1. Introduction
In contemporary industrial production, product quality assurance serves dual imperatives: maintaining a competitive advantage and ensuring consumer trust. The integration of automation and intelligent systems has elevated industrial visual anomaly detection to a pivotal role in optimizing manufacturing precision and operational throughput [
1,
2,
3]. Nevertheless, conventional supervised learning paradigms encounter practical constraints in this domain, particularly stemming from the labor-intensive process of collecting and labeling defective visual data, compounded by data privacy regulations that further restrict anomaly sample availability. These operational challenges necessitate alternative methodologies for precise defect identification. Unsupervised learning has consequently emerged as a promising solution, demonstrating notable efficacy in scenarios with limited annotated data [
2].
Within industrial visual inspection frameworks, unsupervised techniques enable anomaly detection and localization model development through the exclusive utilization of defect-free training samples. This paradigm shift addresses both the scarcity of anomalous exemplars and the prohibitive costs associated with manual annotation. Standard implementations employ pristine image datasets for model training, while evaluation protocols incorporate mixed sets containing both normal and anomalous instances. Current methodological approaches predominantly frame this challenge as an out-of-distribution detection problem. Recent advancements in unsupervised anomaly detection have yielded several principal technical trajectories, including feature embedding-based methods [
4,
5,
6,
7], reconstruction-based methods [
8,
9,
10].
Reconstruction-based approaches identify anomalies through differential error analysis between original and reconstructed images [
10,
11]. The underlying hypothesis posits that autoencoders or generative adversarial networks achieve superior reconstruction fidelity on nominal patterns compared to anomalous regions. However, practical implementations reveal limitations in discriminative capacity as reconstruction artifacts may obscure differences between normal and defective regions [
7,
12]. This inherent ambiguity frequently manifests as performance instability across diverse industrial use cases.
Recent advancements in teacher–student frameworks have demonstrated notable efficacy in visual anomaly detection through hierarchical feature reconstruction. Bergmann et al. [
4] pioneered this paradigm with their Uninformed Students, establishing foundational work in unsupervised anomaly recognition via teacher–student discrepancy analysis. Subsequent innovations [
5,
13] improve the model through systematic multi-layer feature alignment, establishing standardized protocols for multi-resolution anomaly mapping via cross-layer matching errors between architecturally symmetric teacher–student pairs.
While achieving benchmark performance, contemporary teacher–student-based anomaly detection approaches reveal several critical limitations. First, the absence of regularization mechanisms during knowledge transfer makes student model overfitting risks. Empirical evidence suggests that even when trained exclusively on anomaly-free samples, student networks may inadvertently encode anomalous patterns through latent feature sharing with teacher representations, thereby compromising detection specificity. Second, existing implementations [
14,
15,
16] frequently employ computationally intensive architectures to enhance accuracy, exemplified by AEKD’s dual-student configuration [
14], which escalates hardware requirements and complicates industrial deployment.
To overcome these constraints, we propose a Synthetic-Anomaly Contrastive Distillation (SACD) framework. The SACD framework comprises several crucial components: (1) a reverse distillation mechanism where a frozen teacher model utilizing ImageNet-pretrained weights extracts multi-scale representations to guide a structurally inverted student network through layer-wise feature alignment, and (2) a set of feature calibration (FeaCali) modules that eliminate noise interference while retaining critical anomaly indicators in student-decoded features. This configuration preserves normal pattern learning while proactively exposing the student model to synthetic anomalies, thereby enhancing discriminative capacity against potential defects. During training, SACD achieves dual objectives. On the one hand, it can reinforce inter-model consistency in normal feature representation through contrastive distillation, and on the other hand, we intend to amplify feature discrepancies in abnormal pattern decoding via synthetic anomaly confrontation. Moreover, FeaCali modules are designed to ensure parameter-efficient alignment between student and teacher embeddings while mitigating overfitting risks.
