1. Introduction
Wearable-sensor-based HAR is vital for applications in health monitoring, human–computer interaction, and many other areas. However, most current HAR techniques heavily rely on labeled training data, which are often scarce and costly to annotate. This reliance on labeled data presents significant challenges: fully supervised deep learning methods require large labeled datasets, while purely unsupervised techniques typically underperform due to the lack of informative cues. As a result, this labeling challenge hinders the real-world deployment of HAR systems.
To address this challenge, we explored various deep representation learning approaches to reduce label reliance in HAR with wearables. Specifically, we reviewed different learning paradigms within representation learning. We then carefully designed and tailored these approaches by introducing novel model architectures, incorporating domain knowledge, and adopting diverse training methods to effectively address label dependency. Our study focused on evaluating how these modifications impact the label dependency of these approaches. In particular, we explored the following approaches to reduce label reliance:
We first developed a weakly supervised approach inspired by previous research in computer vision [
1,
2]. These prior works demonstrated that selective representation can be achieved using weakly supervised approaches that reduce the need for extensive labeled training data. Building on these findings, we incorporated the weakly supervised approach as a means to decrease the model’s reliance on labeled data.
We next enhanced our weakly supervised approach by integrating multi-task learning to further reduce label reliance by leveraging shared knowledge between related tasks. While achieving favorable outcomes is feasible through learning solely on a single task, potentially superior results might be attainable through the inclusion of related tasks. This is because insights drawn from the training signals of correlated tasks can offer valuable information to improve the model’s competence in the primary task. By sharing representations among correlated tasks, we can empower the model to achieve better overall performance. From a multi-task standpoint [
3,
4,
5], HAR and person identification exhibit a strong connection. Integrating them within a single weakly supervised multi-task model is a logical step and holds potential advantages for both tasks.
We also implemented a self-supervised learning approach that incorporates domain expertise to create supervisory signals from the intrinsic structure of the data. This method leverages the inherent patterns and semantics within sensor data, thereby circumventing the need for manual labeling. In the context of wearable sensors, self-supervised methods can utilize specialized knowledge about human activity movement patterns, biomechanics, and contextual information to construct pretext tasks. These tasks encourage the model to learn representations that capture meaningful aspects of the data without requiring explicit annotations. By integrating this domain understanding into pretext tasks, our approach effectively captures high-level abstractions from raw sensor data, leading to more robust and interpretable representations. Through this method, we address the label dependence challenge in HAR by deriving useful supervisory signals directly from the sensor data.
Finally, we developed a novel hybrid framework that combines weak supervision with self-supervision to further reduce label dependency. This weakly self-supervised approach integrates the complementary strengths of both paradigms, enabling the model to benefit from the structured guidance of weak supervision while simultaneously leveraging self-supervised signals from unlabeled data. To demonstrate the practical benefits of this innovative hybrid approach, we conducted experiments with extremely limited label availability (1%, 5%, and 10% of labeled data), showing how our combined framework progressively improves performance as more labels become available.
By evaluating and integrating various learning paradigms, we aim to advance HAR systems that are less reliant on extensive labeled data. Our comprehensive experimental evaluation compares our proposed approaches against both traditional supervised and unsupervised baselines as well as established approaches from prior research, providing insights into the trade-offs between supervision requirements and recognition performance. The remainder of this paper outlines the theoretical foundations and methodologies that guide our investigation, setting the stage for the comparative analysis of these strategies.
2. Background
In this section, we provide a comprehensive overview of the foundational concepts and techniques central to our study. We begin with the fundamentals of HAR, which involves identifying and categorizing activities based on data from wearable sensors. Next, we explore deep representation learning, a key aspect of modern machine learning that focuses on automatically extracting meaningful features from raw data. Finally, we examine the technical approaches employed in our research, including various deep learning architectures and specialized loss functions designed to reduce label reliance in HAR. These components form the theoretical and practical foundation upon which our proposed methods are built.
2.1. Human Activity Recognition
Wearable sensor-based HAR approaches generally fall into two main categories: methods using carefully designed handcrafted features, and those leveraging deep neural networks (DNNs) to automatically derive discriminative representations from raw sensor data.
2.1.1. Handcrafted Features
Handcrafted features are deliberately designed based on domain expertise, offering a manual approach to feature engineering. In HAR systems, these features are specifically tailored to capture relevant information from sensor data for accurate activity recognition. Various statistical features, such as mean, variance, and entropy, have been successfully integrated into models [
6,
7,
8]. Additionally, researchers have employed wavelet transform-based features [
9], while He and Jin [
10] proposed features derived from the discrete cosine transform. These signal-based features have proven effective in HAR systems, demonstrating their capability to accurately capture crucial information for activity recognition.
2.1.2. Learned Features
In recent years, DNNs [
11,
12] have significantly transformed HAR. DNNs enable automatic extraction of features from raw sensor data, eliminating the need for manual feature crafting. Morales and Roggen [
13] designed a model that integrates Convolutional Neural Networks (CNNs) with Long Short-Term Memory (LSTM) components. While CNNs capture local temporal relationships, LSTM’s memory states facilitate the understanding of broader time-scale dependencies. Abu Alsheikh et al. [
14] introduced a hybrid approach combining a deep belief network with a Hidden Markov Model, effectively leveraging the strengths of both paradigms for feature extraction. More recently, Chen et al. [
15] proposed a framework where a deep network architecture utilizes stage distillation, progressively extracting more informative features from raw data, enhancing HAR performance. These DNN-based strategies excel in automated feature extraction but still require explicit labels for model training.
2.1.3. Hybrid Features
Beyond the traditional dichotomy between handcrafted and learned features, recent studies have pursued hybrid strategies that integrate the best of both worlds. Qin et al. [
16], for instance, incorporated engineered wavelet features organized as an image input. These features were then processed through a convolutional network to autonomously extract and abstract the engineered attributes, resulting in enhanced representation. This hybrid approach combines the interpretability of handcrafted features with the automation power of DNNs, offering increased flexibility to the learning system. However, similar to other approaches, this hybrid strategy still relies on explicit labels for effective training.
For a comprehensive understanding of various aspects and methodologies in HAR, we refer readers to survey papers by Minh Dang et al. [
17], Wang et al. [
18], and Zhang et al. [
19], which offer in-depth discussions on different techniques in HAR research.
Building on this foundation of HAR approaches, our work focuses on representation learning, a key strategy for achieving label efficiency by improving model performance with fewer labeled examples. In the following section, we explore several representation learning paradigms that directly address the challenge of label scarcity in HAR applications.
2.2. Representation Learning
We categorize representation learning paradigms based on the degree of supervision used during training: supervised representation learning (
Section 2.2.1), unsupervised representation learning (
Section 2.2.2), weakly supervised representation learning (
Section 2.2.3), and self-supervised representation learning (
Section 2.2.4).
In order to illustrate these concepts, let us consider a running example and follow the same notations in this section. Consider a dataset with labels as , where represents the input samples, symbolizes the corresponding labels, N is the number of training samples, i is the sample index, M is the number of classes in the dataset, and j is the class index. In the context of wearable-sensor-based HAR, X would be the readings from different sensors, while Y would be distinct categories of human activities. The objective of representation learning involves training a feature extraction function, denoted as , which maps an input sample to a feature representation . The core goal is to learn a transformation that projects raw input data into a new representation space where samples from different classes or categories become more distinct and separable. Ideally, the learned representations should highlight the discriminative factors that distinguish between distinct classes or concepts, while being invariant to irrelevant variations. By capturing these class-differentiating characteristics in a disentangled and information-preserving manner, the derived representations can significantly improve the performance of models in subsequent tasks such as classification, clustering, regression, or other downstream analyses.
2.2.1. Supervised Representation Learning
In supervised representation learning [
20], the training process leverages labeled data, where each input sample
is associated with a corresponding target label
. The goal is to learn a feature extractor
that maps the raw input
to a representation
that is well suited and effective for the target task. This learned representation
serves as input to a task-specific function
, which generates the predicted output
. The predicted output
is then compared against the ground truth target
using a suitable loss function, which guides the optimization of both
and
to learn representations that are discriminative for the supervised task at hand. The training involves minimizing the supervised loss function
, which could be, for instance, a cross-entropy loss. Following the minimization of the supervised loss
, the trained
is employed as the feature extraction function to generate the representation. This representation can then be used for various subsequent tasks.
One of the strengths of supervised representation learning is the acquisition of the feature extraction function
as a direct outcome of supervised training. As an example, models like VGG [
21], initially trained for ImageNet classification, have found extensive utility across diverse visual tasks [
22]. A larger dataset in supervised representation learning has been shown to positively impact downstream performance [
23]. However, it is crucial to acknowledge that supervised representation learning heavily depends on available labels, which comes at a significant cost in terms of both time and financial resources. To counter this limitation, unsupervised representation learning has attracted substantial attention within the machine learning and HAR research communities.
2.2.2. Unsupervised Representation Learning
Unsupervised representation learning is relevant when labeled data are unavailable. In such a scenario, the objective is to unveil patterns or inherent structure within unlabeled data and to reshape input data into a more insightful representation space without relying on explicit labels. This is usually achieved by training the feature extraction function through unsupervised tasks, such as dimensionality reduction, data reconstruction, clustering, or generative modeling. The feature extractor is designed to map the raw input to a representation that captures features and structure within the data. This learned representation then serves as input to downstream tasks.
One major category of unsupervised representation learning techniques is dimensionality reduction. Linear approaches like principal component analysis (PCA) identify the principal components that explain the maximum variance in the data through mathematical decomposition, allowing for a simplified representation of the original dataset while retaining as much of the original information as possible. Nonlinear dimensionality reduction methods like t-SNE [
24] or UMAP [
25] better preserve local neighborhood structures, enabling more accurate representation of complex data manifolds.
Beyond traditional dimensionality reduction, neural-network-based approaches offer powerful alternatives for unsupervised representation learning. Autoencoders learn to compress data into a lower-dimensional latent space and then reconstruct it, forcing the network to capture essential features of the data. Unlike PCA, autoencoders can model complex nonlinear relationships in the data. Various extensions of the basic autoencoder architecture, such as denoising autoencoders that learn robust representations by reconstructing clean inputs from corrupted versions, or variational autoencoders that learn probabilistic latent variable models, further enhance representation quality for downstream tasks.
