
Efficient and Accurate Zero-Day Electricity Theft Detection from Smart Meter Sensor Data Using Prototype and Ensemble Learning

 ,
,  ,
,  , and
, and
Abstract
1. Introduction
- We developed a prototype learning approach to improve the efficiency of one-class classifiers in processing electricity usage data. Specifically, we applied Principal Component Analysis (PCA) followed by K-means clustering to compress the dataset before feeding it into an ensemble-based anomaly detection pipeline for identifying novel electricity theft patterns.
- We proposed an ensemble learning framework that incorporates a meta-One-Class Support Vector Machine (OCSVM) classifier trained on the normalized output scores of two base models, the Gaussian Mixture Model (GMM) and OCSVM, each trained on prototype-reduced data, to enhance classification accuracy between benign and malicious behaviors.
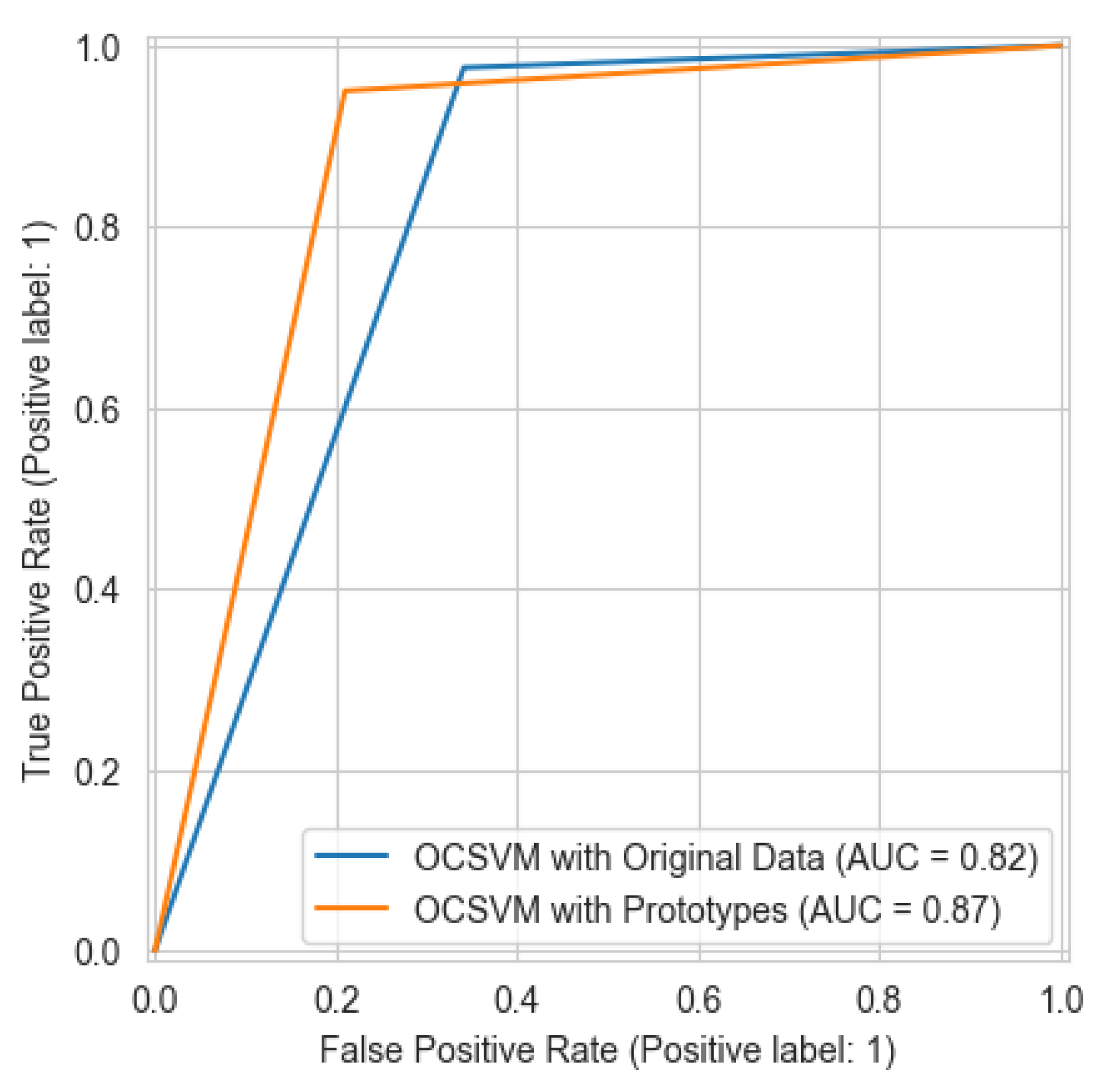
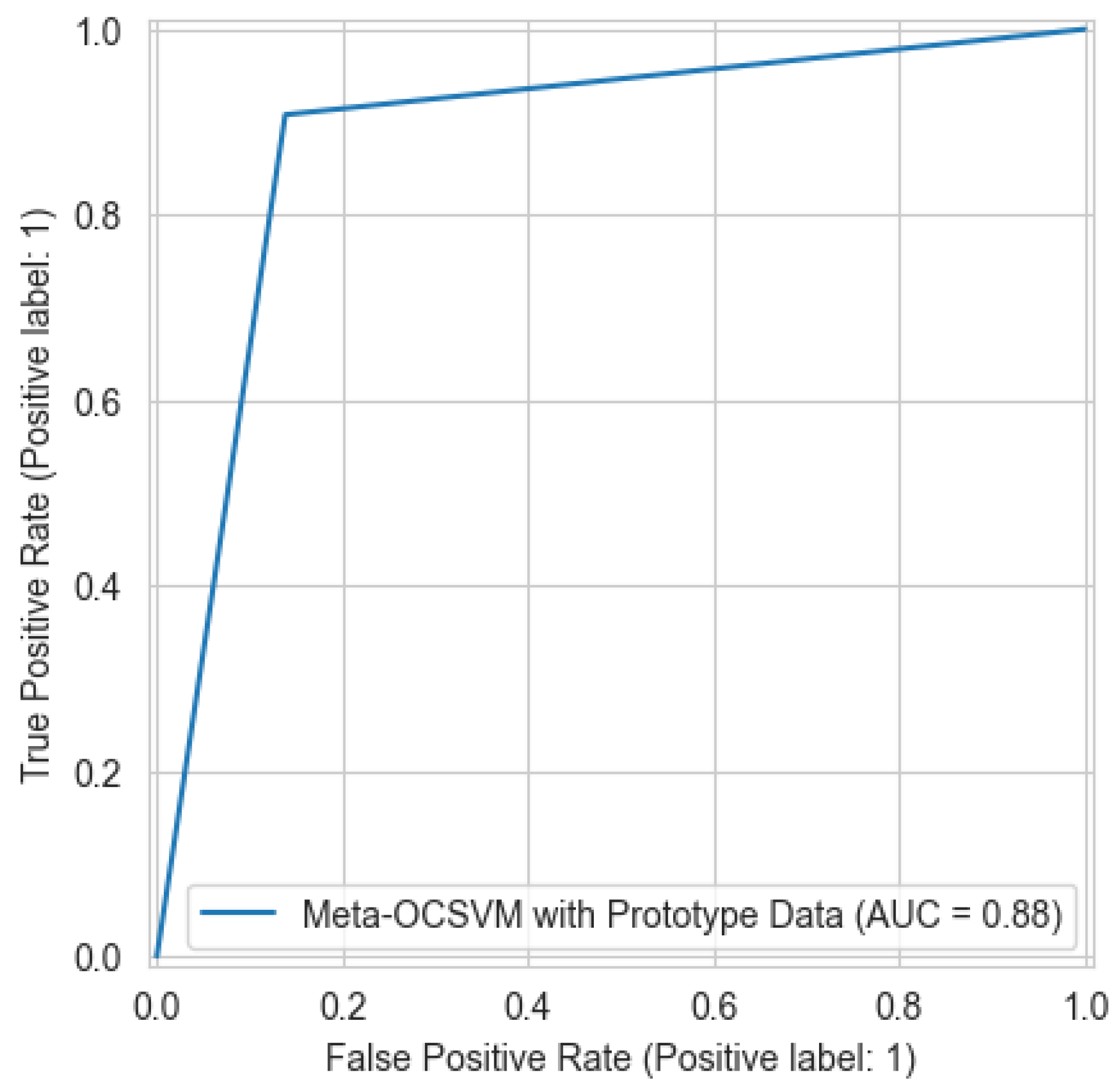
- Experimental results demonstrate that the proposed method achieves a 92% reduction in dataset size and a 76.1% decrease in training time. Furthermore, it significantly improves performance compared to a standalone OCSVM model, improving accuracy from 81.52% to 88.45% and HD from 63.31% to 76.93%, while notably lowering the false alarm rate from 34.25% to 13.85%, addressing common limitations of one-class classifiers.
