
A Comprehensive Review of Explainable Artificial Intelligence (XAI) in Computer Vision


Abstract
1. Introduction
1.1. Motivation and Challenges
1.2. Background on XAI and CV
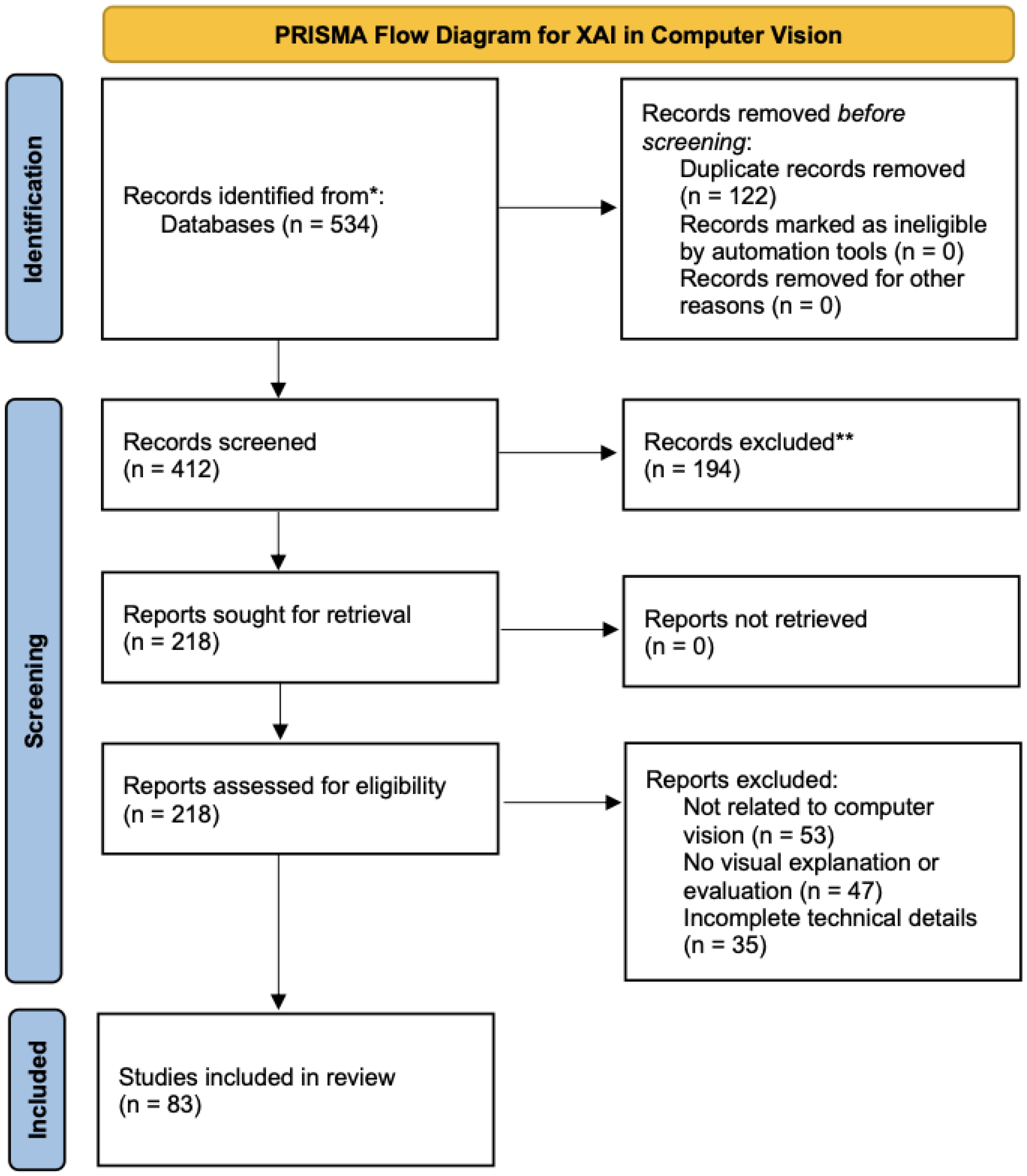
1.3. Literature Selection Methodology
1.4. Objectives and Scope
2. Categorization of XAI Methods
2.1. Attribution-Based XAI Methods
2.1.1. Grad-CAM (Gradient-Weighted Class Activation Mapping)
2.1.2. FullGrad-CAM and FullGrad-CAM++
2.1.3. SmoothGrad
2.2. Activation-Based Methods
2.2.1. DeConvNets (Deconvolutional Networks)