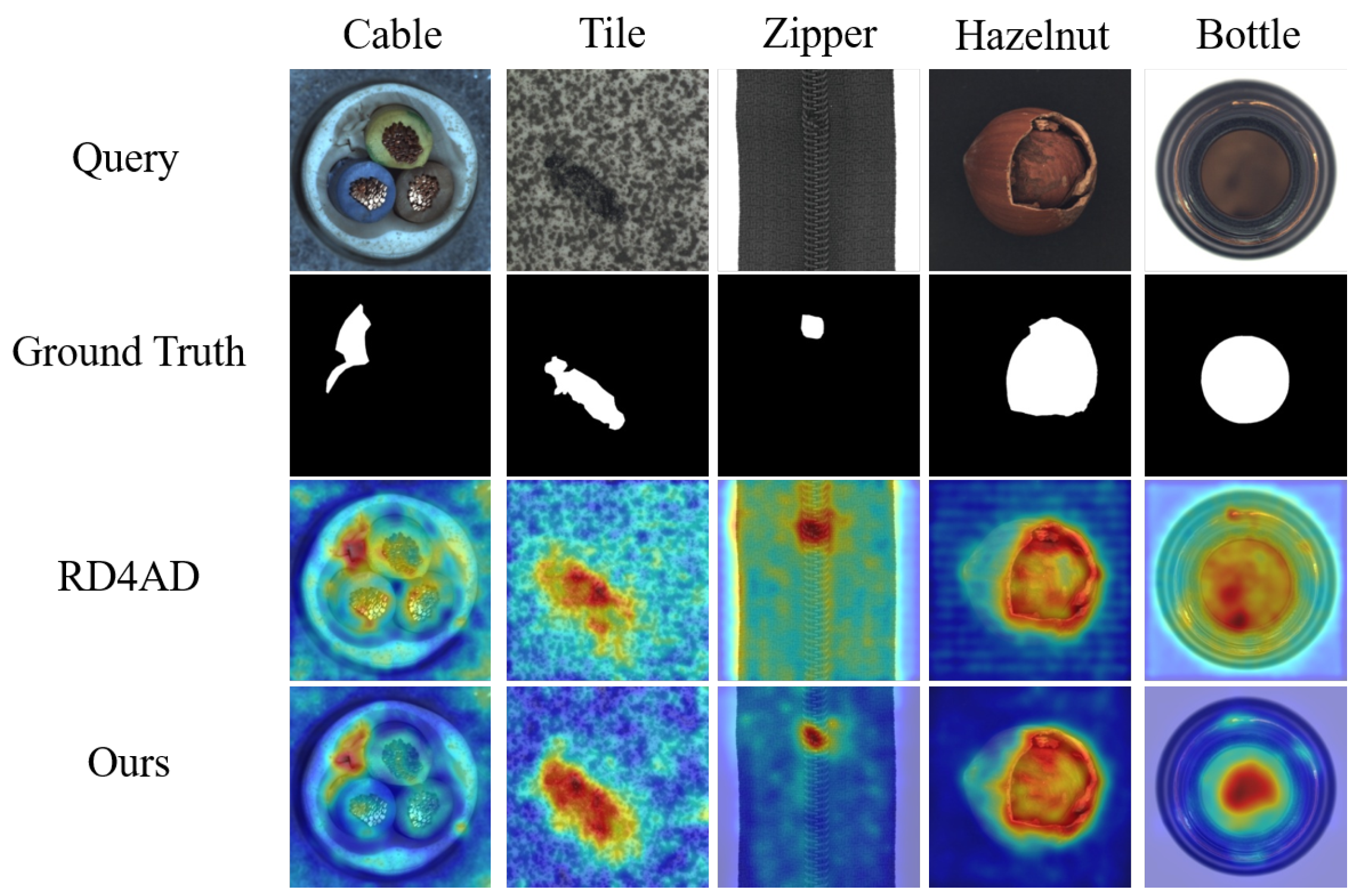
The proposed framework employs a dual-objective loss function that orchestrates the training process through two aspects: cross-model feature alignment between the student–teacher pair and intra-model component coordination within the Siamese students. This composite loss simultaneously enforces representation consistency across network hierarchies while maintaining functional complementarity among different streams, thereby ensuring concurrent optimization of normal pattern reconstruction fidelity and abnormal feature discrimination capability. During inference, pixel-wise anomaly scores are computed via multi-scale feature deviation metrics between the teacher’s preserved knowledge and the student’s calibrated outputs. Extensive benchmark evaluations on the MVTec AD dataset [
17] demonstrate the effectiveness of our proposed
SACD framework. Qualitative and quantitative results show that
SACD achieves superior performance in anomaly detection and localization tasks, surpassing current baseline methods in terms of detection accuracy, while achieving optimizations in model size and computational complexity.
