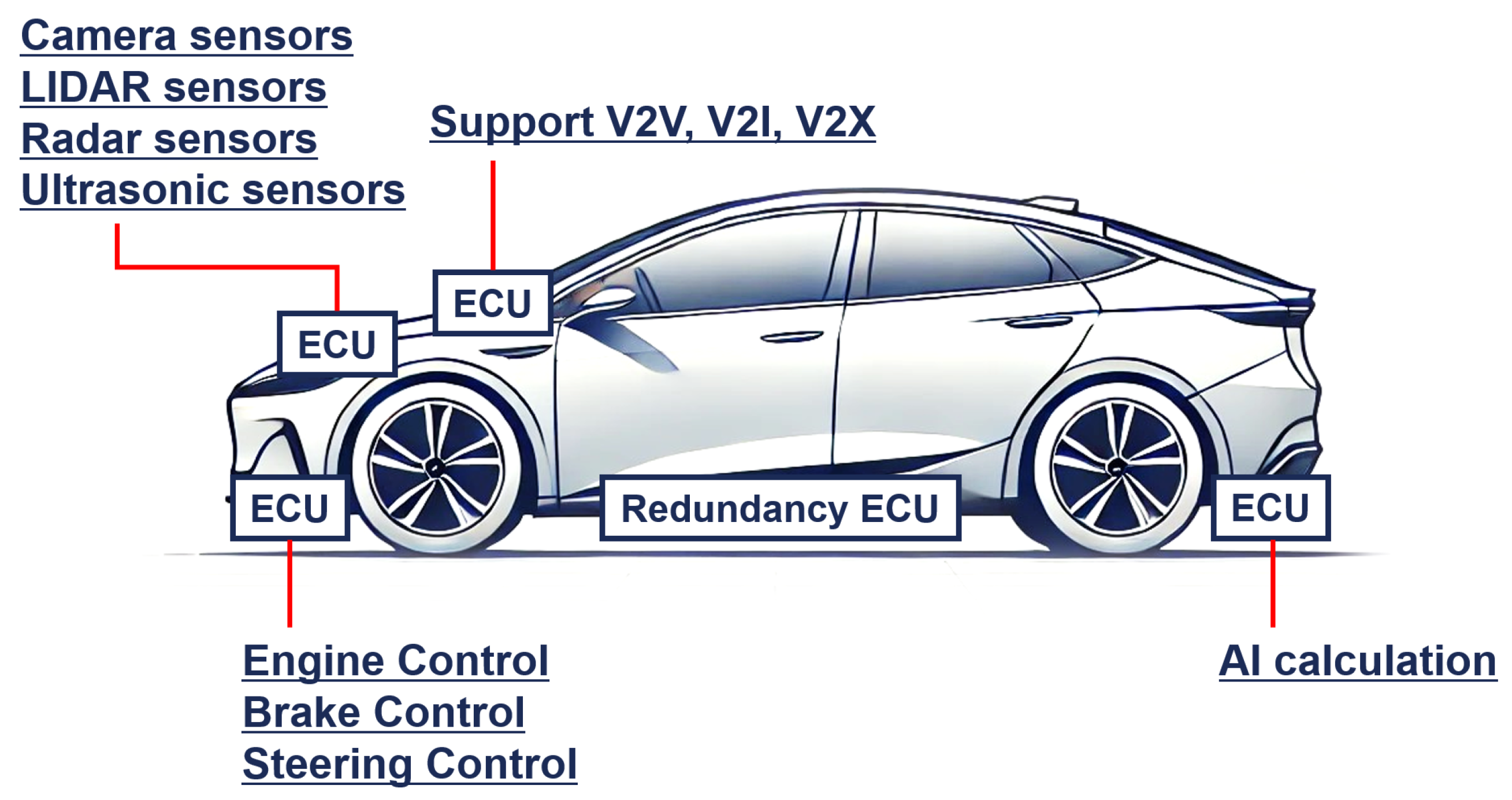
1. Introduction
- This paper presents the development of a deep learning-based IDS for in-vehicle networks. To effectively detect unknown attacks, an unsupervised learning model, specifically an autoencoder, was employed.
- The proposed model requires the determination of the optimal number of data frames to be grouped during training and the threshold for distinguishing between normal and attack data to achieve high performance. A KDE function was utilized to identify the optimal frame count and threshold.
- The IDS model, initially validated in software, was redesigned as a lightweight hardware implementation. It was deployed on an FPGA board and evaluated under real-time CAN communication.
2. Theoretical Background
2.1. Controller Area Network
2.1.1. Controller Area Network Overview
- Start of Frame: The SoF is a single bit that marks the beginning of the frame, indicating the initiation of communication.
- Arbitration field: The arbitration field consists of an 11-bit standard ID, a 1-bit substitute remote request (SRR), a 1-bit identifier extension (IDE), an 18-bit extended ID, and a 1-bit remote transmission request (RTR). This field determines the priority of the message. The SRR bit ensures compatibility between CAN 2.0A, which uses an 11-bit ID, and CAN 2.0B, which employs a 29-bit ID. The IDE bit distinguishes between CAN2.0A and CAN2.0B, while the RTR bit differentiates between data frames and remote frames.
- Control field: The control field is composed of r1, r0, and the data length code (DLC), which define the message format and data length. The r1 and r0 bits are reserved, while the DLC specifies the size of the data field.
- Data field: The data field contains the actual data being transmitted and allows for a maximum data size of up to 8 bytes.
- CRC field: The CRC field ensures the integrity of the transmitted data and is used for error detection.
- ACK field: The ACK field is an acknowledgment bit that indicates successful receipt of the message by the receiver.
- End of Frame: The EoF is a single bit that marks the conclusion of the frame and signals the completion of transmission.