2.2.2. Class Activation Mapping (CAM)
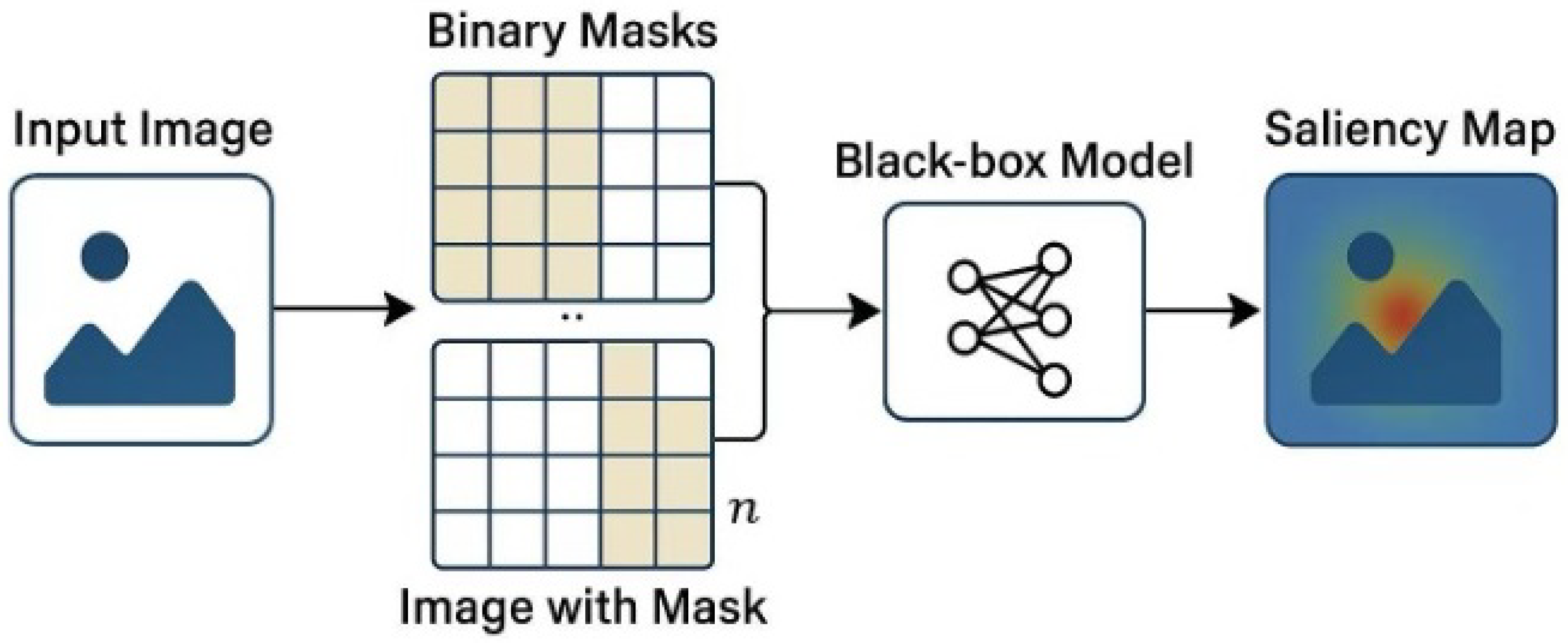
2.3. Perturbation-Based Methods
2.4. Transformer-Based XAI
3. Experiments and Evaluation
3.1. Evaluation Metrics (Faithfulness, Localization, Robustness)
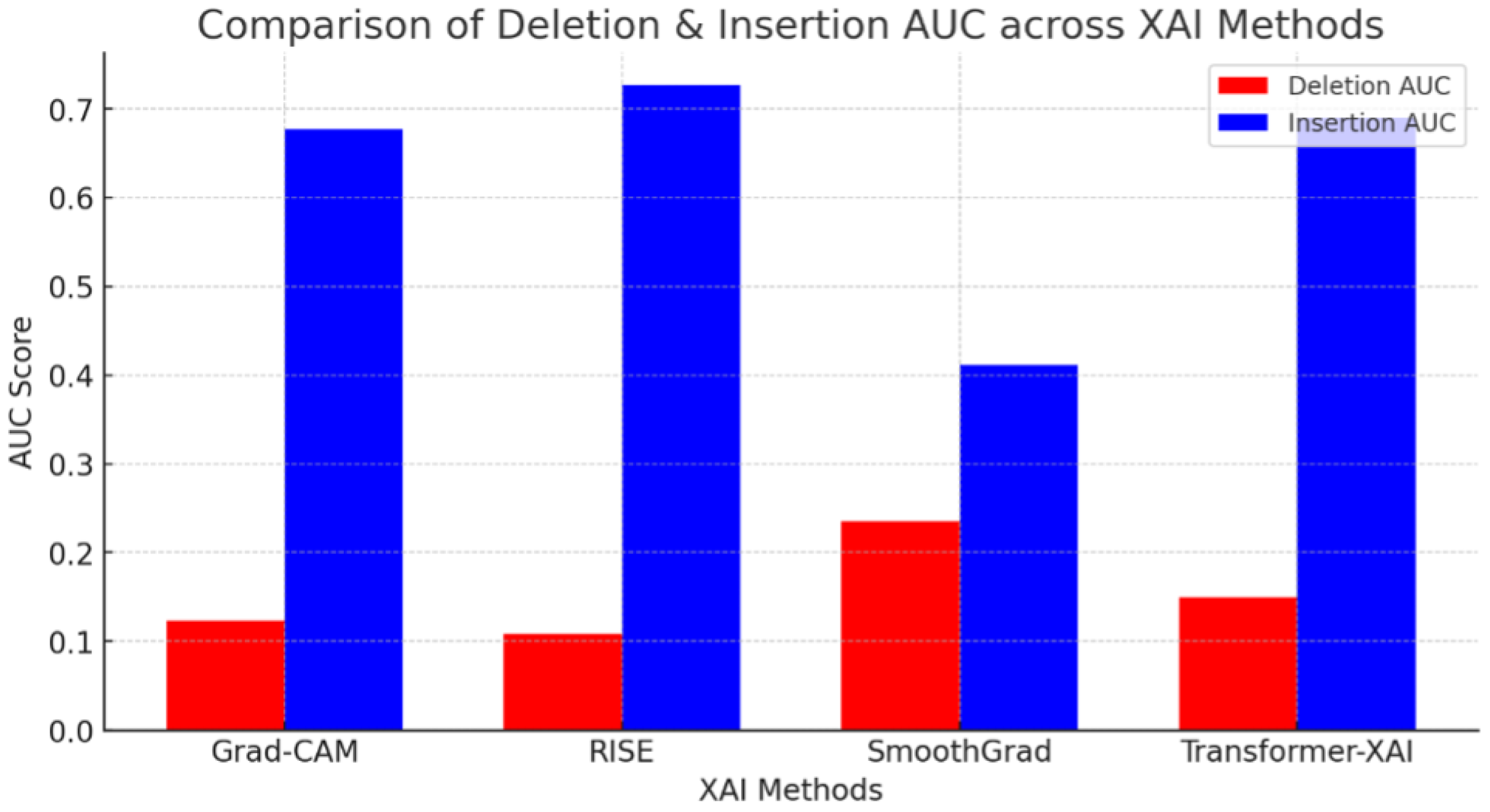
- Faithfulness: Measured using insertion and deletion AUC tests, which evaluate the impact of the highlighted regions on the model’s decision.
- Localization Accuracy: Measured using pointing game accuracy, which tests whether the most important regions match the ground truth.
