1. Introduction
In recent years, deep learning and big data technologies, serving as pivotal components within the artificial intelligence domain, have propelled significant advancements in target recognition [
1,
2] through innovative architectural designs and algorithmic breakthroughs, thereby unlocking the potential for knowledge extraction from vast datasets. However, the strong dependence of the existing supervised learning paradigm on the scale and quality of labeled data severely restricts its application efficacy in scenarios with limited labeling resources. The main applications of radar target recognition technology include disaster monitoring, geological exploration, and camouflage target recognition. The primary recognition object is a non-cooperative target. However, several issues arise, including long data acquisition and processing cycles, unstable and imprecise feature extraction, and high annotation costs and the need for expert knowledge. These issues severely limit the application of big data in traditional deep learning methods. In this context, how to exploit the advantages of few-shot learning (FSL) [
3] has become an urgent need for radar target recognition applications. FSL has become a research frontier technology in radar target recognition due to its unique knowledge migration mechanism. By constructing a relocatable feature space and efficient meta-learning strategies, discriminative features with strong generalization ability can be extracted from a very small number of labeled samples, and fast adaptation to new classes of targets can be achieved.
At present, the majority of research in the domain of FSL for radar target recognition is oriented towards the utilization of features such as synthetic aperture radar (SAR) [
4,
5,
6,
7,
8] and high-resolution range profile (HRRP) [
9,
10,
11]. The investigation of models and features for resonance zone signals remains in the exploratory phase. While optical region features are advantageous in target characterization, the complex nature of feature extraction results in low computational efficiency and unstable features, which hinders its applicability in FSL scenarios. In light of the model’s necessity to extract features exhibiting enhanced differentiation and stability from limited samples, this paper proposes to utilize the natural resonance frequency feature of the resonance region as the core recognition feature. This feature is seen to reflect the intrinsic electromagnetic scattering characteristics of the target in the resonance region, thereby enabling the characterization of the target’s resonance scattering characteristics in a very low dimension. Furthermore, the intrinsic physical properties and scattering mechanism of this feature ensure a certain degree of invariance of the attitude and observation angle [
12], which is more compatible with the generalization demand for features in FSL. This theoretical framework provides a robust foundation for the study and its findings. A flowchart of a typical classification task in an FSL scenario according to the literature [
13] is presented in
Figure 1.
In recent years, the field of computer vision has witnessed considerable advancements in multimodal FSL [
14,
15,
16,
17]. However, the majority of extant studies are confined to the integration of features such as optical images, text, and other modalities, lacking a comprehensive fusion mechanism that encompasses the deep physical properties of the target. In the domain of radar target recognition, prevailing methodologies predominantly depend on single-modal features, which are inadequate in addressing the substantial variations in features within complex electromagnetic environments. Furthermore, it is challenging to establish rational cross-modal correlations. In order to further enhance the comprehensiveness of features in scenarios where sample sizes are limited, this study challenges the conventional single-modal feature learning paradigm. It proposes an innovative approach that integrates natural resonance frequencies with signal time-frequency characteristics in a multimodal manner. The proposed multi-mode fusion classification network based on residual neural network and bi-directional long short-term memory (Res-BiLSTM-MFCNet) to achieve cross-modal fusion of time-frequency image features and natural resonance frequency features in radar signals. The energy-guided attentional fusion framework is embedded, and the cross-modal equilibrium loss (CME loss) function is designed based on the composite of feature similarity metrics and classification loss. The objective is to facilitate radar target recognition under small sample conditions.
The primary research contributions and innovations of this paper can be outlined as follows:
In response to the shortcomings of traditional meta-learning techniques that emphasize model generalization at the expense of feature representation, a novel methodology is introduced. This approach incorporates the natural resonance frequency sequence, which delineates the scattering characteristics of the target resonance area, into the FSL framework. By capitalizing on the angular and attitude stability inherent in the natural resonance frequency, this method enables the fusion of multimodal features, thereby reducing the influence of extraction accuracy on the natural resonance frequency.
The Res-BiLSTM-MFCNet model is introduced, wherein the energy associated with each natural resonant frequency mode is incorporated into the features as a matrix of weight coefficients. This model facilitates the deep integration of multimodal features through a feature mapping process that encompasses encoding, fusion, and decoding, ultimately leading to the desired classification outcome.
The CME loss, which integrates a feature similarity measure with classification loss, is intended to enhance the discriminability of the feature space while enabling the model to acquire a more distinct feature representation.
The experimental findings demonstrate that, without a significant increase in inference time and computational complexity, the proposed method achieves a recognition accuracy of 95.36% under varying observation angles. This accuracy is 2.26% and 8.73% higher than that of traditional unimodal and concatenation fusion feature methods, respectively. Additionally, the ablation experiment further validates the effectiveness of each innovative module and confirms the feasibility and practical value of the proposed method.
2. Res-BiLSTM-MFCNet
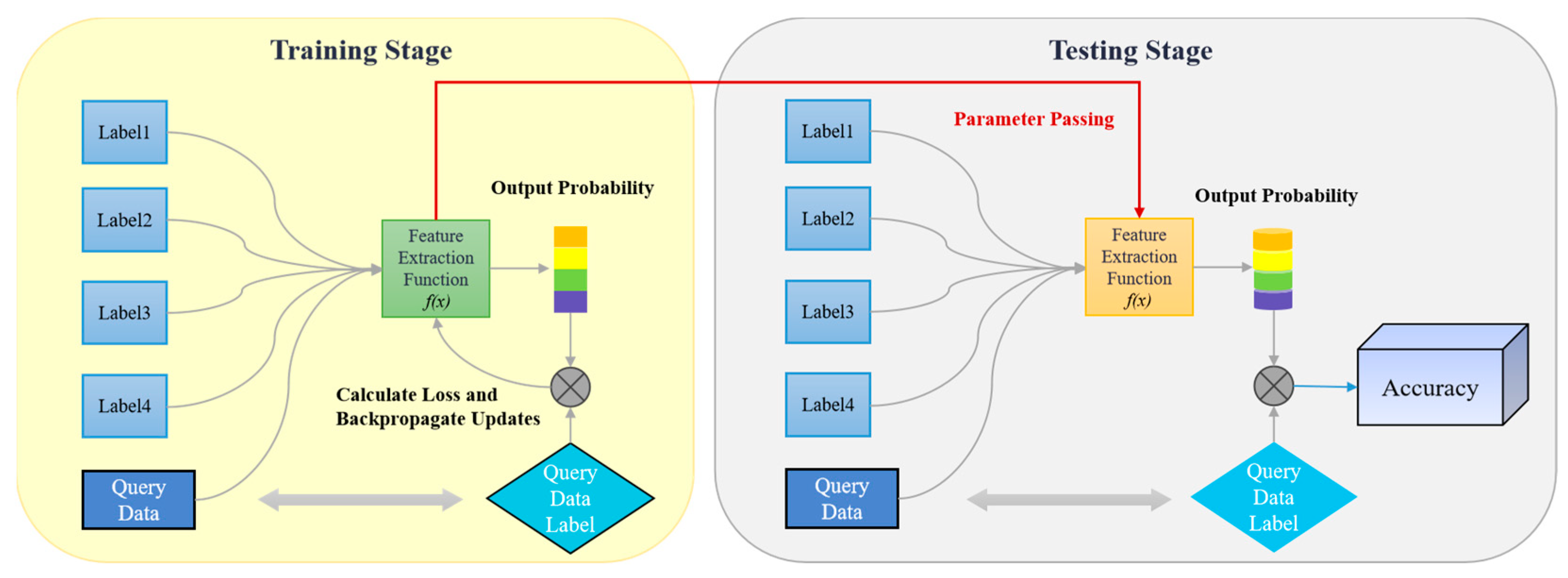
As illustrated in
Figure 2, the Res-BiLSTM-MFCNet model is utilized for recognizing few-shot target tasks
, leveraging both training and test samples
,
from a known category dataset
. The model is primarily composed of three core phases: multimodal feature characterization, cross-modal feature fusion and FSL classification.
