Abstract
Anomaly detection in multivariate time series is a critical task across a range of real-world domains, such as industrial automation and the internet of things. These environments are generally monitored by various types of sensors that produce complex, high-dimensional time-series data with intricate cross-sensor dependencies. While existing methods often utilize sequence modeling or graph neural networks to capture global sensor relationships, they typically treat all sensors uniformly—potentially overlooking the benefit of grouping sensors with similar temporal patterns. To this end, we propose a novel framework called Multi-task Learning Anomaly Detection (MLAD), which leverages clustering techniques to group sensors based on their temporal characteristics, and employs a multi-task learning paradigm to jointly capture both shared patterns across all sensors and specialized patterns within each cluster. MLAD consists of four key modules: (1) sensor clustering based on sensors’ time series, (2) representation learning with a cluster-constrained graph neural network, (3) multi-task forecasting with shared and cluster-specific learning layers, and (4) anomaly scoring. Extensive experiments on three public datasets demonstrate that MLAD achieves superior detection performance over state-of-the-art baselines. Ablation studies further validate the effectiveness of the modules of our MLAD. This study highlights the value of incorporating sensor heterogeneity into model design, which contributes to more accurate and robust anomaly detection in sensor-based monitoring systems.
1. Introduction
From the internet of things to industrial automation, multivariate time-series data power decision-making by capturing dynamic system behavior [1,2]. Anomaly detection is a fundamental task in these data-driven systems, aiming to identify patterns or observations that deviate from expected behavior. It is critical across various domains, including detecting power grid failures [2], ensuring autonomous vehicle safety [3], identifying anomalies in railway infrastructure [4], and monitoring water treatment systems [5].
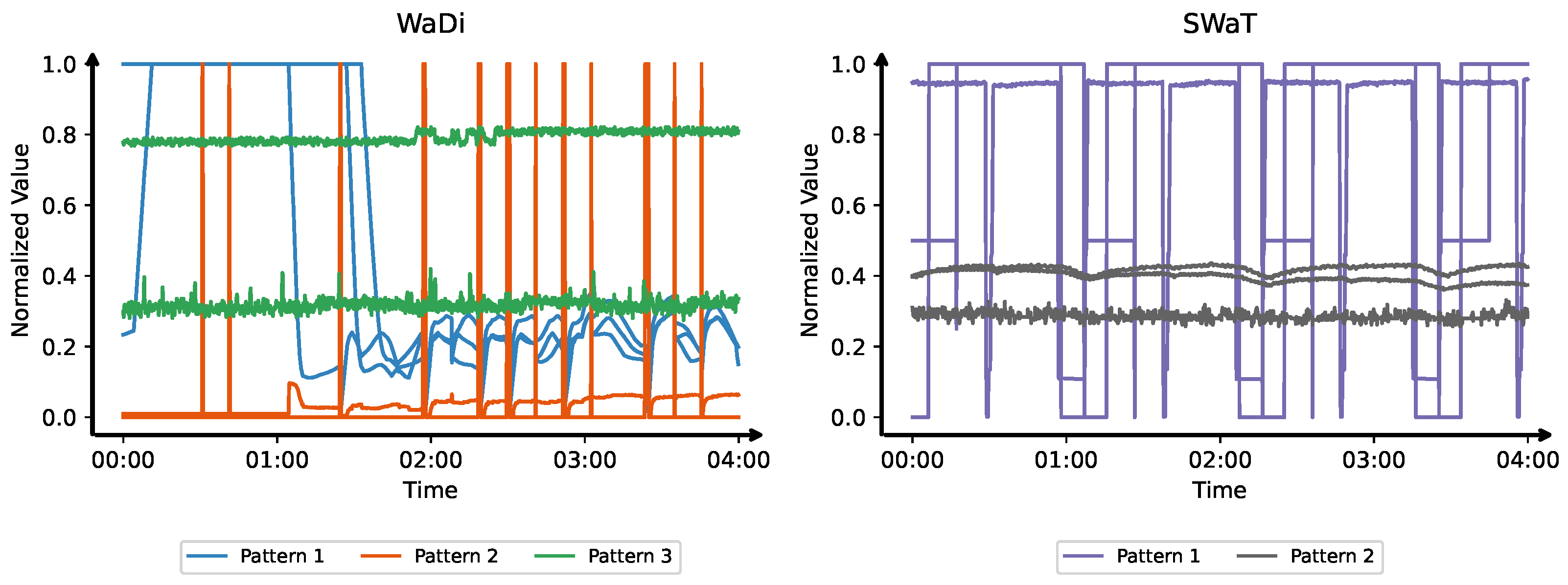
In real-world industrial deployments, anomaly detection systems typically rely on large-scale, heterogeneous sensor networks to continuously monitor various subsystems and operational parameters [6]. These sensors exhibit a wide diversity of temporal behaviors due to differences in their physical characteristics and functional roles. However, despite this diversity, sensors within the same functional class often produce similar temporal patterns. As shown in Figure 1, sensors in Water Distribution (WaDi) [7] and Secure Water Treatment (SWaT) [8] datasets display recurring class-specific signatures, such as gradually rising and falling values, sharp and frequent switches between high and low states, and nearly constant signals with minimal variation. These characteristic patterns among functionally or behaviorally similar sensors suggest the potential benefit of modeling sensor subsets based on temporal similarity.
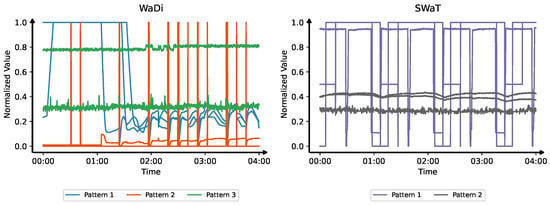
Figure 1.
Temporal pattern diversity across sensor subsets and consistency within each subset in two datasets. (Left): Water Distribution (WaDi) [7]; (Right): Secure Water Treatment (SWaT) [8]. In WaDi, Pattern 1 (blue) includes sensors with smooth, gradual trends; Pattern 2 (orange) shows binary transitions; Pattern 3 (green) exhibits steady-state signals. In SWaT, Pattern 1 (purple) features on/off toggling, while Pattern 2 (gray) contains stable analog measurements.