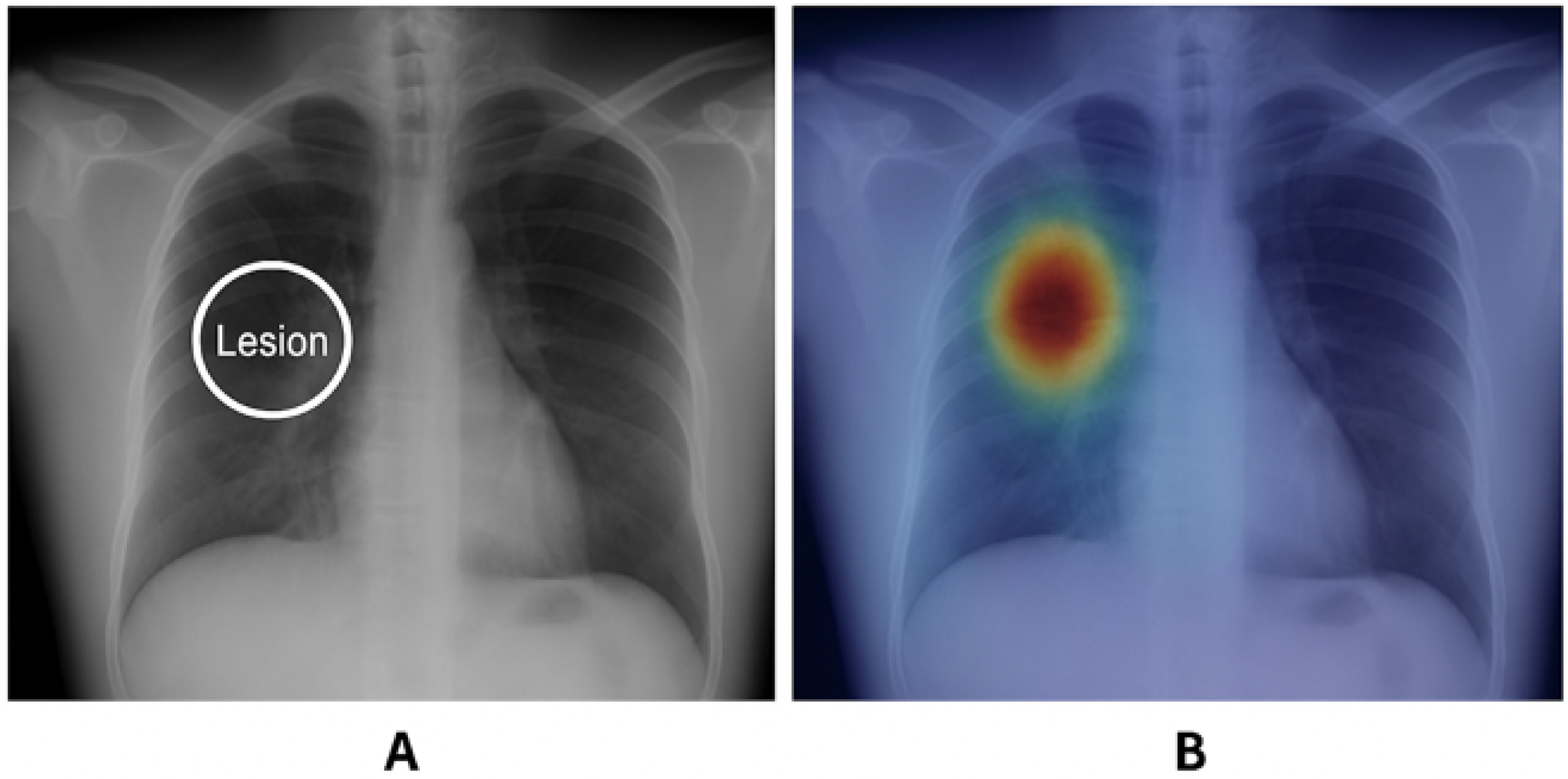
- Medical Imaging Overlap: In medical datasets such as CheXpert, Intersection over Union (IoU) is used to quantify the overlap between saliency maps and disease regions.
- Transparency Score: Some frameworks assign interpretability indices to explanations based on domain-specific expert scoring.
3.2. Benchmark Datasets
- ImageNet and CIFAR-10 for natural image classification and localization.
- CheXpert and NIH ChestX-ray14 for medical imaging, emphasizing pixel-level diagnostic localization.
- IEEE P7001 (Transparency of Autonomous Systems Standard. IEEE Standards Association: Piscataway, USA, 2021) have introduced comprehensive efforts aimed at standardizing datasets to enable fair, reproducible comparisons across methods.
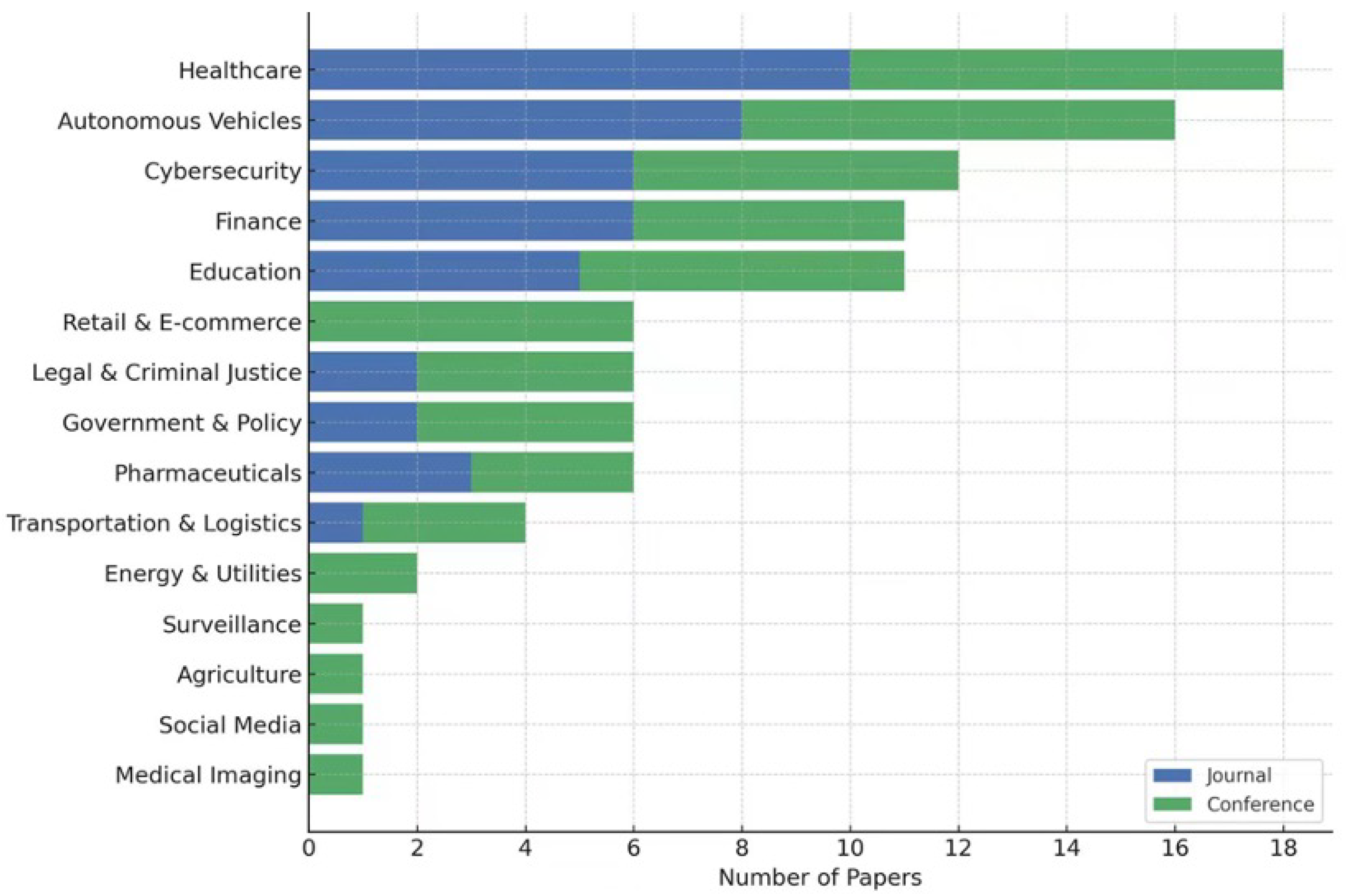
3.3. Domain-Specific Evaluation
- Medical imaging requires high-resolution, spatially accurate maps to support diagnostic decision-making.