In the multimodal feature characterization stage, cross-modal cooperative coding processing is developed based on time-frequency image features and natural resonant frequency sequence features. The essence of this process lies in the realization of multidimensional decoupling and reconstruction of the target’s scattering characteristics through the optimization of various feature spaces. The feature extraction framework equips the model with the ability to represent multimodal features effectively. For the time-frequency image features, ResNet-18 is employed to construct the spatial energy distribution extraction module, where energy aggregation features in the time-frequency domain are extracted layer by layer using a multilayered convolutional kernel approach. For the natural resonance frequency sequence features, the oscillatory variation patterns of resonance poles over time and the angular stabilization characteristics are captured using a BiLSTM network. The scattering characteristics of the target are described jointly from the different dimensions of signal energy distribution and resonance oscillation changes, resulting in a joint feature representation with enhanced discriminative properties.
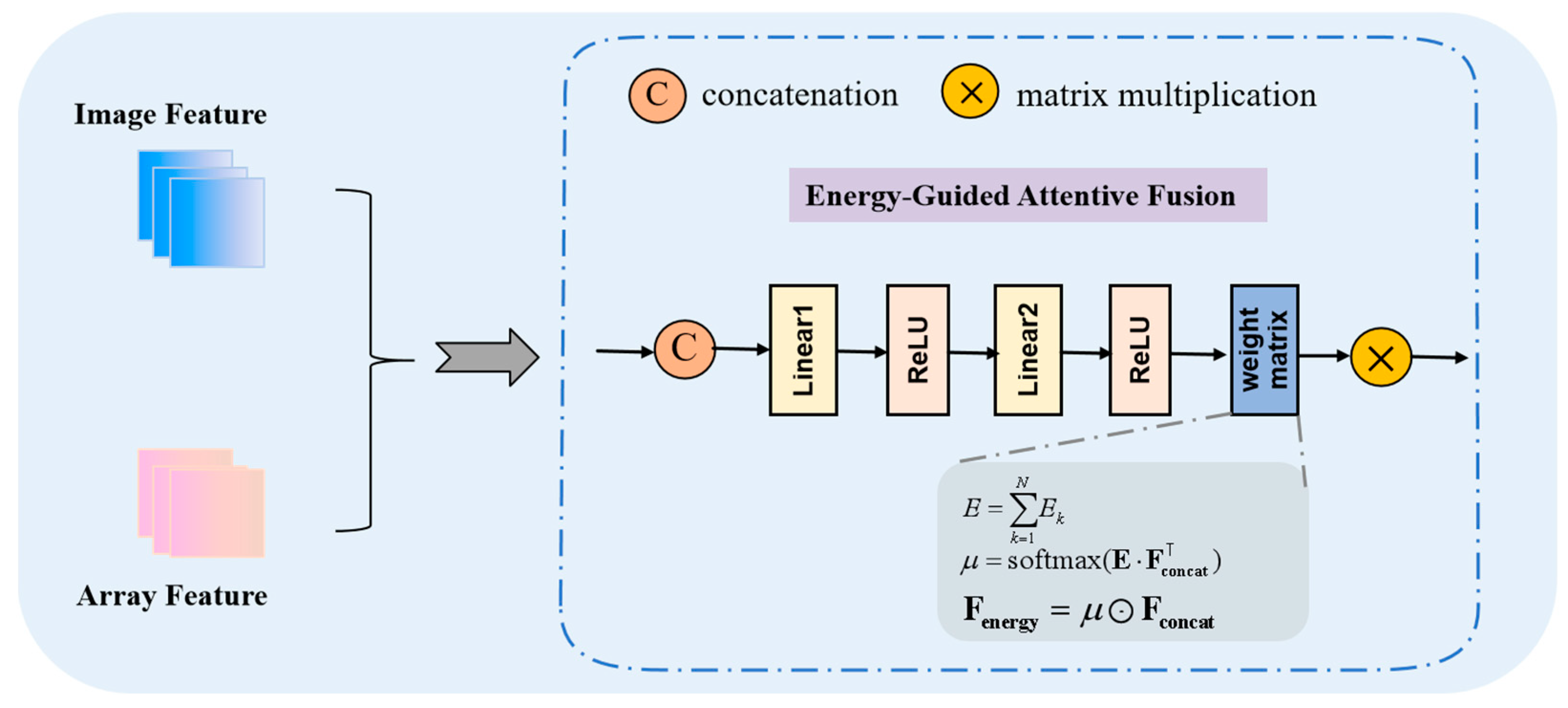
In the cross-modal feature fusion stage, the energy-guided attentive fusion (EGAF) framework is proposed to provide a more comprehensive description of the physical properties of the signal. The model’s ability to characterize the physical nature of the signal is enhanced by the introduction of an energy weight matrix during the projection of the fused features. This matrix intuitively reflects the relative importance of various natural resonant frequency modes within the signal, thereby facilitating the model’s ability to capture and learn the signal’s key features. To address the local feature sensitivity of non-visual signals, the model utilizes a multi-level feature fusion capability to enhance feature sensitivity. This is accomplished by incorporating guidance from the scattering mechanism, which strengthens the feature response in critical frequency bands through the allocation of energy weights. Consequently, this approach improves feature discriminability.
In the FSL classification stage, training sample pairs are constructed from the support set and query set. A weighted combination of triplet loss, dynamic time warping (DTW), and cross-entropy loss is utilized as the CME loss. The triplet loss and DTW serve as similarity measures for image features and sequence features, respectively, enhancing the discriminative properties of the features. Meanwhile, the cross-entropy loss optimizes the model’s classification performance. The DTW loss improves the stability of the natural resonance frequency through elastic temporal alignment, providing a modal complement to the spatial discriminative constraints imposed by the triplet loss. The weighting coefficients are designed to prevent a loss function and to concentrate the optimization on the classification task. Due to the suboptimal extraction quality of the natural resonant frequency features, the image features are assigned a weight that is twice that of the natural resonant frequency features. The components of the loss function correspond to time-domain matching, spatial separability, and classification inference in signal processing, respectively. This design ensures both the model’s ability to distinguish between inter-class samples and its classification accuracy. A 5-way 1-shot few-shot classification sampling strategy, which is a more common approach, is employed to estimate the correlation of inter-sample features for classification purposes, thereby facilitating the completion of the target recognition task.