2. Related Works
2.1. Supervised and Unsupervised Learning
2.2. Ensemble Learning
2.3. Prototype Learning
2.4. Limitations of Existing Techniques
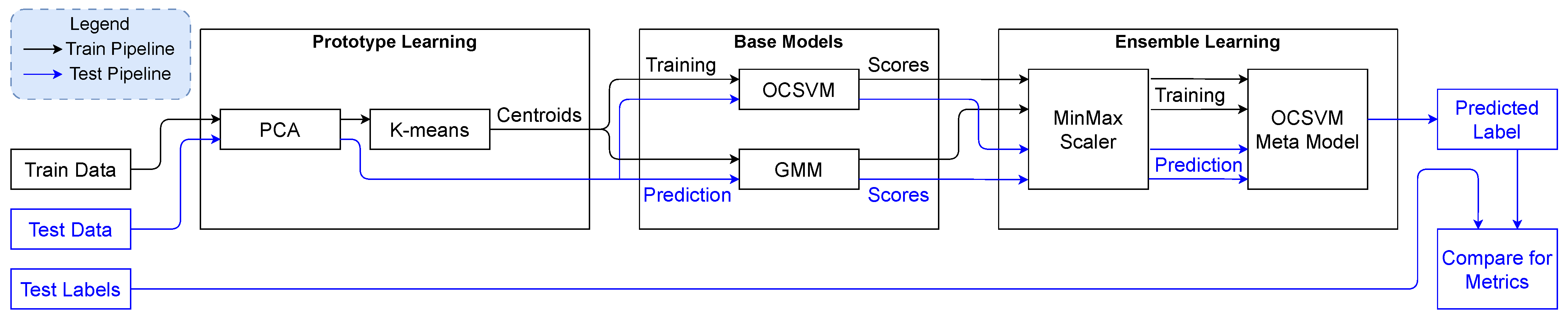
3. Methodology
3.1. Efficient Training Through Prototype Learning
| Algorithm 1 PCA. |
| Input: X_input, k Output: X_transformed |
|
- Initialize K centroids randomly in the feature space.
- Repeat until convergence:
- Assign each sample to the nearest centroid depending on the Euclidean distance.
- Update each cluster’s centroid to be the mean of all samples in the cluster.
- It naturally finds representatives of different consumption patterns.
- The centroids average out random variations while preserving systematic patterns.
- The number of prototypes can be specified.
- It complements the PCA since it reduces samples instead of features.
- The centroids can be directly used to efficiently train the one-class classifiers.
| Algorithm 2 Our proposed data-size reduction approach. |
| Input: training_X, testing_X, testing_y, number_components, number_clusters Output: training_X_centroids, testing_X_pca |
|
3.2. Zero-Day Detection Through One-Class Classification
3.2.1. One-Class Support Vector Machine (OCSVM)
3.2.2. Gaussian Mixture Model (GMM)
3.3. Accurate Detection Through Ensemble Learning
3.3.1. Score Space Transformation
3.3.2. Score Normalization
3.3.3. Meta Classification
3.3.4. Final Prediction
4. Performance Evaluation
4.1. Dataset and Attack Model
4.2. Metrics
- TP (True Positives): the number of malicious samples correctly identified.
- FP (False Positives): the number of benign samples incorrectly identified as malicious.
- TN (True Negatives): the number of benign samples correctly identified.
- FN (False Negatives): the number of malicious samples incorrectly identified as benign.
- Accuracy: The percentage of samples identified correctly as what they are. It can be calculated as follows:
- Confusion Matrix: This is a matrix that has the TN, FN, TP, and FP at indices , , , and , respectively.
- Recall: Measures the ratio of malicious samples identified as malicious.
- Precision: Measures the proportion of correctly identified malicious samples among all samples labeled as malicious by the model.
- F1 Score: As shown by the formula below, it represents a balance between the recall and precision.