- Autonomous driving needs real-time saliency generation with temporal consistency across video frames.
- Generic object recognition often focuses on class-level attribution using coarse heatmaps.
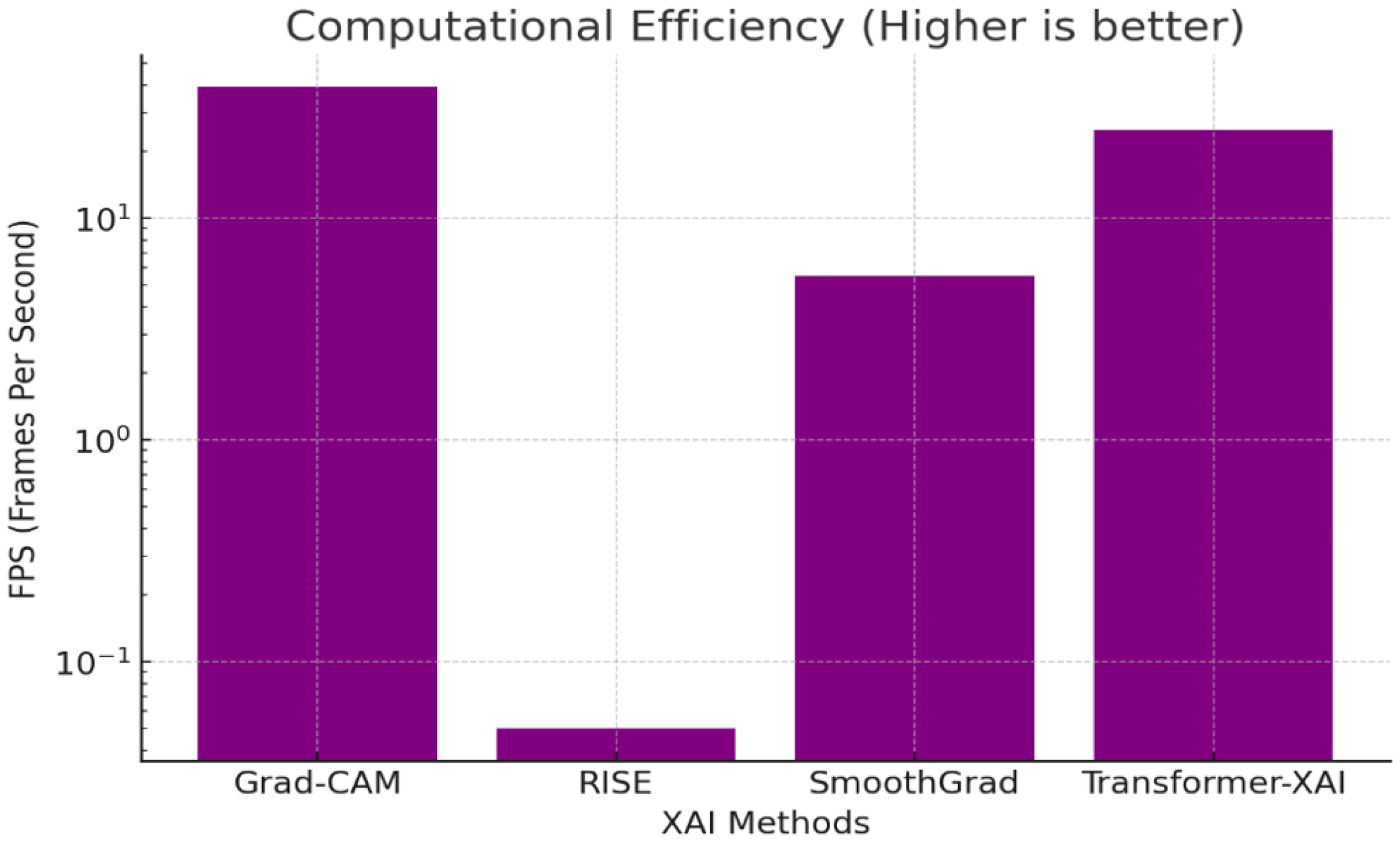
3.4. Computational Efficiency and Scalability
3.5. Human-Centered Evaluation
3.6. Experimental Results and Visualization
3.6.1. Faithfulness Evaluation
- A higher insertion AUC means the identified features significantly contribute to the model’s decision.
- A lower deletion AUC means removing important features drastically reduces confidence.
- RISE achieves the best faithfulness (highest Insertion AUC = 0.727, lowest Deletion AUC = 0.108).
- Grad-CAM performs well but slightly worse than RISE.
- SmoothGrad struggles in faithfulness due to noise reduction reducing critical feature importance.
- Transformer-based XAI performs well, but global attention introduces some loss in localized feature importance.
3.6.2. Localization Accuracy
- RISE performs the best (91.9%), making it the most precise localization method.
- SmoothGrad (89.5%) performs better than Grad-CAM but has high variance.
- Transformer-based XAI (88.2%) provides strong localization but is slightly more diffused due to global attention.
3.6.3. Computational Efficiency
- Grad-CAM is the fastest (39 FPS), making it ideal for real-time applications.
- RISE is extremely slow (0.05 FPS) due to repeated perturbations.
- Transformer-based XAI (25 FPS) is a good balance of accuracy and efficiency.
3.6.4. Medical Imaging Performance
- Transformer-based XAI achieves the highest IoU (0.090), making it most effective in medical imaging applications.
- RISE (0.045 IoU) performs better than Grad-CAM and SmoothGrad but at high computational cost.
- Grad-CAM (0.027 IoU) and SmoothGrad (0.021 IoU) struggle in aligning with expert annotations.
