
Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition
 , and
, and
Abstract
1. Introduction
- -
- RQ1: How can we enhance the efficiency and accuracy of FER using a lightweight deep learning model?
- -
- RQ2: To what extent does the integration of Gabor and LBP features and a modified AlexNet architecture improve the performance of FER in resource-constrained environments?
- -
- RQ3: Can the combination of depthwise-separable convolution and pointwise convolution significantly reduce the computational costs of FER models without sacrificing their performance in terms of emotion detection accuracy?
- -
- A novel FER method was developed, which utilizes Gabor and LBP features to extract texture information, along with a modified AlexNet for classification;
- -
- The developed FER method was optimized for limited hardware resources;
- -
- A modified AlexNet model was successfully developed and validated for classification purposes in this research;
- -
2. Proposed Method
2.1. Feature Extraction
2.1.1. Gabor Feature
2.1.2. LBP Feature
2.2. FER with Modified AlexNet
3. Results
3.1. Datasets and Evaluation Metrics
- (1)
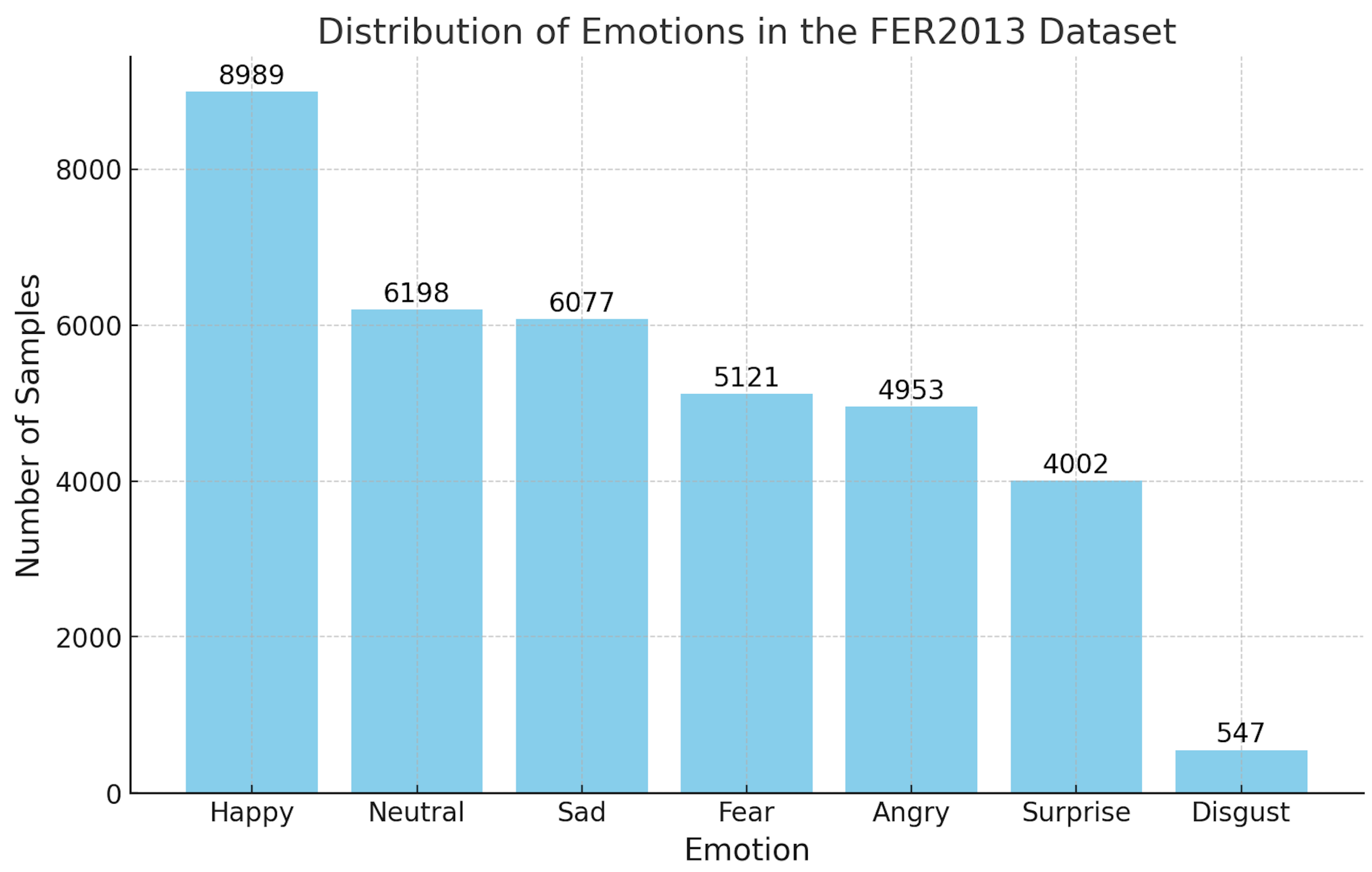
- The FER2013 [29] dataset consists of grayscale images, each labeled with the corresponding emotion displayed by the person. It features 48 × 48 pixel images categorized into seven emotions (Figure 3): angry, disgust, fear, happy, sad, surprise, and neutral. The dataset is divided into three parts: 28,709 images for training, 3589 for public testing, and 3589 for private testing.
- (2)
- The RAF-DB [30] dataset comprises 15,339 facial images collected from real-world scenarios, showcasing a broad spectrum of emotions displayed by individuals in natural settings. The dataset includes a variety of emotions (Figure 4), such as anger, disgust, fear, happiness, sadness, surprise, and neutral expressions.

3.1.1. Precision
3.1.2. Recall
3.1.3. F1-Score
3.1.4. Accuracy
3.2. Experimental Settings and Results
Model Performances
4. Discussion
- -