- False Alarm Rate (FAR): The proportion of negative points that were incorrectly classified as positive. It can be calculated according to the following formula:
- Highest Difference (HD): Shows how well a classifier can distinguish between malicious and benign samples. It is calculated as follows:
- Area Under the Receiver Operating Characteristic Curve (AUC): The Receiver Operating Characteristic Curve (ROC) represents the relationship between TP and FP as the threshold for classification changes. The AUC represents a model’s ability to distinguish between different classes.
- Dataset Size Reduction: To judge the effectiveness of our prototype learning approach in reducing the size of the dataset, Equation (25) shows the overall percentage of data points/components of the reduced dataset relative to the original dataset as a function of the number of clusters , number of original data points , number of components after PCA , and original number of components .
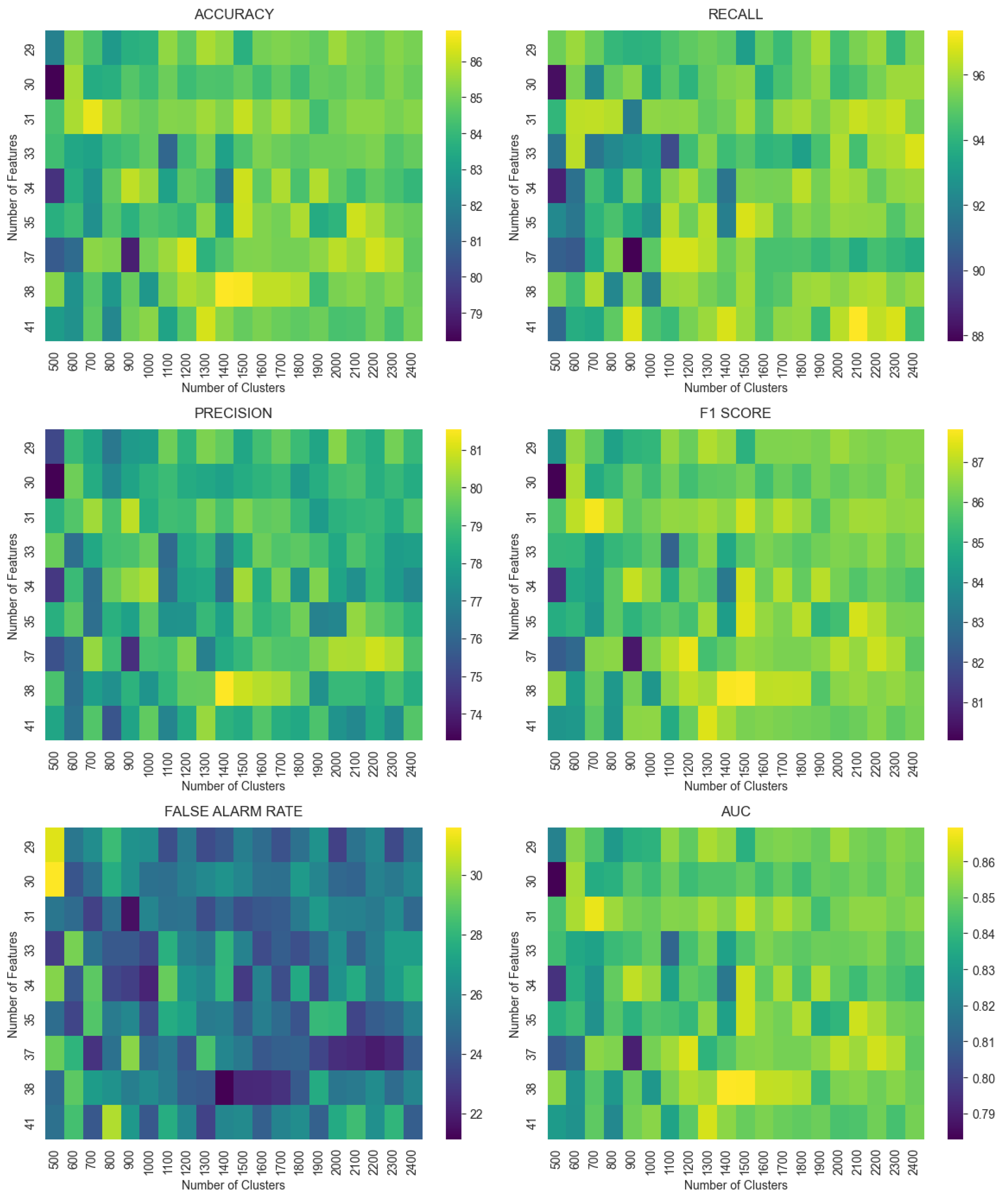
4.3. Experiments
4.3.1. Experiment 1
| Algorithm 3 The Grid Search algorithm for fine-tuning the models. |
| Input: Vector of n sets of parameters P, for a specific classification algorithm a. Scoring function s that is to be maximized. Output: Set of parameters p that produces the highest value for s |
|
4.3.2. Experiment 2
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yassine, A.; Baza, M.; Abdelfattah, S.; Badr, M.; Rasheed, A.; Amer, R. Recent advances towards securing smart grids with blockchain. In Proceedings of the International Telecommunications Conference (ITC-Egypt), Alexandria, Egypt, 18–20 July 2023; pp. 101–106. [Google Scholar]
- Badr, M.M. Security and Privacy Preservation for Smart Grid AMI Using Machine Learning and Cryptography. Ph.D. Thesis, Tennessee Technological University, Cookeville, TN, USA, 2022. [Google Scholar]
- Savian, F.d.S.; Siluk, J.C.M.; Garlet, T.B.; do Nascimento, F.M.; Pinheiro, J.R.; Vale, Z. Non-technical losses: A systematic contemporary article review. Renew. Sustain. Energy Rev. 2021, 147, 111205. [Google Scholar] [CrossRef]
- Eltoukhy, A.T.; Badr, M.M.; Elgarhy, I.; Mahmoud, M.; Alsabaan, M.; Alshawi, T. Repetitive Backdoor Attacks and Countermeasures for Smart Grid Reinforcement Incremental Learning. IEEE Internet Things J. 2025, 12, 3089–3104. [Google Scholar] [CrossRef]