Despite recent advances for multivariate time-series anomaly detection [1,9], most existing methods adopt a uniform modeling strategy that treats all sensors equally. For example, recent Graph Neural Network (GNN)-based models [10,11] achieve state-of-the-art performance. These approaches typically construct a global adjacency matrix to capture correlations among all sensors and apply spatial–temporal modeling over the entire graph. However, this design overlooks the fact that many sensors consistently exhibit similar temporal behaviors within a specific subset of sensors. As a result, the models tend to learn only global patterns shared across the entire sensor system, while neglecting the specific temporal patterns embedded within a particular family of sensors. This can lead to reduced sensitivity to localized anomalies that are only apparent within certain classes of sensors.
To address these limitations, we propose a Multitask Learning-based Anomally Detection framework, termed MLAD. We build MLAD with four key components: (1) sensors clustering—we perform unsupervised clustering to classify sensors into subsets based on similarities in their time series; (2) time-series representation learning with a cluster-constrained GNN—a graph is constructed in which edges are restricted to connections within each sensor cluster, which allows the GNN to focus on learning relationships specific to individual clusters, rather than modeling the entire sensor network uniformly; (3) multi-task learning—the learned representations from the GNN are then passed into a multi-task learning module that comprises both shared layers for capturing global patterns across all sensors, and task-specific (i.e., cluster-specific) layers that learn local temporal dynamics unique to each sensor cluster; and (4) anomaly detection—anomalies are finally detected by a Principal Component Analysis (PCA)-based reconstruction errors over forecasting errors. Extensive experiments on three real-world datasets demonstrate that MLAD consistently outperforms strong baselines. Ablation studies confirm the effectiveness of both the cluster-constrained graph neural networks and multi-task forecasting module.
Our main contributions are summarized as follows:
- We employ an unsupervised clustering strategy to group sensors into clusters and introduce a cluster-constrained GNN that enables the model to focus on sensor relationships within each cluster.
- We introduce a multi-task forecasting architecture to multivariate time-series anomaly detection that jointly learns global behaviors shared across all sensors and specialized patterns unique to each cluster of sensors, which finally benefits the performance of the downstream anomaly detection task.
- Extensive experiments on three public datasets show that MLAD outperforms state-of-the-art baselines, and ablation studies confirm the contribution of each module to its strong detection performance.
The remainder of this paper is organized as follows. Section 2 reviews related works on multivariate time-series anomaly detection. Section 3 formally defines the problem of multivariate time-series anomaly detection. Section 4 details our proposed framework, including sensor clustering, cluster-constrained GNN, multi-task learning, and anomaly detection. Section 5 presents experimental settings and results, followed by discussions. Finally, Section 6 concludes the paper and outlines future research directions.
2. Related Work
2.1. Time-Series Anomaly Detection
Anomaly detection in multivariate time series has been a longstanding research challenge in multiple domains such as industrial automation and internet of things. Traditional statistical methods, including autoregressive integrated moving average [12], PCA [13], and support vector machines [14], have been widely applied to this field. Despite their interpretability and low computational cost, these traditional models have several key limitations [15]. First, they struggle with handling non-linear and high-dimensional dependencies. Second, statistical models generally rely on strong assumptions, such as stationarity and independence, which do not hold in many real-world situations.
With the limitations of traditional statistical methods, deep learning has emerged as a powerful alternative for analyzing and detecting anomalies in multivariate time-series data. Specifically, deep learning models offer three key advantages over classical approaches: automatic feature extraction, non-linearity modeling, and adaptability to large-scale data [9]. Furthermore, deep learning models do not rely on strong stationarity assumptions, making them more suitable for real-world, dynamic datasets where time-series patterns evolve over time.
Among the widely used deep learning architectures for time-series anomaly detection, Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Variational Autoencoders (VAEs) each offer distinct modeling capabilities. RNNs, particularly long short-term memory networks, are well-suited for capturing long-range temporal dependencies in sequential data [16]. CNNs are designed to extract local and hierarchical patterns by applying convolutional filters over the input. When applied to time series, CNNs can effectively capture short-term dependencies and spatial correlations between variables, making them a powerful alternative or complement to RNNs in capturing complex dynamics [17]. Meanwhile, VAEs offer a generative approach that learns a probabilistic latent representation of the input data and detecting anomalies by reconstructing normal patterns and quantifying deviations through reconstruction errors [18].
Despite notable success, deep learning approaches still face key challenges. Traditional RNN-, CNN-, and VAE-based methods do not explicitly model relationships between different time-series variables, instead encoding them into global hidden states [11]. This lack of modeling relationship between variables can lead to suboptimal performance, particularly in complex, high-dimensional multivariate time-series settings. As a result, GNNs have recently gained attention as a promising approach for anomaly detection by explicitly representing dependencies between time-series variables.
2.2. Graph Neural Networks
Graph Neural Networks offer a solution to explicitly modeling dependencies among time-series variables as graph structures [19]. The key idea behind GNNs is the message-passing mechanism, where each node (representing a time-series variable or sensor) iteratively updates its representation by aggregating information from its neighboring nodes. This enables the model to learn meaningful spatial relationships between different variables while simultaneously capturing temporal dynamics.
As a result, GNN-based anomaly detection methods have shown promising results in detecting complex anomalies that involve interactions between multiple variables. Deng and Hooi [10] introduced a structure-learning-based GNN with attention mechanisms to explicitly model inter-sensor relationships, enhancing both detection accuracy and explainability. Ning et al. [20] expanded on this by proposing MST-GNN, which integrates multi-scale temporal features with GNNs to capture latent correlations, significantly improving anomaly detection performance. Zheng et al. [11] further advanced the field with CST-GL, a correlation-aware spatial–temporal graph learning model that leverages graph convolution to encode rich spatial information from complex pairwise dependencies between variables.
Despite their success, GNN-based anomaly detection models face a critical challenge: balancing the need to capture global dependencies across the sensor network while preserving the distinct, localized behaviors of functionally similar sensors. Most existing approaches construct a global adjacency matrix across all sensors, which may obscure meaningful dynamics specific to individual sensor groups. This design often favors general patterns at the expense of sensors’ cluster-specific characteristics, limiting the model’s ability to detect anomalies.
To address this limitation, we innovatively proposed a promising direction is to incorporate sensor cluster information through unsupervised clustering and cluster-constrained graph design. By first identifying clusters among sensors based on temporal similarity, models can construct structured priors that more accurately reflect subsystem boundaries. These clusters can then guide both the construction of the sensor graph and the design of forecasting modules, enabling more fine-grained modeling.