2.1. Multimodal Characterization Module
The multimodal feature characterization module primarily comprises a time-frequency image encoder and a natural resonance frequency sequence feature encoder. The time-frequency image encoder constructs a time-frequency capability distribution parsing module based on ResNet-18 [
18]. Its set of convolution kernels extracts the time-frequency features
of the signal layer by layer. We establish the characteristic expression formula as follows:
is the time-frequency image generated by the CWD time-frequency transform and is the network parameter.
BiLSTM [
19] temporal encoder is designed for natural resonance frequencies to capture the contextual dependencies of feature sequences
through forward and backward hidden states
and
, specifically for natural resonance frequencies. We establish the characteristic expression formula as follows:
is the natural resonance frequency sequence and is the length of the sequence.
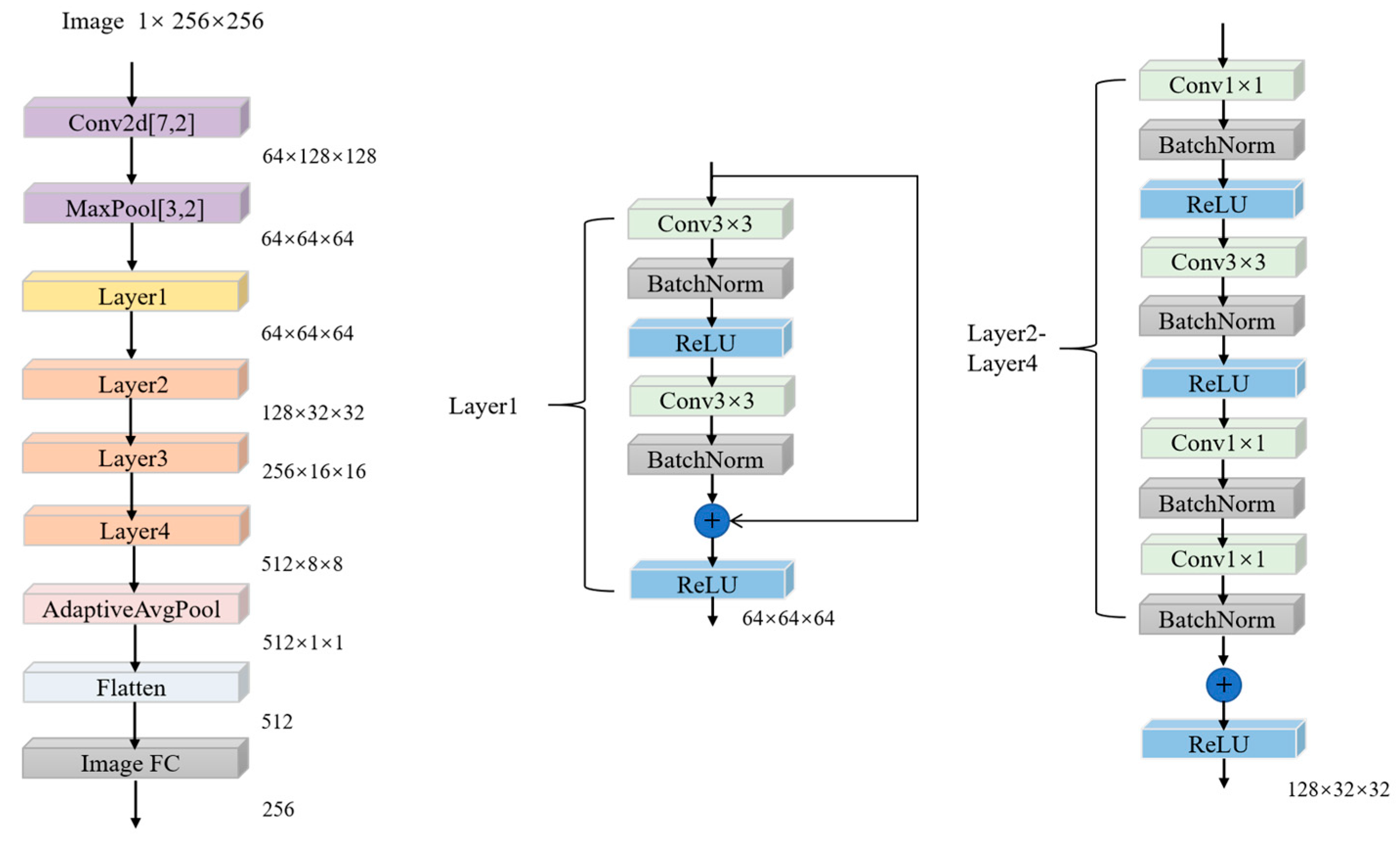
Input single-channel time-frequency grayscale image , and its processing flow is as follows:
The initial convolutional layer utilizes a large-scale receptive field convolutional kernel to extract features related to low-frequency energy distribution. The configuration of this kernel is as follows: kernel size = 7 × 7, stride = 2, padding = 3. Consequently, an output feature map is generated. Following this, a normalization and activation process is initiated, maintaining the full dimensionality. The residual network layer group is responsible for feature abstraction through a four-level residual structure. Layer 1 consists of two standard residual blocks, where the convolution operation is denoted by
.
denotes the convolution operation on the input features
,
stands for batch normalization,
is rectified linear unit function and
is skip connection.
stands for output feature and the output dimension is 64 × 64 × 64. The remaining three layers consist of two bottleneck residual blocks with downsampling. Each block follows a sequence of 1 × 1 downsampling, a 3 × 3 convolution, and another 1 × 1 downsampling. The residual blocks are adjusted to match the dimensions using a stride of 2, resulting in output dimensions of 128 × 32 × 32, 256 × 16 × 16, and 512 × 8 × 8. Finally, global mean pooling and fully connected layers are employed for feature compression and dimensionality reduction, yielding image features with 256 dimensions. The structure of the image encoder is illustrated in
Figure 3, which is followed by a pooling layer with a kernel size of 3 × 3, a stride of 2, and padding of 1, resulting in the final output.