- Enhancing both efficiency and accuracy in FER represents a long-standing challenge in affective computing, particularly when deploying models in real-time, low-resource environments such as embedded systems, mobile devices, or surveillance systems. Our study proposes a lightweight yet expressive deep learning framework by modifying the classical AlexNet architecture. The key to achieving this efficiency–accuracy balance lies in network compression without performance degradation. We adopt depthwise-separable convolutions, which decompose standard convolutions into spatial and channel-wise operations. This reduces the number of parameters and floating-point operations significantly—by approximately 80%—compared to standard convolution layers. Despite this compression, we observed only marginal degradation in performance, and in some cases, even improved accuracy, suggesting better generalization due to reduced overfitting. The result is a model that maintains discriminative power for emotion classification while being computationally tractable for real-time inference.
- -
- The integration of handcrafted features—particularly Gabor filters and LBP—with deep learning architectures is a strategy rooted in hybrid feature representation, which seeks to combine domain knowledge with data-driven learning. This integration aims to augment the model’s robustness, especially when training data is limited or heterogeneous. Gabor filters model the response of the human visual cortex to spatial frequency and orientation, making them biologically inspired and well-suited for detecting local facial structure changes (e.g., eye wrinkles or smile contours). They are particularly effective at encoding directional and frequency-sensitive information—key cues in emotional expression. LBP, on the other hand, excels in capturing fine-grained texture variations through pixel intensity comparisons, which is critical for representing subtle expressions, such as disgust or fear. Our results showed that fusing these handcrafted features with deep feature maps significantly improved classification accuracy across both the FER2013 and RAF-DB datasets. This is particularly important in resource-constrained settings, where the depth of the network is limited and may struggle to learn complex low-level features from scratch. The hybrid approach effectively compensates for this limitation by injecting priors into the learning process, improving feature richness and reducing the model’s dependency on data quantity.