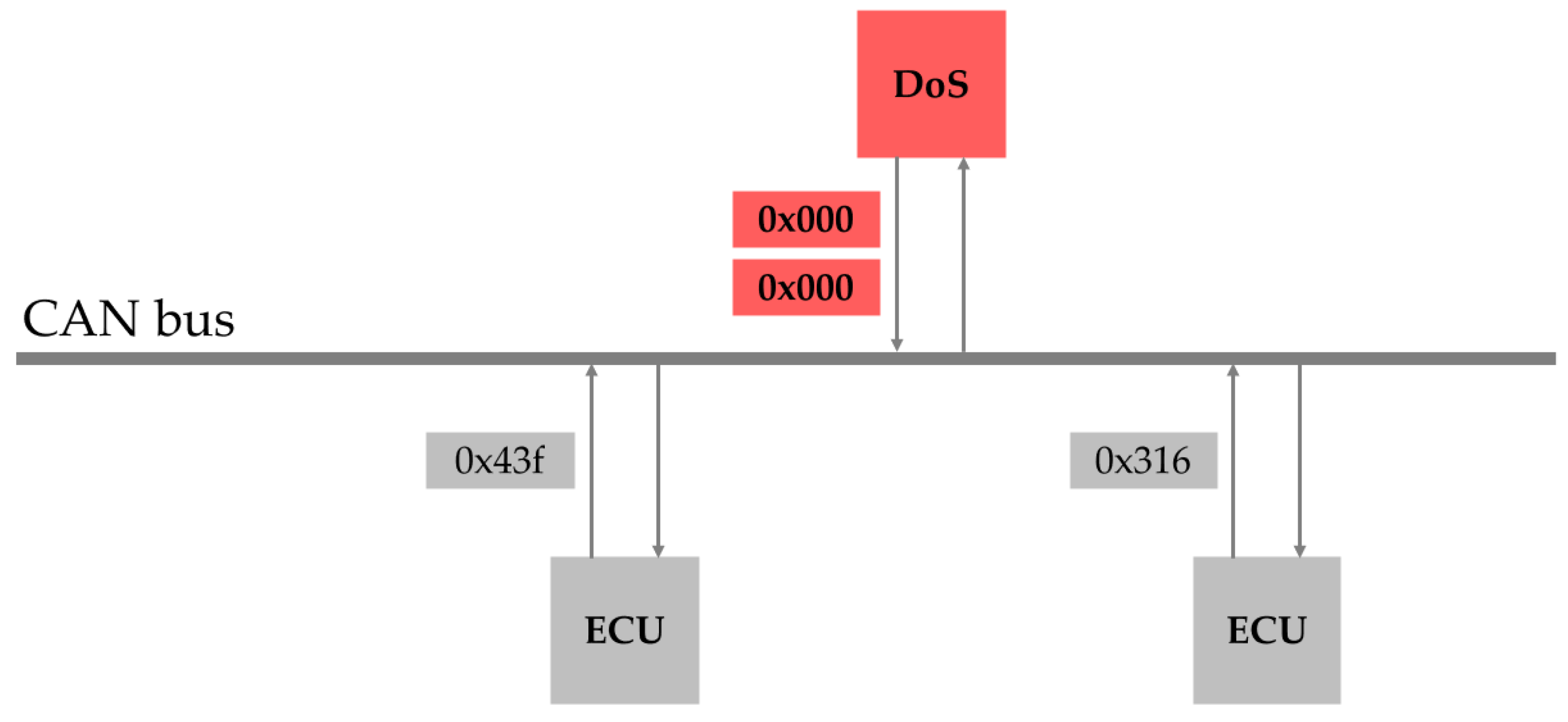
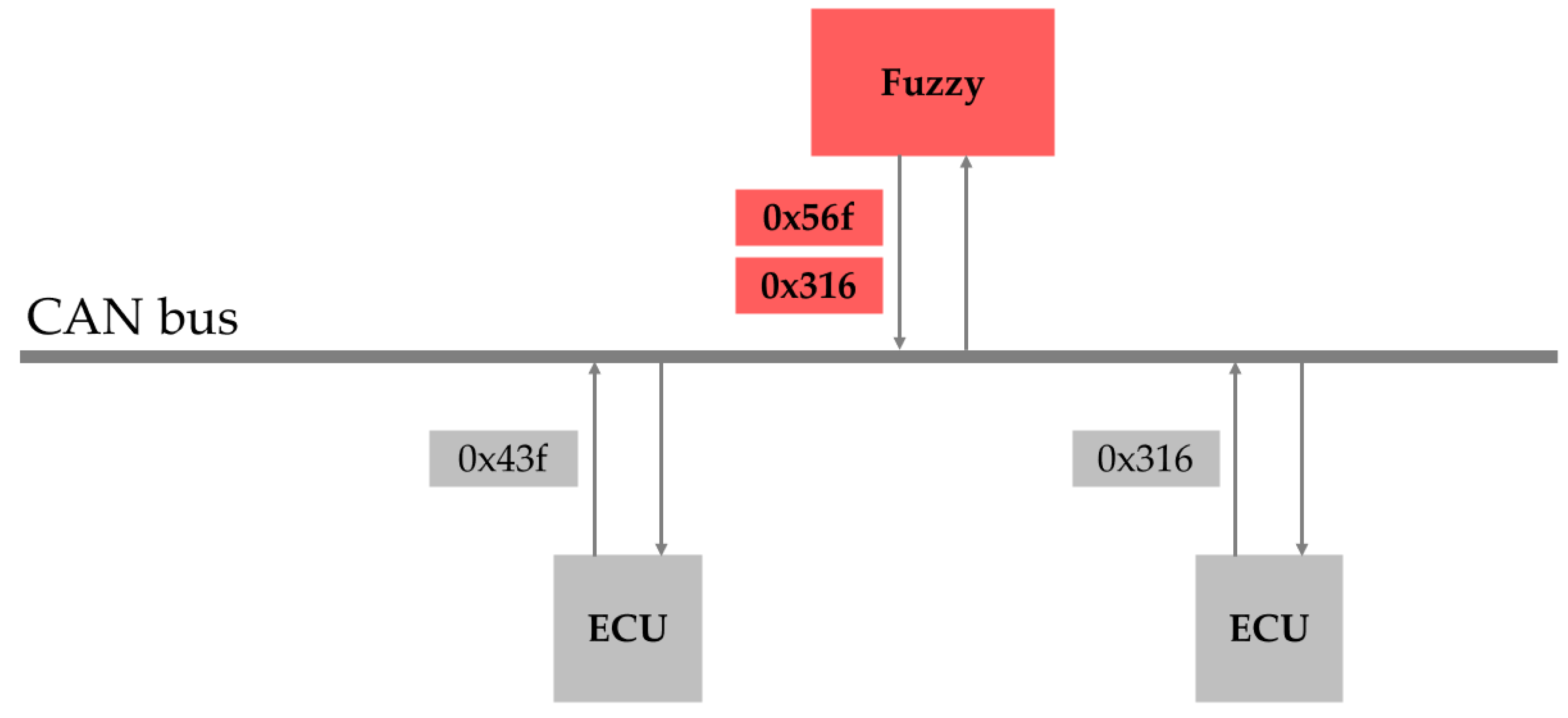
2.1.2. CAN Bus Attack
2.2. Autoencoder
2.3. Gaussian Kernel Density Estimation
3. Materials and Methods
3.1. Dataset
3.2. Data Preprocessing
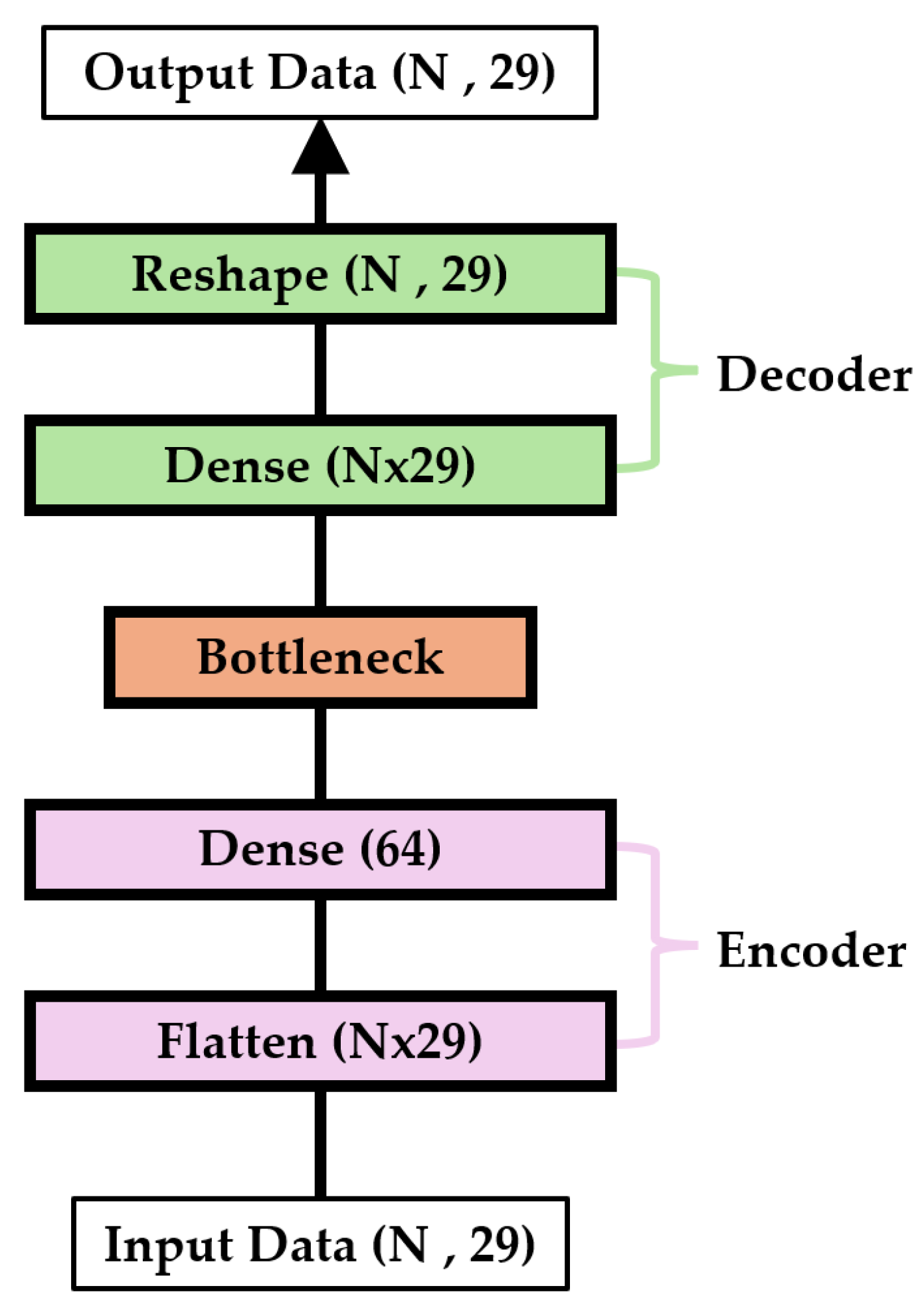
3.3. Model Structure