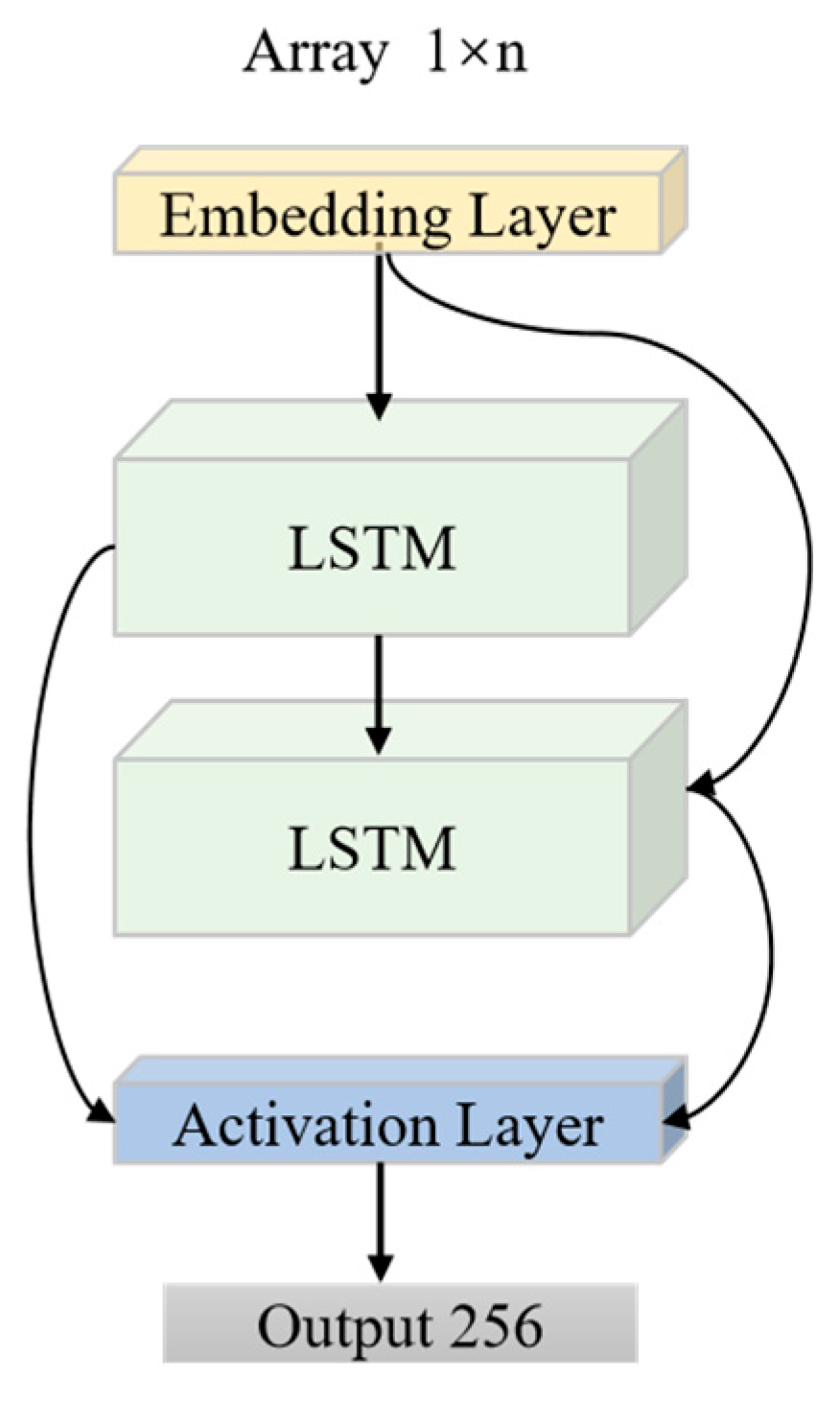
Input the natural resonant frequency imaginary part sequence , the processing flow is as follows:
The time-series embedding layer performs a linear projection with an output dimension of 64, while each hidden cell of the two-layer BiLSTM has 128 dimensions. The embedding layer maps the scalar sequence to a higher-dimensional space, thereby enhancing its nonlinear characterization. The BiLSTM network has the capacity to represent both the forward resonance build-up and the backward resonance decay processes through forward and backward propagation, respectively. According to [
19], the forward propagation formula is:
is the hidden state at the current time step and denotes the output of the forward LSTM at time step . is the hidden state of the previous time step and serves as one of the inputs for the current time step. The variable is the input feature at time step , while is the set of parameters for the forward LSTM.
The backward propagation formula [
19] is:
represents the output of the backward LSTM at time step , is the hidden state of the later time step and serves as one of the inputs to the current time step. The variable is the set of parameters of the backward LSTM, which has a similar structure to the forward LSTM, but the parameter values may be different.
Finally, the features are spliced to output a 256-dimensional feature vector. The image encoder structure is shown in
Figure 4.
In this paper, two networks are selected for feature extraction and fusion. To address the local feature sensitivity of non-visual signals, the model’s multi-level feature fusion capability is utilized. Additionally, the guidance of the scattering mechanism is incorporated to enhance the feature response of key bands through dynamic weight allocation, thereby improving the discriminability of the features.
2.2. Cross-Modal Feature Fusion Module
In the cross-modal feature fusion stage, this paper introduces the EGAF framework, which consists of several key steps in its core processing flow. First, the feature fusion module splices and further processes the features from the two modalities. An energy weight matrix is then introduced to generate more discriminative fused features. The objective of the encoding-fusion-decoding process is to map the fused feature representation to the final classification result. A flowchart illustrating the feature fusion process is presented in
Figure 5.
The specific steps are as follows:
Take the training sample
as an example. Let its time-frequency image features and natural resonance frequency features be
and
, respectively. The feature fusion module combines the features from both modes to construct the multimodal features of the sample. We can express this relationship with the following formula:
where
denotes the time-frequency analysis with a local feature dimension of 256, where the time-frequency image features
of the samples are extracted by the image encoder and the natural resonance frequency features
are extracted by the data encoder. The aforementioned fusion features
are utilized to generate more discriminative multimodal fusion features through a two-layer fully connected network. The feature vectors are mapped to the category space via a fully connected layer, resulting in the output of initial score vectors for each category.
It is important to note that the time-frequency image serves as a visualization of the energy distribution of a signal across both time and frequency dimensions. Consequently, the two parameters of the natural resonance frequency—representing the oscillatory decay rate and the oscillation frequency of the signal, respectively—do not directly reflect changes in energy. To more comprehensively describe the physical properties of the signal and enhance the model’s ability to focus on learning the fused features, we incorporate energy information into the multimodal fusion features.
According to the theory of the singularity expansion method [
20], the late-time response in the resonant region of a radar target can be expressed as the sum of the decaying negative exponents of the natural resonant frequencies. For the
th natural resonant frequency, its mode is
,
is the residue,
is the natural resonant frequency, and
is defined as the attenuation factor. Based on the method used to calculate signal energy
, its energy can be expressed as follows:
Substituting the expression of
into the above equation, we can get:
Since the stability of the system requires that , the convergence of the above integrals, the energy can be further simplified to . This result demonstrates that the energy of each natural resonant frequency mode is proportional to the square of its amplitude and inversely proportional to the absolute value of the decay rate. Consequently, we can utilize the energy of each mode as a weight matrix for subsequent signal analysis and feature extraction.
In the text, we can deduce that the total energy of the signal can be obtained by summing the energies of all modes:
The energy weight matrix
is introduced to characterize the energy distribution of the features, and the energy-guided modal saliency weights
are generated through the differentiable attention mechanism, the formula is constructed in the paper:
This weight dynamically modulates the fusion feature constructed in the paper:
The energy of each natural resonant frequency mode is represented as a matrix of weight coefficients. Modes with larger amplitudes and slower decay rates contribute more energy to the signal and, therefore, are assigned higher weights in the weight matrix. This approach intuitively reflects the relative importance of the various natural resonant frequency modes within the signal and facilitates the subsequent model’s ability to capture and learn the key features of the signal.