- Bondok, A.H.; Badr, M.; Mahmoud, M.; Alsabaan, M.; Fouda, M.M.; Abdallah, M. Securing One-Class Federated Learning Classifiers Against Trojan Attacks in Smart Grid. IEEE Internet Things J. 2025, 12, 4006–4021. [Google Scholar] [CrossRef]
- Elgarhy, I.; Badr, M.M.; Mahmoud, M.; Alsabaan, M.; Alshawi, T.; Alsaqhan, M. XAI-Based Accurate Anomaly Detector That Is Robust Against Black-Box Evasion Attacks for the Smart Grid. Appl. Sci. 2024, 14, 9897. [Google Scholar] [CrossRef]
- Blazakis, K.; Schetakis, N.; Badr, M.M.; Aghamalyan, D.; Stavrakakis, K.; Stavrakakis, G. Power Theft Detection in Smart Grids Using Quantum Machine Learning. IEEE Access 2025, 13, 61511–61525. [Google Scholar] [CrossRef]
- Elgarhy, I.; El-Toukhy, A.T.; Badr, M.M.; Mahmoud, M.; Fouda, M.M.; Alsabaan, M.; Kholidy, H.A. Secured Cluster-Based Electricity Theft Detectors Against Blackbox Evasion Attacks. In Proceedings of the IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 333–338. [Google Scholar]
- Ahmad, T. Non-technical loss analysis and prevention using smart meters. Renew. Sustain. Energy Rev. 2017, 72, 573–589. [Google Scholar] [CrossRef]
- Gaur, V.; Gupta, E. The determinants of electricity theft: An empirical analysis of Indian states. Energy Policy 2016, 93, 127–136. [Google Scholar] [CrossRef]
- Jokar, P.; Arianpoo, N.; Leung, V.C.M. Electricity Theft Detection in AMI Using Customers’ Consumption Patterns. IEEE Trans. Smart Grid 2016, 7, 216–226. [Google Scholar] [CrossRef]
- Lewis, F.B. Costly ‘Throw-Ups’: Electricity Theft and Power Disruptions. Electr. J. 2015, 28, 118–135. [Google Scholar] [CrossRef]
- Ghasemi, A.A.; Gitizadeh, M. Detection of illegal consumers using pattern classification approach combined with Levenberg-Marquardt method in smart grid. Int. J. Electr. Power Energy Syst. 2018, 99, 363–375. [Google Scholar] [CrossRef]
- Yao, D.; Wen, M.; Liang, X.; Fu, Z.; Zhang, K.; Yang, B. Energy Theft Detection With Energy Privacy Preservation in the Smart Grid. IEEE Internet Things J. 2019, 6, 7659–7669. [Google Scholar] [CrossRef]
- McLaughlin, S.; Holbert, B.; Fawaz, A.; Berthier, R.; Zonouz, S. A Multi-Sensor Energy Theft Detection Framework for Advanced Metering Infrastructures. IEEE J. Sel. Areas Commun. 2013, 31, 1319–1330. [Google Scholar] [CrossRef]
- Aslam, Z.; Javaid, N.; Ahmad, A.; Ahmed, A.; Gulfam, S.M. A Combined Deep Learning and Ensemble Learning Methodology to Avoid Electricity Theft in Smart Grids. Energies 2020, 13, 5599. [Google Scholar] [CrossRef]