2.3. Multi-Task Learning
Multi-Task Learning (MTL) is an increasingly prominent paradigm in machine learning wherein a single model is trained to simultaneously solve multiple related tasks [21]. By leveraging shared representations across tasks, MTL promotes inductive transfer, which can lead to improved generalization, faster convergence during training, and enhanced robustness, particularly in data-scarce scenarios [22]. This shared structure enables the model to learn commonalities and distinctions across tasks, often outperforming models trained in isolation on each task.
MTL has demonstrated broad applicability across various domains. In natural language processing, it has been employed for joint tasks such as part-of-speech tagging and named entity recognition [23]. In computer vision, MTL enables models to perform complex tasks like egocentric vision in data-scarce scenarios [24]. In recommender systems, MTL has been employed to jointly model interactions from multiple domains, such as user–item and user–social relationships, thereby improving performance in cold-start settings [25]. A common architectural approach in MTL involves a shared feature extraction module—often based on CNNs or transformer encoders—followed by task-specific output heads that tailor predictions to individual objectives [23]. This design balances parameter sharing with task-specific specialization, capturing both general and unique aspects of each task.
In this work, we build upon the multi-task learning paradigm by proposing a novel time-series forecasting module, specifically designed for heterogeneous, multivariate time-series data. Our approach define forecasting tasks based on sensor clusters—each representing a coherent temporal pattern. The forecasting module incorporates cluster-specific layers to adapt its output processing to the nuances of each sensor cluster, while retaining shared layers across all sensors to encourage joint optimization. This design can foster localized specialization of each sensor clusters without forfeiting the benefits of shared representations captured by the cluster-constrained CNN model.
3. Problem Statement
The problem addressed in this paper is multivariate time-series anomaly detection, where each time step comprises simultaneous observations of N correlated variables. Such data commonly arise in sensor networks like industrial monitoring, finance, and cloud systems. At any timestamp t, the observations form a column vector , where N denotes the number of monitored variables.
The training dataset—assumed to consist solely of normal behavior—is defined as follows:
where is the number of time steps in the training sequence.
Similarly, the test data is represented as follows:
Given a historical window of length , we aim to learn a function that assigns a real-valued anomaly score at each timestamp t:
where denotes the learnable model parameters.
An anomaly is flagged if exceeds a threshold :
where indicates whether the system is anomalous at time t.
Training is performed exclusively on normal data. The learned model is expected to assign higher scores to test points that deviate from these normal patterns.
4. Methodology
4.1. Overview of the Framework
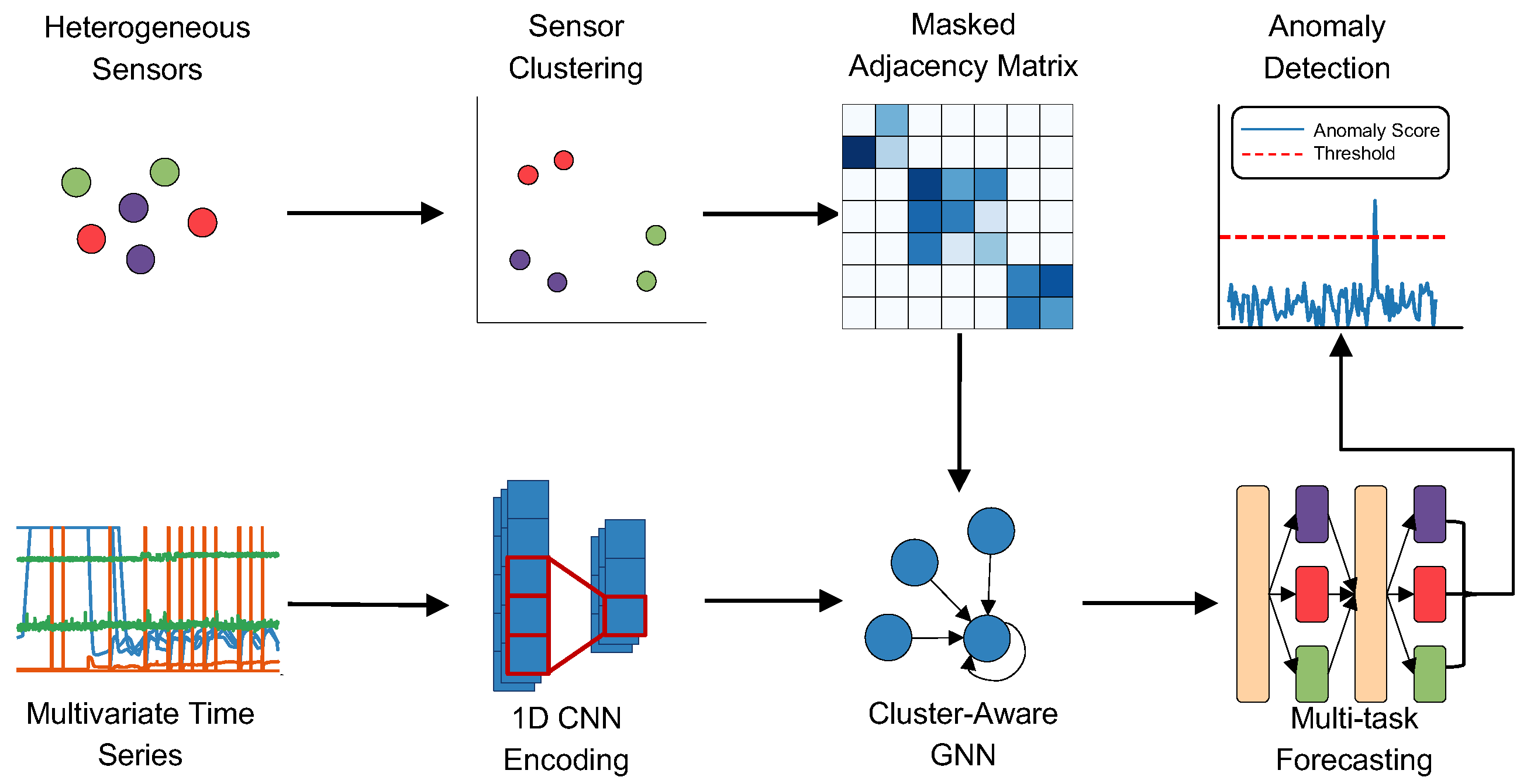
To address the challenges of detecting anomalies in complex multivariate time-series data, we propose MLAD, a framework that integrates cluster-aware GNN and multi-task learning. The framework, shown in Figure 2, consists of four components: (1) sensor clustering, (2) GNN learning with cluster-constrained graph construction, (3) multi-task forecasting, and (4) a PCA-based anomaly detection module.