Due to its unsupervised nature, unsupervised representation learning can easily be scaled to larger unlabeled datasets at minimal cost. For instance, in the work of [
26], word representations were trained using an extremely extensive dataset. This characteristic holds significant value, given that the magnitude of the dataset plays a pivotal role in enhancing the real-world performance of models in downstream tasks, as highlighted by studies such as [
27].
While unsupervised approaches eliminate the need for labels entirely, they often struggle to capture task-specific representations effectively. This limitation inspired the development of weakly supervised representation learning, which aims to achieve better performance with minimal labeling effort.
2.2.3. Weakly Supervised Representation Learning
Weakly supervised representation learning methods bridge the gap between fully supervised and unsupervised approaches. By incorporating limited or imperfect labels, these techniques aim to guide representation learning more effectively than unsupervised methods while requiring less complete annotation than fully supervised techniques. Common weakly supervised strategies include multiple instance learning using group-level labels [
28], label propagation from a small labeled subset [
29], and contrastive methods with pairwise constraints [
30,
31] (e.g., must-link, cannot-link). The learning process optimizes representations using noisy or incomplete labels, understanding they may be less reliable than full supervision.
In weakly supervised learning, the available labels are incomplete or imprecise. A function utilizes the learned representations to predict weak labels , which only provide partial or coarse ground truth for the desired outputs. The predicted weak label, , will be measured against the true weak label . The loss function , which measures the error between predictions and true values, is minimized to optimize the functions and , thereby learning representations suited for downstream tasks while accounting for imperfect labels. For instance, in contrastive learning with pairwise constraints, the model is guided by information about which data pairs should be similar (must-link) and which should be dissimilar (cannot-link). The learning objective typically involves minimizing the distance between representations of must-link pairs while maximizing the distance between cannot-link pairs. This encourages the model to learn a representation space where semantically similar items are clustered together and dissimilar items are separated, even without knowing the exact class labels.
Despite their effectiveness, weakly supervised methods still require some form of external supervision. Self-supervised representation learning emerged as an alternative that eliminates the need for any external labels by deriving supervisory signals directly from the data itself.
2.2.4. Self-Supervised Representation Learning
Self-supervised representation learning generates internal supervision from the data through pretext tasks that expose meaningful features. By designing proxy objectives leveraging intrinsic structure within the data, self-supervision transforms the data into their own source of labels.
The general approach involves creating artificial prediction tasks that do not require manual annotations but force the model to learn useful representations. These pretext tasks are designed so that solving them requires understanding important structural aspects of the data. The learning process minimizes the discrepancy between predicted and actual labels derived from these internal supervisory signals.
Numerous pretext tasks have been developed across different domains. In computer vision, these include predicting missing image parts [
32], determining relative patch positions, colorizing grayscale images, and predicting image rotations [
33]. For sequential data, common tasks include predicting future steps, sorting scrambled sequences [
34], or determining sequence ordering [
35].
As a concrete example, in the image rotation prediction task [
33], the authors define a collection of
K discrete geometric transformations, denoted as
. Here,
represents the operator that applies a geometric transformation labeled
r to an image
, resulting in the transformed image
. The feature extraction function, denoted as
, and the rotation prediction function, denoted as
, operate on the transformed image
(with the label
r unknown to these functions). The predicted label,
, is then compared to the true label
r. The optimization of
and
is driven by a surrogate supervised loss function,
, which measures the prediction accuracy of the rotation transformations. After training, the learned
is used as the feature extraction function to generate representations for downstream tasks.
These self-supervised methods extend representation learning to scenarios with limited external supervision by generating internal supervisory signals from the data. They offer viable alternatives when external labels are scarce or imperfect. Self-supervised approaches are particularly valuable in domains like HAR with wearables, where collecting labeled data is challenging and expensive.
2.3. Technical Methodologies
Building on the review of HAR and deep representation learning methods in
Section 2.1 and
Section 2.2, we identified and selected the techniques most relevant to this work. These fundamental deep learning architectures and methods have been chosen for their proven effectiveness in capturing temporal patterns and learning discriminative representations from wearable sensor data. Each selected technique addresses specific challenges in HAR: autoencoders [
36] for unsupervised representation learning, ResNet [
37] for handling deep architectures without degradation, Siamese networks [
38] for similarity-based learning in weakly supervised settings, temporal convolutional networks (TCNs) [
39] for effective temporal pattern extraction, and contrastive loss functions [
40] for implementing pairwise constraint-based learning.
These methods have been extensively tested and widely adopted in prior studies, providing a strong and reliable foundation for our research. More importantly, they offer the flexibility needed to implement and compare the different representation learning paradigms outlined in
Section 2.2. The following subsections present a detailed exploration of each selected technique and how they contribute to our framework for reducing label dependency in HAR.
2.3.1. Autoencoder
An autoencoder consists of two primary components: an encoder and a decoder. The encoder serves as the feature extraction function, , while the decoder performs the transformation , aiming to reconstruct the original input from its representation . Formally, this process is defined as .
The optimization of
and
is guided by the data reconstruction loss:
here,
denotes a metric such as the Euclidean distance. This loss function minimizes the difference between the original input
and its reconstruction
, encouraging
to closely approximate
.
A high-quality reconstruction implies that the representation effectively preserves the essential information from . Consequently, this representation becomes valuable for downstream tasks such as classification or clustering.
Autoencoders have been successfully applied across various domains. For instance, Vincent et al. [
41] used denoising autoencoders for robust feature learning, Kingma and Welling [
42] introduced variational autoencoders for generative modeling, and Sakurada and Yairi [
43] employed autoencoders for anomaly detection in time-series data.
2.3.2. ResNet
The ResNet architecture provides an effective means to increase network capacity while addressing the degradation of feature learning commonly observed in standard deep neural networks (DNNs). It achieves this through skip connections or shortcuts, as illustrated in
Figure 1a for a single ResNet block. These connections allow certain layers to be bypassed, ensuring that information flows more efficiently through the network.
The output of a ResNet block is computed by summing the result of the last layer with the input to the block. When the input and output tensors differ in shape, a linear layer of matching size is used for the residual connection. If the tensors share the same shape, an identity function is employed instead. This design ensures seamless integration of residual connections, enhancing learning stability and improving overall network performance.
ResNet architectures have demonstrated remarkable success in numerous applications. He et al. [
37] showed their superior performance in image recognition tasks, Kolesnikov et al. [
44] adapted ResNets for self-supervised visual representation learning, and Maweu et al. [
45] applied them to time-series data to improve diagnostic accuracy in healthcare.
2.3.3. Siamese Neural Networks
A Siamese neural network consists of two branches with shared weights, as depicted in
Figure 1b. This architecture processes two distinct inputs, generating comparable representation vectors that encapsulate each input’s unique features. These vectors are then fed to a metric layer [
46] or a learned metric network, which measures the similarity between the two inputs.
Siamese networks are widely applied in nonlinear metric learning across domains such as computer vision and speech recognition. For instance, Siamese CNNs have been used to develop sophisticated similarity metrics for face verification [
2]. In natural language processing, Mueller and Thyagarajan [
46] introduced a Siamese RNN to evaluate semantic similarity between sentences, while Neculoiu et al. [
47] employed one for job title normalization in recruitment analysis. Zeghidour et al. [
48] leveraged a multi-output Siamese network for speaker and phonetic similarity detection, demonstrating the versatility of this architecture.
2.3.4. Temporal Convolutional Networks
Temporal convolutional networks (TCNs) serve as a foundational component in the proposed approaches. A variation of the TCN block, illustrated in
Figure 1c, uses convolutional layers to extract local patterns from input sequences while enabling translational invariance for these patterns across the data sequence.
Each convolutional layer is followed by batch normalization (BN) [
49], which stabilizes optimization by reparameterizing the problem into a more tractable form. BN accelerates training and provides regularization, preventing early saturation of the nonlinear activation functions. The rectified linear unit (ReLU) [
50] serves as the activation function, further enhancing nonlinear representation learning.
To reduce temporal dimensionality and introduce a degree of translational invariance, a temporal max-pooling layer is added after every two TCN blocks. Max-pooling selects the maximum value within predefined regions, achieving a subsampling effect.
TCNs have demonstrated efficacy in capturing temporal dependencies across diverse applications. For example, Lea et al. [
51] utilized a TCN for action segmentation and detection, Zhang et al. [
52] applied it for text classification, and Bednarski et al. [
53] employed it in health informatics for predicting clinical length of stay and mortality.
2.3.5. Contrastive Loss
In our experiments, we adopt the contrastive loss function to train the model. This function operates on triplets
, where
and
are input samples and
is a binary label indicating whether the samples are similar (
) or dissimilar (
). The model generates activity representations
and
. The contrastive loss evaluates the similarity distance
between these representations using the Euclidean distance metric, defined as:
This distance measures the similarity or dissimilarity between inputs in the representation space. The loss function is designed to minimize the distance for similar pairs while maximizing it for dissimilar pairs, enabling the model to capture meaningful patterns for activity discrimination.
For simplicity, the similarity distance
is denoted as
D. Using this notation, the loss for each training sample is expressed as:
The overall loss for all training samples is then given by:
here,
represents the
i-th training sample, and
N is the total number of samples.
and
denote the loss terms for positive (similar) pairs
and negative (dissimilar) pairs
, respectively. These loss terms are defined as:
The hyperparameter , known as the margin, ensures that only negative pairs with a similarity distance smaller than contribute to the loss. This mechanism focuses the learning process on difficult negative samples near the decision boundary while ignoring well-separated negative pairs.
Contrastive loss functions have been widely adopted in various domains. Chen et al. [
54] employed contrastive learning for visual representations, Xu et al. [
55] used similar techniques for learning sentence representations, and Pan et al. [
56] applied contrastive loss for multilingual neural machine translation.
2.4. Positioning Within Current Research
Recent developments in wearable-based HAR have demonstrated the potential of deep learning architectures and various learning paradigms to improve performance and address labeling challenges. A wide range of approaches have been explored, covering supervised, unsupervised, weakly supervised, and self-supervised learning strategies, each with its own strengths and trade-offs.