2.3. N-Way K-Shot Learning
In light of the rapid advancements in deep learning technology, the research paradigm for FSL has gradually transitioned towards the N-way K-shot learning problem, with multi-categorization as the target task. The N-way K-shot learning problem posits the existence of N new categories within the target task, each comprising K annotated samples (typically, K is a small value). The model is tasked with learning from these limited annotated samples and recognizing the N new categories. Specifically, an FSL task with K samples across N categories consists of a support set and a query set . The support set contains labeled samples used for model training, while the query set comprises unlabeled samples utilized for model testing. It is essential to note that both the support set and the query set exist within the same category space, denoted by . signifying the N new categories introduced in the context of the FSL task. This task setting illustrates the expanded scope of FSL, significantly enhancing the model’s ability to generalize under conditions of limited data.
The introduction of the N-class K-sample learning framework facilitates a more systematic evaluation of a model’s classification performance with a limited number of samples. This framework establishes clear objectives and evaluation criteria for the design and optimization of FSL algorithms. By utilizing a reduced number of samples, it can more accurately simulate the learning of new categories in real-world scenarios. Furthermore, incorporating multiple categories is essential for ensuring the diversity and complexity of the task, thereby preventing the model from failing to learn all categories of data during the training process.
2.4. Metric Space Optimization and Loss Function Design
The triplet loss function [
21], initially proposed by the Google research team, establishes explicit category decision boundaries within its learned feature space by enforcing the constraint that the feature distance from an anchor to a positive sample is less than the distance from the anchor to a negative sample, within a predefined margin. In the context of small sample learning, samples from the support and query sets are utilized to construct triplets (Anchor, Positive, Negative). The Anchor denotes the feature representation of a sample, while the Positive represents a positive sample, i.e., the feature representation of another sample belonging to the same category as the Anchor. Conversely, the Negative represents a negative sample, i.e., the feature representation of a sample belonging to a different category than the Anchor. For each training batch, a set of triplets
is selected, and a neural network is employed to learn the embedding function and compute the feature embedding vectors. The gradient is backpropagated, and the parameters are updated to minimize the loss.
The computational method of using Euclidean distance to measure triplet loss evaluates the similarity of features through high-order operations. This approach primarily focuses on interpolating the probability distribution functions of the corresponding points while neglecting the geometric properties of the two types of feature distributions. In contrast, the Wasserstein distance metric [
22] offers a more sophisticated approach by taking into account the geometric properties between probability distributions. This allows for a more accurate measurement of the distance between two feature distributions while preserving their underlying characteristics. As a result, the Wasserstein distance is chosen as the similarity metric for time-frequency image features.
When the characteristic probability distributions of
are, respectively,
, the distance metric [
22] is calculated as:
In this context,
is the joint distribution of
,
is the set of all possible joint distributions, and
are the variables randomly selected from
, respectively. The Wasserstein distance has the capacity to measure and optimize the difference between the two types of feature distributions. In cases where the two feature distributions exhibit a significant difference or incomplete overlap, effective gradient information can be computed, positively impacting the stability of the model optimization process. Consequently, the triplet loss function [
21] is computed as follows:
is the interval margin, which specifies the minimum required separation for the distance between positive and negative sample pairs. indicates that the loss is non-negative and is 0 when the model satisfies the desired condition, otherwise a loss greater than 0 indicates a penalty to the model.
The DTW [
23] methodology is utilized to calculate the similarity between two sequences. Given that the natural resonance frequency of the target can vary with changes in sequence length, DTW is employed as a loss function. This function has the capacity to regularize and align the two sequences, thereby reducing the impact of delays and fluctuations. Furthermore, it can be utilized to enhance the discriminative properties of the features. The sequence feature similarity measure
,
is defined as the sequence feature of the
th sample, and
is the set of indices of samples that are similar to the sample. The minimum path distance between similar samples is then calculated as [
23]:
The cross-entropy loss function [
24] is a widely used metric in deep learning classification tasks, designed to assess the accuracy of the model outputs by quantifying the difference between the predicted distribution and the true distribution. According to [
24], when the number of categories is
, the cross-entropy is calculated based on the true label
and the model’s predicted probabilities
:
The sequence feature similarity metric, image feature similarity metric, and categorical cross-entropy loss are integrated into the CME loss. The similarity metric can be viewed as an implicit regularization term, designed to prevent the model from overfitting to unimodal features. By constraining the similarity within the multimodal feature space, the similarity metric aids the model in learning a shared representation across modalities, thereby enhancing the complementarity of intermodal information. Simultaneously, the cross-entropy loss serves as a mechanism to ensure the model’s discriminative performance in classification tasks, thus preventing any deviation from the intended objective. The equation is derived in the paper:
where
and
are the weight coefficients, currently set to 1:2:7, in order to achieve a synergistic optimization of classification loss and feature regularization. Initially, the focus is on modeling feature distribution, where the divisibility of the time-frequency image features is superior to that of the natural resonance frequency features. The coefficients
are set to 0.1 and 0.2, respectively. The subsequent enhancement of the classification boundary optimization is based on the classification task being the primary objective, with a coefficient
set to 0.7. Here, the term
represents the sequence feature similarity loss, while
denotes the image feature similarity loss. The loss function
is defined as the weighted sum of the classification loss and the triplet loss, and this composite approach optimizes both classification performance and feature representation. The schematic illustrating the metric space optimization and loss function design is presented in
Figure 6.
4. Results and Discussion
4.1. Effect of Different Features on Recognition Results
In order to investigate the effects of various features on recognition results, unimodal time-frequency, unimodal sequence, and concatenated fusion features are utilized as inputs for the comparative recognition experiments. By maintaining constant parameters across 100 experiments, the mean outcomes following 100 iterations are calculated.
As demonstrated in
Table 2, the fusion features employed in this study exhibit optimal performance in terms of recognition accuracy and stability. In scenarios requiring high accuracy, these features remain the preferred choice, despite the increased training and inference time associated with their more complex model structure. When unimodal time-frequency features are utilized as input, the performance is more balanced regarding accuracy and inference time, with a reduction in inference time of 17.3%. The fusion feature achieves a recognition accuracy of 95.36%, while the unimodal time-frequency feature attains 93.10% recognition accuracy, with the former exceeding the latter by 2.26%.
Despite the advantages of the unimodal sequence feature model, such as its compact data size and rapid computation, its performance in few-shot learning (FSL) remains suboptimal. This is primarily due to the lack of a significant clustering effect in the feature distribution of natural resonance frequency data, combined with minimal inter-class variability, which impedes the model’s ability to learn the underlying physical properties. As a result, the unimodal sequence feature achieves only 64.18% recognition accuracy. In contrast, the performance of the concatenation fusion feature model is consistent across all metrics. The direct tensor concatenation of time-frequency and sequence data is straightforward and intuitive; however, time-frequency data and structured sequence data exist in different feature spaces and convey distinct semantic information. Consequently, it is challenging for the model to capture the correlation between the two modalities. The direct concatenation of features lacks clear physical meaning, resulting in a lower recognition accuracy rate. In comparison to the 86.63% recognition rate achieved with concatenation features, the recognition rate of the fusion features we employed increased by 8.73%. A comparison of the parametric metrics indicates that the features utilized in this study demonstrate only a marginal improvement over the use of unimodal time-frequency features combined with concatenation fusion features, while the FLOPs remain constant. This observation supports the conclusion that the model’s resource consumption and computational complexity experience negligible increases.