- Lin, C.H.; Chen, S.J.; Kuo, C.L.; Chen, J.L. Non-Cooperative Game Model Applied to an Advanced Metering Infrastructure for Non-Technical Loss Screening in Micro-Distribution Systems. IEEE Trans. Smart Grid 2014, 5, 2468–2469. [Google Scholar] [CrossRef]
- Amin, S.; Schwartz, G.A.; Cardenas, A.A.; Sastry, S.S. Game-Theoretic Models of Electricity Theft Detection in Smart Utility Networks: Providing New Capabilities with Advanced Metering Infrastructure. IEEE Control Syst. Mag. 2015, 35, 66–81. [Google Scholar] [CrossRef]
- Sun, X.; Hu, J.; Zhang, Z.; Cao, D.; Huang, Q.; Chen, Z.; Hu, W. Electricity Theft Detection Method Based on Ensemble Learning and Prototype Learning. J. Mod. Power Syst. Clean Energy 2024, 12, 213–224. [Google Scholar] [CrossRef]
- Badr, M.M.; Baza, M.; Rasheed, A.; Kholidy, H.; Abdelfattah, S.; Zaman, T.S. Comparative Analysis between Supervised and Anomaly Detectors Against Electricity Theft Zero-Day Attacks. In Proceedings of the 2024 International Telecommunications Conference (ITC-Egypt), Cairo, Egypt, 22–25 July 2024; pp. 706–711. [Google Scholar] [CrossRef]
- Verma, P.; Tan, S. A bottle of water per email: The hidden environmental costs of using AI chatbots. The Washington Post. 18 September 2024. Available online: https://www.washingtonpost.com/technology/2024/09/18/energy-ai-use-electricity-water-data-centers/ (accessed on 19 September 2024).
- Li, P.; Yang, J.; Islam, M.A.; Ren, S. Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models. arXiv 2023, arXiv:2304.03271. [Google Scholar]
- O’Brien, I. Data center emissions probably 662% higher than big tech claims. Can it keep up the ruse? The Guardian. 15 September 2024. Available online: https://www.theguardian.com/technology/2024/sep/15/data-center-gas-emissions-tech (accessed on 21 September 2024).
- Gunturi, S.K.; Sarkar, D. Ensemble machine learning models for the detection of energy theft. Electr. Power Syst. Res. 2021, 192, 106904. [Google Scholar] [CrossRef]
- Staps, D.; Schubert, R.; Kaden, M.; Lampe, A.; Hermann, W.; Villmann, T. Prototype-based One-Class-Classification Learning Using Local Representations. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Miller, M.; Habbak, H.; Badr, M.; Baza, M.; Mahmoud, M.; Fouda, M.M. Electricity Theft Detection Approach Using One-Class Classification for AMI. In Proceedings of the 2024 IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 260–265. [Google Scholar] [CrossRef]