In summary, the main contributions of this paper are as follows:
We propose a novel Synthetic-Anomaly Contrastive Distillation framework for industrial image anomaly detection, which enhances anomalous feature decoupling while preserving normal pattern reconstruction capabilities of the student model.
We construct a dual-objective loss function encompassing both cross-model feature alignment and intra-model component coordination, enabling hierarchical representation consistency and discrepancy amplification between the teacher–student model.
Extensive experiments conducted on the MVTec AD and BTAD dataset demonstrated our proposed method is effective and achieves superior anomaly detection performance with optimized model size and computational efficiency compared with the current KD-based approaches.
3. Method
In this section, we elaborate on the overall framework of the proposed Synthetic-Anomaly Contrastive Distillation (
SACD) framework, as illustrated in
Figure 1.
SACD comprises a Siamese reverse distillation flow and a group of feature calibration modules. During training, the teacher encoder is frozen; the weights of the one-class bottleneck embedding (
OCBE) module, student decoder, and
FeaCali modules are optimized via a dual-objective loss function.
3.1. Reverse Distillation
Reverse distillation comprises three main components: the teacher encoder, the OCBE module, and the student decoder.
3.1.1. Teacher Encoder
In unsupervised anomaly detection using knowledge distillation, constructing a robust teacher model is essential. Following Wang et al. [
33], we employ a WideResNet-50 model pre-trained on ImageNet as the teacher encoder. The ResNet-like architecture, with its multiple residual blocks, enables the network to capture complex feature representations. Intermediate outputs from these blocks are treated as multi-scale feature representations of input images [
5,
14,
33,
43,
44]. Based on this idea, and in line with previous work, by default, feature maps from the 1st, 2nd, and 3rd layers of WideResNet-50 are selected as learning targets for the student model. This allows the student decoder to inherit rich multi-level features, enhancing multi-scale feature reconstruction and anomaly perception.
Let
T denote the teacher model. For an input
I, the multi-scale features are obtained as
where
,
, and
correspond to the outputs of the 1st, 2nd, and 3rd layers of the teacher encoder
T, respectively.
3.1.2. One-Class Bottleneck Embedding
In conventional encoder–decoder frameworks, the decoder typically relies on the final-layer output of the encoder. However, reverse distillation poses challenges when transferring high-level embeddings from the teacher encoder directly to the student decoder, as it hinders the reconstruction of fine-grained features. To mitigate this, as is presented in
Figure 2, OCBE is designed to facilitate multi-scale feature fusion and dimensionality reduction through feature compaction, preserving essential information while mapping high-dimensional inputs to a lower-dimensional space. This design enhances the student decoder’s ability to interpret hierarchical features from the teacher, leading to more expressive and efficient reconstructions.
Let
denote the fusion and compression function of the OCBE module. By integrating the three feature embeddings
,
, and
, the resultant representation can be expressed as
:
3.1.3. Student Decoder
Upon receiving the compressed multi-scale teacher features
, the student decoder is required to reconstruct feature embeddings of identical dimensions across different scales based on these features. Consequently, in the reverse distillation process, the student decoder is designed with an inverse architecture, while ensuring that the size of its output tensors remains consistent with the corresponding teacher embeddings. Specifically, the number of forward residual blocks in the student decoder is aligned with that of the teacher encoder, while the channel dimensions are adjusted via upsampling to match the embedding dimensions of the teacher model at the corresponding scales. It is worth noting that, in contrast to conventional convolutional pooling operations, the reverse process employs deconvolution for upsampling. The entire procedure can be formalized as follows:
where
,
, and
correspond to the outputs of the 1st, 2nd, and 3rd layers of the student decoder
S, respectively.