From an architectural perspective, several state-of-the-art models have been proposed for time-series representation learning. Transformer-based approaches such as PatchTST [
57] have shown strong performance in capturing long-range temporal dependencies and are increasingly applied in HAR tasks. Likewise, InceptionTime [
58] and TimesNet [
59] represent powerful architectures that extract multi-scale temporal features through hierarchical design. In our work, we adopt TCN and ResNet backbones for their proven effectiveness and computational efficiency on sensor data, while noting that these newer architectures present promising directions for future exploration.
In terms of learning paradigms, recent self-supervised HAR studies offer valuable insights into pretraining strategies. Haresamudram et al. [
12] conduct an extensive evaluation of self-supervised methods across multiple HAR settings. Yuan et al. [
60] leverage large-scale wearable data to train generalizable representations using self-supervision. Cheng et al. [
61] propose contrastive learning techniques that emphasize invariance to augmentation, and Qian et al. [
62] examine how contrastive learning can be adapted to small-scale HAR datasets.
Our study contributes to this growing body of work by comparing the effectiveness of different learning paradigms, supervised, unsupervised, weakly supervised, and self-supervised, and exploring how they can be combined. In particular, we investigate the integration of domain-informed self-supervision with weak supervision using pairwise constraints. This perspective provides a systematic view of the label–efficiency trade-offs inherent to each approach and highlights potential synergies between them for sensor-based HAR.
By situating our experiments within this broader landscape, we aim to offer practical guidance on designing HAR systems under various labeling constraints and to encourage further exploration of hybrid strategies in representation learning.
3. Approaches
In this section, we explore strategies for reducing reliance on labeled data in HAR systems through deep representation learning. Our discussion covers supervised, unsupervised, weakly supervised, self-supervised, and multi-task learning paradigms. Existing HAR models primarily rely on supervised learning for high accuracy but require extensive labeled data, making them costly and time consuming. In contrast, unsupervised methods reduce labeling needs but often perform worse due to the lack of explicit supervision. This fundamental trade-off between label efficiency and model effectiveness motivates our exploration of alternative learning paradigms.
By adapting these approaches to the intrinsic characteristics of human activities, we enhance their applicability to wearable-sensor-based HAR. Leveraging diverse learning paradigms and domain knowledge enables us to minimize labeling requirements while supporting the acquisition of effective representations for sensor-driven HAR tasks. Our primary goal is to systematically compare and investigate these paradigms and reduce the need for large labeled datasets, facilitating the deployment of deep-learning-based HAR in real-world scenarios.
3.1. Supervised Learning Approach
Supervised deep learning techniques have seen development and utilization within HAR systems [
13,
63,
64]. These techniques have the capacity to automatically extract features from data and have proven valuable in HAR applications. Nonetheless, they still demand explicit labels to supervise model training. In real-world HAR use cases, manually labeling extensive sensor datasets is often infeasible, limiting the scalability of purely supervised methods. In our experiments, we use a TCN as the baseline model to evaluate the effectiveness of supervised learning in HAR.
Model Architecture and Training Process
The supervised baseline employs a TCN architecture as illustrated in
Figure 2. This architecture incorporates ResNet’s skip connections (shown in
Figure 1a) within the TCN blocks (shown in
Figure 1c), creating a residual temporal convolutional network that benefits from both techniques. The model processes raw sensor data through a series of TCN blocks, each containing dilated causal convolutions that capture temporal patterns at increasing time scales. This architecture enables the network to effectively model long-range dependencies while maintaining computational efficiency.
Each TCN block contains a sequence of 1D convolutional layers, with each convolutional layer followed by batch normalization and ReLU activation. Residual connections are implemented within blocks to facilitate gradient flow during training. The model concludes with a max pooling layer and a fully connected layer that maps to the target activity classes.
The supervised model is trained using cross-entropy loss
, which measures the discrepancy between predicted class probabilities and the ground truth labels:
where
is the ground truth labels,
represents the predicted class probabilities, and
M is the number of activity classes. This loss function encourages the model to learn discriminative representations that map directly to activity categories, but requires complete activity labels for all training samples.
3.2. Unsupervised Learning Approach
To mitigate the reliance on labeled data, researchers have explored unsupervised learning techniques such as clustering and autoencoder-based feature learning [
65]. These methods extract latent representations from sensor data without requiring explicit activity labels. While this reduces annotation costs, the performance of unsupervised models often lags behind their supervised counterparts, as they lack guidance on what features are most relevant for distinguishing activities. For our unsupervised baseline, we adopt an autoencoder to learn meaningful activity representations from unlabeled sensor data.
Unlike the supervised approach, which processes raw sensor data directly, our unsupervised method operates on handcrafted features extracted from the sensor data. This design choice is deliberate and addresses several challenges inherent to unsupervised learning for HAR. Without the guidance of labels to direct feature learning, autoencoders applied directly to raw wearable sensor data can struggle to identify meaningful activity patterns among sensor noise and irrelevant variations. Handcrafted features incorporate domain expertise about which signal characteristics are most relevant for distinguishing human activities, providing valuable inductive bias that compensates for the absence of explicit supervision. Additionally, these statistical features help reduce dimensionality while preserving essential activity information, enabling the autoencoder to focus on learning higher-level activity representations rather than basic signal processing. Using handcrafted features is particularly valuable in the unsupervised context, where the model must discover meaningful structure without label guidance.
3.2.1. Feature Extraction
This section focuses on the handcrafted features used in the experiments. In the feature extraction stage, the segmented raw sensor signals are converted into feature vectors. Formally, let
denote the sample
i in the set of the segmented raw sensor signals,
the converted feature vector, and
C the feature extraction function. Then, the feature extraction can be defined as Equation (
8):
Finally,
is used as the input to the model.
Table 1 illustrates the statistical high-level features that are used in this approach. Mean, variance, standard deviation, and median, which are the most commonly adopted features in HAR research works, are used in this approach. In addition, some other features, which have been shown to be efficient in previous works [
7], are included here as well. For example, the feature interquartile range (
). Quartiles (
,
, and
) divide the time series signal into quarters. Using this,
is the measure of variability between the upper and lower quartiles,
.
The aforementioned features are computed separately for each axis of the sensor data. Since the data from different sensors are time-synchronized, it is possible to combine features derived from multiple sensor modalities. During the training process, the autoencoder takes the derived features as input and learns to retain the key information while discarding the unnecessary reconstruction-irrelevant components. The encoder effectively projects the feature representations into a lower-dimensional subspace that captures the most informative characteristics for the reconstruction task.
3.2.2. Model Architecture and Training Process
Our unsupervised approach utilizes an autoencoder architecture as shown in
Figure 3. The model consists of an encoder and a decoder network. The encoder maps the input data to a lower-dimensional latent representation, while the decoder attempts to reconstruct the original input from this compressed representation.
The encoder employs a residual-based architecture composed of residual blocks with progressively decreasing dimensions, followed by batch normalization and ReLU activation. The residual connections help preserve important features and improve the gradient flow during training. The final encoder layer outputs a condensed latent representation, , which captures the fundamental characteristics of the input. The decoder adopts a simpler structure, consisting of fully connected layers with progressively increasing dimensions, and concludes with an output layer that matches the input dimensions, as the reconstruction task does not require deep residual connections.
The model is trained using the reconstruction loss already defined in
Section 2.3.1. This loss function encourages the model to learn a compact representation that preserves the important properties of the input data without requiring any activity labels. After training, the encoder part of the neural network serves as a feature extractor, generating representations that capture the intrinsic structure of the input data for downstream clustering.
While the unsupervised approach reduces the reliance on labeled data, it still faces challenges in learning discriminative representations specifically relevant to activity recognition tasks. To address this limitation while still minimizing labeling requirements, we next explore a weakly supervised paradigm that leverages minimal supervision signals in the form of pairwise constraints.
3.3. Weakly Supervised Single-Task Approach
To address the challenge of minimizing the need for extensive supervision during model training, we introduce an initial weakly supervised single-task approach using siamese networks to identify human activities within sensor data streams. This method trains a Siamese network to provide a similarity metric, enabling activity clustering without the strict requirement of explicitly labeled data.
Model Architecture and Training Process
Our model uses a Siamese architecture, as depicted in
Figure 4. For any pair of input sequences representing human activity data, denoted as
, the Siamese network learns to map them to a shared representation space
,
. The layers following this dual-branch architecture constitute a similarity function, which measures the distance between the two extracted representation vectors. Our Siamese networks maintain weight sharing across their twin branches. Each branch employs identical TCN blocks. Outputs from both branches are subsequently processed using fully connected (FC) layers.
The model is trained using triplets , where and are segmented activity sequences and indicates if they are of the same or different activity type.
We adopt pairwise similarity constraints to supervise representation learning. This choice provides a clean and interpretable formulation that aligns with our aim of isolating the effects of different learning paradigms under consistent architectural and supervision settings. While other formulations such as triplet-based or relative constraints are possible, pairwise supervision offers a simple and effective baseline for evaluating the benefits of weak supervision in activity recognition.
As defined in
Section 2.3.5, we use a contrastive loss function to learn a mapping
that captures critical similarities between the input pairs. If
, the representations
and
should be embedded closer together. If
, the representations should be farther apart. The activity-specific contrastive loss is defined as:
where
,
, and
represent individual training samples, and
N is the total number of such samples. The variables
,
, and
on the left side of the equation denote the entire collections of samples.
3.4. Weakly Supervised Multi-Task Approach
In machine learning, models are typically trained to optimize a single metric by specializing on one particular task. However, this narrow focus can neglect useful information from related tasks that could improve performance on the original metric of interest. Multi-task learning provides a technique to harness these additional signals by sharing representations across related tasks. Rather than learning in isolation, the shared representation is trained concurrently on multiple objectives. This enables the model to learn generalized patterns that transfer and benefit all tasks. By leveraging inter-task relationships, multi-task learning can enhance model performance on the original target metric beyond single-task specialized approaches. The joint training process allows complementary signals from related tasks to regularize and inform the shared representation. Motivated by this observation, we extended the weakly supervised single-task approach in
Section 3.3 to include one more related task, person identification, and conducted experiments to evaluate the effectiveness of the weakly supervised multi-task approach on HAR and person identification tasks.