As demonstrated in
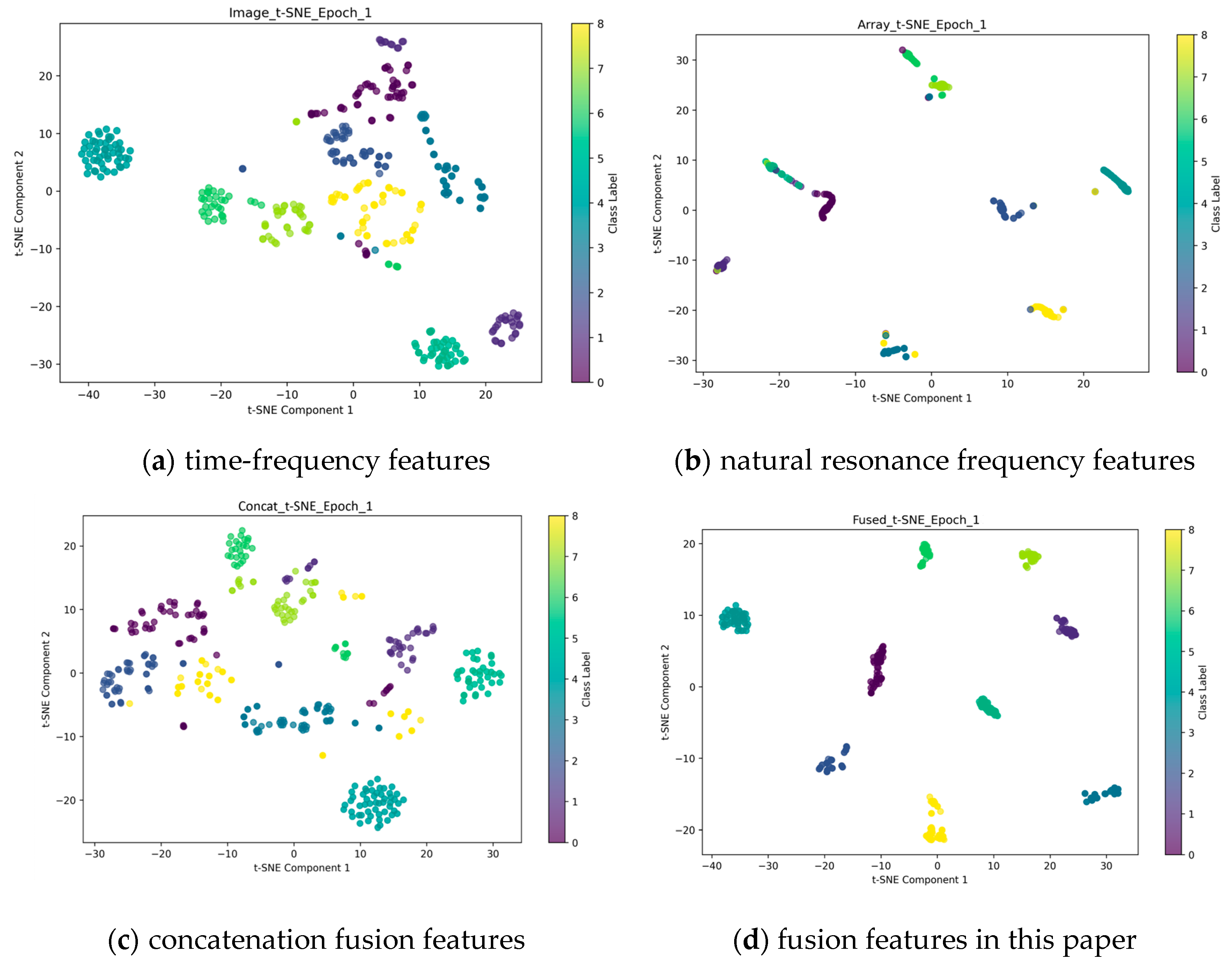
Table 3, the results of the quantitative analysis reveal significant disparities in the spatial characteristics of the various features, as indicated by the intra-class average distance and inter-class separation metrics. The intra-class average distance for unimodal time-frequency features is 5.72, while the inter-class separation metric reaches 21.81. This suggests a moderate degree of intra-class aggregation but limited inter-class differentiation capability. In contrast, the unimodal sequence features exhibit excessive compression, with an intra-class average distance of only 0.10 and an inter-class separation metric as low as 0.88. This indicates a deficiency in effective separability within the original space. The simple concatenation fusion feature maintains an intra-class distance of 5.04, but the inter-class separation metrics plummet to 13.36, revealing that the direct concatenation of different modal features may trigger semantic conflicts and does not have good consistency. In contrast, the multimodal fusion method proposed in this paper enhances the inter-class separation to 25.83 while maintaining the intra-class distance metrics steady. This leads to an improvement in separability scores of 18.37% and 70.19% compared to unimodal time-frequency features and concatenation fusion features, respectively. This phenomenon can be attributed to the energy-guided cross-modal fusion mechanism, which establishes the optimal mapping between the support set and the query set through Wasserstein distance constraint. Furthermore, the fused features of this paper’s method enhance the boundary identifiability while maintaining the intra-class compactness. The visualization distribution of different features after t-SNE, as presented in
Figure 9, also substantiates the aforementioned conclusion. In comparison with the other three features, the fused features in this paper exhibit enhanced divisibility and aggregation.