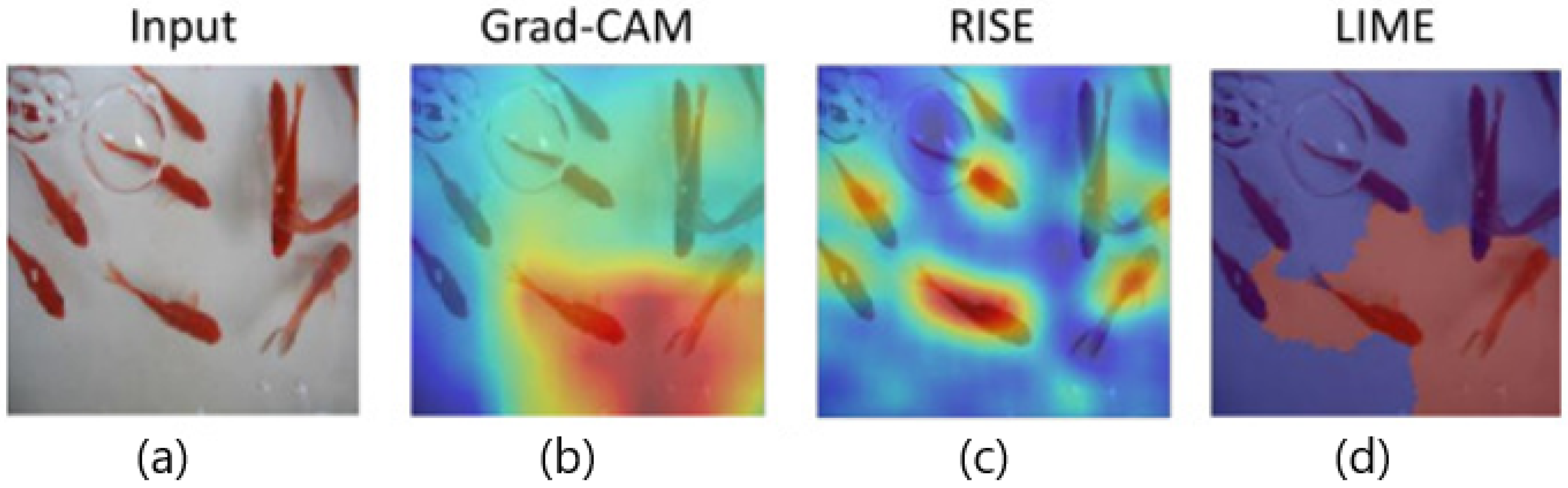
3.6.5. Visual Comparison and Qualitative Examples
3.7. Comparative Analysis (Grad-CAM vs. RISE vs. Transformers)
3.7.1. Grad-CAM
- Best for: Large-scale single-object interpretation with high efficiency.
- Drawback: May miss fine-grained details.
3.7.2. RISE
- RISE heatmaps tend to provide more comprehensive coverage than Grad-CAM (sometimes even exceeding Grad-CAM in pointing game accuracy).
- Major drawback: Extremely high computational cost, making it unsuitable for real-time applications. Additionally, the heatmaps can sometimes appear noisy and scattered, especially when using a small number of masks or when dealing with objects of varying sizes.
- Best for: High-precision attribution analysis, such as identifying key factors in medical decision-making.
- Drawback: Not practical for large-scale or real-time interpretations due to computational overhead.
3.7.3. SmoothGrad
- This improves human readability, making important regions more distinct with sharper edges.
- However, studies have shown that SmoothGrad often highlights weakly contributing features, such as image textures or background noise, leading to biased faithfulness scores [22].
- Best for: Improving visual aesthetics in explanations, especially when presenting results to non-technical users.
- Drawback: Lower faithfulness scores compared to Grad-CAM and RISE.
3.7.4. Transformer-Based XAI
- More advanced transformer-based XAI methods incorporate gradients, attention propagation, and multi-layer interactions to improve faithfulness (e.g., attention rollout and gradient-based backpropagation).
- Best for: Global-level explanations, making it suitable for context-aware classification tasks.
- Drawback: Attention heatmaps tend to cover broader regions, which may reduce localization precision.
- Best for: Object detection, medical imaging, and other tasks requiring long-range dependencies.
- Drawback: Requires attention refinement to improve localization precision.
4. Discussion
4.1. Effectiveness and Limitations
4.2. Ethical and Societal Implications
4.2.1. Trust and Transparency
4.2.2. Bias Amplification and Fairness
4.2.3. Informed Consent and User Autonomy
4.2.4. Misuse of Explanations
4.2.5. Regulatory and Legal Implications
4.3. Domain-Specific Challenges
4.3.1. Medical Imaging
4.3.2. Autonomous Driving and Real-Time Systems
4.3.3. General Image Classification
4.3.4. Surveillance and Security
4.3.5. Cross-Domain and Multimodal Systems
4.4. Open Problems and Future Directions
4.4.1. Lack of Standardized Evaluation Protocols
4.4.2. Faithfulness vs. Plausibility Trade-Off
4.4.3. Robustness and Stability of Explanations
4.4.4. Human-Centered and Context-Aware Explanations
4.4.5. Integration of Domain Knowledge and Causal Reasoning
4.4.6. Alignment with Legal and Ethical Frameworks
4.5. Real-World Case Studies
4.5.1. Diabetic Retinopathy Detection
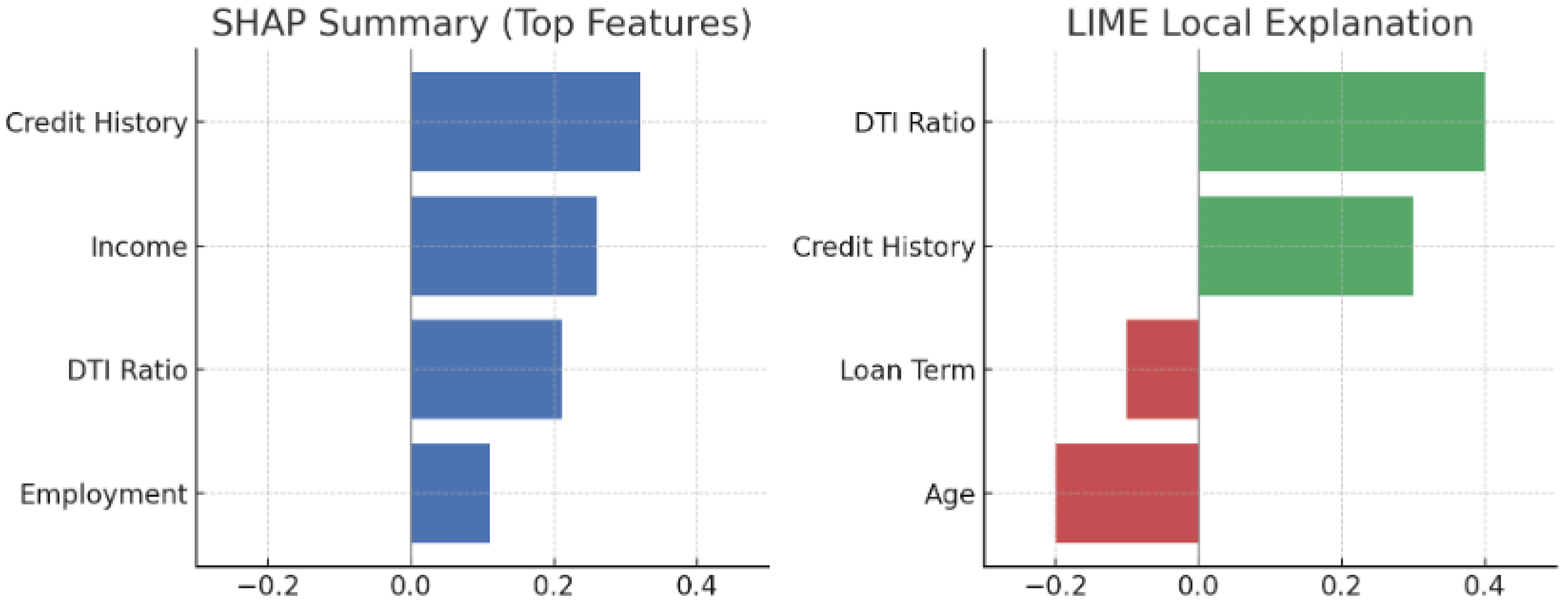
4.5.2. Financial Application
4.5.3. Counterfactual XAI as a Complement to Heatmap-Based Methods
4.5.4. Concrete Defect Detection with Ultrasonic–AI Hybrid Approach
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abhishek, K.; Kamath, D. Attribution-based XAI methods in computer vision: A review. arXiv 2022, arXiv:2211.14736. [Google Scholar]
- Gujjsa, R.; Tsai, C.-W.; Kurasova, O. Explainable AI (XAI) in image segmentation in medicine, industry, and beyond: A survey. arXiv 2024, arXiv:2405.01636. [Google Scholar]
- Kuznietsov, A.; Gyevnar, B.; Wang, C.; Peters, S.; Albrecht, S.V. Explainable AI for safe and trustworthy autonomous driving: A systematic review. arXiv 2024, arXiv:2402.10086. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you?: Explaining the predictions of any classifier. In Proceedings of the The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 12–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Petsiuk, V.; Das, A.; Saenko, K. RISE: Randomized input sampling for explanation of black-box models. BMVC 2018. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Samek, W.; Wiegand, T.; Müller, K.-R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Mendes, C.; Rios, T.N. Explainable artificial intelligence and cybersecurity: A systematic literature review. arXiv 2023, arXiv:2303.01259. [Google Scholar]
- Černevičienė, J.; Kabašinskas, A. Explainable artificial intelligence (XAI) in finance: A systematic literature review. Artif. Intell. Rev. 2024, 57, 216. [Google Scholar] [CrossRef]