3.2. Siamese Reverse Distillation Flow
In traditional multi-scale feature knowledge distillation frameworks, teacher–student models typically follow a one-to-one configuration, where the teacher model transfers multi-layer embedding knowledge of normal images to the student model. The student then identifies anomalous regions based on the representation differences between the teacher and student model. However, during training, the student model may overfit or develop overly strong encoding capabilities, causing it to produce representations for anomalous regions that closely resemble those of the teacher, thereby degrading anomaly detection performance. In view of this, we extend the original anomaly-free input and synthesize abnormal substitutes of normal samples using image-level anomaly synthesis. Additionally, we introduce a Siamese reverse distillation flow to encode and decode the features of both normal and synthesized abnormal inputs.
3.2.1. Normal RD Branch
Assuming the input anomaly-free sample is denoted as
, the processing through the normal branch yields two sets of features:
where
,
, and
denote the anomaly-free features encoded by the teacher model, while
,
, and
represent the feature embeddings reconstructed by the student decoder.
3.2.2. Abnormal RD Branch
As described above, normal branch is responsible for receiving and encoding multi-scale features of normal images. In this way, abnormal branch receives and encodes the anomalous version (synthesized) of the corresponding normal image. Importantly, our goal is for the student network to exclusively encode features from the normal regions, while ensuring a significant difference in the representation of anomalous regions between the teacher and student models. In addition to the basic RD model, the anomaly branch also incorporates an anomaly synthesis module and a feature refinement module. The details of these components are described in the following subsections.
- (1)
Anomaly Synthesis
This paper assumes that normal and anomalous patterns might share some basic features, which allows the student model to reconstruct anomalies effectively. To handle this, we create anomalous versions of normal images during training. This helps the student model learn about anomalies beforehand, preparing it for better detection later. Recent studies have suggested methods like Gaussian noise [
33], masking [
45], and CutPaste [
21] for creating anomalies. Given its effectiveness and simplicity, we use the simplex method as our default approach. Simplex noise performs better than Gaussian noise when simulating anomalies using a power-law distribution. As shown in
Figure 3, simplex noise creates more natural-looking anomalies compared to Gaussian noise. Let
represent the synthesized anomalous image, and the full process is described in Algorithm 1.
Consistent with the normal branch, the RD model encodes the synthesized anomaly samples into two sets of features:
where
,
, and
denote the anomaly-free features encoded by the teacher model, while
,
, and
represent the feature embeddings reconstructed by the student decoder.
Since the input consists of anomaly samples, the features encoded by the teacher model will contain anomalous patterns. After undergoing fusion and compression operations in the OCBE module, these features may still retain latent anomalous patterns due to the absence of an explicit mechanism to eliminate such anomalies. Consequently, the multi-scale feature embeddings reconstructed by the student model will also include latent anomaly information, which can undermine the feature matching process between the teacher and student models, thereby degrading the performance of anomaly detection.
| Algorithm 1: Pseudo-code of the process of anomaly synthesis |
Input: Normal training set , discrete range , noise parameter
Output: Modified training set with Simplex noise
![Sensors 25 03721 i001]() |
- (2)
Feature Calibration Module
As stated in the assumption, when the input image contains anomalies, the feature calibration (
FeaCali) module is designed to filter out potential anomalous patterns from the student decoder’s outputs. This prevents performance degradation caused by anomaly leakage. To keep the module lightweight,
FeaCali uses stacked convolutional blocks in a bottleneck style, including convolution, InstanceNorm, and LeakyReLU layers, where the channel dimensionality is halved progressively at each layer. After obtaining restored feature embeddings
,
, and
, the
FeaCali module operates in multi-scale modes, denoted as
,
, and
, individually. Its main task is to take intermediate layer outputs as input and refine them by augmenting normal features. Through this process,
,
, and
are refined into
,
, and
.
Figure 4 shows the structure of the MFR module. In the experiments,
L is set to 2.