- -
- The integration of depthwise-separable convolution with pointwise convolution helps tackle one of the major challenges in deploying deep learning models by reducing computational cost. Traditional CNNs apply full 3D kernels across all input channels, which scales poorly as the number of channels increases. In contrast, depthwise convolution applies a single filter per input channel, followed by pointwise convolution (1×1) to combine the resulting features across channels. This drastically reduces both the parameter count and floating-point operations while maintaining expressive power. Our empirical findings show that this architectural refinement preserves or even enhances accuracy, particularly when combined with domain-specific enhancements like Gabor and LBP. The reduction in model complexity improves generalization by reducing overfitting, especially when the training data is noisy or unbalanced—common challenges in FER datasets. From a deployment perspective, this architectural decision makes our model viable for edge computing, where computational and memory budgets are minimal. Furthermore, the reduced model size facilitates on-device learning and privacy-preserving computation, which are emerging needs in privacy-sensitive applications.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wróbel, M.R. Emotion Recognition and Its Applications. In Human-Computer Systems Interaction: Backgrounds and Applications 3; Hippe, Z., Kulikowski, J., Mroczek, T., Wtorek, J., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2014; Volume 300. [Google Scholar] [CrossRef]
- Yi, M.-H.; Kwak, K.-C.; Shin, J.-H. KoHMT: A Multimodal Emotion Recognition Model Integrating KoELECTRA, HuBERT with Multimodal Transformer. Electronics 2024, 13, 4674. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Kutlimuratov, A.; Nasimov, R.; Whangbo, T.K. Improved speech emotion recognition focusing on high-level data representations and swift feature extraction calculation. Comput. Mater. Contin. 2023, 77, 2915–2933. [Google Scholar] [CrossRef]
- Cavus, N.; Esmaili, P.; Sekeroglu, B.; Aşır, S.; Azar, N.A.N. Detecting emotions through EEG signals based on modified convolutional fuzzy neural network. Sci. Rep. 2024, 14, 10371. [Google Scholar] [CrossRef]
- Wang, L.; Hao, J.; Zhou, T.H. ECG Multi-Emotion Recognition Based on Heart Rate Variability Signal Features Mining. Sensors 2023, 23, 8636. [Google Scholar] [CrossRef]