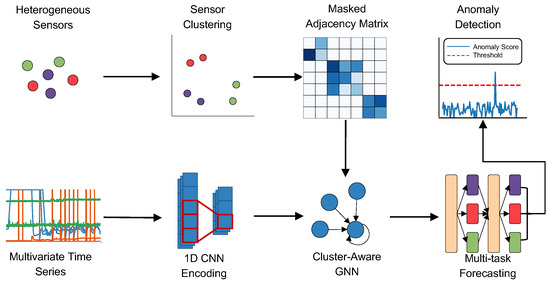
Figure 2.
Overview of the MLAD framework. The pipeline begins with heterogeneous sensor inputs, which are then clustered into behaviorally similar sensor groups. Before training the GNN, a masked adjacency matrix is created to reflect connections within each sensor cluster. The input time series is encoded via 1D CNNs, then processed through a cluster-constrained GNN to model dependencies. Finally, a multi-task forecasting module predicts future values and anomalies are detected by evaluating the forecasting error through a PCA-based anomaly scoring mechanism.
For a given multivariate time series, we begin by generating low-dimensional embeddings for each sensor’s time-series sequence using Uniform Manifold Approximation and Projection (UMAP) [26]. These embeddings capture the temporal characteristics of each sensor and are subsequently clustered using Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [27]. The resulting clusters reveal groups of sensors with similar dynamic behavior and serve as structural priors for both graph construction and multi-task learning modules.
Building on the identified sensor clusters, we process the multivariate time series through a GNN module designed with cluster-aware graph construction. First, a 1D convolutional encoder extracts temporal features from each sensor’s sequence. These features are then passed to the GNN, where each sensor is represented as a node in a graph and edge weights between nodes are learned in a data-driven manner. To ensure robustness and meaningful connectivity, we apply a cluster-aware masking strategy that restricts edges to only form between nodes within the same cluster, reflecting the assumption that sensors in the same group exhibit stronger correlations.
To capture both common and cluster-specific temporal behaviors, we employ a multi-task forecasting head after the GNN module. This component consists of a set of shared layers that capture common temporal dynamics, along with task-specific layers tailored to each sensor cluster. By separating the forecasting tasks according to cluster membership, the model is able to learn both shared and specialized patterns across sensor clusters. The resulting predictions are then passed to a PCA-based anomaly detection module to compute anomaly scores.
The remainder of this section provides a detailed explanation of each component within the MLAD framework. Section 4.2 outlines the embedding and clustering process used to identify sensor groups. Section 4.3 describes the construction of the cluster-constrained graph and the graph neural network architecture. Section 4.4 details the multi-task forecasting module designed to handle both shared and cluster-specific patterns. Finally, Section 4.5 explains the PCA-based anomaly scoring mechanism used to identify deviations from expected behavior.
4.2. Sensor Clustering
To enhance structural awareness and improve the precision of anomaly detection, we begin with a clustering operation that identifies latent groupings of sensors based on their temporal dynamics. By uncovering these intrinsic relationships, the framework is better equipped to learn both general patterns shared across the system and specific dynamics unique to individual sensor clusters.
Given a multivariate training dataset , where each row represents the time series for sensor n, we treat each as a high-dimensional sequence. Due to the long temporal sequences involved, we first project these time series into a lower-dimensional latent space to make them comparable. For this purpose, we employ UMAP [26], a non-linear dimensionality reduction technique that preserves both local and global data structure. The embedding of sensor n given by UMAP is
where is the embedding dimension.
Specifically, UMAP builds a fuzzy topological graph in the original space by computing the edge probability between sensors i and j as follows:
where denotes the distance between the series, and , are local parameters controlling neighbor sensitivity. Based on this topological graph, the time series of sensors are then mapped into a low-dimensional embedding space, while preserving the relative distances among sensors. For further theoretical details, readers are referred to the original work [26].
Once embedded, we apply DBSCAN [27] on the set of embeddings . DBSCAN clusters nearby points based on density connectivity and marks isolated points as noise. Formally, it assigns each sensor a discrete cluster label:
where C is the total number of clusters discovered.
These cluster assignments serve as a structural prior for the remaining components of our model. They constrain the connectivity of the learned sensor graph (Section 4.3) and determine the organization of multi-task prediction heads (Section 4.4).
4.3. GNN Learning with Cluster-Constrained Graph Construction
With the sensor clusters identified in the previous stage, we proceed to construct a graph of sensors that leverages these structural priors by restricting connectivity to occur only within the same clusters. Specifically, we enforce that edges only form among sensors within the same clusters. This design enhances robustness by limiting information propagation to semantically related sensors.
As shown in Figure 2, multivariate time series is first passed through a one-dimensional convolutional encoder, inspired by the gated temporal convolutional structure proposed in [28]. The encoder is defined as
where is the encoded features, is a linearly projected version of the raw input, and denote the convolution and gating functions, and ⊙ indicates element-wise multiplication.
Following the 1D convolutional encoding, the extracted representations are passed into a GNN module. To incorporate structural priors derived from sensor clustering, we construct a cluster-aware graph where each node corresponds to a sensor.
Specifically, we begin with initializing two sets of learnable node embeddings, . These embeddings are then projected independently via trainable matrices followed by non-linear activation:
where are learnable parameters, and controls the activation sharpness.
To capture directional influence between sensors, we adopt an asymmetric similarity function inspired by [11] to compute a directed adjacency matrix :
This formulation yields a non-negative adjacency matrix where indicates the directed influence from sensor j to sensor i.
Based on the raw adjacency matrix, a key innovation in our framework is the introduction of a masking mechanism to incorporate structural priors from the sensor clustering stage (Section 4.2). We hypothesize that functional correlations are more meaningful within clusters of similarly behaving sensors than across heterogeneous groups. To operationalize this, we define a binary mask :
where denotes the cluster assignment of sensor i. The masked graph is computed as
where ⊙ denotes element-wise multiplication.