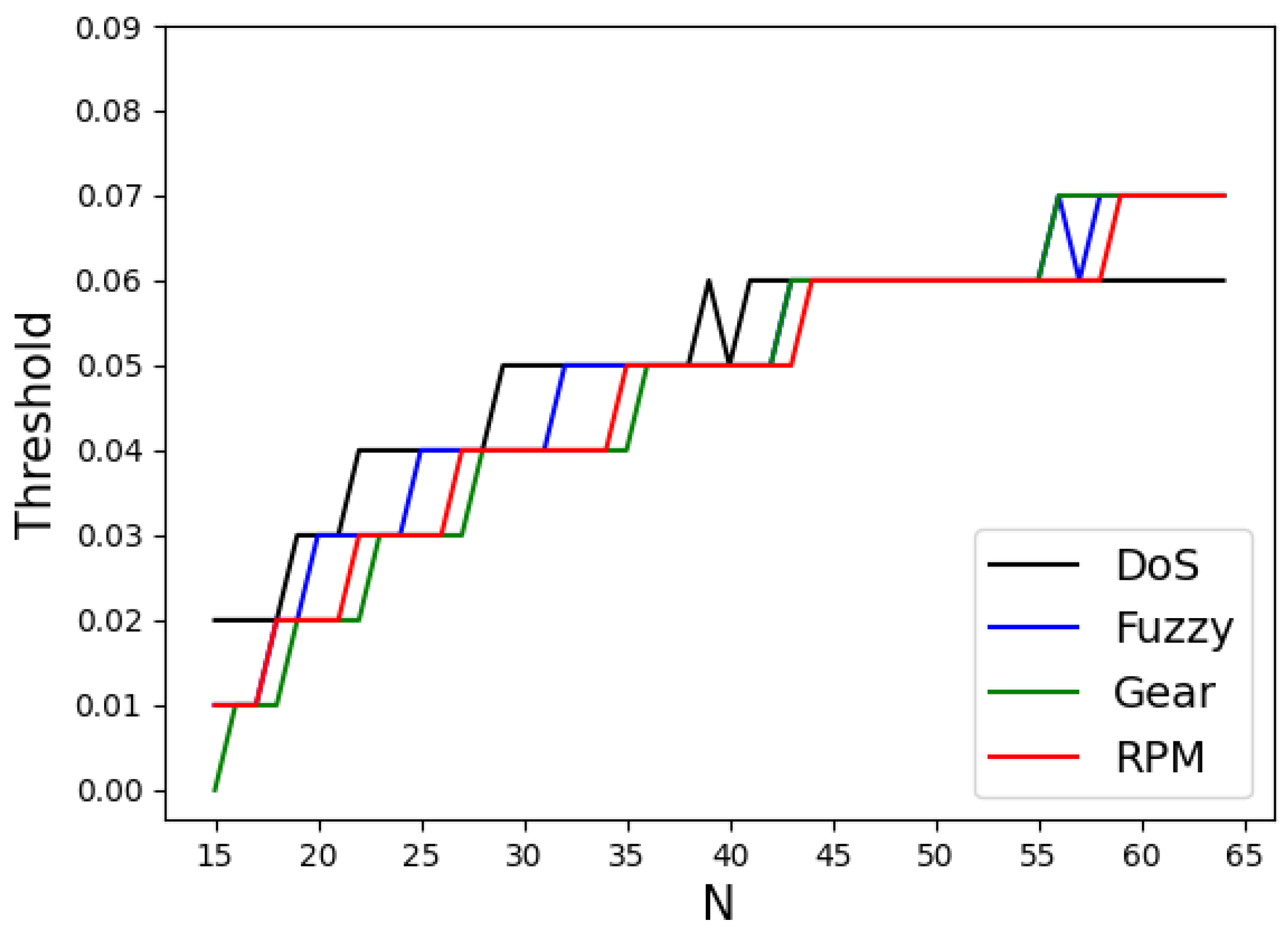
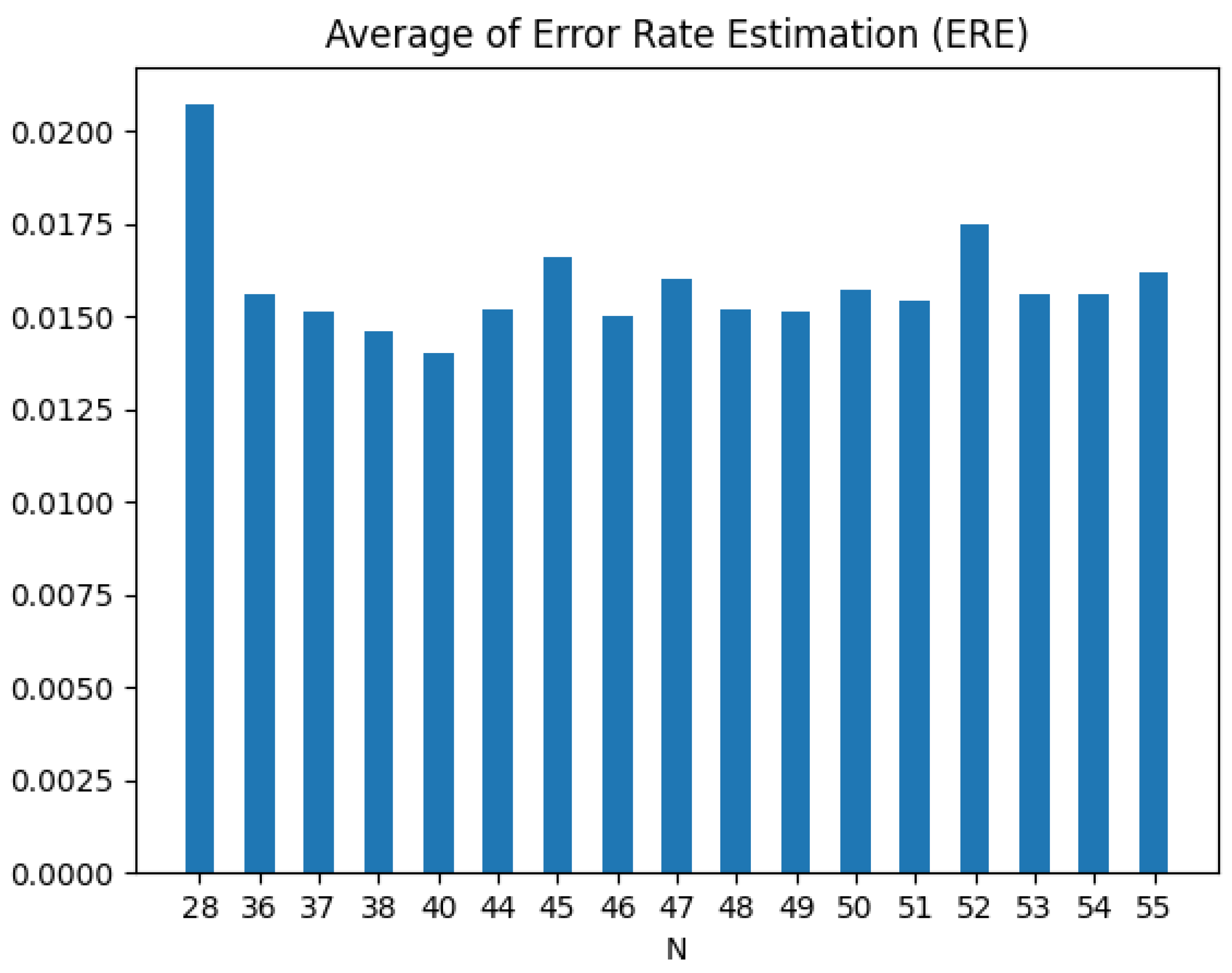
3.4. Determination of Optimal Threshold and Frame Count
| Algorithm 1 Determination of Optimal Value of N and Threshold |
| 1: Input: Trained autoencoder model using N frames 2: Output: and 3: Initialize , , 4: Initialize = () 5: Initialize