- Shen, Z.; Cheng, J.; Hu, X.; Dong, Q. Emotion Recognition Based on Multi-View Body Gestures. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3317–3321. [Google Scholar] [CrossRef]
- Ciraolo, D.; Fazio, M.; Calabrò, R.S.; Villari, M.; Celesti, A. Facial expression recognition based on emotional artificial intelligence for tele-rehabilitation. Biomed. Signal Process. Control. 2024, 92, 106096, ISSN 1746-8094. [Google Scholar] [CrossRef]
- Kalyta, O.; Barmak, O.; Radiuk, P.; Krak, I. Facial Emotion Recognition for Photo and Video Surveillance Based on Machine Learning and Visual Analytics. Appl. Sci. 2023, 13, 9890. [Google Scholar] [CrossRef]
- Chowdary, M.K.; Nguyen, T.N.; Hemanth, D.J. Deep learning-based facial emotion recognition for human–computer interaction applications. Neural Comput. Appl. 2023, 35, 23311–23328. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Mamieva, D.; Abdusalomov, A.B.; Kutlimuratov, A.; Muminov, B.; Whangbo, T.K. Multimodal Emotion Detection via Attention-Based Fusion of Extracted Facial and Speech Features. Sensors 2023, 23, 5475. [Google Scholar] [CrossRef]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Afect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Chen, D.; Wen, G.; Li, H.; Chen, R.; Li, C. Multi-Relations Aware Network for In-the-Wild Facial Expression Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3848–3859. [Google Scholar] [CrossRef]
- Makhmudov, F.; Kultimuratov, A.; Cho, Y.-I. Enhancing Multimodal Emotion Recognition through Attention Mechanisms in BERT and CNN Architectures. Appl. Sci. 2024, 14, 4199. [Google Scholar] [CrossRef]
- Gao, G.; Chen, C.; Liu, K.; Mashhadi, A.; Xu, K. Automatic face detection based on bidirectional recurrent neural network optimized by improved Ebola optimization search algorithm. Sci. Rep. 2024, 14, 27798. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, H.; Guo, W.; Zhou, M.; Li, S.; Li, J.; Ding, Y. LighterFace Model for Community Face Detection and Recognition. Information 2024, 15, 215. [Google Scholar] [CrossRef]
- Charoqdouz, E.; Hassanpour, E. Feature Extraction from Several Angular Faces Using a Deep Learning Based Fusion Technique for Face Recognition. Int. J. Eng. 2023, 36, 1548–1555. [Google Scholar] [CrossRef]