Model Architecture and Training Process
To achieve these capabilities, we adopted a model architecture as illustrated in
Figure 5. This architecture extends the single-task Siamese network from
Section 3.3 by adding a second output head for person identification alongside the original activity recognition branch. Two fully connected layers are connected to the TCN networks and are responsible for processing the activity representations
and the person representations
, respectively. The weights of the FC layers are shared within each representation learning task.
This study adopts a dual-task setup involving activity recognition and person identification. These two tasks were chosen because they are both semantically meaningful in the context of wearable-sensor-based HAR and offer complementary signals for representation learning. While the multi-task framework can be extended to additional tasks, our focus in this work remains on these two to maintain clarity and tractability in evaluation.
Formally, consider a quadruple , where and are the input data sequences (e.g., sensor readings), and denote the semantic relationships between the input pair in terms of activity and person, respectively. Here, or indicates that is a semantically dissimilar pair, i.e., they correspond to different activities or are performed by different persons. Conversely, or indicates a semantically similar pair.
Following the contrastive loss framework defined in
Section 2.3.5, the model learns two mappings,
, and
that encode the relevant semantic relationships between input pairs
in their respective representation spaces. If
(or
), the representations
and
(or
and
) should be mapped to nearby positions. If
(or
), they should be pushed apart.
The loss function is applied separately in each representation space. The final multi-task loss is defined as a weighted sum, with
and
as the corresponding weights for each task, as shown in Equation (
10).
here,
and
represent the contrastive loss functions for activity and person similarity, respectively.
3.5. Self-Supervised Approach
As discussed previously in
Section 2.3.1 and
Section 3.2, autoencoders learn to ensure that the reconstructed output closely resembles the initial input. When a high-quality reconstruction can be generated from the encoded representation, it indicates that the representation preserves essential information from the input data, making it potentially useful for downstream tasks like classification and clustering.
However, simply memorizing information for reconstruction is often inadequate for learning useful representations. Standard reconstruction objectives inevitably capture noise and minute details present in the input data, which may be irrelevant or even detrimental for subsequent tasks. To enhance the utility of representations for specific tasks, the autoencoder training objective should incorporate tailored guidance that prioritizes capturing relevant information while filtering out noise and extraneous details.
To address these limitations, we propose a self-supervised approach that leverages two key relationships in human activity data: the temporal consistency of time series and feature consistency in the feature space. Similar to our unsupervised approach in
Section 3.2, this method operates on the handcrafted statistical features described in
Section 3.2.1, ensuring consistent comparison between approaches while incorporating domain knowledge necessary for effective representation learning.
Our self-supervised approach is built upon specialized consistency objectives that guide the representation learning process toward capturing activity-relevant patterns. In the following subsections, we first describe these two consistency objectives that form the core of our approach, followed by the model architecture that integrates these components into a unified framework.
3.5.1. Temporal Consistency
Intuitively, a human activity can be decomposed into two components, a temporally varying component and a temporally stationary component. Specifically, certain dynamic properties of a single activity can vary over time. For example, while walking, the body pose varies over time: left foot and right foot alternately step forward. This type of dynamic property is recorded in the sensor data, too, and we refer to it here as the temporally varying component. On the other hand, no matter how the body pose varies over time, the semantic content of the activity remains the same. Namely, left foot and right foot can step forward alternately, but the type of the activity is still walking. We refer to this part as the temporally stationary component.
Based on this quality of human activity, the temporal consistency loss forces temporally close data samples to be similar to one another and ignores the difference in the temporally varying component. It is motivated by the intention that the semantic content (i.e., the type of the activity in which we are interested) should vary relatively infrequently over time. If the data samples are temporally close to each other, they may represent the same type of activity, even as they may be very distant in terms of the Euclidean distance in the sensor data space. The temporal consistency loss preserves the temporal continuity of the sensor data.
More formally, let
denote data sample
i, which occurs at time
t during the course of an activity. For each sample, we define
as the set of indices of its
temporal neighbors, which are samples that occur close in time to
. The temporal consistency loss
for
is then defined as:
where
is the reconstruction of
produced by the autoencoder. This loss encourages the reconstruction to be similar to the sample’s temporal neighbors, guiding the encoder to extract features that capture the temporally stationary component while ignoring irrelevant time-varying details.
In our implementation, the temporal neighborhood is defined as the five samples centered around each timestamp t, specifically . These temporal neighbors are treated as semantically similar to the center sample. This similarity definition is used solely to compute the temporal consistency loss and is independent of the actual batch construction used during training.
3.5.2. Feature Consistency
Feature consistency is inspired by the observation that different persons perform the same type of activity in different fashions, but different fashions do not hinder other people from identifying the activity type. Hence, we assume that the personal or individual features in the activity data may not be necessary in the activity clustering stage, and the features, which are commonly present across multiple data points, may be the essential features of the activity. The feature consistency loss function is based on this assumption.
Previous research has demonstrated that combining carefully designed, handcrafted high-level features, which capture the essential characteristics of temporally varying signals, with the k-nearest neighbor algorithm can accurately classify sensor data associated with human activities [
66]. Due to its effectiveness and simplicity, it is employed in this approach to define the local neighborhood of a data sample. The feature consistency loss then aims to preserve the high-level feature characteristics that are generally present in the local neighborhood.
The feature consistency loss encourages the reconstruction of a data sample to be similar to its neighbors in the feature space. The rationale is that if data samples are close to each other in the handcrafted feature space, they likely represent the same type of activity. Thus, the features shared across multiple nearby data samples should represent the essential characteristics of that activity type. Features that only exist in some samples but not others likely represent individual or person-specific variations rather than core activity characteristics.
Formally, let
denote data sample
i in the feature space, and
the reconstruction of
produced by the autoencoder. Let
denote the index set of
local neighbors,
, of
in the handcrafted feature space. The feature consistency loss
for
is defined as:
This loss encourages the reconstruction of the center point to be similar to all of its neighbors in the feature space. By minimizing the difference between the reconstruction of a sample and its neighbors, the model learns to capture the common features shared across similar activity examples while disregarding individual variations. This guides the encoder to focus on information that is consistent across the neighborhood rather than on unique characteristics of individual samples.
For the feature consistency loss, we define the local neighborhood using k-nearest neighbors in the handcrafted statistical feature space, where . These feature neighbors are considered similar in terms of shared activity characteristics. As with temporal consistency, this neighbor selection is used exclusively for defining similarity relationships in the loss function and does not affect how training batches are constructed.
3.5.3. Model Architecture and Training Process
As shown in
Figure 6, the foundation of the overall architecture of this approach is an autoencoder framework with two task-oriented objective functions
,
and one regular reconstruction objective function
. By integrating guidance customized to HAR specifics, this approach facilitates learning representations that emphasize task-relevant information and minimize focus on irrelevant details. This equips the resulting representations with greater utility for subsequent activity analysis tasks.
Specifically, the model is trained using a joint loss function combining temporal consistency, feature consistency, and reconstruction objectives. This composite loss is defined as Equation (
13):
where
i is the index of the sample,
N is the size of the dataset, and
and
are the parameters to balance the contribution of
,
, and
. While
and
preserve more task-relevant information in the representation, the
component is also necessary in the learning process because without the reconstruction loss
, the risk of learning trivial solutions or worse representations will increase [
67]. By encouraging the model to accurately reconstruct the input data,
compels the learned representations to maintain the underlying structure and properties inherent in the data during the training. The specific contributions of each loss component to the overall performance are further analyzed through ablation studies presented in
Section 4.4.
3.6. Weakly Self-Supervised Approach
Building on the strengths and limitations of the approaches presented so far, we now introduce a novel two-stage framework that integrates weakly supervised and self-supervised learning. This weakly self-supervised approach bridges the concepts presented in
Section 3.3 and
Section 3.5, combining their complementary strengths to further reduce label dependency while maintaining strong performance.
Section 3.3 explores weak supervision using pairwise constraints with Siamese networks, while
Section 3.5 leverages self-supervision through domain knowledge losses to train a residual autoencoder without labeled data. The proposed approach integrates these methods by employing self-supervised training in the initial phase, followed by fine-tuning with limited pairwise constraints. Specifically, the first stage utilizes temporal and feature consistency losses from
Section 3.5 for self-supervised pre-training. In the second stage, the model is fine-tuned in a weakly supervised manner guided by similarity pairs, as outlined in
Section 3.3. By combining self-supervised residual autoencoder training with weakly supervised Siamese networks, this unified two-stage framework retains the advantages of self-supervision while effectively incorporating available weak supervision.
It is worth noting that we deliberately selected the weakly supervised single-task approach rather than the multi-task approach with self-supervision. This design choice stems from a fundamental compatibility consideration: the feature consistency component in our self-supervised approach explicitly attempts to eliminate person-specific variations by encouraging the model to focus on common activity patterns across different individuals. This objective would directly conflict with the person identification task in the multi-task approach, which aims to preserve and leverage precisely these individual differences. By using the single-task approach focused solely on activity recognition, we ensure alignment in our combined framework as both components share the goal of identifying activity patterns while disregarding person-specific variations.
Model Architecture and Training Process
The architecture of the proposed weakly self-supervised model is depicted in
Figure 7. The training process unfolds over two stages, each contributing uniquely to the model’s learning capabilities.
In the first stage, the model is trained using the joint loss function defined in Equation (
13). This loss function ensures that the model focuses on retaining task-relevant features while minimizing the influence of irrelevant ones. By leveraging self-supervised learning at this stage, the model establishes a foundational understanding of the underlying data structure.
In the second stage, the similarity loss
is introduced to enhance the model’s performance. Building upon the learned representations from the first stage, this phase applies a small set of pairwise constraints derived from weakly supervised data. These constraints refine the model’s representations by aligning them more closely with the target classes. The joint loss function for this stage is formulated as Equation (
14):
where
,
, and
are weight parameters that balance the contributions of temporal consistency, feature consistency, and similarity loss, respectively.
The similarity supervision
plays a pivotal role in this stage. Despite being limited in quantity, it is highly relevant to the activity recognition task. To maximize its impact, the similarity loss is assigned a larger weight, ensuring it dominates the learning process. Conversely, the remaining loss functions (two self-supervised and one unsupervised) serve as regularization terms. Their inclusion prevents overfitting and promotes robust and generalized learning. Additionally, the model’s feature extraction process remains consistent with the procedure outlined in
Section 3.2.1, maintaining methodological coherence across stages.