k = 6: for N from 15 to 64 do 7: (x) = (x) 8: for from do 9: (x) = (x) 10: = (|(x) - (x)|) 11: 12: 13: 14: end for 15: 16: 17: 18: if then 19: = 20: Add N to set Y 21: Add to set L 22: 23: end if 24: end for 25: Find as the N with the smallest 26: Retrieve corresponding from L for , denote as |
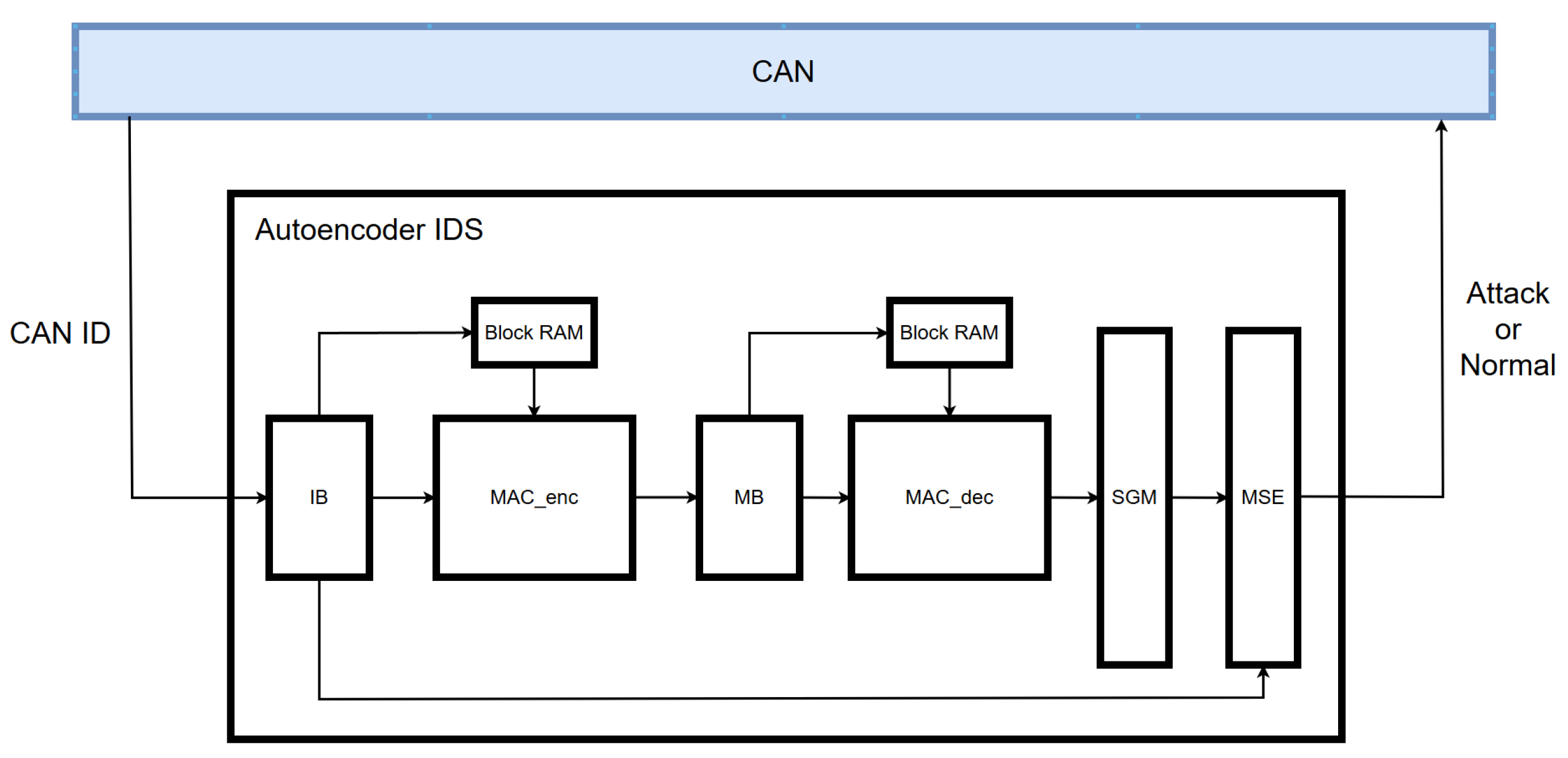
3.5. Hardware Implementation
- The 11-bit CAN ID is received and expanded to 29 bits using a zero-padding technique.
- The transformed 29-bit CAN ID is sent bit by bit to the MAC_enc module and simultaneously transferred to the MSE module for later loss computation.