- Yang, Y. Facial Features Extraction And Clustering With Machine Learning. In Proceedings of the EITCE’ 22: Proceedings of the 2022 6th International Conference on Electronic Information Technology and Computer Engineering; Xiamen, China, 21–23 October 2022, pp. 1806–1810. [CrossRef]
- Anand, M.; Babu, S. Multi-class Facial Emotion Expression Identification Using DL-Based Feature Extraction with Classification Models. Int. J. Comput. Intell. Syst. 2024, 17, 25. [Google Scholar] [CrossRef]
- Rakhimovich, A.M.; Kadirbergenovich, K.K.; Ishkobilovich, Z.M.; Kadirbergenovich, K.J. Logistic Regression with Multi-Connected Weights. J. Comput. Sci. 2024, 20, 1051–1058. [Google Scholar] [CrossRef]
- Nautiyal, A.; Bhardwaj, D.K.; Narula, R.; Singh, H. Real Time Emotion Recognition Using Image Classification. In Proceedings of the 2023 Fifteenth International Conference on Contemporary Computing (IC3-2023), Noida, India, 3–5 August 2023; pp. 8–12. [Google Scholar] [CrossRef]
- Lolaev, M.; Madrakhimov, S.; Makharov, K.; Saidov, D. Choosing allowability boundaries for describing objects in subject areas. IAES Int. J. Artif. Intell. 2024, 13, 329–336. [Google Scholar] [CrossRef]
- Vaijayanthi, S.; Arunnehru, J. Deep neural network-based emotion recognition using facial landmark features and particle swarm optimization. Automatika 2024, 65, 1088–1099. [Google Scholar] [CrossRef]
- Palestra, G.; Pettinicchio, A.; Del Coco, M.; Carcagnì, P.; Leo, M.; Distante, C. Improved Performance in Facial Expression Recognition Using 32 Geometric Features. In Image Analysis and Processing—ICIAP 2015; Murino, V., Puppo, E., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland; Volume 9280. [CrossRef]
- Chen, L.; Zhou, M.; Su, W.; Wu, M.; She, J.; Hirota, K. Softmax regression based deep sparse autoencoder network for facial emotion recognition in human-robot interaction. Inf. Sci. 2018, 428, 49–61. [Google Scholar] [CrossRef]
- Fu, S.; Li, Z.; Liu, Z.; Yang, X. Interactive knowledge distillation for image classification. Neurocomputing 2021, 449, 411–421. [Google Scholar] [CrossRef]
- Ma, T.; Tian, W.; Xie, Y. Multi-level knowledge distillation for low-resolution object detection and facial expression recognition. Knowl.-Based Syst. 2022, 240, 108136, ISSN 0950-7051. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Proceedings of the Neural Information, Processing; Lee, M., Hirose, A., Hou, Z.G., Kil, R.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Li, S.; Deng, W.; Du, J.P. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Munawar, H.S.; Aggarwal, R.; Qadir, Z.; Khan, S.I.; Kouzani, A.Z.; Mahmud, M.A.P. A Gabor Filter-Based Protocol for Automated Image-Based Building Detection. Buildings 2021, 11, 302. [Google Scholar] [CrossRef]