3.7. Methodology Summary and Clustering Approach
Table 2 summarizes the technical methodologies employed by the discussed approaches. All models are trained via standard backpropagation with stochastic gradient descent, with parameters initialized using small random values. The supervised learning approach is optimized with cross-entropy loss using ground-truth labels, aiming primarily at accurate classification rather than the extraction of latent representations.
In contrast, the remaining approaches, including the unsupervised, self-supervised, and weakly supervised paradigms, as well as their extensions, are designed to learn mappings from input data to latent representations , such that semantically similar activities are embedded close to one another in the latent space. This clustering-friendly structure enables direct application of off-the-shelf clustering algorithms on the learned representations. In our experiments, we applied k-means clustering to the latent space to group similar activity samples into clusters.
4. Evaluation and Experiments
We evaluated the effectiveness of our proposed approaches on three benchmark datasets: UCI-Smartphone [
6], PAMAP2 [
66], and REALDISP [
68], focusing on their performance in the HAR task with an emphasis on label efficiency. Using both accuracy and F1-score as evaluation metrics, we compared our methods against established techniques as well as our own implemented baselines.
For comparison with published works, we included several supervised approaches: DeepConvLSTM [
13], which integrates convolutional and LSTM recurrent units to capture temporal dynamics in sensor data without requiring manual feature engineering; Self-Attention [
69], which employs attention mechanisms to learn the importance of different sensor modalities and better capture spatio-temporal context; ResGCNN [
70], which leverages residual graph convolutional neural networks to model relationships between sensor data and enable transfer learning capabilities; and Contrastive GNN [
71], which models spatial dependencies between sensors as a graph and applies contrastive learning to maximize mutual information between local and global representations. Additionally, we considered Efficient Deep Clustering [
72], which offers a different approach by training an encoder through iterative pseudo-labeling, where temporally consistent clusters are refined using UMAP dimensionality reduction and HMM-based label smoothing. Most of these baseline methods, with the exception of Efficient Deep Clustering, rely on fully supervised learning paradigms, requiring complete labeled datasets for training, which highlights the importance of our research on reducing label dependency.
A consistent experimental protocol was followed across datasets, with stratified splits ensuring balanced activity class distributions in training, validation, and test sets. Beyond the metrics, we analyzed the quality of the learned representations, using visualization techniques to illustrate how effectively each method captured meaningful structures and discriminative features from raw sensor data. These comparisons highlight the advantages of the methods in producing task-relevant and label-efficient representations for HAR.
To isolate the effect of supervision strategy from architectural complexity, we adopted consistent backbone encoders within each methodological family. Supervised and weakly supervised approaches share a TCN-based encoder, while the unsupervised and self-supervised models use a residual-based encoder, which is suited for processing handcrafted statistical features and incorporating domain-specific inductive biases. As described in
Section 3.3, we also standardized the weak supervision signal using pairwise constraints across applicable methods. This design allows for a clean comparison of learning paradigms under aligned modeling conditions. The detailed model architectures and training configurations are provided in
Appendix A.
4.1. Datasets
Our approaches were evaluated on benchmark HAR datasets featuring diverse activities performed by multiple individuals using various wearable sensors [
18]. These datasets introduce real-world challenges, including varied activities, sensing modalities, and intra- and inter-person variability. Sensors captured motion, orientation, and physiological signals from various body locations, including data from accelerometers, gyroscopes, magnetometers, and other devices.
To standardize input, raw sensor streams were pre-processed into fixed-size windows using dataset-specific sliding window techniques. This sensor-rich evaluation highlights the robustness, flexibility, and label efficiency of our methods in multimodal activity recognition under realistic conditions.
Table 3 summarizes the key characteristics of the datasets used in this study.
4.1.1. UCI-Smartphone
The UCI-Smartphone dataset captures smartphone-based sensing data from 30 participants performing 12 activities. These include six fundamental motions (e.g., walking, lying down) and six postural transitions (e.g., stand-to-sit). Tri-axial accelerometer and gyroscope data were sampled at 50 Hz from smartphones worn on participants’ waists, providing insights into both dynamic and static body behaviors. For this study, postural transitions were grouped into a combined transition class, and sensor streams were segmented into 2.56 s windows with a 1.28 s overlap, following established practices [
7]. This dataset presents challenges related to individual variations and mobile HAR scenarios.
4.1.2. PAMAP2
The PAMAP2 dataset includes multimodal sensor data from nine participants performing 12 diverse activities, ranging from sports exercises (e.g., rope jumping) to household tasks (e.g., vacuuming). Data were collected using a heart rate monitor and three IMUs positioned on the chest, dominant wrist, and ankle, measuring accelerometer, gyroscope, magnetometer, and temperature signals. Following prior work [
64,
73], sensor streams were downsampled from 100 Hz to 33.3 Hz and segmented into 5.12 s windows with a 1 s step size. This dataset provides comprehensive multimodal data for analyzing human activities across various contexts.
4.1.3. REALDISP
The REALDISP dataset provides sensor recordings from 17 participants performing 33 fitness and workout activities, collected under different sensor placement conditions. In this study, we use the standard ideal-placement recordings to maintain consistency across all datasets. Other datasets in our evaluation, such as UCI-Smartphone and PAMAP2, do not include comparable displacement variants, so using the ideal setup ensures a clean and fair comparison of learning paradigms under aligned conditions. The data were collected using 9 MTx inertial sensors placed on both arms, legs, and the torso, capturing 3D acceleration, angular velocity, and magnetic field orientation at a 50 Hz sampling rate. Sensor streams were segmented into non-overlapping 2 s windows, following standard practices. With its rich body-wide sensing and extensive activity diversity, REALDISP supports the development of robust techniques for HAR tasks [
68].
4.2. Results and Analysis
The experimental results presented in
Table 4,
Table 5 and
Table 6 demonstrate the performance of the various deep learning approaches across the evaluated datasets. These findings offer a quantitative comparison, emphasizing the ability of the proposed methods to effectively capture meaningful activity representations. Notably, the proposed approaches achieve performance levels comparable to fully supervised models, despite relying on limited labeled data or weak supervision. In contrast, fully unsupervised models, which operate without any labeled data, exhibit significantly lower performance, underscoring the advantages of incorporating even minimal supervision for representation learning.
The performance of each method is influenced by dataset-specific characteristics that also mirror challenges encountered in real-world deployment. PAMAP2 consistently yields high accuracy for label-efficient approaches, including unsupervised, self-supervised, weakly supervised single-task, and multi-task methods, likely due to its favorable balance of sensor richness, activity diversity, and manageable complexity. REALDISP, while offering the most comprehensive body-wide sensing setup, includes a larger number of activity classes and higher inter-subject variability, which can increase learning difficulty, particularly under weak or self-supervised conditions. UCI-Smartphone, with its simpler sensor configuration and fewer activity classes, performs best under full supervision, where clean labels compensate for limited sensor coverage. These patterns highlight that sensor richness and dataset complexity, while potentially beneficial, may also introduce confounding factors such as user diversity, placement inconsistency, and signal noise. To ensure controlled comparisons across methods, this study focuses on ideal-placement settings, while recognizing that real-world deployments introduce additional variability not captured in this setup.
One of the key advantages of non-fully supervised learning approaches is their ability to significantly reduce the reliance on explicitly labeled data. However, this label efficiency comes with an inherent trade-off in accuracy. The results indicate that fully supervised models generally achieve consistently strong performance because of their direct access to complete labeled ground truth. In contrast, weakly supervised and self-supervised methods must infer structure and relationships from limited annotations or proxy tasks, which can introduce inconsistencies and errors. This trade-off becomes particularly evident in the weakly self-supervised approach, where increasing the fraction of labeled data from 1% to 10% leads to improved accuracy, though still falling short of fully supervised methods. This demonstrates that achieving label efficiency requires a careful balance between minimizing supervision requirements and maintaining model reliability.
The following subsections provide a detailed analysis of these outcomes, examining how each model performs and the insights derived from their results.
4.2.1. Weakly Supervised Single-Task Approach
The weakly supervised single-task approach demonstrates strong performance across all datasets, achieving 94.36%, 98.56%, and 97.96% accuracy on UCI-Smartphone, PAMAP2, and REALDISP, respectively. While it does not consistently outperform all supervised methods, it achieves results comparable to or better than several fully supervised techniques despite not requiring explicitly labeled data during training. By incorporating limited supervision in the form of activity similarity information, this method significantly outperforms unsupervised approaches (which achieve only 63.69%, 77.06%, and 64.01% across the datasets). These findings underline the potential of weak supervision to bridge the gap between fully supervised and unsupervised learning paradigms.
4.2.2. Weakly Supervised Multi-Task Approach
The weakly supervised multi-task approach achieves exceptional performance across all three datasets (98.85%, 98.93%, and 98.22%), outperforming our weakly supervised single-task method and many fully supervised approaches, including DeepConvLSTM, Self-Attention, and ResGCNN. On the UCI-Smartphone dataset, it even exceeds the performance of our fully supervised TCN baseline (98.85% vs. 98.66%). By leveraging limited supervision that accounts for both activity and person similarity, this method enhances performance by disentangling semantic representations while maintaining similarity metrics within the activity and person domains. Its superior performance compared to single-task approaches highlights the framework’s effective capability to share information among related tasks, illustrating the advantages of multi-task learning in weakly supervised settings.
4.2.3. Self-Supervised Approach
The self-supervised approach, an enhanced version of the standard autoencoder, consistently outperforms the standard autoencoder across all three datasets (74.01% vs. 63.69% on UCI-Smartphone, 85.43% vs. 77.06% on PAMAP2, and 68.12% vs. 64.01% on REALDISP). It effectively derives meaningful features for activity clustering without relying on labeled data. Although fully supervised methods achieve higher accuracy by leveraging labeled data, they are constrained by the need for such annotations. The performance gap between self-supervised and fully supervised approaches varies by dataset, with PAMAP2 showing the smallest gap (85.43% vs. 95.27%). We note that activity transitions, such as sit-to-stand or stand-to-walk, tend to produce ambiguous signal patterns that may challenge the assumption of temporal continuity. These edge cases can introduce inconsistencies in representation learning, limiting the effectiveness of self-supervised objectives that rely on local consistencies. Despite these limitations, the approach successfully learns robust representations that enhance clustering performance, showcasing its potential in label-scarce scenarios.