- In the MAC_enc module, each input bit received from the input buffer is multiplied with a 16-bit weight retrieved from Block RAM and then accumulated.
- Once the operations for 40 CAN IDs are completed, the accumulated value is passed to the middle buffer module.
- The middle buffer module adds a bias term to the received value, applies the ReLU function, and forwards the result to the MAC_dec module.
- In the MAC_dec module, the 16-bit value is multiplied by a 16-bit weight retrieved from Block RAM and summed.
- After all computations are completed, a bias term is added and the result is forwarded to the sigmoid module.
- The sigmoid module applies an approximated sigmoid function and sends the output to the MSE module.
- The MSE module calculates the loss using the received output and the originally stored input value based on the mean squared error method.
- Finally, the computed loss is compared with a predefined threshold to determine whether an attack is present.
3.5.1. Parameter
3.5.2. PLAN Sigmoid
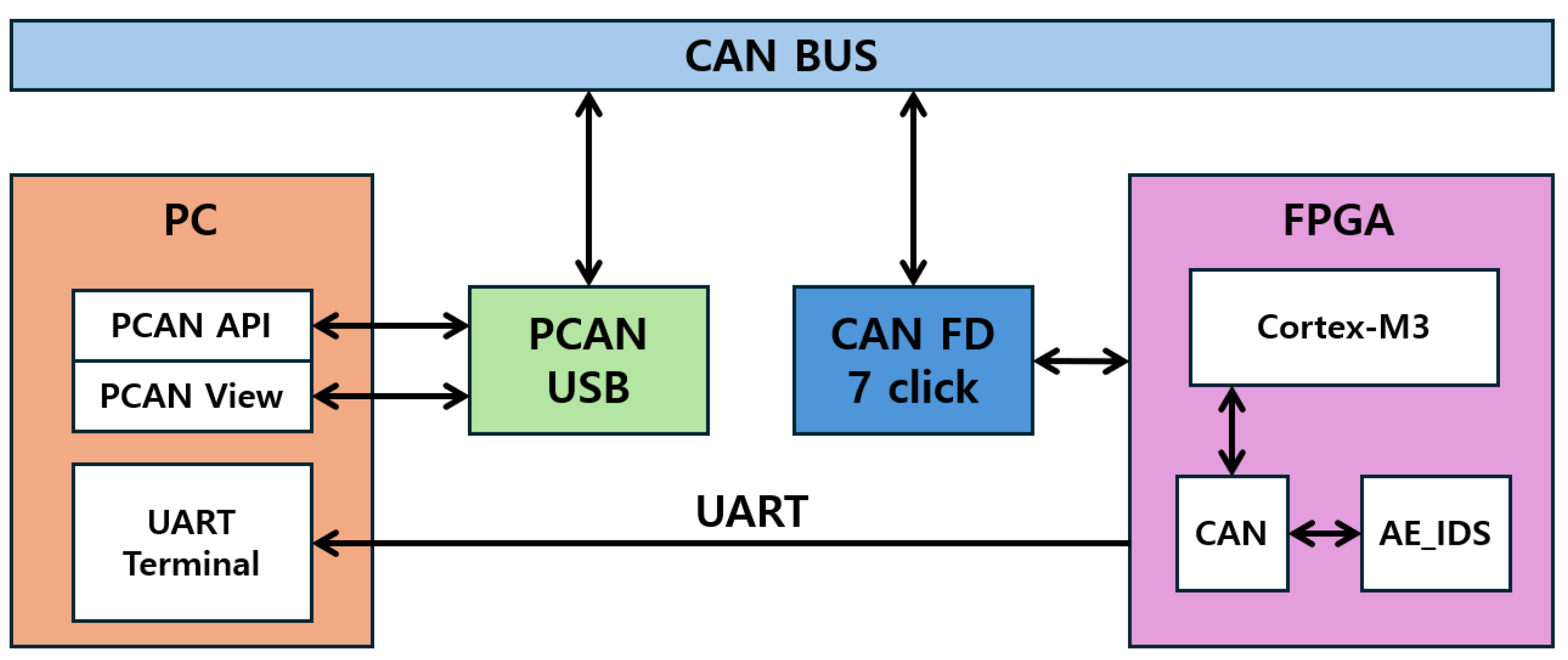
3.5.3. Hardware Verification Environment
4. Results
4.1. Performance Metrics
- Accuracy: Accuracy is the proportion of correctly classified instances out of all predictions. It evaluates how well the model classifies the entire dataset.
- Precision: Precision indicates the proportion of cases predicted as attacks that are actually attacks. It assesses the ability of the model to minimize false positive predictions for attacks.
- Recall: Recall refers to the proportion of actual attack cases that the model correctly predicts as attacks. It is particularly useful in scenarios where minimizing false negative predictions is crucial.
- F1-Score: F1-score represents the harmonic mean of precision and recall and evaluates the balance between these two metrics.