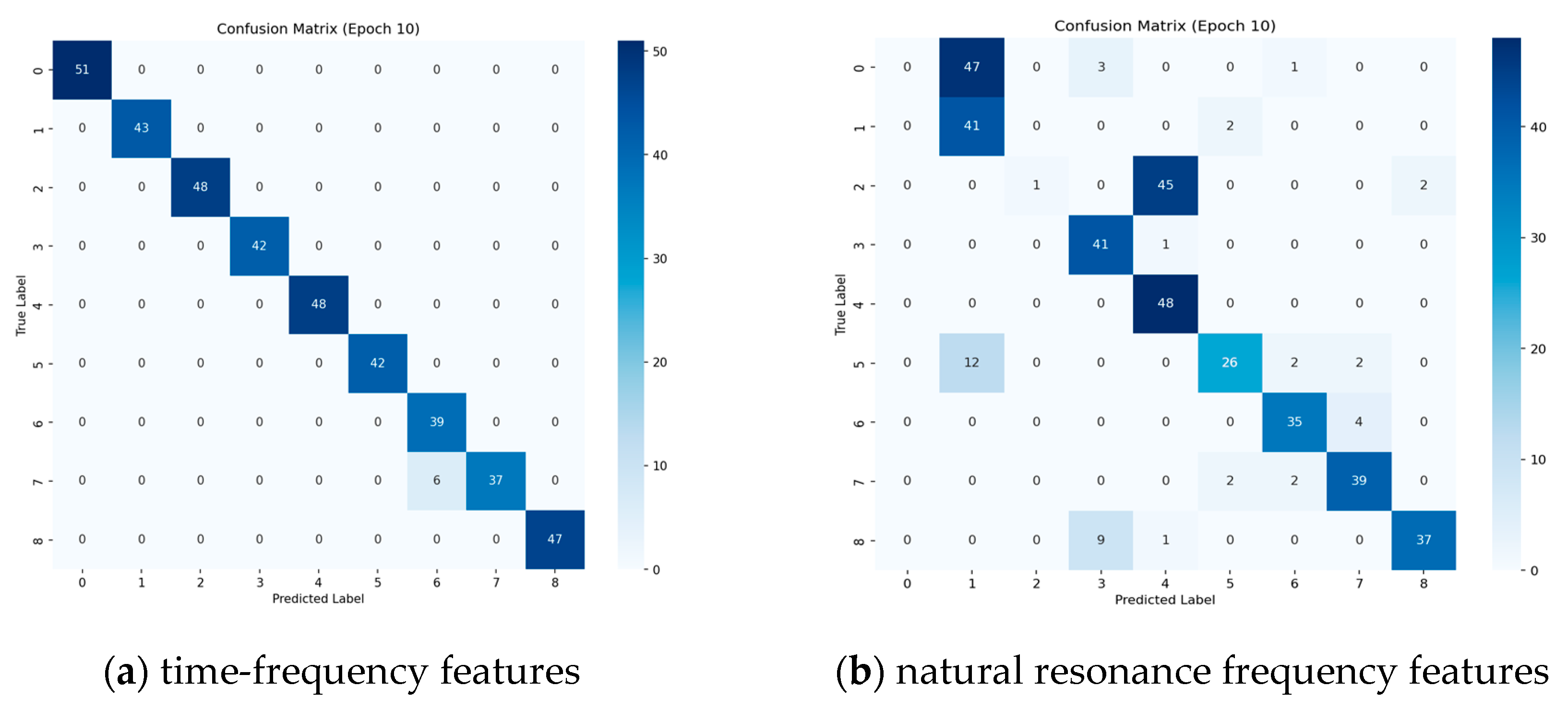
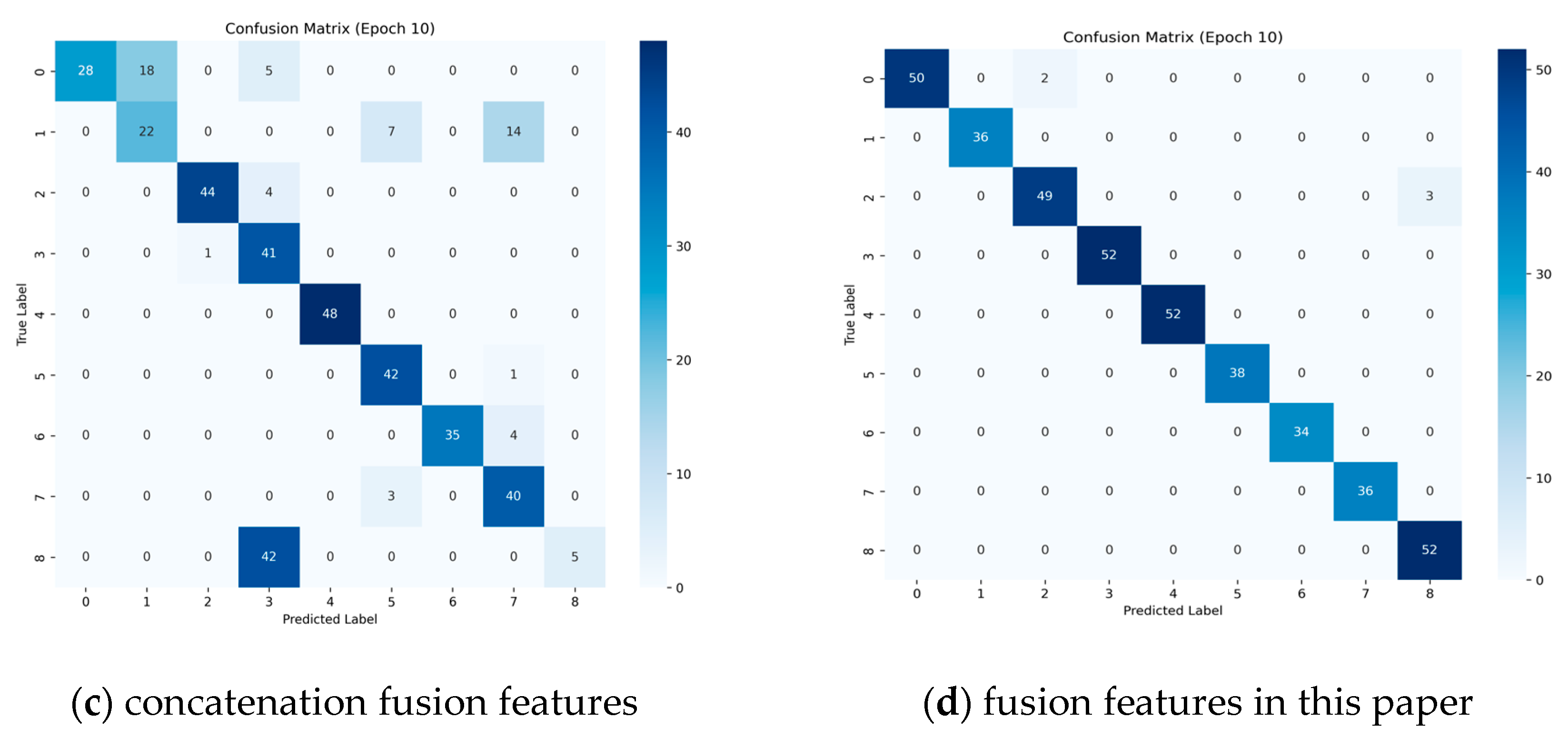
As demonstrated in
Figure 10, an investigation into the differential performance of different features in different target recognition tasks is presented in the confusion matrix analysis (Epoch10). The unimodal time-frequency features exhibit interclass confusion for geometrically similar targets, such as rod 1 and rod 2, with a recognition accuracy of 86.05% for rod 2, attributable to the high similarity of the distribution of scattering centers in the time-frequency image. The fusion feature proposed in this paper demonstrates superior inter-class discrimination; however, it still exhibits a misclassification rate of 5.77% for targets exhibiting similar lateral scattering characteristics, such as combination and cubic panels. The physical mechanism underlying this phenomenon can be attributed to the presence of certain overlapping distributions in the natural resonant frequency attenuation factor for these targets. The utilization of sequence and concatenation features has been demonstrated to be ineffective, as both of these approaches appear to lack the capacity to differentiate between rod targets of varying dimensions. Further analysis indicates that a single natural resonant frequency sequence feature is inadequate in corresponding to variations in target size, and it is challenging to differentiate between similarly shaped rod targets. Additionally, projected similarity at characteristic observation angles triggers confusion in the frequency-domain features. For instance, similarly shaped targets projected perpendicularly to the radar line-of-sight direction, such as cones and spheres, are also not accurately recognized. The direct concatenation of features disregards the semantic gap between modalities, and the confusion matrix presents diffuse misclassification and generalized confusion for multi-class targets. This indicates that simple feature superposition does not possess satisfactory feature discriminative properties.