- Mehrotra, R.; Namuduri, K.R.; Ranganathan, N. Gabor filter-based edge detection. Pattern Recognit. 1992, 25, 1479–1494, ISSN 0031-3203. [Google Scholar] [CrossRef]
- Song, Z. Facial Expression Emotion Recognition Model Integrating Philosophy and Machine Learning Theory. Front. Psychol. 2021, 12, 759485. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolutiongray-scale and rotation invariant texture classification withlocal binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Niu, B.; Gao, Z.; Guo, B. Bingbing, Facial Expression Recognition with LBP and ORB Features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef]
- Garcia Freitas, P.; Da Eira, L.P.; Santos, S.S.; Farias, M.C.Q.D. On the Application LBPTexture Descriptors and Its Variants for No-Reference Image Quality Assessment. J. Imaging 2018, 4, 114. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Kuldashboy, A.; Umirzakova, S.; Allaberdiev, S.; Nasimov, R.; Abdusalomov, A.; Im Cho, Y. Efficient image classification through collaborative knowledge distillation: A novel AlexNet modification approach. Heliyon 2024, 10, e34376. [Google Scholar] [CrossRef] [PubMed]
- Powers, D.M. Evaluation: From precision, recall and Fmeasure to ROC, informedness, markedness and correlation. J. Mach. Learn. Res. 2011, 2, 37–63. [Google Scholar]
- Liao, L.; Wu, S.; Song, C.; Fu, J. RS-Xception: A Lightweight Network for Facial Expression Recognition. Electronics 2024, 13, 3217. [Google Scholar] [CrossRef]
- Gursesli, M.C.; Lombardi, S.; Duradoni, M.; Bocchi, L.; Guazzini, A.; Lanata, A. Facial Emotion Recognition (FER) Through Custom Lightweight CNN Model: Performance Evaluation in Public Datasets. IEEE Access 2024, 12, 45543–45559. [Google Scholar] [CrossRef]
- Kalsum, T.; Mehmood, Z. A Novel Lightweight Deep Convolutional Neural Network Model for Human Emotions Recognition in Diverse Environments. J. Sens. 2023, 2023, 6987708. [Google Scholar] [CrossRef]
- Chen, X.; Huang, L. A Lightweight Model Enhancing Facial Expression Recognition with Spatial Bias and Cosine-Harmony Loss. Computation 2024, 12, 201. [Google Scholar] [CrossRef]