- Liu, Q.; Pinto, J.D.; Paquette, L. Applications of explainable AI (XAI) in education. In Trust and Inclusion in AI-Mediated Education; Sánchez, L., Yao, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2024; pp. 123–145. [Google Scholar] [CrossRef]
- Zhang, Y.; Gu, S.; Song, J.; Pan, B.; Zhao, L. XAI Benchmark for Visual Explanation. arXiv 2023, arXiv:2310.08537. [Google Scholar]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. Available online: https://www.researchgate.net/publication/320727679_Grad-CAM_Generalized_Gradient-based_Visual_Explanations_for_Deep_Convolutional_Networks (accessed on 15 February 2025).
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), Online, 5–10 July 2020; pp. 4190–4197. [Google Scholar] [CrossRef]
- Clement, T.; Nguyen, T.T.H.; Abdelaal, M.; Cao, H. XAI-Enhanced Semantic Segmentation Models for Visual Quality Inspection. arXiv 2024, arXiv:2401.09900. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 93. [Google Scholar] [CrossRef]
- Jain, S.; Wallace, B.C. Attention is not explanation. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–5 June 2019; pp. 3543–3556. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Y.; Thirusevli, A.A.; Hamou-Lhadj, A. XAIport: A Service Framework for the Early Adoption of XAI in AI Model Development. In Proceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results, Lisbon, Portugal, 14–20 April 2024. [Google Scholar] [CrossRef]
- Suara, S.; Jha, A.; Sinha, P.; Sekh, A.A. Is Grad-CAM explainable enough? arXiv 2023, arXiv:2307.10506. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 2673–2682. Available online: http://proceedings.mlr.press/v80/kim18d.html (accessed on 15 February 2025).
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. SmoothGrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Shreim, H.; Gizzini, A.K.; Ghandour, A.J. Trainable Noise Model as an XAI evaluation method: Application on Sobol for remote sensing image segmentation. arXiv 2023, arXiv:2310.01828. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Proceedings of the ICLR Workshop 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar] [CrossRef]
- Höhl, A.; Obadic, I.; Fernández-Torres, M.-Á.; Oliveira, D.; Zhu, X.X. Recent Trends, Challenges, and Limitations of Explainable AI in Remote Sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–18 June 2024; pp. 8199–8205. [Google Scholar]
- Mitra, A.; Chakravarty, A.; Ghosh, N.; Sarkar, T.; Sethuraman, R.; Sheet, D. A systematic search over deep convolutional neural network architectures for screening chest radiographs. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 1225–1228. [Google Scholar] [CrossRef]
- Hryniewska, W.; Grudzień, A.; Biecek, P. LIMEcraft: Handcrafted Superpixel Selection and Inspection for Visual Explanations. ResearchGate 2022. Available online: https://www.researchgate.net/publication/356282190_LIMEcraft_Handcrafted_superpixel_selection_and_inspection_for_Visual_eXplanations (accessed on 15 February 2025). [CrossRef]
- Choe, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 782–791. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, S.F. Visual interpretability for deep learning: A survey. Front. Inf. Technol. Electron. Eng. 2018, 19, 27–39. [Google Scholar] [CrossRef]
- Mishra, A.; Shetkar, A.; Bapat, G.M.; Ojha, R.; Verlekar, T.T. XAI-based gait analysis of patients walking with Knee-Ankle-Foot orthosis using video cameras. arXiv 2024, arXiv:2402.16175. [Google Scholar]
- Lee, J.H.; Mikulik, G.P.; Schwalbe, G.; Wagstaff, S.; Wolter, D. Concept-Based Explanations in Computer Vision: Where Are We and Where Could We Go? arXiv 2024, arXiv:2409.13456. [Google Scholar]
- Borys, K.; Schmitt, Y.A.; Nauta, M.; Seifert, C.; Krämer, N.; Friedrich, C.M.; Nensa, F. Explainable AI in medical imaging: An overview for clinical practitioners—Beyond saliency-based XAI approaches. Eur. J. Radiol. 2023, 162, 110786. [Google Scholar] [CrossRef]
- Ghassemi, M.; Oakden-Rayner, L.; Beam, A.L. The false hope of current approaches to explainable artificial intelligence in health care. Lancet Digit. Health 2021, 3, e745–e750. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.P.T.; Nguyen, H.T.T.; Cao, H. ODExAI: A Comprehensive Object Detection Explainable AI Evaluation. arXiv 2025, arXiv:2504.19249. Available online: https://arxiv.org/abs/2504.19249 (accessed on 1 June 2025).