- Liu, D.; Huang, D.; Chen, X.; Dou, J.; Tang, L.; Zhang, Z. An Unsupervised Abnormal Power Consumption Detection Method Combining Multi-Cluster Feature Selection and the Gaussian Mixture Model. Electronics 2024, 13, 3446. [Google Scholar] [CrossRef]
- Viegas, J.L.; Esteves, P.R.; Vieira, S.M. Clustering-based novelty detection for identification of non-technical losses. Int. J. Electr. Power Energy Syst. 2018, 101, 301–310. [Google Scholar] [CrossRef]
- Singh, S.; Bose, R.; Joshi, A. PCA based electricity theft detection in advanced metering infrastructure. In Proceedings of the 2017 7th International Conference on Power Systems (ICPS), Pune, India, 21–23 December 2017; pp. 441–445. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Shawe-Taylor, J.; Smola, A.; Williamson, R. Estimating Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, C.C. Outlier Analysis; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Commission for Energy Regulation (CER). Smart Metering Project—Electricity Customer Behaviour Trial, 1st ed.; Commission for Energy Regulation (CER): Dublin, Ireland, 2012; Data archived by the Irish Social Science Data Archive (ISSDA). [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Detection Approach | Zero-Day Attacks Detection | Improved Performance through Ensemble Learning | Efficiency Through Prototype Learning | Achieving Efficiency While Keeping High Performance |
|---|---|---|---|---|---|
| Badr et al. [20] | Unsupervised (OCSVM, IF) | ✓ | × | × | × |
| Miller et al. [26] | Unsupervised (OCSVM + Autoencoder) | ✓ | ✓ | × | × |
| Liu et al. [27] | Unsupervised (GMM + MCFS) | ✓ | × | × | × |
| Gunturi & Sarkar [24] | Supervised (AdaBoost, XGBoost…) | × | ✓ | × | × |
| Aslam et al. [16] | Supervised (LSTM-UNet-Adaboost) | × | ✓ | × | × |
| Sun et al. [19] | Supervised (CNN-LSTM) | × | ✓ | × | × |
| Viegas et al. [28] | Unsupervised (GK Clustering) | ✓ | × | × | × |
| Proposed Method | Unsupervised (PCA+K-means + Meta-OCSVM) | ✓ | ✓ | ✓ | ✓ |
| Component | Specification |
|---|---|
| Processor | Intel Core i7-12700H |
| Number of Cores | 20 cores |
| Processor Speed | Up to 4.7 GHz |
| RAM | 16 GB |
| RAM Type | DDR5 |
| Graphics Card | NVIDIA GeForce RTX 3060 Mobile / MaxQ |