- Peng, C.; Li, B.; Zou, K.; Zhang, B.; Dai, G.; Tsoi, A.C. An Innovative Neighbor Attention Mechanism Based on Coordinates for the Recognition of Facial Expressions. Sensors 2024, 24, 7404. [Google Scholar] [CrossRef]
- Soman, G.; Vivek, M.V.; Judy, M.V.; Papageorgiou, E.; Gerogiannis, V.C. Precision-Based Weighted Blending Distributed Ensemble Model for Emotion Classification. Algorithms 2022, 15, 55. [Google Scholar] [CrossRef]
- Alsharekh, M.F. Facial Emotion Recognition in Verbal Communication Based on Deep Learning. Sensors 2022, 22, 6105. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, D. Expression Recognition Using Improved AlexNet Network in Robot Intelligent Interactive System. J. Robot. 2022, 2022, 4969883. [Google Scholar] [CrossRef]
- Zhang, Y. DCAlexNet: Deep coupled AlexNet for micro facial expression recognition based on double face images. Comput. Biol. Med. 2025, 189, 109986, ISSN 0010-4825. [Google Scholar] [CrossRef] [PubMed]
- Salas-Cáceres, J.; Lorenzo-Navarro, J.; Freire-Obregón, D.; Castrillón-Santana, M. Multimodal emotion recognition based on a fusion of audiovisual information with temporal dynamics. Multimed. Tools Appl. 2024. [Google Scholar] [CrossRef]
- Makhmudov, F.; Kilichev, D.; Giyosov, U.; Akhmedov, F. Online Machine Learning for Intrusion Detection in Electric Vehicle Charging Systems. Mathematics 2025, 13, 712. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotions | Accuracy (%) | Average Accuracy and Standard Deviation (%) | ||
|---|---|---|---|---|
| FER2013 | RAF-DB | FER2013 | RAF-DB | |
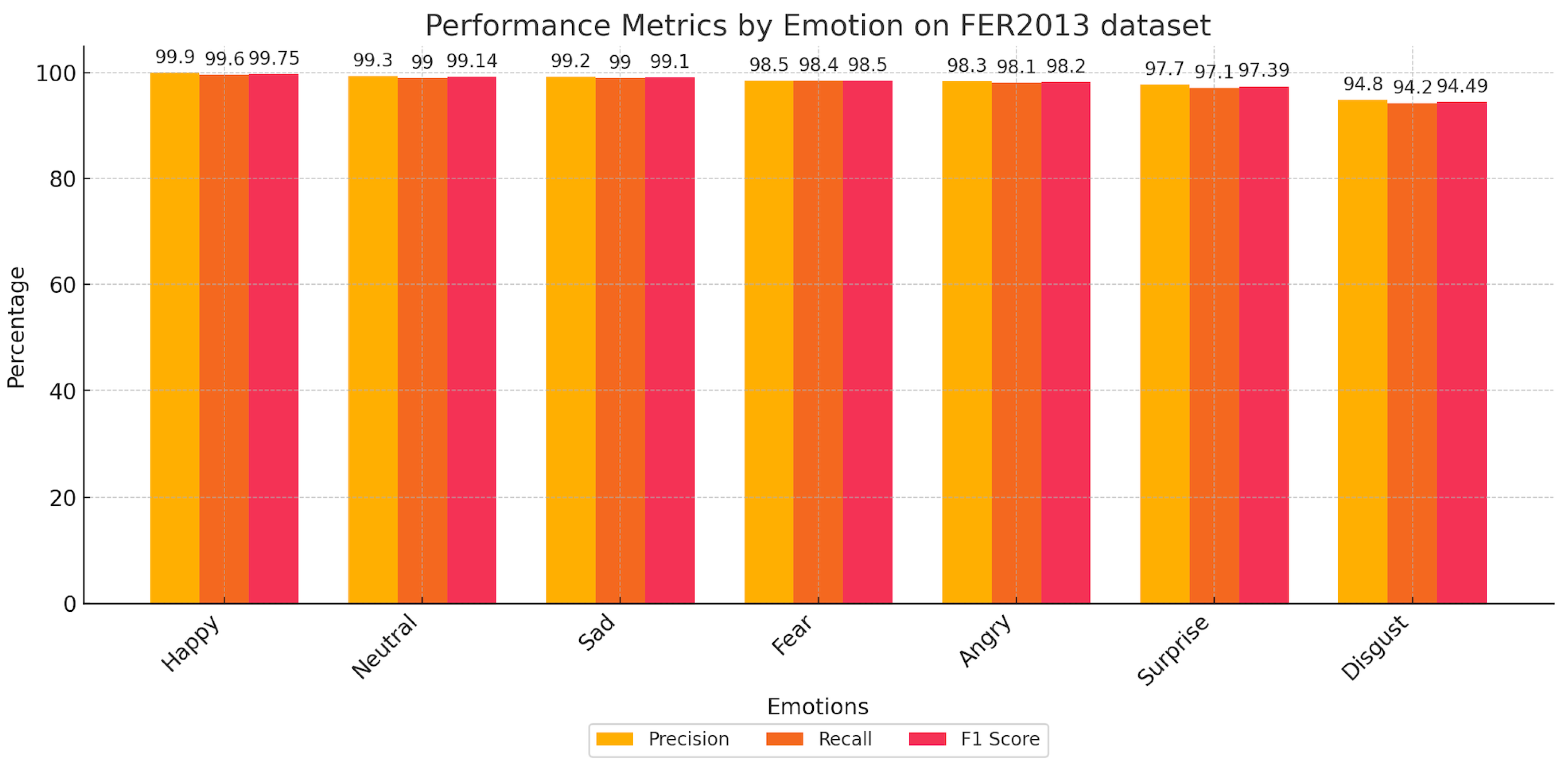
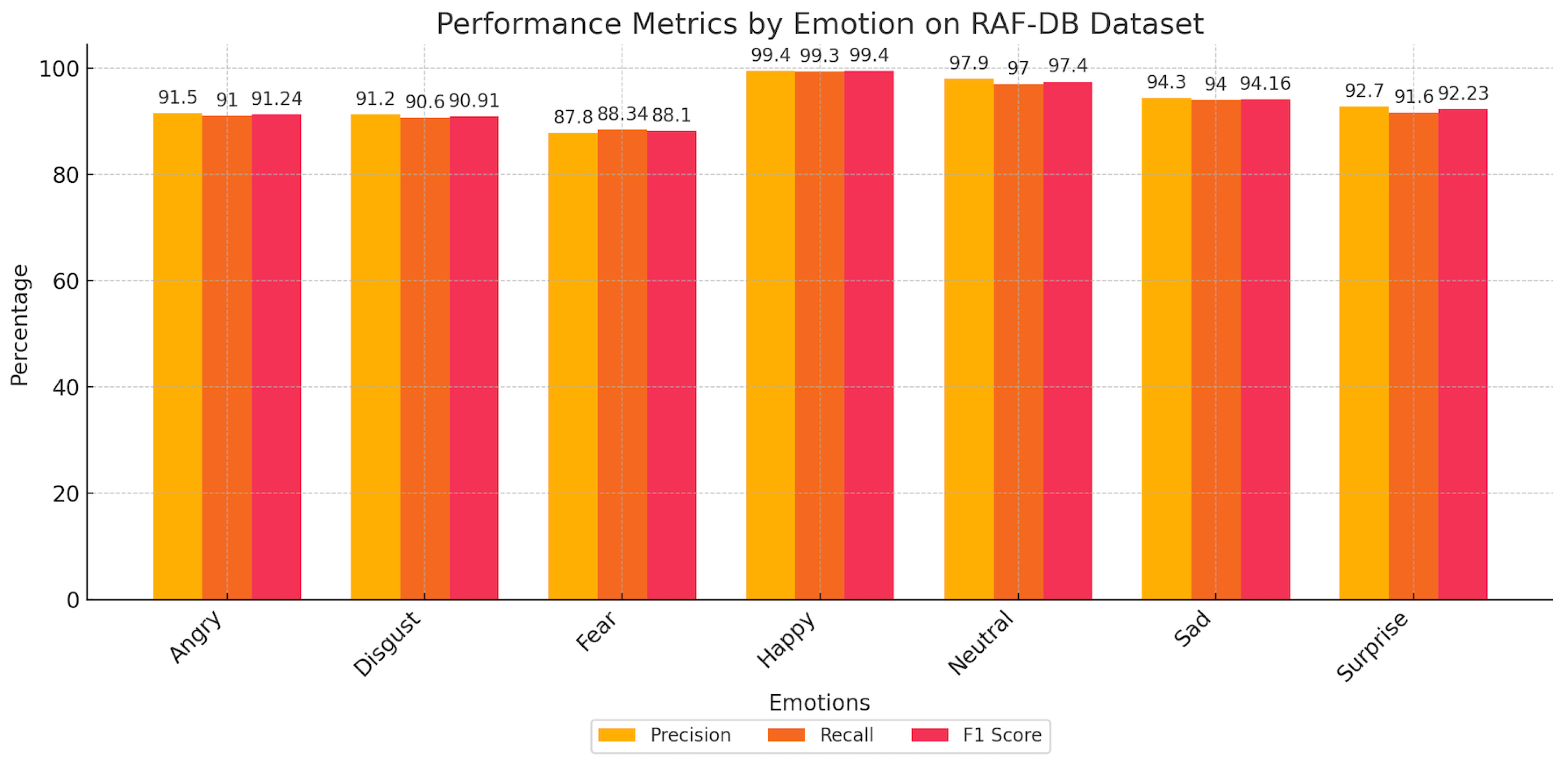
| Happy | 99.75 | 99.37 | 98.10 and 1.63 | 93.34 and 3.62 |
| Neutral | 99.15 | 97.43 | ||
| Sad | 99.10 | 94.15 | ||
| Fear | 98.47 | 88.10 | ||
| Angry | 98.20 | 91.25 | ||
| Surprise | 97.40 | 92.20 | ||
| Disgust | 94.50 | 91.0 | ||
| Happy | Neutral | Sad | Fear | Angry | Surprise | Disgust | |
|---|---|---|---|---|---|---|---|
| Happy | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Neutral | 0.01 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Sad | 0.00 | 0.00 | 0.99 | 0.01 | 0.00 | 0.00 | 0.00 |
| Fear | 0.00 | 0.00 | 0.00 | 0.98 | 0.02 | 0.00 | 0.00 |
| Angry | 0.00 | 0.00 | 0.02 | 0.00 | 0.98 | 0.00 | 0.00 |
| Surprise | 0.02 | 0.00 | 0.00 | 0.00 | 0.01 | 0.97 | 0.00 |
| Disgust | 0.00 | 0.00 | 0.00 | 0.04 | 0.02 | 0.00 | 0.94 |