4.2. Experimental Results
4.3. Discussion and Limitation
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koscher, K.; Czeskis, A.; Roesner, F.; Patel, S.; Kohno, T.; Checkoway, S.; McCoy, D.; Kantor, B.; Anderson, D.; Shacham, H.; et al. Experimental security analysis of a modern automobile. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 447–462. [Google Scholar]
- Chowdhury, A.; Karmakar, G.; Kamruzzaman, J.; Jolfaei, A.; Das, R. Attacks on self-driving cars and their countermeasures: A survey. IEEE Access 2020, 8, 207308–207342. [Google Scholar] [CrossRef]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Hobert, L.; Festag, A.; Llatser, I.; Altomare, L.; Visintainer, F.; Kovacs, A. Enhancements of V2X communication in support of cooperative autonomous driving. IEEE Commun. Mag. 2015, 53, 64–70. [Google Scholar] [CrossRef]
- Tanksale, V. Intrusion detection for controller area network using support vector machines. In Proceedings of the IEEE 16th International Conference on Mobile Ad Hoc and Sensor Systems Workshops (MASSW), Monterey, CA, USA, 4–7 November 2019; pp. 121–126. [Google Scholar]
- Tomlinson, A.; Bryans, J.; Shaikh, S.A. Using a one-class compound classifier to detect in-vehicle network attacks. In Proceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO), New York, NY, USA, 15–19 July 2018; pp. 1926–1929. [Google Scholar]
- Song, H.M.; Woo, J.; Kim, H.K. In-vehicle network intrusion detection using deep convolutional neural network. Veh. Commun. 2020, 21, 100198. [Google Scholar] [CrossRef]
- Seo, E.; Song, H.M.; Kim, H.K. GIDS: GAN based intrusion detection system for in-vehicle network. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, UK, 28–30 August 2018; pp. 1–6. [Google Scholar]
- De Araujo-Filho, P.F.; Pinheiro, A.J.; Kaddoum, G.; Campelo, D.R.; Soares, F.L. An efficient intrusion prevention system for CAN: Hindering cyber-attacks with a low-cost platform. IEEE Access 2021, 9, 166855–166869. [Google Scholar] [CrossRef]
- Agrawal, K.; Alladi, T.; Agrawal, A.; Chamola, V.; Benslimane, A. NovelADS: A novel anomaly detection system for intra-vehicular networks. IEEE Trans. Intell. Transp. Syst. 2022, 11, 22596–22606. [Google Scholar] [CrossRef]
- Khandelwal, S.; Shreejith, S. A Lightweight FPGA-based IDS-ECU Architecture for Automotive CAN. In Proceedings of the 2022 international Conference on Field-Programmable Technology (ICFPT), Hong Kong, 5–9 February 2022; pp. 1–9. [Google Scholar]
- Rangsikunpum, A.; Amiri, S.; Ost, L. An FPGA-Based Intrusion Detection System Using Binarised Neural Network for CAN Bus Systems. In Proceedings of the 2024 IEEE International Conference on Industrial Technology (ICIT), Bristol, UK, 25–27 March 2024; pp. 1–6. [Google Scholar]
- Luo, F.; Wang, J.; Zhang, X.; Jiang, Y.; Li, Z.; Luo, C. In vehicle network intrusion detection systems: A systematic survey of deep learning-based approaches. PeerJ Comput. Sci. 2023, 9, e1648. [Google Scholar] [CrossRef]
- Alqahtani, H.; Kumar, G. A deep learning-based intrusion detection system for in-vehicle networks. Comput. Electr. Eng. 2022, 104, 108447. [Google Scholar] [CrossRef]
- Ashraf, J.; Bakhshi, A.D.; Moustafa, N.; Khurshid, H.; Javed, A.; Beheshti, A. Novel deep learning-enabled LSTM autoencoder architecture for discovering anomalous events from intelligent transportation systems. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4507–4518. [Google Scholar] [CrossRef]
- Longari, S.; Valcarcel, D.H.N.; Zago, M.; Carminati, M.; Zanero, S. CANnolo: An anomaly detection system based on LSTM autoencoders for controller area network. IEEE Trans. Netw. Serv. Manag. 2020, 18, 1913–1924. [Google Scholar] [CrossRef]
- Cheng, P.; Han, M.; Liu, G. DESC-IDS: Towards an efficient real-time automotive intrusion detection system based on deep evolving stream clustering. Future Gener. Comput. Syst. 2023, 140, 266–281. [Google Scholar] [CrossRef]
- Wei, P.; Wang, B.; Dai, X.; Li, L.; He, F. A novel intrusion detection model for the CAN bus packet of in-vehicle network based on attention mechanism and autoencoder. Digit. Commun. Netw. 2023, 9, 14–21. [Google Scholar] [CrossRef]
- Lokman, S.F.; Othman, A.T.; Musa, S.; Abu Bakar, M.H. Deep contractive autoencoder-based anomaly detection for in-vehicle controller area network (CAN). In Progress in Engineering Technology; Springer: Cham, Switzerland, 2019; pp. 195–205. [Google Scholar]
- Kukkala, V.K.; Thiruloga, S.V.; Pasricha, S. INDRA: Intrusion detection using recurrent autoencoders in automotive embedded systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 3698–3710. [Google Scholar] [CrossRef]
- Kheddar, H.; Dawoud, D.W.; Awad, A.I.; Himeur, Y.; Khan, M.K. Reinforcement-Learning-Based Intrusion Detection in Communication Networks: A Review. IEEE Commun. Surv. Tutor. 2024. [Google Scholar] [CrossRef]
- Kheddar, H.; Himeur, Y.; Awad, A.I. Deep transfer learning for intrusion detection in industrial control networks: A comprehensive review. J. Netw. Comput. Appl. 2023, 220, 103760. [Google Scholar] [CrossRef]
- Bosch Specification. Controller Area Network (CAN) Specification; Robert Bosch GmbH: Gerlingen, Germany, 1991; Volume 50. [Google Scholar]
- Checkoway, S.; McCoy, D.; Kantor, B.; Anderson, D.; Shacham, H.; Savage, S.; Koscher, K.; Czeskis, A.; Roesner, F.; Kohno, T. Comprehensive experimental analyses of automotive attack surfaces. In Proceedings of the 20th USENIX Security Symposium (USENIX Security 11), San Francisco, CA, USA, 10–12 August 2011. [Google Scholar]