4.2. Effect of Different Sequence Lengths on Recognition Results
In order to investigate the effect of different natural resonance frequency sequence lengths on the model performance, based on the energy weighting coefficient matrix assignment strategy in
Section 2.2, the natural resonance frequencies with larger weighting coefficients are selected as the input sequence data. The approach we take is not to deal with the sequence length, directly input the network. It is acknowledged that natural resonance sequences of varying lengths are associated with different targets; therefore, the natural resonance frequencies with lengths of 3, 5, and 11 are selected in accordance with the ranking relationship of decreasing weight coefficients to form new sequence data. The identification results are then compared in the experiments. Maintaining constant all other parameters in 100 experiments, the mean of the results following 100 iterations is calculated.
The comparative experimental results in
Table 4 reveal the intrinsic correlation between the energy-dominated natural resonance feature selection mechanism and data missing robustness. In addressing the issue of excluding spurious data during the extraction of natural resonance frequencies, this study incorporates the disparity in energy distribution between authentic resonance modes and spurious interference. Authentic natural resonance frequencies are characterized by higher energy and more stable distribution, while spurious data exhibits low energy. It is important to note that without altering the sequence length, this corresponds to complete resonant mode coverage. However, the presence of spurious data can potentially influence the outcomes. When the sequence length is 11, the natural resonance frequency corresponding to certain angles is already absent, yet the recognition accuracy reaches 96.90%, indicating that the high-dimensional sequence can adequately capture the intrinsic resonance characteristics of the target. Furthermore, the feature selection method based on the decreasing energy order effectively strengthens the contribution of the dominant modes, which in turn improves the regularity of the feature distribution. However, when the sequence length is reduced to 5 and 3, the recognition effect is diminished by the influence of missing data, and the recognition accuracy drops to 92.38% and 93.26%, respectively. This may be due to the fact that the sequence is too short with missing modes, which cannot completely characterize the multi-resonance effect, resulting in the increase in intra-class feature variance. However, the model maintains more than 90% recognition accuracy even under severe data-missing conditions, thereby verifying the effectiveness of the multimodal complementary mechanism. The time-frequency image features can be discriminatively compensated by time-domain energy focusing, while the BiLSTM sequence encoder effectively suppresses spurious modal interference. The experiment demonstrates the method’s feasibility in scenarios where natural resonant frequencies are incomplete, offering a valuable reference point for target recognition in practical applications.
4.3. Validation of the Effectiveness of the Loss Function
In order to explore the effect of loss function on model performance, different loss functions are used for comparison experiments. Cross-entropy + triplet loss, cross-entropy loss, triplet loss, and contrast loss are utilized as loss functions, respectively. One hundred repetitions of experiments under the same conditions are conducted to calculate the average recognition accuracy and stability scores.
As demonstrated in
Table 5, a comparison of disparate loss function models reveals that the CME loss function in this paper attains the maximum recognition accuracy. Cross-entropy loss is a frequently employed loss function in classification tasks, which is capable of effectively distinguishing between different classes and exhibits stable classification performance. However, it solely optimizes inter-class decision boundaries during training and is deficient in its capacity to characterize multimodal feature distributions. Despite the fact that the triplet loss is both small in variance and fast, its optimization objective is not fully consistent with the classification task. As a separate loss function, it lacks explicit classification supervision, which causes the model to fall into a local optimum. The low variance reflects the risk of possible over-compression of the feature space. When the cross-entropy loss is combined with the triplet group loss to construct the hybrid loss, although the stability is improved by the feature space constraint, the accuracy is not significantly improved due to the conflicting gradient directions of the two different losses. The variance of the contrast loss is 0, and the recognition effect is very poor, probably because its optimization objective does not match the classification task and the model fails to learn effectively. The experimental results demonstrate that CME lOSS exhibits enhanced robustness and attains synergistic optimization of classification loss and feature regularization through the weight adjustment mechanism. With a weight factor set to 3:7, this strategy prioritizes feature distribution modeling during the initial stage and strengthens the optimization of classification boundaries during the subsequent stage. This phased optimization approach maintains high efficiency while adapting to the multimodal feature distribution.
4.4. Validation of the Effectiveness of EGAF Framework
In order to investigate the impact of the energy bootstrapping strategy described in
Section 2.2 of this paper on the model effectiveness, comparison experiments are conducted using unprocessed fusion features and competence-boosted fusion features, respectively. A total of 100 repetitions of the experiments are conducted under identical conditions, and the mean recognition accuracy and stability scores are calculated.
As demonstrated in
Table 6, the EGAF framework employed in this paper offers distinct advantages in enhancing recognition accuracy and stability. The recognition accuracy is notably higher when the EGAF framework is implemented compared to its absence, though its performance is less stable. The incorporation of the energy matrix within the model facilitates the concentration on the energy aggregation region within the time-frequency domain, which corresponds to the primary modes of the target resonance. This, in turn, ensures that the deep fusion features are spatially consistent with the physical scattering mechanism. The region of energy concentration can be mapped to the critical scattering center of the target, which is consistent with the physical perception convention of the model. The time-frequency image is indicative of the spatial energy distribution, and the natural resonance frequency is reflective of the transient oscillation characteristics. It can be posited that the two features reflect the steady state and transient characteristics of the target scattering, respectively, to a certain extent. The energy-guided strategy has been shown to constrain the feature search space, thereby enabling the model to converge more rapidly to achieve optimal classification results. This is advantageous in scenarios involving small sample sizes; however, it should be noted that this approach may also result in a concomitant increase in instability during the convergence process.
4.5. Validity Verification of Training Strategies
To investigate the impact of loss functions on model performance, comparative experiments were conducted using different training strategies. The optimizer selected for this study is SGD with Momentum, while Adam and RMSProp optimization methods were employed to perform 100 repeated experiments under identical conditions. The average recognition accuracy and stability scores were then calculated.
It can be seen from
Table 7 that the optimizer combination of SGD + Momentum adopted in this paper performs best in recognition accuracy, possibly because the introduction of Momentum helps the model to build an inertial system with gradient updates and converge to a better local optimal solution faster. The Adam optimizer uses a fixed learning rate, so the accumulation of deviation at the first-order distance will lead to the late update step size being too small, which is the best performance in training stability, but the fast convergence will cost the model capacity, and the recognition accuracy is slightly worse than SGD + Momentum. RMSProp uses the exponential moving average of the squared gradient to adjust the learning rate, which is not stable enough. It may be that the long-term gradient memory and the instantaneous gradient in multi-modal features fluctuate and conflict, and the gradient magnitude difference between feature channels will be amplified, so the recognition accuracy is lower than that of other optimizers.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}