| Graphics Memory | 6 GiB |
| Operating System | NixOS 24.11 |
| Python | CPython 3.11 |
| NumPy | v1.26.4 |
| Scikit-learn | v1.5.2 |
| Model | Acc | RE | PR | F1 | FAR | HD | AUC |
|---|---|---|---|---|---|---|---|
| OCSVM before prototype learning | 81.52 | 97.56 | 73.69 | 83.96 | 34.25 | 63.31 | 0.8165 |
| OCSVM after prototype learning | 86.86 | 94.99 | 81.55 | 87.76 | 21.13 | 73.86 | 0.8693 |
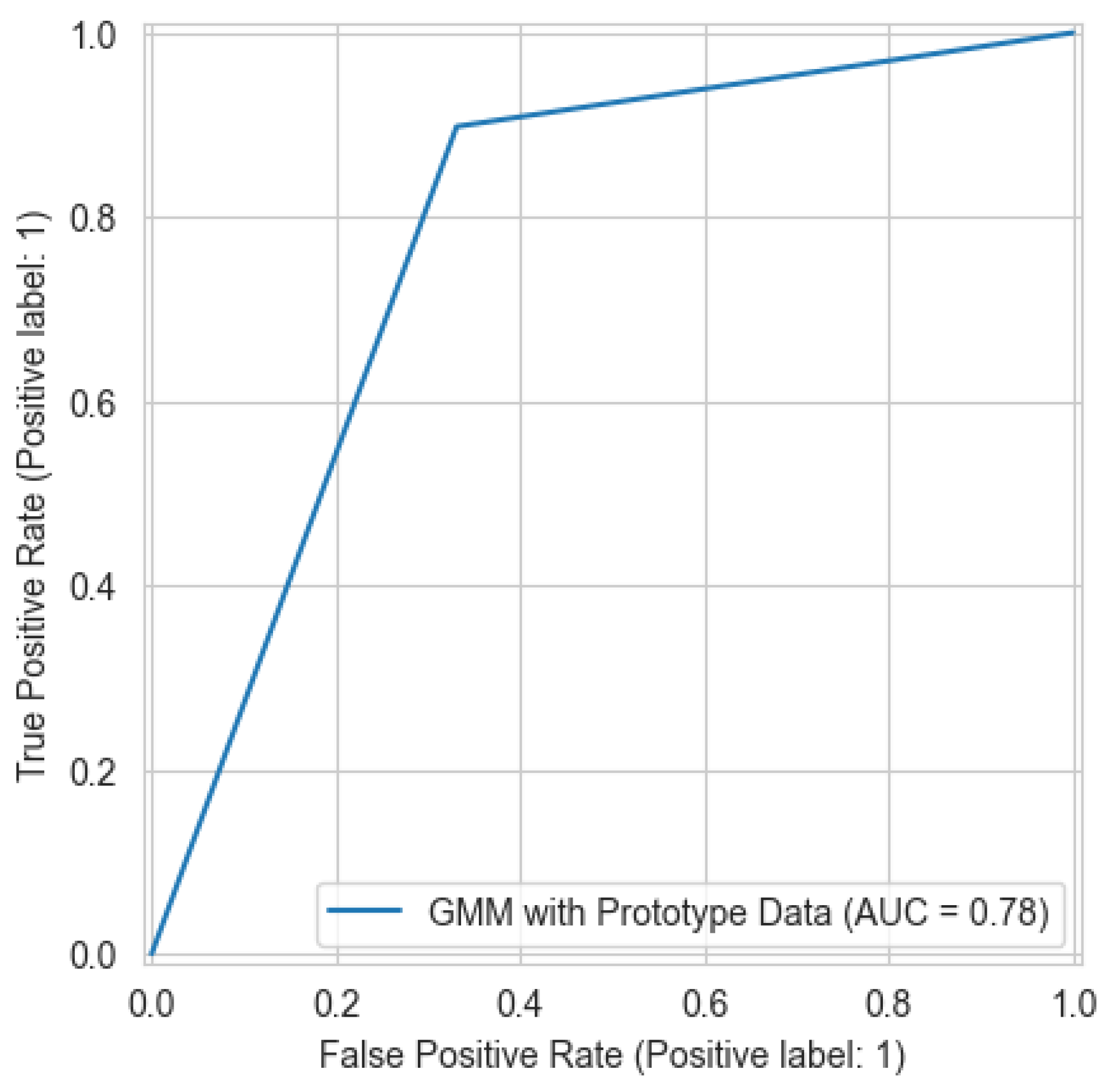
| GMM after prototype learning | 78.47 | 89.82 | 72.99 | 80.53 | 32.68 | 57.14 | 0.7857 |
| Meta-OCSVM after prototype learning (Proposed) | 88.45 | 90.78 | 86.57 | 88.62 | 13.85 | 76.93 | 0.8846 |
| Hyperparameter | Value |
|---|---|
| Number of Components () | 208 |
| Tolerance () | 0.0001 |
| Covariance Type | spherical |
| Contamination | 0.1 |
| Random State | 42 |
| Hyperparameter | Base OCSVM | Meta OCSVM |
|---|---|---|
| Kernel | sigmoid | rbf |
| Gamma | scale | scale |
| Nu () | 0.02 | 0.115 |
| Model | Training Time | |
|---|---|---|
| Without Prototypes | OCSVM | 0.311 s |
| GMM | 13.073 s | |
| Meta-OCSVM | 1.342 s | |
| Total | 14.726 s | |
| With Prototypes (Proposed) | PCA | 0.006 s |
| K-means | 1.621 s | |
| OCSVM | 0.036 s | |
| GMM | 1.691 s | |
| Meta-OCSVM | 0.179 s | |
| Total | 3.533 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Massarani, A.H.; Badr, M.M.; Baza, M.; Alshahrani, H.; Alshehri, A. Efficient and Accurate Zero-Day Electricity Theft Detection from Smart Meter Sensor Data Using Prototype and Ensemble Learning. Sensors 2025, 25, 4111. https://doi.org/10.3390/s25134111
Massarani AH, Badr MM, Baza M, Alshahrani H, Alshehri A. Efficient and Accurate Zero-Day Electricity Theft Detection from Smart Meter Sensor Data Using Prototype and Ensemble Learning. Sensors. 2025; 25(13):4111. https://doi.org/10.3390/s25134111
Chicago/Turabian StyleMassarani, Alyaman H., Mahmoud M. Badr, Mohamed Baza, Hani Alshahrani, and Ali Alshehri. 2025. "Efficient and Accurate Zero-Day Electricity Theft Detection from Smart Meter Sensor Data Using Prototype and Ensemble Learning" Sensors 25, no. 13: 4111. https://doi.org/10.3390/s25134111
APA StyleMassarani, A. H., Badr, M. M., Baza, M., Alshahrani, H., & Alshehri, A. (2025). Efficient and Accurate Zero-Day Electricity Theft Detection from Smart Meter Sensor Data Using Prototype and Ensemble Learning. Sensors, 25(13), 4111. https://doi.org/10.3390/s25134111