- Hoppe, T.; Kiltz, S.; Dittmann, J. Security threats to automotive CAN networks—Practical examples and selected short-term countermeasures. In Proceedings of the International Conference on Computer Safety, Reliability, and Security, Berlin/Heidelberg, Germany, 22–25 September 2008; pp. 235–248. [Google Scholar]
- Hounsinou, S.; Stidd, M.; Ezeobi, U.; Olufowobi, H.; Nasri, M.; Bloom, G. Vulnerability of controller area network to schedule-based attacks. In Proceedings of the IEEE Real-Time Systems Symposium, Dortmund, DE, Germany, 7–10 December 2021; pp. 495–507. [Google Scholar]
- Woo, S.; Jo, H.J.; Lee, D.H. A practical wireless attack on the connected car and security protocol for in-vehicle CAN. IEEE Trans. Intell. Transp. Syst. 2015, 16, 993–1006. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Pawar, A. Noise reduction in images using autoencoders. In Proceedings of the 3rd International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 3–5 December 2020; pp. 987–990. [Google Scholar]
- Hacking and Countermeasure Research Lab. Car-Hacking Dataset. Available online: https://ocslab.hksecurity.net/Datasets/car-hacking-dataset (accessed on 14 May 2025).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IDS Model | Limitation | Our Model |
|---|---|---|
| Supervised Learning | Can detect only attacks used in training | Can detect attacks not used in training |
| GAN | Lower performance compared to supervised models | Comparable performance to supervised models |
| iForest | Lower performance compared to supervised models | Comparable performance to supervised models |
| NovelADS | Requires separate thresholds for each attack type | Uses a single threshold for all attack types |
| QMLP | High hardware resource consumption | Reduced hardware resource usage through lightweight design |
| BNN | High hardware resource consumption | Reduced hardware resource usage through lightweight design |
| Data Type | # of Total Frame | # of Normal Frame | # of Attack Frame |
|---|---|---|---|
| Normal | 988,987 | 988,987 | - |
| DoS attack | 3,665,771 | 3,078,250 | 587,521 |
| Fuzzy attack | 3,838,860 | 3,347,013 | 491,847 |
| Gear attack | 4,443,142 | 3,845,890 | 597,252 |
| RPM attack | 4,621,702 | 3,966,805 | 654,897 |
| Condition | Operation |
|---|---|
| Attack Type | Learning Method | Detection Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| Supervised | DCNN | 99.97 | 100 | 99.89 | 99.95 | |
| GIDS | 97.90 | 96.80 | 99.60 | 98.18 | ||
| DoS attack | Unsupervised | iForest | - | - | - | - |
| NovelADS | - | 99.97 | 99.91 | 99.94 | ||
| Our Model | 98.87 | 98.19 | 98.98 | 98.58 | ||
| Supervised | DCNN | 99.82 | 99.95 | 99.65 | 99.80 | |
| GIDS | 98.00 | 97.30 | 99.50 | 98.39 | ||
| Fuzzy attack | Unsupervised | iForest | 99.29 | 95.07 | 99.93 | 97.44 |
| NovelADS | - | 99.99 | 100 | 100 | ||
| Our Model | 99.48 | 99.54 | 99.43 | 99.48 | ||
| Supervised | DCNN | 99.95 | 99.99 | 99.89 | 99.94 | |
| GIDS | 96.20 | 98.10 | 96.50 | 97.29 | ||
| Gear attack | Unsupervised | iForest | 99.24 | 94.79 | 100 | 97.33 |
| NovelADS | - | 99.89 | 99.93 | 99.91 | ||
| Our Model | 99.16 | 99.40 | 99.00 | 99.20 | ||
| Supervised | DCNN | 99.97 | 99.99 | 99.94 | 99.96 | |
| GIDS | 98.00 | 98.30 | 99.00 | 98.65 | ||
| RPM attack | Unsupervised | iForest | 99.85 | 98.97 | 100 | 99.48 |
| NovelADS | - | 99.91 | 99.90 | 99.91 | ||
| Our Model | 99.25 | 99.49 | 99.11 | 99.30 |
| Model | FLOPs | Parameters |
|---|---|---|
| DCNN | 100.13 M | 1.71 M |
| GIDS | 1.59 M | 1.52 M |
| NovelADS | 36.46 M | 0.90 M |
| Our Model | 0.30 M | 0.15 M |
| Attack Type | IDS Type | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| DoS attack | Software | 98.87 | 98.19 | 98.98 | 98.58 |
| Hardware | 98.93 | 98.34 | 98.98 | 98.66 | |
| Fuzzy attack | Software | 99.48 | 99.54 | 99.43 | 99.48 |
| Hardware | 99.40 | 99.47 | 99.34 | 99.41 | |
| Gear attack | Software | 99.16 | 99.40 | 99.00 | 99.20 |
| Hardware | 99.17 | 99.37 | 99.04 | 99.21 | |
| RPM attack | Software | 99.25 | 99.49 | 99.11 | 99.30 |
| Hardware | 99.32 | 99.55 | 99.18 | 99.37 |
| Metric | QMLP-IDS | BNN-IDS | Proposed IDS |
|---|---|---|---|
| FPGA Device | ZCU104 XCZU7EV | Zedboard XC7Z020 | Nexys Video XC7A200T |
| LUT | 56,733 | 33,224 | 9223 |
| Flip Flop | 72,146 | 54,175 | 10,472 |
| BRAM (Mb) | 3.06 | 4.85 | 2.39 |
| URAM (Mb) | 6.75 | 0 | 0 |
| Power (W) | 3.76 | 2.29 | 0.25 |
| Latency (ms) | 0.24 | 0.26 | 0.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Im, H.; Lee, S. Adaptive Autoencoder-Based Intrusion Detection System with Single Threshold for CAN Networks. Sensors 2025, 25, 4174. https://doi.org/10.3390/s25134174
Kim D, Im H, Lee S. Adaptive Autoencoder-Based Intrusion Detection System with Single Threshold for CAN Networks. Sensors. 2025; 25(13):4174. https://doi.org/10.3390/s25134174
Chicago/Turabian StyleKim, Donghyeon, Hyungchul Im, and Seongsoo Lee. 2025. "Adaptive Autoencoder-Based Intrusion Detection System with Single Threshold for CAN Networks" Sensors 25, no. 13: 4174. https://doi.org/10.3390/s25134174
APA StyleKim, D., Im, H., & Lee, S. (2025). Adaptive Autoencoder-Based Intrusion Detection System with Single Threshold for CAN Networks. Sensors, 25(13), 4174. https://doi.org/10.3390/s25134174