This cluster-constrained design enforces connectivity among sensors in the same cluster and discourages spurious inter-cluster edges, promoting better alignment with real-world modular structures. Unlike prior methods that treat all sensor pairs uniformly, our cluster-aware masking introduces an explicit structural inductive bias.
To further reduce redundancy and improve efficiency, we sparsify the masked graph by retaining only the top-k strongest connections for each node. The resulting is a sparse, directed, and cluster-aware adjacency matrix.
With the masked adjacency matrix established, we proceed to perform directional message passing using a gated graph convolutional architecture. Let denote the output of the CNN encoder, which serves as the input to the GNN.
Similar to [28], the GNN is composed of K propagation steps, and at each depth k, node representations are updated using a gated residual mechanism:
where is the row-normalized version of and is a learnable gating parameter.
After K iterations, the final output of the GNN is computed as a weighted sum across all propogation steps:
where each is a layer-specific learnable weight matrix.
To enhance the interaction between temporal and spatial features, our architecture stacks multiple layers of CNN encoders and cluster-constrained GNN modules. The CNN captures each sensor’s temporal patterns, while the GNN models dependencies among sensors. Residual connections are applied on each layer to facilitate more stable training by improving gradient flow. The final latent feature map is then passed to the multi-task learning module, which generates predictions used for anomaly detection.
4.4. Multi-Task Forecasting
To model both shared and cluster-specific patterns, we introduce a multi-task forecasting module—one of the central innovations of our framework. Unlike previous works [10,11] that apply a uniform predictor across all sensors, our approach decomposes forecasting into a set of parallel tasks—each corresponding to a distinct sensor cluster—thereby explicitly modeling cluster-wise heterogeneity.
The GNN output is first processed through a series of shared transformation layers designed to capture global features across all sensors. These shared features are then routed into cluster-specific branches, where each branch learns to specialize in the unique dynamics of its corresponding cluster of sensors. This design enables the model to combine generalization with localized specialization.
Formally, let be the input tensor to the forecasting module, and let represent the cluster assignments. We first compute a shared latent representation:
where and are learnable parameters. This operation projects the input into a shared latent space that encodes global forecasting cues.
Next, for each cluster , we apply a cluster-specific transformation to the relevant slice of the shared representation:
where denotes the rows of corresponding to sensors assigned to cluster c, and are learnable parameters for that cluster. This structure allows each branch to adapt to the patterns specific to its sensor cluster.
To maintain consistency with the original sensor order, the outputs of the cluster-specific branches are reassembled using a function:
which maps the cluster-wise predictions back to their respective sensor positions, producing a final forecasting vector aligned with the input.
When necessary, the forecasting head applies multiple layers of shared and cluster-specific transformations in succession, enabling a deeper interaction between global and localized representations. The final refined predictions are forwarded to the anomaly detection module, where discrepancies between predicted and observed values are assessed to determine potential anomalies.
4.5. Anomaly Detection
Based on the forecasting results, we detect anomalies in the multivariate time series by analyzing PCA-reconstruction errors. Specifically, we compute the pointwise prediction error between the predicted and actual values, normalize these errors to account for variable-specific scale differences, and then apply PCA to reduce noise. An anomaly score is then derived by measuring the discrepancy between the original and PCA-reconstructed normalized error vectors.
Let and denote the ground truth and predicted vectors at timestamp t, respectively. The absolute error is defined as
To account for variations in scale and variability across variables, each error is normalized using the median and interquartile range (IQR) computed over a sliding window of length :
Inspired by [11], we apply PCA to reduce noise in the normalized error signals. PCA is fitted on the set of validation errors . From this, we compute the mean and covariance, followed by eigendecomposition:
where contains orthogonal eigenvectors and is a diagonal matrix of eigenvalues.
For a test-time vector , we subtract the validation mean and project it onto the PCA space defined by . Retaining the top-K components, we reconstruct the denoised vector:
The anomaly score is calculated as the distance between the original and reconstructed normalized error vectors:
For thresholding, we classify a timestamp t as anomalous if its score exceeds the maximum anomaly score observed during the training period:
This non-parametric approach removes the need for manual threshold tuning and is suitable for large-scale, heterogeneous time-series data. It assumes that training data reflects normal system behavior, enabling reliable anomaly detection through reconstruction residuals.
5. Experiments
In this section, we evaluate the effectiveness and generalization of our proposed MLAD framework for multivariate time-series anomaly detection. The experiments are designed to address the following research questions: (1) Can MLAD achieve superior anomaly detection performance across diverse and complex datasets? (2) How do the proposed cluster-constrained GNN learning and multi-task forecasting modules contribute to performance gains? To this end, we conduct comprehensive experiments on three public benchmark datasets, compare against strong baselines, and perform detailed ablation analyses.
5.1. Experimental Settings
(1) Datasets: We evaluate the effectiveness of our proposed MLAD framework on three widely-used benchmark datasets: SWaT, WaDi, and SMD.
- SWaT [8] is collected from a scaled-down version of a real-world industrial water treatment testbed. The dataset comprises 11 days of multivariate sensor readings, divided into 7 days for training (normal data only) and 4 days for testing. During testing, anomalies are labeled based on a series of simulated attack scenarios. To ensure consistency with previous studies [10,11], we follow a common preprocessing approach: the first 21,600 samples are removed, and the data is downsampled by taking the median value over 10 s intervals.
- WaDi [7] is an extended version of the SWaT dataset, representing a more complex and larger-scale water distribution system. The training set includes 14 days of normal operation, while the test set contains 2 days of labeled attack data. As with SWaT, we remove the first 21,600 samples and apply 10-s median downsampling.
- SMD [29] (Server Machine Dataset) consists of time-series readings from 28 servers, each with 38 variables. However, prior studies have shown that 16 of these machines exhibit significant concept drift, which can confound anomaly detection performance [30]. Following [11], we focus only on the 12 machines with stable distributions and report averaged results across these selected subsets.
(2) Evaluation Metrics: We assess the anomaly detection performance of MLAD and all baseline methods using two widely adopted metrics: Area Under the Receiver Operating Characteristic Curve (AUC-ROC) and Area Under the Precision–Recall Curve (AUC-PRC). AUC-ROC evaluates the model’s ability to distinguish between normal and anomalous samples across different thresholds by computing the area under the ROC curve, which plots the true positive rate (TPR) against the false positive rate (FPR). AUC-PRC focuses more on the positive (anomalous) class, which is particularly important in imbalanced datasets. It is computed as the Area Under the Precision–Recall Curve. Both metrics are threshold-independent and offer complementary insights into detection quality.