3.3. Training Objective
We design a dual-objective loss function to train the OCBE module, student decoder, and
FeaCali module. This function ensures consistent hierarchical representations between the teacher and student models while amplifying discrepancies for anomaly detection. The total loss consists of two parts: cross-model feature alignment loss, denoted as
, and intra-model component coordination loss, denoted as
.
transfers knowledge from the teacher model to the student model, enabling the student to replicate the teacher’s understanding of normal image features.
optimizes the
FeaCali module, helping it filter out potential anomalies and reconstruct high-quality normal features. The overall loss is expressed as
where
is a positive regularization parameter for adjusting the optimization weights of the
FeaCali module.
3.3.1. Intra-Model Component Coordination Loss
After building the FeaCali module, we aim for it to enhance normal features and filter out anomalous ones. A simple approach is to use the multi-scale restored feature embeddings from the student decoder’s normal branch as ground truth to guide feature reconstruction. The loss is computed using cosine similarity to optimize the FeaCali module.
First, the features
,
, and
are flattened from shape (B, C, H, W) to (B,
) to calculate the similarity between teacher and student features at each layer. The total loss is the sum of these layer-wise losses:
where
represents the flattening operation,
is the number of feature layers used in training, and
denote the height and width of the k-th feature map. Cosine similarity measures feature similarity, and minimizing
optimizes the
FeaCali module.
3.3.2. Cross-Model Feature Alignment Loss
In order to effectively transfer the teacher model’s multi-scale knowledge to the student model, the teacher–student models employ cosine similarity as the knowledge distillation loss
for knowledge transfer and feature alignment. The loss function for optimizing the
OCBE module and student decoder is derived from the following equation:
where,
denotes the number of feature layers used in training, and
h and
w represent the height and width of the k-th feature map.
3.4. Inference and Anomaly Scoring
During the inference stage, the entire reverse distillation process is fully retained, and the output of the student decoder is enhanced by the
FeaCali module for normal feature refinement. Given a query image
, we obtain a pair of multi-level feature embeddings from the teacher and student models, denoted as
,
,
and
,
,
, respectively. Then we calculate the anomaly score based on the difference between the outputs of the intermediate layers at corresponding positions of the teacher and student models:
where
refers to the anomaly score in (
h,
w) of the k-th feature map,
h and
w are the corresponding location in the query image.
To locate anomalies in the query image, we combine anomaly prediction score maps from different scales. Intermediate layer features are upsampled to match the query image’s resolution using bilinear interpolation. The final anomaly map is computed as
where
represents the final anomaly map, and
is a Gaussian filter with
to smooth noise in the map. The inference process is illustrated in
Figure 5.
5. Conclusions
This paper proposes a Synthetic-Anomaly Contrastive Distillation (SACD) framework for industrial image anomaly detection. SACD is built on two key components: (1) a reverse distillation framework where a pre-trained teacher network extracts hierarchical representations, guiding the student network with an inverse architecture to achieve feature alignment across multiple scales; and (2) FeaCali modules that refine the student’s outputs by filtering out anomalous feature responses. During training, SACD employs a dual-branch strategy, with one branch encoding multi-scale features from defect-free images and a Siamese anomaly branch processing synthetically corrupted samples. The FeaCali modules are trained to eliminate anomalous patterns in the anomaly branch, enabling the student network to focus exclusively on modeling normal patterns. A dual-objective optimization framework, combining cross-model distillation loss and intra-model contrastive loss, is used to train SACD, ensuring effective feature alignment and enhanced discrepancy amplification. At the inference stage, pixel-wise anomaly scores are computed based on discrepancies between the teacher’s representations and the student’s refined outputs across multiple layers. Extensive evaluations on the MVTec AD benchmark confirm our approach is effective and achieve superiority to current KD-based approaches for anomaly detection.
In future work, we plan to explore cross-domain anomaly detection scenarios, where the model trained on one type of industrial product is required to generalize to unseen categories or domains with minimal adaptation. This is crucial for practical deployment, as collecting labeled anomaly data for every product line is often infeasible. In addition, we aim to investigate more natural and physically consistent anomaly synthesis methods, beyond procedural noise, to better mimic the texture, geometry, and defect formation process of real-world industrial anomalies. Such approaches could further enhance the realism and diversity of training data, thereby improving the robustness of detection models in complex environments.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}