4.2.4. Weakly Self-Supervised Approach
The weakly self-supervised approach achieves significant improvements over both unsupervised and self-supervised methods, underscoring the benefits of integrating even minimal weakly labeled data. Its performance demonstrates a clear trend: as the amount of labeled data increases, so does the model’s effectiveness. With just 1% of labeled data, the approach already achieves substantial gains over the purely self-supervised method (80.15% vs. 74.01% on UCI-Smartphone, 91.28% vs. 85.43% on PAMAP2, and 75.15% vs. 68.12% on REALDISP). With 10% of labeled data, it approaches the performance of many fully supervised methods (93.52%, 99.04%, and 92.23% across the three datasets), despite using only a small fraction of the annotations. In particular, on PAMAP2, with 10% labels it achieves 99.04% accuracy, exceeding even our fully supervised TCN baseline (95.27%). These results validate our design decision to integrate the single-task approach with self-supervision rather than the multi-task approach, as the alignment between their objectives (both focusing on activity recognition while disregarding person-specific variations) enables effective knowledge transfer even with minimal labeled data. This ability to maximize the utility of available information underscores its adaptability and efficiency. Overall, the results validate the strength of this approach in effectively combining weak supervision with self-supervision to outperform purely unsupervised and self-supervised alternatives.
4.3. Visualization
To better understand the learned representations, we visualized the distribution of activity representation vectors using t-SNE [
24], a technique that maps high-dimensional data into a low-dimensional space. These visualizations, derived from the UCI-Smartphone dataset, are presented in
Figure 8 and
Figure 9, where different colors denote various activities. The following observations can be drawn:
Semantic disentanglement: The evaluated deep representation learning approaches effectively disentangle semantic representations, forming distinct clusters in the representation space. This separation facilitates downstream tasks such as clustering, which leverage these representations for improved performance.
Effectiveness of weakly supervised approaches: As shown in
Figure 8a,b, the weakly supervised single-task and multi-task approaches produce the most distinct clusters, benefiting from the use of all labeled data. However, this comes with the trade-off of requiring extensive labeling.
Multi-task mechanism advantage: The weakly supervised multi-task approach (
Figure 8b) outperforms the single-task variant (
Figure 8a) by leveraging knowledge sharing between activity recognition and person identification tasks, resulting in improved cluster quality.
Self-supervised efficiency:
Figure 8c illustrates the self-supervised approach’s effectiveness in generating reasonably distinct clusters. This highlights the role of temporal and feature consistency in shaping meaningful clusters.
Reduced labeling requirements: Although the weakly self-supervised approach (
Figure 9) does not achieve the same level of cluster distinctiveness as weakly supervised methods, it relies on only a fraction of the labeled data, whereas weakly supervised methods utilize the entire labeled dataset. This distinction underscores the weakly self-supervised approach’s ability to alleviate the labeling burden while still maintaining competitive performance.
4.4. Ablation Studies on the Effect of Domain Knowledge
To evaluate the individual contributions of different loss terms in our self-supervised approach, we conducted a series of ablation experiments by selectively removing components of the loss formulation. We focused on the self-supervised model as it incorporates multiple domain-specific objectives that can be independently analyzed.
Specifically, we trained separate models using reduced loss configurations: (i) a model trained with only the temporal consistency loss (
) and reconstruction losses (
), and (ii) a model trained with only the feature consistency loss (
) and reconstruction losses. By comparing the performance of these ablated models, we isolated the impacts of
and
. The results of these experiments are presented in
Table 7.
The findings reveal that models trained with either or outperform the vanilla autoencoder in most scenarios. However, the model incorporating all three loss terms, , achieves the best overall results, indicating the complementary nature of and . A closer examination highlights the greater impact of the loss, which aligns with the intuition that consistency in the feature space provides a stronger supervisory signal for activity recognition than temporal consistency alone.
Interestingly, we observed that on the REALDISP dataset, adding only temporal consistency () to the reconstruction loss () resulted in a slight performance decrease (from 64.01% to 63.41%). This dataset-specific behavior might be attributed to the unique characteristics of the REALDISP dataset, which contains 33 fitness activities with potentially more complex temporal dynamics than the other datasets. Nevertheless, the complete model with all three losses still achieves the best performance across all datasets, confirming the overall benefit of our approach.
These ablation studies underscore the effectiveness of incorporating domain knowledge into representation learning models. By dissecting the role of each loss component, we demonstrate that integrating these design choices enables models to achieve strong accuracy while significantly reducing the reliance on labeled data.
5. Conclusions