(3) Baselines: We compare MLAD with a comprehensive set of baselines categorized into three groups. (1) Classical statistical methods: PCA and KMeans provide simple, interpretable baselines for anomaly detection. (2) Deep reconstruction models: AutoEncoder and USAD [31] are unsupervised models that learn to reconstruct normal patterns, detecting anomalies via reconstruction error. (3) Graph and temporal models: MTAD-GAT [32] and GDN [10] incorporate graph neural networks and attention mechanisms to model complex inter-variable dependencies. THOC [14] applies hierarchical temporal clustering for one-class classification. CST-GL [11], a recent state-of-the-art method, constructs a correlation-aware spatial–temporal graph to model both feature and temporal structure. These baselines reflect the current landscape of multivariate time-series anomaly detection and provide rigorous points of comparison.
(4) Implementation Details: We implemented MLAD using PyTorch 2.6.0 and conducted all experiments on a single NVIDIA RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA). Model hyperparameters were selected based on validation performance and alignment with prior studies. For sensor clustering, we set the UMAP embedding dimension to 5, and applied DBSCAN with an epsilon of 2 and a minimum samples threshold of 10 to identify sensor clusters. The temporal encoder consists of two convolutional layers, and the GNN module uses a 256-dimensional node embedding and two propagation layers to model interactions among sensors in the same clusters. The multi-task forecasting head includes two shared layers for global dynamics and two sets of cluster-specific layers, each with one fully connected layer per cluster. We optimized the model using the Adam optimizer with a learning rate of 0.0005 and a batch size of 64, and trained using a masked mean squared error loss that selectively penalizes errors on observed values. Following prior work [29,30], we set the validation ratio to 0.1 for SWaT and WADI, and 0.3 for SMD. The sliding window sizes were set to for SWaT and WADI, and for SMD, consistent with previous studies [10,11]. The full model training for each dataset was completed within a few hours, while the computational cost for the UMAP and DBSCAN clustering was minimal, typically finishing within minutes. Overall, the approach remains computationally efficient and suitable for practical, moderate-scale deployments.
5.2. Overall Anomaly Detection Results
As shown in Table 1, MLAD achieves strong performance across all three benchmark datasets in both AUC-ROC and AUC-PRC, consistently outperforming state-of-the-art baselines. These results validate the effectiveness of our cluster-aware GNN and multi-task forecasting design in capturing both shared and cluster-specific temporal dynamics. In particular, MLAD’s improvements are most pronounced in AUC-ROC.

Table 1.
Average AUC performance (±standard deviation) of five experimental runs on three benchmark datasets. The best, second best, and third best results in each column are marked in bold, with * and † respectively.
On the SWaT dataset, MLAD achieves an AUC-ROC of 0.8583 and an AUC-PRC of 0.7570. This slightly surpasses the previous top performer CST-GL (0.8520/0.7628) in AUC-ROC while remaining highly competitive in AUC-PRC. Compared to THOC, the second-best in AUC-ROC (0.8380) and AUC-PRC (0.7440), MLAD delivers notable gains. Even against MTAD-GAT—the third-best in AUC-PRC (0.7176)—our model demonstrates a consistent performance margin.
On the more complex WaDi dataset, MLAD achieves the highest AUC-ROC (0.8327), slightly edging out CST-GL (0.8283). While its AUC-PRC (0.5267) falls just below CST-GL (0.5477), it still ranks among the top performers and shows a significant margin over third-place methods such as PCA and USAD.
For SMD, MLAD again ranks first with an AUC-ROC of 0.8703 and AUC-PRC of 0.5204. It edges out CST-GL (0.8604/0.5132) and MTAD-GAT (0.8576/0.5057), reaffirming its ability to generalize across heterogeneous sensor environments.
Overall, MLAD delivers consistently strong performance across varied domains, confirming its robustness and adaptability to both structured industrial systems and high-dimensional cloud environments.
5.3. Ablation Study
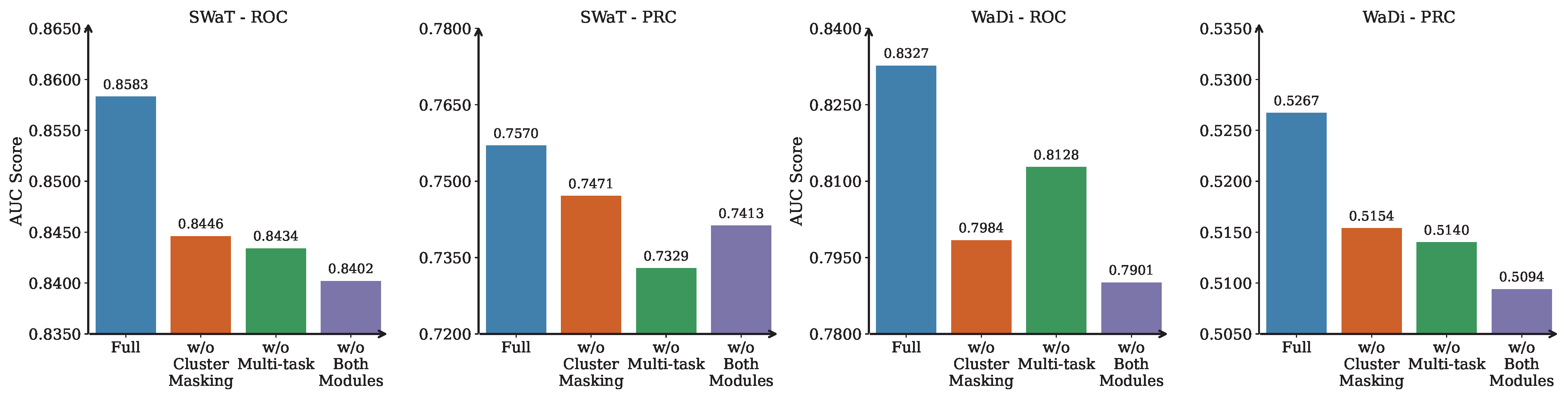
To assess the individual contributions of MLAD’s key architectural components, we conduct an ablation study by systematically removing the cluster masking mechanism, the multi-task forecasting module, and both simultaneously. The results are reported in Figure 3, which shows average AUC-ROC and AUC-PRC scores on SWaT and WADI across five independent runs. This evaluation allows us to quantify the importance of each module in isolation and to better understand how they interact to support robust anomaly detection under complex multivariate dynamics.