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS) 30, Long Beach, CA, USA, 4–9 December 2017; Available online: https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html (accessed on 15 February 2025).
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Akhtar, N. A survey of explainable AI in deep neural networks. arXiv 2023, arXiv:2301.13445. [Google Scholar]
- Kundu, S. AI in medicine must be explainable. Nat. Med. 2021, 27, 1328. [Google Scholar] [CrossRef]
- Kundu, S. Measuring trustworthiness is crucial for medical AI tools. Nat. Hum. Behav. 2023, 7, 1812–1813. [Google Scholar] [CrossRef]
- Singh, A.; Sengupta, S.; Lakshminarayanan, V. Explainable deep learning models in medical image analysis. J. Imaging 2020, 6, 52. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. arXiv 2018, arXiv:1706.07269. [Google Scholar] [CrossRef]
- Chen, J.; Song, L.; Wainwright, M.J.; Jordan, M.I. Learning to Explain: An Information-Theoretic Perspective on Model Interpretation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 883–892. Available online: https://proceedings.mlr.press/v80/chen18j.html (accessed on 15 February 2025).
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar] [CrossRef]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. In Proceedings of the Advances in Neural Information Processing Systems, 31, Montreal, QC, Canada, 3–8 December 2018; Available online: https://papers.nips.cc/paper_files/paper/2018/hash/294a8ed24b1ad22ec2e7efea049b8737-Abstract.html (accessed on 15 February 2025).
- Ghorbani, A.; Abid, A.; Zou, J. Interpretation of neural networks is fragile. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3681–3688. [Google Scholar] [CrossRef]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling LIME and SHAP: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES), New York, NY, USA, 7–9 February 2020; pp. 180–186. [Google Scholar] [CrossRef]
- Panda, M.; Mahanta, S.R. Explainable Artificial Intelligence for Healthcare Applications Using Random Forest Classifier with LIME and SHAP. arXiv 2023, arXiv:2311.056. [Google Scholar]
- Chang, C.-H.; Creager, E.; Goldenberg, A.; Duvenaud, D. Explaining image classifiers by counterfactual generation. arXiv 2019, arXiv:1807.08024. [Google Scholar]
- Hooker, S.; Erhan, D.; Kindermans, P.J.; Kim, B. A benchmark for interpretability methods in deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar] [CrossRef]
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.S.; Inouye, D.I.; Ravikumar, P.K. On the (in)fidelity and sensitivity of explanations. In Proceedings of the Advances in Neural Information Processing Systems, 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar] [CrossRef]
- Silva, R.S.R.; Silva, R. FM-G-CAM: A holistic approach for explainable AI in computer vision. arXiv 2023, arXiv:2312.05975. [Google Scholar]
- Kazmierczak, R.; Berthier, E.; Frehse, G.; Franchi, G. Explainability for vision foundation models: A survey. arXiv 2025, arXiv:2501.12203. [Google Scholar] [CrossRef]
- Gao, Y.; Sun, T.S.; Hong, S.R. GNES: Learning to Explain Graph Neural Networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1234–1242. Available online: https://cs.emory.edu/~lzhao41/materials/papers/GNES.pdf (accessed on 15 February 2025).
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328. Available online: https://proceedings.mlr.press/v70/sundararajan17a.html (accessed on 15 February 2025).
- Moradi, M.; Yan, K.; Colwell, D.; Samwald, M.; Asgari, R. Model-agnostic explainable artificial intelligence for object detection in image data. arXiv 2023, arXiv:2303.17249. [Google Scholar] [CrossRef]
- Kindermans, P.-J.; Hooker, S.; Adebayo, J.; Alber, M.; Schütt, K.T.; Dähne, S.; Erhan, D.; Kim, B. The (un)reliability of saliency methods. arXiv 2019, arXiv:1711.00867. [Google Scholar]
- Alvarez-Melis, D.; Jaakkola, T.S. Towards robust interpretability with self-explaining neural networks. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar] [CrossRef]
- Goyal, Y.; Wu, Z.; Ernst, J.; Batra, D.; Parikh, D.; Lee, S. Counterfactual visual explanations. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, S.-C. Visual interpretability for deep learning: A survey. arXiv 2018, arXiv:1802.00614. [Google Scholar] [CrossRef]
- Patricio, C.; Neves, J.C.; Teixeira, L.F. Explainable Deep Learning Methods in Medical Image Classification: A Survey. arXiv 2022, arXiv:2205.04766. [Google Scholar] [CrossRef]
- Dhamdhere, K.; Sundararajan, M.; Yan, Q. How important is a neuron? arXiv 2020, arXiv:1805.12233. [Google Scholar]
- Rajasekaran, V. Explainable AI: Insightful AI Diagnostics. Medium, 2023. Available online: https://medium.com/@Vidya_Rajasekaran/explainable-ai-xai-e82857f10931 (accessed on 15 February 2025).