This study provides a comprehensive exploration across the supervision spectrum for HAR using wearable sensors, directly addressing the critical challenge of label dependency. We systematically investigated fully supervised learning, unsupervised learning, weakly supervised learning with pairwise constraints, multi-task learning with knowledge sharing, self-supervised learning incorporating domain knowledge, and our novel weakly self-supervised framework that combines complementary strengths of multiple paradigms. Through systematic evaluation across multiple benchmark datasets, we demonstrated how each approach navigates the fundamental trade-off between supervision requirements and recognition performance.
Our findings reveal several significant insights: First, weakly supervised methods achieve performance comparable to fully supervised approaches while eliminating the need for explicit activity labels, instead relying on pairwise similarity constraints that are often easier to obtain. Second, multi-task learning effectively integrates related tasks such as HAR and person identification, leveraging shared knowledge to enhance overall performance beyond what single-task approaches can achieve. Third, incorporating domain knowledge through temporal and feature consistency enables self-supervised approaches to learn meaningful representations without any labels, significantly outperforming standard unsupervised methods. Finally, our novel weakly self-supervised framework demonstrates remarkable label efficiency, achieving 99.04% accuracy on PAMAP2 with only 10% of labeled data, surpassing even fully supervised techniques that require complete label sets.
Our careful design choices, such as integrating single-task rather than multi-task supervision with self-supervision to ensure objective alignment, further enhanced the effectiveness of our approaches. These results have important implications for both research and practical HAR applications where labeled data is scarce or expensive to obtain. They provide a systematic framework for selecting appropriate learning methodologies based on label availability and application requirements. By reducing the annotation burden while maintaining high accuracy, this work advances representation learning for wearable sensor data and paves the way for more scalable, efficient, and practical HAR systems in real-world settings. Future work will consider expanding evaluation to additional datasets and deployment scenarios to further assess generalizability under varied sensor conditions.



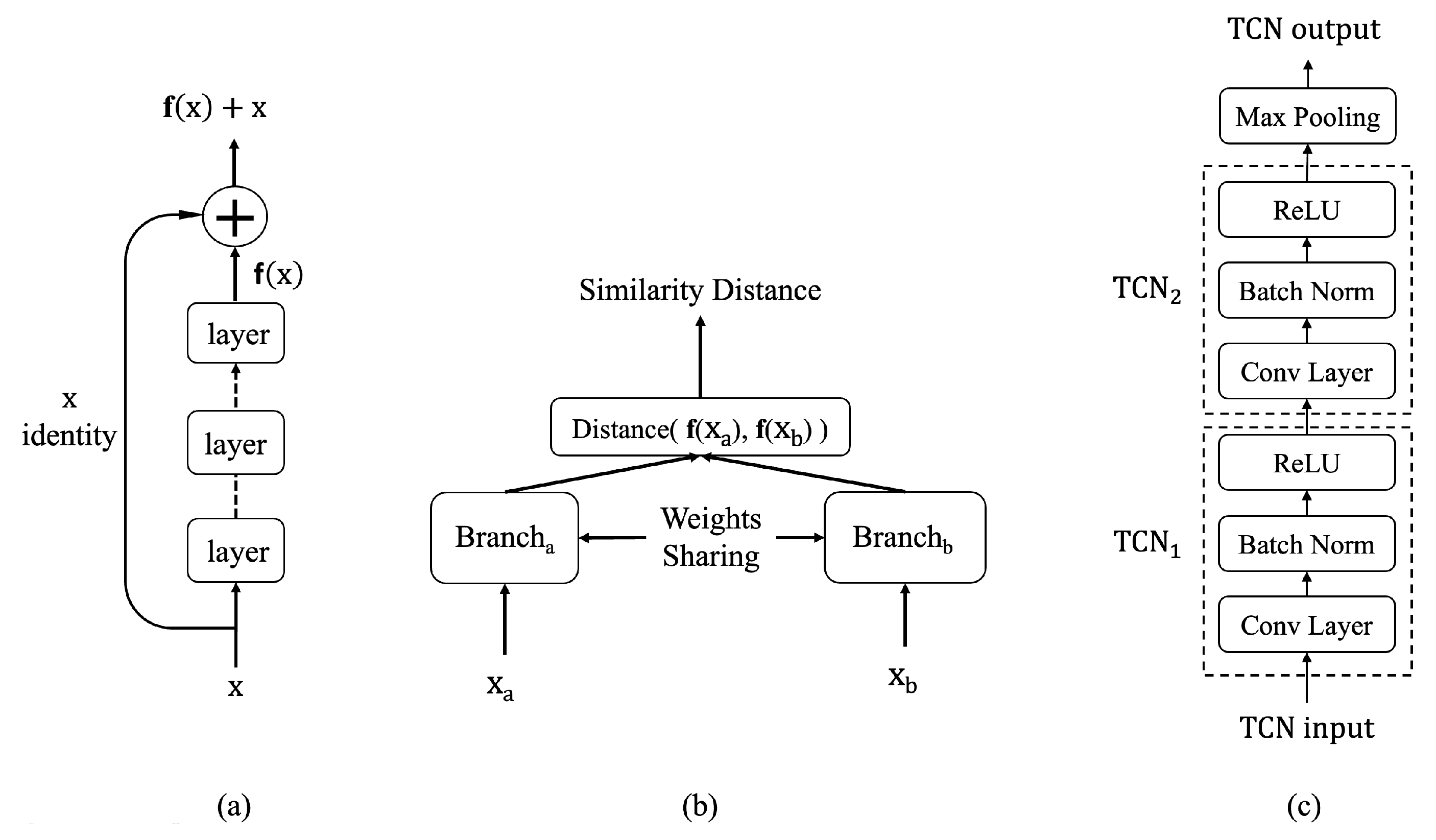
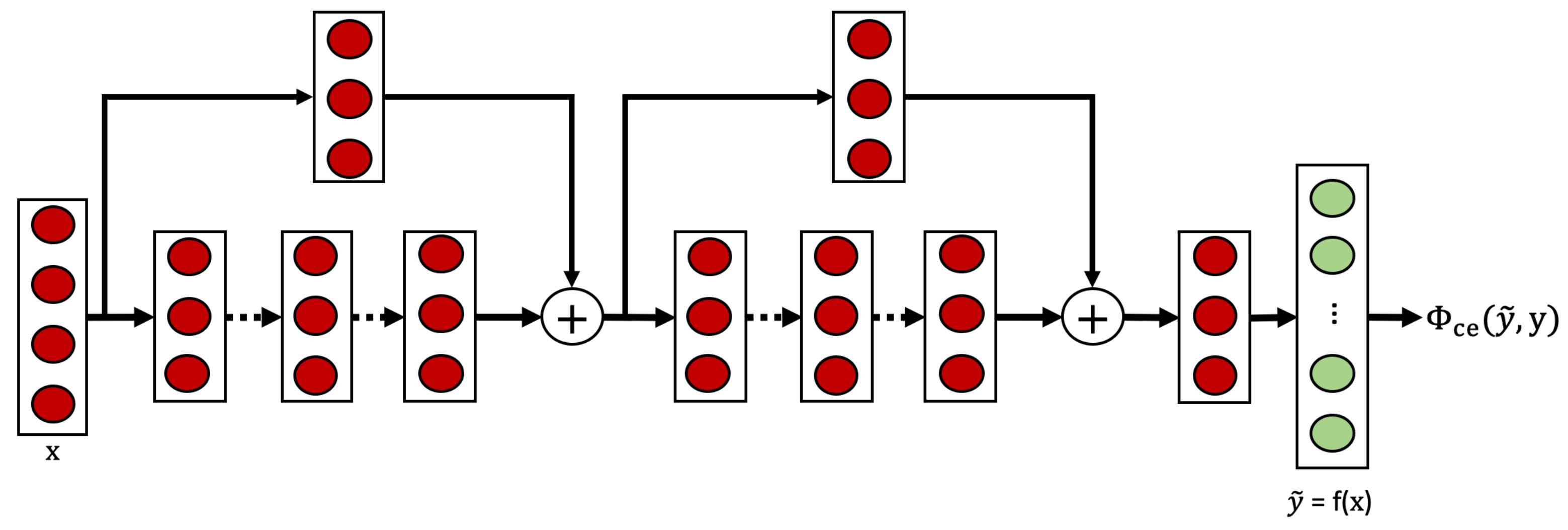
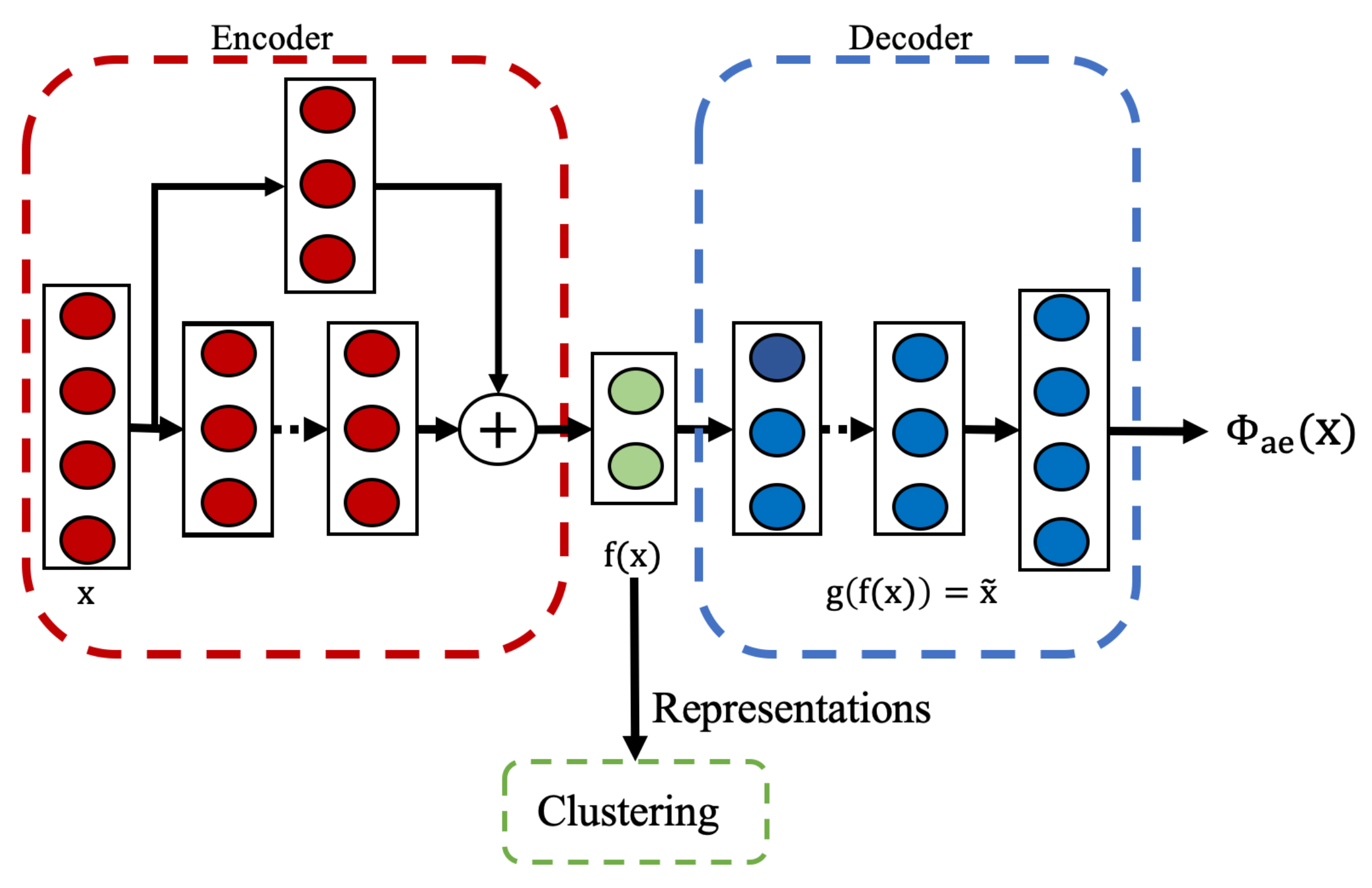
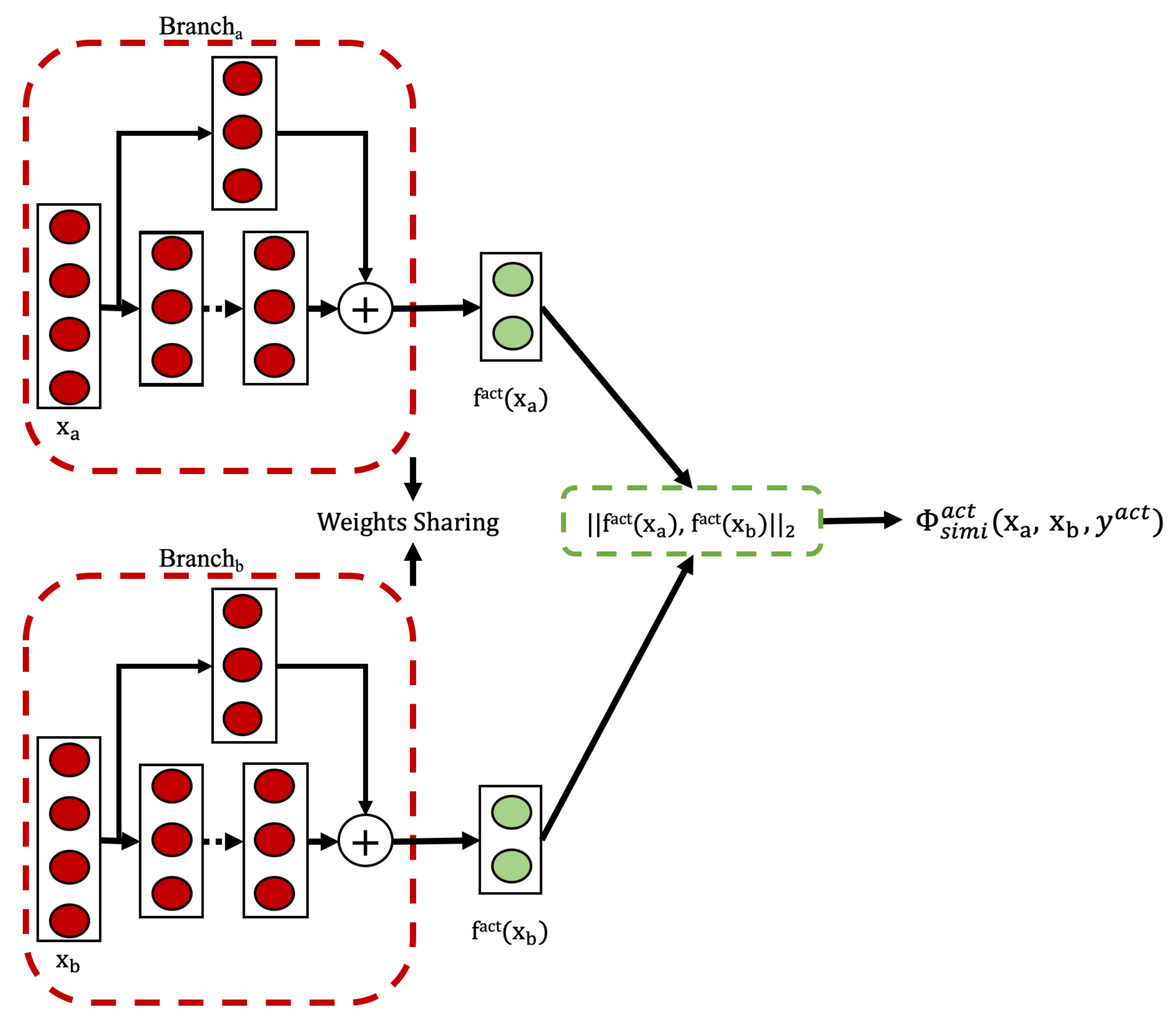
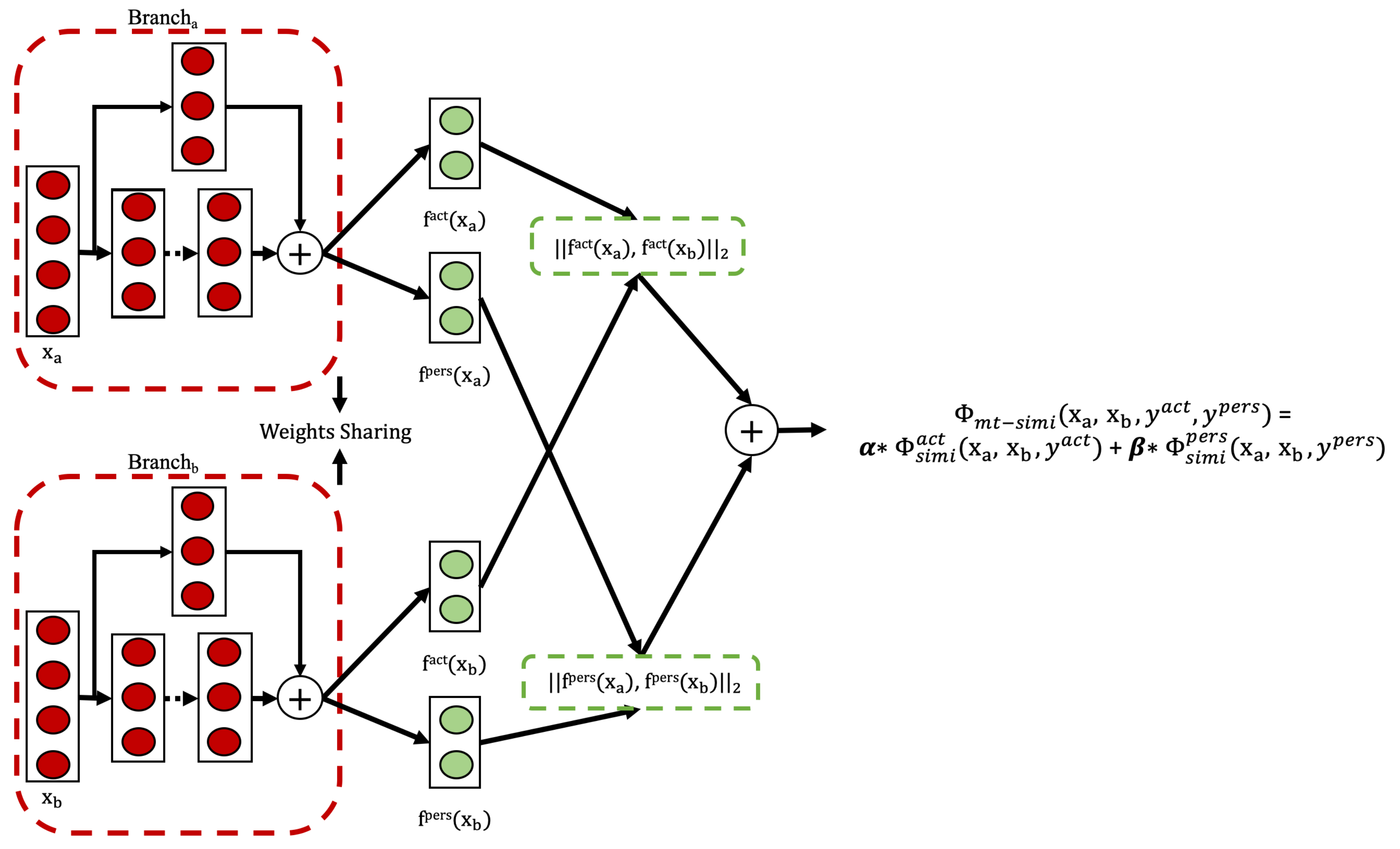

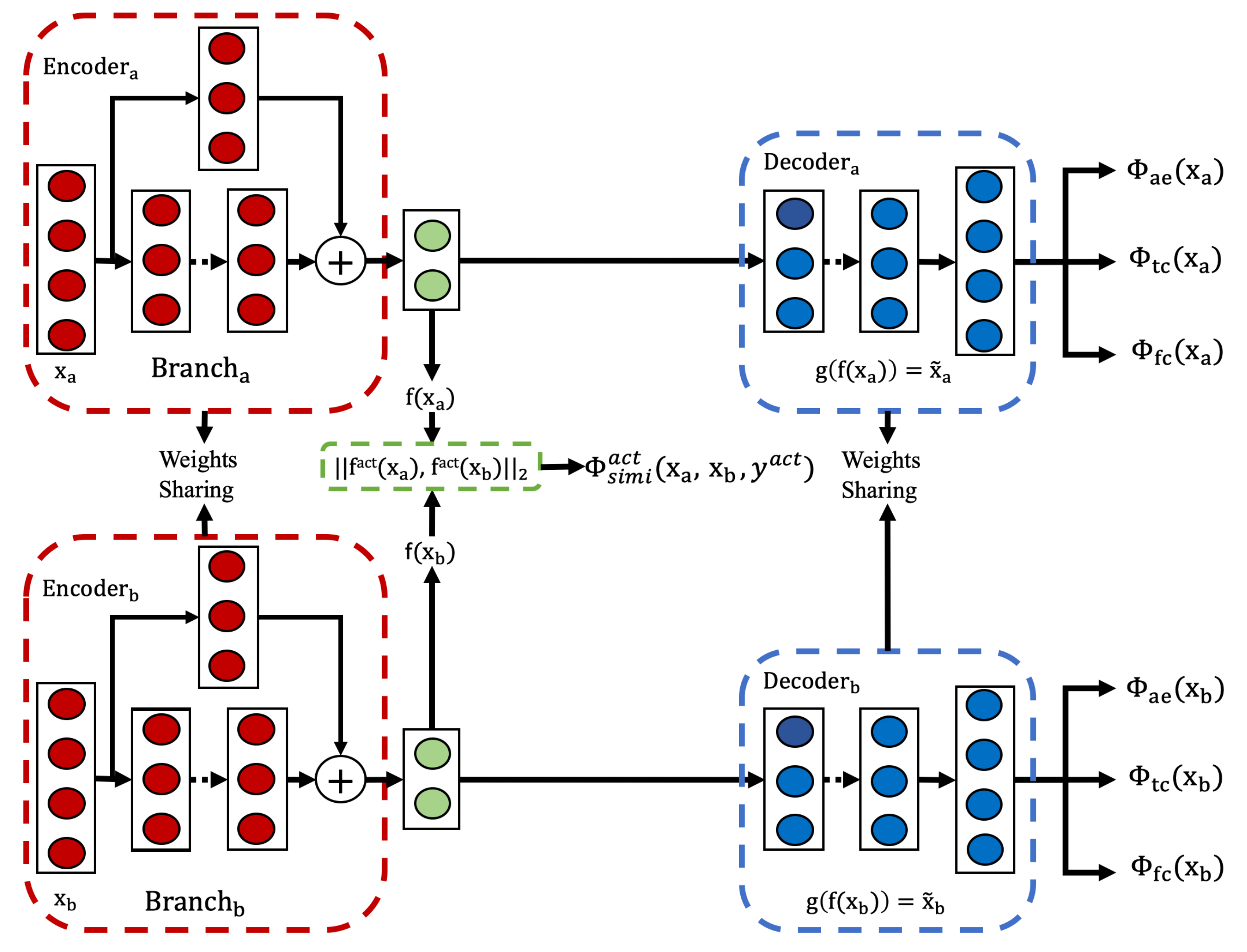
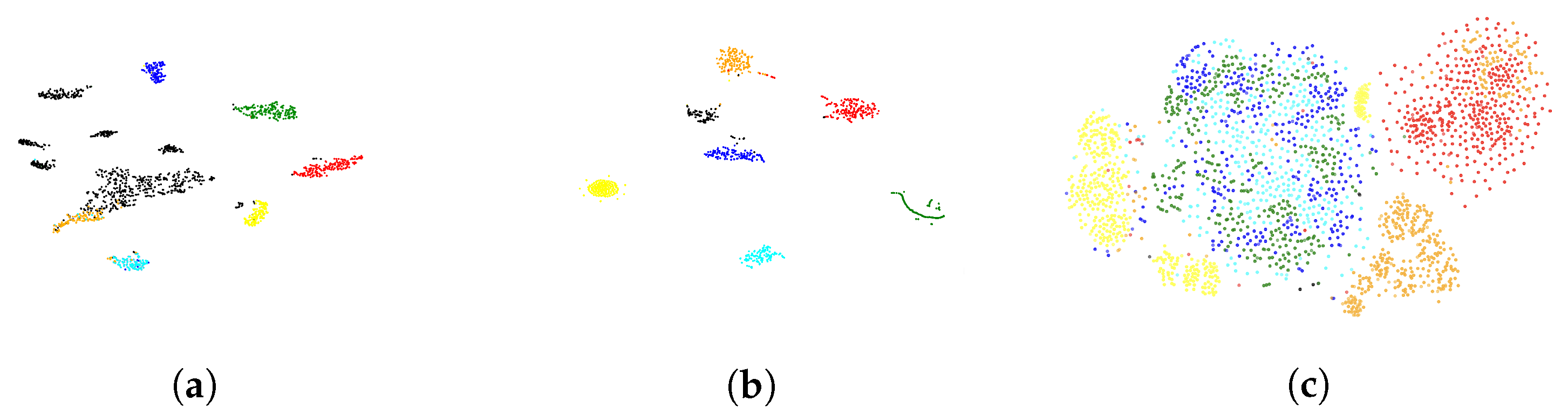


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}