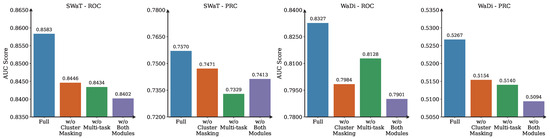
Figure 3.
Ablation study results on SWaT and WaDi datasets. Bars represent average AUC-ROC and AUC-PRC scores across 3 runs. Removing either the cluster masking or multi-tasking module leads to a performance drop, validating their contribution to the full MLAD framework.
(1) Contribution of Cluster Masking. The cluster masking mechanism is a core structural prior in MLAD, designed to restrict graph connectivity within coherent clusters of sensors. This masking encourages message passing only among sensors that share similar temporal dynamics, as determined through UMAP and DBSCAN clustering. By incorporating this inductive bias, the model avoids propagating signals between loosely correlated or unrelated variables. As shown in our experiments, removing this module leads to performance degradation on both datasets—dropping from 0.8583 to 0.8446 AUC-ROC and from 0.7570 to 0.7471 AUC-PRC on SWaT. This indicates that while the GNN can still learn inter-sensor relationships in a data-driven way, the lack of structured guidance weakens its precision, especially for rare anomalies.
The impact is even more substantial on the WaDi dataset, where structural complexity and sensor heterogeneity are higher. Here, the model without cluster masking achieves only 0.7984 AUC-ROC and 0.5154 AUC-PRC, down from 0.8327 and 0.5267 respectively. This supports the intuition that enforcing connectivity within clusters is especially important in large-scale, multi-module systems. Without this masking, the GNN risks overfitting to noisy or misleading correlations across sensor subsystems.
(2) Effectiveness of Multi-task Forecasting Module. Our multi-task forecasting module aims to model both global temporal dynamics and cluster-specific behavior patterns. The shared layers capture system-wide trends, while the cluster-specific branches allow for specialization based on sensor clustering. Ablating this module forces the model to apply the same forecasting logic to all sensors, regardless of their group patterns. On SWaT, this simplification results in performance dropping to 0.8434 AUC-ROC and 0.7329 AUC-PRC. Compared to the full model, this highlights a diminished capacity to detect anomalies that emerge in highly localized or cluster-specific ways.
WaDi results reflect a similar trend. The AUC-ROC drops to 0.8128 and AUC-PRC to 0.5140. Although this drop is slightly smaller than that caused by removing the cluster masking, it still illustrates the importance of the multi-task design. In environments where sensor modules operate under different physical or logical regimes, applying a single forecasting head fails to capture the nuance of localized failures.
(3) Combined Effect Analysis. To evaluate the complementary role of the two modules, we analyze the performance when both cluster masking and multi-task forecasting are removed. In this ablated variant, the model relies solely on unconstrained graph learning and a single forecasting head. Performance degrades to 0.8402 AUC-ROC and 0.7413 AUC-PRC on SWaT, and to 0.7901 AUC-ROC and 0.5094 AUC-PRC on WaDi. The combined removal results in the worst scores across all configurations, emphasizing that each module plays a non-redundant role in the MLAD pipeline.
This outcome aligns with the framework’s conceptual foundation: cluster masking shapes the graph’s structure by embedding sensor group information, while multi-task forecasting the separation between sensor clusters during prediction. When both constraints are lifted, the model’s inductive bias weakens considerably, leading to poorer generalization and noisier anomaly scores. Importantly, this supports our design philosophy of modular integration—each component addresses a distinct modeling challenge, and their synergy results in more robust detection under complex real-world conditions.
(4) Summary of Findings. The ablation study provides clear and consistent evidence supporting the architectural choices made in MLAD. Both the cluster masking strategy and the multi-task forecasting module contribute significantly to overall performance. Their removal leads to noticeable degradation in both AUC-ROC and AUC-PRC. Together, these experiments demonstrate that MLAD’s modular design is not only interpretable but also empirically effective. The cluster masking module injects structural priors that improve GNN message passing, while the multi-task forecasting head enables flexible adaptation to heterogeneous sensor dynamics.
6. Conclusions, Limitation, and Future Direction
In this paper, we introduced MLAD, a novel framework for multivariate time-series anomaly detection that integrates cluster-constrained graph neural network with multi-task forecasting. MLAD leverages unsupervised clustering to identify behaviorally coherent sensor groups. These clusters serve as structural priors for two key components: a cluster-constrained GNN that models sensor relationships within each cluster, and a multi-task forecasting module that captures both global system dynamics and cluster-specific patterns.
Through extensive experiments on three benchmark datasets—SWaT, WaDi, and SMD—MLAD consistently outperforms strong baseline methods. Our framework not only demonstrates superior detection accuracy but also shows robustness across heterogeneous environments with varying system complexity. Ablation studies further validate the complementary contributions of the clustering-based GNN learning and the multi-task forecasting design.
Despite its strong empirical performance, MLAD has several limitations. First, the sensor clustering step is performed offline and remains fixed during model training. This may limit adaptability in dynamic environments where sensor relationships evolve over time. Second, although the anomaly scoring mechanism is effective, it currently treats all prediction errors equally, without explicitly incorporating sensor cluster information. Addressing these limitations could further enhance the flexibility, precision, and interpretability of the framework in real-world deployments. Moreover, our current pipeline performs clustering and anomaly detection in sequence, which limits its suitability for real-time or continuously evolving environments.
Moving forward, several promising research directions emerge. One is to integrate clustering into the training pipeline, enabling the model to jointly learn sensor clustering and anomaly detection in an end-to-end manner. Another is to enhance the interpretability of the framework by introducing mechanisms that explain why anomalies are detected, possibly at the level of sensor clusters or graph structure. Lastly, incorporating cluster-specific anomaly scoring may further improve the model’s sensitivity and robustness in complex, real-world deployments.
In summary, MLAD represents an effective and robust approach to anomaly detection in multivariate time series, particularly in systems characterized by heterogeneous sensor behavior. By bridging sensor clustering with multi-task learning techniques, it offers strong foundation for future innovation.