- Comaniciu, D.; Engel, K.; Georgescu, B.; Mansi, T. Shaping the future through innovations: From medical imaging to precision medicine. Med. Image Anal. 2016, 33, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Tasin, I.; Nabil, T.U.; Islam, S.; Khan, R. Diabetes prediction using machine learning and explainable AI techniques. Healthc. Technol. Lett. 2023, 10, 1–10. [Google Scholar] [CrossRef]
- Ganguly, R.; Singh, D. Explainable Artificial Intelligence (XAI) for the Prediction of Diabetes Management: An Ensemble Approach. J. Emerg. Technol. Innov. Res. 2023, 10, 1–7. Available online: https://thesai.org/Downloads/Volume14No7/Paper_17-Explainable_Artificial_Intelligence_XAI_%20for_the_Prediction_of_Diabetes.pdf (accessed on 15 February 2025). [CrossRef]
- Uy, H.; Fielding, C.; Hohlfeld, A.; Ochodo, E.; Opare, A.; Mukonda, E.; Engel, M.E. Diagnostic test accuracy of artificial intelligence in screening for referable diabetic retinopathy in real-world settings: A systematic review and meta-analysis. PLoS Global Public Health 2023, 3, e0002160. [Google Scholar] [CrossRef] [PubMed]
- Sarvamangala, D.R.; Kulkarni, R.V. Convolutional Neural Networks in Medical Image Understanding: A Survey. Evolut. Intell. 2022, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.-S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable Artificial Intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Nadeem, A.; Vos, D.; Cao, C.; Pajola, L.; Dieck, S.; Baumgartner, R.; Verwer, S. SoK: Explainable machine learning for computer security applications. arXiv 2022, arXiv:2208.10605. [Google Scholar]
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. explAIner: A Visual Analytics Framework for Interactive and Explainable Machine Learning. arXiv 2019, arXiv:1908.00087. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, J.; Chan, A.B.; Hsiao, J.H. Human attention-guided explainable artificial intelligence for computer vision models. Neural Netw. 2024, 177, 106392. [Google Scholar] [CrossRef]
- Rachha, A.; Seyam, M. Explainable AI in education: Current trends, challenges, and opportunities. SoutheastCon 2023, 2023, 1–6. [Google Scholar] [CrossRef]
- Aziz, N.A.; Manzoor, A.; Qureshi, M.D.M.; Qureshi, M.A.; Rashwan, W. Explainable AI in Healthcare: Systematic Review of Clinical Decision Support Systems. medRxiv 2024. [Google Scholar] [CrossRef]
- Quellec, G.; Al Hajj, H.; Lamard, M.; Conze, P.-H.; Massin, P.; Cochennec, B. ExplAIn: Explanatory Artificial Intelligence for Diabetic Retinopathy Diagnosis. arXiv 2020, arXiv:2008.05731. [Google Scholar] [CrossRef] [PubMed]
- Khokhar, P.B.; Pentangelo, V.; Palomba, F.; Gravino, C. Towards Transparent and Accurate Diabetes Prediction Using Machine Learning and Explainable Artificial Intelligence. arXiv 2025, arXiv:2501.18071. [Google Scholar]
- Band, S.S.; Yarahmadi, A.; Hsu, C.-C.; Biyari, M.; Sookhak, M.; Ameri, R.; Dehzangi, I.; Chronopoulos, A.T.; Liang, H.-W. Application of explainable artificial intelligence in medical health: A systematic review of interpretability methods. Inform. Med. Unlocked 2023, 39, 101286. [Google Scholar] [CrossRef]
- Shen, Y.; Li, C.; Xiong, F.; Jeong, J.-O.; Wang, T.; Latman, M.; Unberath, M. Reasoning Segmentation for Images and Videos: A Survey. arXiv 2025, arXiv:2505.18816. [Google Scholar]
- Rossi, E.B.; Lopez, E.; Comminiello, D. Tumor-Aware Counterfactual Explanations (TACE). arXiv 2024, arXiv:2409.13045. [Google Scholar]
- Wan, S.; Li, S.; Chen, Z.; Tang, Y. An Ultrasonic-AI Hybrid Approach for Predicting Void Defects in Concrete-Filled Steel Tubes via Enhanced XGBoost with Bayesian Optimization; Elsevier: Amsterdam, The Netherlands, 2024; Available online: https://library.kab.ac.ug/Record/doaj-art-c6efce6ddbfb4b54bc12d35f14a818ca (accessed on 15 February 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey Works | Challenges | Evaluation | Applications | Qualitative Analysis | Evaluation Metrics | Future Directions |
|---|---|---|---|---|---|---|
| [1] Abhishek & Kamath (2022) | ✓ | ✓ | ||||
| [2] Gujjsa et al. (2024) | ✓ | ✓ | ||||
| [3] Kuznietsov et al. (2022) | ✓ | ✓ | ||||
| [4] Zhou et al. (2016) | ✓ | ✓ | ||||
| [5] Ribeiro et al. (2016) | ✓ | ✓ | ||||
| [6] Petsiuk et al. (2018) | ✓ | ✓ | ✓ | |||
| [7] Samek et al. (2017) | ✓ | |||||
| [8] Abadi & Berrada (2018) | ✓ | ✓ | ✓ | |||
| [9] Mendes & Rios (2023) | ✓ | ✓ | ||||
| [10] Alonso & Sánchez (2024) | ✓ | ✓ | ||||
| [11] Liu et al. (2024) | ✓ | ✓ | ||||
| Our Work | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Method | Deletion AUC (Lower Better) | Insertion AUC (Higher Better) | Pointing Game Accuracy (%) | FPS (Higher Better) | Medical IoU (Higher Better) | Source |
|---|---|---|---|---|---|---|
| Grad-CAM | 0.123 | 0.677 | 86.3 | 39.0 | 0.027 | Selvaraju [16] |
| RISE | 0.108 | 0.727 | 91.9 | 0.05 | 0.045 | Petsiuk [6,27] |
| SmoothGrad | 0.235 | 0.412 | 89.5 | 5.5 | 0.021 | Sulikov [23] |
| Transformer-based XAI | 0.150 | 0.690 | 88.2 | 25.0 | 0.099 | Zhang [12] |
| Method | Category | Strengths | Limitations | Best Suited For |
|---|---|---|---|---|
| [13,21] Grad-CAM | Attribution-based | Efficient and class-discriminative; widely adopted | Low resolution; requires gradients | Real-time classification tasks |
| [23] SmoothGrad | Attribution-based | Reduced noise with better visual clarity | Less faithful; needs multiple runs | Visualization for human users |
| [6] RISE | Perturbation-based | Model-agnostic and highly faithful | Extremely slow; stochastic saliency maps | Offline analysis in sensitive domains |
| [28,50,51] LIME | Perturbation-based | Easy to understand; black-box friendly | Segmentation-dependent; low scalability | Local explanations for individual samples |
| [14] ViT Attention | Transformer-based | Captures global context with interpretable weights | Diffuse attention; not always faithful | Medical and semantic reasoning tasks |
| [29,52] Attention Rollout | Transformer-based | Aggregates multi-layer attention; better coherence | Low localization precision; complex to implement | Long-range and multimodal systems |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Z.; Wu, Y.; Li, Y.; Cai, L.; Ihnaini, B. A Comprehensive Review of Explainable Artificial Intelligence (XAI) in Computer Vision. Sensors 2025, 25, 4166. https://doi.org/10.3390/s25134166
Cheng Z, Wu Y, Li Y, Cai L, Ihnaini B. A Comprehensive Review of Explainable Artificial Intelligence (XAI) in Computer Vision. Sensors. 2025; 25(13):4166. https://doi.org/10.3390/s25134166
Chicago/Turabian StyleCheng, Zhihan, Yue Wu, Yule Li, Lingfeng Cai, and Baha Ihnaini. 2025. "A Comprehensive Review of Explainable Artificial Intelligence (XAI) in Computer Vision" Sensors 25, no. 13: 4166. https://doi.org/10.3390/s25134166
APA StyleCheng, Z., Wu, Y., Li, Y., Cai, L., & Ihnaini, B. (2025). A Comprehensive Review of Explainable Artificial Intelligence (XAI) in Computer Vision. Sensors, 25(13), 4166. https://doi.org/10.3390/s25134166