| Angry | Disgust | Fear | Happy | Neutral | Sad | Surprise | |
|---|---|---|---|---|---|---|---|
| Angry | 0.91 | 0.00 | 0.03 | 0.00 | 0.00 | 0.06 | 0.00 |
| Disgust | 0.01 | 0.91 | 0.05 | 0.00 | 0.00 | 0.03 | 0.00 |
| Fear | 0.03 | 0.00 | 0.88 | 0.00 | 0.00 | 0.09 | 0.00 |
| Happy | 0.00 | 0.00 | 0.00 | 0.99 | 0.00 | 0.00 | 0.01 |
| Neutral | 0.00 | 0.00 | 0.00 | 0.02 | 0.97 | 0.01 | 0.00 |
| Sad | 0.01 | 0.00 | 0.05 | 0.00 | 0.00 | 0.94 | 0.00 |
| Surprise | 0.00 | 0.00 | 0.00 | 0.06 | 0.00 | 0.02 | 0.92 |
| References | Models | Average Accuracy (%) | |
|---|---|---|---|
| FER2013 | RAF-DB | ||
| Lia et.al. [40] | RS-exception | 69.02 | 82.98 |
| Gursesli et.al. [41] | Custom Lightweight CNN-based Model (CLCM) | 63.0 | 84.0 |
| Kalsum et.al. [42] | EfficientNet_FER | 69.87 | 84.10 |
| Chen et al. [43] | Lightweight Facial Network with Spatial Bias | - | 91.07 |
| Peng et al. [44] | Coordinate-based Neighborhood Attention Mechanism | - | 92.37 |
| Soman et al. [45] | Weighted Ensemble Model | 76.20 | - |
| Alsharekh M.F. [46] | Deep CNN | 89.20 | - |
| Our model | Modified Alexnet with LBP and Gabor Features | 98.10 | 93.34 |
| Metric | FER2013 Std Dev (%) | RAF-DB Std Dev (%) | U Statistic | p-Value | Significant (p < 0.05) |
|---|---|---|---|---|---|
| Accuracy | 1.622 | 3.632 | 41.0 | 0.037 | Yes |
| Precision | 1.558 | 3.726 | 41.0 | 0.037 | Yes |
| Recall | 1.687 | 3.586 | 42.0 | 0.029 | Yes |
| F1-Score | 1.626 | 3.642 | 41.0 | 0.037 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safarov, F.; Kutlimuratov, A.; Khojamuratova, U.; Abdusalomov, A.; Cho, Y.-I. Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition. Sensors 2025, 25, 3832. https://doi.org/10.3390/s25123832
Safarov F, Kutlimuratov A, Khojamuratova U, Abdusalomov A, Cho Y-I. Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition. Sensors. 2025; 25(12):3832. https://doi.org/10.3390/s25123832
Chicago/Turabian StyleSafarov, Furkat, Alpamis Kutlimuratov, Ugiloy Khojamuratova, Akmalbek Abdusalomov, and Young-Im Cho. 2025. "Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition" Sensors 25, no. 12: 3832. https://doi.org/10.3390/s25123832
APA StyleSafarov, F., Kutlimuratov, A., Khojamuratova, U., Abdusalomov, A., & Cho, Y.-I. (2025). Enhanced AlexNet with Gabor and Local Binary Pattern Features for Improved Facial Emotion Recognition. Sensors, 25(12), 3832. https://doi.org/10.3390/s25123832