Author Contributions
Conceptualization, B.L. and S.L.; methodology, K.L., B.L., and S.L.; software, K.L.; validation, K.L.; formal analysis, K.L. and S.L.; writing—original draft preparation, K.L. and Z.T.; writing—review and editing, K.L., S.L., and B.L.; visualization, K.L.; supervision, B.L., Z.L., and S.L.; project administration, B.L. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are publicly available. SWaT and WaDi can be accessed via iTrust Singapore, and SMD is available at: https://github.com/NetManAIOps/OmniAnomaly (accessed on 1 February 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on Outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. 2022, 54, 1–33. [Google Scholar] [CrossRef]
- Guato Burgos, M.F.; Morato, J.; Vizcaino Imacaña, F.P. A Review of Smart Grid Anomaly Detection Approaches Pertaining to Artificial Intelligence. Appl. Sci. 2024, 14, 1194. [Google Scholar] [CrossRef]
- Van Wyk, F.; Wang, Y.; Khojandi, A.; Masoud, N. Real-Time Sensor Anomaly Detection and Identification in Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1264–1276. [Google Scholar] [CrossRef]
- Bałdyga, M.; Barański, K.; Belter, J.; Kalinowski, M.; Weichbroth, P. Anomaly Detection in Railway Sensor Data Environments: State-of-the-Art Methods and Empirical Performance Evaluation. Sensors 2024, 24, 2633. [Google Scholar] [CrossRef] [PubMed]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly Detection for a Water Treatment System Using Unsupervised Machine Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1058–1065. [Google Scholar] [CrossRef]
- Ramotsoela, D.; Abu-Mahfouz, A.; Hancke, G. A Survey of Anomaly Detection in Industrial Wireless Sensor Networks with Critical Water System Infrastructure as a Case Study. Sensors 2018, 18, 2491. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, C.M.; Palleti, V.R.; Mathur, A.P. WADI: A Water Distribution Testbed for Research in the Design of Secure Cyber Physical Systems. In Proceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks, Pittsburgh, PA, USA, 21 April 2017; pp. 25–28. [Google Scholar] [CrossRef]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A Water Treatment Testbed for Research and Training on ICS Security. In Proceedings of the 2016 International Workshop on Cyber-physical Systems for Smart Water Networks (CySWater), Vienna, Austria, 11 April 2016; pp. 31–36. [Google Scholar] [CrossRef]
- Zamanzadeh Darban, Z.; Webb, G.I.; Pan, S.; Aggarwal, C.; Salehi, M. Deep Learning for Time Series Anomaly Detection: A Survey. ACM Comput. Surv. 2025, 57, 1–42. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4027–4035. [Google Scholar] [CrossRef]
- Zheng, Y.; Koh, H.Y.; Jin, M.; Chi, L.; Phan, K.T.; Pan, S.; Chen, Y.P.P.; Xiang, W. Correlation-Aware Spatial-Temporal Graph Learning for Multivariate Time-series Anomaly Detection. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 11802–11816. [Google Scholar] [CrossRef] [PubMed]
- Kozitsin, V.; Katser, I.; Lakontsev, D. Online Forecasting and Anomaly Detection Based on the ARIMA Model. Appl. Sci. 2021, 11, 3194. [Google Scholar] [CrossRef]
- Crépey, S.; Lehdili, N.; Madhar, N.; Thomas, M. Anomaly Detection in Financial Time Series by Principal Component Analysis and Neural Networks. Algorithms 2022, 15, 385. [Google Scholar] [CrossRef]
- Ma, J.; Perkins, S. Time-Series Novelty Detection Using One-Class Support Vector Machines. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 3, pp. 1741–1745. [Google Scholar] [CrossRef]
- Sgueglia, A.; Di Sorbo, A.; Visaggio, C.A.; Canfora, G. A Systematic Literature Review of IoT Time Series Anomaly Detection Solutions. Future Gener. Comput. Syst. 2022, 134, 170–186. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent Neural Networks for Multivariate Time Series with Missing Values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Dong, Y. Temperature Forecasting via Convolutional Recurrent Neural Networks Based on Time-Series Data. Complexity 2020, 2020, 1–8. [Google Scholar] [CrossRef]
- Lin, S.; Clark, R.; Birke, R.; Schonborn, S.; Trigoni, N.; Roberts, S. Anomaly Detection for Time Series Using VAE-LSTM Hybrid Model. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4322–4326. [Google Scholar] [CrossRef]
- Jin, M.; Koh, H.Y.; Wen, Q.; Zambon, D.; Alippi, C.; Webb, G.I.; King, I.; Pan, S. A Survey on Graph Neural Networks for Time Series: Forecasting, Classification, Imputation, and Anomaly Detection. arXiv 2024. [Google Scholar] [CrossRef] [PubMed]
- Ning, Z.; Jiang, Z.; Miao, H.; Wang, L. MST-GNN: A Multi-scale Temporal-Enhanced Graph Neural Network for Anomaly Detection in Multivariate Time Series. In Web and Big Data; Li, B., Yue, L., Tao, C., Han, X., Calvanese, D., Amagasa, T., Eds.; Springer Nature: Cham, Switzerland, 2023; Volume 13421, pp. 382–390. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2022, 34, 5586–5609. [Google Scholar] [CrossRef]
- Yu, J.; Dai, Y.; Liu, X.; Huang, J.; Shen, Y.; Zhang, K.; Zhou, R.; Adhikarla, E.; Ye, W.; Liu, Y.; et al. Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras. arXiv 2024. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Yang, Q. Multi-Task Learning in Natural Language Processing: An Overview. ACM Comput. Surv. 2024, 56, 1–32. [Google Scholar] [CrossRef]
- Kapidis, G.; Poppe, R.; Veltkamp, R.C. Multi-Dataset, Multitask Learning of Egocentric Vision Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6618–6630. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Liu, Z.; Wu, W.; Zuo, W. Social Recommendation via Deep Neural Network-Based Multi-Task Learning. Expert Syst. Appl. 2022, 206, 117755. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; KDD’96; pp. 226–231. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 753–763. [Google Scholar] [CrossRef]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Han, J.; Su, Y.; Jiao, R.; Wen, X.; Pei, D. Multivariate Time Series Anomaly Detection and Interpretation Using Hierarchical Inter-Metric and Temporal Embedding. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3220–3230. [Google Scholar] [CrossRef]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 3395–3404. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; Zhang, Q. Multivariate Time-Series Anomaly Detection via Graph Attention Network. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 841–850. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).